 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
FEMa-FS: Finite Element Machines for Feature Selection
Dec 05, 2022
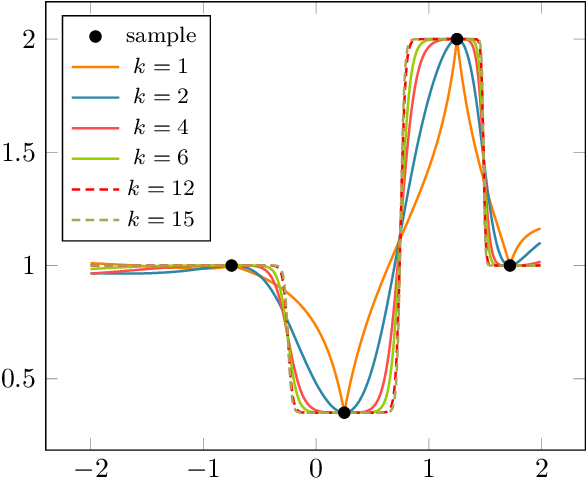
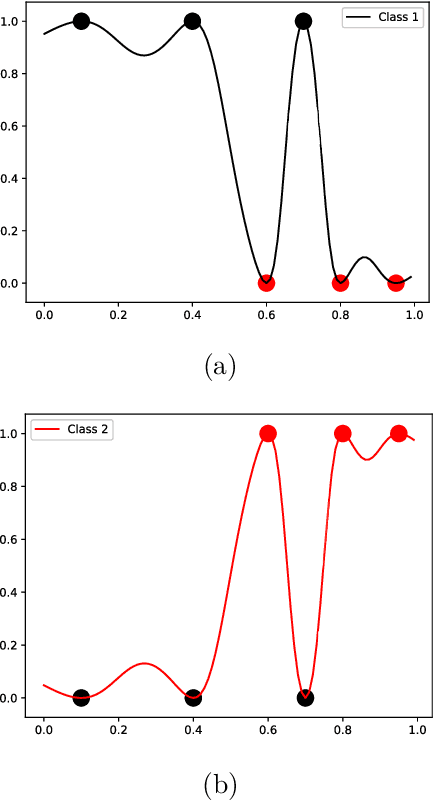
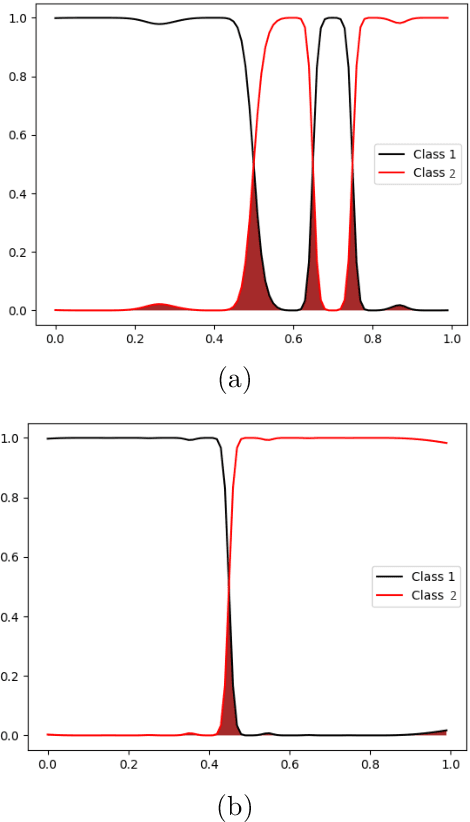
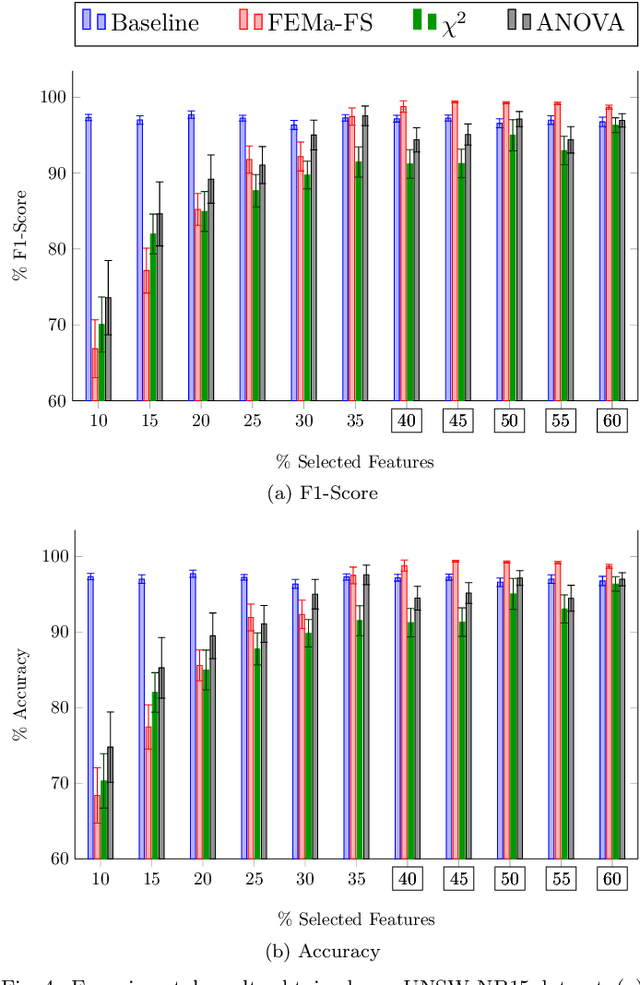
Identifying anomalies has become one of the primary strategies towards security and protection procedures in computer networks. In this context, machine learning-based methods emerge as an elegant solution to identify such scenarios and learn irrelevant information so that a reduction in the identification time and possible gain in accuracy can be obtained. This paper proposes a novel feature selection approach called Finite Element Machines for Feature Selection (FEMa-FS), which uses the framework of finite elements to identify the most relevant information from a given dataset. Although FEMa-FS can be applied to any application domain, it has been evaluated in the context of anomaly detection in computer networks. The outcomes over two datasets showed promising results.
Dynamically Modular and Sparse General Continual Learning
Jan 02, 2023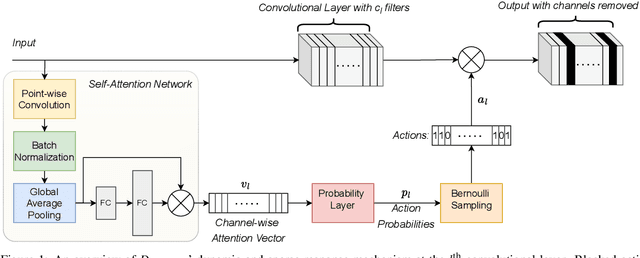
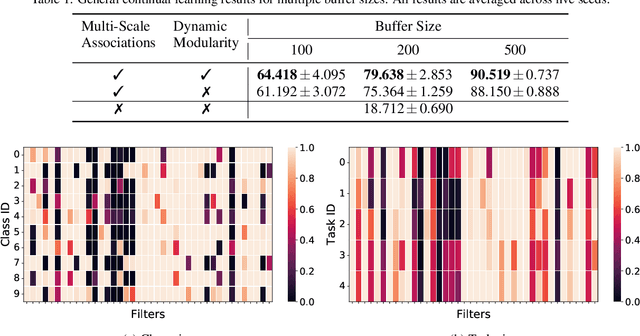
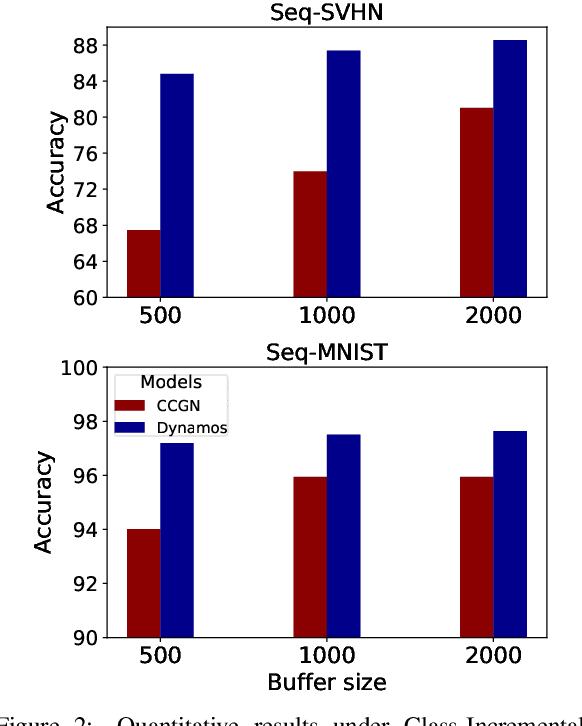
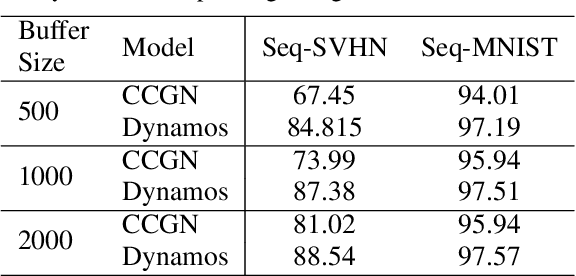
Real-world applications often require learning continuously from a stream of data under ever-changing conditions. When trying to learn from such non-stationary data, deep neural networks (DNNs) undergo catastrophic forgetting of previously learned information. Among the common approaches to avoid catastrophic forgetting, rehearsal-based methods have proven effective. However, they are still prone to forgetting due to task-interference as all parameters respond to all tasks. To counter this, we take inspiration from sparse coding in the brain and introduce dynamic modularity and sparsity (Dynamos) for rehearsal-based general continual learning. In this setup, the DNN learns to respond to stimuli by activating relevant subsets of neurons. We demonstrate the effectiveness of Dynamos on multiple datasets under challenging continual learning evaluation protocols. Finally, we show that our method learns representations that are modular and specialized, while maintaining reusability by activating subsets of neurons with overlaps corresponding to the similarity of stimuli.
Russia-Ukraine war: Modeling and Clustering the Sentiments Trends of Various Countries
Jan 02, 2023
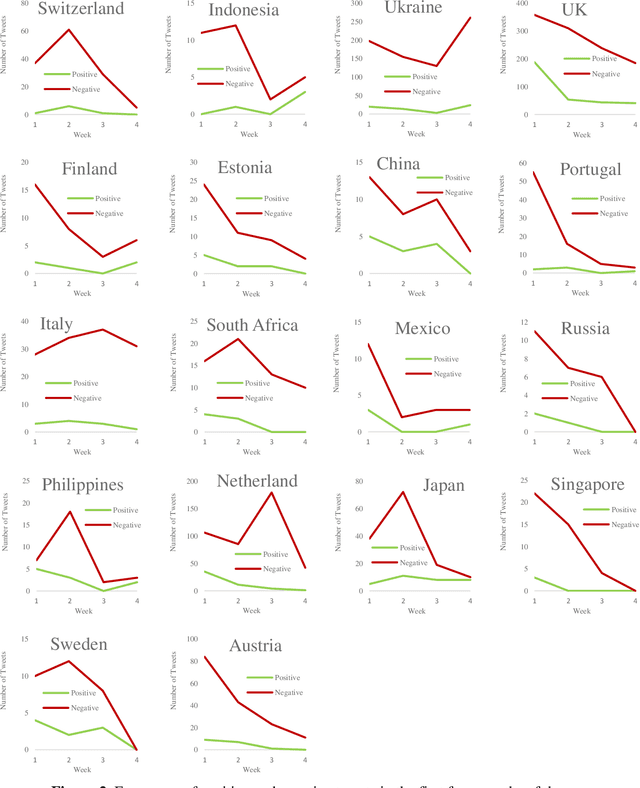
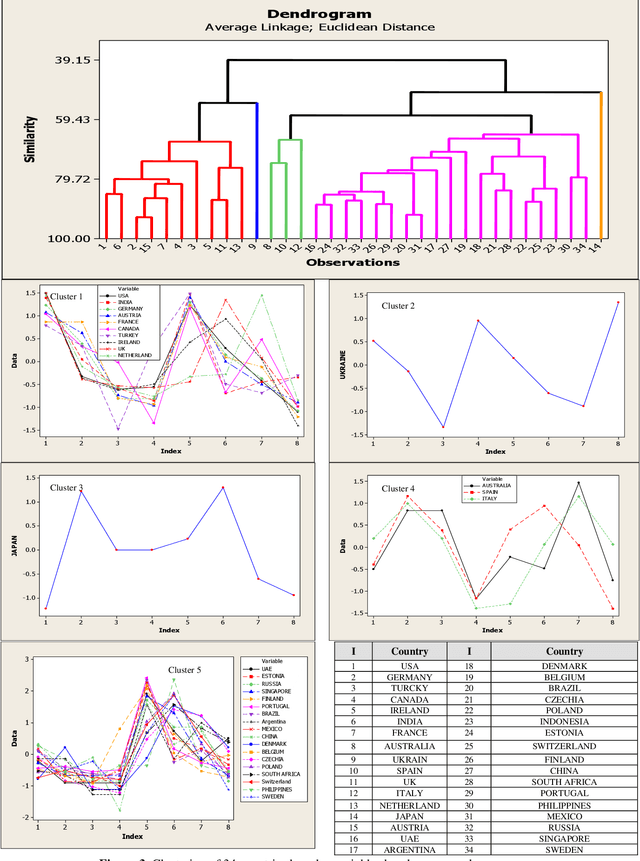
With Twitter's growth and popularity, a huge number of views are shared by users on various topics, making this platform a valuable information source on various political, social, and economic issues. This paper investigates English tweets on the Russia-Ukraine war to analyze trends reflecting users' opinions and sentiments regarding the conflict. The tweets' positive and negative sentiments are analyzed using a BERT-based model, and the time series associated with the frequency of positive and negative tweets for various countries is calculated. Then, we propose a method based on the neighborhood average for modeling and clustering the time series of countries. The clustering results provide valuable insight into public opinion regarding this conflict. Among other things, we can mention the similar thoughts of users from the United States, Canada, the United Kingdom, and most Western European countries versus the shared views of Eastern European, Scandinavian, Asian, and South American nations toward the conflict.
Information-driven Path Planning for Hybrid Aerial Underwater Vehicles
Apr 08, 2022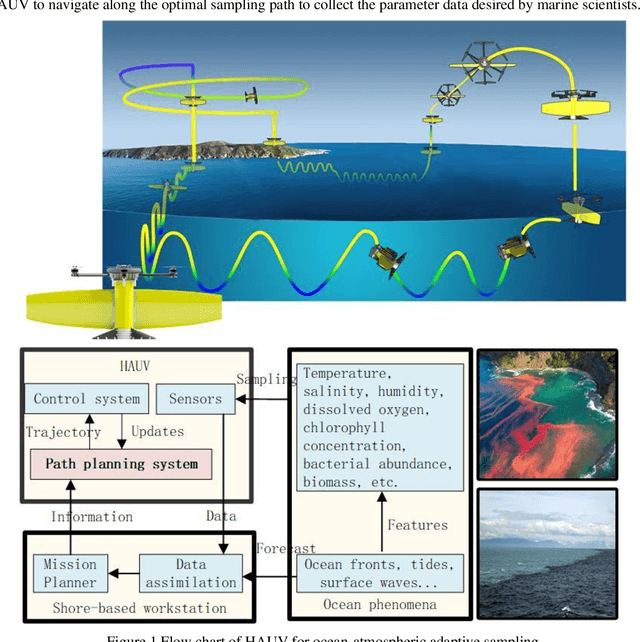
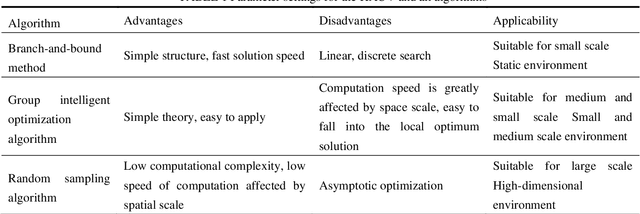

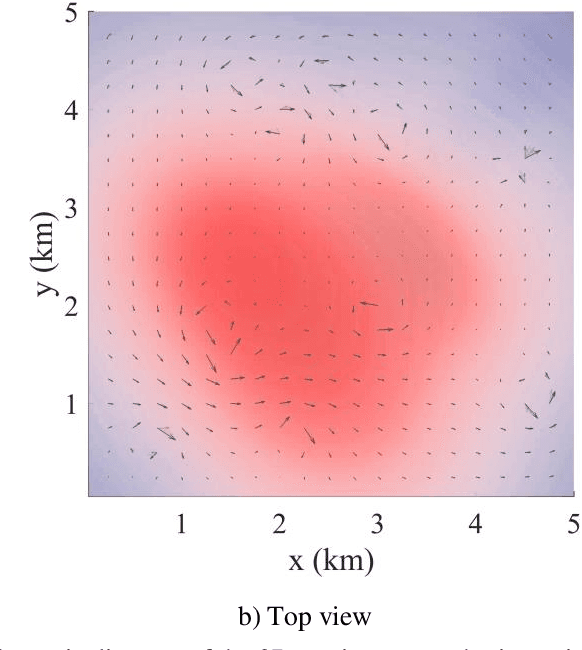
This paper presents a novel Rapidly-exploring Adaptive Sampling Tree (RAST) algorithm for the adaptive sampling mission of a hybrid aerial underwater vehicle (HAUV) in an air-sea 3D environment. This algorithm innovatively combines the tournament-based point selection sampling strategy, the information heuristic search process and the framework of Rapidly-exploring Random Tree (RRT) algorithm. Hence can guide the vehicle to the region of interest to scientists for sampling and generate a collision-free path for maximizing information collection by the HAUV under the constraints of environmental effects of currents or wind and limited budget. The simulation results show that the fast search adaptive sampling tree algorithm has higher optimization performance, faster solution speed and better stability than the Rapidly-exploring Information Gathering Tree (RIGT) algorithm and the particle swarm optimization (PSO) algorithm.
Video Semantic Segmentation with Inter-Frame Feature Fusion and Inner-Frame Feature Refinement
Jan 10, 2023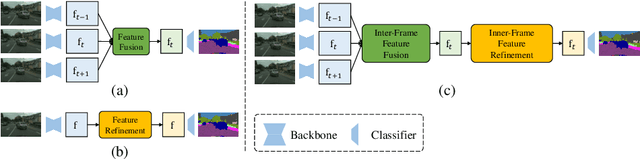
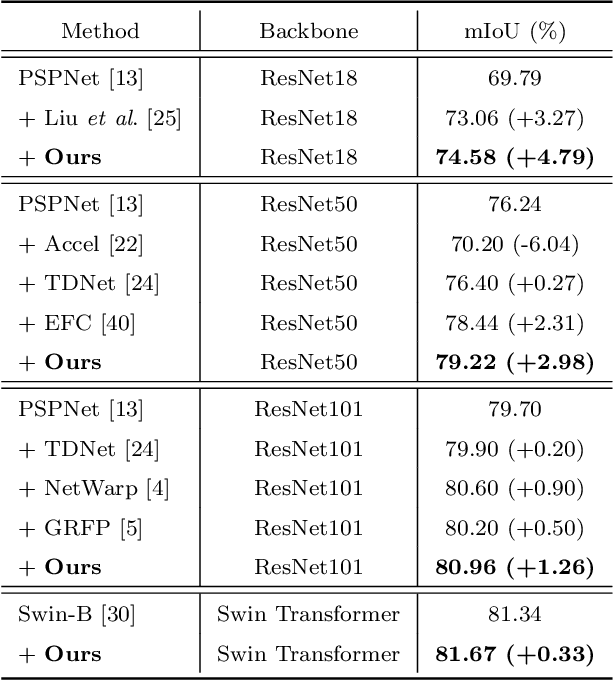
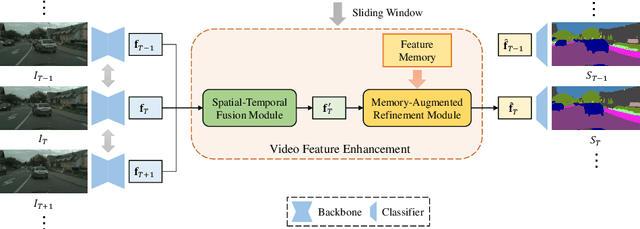
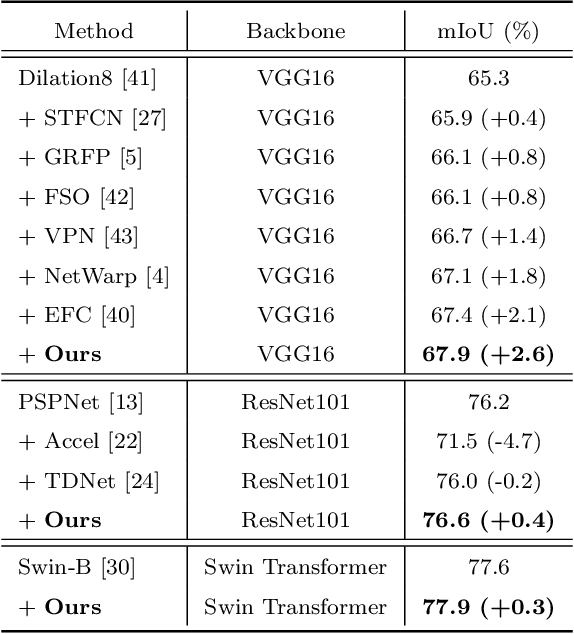
Video semantic segmentation aims to generate accurate semantic maps for each video frame. To this end, many works dedicate to integrate diverse information from consecutive frames to enhance the features for prediction, where a feature alignment procedure via estimated optical flow is usually required. However, the optical flow would inevitably suffer from inaccuracy, and then introduce noises in feature fusion and further result in unsatisfactory segmentation results. In this paper, to tackle the misalignment issue, we propose a spatial-temporal fusion (STF) module to model dense pairwise relationships among multi-frame features. Different from previous methods, STF uniformly and adaptively fuses features at different spatial and temporal positions, and avoids error-prone optical flow estimation. Besides, we further exploit feature refinement within a single frame and propose a novel memory-augmented refinement (MAR) module to tackle difficult predictions among semantic boundaries. Specifically, MAR can store the boundary features and prototypes extracted from the training samples, which together form the task-specific memory, and then use them to refine the features during inference. Essentially, MAR can move the hard features closer to the most likely category and thus make them more discriminative. We conduct extensive experiments on Cityscapes and CamVid, and the results show that our proposed methods significantly outperform previous methods and achieves the state-of-the-art performance. Code and pretrained models are available at https://github.com/jfzhuang/ST_Memory.
Adaptive and Scalable Compression of Multispectral Images using VVC
Jan 10, 2023
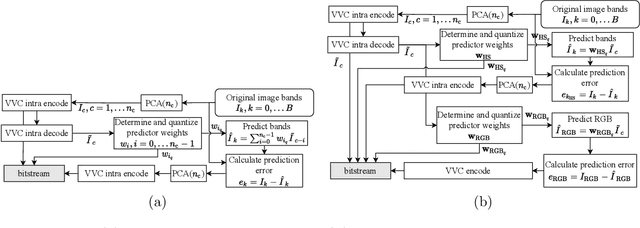
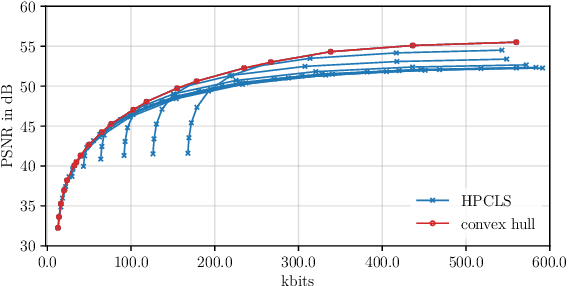
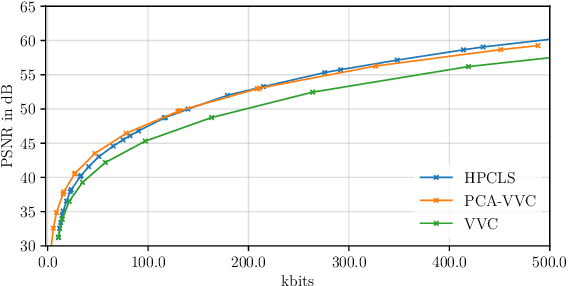
The VVC codec is applied to the task of multispectral image (MSI) compression using adaptive and scalable coding structures. In a 'plain' VVC approach, concepts from picture-to-picture temporal prediction are employed for decorrelation along the MSI's spectral dimension. The popular principle component analysis (PCA) for spectral decorrelation is further evaluated in combination with VVC intra-coding for spatial decorrelation. This approach is referred to as PCA-VVC. A novel adaptive MSI compression algorithm, named HPCLS, is introduced, that uses PCA and inter-prediction for spectral and VVC intra-coding for spatial decorrelation. Further, a novel adaptive scalable approach is proposed, that provides a separately decodable spectrally scaled preview of the MSI in the compressed file. Information contained in the preview is exploited in order to reduce the overall file size. All schemes are evaluated on images from the ARAD HS data set containing outdoor scenes with a high variety in brightness and color. We found that 'Plain' VVC is outperformed by both PCA-VVC and HPCLS. HPCLS shows advantageous rate-distortion (RD) behavior compared to PCA-VVC for reconstruction quality above 51dB PSNR. The performance of the scalable approach is compared to the combination of an independent RGB preview and one of HPCLS or PCA-VVC. The scalable approach shows significant benefit especially at higher preview qualities.
Channel-aware Decoupling Network for Multi-turn Dialogue Comprehension
Jan 10, 2023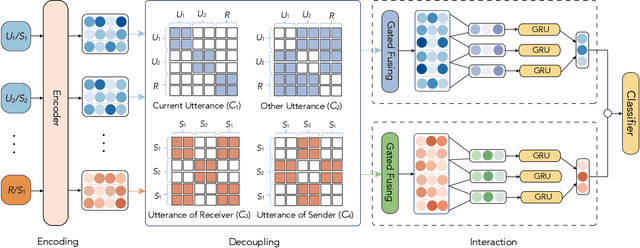
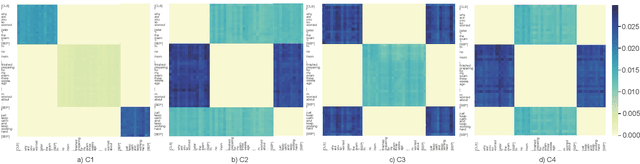
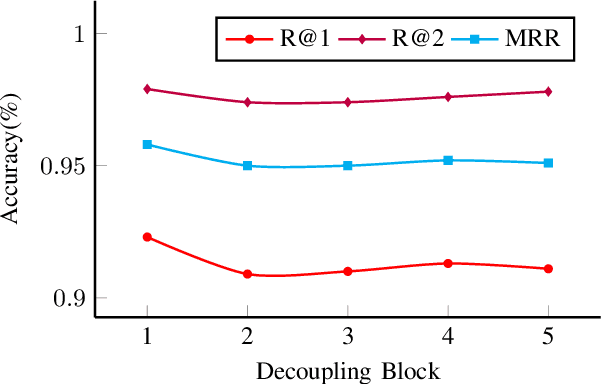
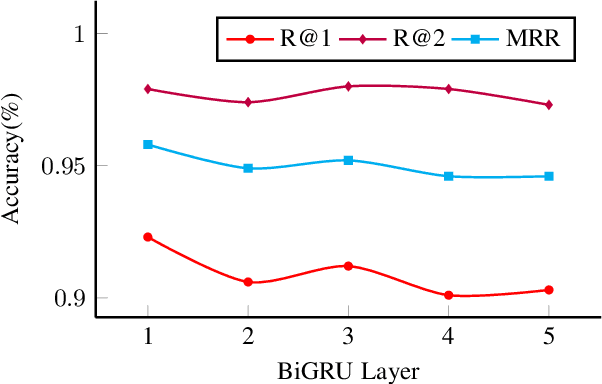
Training machines to understand natural language and interact with humans is one of the major goals of artificial intelligence. Recent years have witnessed an evolution from matching networks to pre-trained language models (PrLMs). In contrast to the plain-text modeling as the focus of the PrLMs, dialogue texts involve multiple speakers and reflect special characteristics such as topic transitions and structure dependencies between distant utterances. However, the related PrLM models commonly represent dialogues sequentially by processing the pairwise dialogue history as a whole. Thus the hierarchical information on either utterance interrelation or speaker roles coupled in such representations is not well addressed. In this work, we propose compositional learning for holistic interaction across the utterances beyond the sequential contextualization from PrLMs, in order to capture the utterance-aware and speaker-aware representations entailed in a dialogue history. We decouple the contextualized word representations by masking mechanisms in Transformer-based PrLM, making each word only focus on the words in current utterance, other utterances, and two speaker roles (i.e., utterances of sender and utterances of the receiver), respectively. In addition, we employ domain-adaptive training strategies to help the model adapt to the dialogue domains. Experimental results show that our method substantially boosts the strong PrLM baselines in four public benchmark datasets, achieving new state-of-the-art performance over previous methods.
Low-rank Tensor Assisted K-space Generative Model for Parallel Imaging Reconstruction
Dec 11, 2022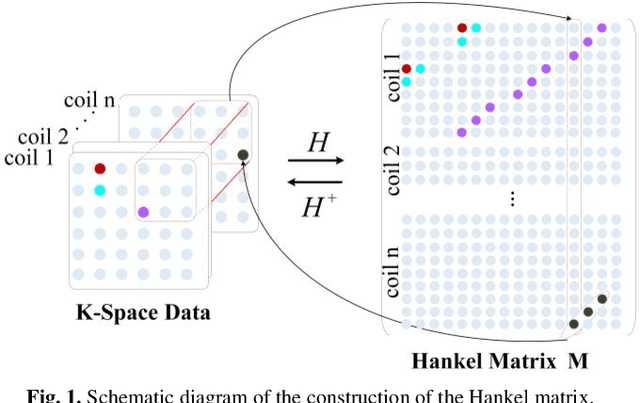
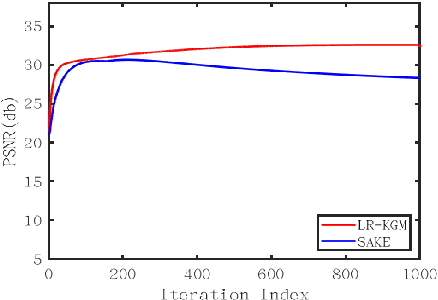
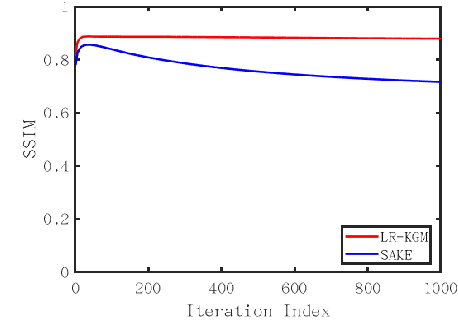
Although recent deep learning methods, especially generative models, have shown good performance in fast magnetic resonance imaging, there is still much room for improvement in high-dimensional generation. Considering that internal dimensions in score-based generative models have a critical impact on estimating the gradient of the data distribution, we present a new idea, low-rank tensor assisted k-space generative model (LR-KGM), for parallel imaging reconstruction. This means that we transform original prior information into high-dimensional prior information for learning. More specifically, the multi-channel data is constructed into a large Hankel matrix and the matrix is subsequently folded into tensor for prior learning. In the testing phase, the low-rank rotation strategy is utilized to impose low-rank constraints on tensor output of the generative network. Furthermore, we alternately use traditional generative iterations and low-rank high-dimensional tensor iterations for reconstruction. Experimental comparisons with the state-of-the-arts demonstrated that the proposed LR-KGM method achieved better performance.
I2MVFormer: Large Language Model Generated Multi-View Document Supervision for Zero-Shot Image Classification
Dec 05, 2022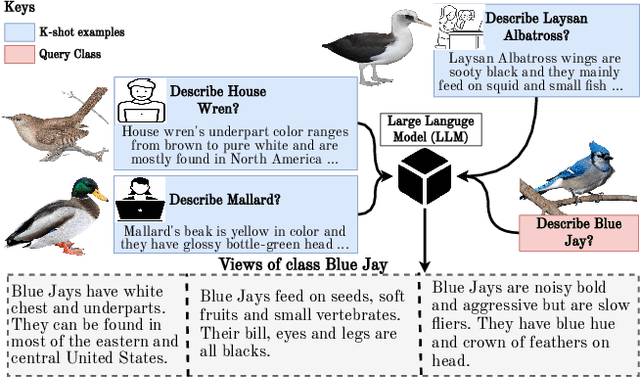
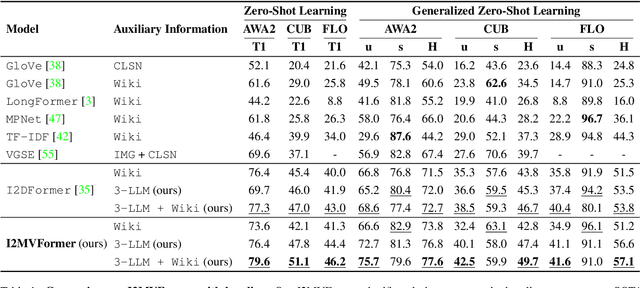
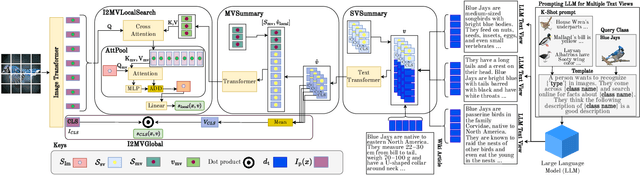

Recent works have shown that unstructured text (documents) from online sources can serve as useful auxiliary information for zero-shot image classification. However, these methods require access to a high-quality source like Wikipedia and are limited to a single source of information. Large Language Models (LLM) trained on web-scale text show impressive abilities to repurpose their learned knowledge for a multitude of tasks. In this work, we provide a novel perspective on using an LLM to provide text supervision for a zero-shot image classification model. The LLM is provided with a few text descriptions from different annotators as examples. The LLM is conditioned on these examples to generate multiple text descriptions for each class(referred to as views). Our proposed model, I2MVFormer, learns multi-view semantic embeddings for zero-shot image classification with these class views. We show that each text view of a class provides complementary information allowing a model to learn a highly discriminative class embedding. Moreover, we show that I2MVFormer is better at consuming the multi-view text supervision from LLM compared to baseline models. I2MVFormer establishes a new state-of-the-art on three public benchmark datasets for zero-shot image classification with unsupervised semantic embeddings.
MaNi: Maximizing Mutual Information for Nuclei Cross-Domain Unsupervised Segmentation
Jun 29, 2022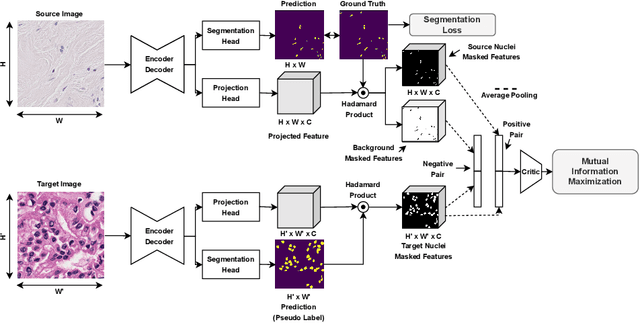
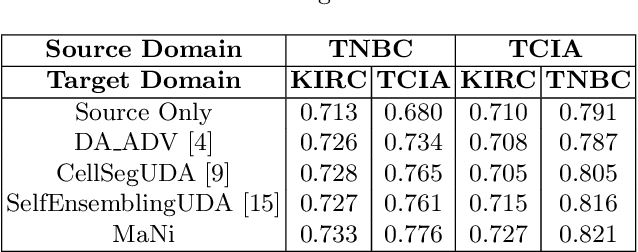
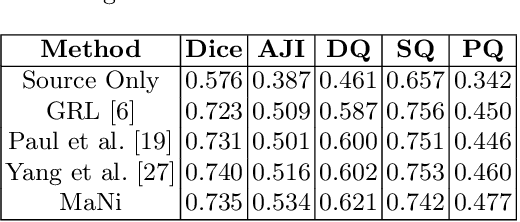
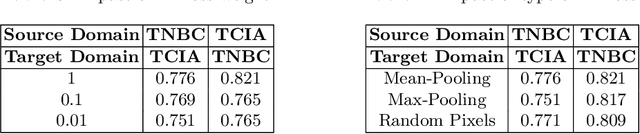
In this work, we propose a mutual information (MI) based unsupervised domain adaptation (UDA) method for the cross-domain nuclei segmentation. Nuclei vary substantially in structure and appearances across different cancer types, leading to a drop in performance of deep learning models when trained on one cancer type and tested on another. This domain shift becomes even more critical as accurate segmentation and quantification of nuclei is an essential histopathology task for the diagnosis/ prognosis of patients and annotating nuclei at the pixel level for new cancer types demands extensive effort by medical experts. To address this problem, we maximize the MI between labeled source cancer type data and unlabeled target cancer type data for transferring nuclei segmentation knowledge across domains. We use the Jensen-Shanon divergence bound, requiring only one negative pair per positive pair for MI maximization. We evaluate our set-up for multiple modeling frameworks and on different datasets comprising of over 20 cancer-type domain shifts and demonstrate competitive performance. All the recently proposed approaches consist of multiple components for improving the domain adaptation, whereas our proposed module is light and can be easily incorporated into other methods (Implementation: https://github.com/YashSharma/MaNi ).