 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Semi-Supervised Bifold Teacher-Student Learning for Indoor Presence Detection Under Time-Varying CSI
Dec 21, 2022
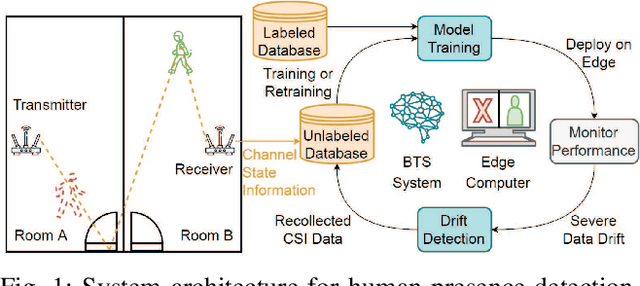
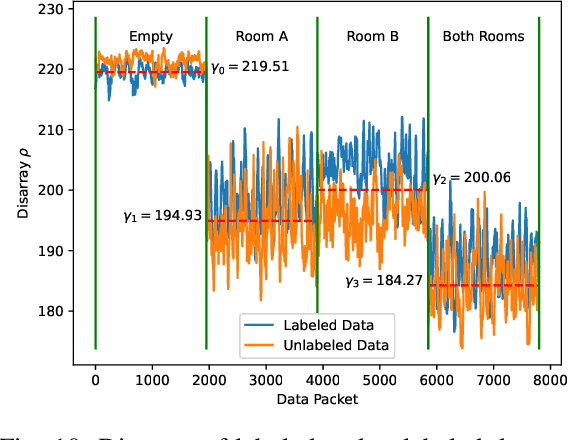
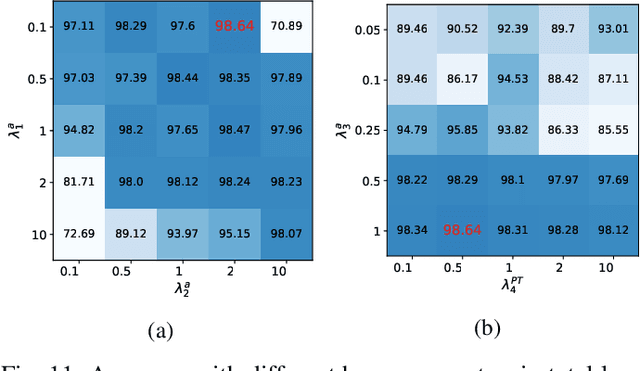
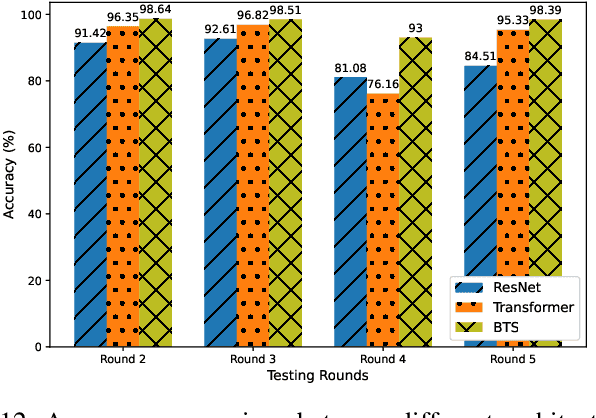
In recent years, there have been abundant researches focused on indoor human presence detection based on laborious supervised learning (SL) and channel state information (CSI). These existing studies adopt spatial information of CSI to improve detection accuracy. However, channel is susceptible to arbitrary environmental changes in practice, such as the object movement, atmospheric factors and machine rebooting, which leads to degraded prediction accuracy. However, the existing SL-based methods require to re-train a new model with time-consuming labeling. Therefore, designing a semi-supervised learning (SSL) based scheme by continuously monitoring model "life-cycle" becomes compellingly imperative. In this paper, we propose bifold teacher-student (BTS) learning for presence detection system, which combines SSL by utilizing partial labeled and unlabeled dataset. The proposed primal-dual teacher-student network is capable of intelligently learning spatial and temporal features from labeled and unlabeled CSI. Additionally, the enhanced penalized loss function leveraging entropy and distance measure can distinguish the drifted data, i.e., features of new dataset are affected by time-varying effect and are alternated from the original distribution. The experimental results demonstrate that the proposed BTS system can sustain the asymptotic accuracy after retraining the model with unlabeled data. Moreover, label-free BTS outperforms the existing SSL-based models in terms of the highest detection accuracy, while achieving the similar performance of SL-based methods.
Shape Aware Automatic Region-of-Interest Subdivisions
Dec 17, 2022
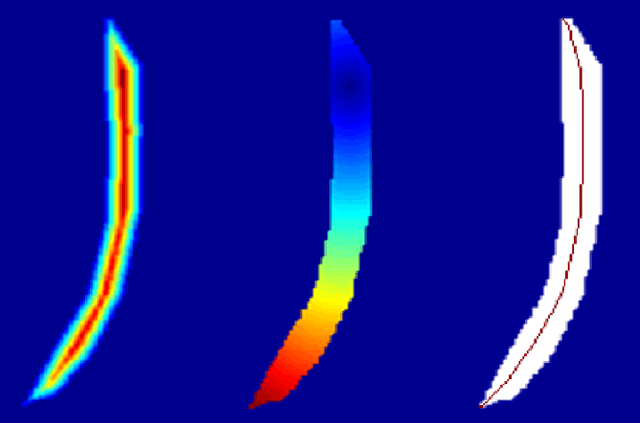
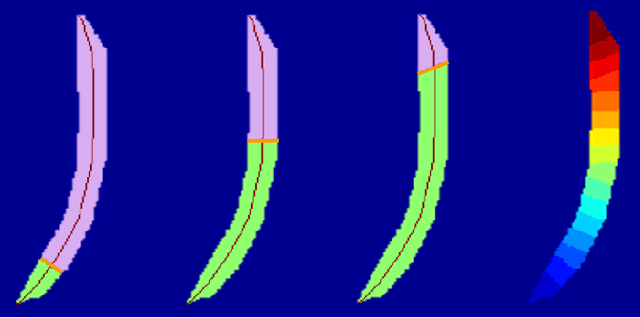
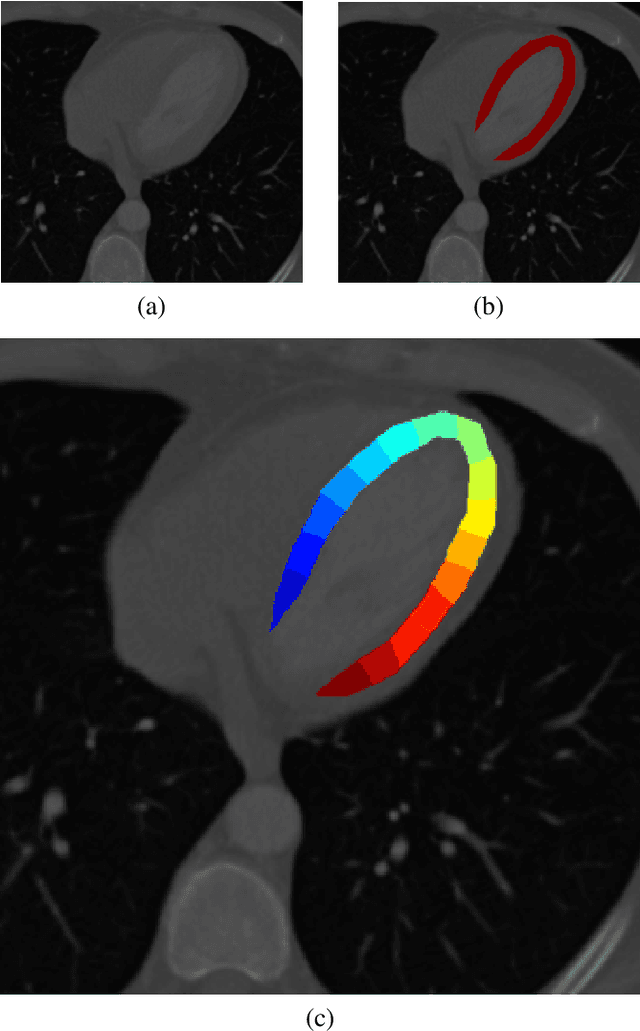
In a wide variety of fields, analysis of images involves defining a region and measuring its inherent properties. Such measurements include a region's surface area, curvature, volume, average gray and/or color scale, and so on. Furthermore, the subsequent subdivision of these regions is sometimes performed. These subdivisions are then used to measure local information, at even finer scales. However, simple griding or manual editing methods are typically used to subdivide a region into smaller units. The resulting subdivisions can therefore either not relate well to the actual shape or property of the region being studied (i.e., gridding methods), or be time consuming and based on user subjectivity (i.e., manual methods). The method discussed in this work extracts subdivisional units based on a region's general shape information. We present the results of applying our method to the medical image analysis of nested regions-of-interest of myocardial wall, where the subdivisions are used to study temporal and/or spatial heterogeneity of myocardial perfusion. This method is of particular interest for creating subdivision regions-of-interest (SROIs) when no variable intensity or other criteria within a region need be used to separate a particular region into subunits.
Improving Continuous Sign Language Recognition with Consistency Constraints and Signer Removal
Dec 26, 2022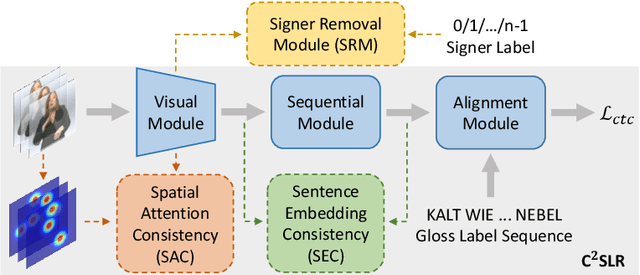
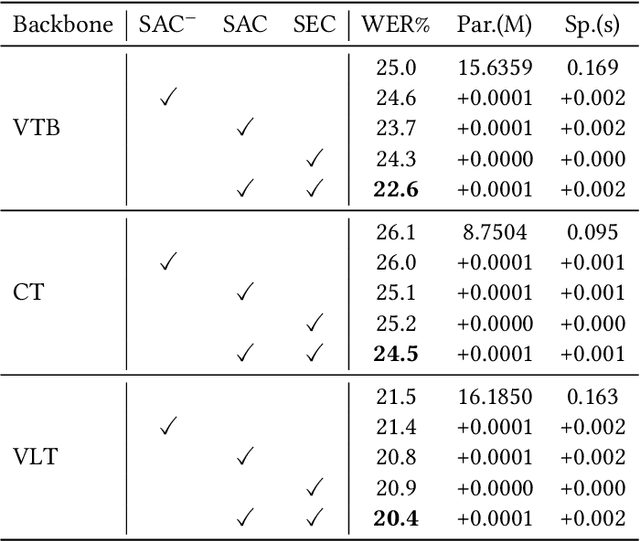
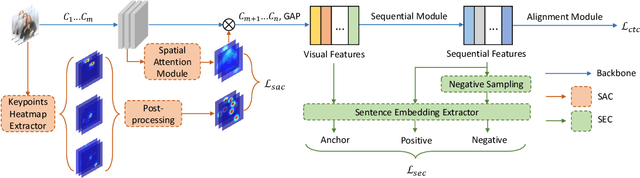
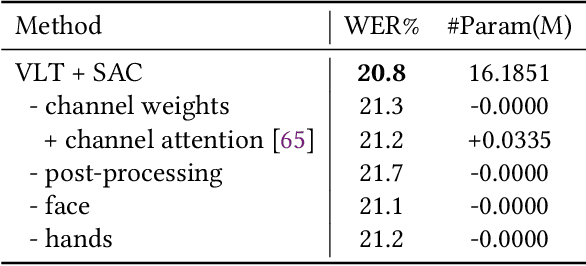
Most deep-learning-based continuous sign language recognition (CSLR) models share a similar backbone consisting of a visual module, a sequential module, and an alignment module. However, due to limited training samples, a connectionist temporal classification loss may not train such CSLR backbones sufficiently. In this work, we propose three auxiliary tasks to enhance the CSLR backbones. The first task enhances the visual module, which is sensitive to the insufficient training problem, from the perspective of consistency. Specifically, since the information of sign languages is mainly included in signers' facial expressions and hand movements, a keypoint-guided spatial attention module is developed to enforce the visual module to focus on informative regions, i.e., spatial attention consistency. Second, noticing that both the output features of the visual and sequential modules represent the same sentence, to better exploit the backbone's power, a sentence embedding consistency constraint is imposed between the visual and sequential modules to enhance the representation power of both features. We name the CSLR model trained with the above auxiliary tasks as consistency-enhanced CSLR, which performs well on signer-dependent datasets in which all signers appear during both training and testing. To make it more robust for the signer-independent setting, a signer removal module based on feature disentanglement is further proposed to remove signer information from the backbone. Extensive ablation studies are conducted to validate the effectiveness of these auxiliary tasks. More remarkably, with a transformer-based backbone, our model achieves state-of-the-art or competitive performance on five benchmarks, PHOENIX-2014, PHOENIX-2014-T, PHOENIX-2014-SI, CSL, and CSL-Daily.
Fake News Quick Detection on Dynamic Heterogeneous Information Networks
May 14, 2022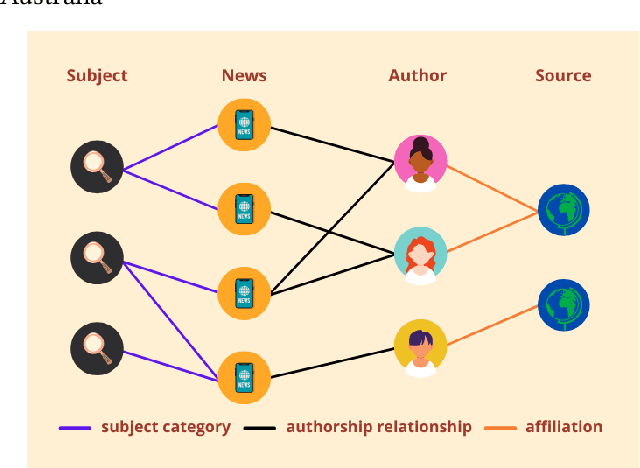
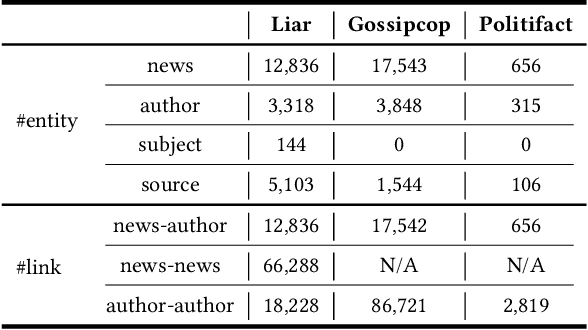
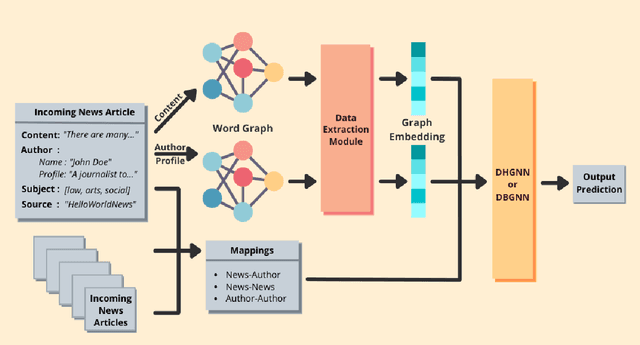

The spread of fake news has caused great harm to society in recent years. So the quick detection of fake news has become an important task. Some current detection methods often model news articles and other related components as a static heterogeneous information network (HIN) and use expensive message-passing algorithms. However, in the real-world, quickly identifying fake news is of great significance and the network may vary over time in terms of dynamic nodes and edges. Therefore, in this paper, we propose a novel Dynamic Heterogeneous Graph Neural Network (DHGNN) for fake news quick detection. More specifically, we first implement BERT and fine-tuned BERT to get a semantic representation of the news article contents and author profiles and convert it into graph data. Then, we construct the heterogeneous news-author graph to reflect contextual information and relationships. Additionally, we adapt ideas from personalized PageRank propagation and dynamic propagation to heterogeneous networks in order to reduce the time complexity of back-propagating through many nodes during training. Experiments on three real-world fake news datasets show that DHGNN can outperform other GNN-based models in terms of both effectiveness and efficiency.
Label-Efficient Self-Supervised Speaker Verification With Information Maximization and Contrastive Learning
Jul 12, 2022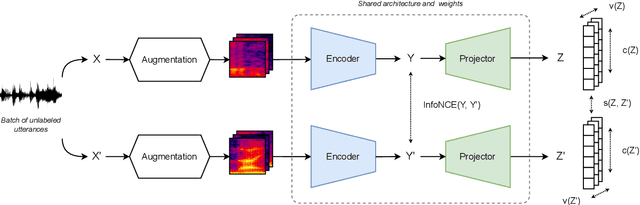
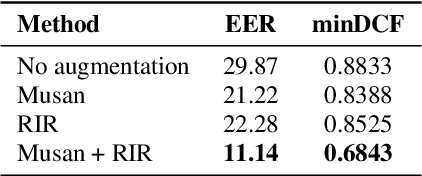
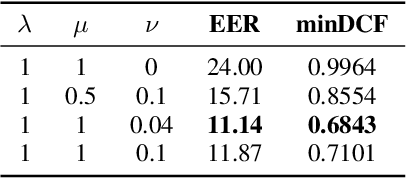
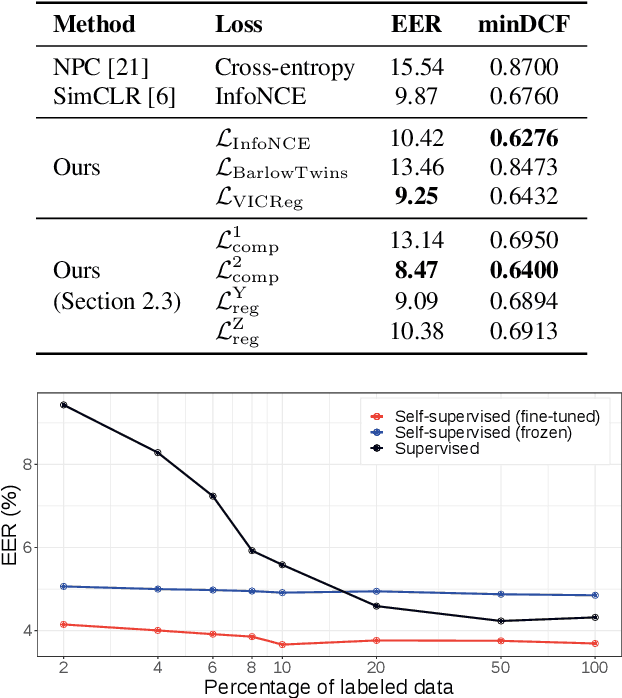
State-of-the-art speaker verification systems are inherently dependent on some kind of human supervision as they are trained on massive amounts of labeled data. However, manually annotating utterances is slow, expensive and not scalable to the amount of data available today. In this study, we explore self-supervised learning for speaker verification by learning representations directly from raw audio. The objective is to produce robust speaker embeddings that have small intra-speaker and large inter-speaker variance. Our approach is based on recent information maximization learning frameworks and an intensive data augmentation pre-processing step. We evaluate the ability of these methods to work without contrastive samples before showing that they achieve better performance when combined with a contrastive loss. Furthermore, we conduct experiments to show that our method reaches competitive results compared to existing techniques and can get better performances compared to a supervised baseline when fine-tuned with a small portion of labeled data.
* accepted to INTERSPEECH 2022
Extending Source Code Pre-Trained Language Models to Summarise Decompiled Binaries
Jan 13, 2023
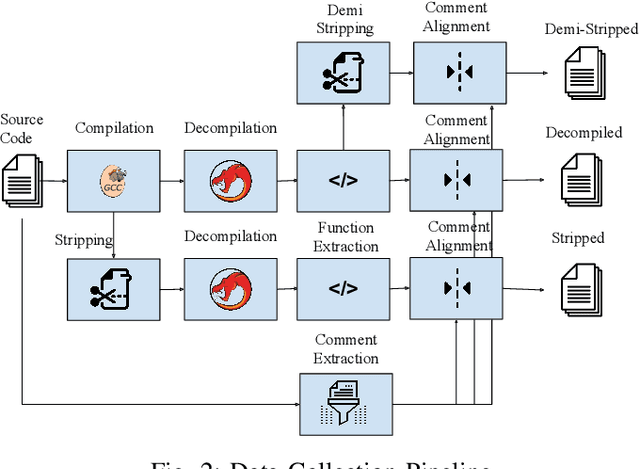

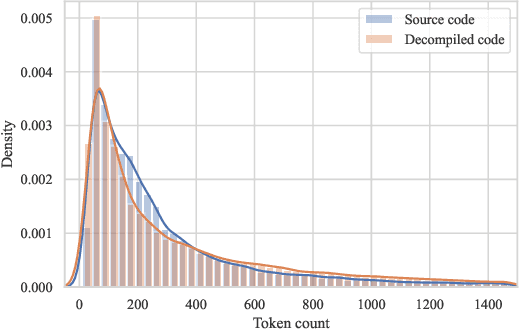
Reverse engineering binaries is required to understand and analyse programs for which the source code is unavailable. Decompilers can transform the largely unreadable binaries into a more readable source code-like representation. However, reverse engineering is time-consuming, much of which is taken up by labelling the functions with semantic information. While the automated summarisation of decompiled code can help Reverse Engineers understand and analyse binaries, current work mainly focuses on summarising source code, and no suitable dataset exists for this task. In this work, we extend large pre-trained language models of source code to summarise decompiled binary functions. Furthermore, we investigate the impact of input and data properties on the performance of such models. Our approach consists of two main components; the data and the model. We first build CAPYBARA, a dataset of 214K decompiled function-documentation pairs across various compiler optimisations. We extend CAPYBARA further by generating synthetic datasets and deduplicating the data. Next, we fine-tune the CodeT5 base model with CAPYBARA to create BinT5. BinT5 achieves the state-of-the-art BLEU-4 score of 60.83, 58.82, and 44.21 for summarising source, decompiled, and synthetically stripped decompiled code, respectively. This indicates that these models can be extended to decompiled binaries successfully. Finally, we found that the performance of BinT5 is not heavily dependent on the dataset size and compiler optimisation level. We recommend future research to further investigate transferring knowledge when working with less expressive input formats such as stripped binaries.
Hierarchical Deep Q-Learning Based Handover in Wireless Networks with Dual Connectivity
Jan 13, 2023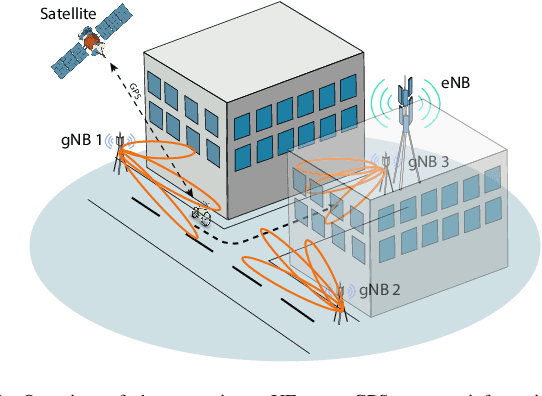
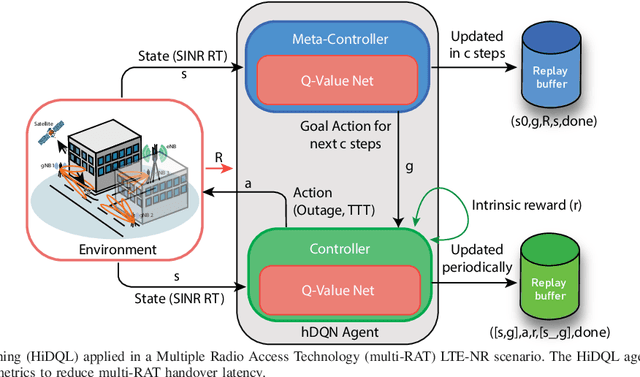
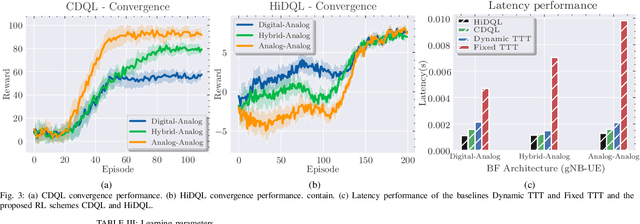
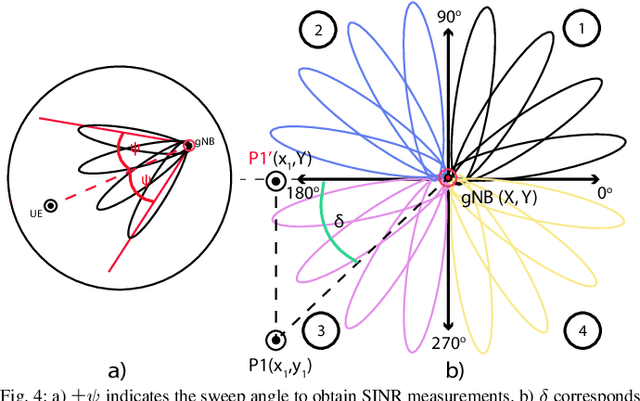
5G New Radio proposes the usage of frequencies above 10 GHz to speed up LTE's existent maximum data rates. However, the effective size of 5G antennas and consequently its repercussions in the signal degradation in urban scenarios makes it a challenge to maintain stable coverage and connectivity. In order to obtain the best from both technologies, recent dual connectivity solutions have proved their capabilities to improve performance when compared with coexistent standalone 5G and 4G technologies. Reinforcement learning (RL) has shown its huge potential in wireless scenarios where parameter learning is required given the dynamic nature of such context. In this paper, we propose two reinforcement learning algorithms: a single agent RL algorithm named Clipped Double Q-Learning (CDQL) and a hierarchical Deep Q-Learning (HiDQL) to improve Multiple Radio Access Technology (multi-RAT) dual-connectivity handover. We compare our proposal with two baselines: a fixed parameter and a dynamic parameter solution. Simulation results reveal significant improvements in terms of latency with a gain of 47.6% and 26.1% for Digital-Analog beamforming (BF), 17.1% and 21.6% for Hybrid-Analog BF, and 24.7% and 39% for Analog-Analog BF when comparing the RL-schemes HiDQL and CDQL with the with the existent solutions, HiDQL presented a slower convergence time, however obtained a more optimal solution than CDQL. Additionally, we foresee the advantages of utilizing context-information as geo-location of the UEs to reduce the beam exploration sector, and thus improving further multi-RAT handover latency results.
Urban Visual Intelligence: Studying Cities with AI and Street-level Imagery
Jan 02, 2023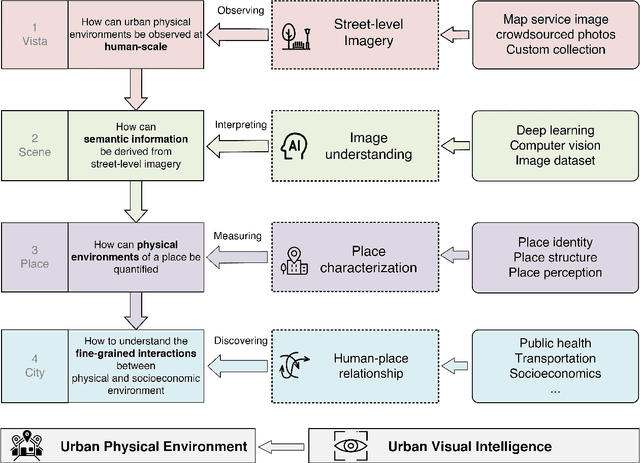

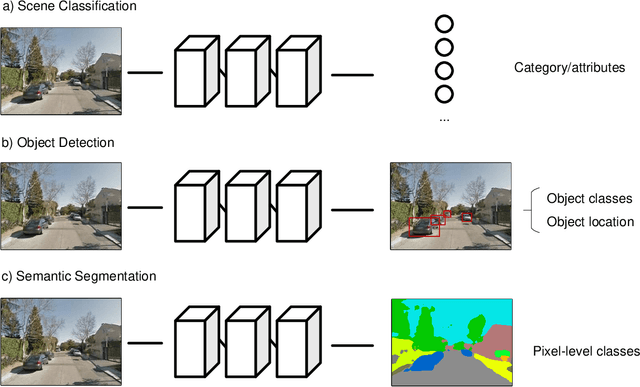
The visual dimension of cities has been a fundamental subject in urban studies, since the pioneering work of scholars such as Sitte, Lynch, Arnheim, and Jacobs. Several decades later, big data and artificial intelligence (AI) are revolutionizing how people move, sense, and interact with cities. This paper reviews the literature on the appearance and function of cities to illustrate how visual information has been used to understand them. A conceptual framework, Urban Visual Intelligence, is introduced to systematically elaborate on how new image data sources and AI techniques are reshaping the way researchers perceive and measure cities, enabling the study of the physical environment and its interactions with socioeconomic environments at various scales. The paper argues that these new approaches enable researchers to revisit the classic urban theories and themes, and potentially help cities create environments that are more in line with human behaviors and aspirations in the digital age.
Sequence Generation with Label Augmentation for Relation Extraction
Dec 29, 2022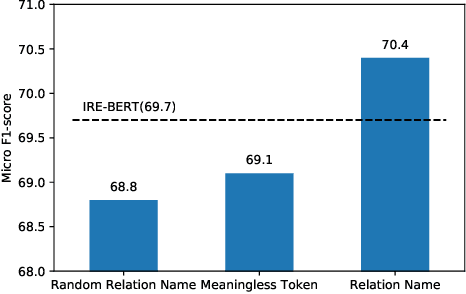

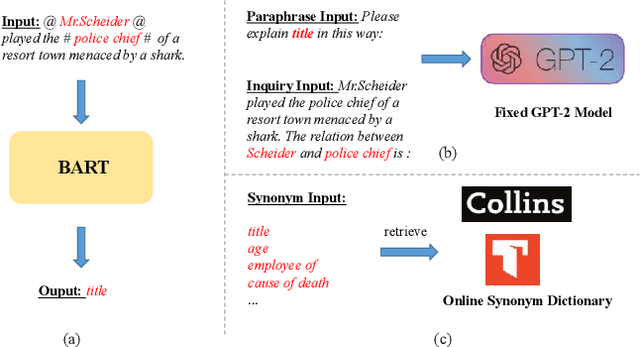
Sequence generation demonstrates promising performance in recent information extraction efforts, by incorporating large-scale pre-trained Seq2Seq models. This paper investigates the merits of employing sequence generation in relation extraction, finding that with relation names or synonyms as generation targets, their textual semantics and the correlation (in terms of word sequence pattern) among them affect model performance. We then propose Relation Extraction with Label Augmentation (RELA), a Seq2Seq model with automatic label augmentation for RE. By saying label augmentation, we mean prod semantically synonyms for each relation name as the generation target. Besides, we present an in-depth analysis of the Seq2Seq model's behavior when dealing with RE. Experimental results show that RELA achieves competitive results compared with previous methods on four RE datasets.
On Suspicious Coincidences and Pointwise Mutual Information
Mar 15, 2022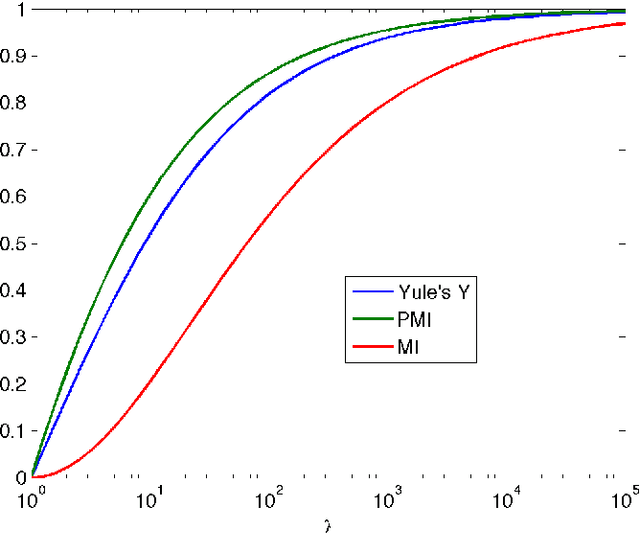
Barlow (1985) hypothesized that the co-occurrence of two events $A$ and $B$ is "suspicious" if $P(A,B) \gg P(A) P(B)$. We first review classical measures of association for $2 \times 2$ contingency tables, including Yule's $Y$ (Yule, 1912), which depends only on the odds ratio $\lambda$, and is independent of the marginal probabilities of the table. We then discuss the mutual information (MI) and pointwise mutual information (PMI), which depend on the ratio $P(A,B)/P(A)P(B)$, as measures of association. We show that, once the effect of the marginals is removed, MI and PMI behave similarly to $Y$ as functions of $\lambda$. The pointwise mutual information is used extensively in some research communities for flagging suspicious coincidences, but it is important to bear in mind the sensitivity of the PMI to the marginals, with increased scores for sparser events.