 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Sample-Efficient Reinforcement Learning in the Presence of Exogenous Information
Jun 09, 2022

In real-world reinforcement learning applications the learner's observation space is ubiquitously high-dimensional with both relevant and irrelevant information about the task at hand. Learning from high-dimensional observations has been the subject of extensive investigation in supervised learning and statistics (e.g., via sparsity), but analogous issues in reinforcement learning are not well understood, even in finite state/action (tabular) domains. We introduce a new problem setting for reinforcement learning, the Exogenous Markov Decision Process (ExoMDP), in which the state space admits an (unknown) factorization into a small controllable (or, endogenous) component and a large irrelevant (or, exogenous) component; the exogenous component is independent of the learner's actions, but evolves in an arbitrary, temporally correlated fashion. We provide a new algorithm, ExoRL, which learns a near-optimal policy with sample complexity polynomial in the size of the endogenous component and nearly independent of the size of the exogenous component, thereby offering a doubly-exponential improvement over off-the-shelf algorithms. Our results highlight for the first time that sample-efficient reinforcement learning is possible in the presence of exogenous information, and provide a simple, user-friendly benchmark for investigation going forward.
Theoretical Understanding of the Information Flow on Continual Learning Performance
Apr 26, 2022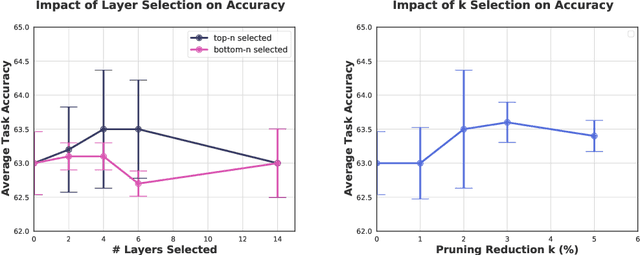
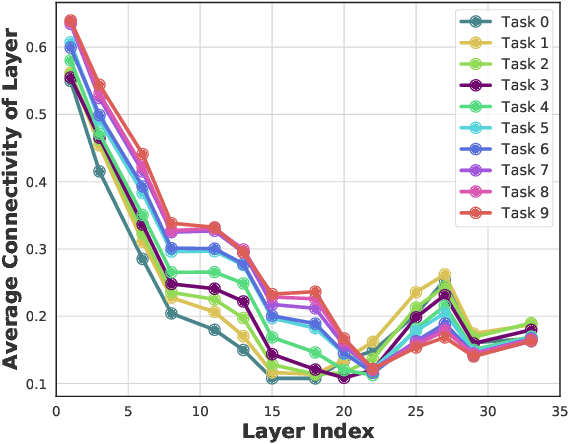
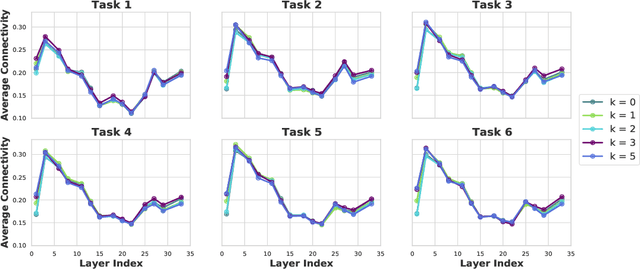
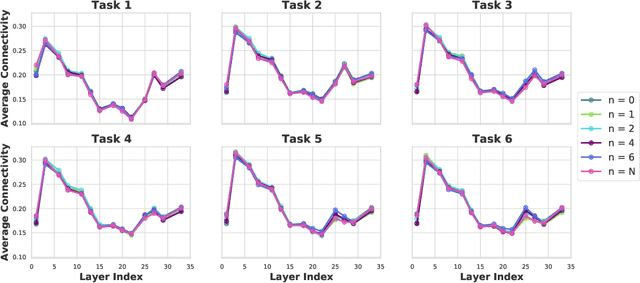
Continual learning (CL) is a setting in which an agent has to learn from an incoming stream of data sequentially. CL performance evaluates the model's ability to continually learn and solve new problems with incremental available information over time while retaining previous knowledge. Despite the numerous previous solutions to bypass the catastrophic forgetting (CF) of previously seen tasks during the learning process, most of them still suffer significant forgetting, expensive memory cost, or lack of theoretical understanding of neural networks' conduct while learning new tasks. While the issue that CL performance degrades under different training regimes has been extensively studied empirically, insufficient attention has been paid from a theoretical angle. In this paper, we establish a probabilistic framework to analyze information flow through layers in networks for task sequences and its impact on learning performance. Our objective is to optimize the information preservation between layers while learning new tasks to manage task-specific knowledge passing throughout the layers while maintaining model performance on previous tasks. In particular, we study CL performance's relationship with information flow in the network to answer the question "How can knowledge of information flow between layers be used to alleviate CF?". Our analysis provides novel insights of information adaptation within the layers during the incremental task learning process. Through our experiments, we provide empirical evidence and practically highlight the performance improvement across multiple tasks.
Attentional Graph Convolutional Network for Structure-aware Audio-Visual Scene Classification
Dec 31, 2022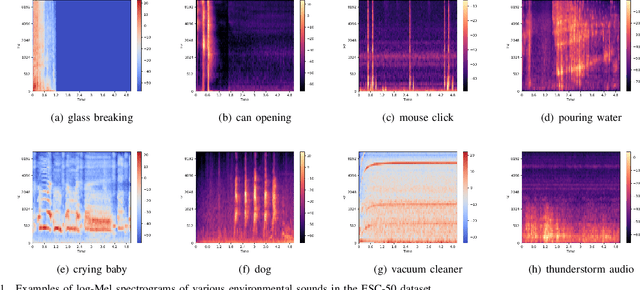
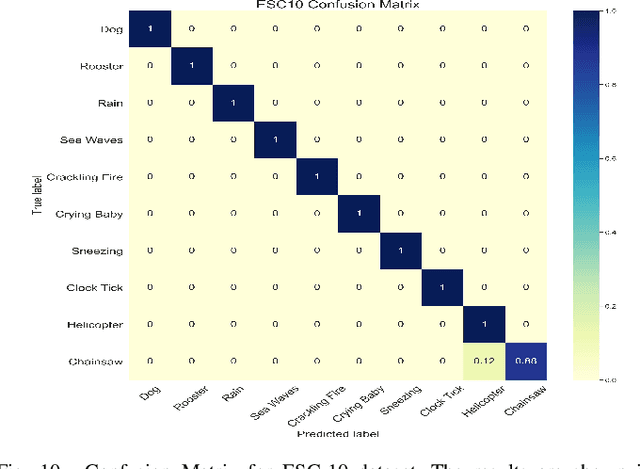
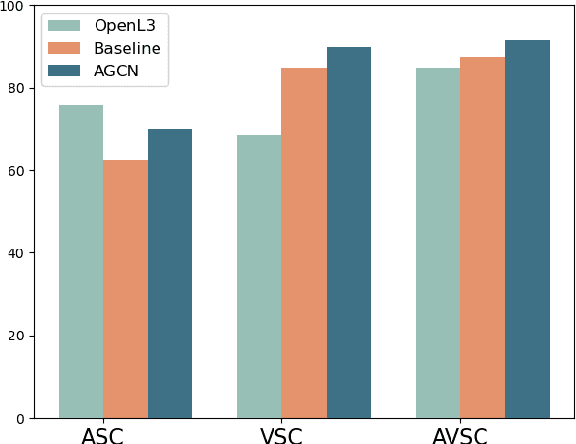
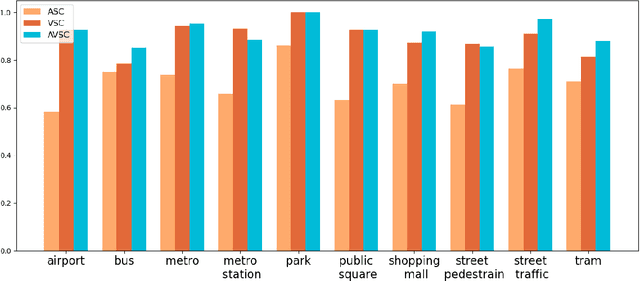
Audio-Visual scene understanding is a challenging problem due to the unstructured spatial-temporal relations that exist in the audio signals and spatial layouts of different objects and various texture patterns in the visual images. Recently, many studies have focused on abstracting features from convolutional neural networks while the learning of explicit semantically relevant frames of sound signals and visual images has been overlooked. To this end, we present an end-to-end framework, namely attentional graph convolutional network (AGCN), for structure-aware audio-visual scene representation. First, the spectrogram of sound and input image is processed by a backbone network for feature extraction. Then, to build multi-scale hierarchical information of input features, we utilize an attention fusion mechanism to aggregate features from multiple layers of the backbone network. Notably, to well represent the salient regions and contextual information of audio-visual inputs, the salient acoustic graph (SAG) and contextual acoustic graph (CAG), salient visual graph (SVG), and contextual visual graph (CVG) are constructed for the audio-visual scene representation. Finally, the constructed graphs pass through a graph convolutional network for structure-aware audio-visual scene recognition. Extensive experimental results on the audio, visual and audio-visual scene recognition datasets show that promising results have been achieved by the AGCN methods. Visualizing graphs on the spectrograms and images have been presented to show the effectiveness of proposed CAG/SAG and CVG/SVG that could focus on the salient and semantic relevant regions.
RECOMMED: A Comprehensive Pharmaceutical Recommendation System
Dec 31, 2022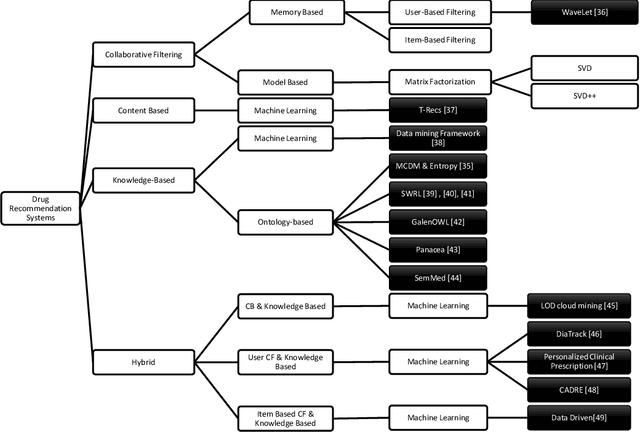
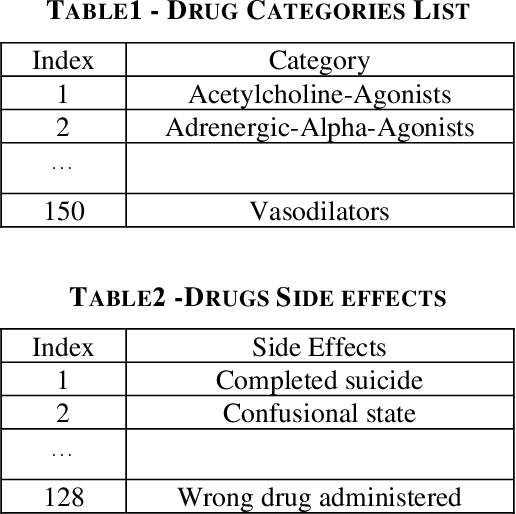
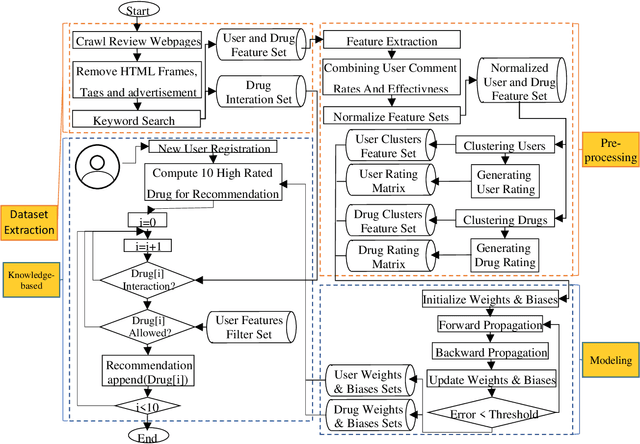
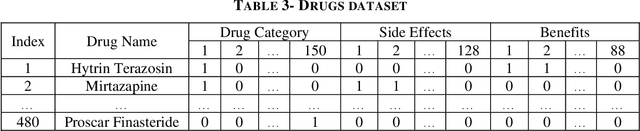
A comprehensive pharmaceutical recommendation system was designed based on the patients and drugs features extracted from Drugs.com and Druglib.com. First, data from these databases were combined, and a dataset of patients and drug information was built. Secondly, the patients and drugs were clustered, and then the recommendation was performed using different ratings provided by patients, and importantly by the knowledge obtained from patients and drug specifications, and considering drug interactions. To the best of our knowledge, we are the first group to consider patients conditions and history in the proposed approach for selecting a specific medicine appropriate for that particular user. Our approach applies artificial intelligence (AI) models for the implementation. Sentiment analysis using natural language processing approaches is employed in pre-processing along with neural network-based methods and recommender system algorithms for modeling the system. In our work, patients conditions and drugs features are used for making two models based on matrix factorization. Then we used drug interaction to filter drugs with severe or mild interactions with other drugs. We developed a deep learning model for recommending drugs by using data from 2304 patients as a training set, and then we used data from 660 patients as our validation set. After that, we used knowledge from critical information about drugs and combined the outcome of the model into a knowledge-based system with the rules obtained from constraints on taking medicine.
IMDeception: Grouped Information Distilling Super-Resolution Network
Apr 25, 2022
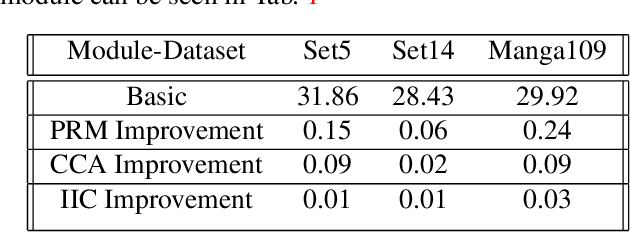
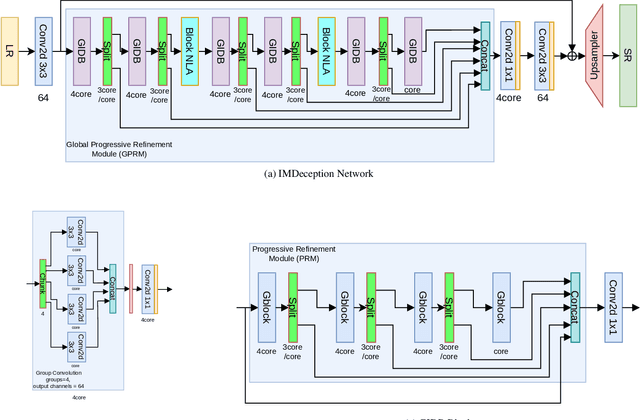
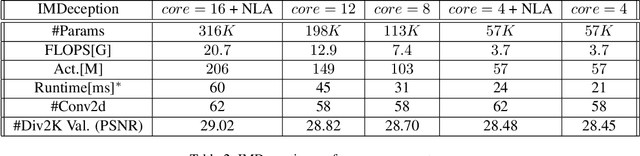
Single-Image-Super-Resolution (SISR) is a classical computer vision problem that has benefited from the recent advancements in deep learning methods, especially the advancements of convolutional neural networks (CNN). Although state-of-the-art methods improve the performance of SISR on several datasets, direct application of these networks for practical use is still an issue due to heavy computational load. For this purpose, recently, researchers have focused on more efficient and high-performing network structures. Information multi-distilling network (IMDN) is one of the highly efficient SISR networks with high performance and low computational load. IMDN achieves this efficiency with various mechanisms such as Intermediate Information Collection (IIC), working in a global setting, Progressive Refinement Module (PRM), and Contrast Aware Channel Attention (CCA), employed in a local setting. These mechanisms, however, do not equally contribute to the efficiency and performance of IMDN. In this work, we propose the Global Progressive Refinement Module (GPRM) as a less parameter-demanding alternative to the IIC module for feature aggregation. To further decrease the number of parameters and floating point operations persecond (FLOPS), we also propose Grouped Information Distilling Blocks (GIDB). Using the proposed structures, we design an efficient SISR network called IMDeception. Experiments reveal that the proposed network performs on par with state-of-the-art models despite having a limited number of parameters and FLOPS. Furthermore, using grouped convolutions as a building block of GIDB increases room for further optimization during deployment. To show its potential, the proposed model was deployed on NVIDIA Jetson Xavier AGX and it has been shown that it can run in real-time on this edge device
Ensemble learning techniques for intrusion detection system in the context of cybersecurity
Dec 21, 2022Recently, there has been an interest in improving the resources available in Intrusion Detection System (IDS) techniques. In this sense, several studies related to cybersecurity show that the environment invasions and information kidnapping are increasingly recurrent and complex. The criticality of the business involving operations in an environment using computing resources does not allow the vulnerability of the information. Cybersecurity has taken on a dimension within the universe of indispensable technology in corporations, and the prevention of risks of invasions into the environment is dealt with daily by Security teams. Thus, the main objective of the study was to investigate the Ensemble Learning technique using the Stacking method, supported by the Support Vector Machine (SVM) and k-Nearest Neighbour (kNN) algorithms aiming at an optimization of the results for DDoS attack detection. For this, the Intrusion Detection System concept was used with the application of the Data Mining and Machine Learning Orange tool to obtain better results
Deterministic-Random Tradeoff of Integrated Sensing and Communications in Gaussian Channels: A Rate-Distortion Perspective
Dec 21, 2022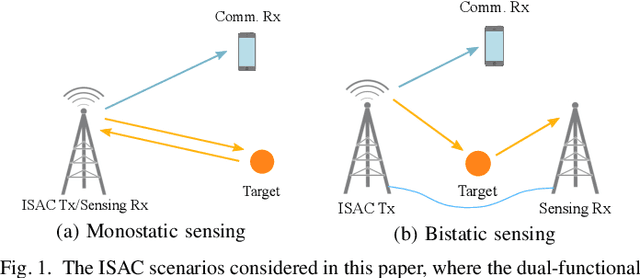
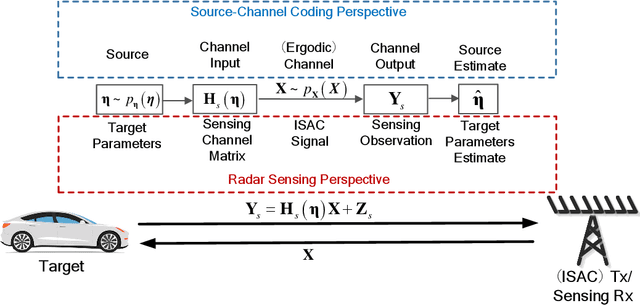
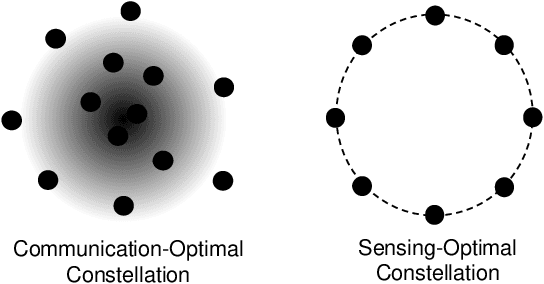
Integrated sensing and communications (ISAC) is recognized as a key enabling technology for future wireless networks. To shed light on the fundamental performance limits of ISAC systems, this paper studies the deterministic-random tradeoff between sensing and communications (S\&C) from a rate-distortion perspective under Gaussian ISAC channels. We model the ISAC signal as a random matrix that carries information, whose realization is perfectly known to the sensing receiver, but is unknown to the communication receiver. We characterize the sensing mutual information conditioned on the random ISAC signal, and show that it provides a universal lower bound for distortion metrics of sensing. Furthermore, we prove that the distortion lower bound is minimized if the sample covariance matrix of the ISAC signal is deterministic. We then offer our understanding of the main results by interpreting wireless sensing as non-cooperative source-channel coding. Finally, we provide sufficient conditions for the achievability of the distortion lower bound by analyzing a specific example of target response matrix estimation.
Cross Version Defect Prediction with Class Dependency Embeddings
Dec 29, 2022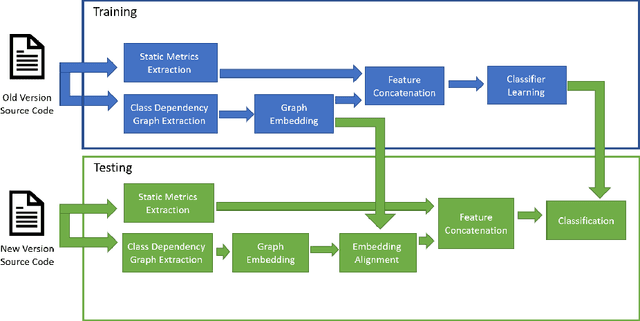
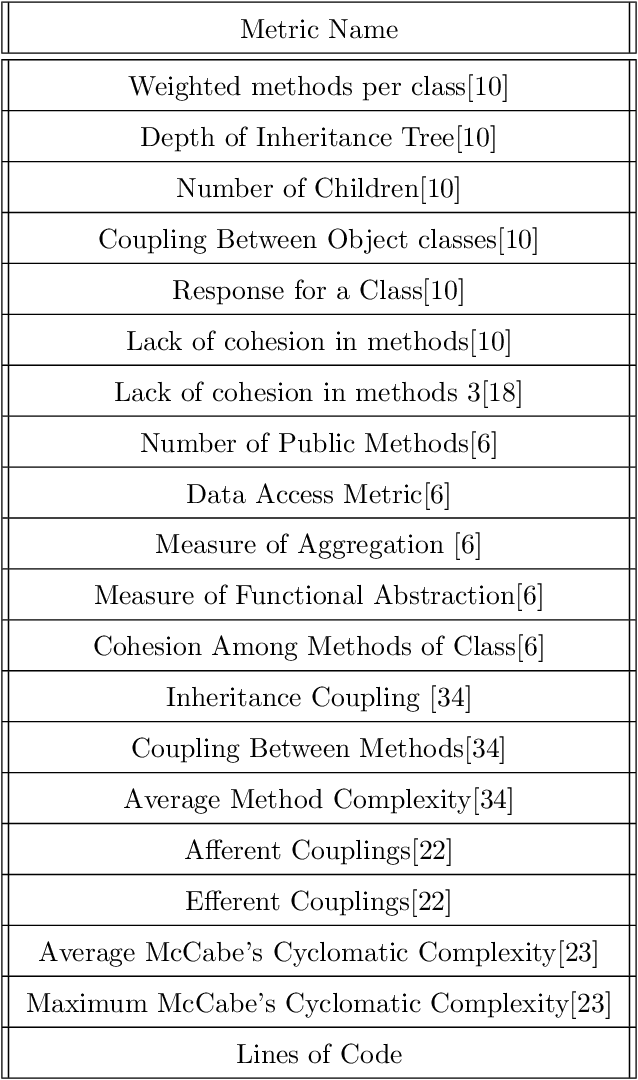
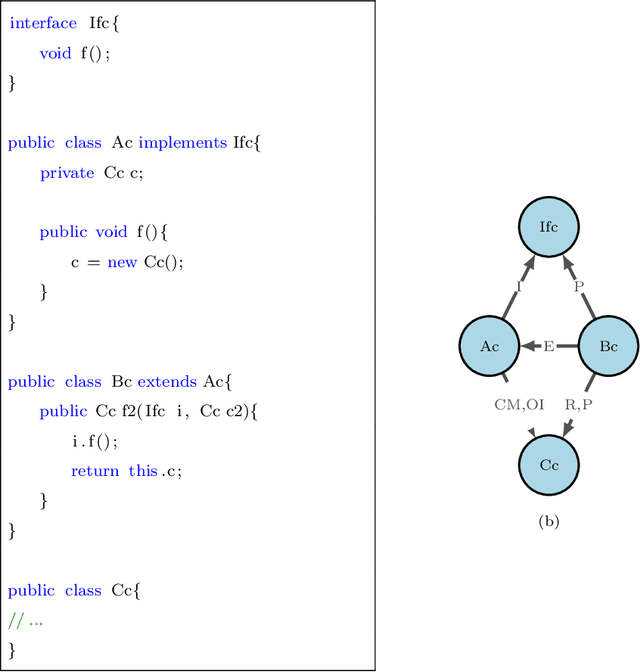
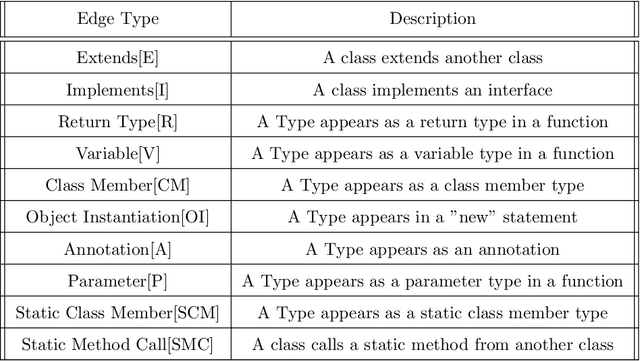
Software Defect Prediction aims at predicting which software modules are the most probable to contain defects. The idea behind this approach is to save time during the development process by helping find bugs early. Defect Prediction models are based on historical data. Specifically, one can use data collected from past software distributions, or Versions, of the same target application under analysis. Defect Prediction based on past versions is called Cross Version Defect Prediction (CVDP). Traditionally, Static Code Metrics are used to predict defects. In this work, we use the Class Dependency Network (CDN) as another predictor for defects, combined with static code metrics. CDN data contains structural information about the target application being analyzed. Usually, CDN data is analyzed using different handcrafted network measures, like Social Network metrics. Our approach uses network embedding techniques to leverage CDN information without having to build the metrics manually. In order to use the embeddings between versions, we incorporate different embedding alignment techniques. To evaluate our approach, we performed experiments on 24 software release pairs and compared it against several benchmark methods. In these experiments, we analyzed the performance of two different graph embedding techniques, three anchor selection approaches, and two alignment techniques. We also built a meta-model based on two different embeddings and achieved a statistically significant improvement in AUC of 4.7% (p < 0.002) over the baseline method.
System Log Parsing: A Survey
Dec 29, 2022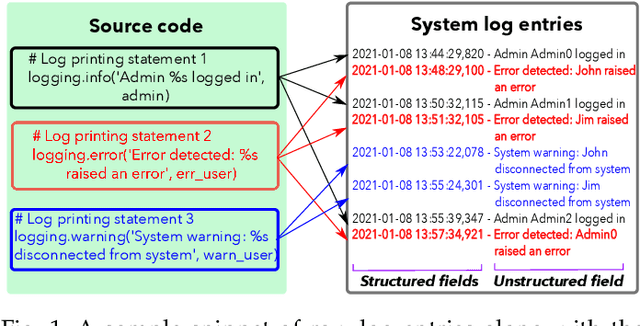
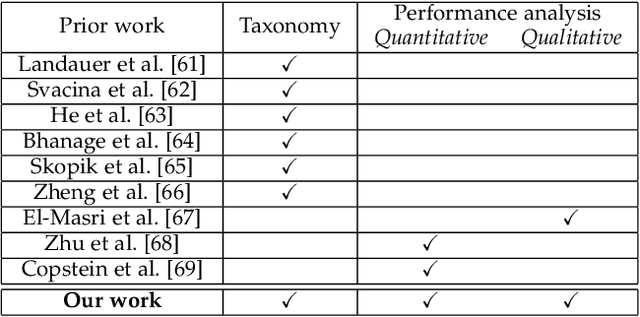
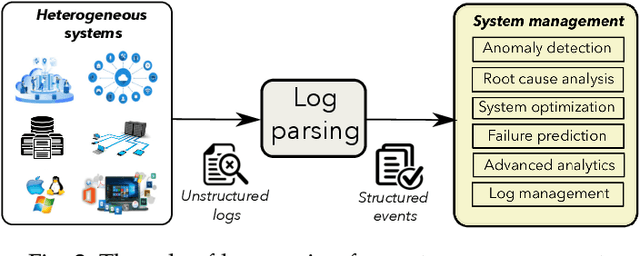
Modern information and communication systems have become increasingly challenging to manage. The ubiquitous system logs contain plentiful information and are thus widely exploited as an alternative source for system management. As log files usually encompass large amounts of raw data, manually analyzing them is laborious and error-prone. Consequently, many research endeavors have been devoted to automatic log analysis. However, these works typically expect structured input and struggle with the heterogeneous nature of raw system logs. Log parsing closes this gap by converting the unstructured system logs to structured records. Many parsers were proposed during the last decades to accommodate various log analysis applications. However, due to the ample solution space and lack of systematic evaluation, it is not easy for practitioners to find ready-made solutions that fit their needs. This paper aims to provide a comprehensive survey on log parsing. We begin with an exhaustive taxonomy of existing log parsers. Then we empirically analyze the critical performance and operational features for 17 open-source solutions both quantitatively and qualitatively, and whenever applicable discuss the merits of alternative approaches. We also elaborate on future challenges and discuss the relevant research directions. We envision this survey as a helpful resource for system administrators and domain experts to choose the most desirable open-source solution or implement new ones based on application-specific requirements.
Learned Hierarchical B-frame Coding with Adaptive Feature Modulation for YUV 4:2:0 Content
Dec 29, 2022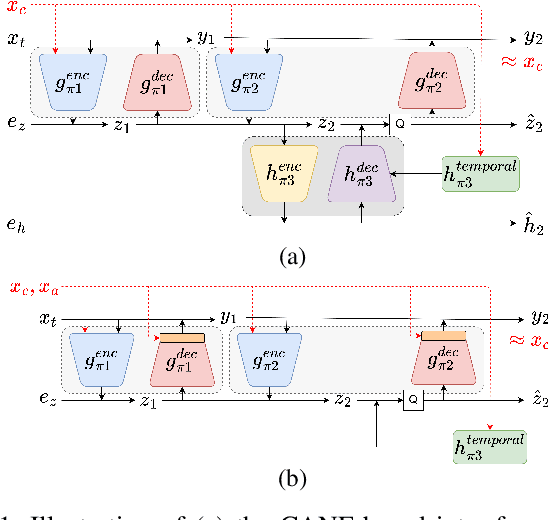
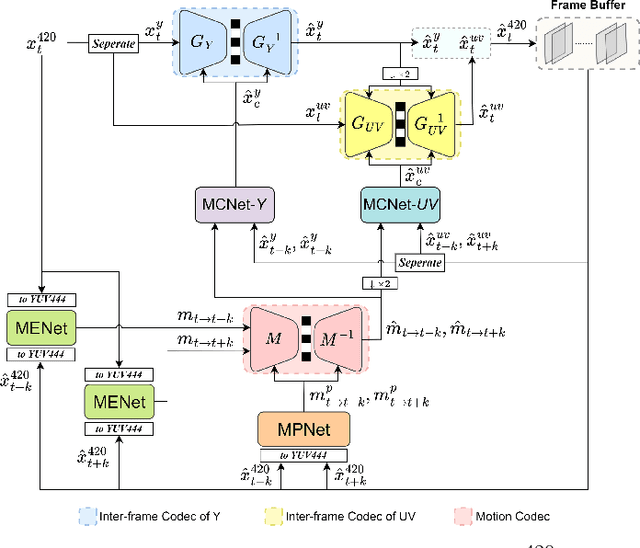
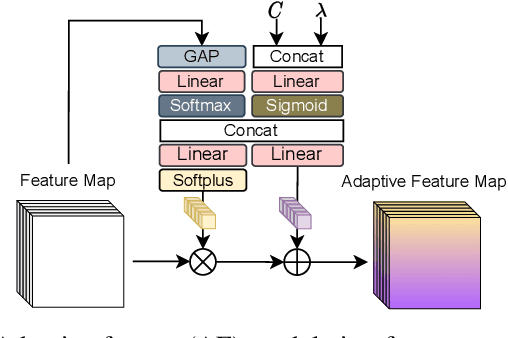

This paper introduces a learned hierarchical B-frame coding scheme in response to the Grand Challenge on Neural Network-based Video Coding at ISCAS 2023. We address specifically three issues, including (1) B-frame coding, (2) YUV 4:2:0 coding, and (3) content-adaptive variable-rate coding with only one single model. Most learned video codecs operate internally in the RGB domain for P-frame coding. B-frame coding for YUV 4:2:0 content is largely under-explored. In addition, while there have been prior works on variable-rate coding with conditional convolution, most of them fail to consider the content information. We build our scheme on conditional augmented normalized flows (CANF). It features conditional motion and inter-frame codecs for efficient B-frame coding. To cope with YUV 4:2:0 content, two conditional inter-frame codecs are used to process the Y and UV components separately, with the coding of the UV components conditioned additionally on the Y component. Moreover, we introduce adaptive feature modulation in every convolutional layer, taking into account both the content information and the coding levels of B-frames to achieve content-adaptive variable-rate coding. Experimental results show that our model outperforms x265 and the winner of last year's challenge on commonly used datasets in terms of PSNR-YUV.