 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Explainable Artificial Intelligence (XAI) from a user perspective- A synthesis of prior literature and problematizing avenues for future research
Nov 24, 2022
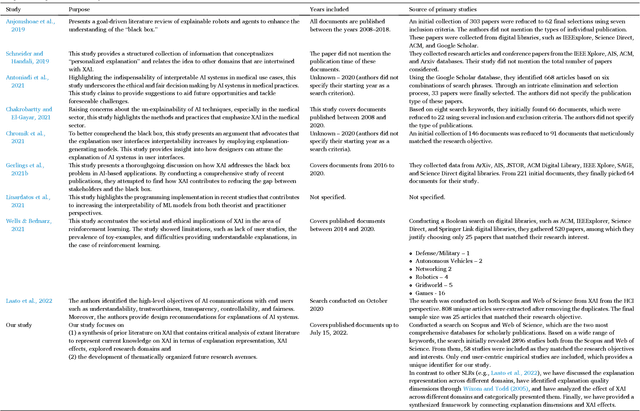
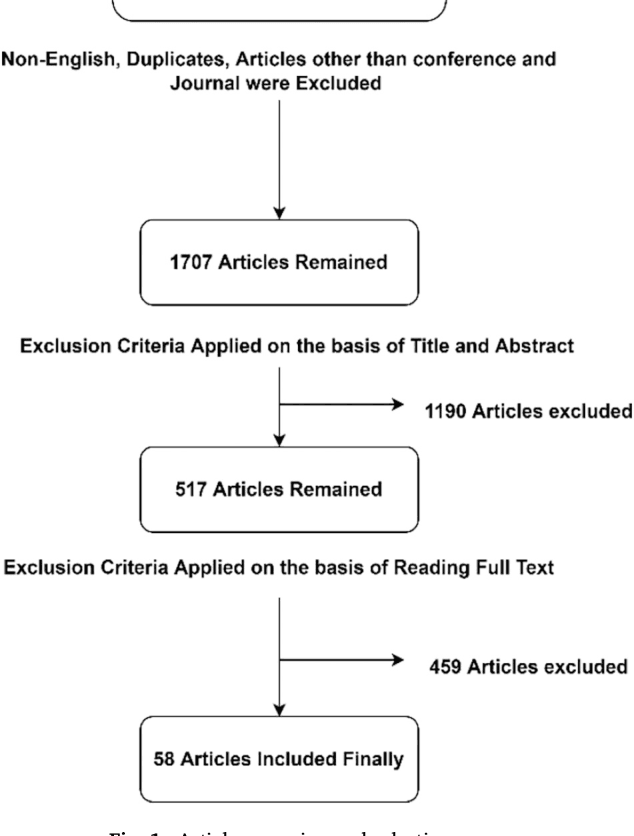

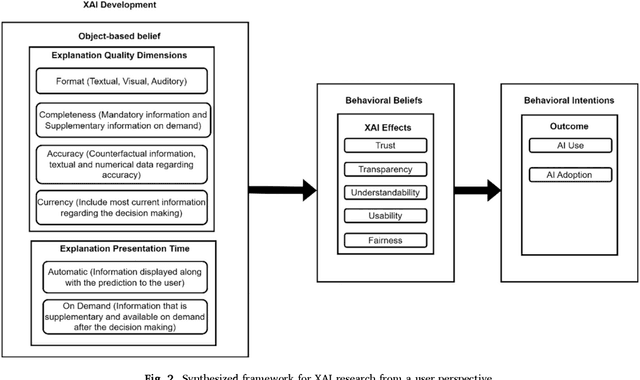
The final search query for the Systematic Literature Review (SLR) was conducted on 15th July 2022. Initially, we extracted 1707 journal and conference articles from the Scopus and Web of Science databases. Inclusion and exclusion criteria were then applied, and 58 articles were selected for the SLR. The findings show four dimensions that shape the AI explanation, which are format (explanation representation format), completeness (explanation should contain all required information, including the supplementary information), accuracy (information regarding the accuracy of the explanation), and currency (explanation should contain recent information). Moreover, along with the automatic representation of the explanation, the users can request additional information if needed. We have also found five dimensions of XAI effects: trust, transparency, understandability, usability, and fairness. In addition, we investigated current knowledge from selected articles to problematize future research agendas as research questions along with possible research paths. Consequently, a comprehensive framework of XAI and its possible effects on user behavior has been developed.
Imperceptible Adversarial Attack via Invertible Neural Networks
Nov 28, 2022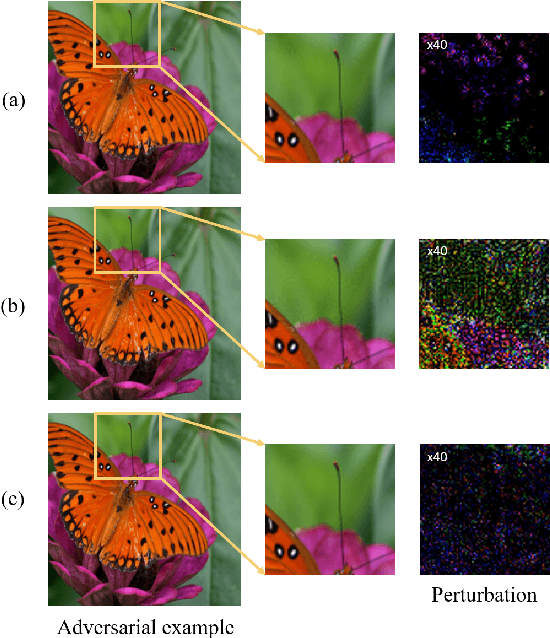
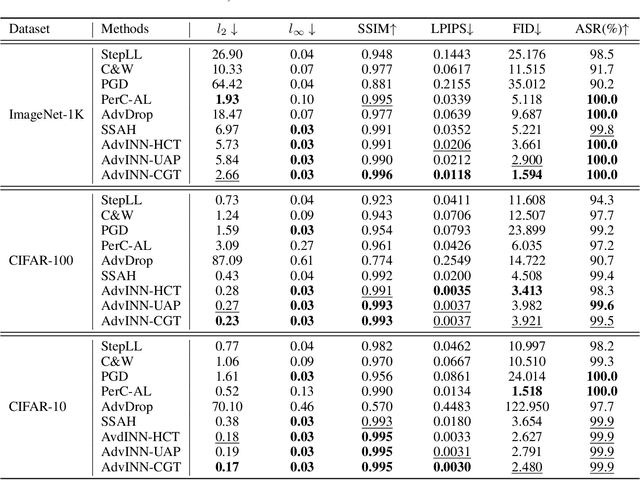
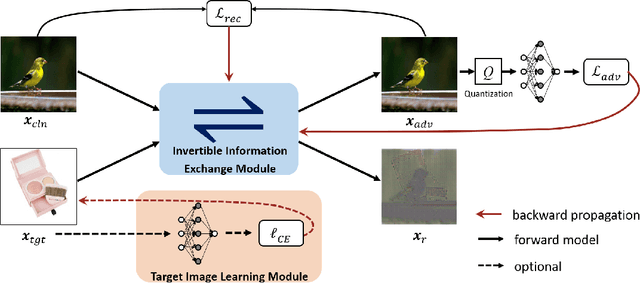
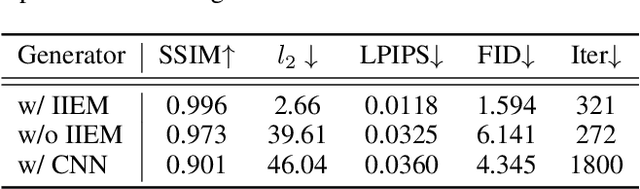
Adding perturbations via utilizing auxiliary gradient information or discarding existing details of the benign images are two common approaches for generating adversarial examples. Though visual imperceptibility is the desired property of adversarial examples, conventional adversarial attacks still generate traceable adversarial perturbations. In this paper, we introduce a novel Adversarial Attack via Invertible Neural Networks (AdvINN) method to produce robust and imperceptible adversarial examples. Specifically, AdvINN fully takes advantage of the information preservation property of Invertible Neural Networks and thereby generates adversarial examples by simultaneously adding class-specific semantic information of the target class and dropping discriminant information of the original class. Extensive experiments on CIFAR-10, CIFAR-100, and ImageNet-1K demonstrate that the proposed AdvINN method can produce less imperceptible adversarial images than the state-of-the-art methods and AdvINN yields more robust adversarial examples with high confidence compared to other adversarial attacks.
KATSum: Knowledge-aware Abstractive Text Summarization
Dec 06, 2022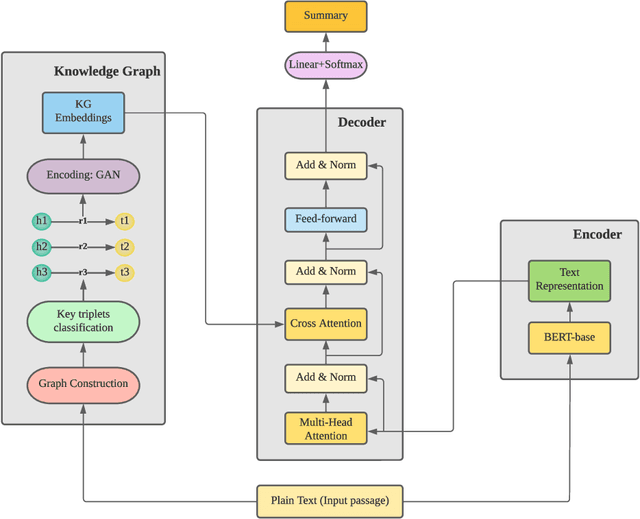
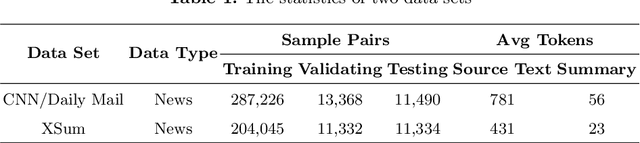
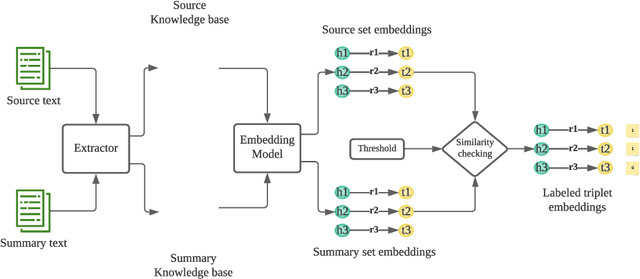
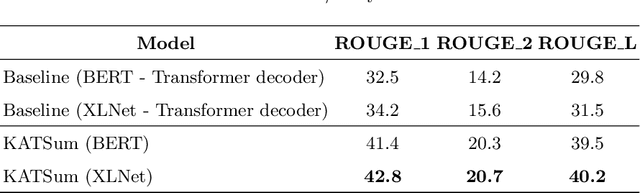
Text Summarization is recognised as one of the NLP downstream tasks and it has been extensively investigated in recent years. It can assist people with perceiving the information rapidly from the Internet, including news articles, social posts, videos, etc. Most existing research works attempt to develop summarization models to produce a better output. However, advent limitations of most existing models emerge, including unfaithfulness and factual errors. In this paper, we propose a novel model, named as Knowledge-aware Abstractive Text Summarization, which leverages the advantages offered by Knowledge Graph to enhance the standard Seq2Seq model. On top of that, the Knowledge Graph triplets are extracted from the source text and utilised to provide keywords with relational information, producing coherent and factually errorless summaries. We conduct extensive experiments by using real-world data sets. The results reveal that the proposed framework can effectively utilise the information from Knowledge Graph and significantly reduce the factual errors in the summary.
Community Detection with Known, Unknown, or Partially Known Auxiliary Latent Variables
Jan 08, 2023
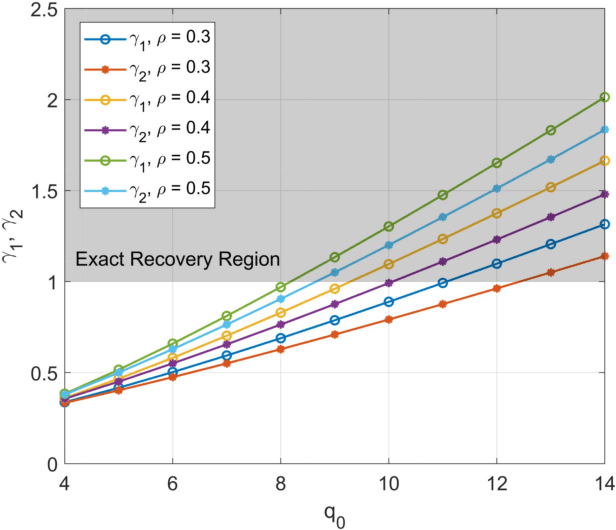
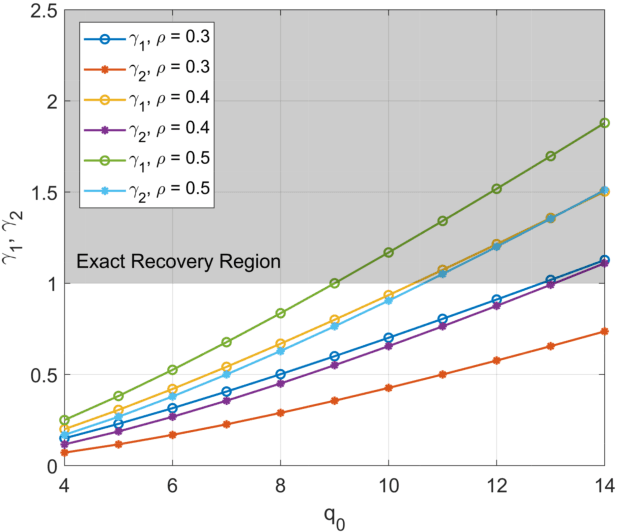
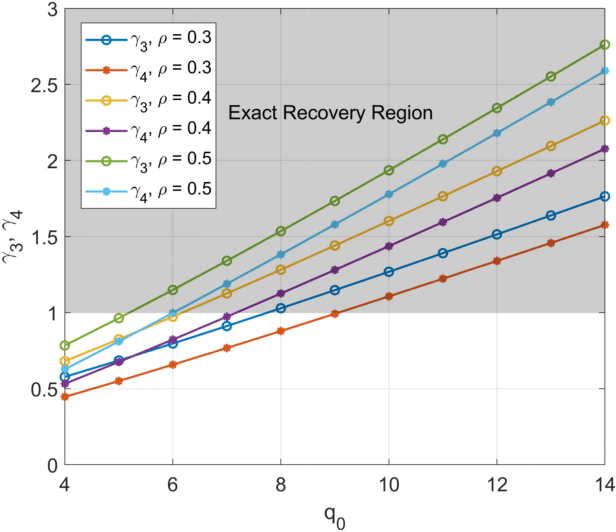
Empirical observations suggest that in practice, community membership does not completely explain the dependency between the edges of an observation graph. The residual dependence of the graph edges are modeled in this paper, to first order, by auxiliary node latent variables that affect the statistics of the graph edges but carry no information about the communities of interest. We then study community detection in graphs obeying the stochastic block model and censored block model with auxiliary latent variables. We analyze the conditions for exact recovery when these auxiliary latent variables are unknown, representing unknown nuisance parameters or model mismatch. We also analyze exact recovery when these secondary latent variables have been either fully or partially revealed. Finally, we propose a semidefinite programming algorithm for recovering the desired labels when the secondary labels are either known or unknown. We show that exact recovery is possible by semidefinite programming down to the respective maximum likelihood exact recovery threshold.
Regularizing disparity estimation via multi task learning with structured light reconstruction
Jan 19, 2023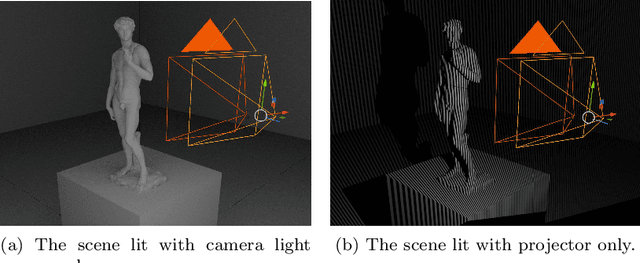

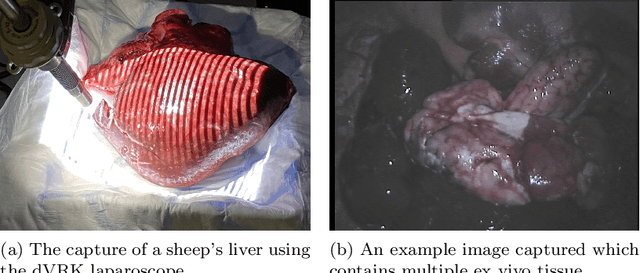
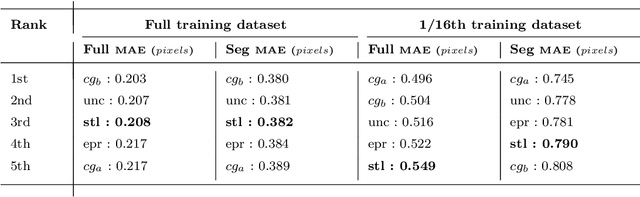
3D reconstruction is a useful tool for surgical planning and guidance. However, the lack of available medical data stunts research and development in this field, as supervised deep learning methods for accurate disparity estimation rely heavily on large datasets containing ground truth information. Alternative approaches to supervision have been explored, such as self-supervision, which can reduce or remove entirely the need for ground truth. However, no proposed alternatives have demonstrated performance capabilities close to what would be expected from a supervised setup. This work aims to alleviate this issue. In this paper, we investigate the learning of structured light projections to enhance the development of direct disparity estimation networks. We show for the first time that it is possible to accurately learn the projection of structured light on a scene, implicitly learning disparity. Secondly, we \textcolor{black}{explore the use of a multi task learning (MTL) framework for the joint training of structured light and disparity. We present results which show that MTL with structured light improves disparity training; without increasing the number of model parameters. Our MTL setup outperformed the single task learning (STL) network in every validation test. Notably, in the medical generalisation test, the STL error was 1.4 times worse than that of the best MTL performance. The benefit of using MTL is emphasised when the training data is limited.} A dataset containing stereoscopic images, disparity maps and structured light projections on medical phantoms and ex vivo tissue was created for evaluation together with virtual scenes. This dataset will be made publicly available in the future.
Modulation spectral features for speech emotion recognition using deep neural networks
Jan 14, 2023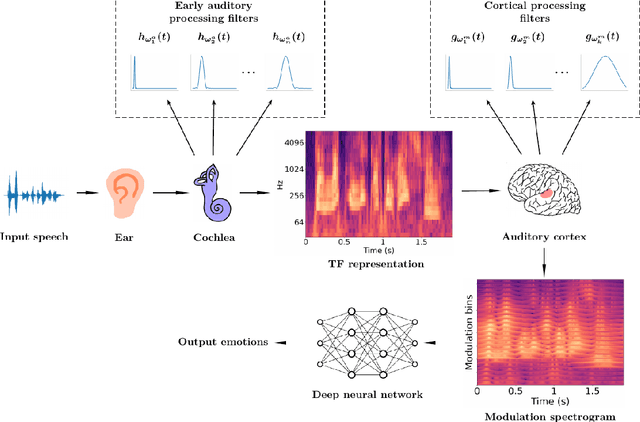
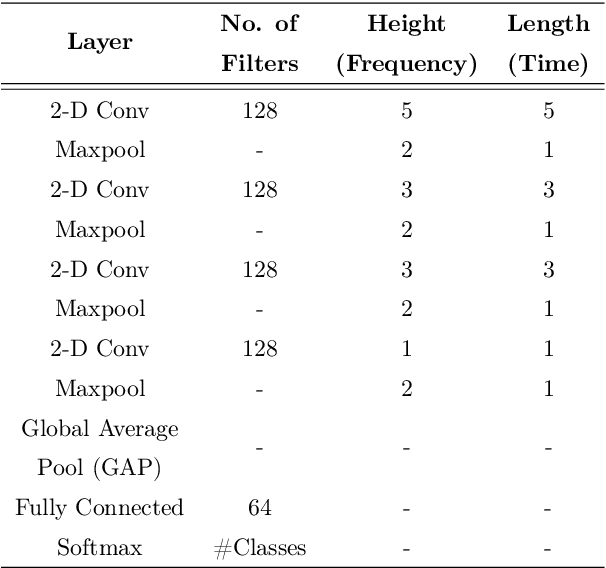


This work explores the use of constant-Q transform based modulation spectral features (CQT-MSF) for speech emotion recognition (SER). The human perception and analysis of sound comprise of two important cognitive parts: early auditory analysis and cortex-based processing. The early auditory analysis considers spectrogram-based representation whereas cortex-based analysis includes extraction of temporal modulations from the spectrogram. This temporal modulation representation of spectrogram is called modulation spectral feature (MSF). As the constant-Q transform (CQT) provides higher resolution at emotion salient low-frequency regions of speech, we find that CQT-based spectrogram, together with its temporal modulations, provides a representation enriched with emotion-specific information. We argue that CQT-MSF when used with a 2-dimensional convolutional network can provide a time-shift invariant and deformation insensitive representation for SER. Our results show that CQT-MSF outperforms standard mel-scale based spectrogram and its modulation features on two popular SER databases, Berlin EmoDB and RAVDESS. We also show that our proposed feature outperforms the shift and deformation invariant scattering transform coefficients, hence, showing the importance of joint hand-crafted and self-learned feature extraction instead of reliance on complete hand-crafted features. Finally, we perform Grad-CAM analysis to visually inspect the contribution of constant-Q modulation features over SER.
* Accepted for publication in Elsevier's Speech Communication Journal
In situ Biological Particle Analyzer based on Digital Inline Holography
Jan 14, 2023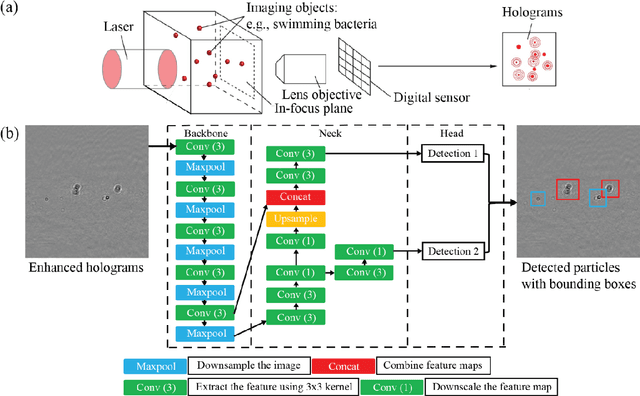
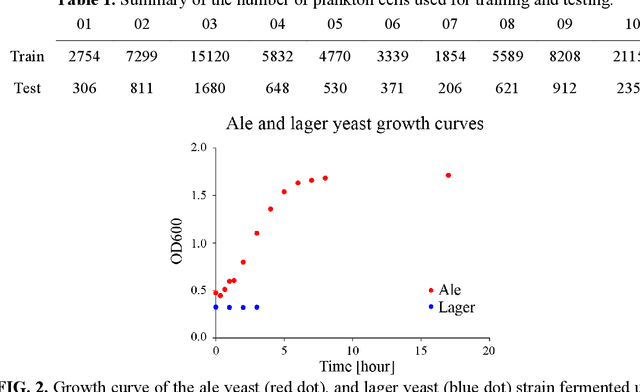

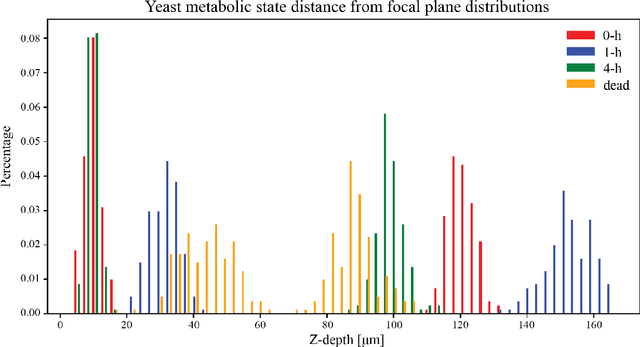
Obtaining in situ measurements of biological microparticles is crucial for both scientific research and numerous industrial applications (e.g., early detection of harmful algal blooms, monitoring yeast during fermentation). However, existing methods are limited to offer timely diagnostics of these particles with sufficient accuracy and information. Here, we introduce a novel method for real-time, in situ analysis using machine learning assisted digital inline holography (DIH). Our machine learning model uses a customized YOLO v5 architecture specialized for the detection and classification of small biological particles. We demonstrate the effectiveness of our method in the analysis of 10 plankton species with equivalent high accuracy and significantly reduced processing time compared to previous methods. We also applied our method to differentiate yeast cells under four metabolic states and from two strains. Our results show that the proposed method can accurately detect and differentiate cellular and subcellular features related to metabolic states and strains. This study demonstrates the potential of machine learning driven DIH approach as a sensitive and versatile diagnostic tool for real-time, in situ analysis of both biotic and abiotic particles. This method can be readily deployed in a distributive manner for scientific research and manufacturing on an industrial scale.
Object Segmentation with Audio Context
Jan 04, 2023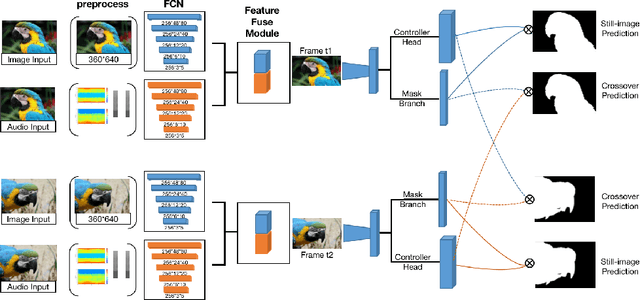
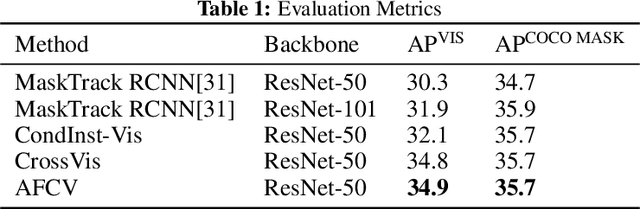

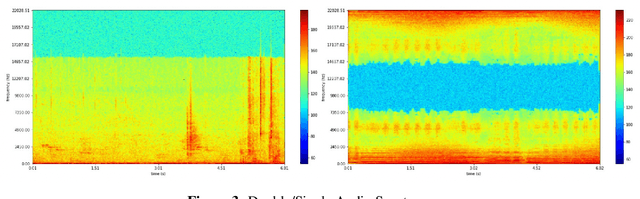
Visual objects often have acoustic signatures that are naturally synchronized with them in audio-bearing video recordings. For this project, we explore the multimodal feature aggregation for video instance segmentation task, in which we integrate audio features into our video segmentation model to conduct an audio-visual learning scheme. Our method is based on existing video instance segmentation method which leverages rich contextual information across video frames. Since this is the first attempt to investigate the audio-visual instance segmentation, a novel dataset, including 20 vocal classes with synchronized video and audio recordings, is collected. By utilizing combined decoder to fuse both video and audio features, our model shows a slight improvements compared to the base model. Additionally, we managed to show the effectiveness of different modules by conducting extensive ablations.
Integrated Sensing and Communication Signals Towards 5G-A and 6G: A Survey
Jan 10, 2023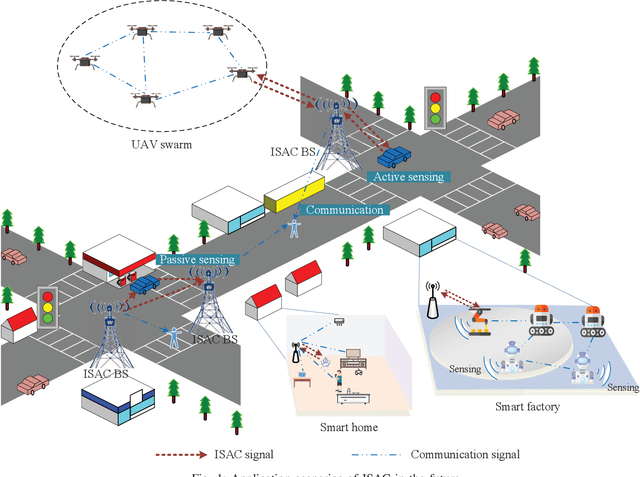
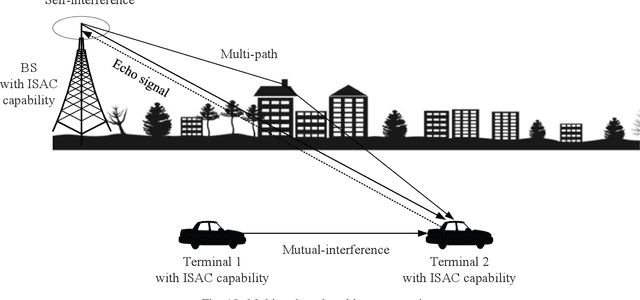
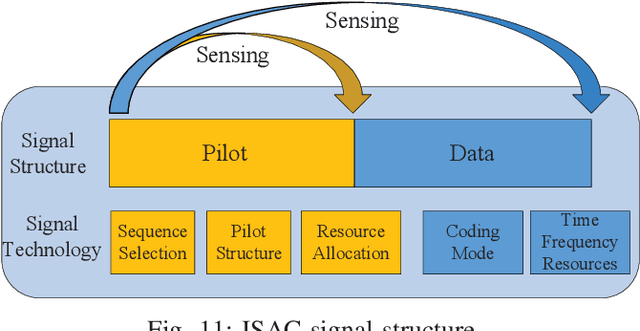
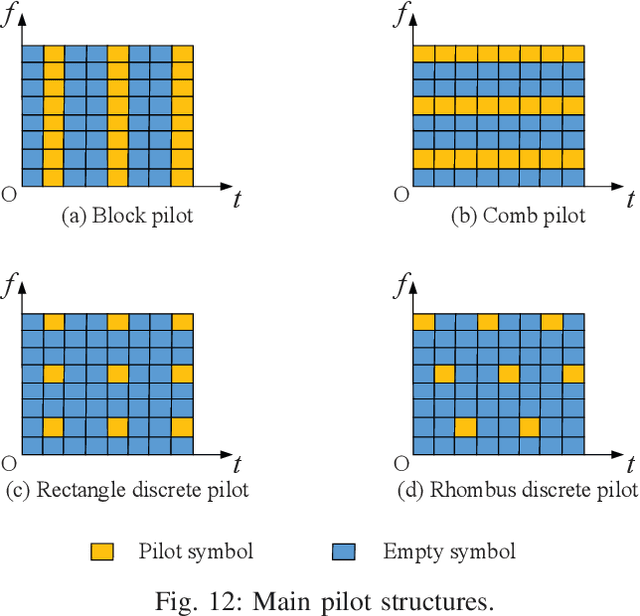
Integrated sensing and communication (ISAC) has the advantages of efficient spectrum utilization and low hardware cost. It is promising to be implemented in the fifth-generation-advanced (5G-A) and sixth-generation (6G) mobile communication systems, having the potential to be applied in intelligent applications requiring both communication and high-accurate sensing capabilities. As the fundamental technology of ISAC, ISAC signal directly impacts the performance of sensing and communication. This article systematically reviews the literature on ISAC signals from the perspective of mobile communication systems, including ISAC signal design, ISAC signal processing algorithms and ISAC signal optimization. We first review the ISAC signal design based on 5G, 5G-A and 6G mobile communication systems. Then, radar signal processing methods are reviewed for ISAC signals, mainly including the channel information matrix method, spectrum lines estimator method and super resolution method. In terms of signal optimization, we summarize peak-to-average power ratio (PAPR) optimization, interference management, and adaptive signal optimization for ISAC signals. This article may provide the guidelines for the research of ISAC signals in 5G-A and 6G mobile communication systems.
Pixelated Reconstruction of Foreground Density and Background Surface Brightness in Gravitational Lensing Systems using Recurrent Inference Machines
Jan 10, 2023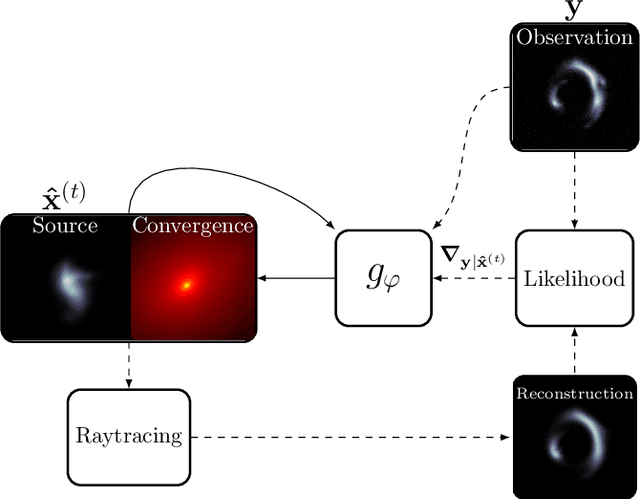

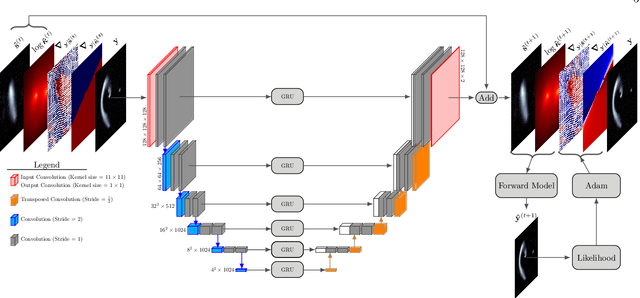
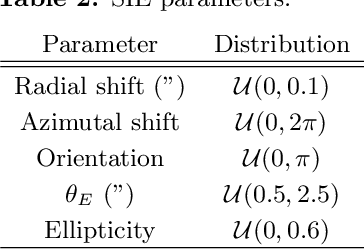
Modeling strong gravitational lenses in order to quantify the distortions in the images of background sources and to reconstruct the mass density in the foreground lenses has been a difficult computational challenge. As the quality of gravitational lens images increases, the task of fully exploiting the information they contain becomes computationally and algorithmically more difficult. In this work, we use a neural network based on the Recurrent Inference Machine (RIM) to simultaneously reconstruct an undistorted image of the background source and the lens mass density distribution as pixelated maps. The method iteratively reconstructs the model parameters (the image of the source and a pixelated density map) by learning the process of optimizing the likelihood given the data using the physical model (a ray-tracing simulation), regularized by a prior implicitly learned by the neural network through its training data. When compared to more traditional parametric models, the proposed method is significantly more expressive and can reconstruct complex mass distributions, which we demonstrate by using realistic lensing galaxies taken from the IllustrisTNG cosmological hydrodynamic simulation.