 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GazBy: Gaze-Based BERT Model to Incorporate Human Attention in Neural Information Retrieval
Jul 04, 2022
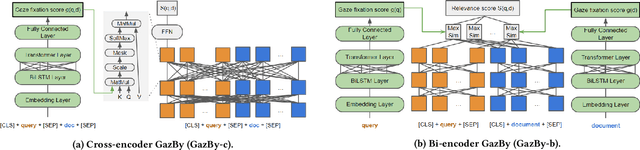
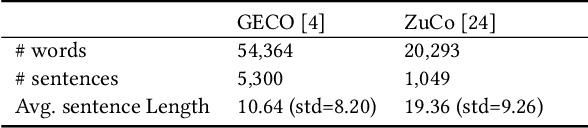
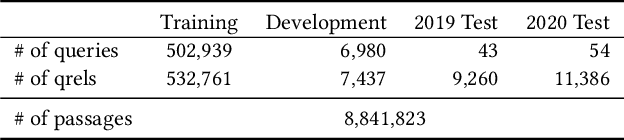
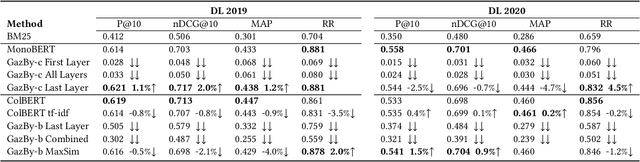
This paper is interested in investigating whether human gaze signals can be leveraged to improve state-of-the-art search engine performance and how to incorporate this new input signal marked by human attention into existing neural retrieval models. In this paper, we propose GazBy ({\bf Gaz}e-based {\bf B}ert model for document relevanc{\bf y}), a light-weight joint model that integrates human gaze fixation estimation into transformer models to predict document relevance, incorporating more nuanced information about cognitive processing into information retrieval (IR). We evaluate our model on the Text Retrieval Conference (TREC) Deep Learning (DL) 2019 and 2020 Tracks. Our experiments show encouraging results and illustrate the effective and ineffective entry points for using human gaze to help with transformer-based neural retrievers. With the rise of virtual reality (VR) and augmented reality (AR), human gaze data will become more available. We hope this work serves as a first step exploring using gaze signals in modern neural search engines.
An advanced YOLOv3 method for small object detection
Dec 06, 2022
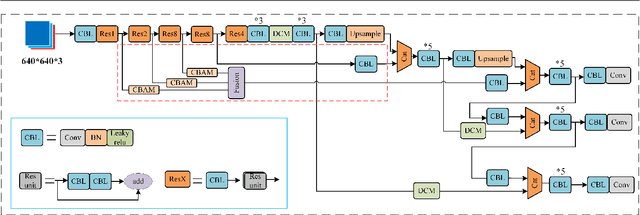
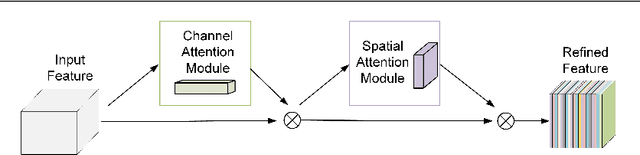
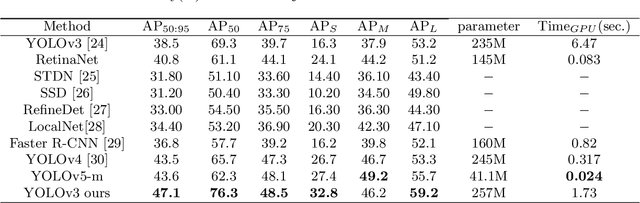
In recent years, object detection has achieved a very large performance improvement, but the detection result of small objects is still not very satisfactory. This work proposes a strategy based on feature fusion and dilated convolution that employs dilated convolution to broaden the receptive field of feature maps at various scales in order to address this issue. On the one hand, it can improve the detection accuracy of larger objects. On the other hand, it provides more contextual information for small objects, which is beneficial to improving the detection accuracy of small objects. The shallow semantic information of small objects is obtained by filtering out the noise in the feature map, and the feature information of more small objects is preserved by using multi-scale fusion feature module and attention mechanism. The fusion of these shallow feature information and deep semantic information can generate richer feature maps for small object detection. Experiments show that this method can have higher accuracy than the traditional YOLOv3 network in the detection of small objects and occluded objects. In addition, we achieve 32.8\% Mean Average Precision on the detection of small objects on MS COCO2017 test set. For 640*640 input, this method has 88.76\% mAP on the PASCAL VOC2012 dataset.
Unsupervised Voice Activity Detection by Modeling Source and System Information using Zero Frequency Filtering
Jun 27, 2022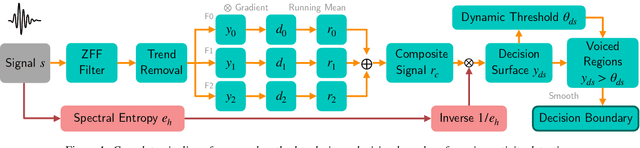
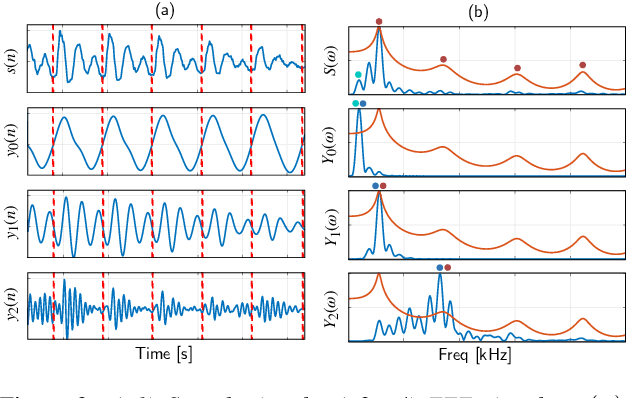
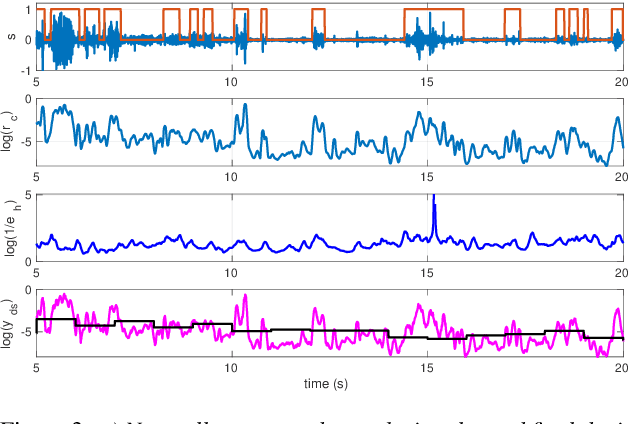
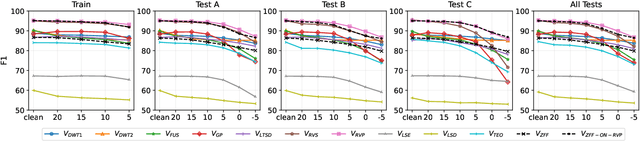
Voice activity detection (VAD) is an important pre-processing step for speech technology applications. The task consists of deriving segment boundaries of audio signals which contain voicing information. In recent years, it has been shown that voice source and vocal tract system information can be extracted using zero-frequency filtering (ZFF) without making any explicit model assumptions about the speech signal. This paper investigates the potential of zero-frequency filtering for jointly modeling voice source and vocal tract system information, and proposes two approaches for VAD. The first approach demarcates voiced regions using a composite signal composed of different zero-frequency filtered signals. The second approach feeds the composite signal as input to the rVAD algorithm. These approaches are compared with other supervised and unsupervised VAD methods in the literature, and are evaluated on the Aurora-2 database, across a range of SNRs (20 to -5 dB). Our studies show that the proposed ZFF-based methods perform comparable to state-of-art VAD methods and are more invariant to added degradation and different channel characteristics.
Enriching Relation Extraction with OpenIE
Dec 19, 2022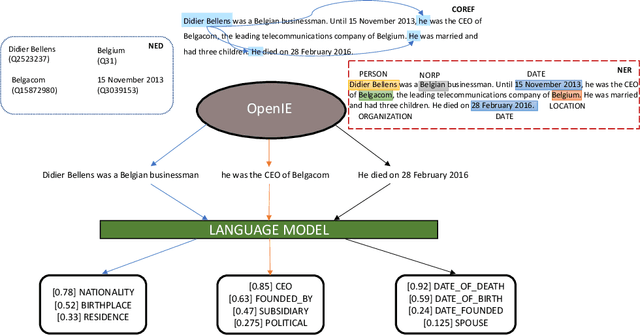
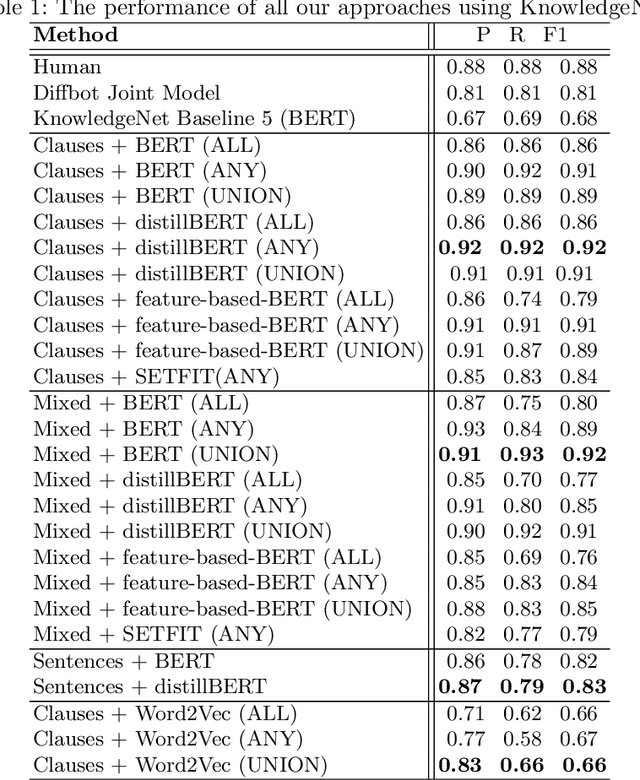
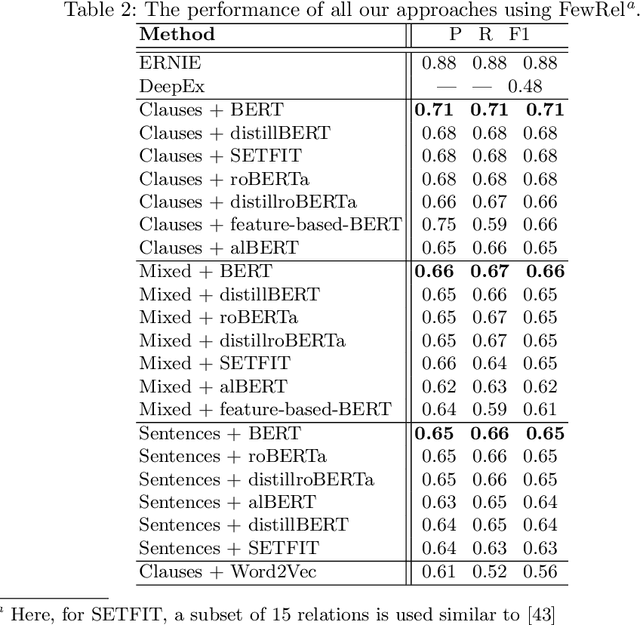
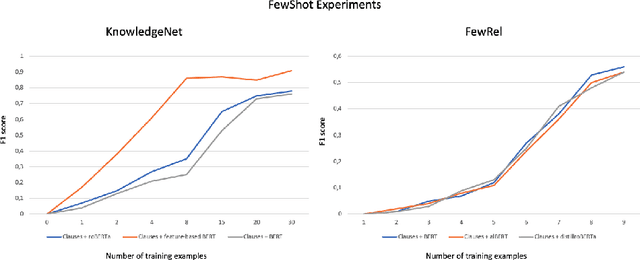
Relation extraction (RE) is a sub-discipline of information extraction (IE) which focuses on the prediction of a relational predicate from a natural-language input unit (such as a sentence, a clause, or even a short paragraph consisting of multiple sentences and/or clauses). Together with named-entity recognition (NER) and disambiguation (NED), RE forms the basis for many advanced IE tasks such as knowledge-base (KB) population and verification. In this work, we explore how recent approaches for open information extraction (OpenIE) may help to improve the task of RE by encoding structured information about the sentences' principal units, such as subjects, objects, verbal phrases, and adverbials, into various forms of vectorized (and hence unstructured) representations of the sentences. Our main conjecture is that the decomposition of long and possibly convoluted sentences into multiple smaller clauses via OpenIE even helps to fine-tune context-sensitive language models such as BERT (and its plethora of variants) for RE. Our experiments over two annotated corpora, KnowledgeNet and FewRel, demonstrate the improved accuracy of our enriched models compared to existing RE approaches. Our best results reach 92% and 71% of F1 score for KnowledgeNet and FewRel, respectively, proving the effectiveness of our approach on competitive benchmarks.
Masked Visual Reconstruction in Language Semantic Space
Jan 17, 2023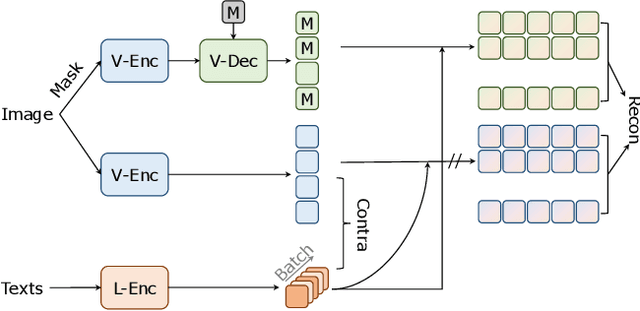
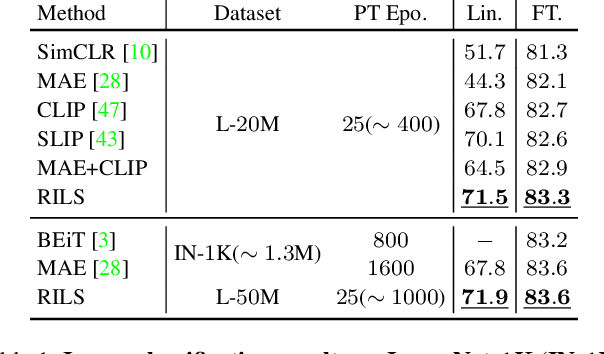
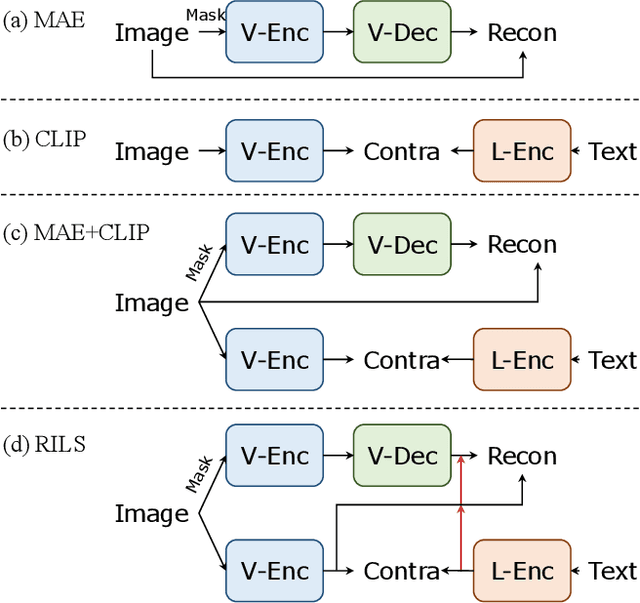
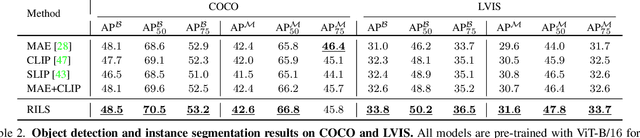
Both masked image modeling (MIM) and natural language supervision have facilitated the progress of transferable visual pre-training. In this work, we seek the synergy between two paradigms and study the emerging properties when MIM meets natural language supervision. To this end, we present a novel masked visual Reconstruction In Language semantic Space (RILS) pre-training framework, in which sentence representations, encoded by the text encoder, serve as prototypes to transform the vision-only signals into patch-sentence probabilities as semantically meaningful MIM reconstruction targets. The vision models can therefore capture useful components with structured information by predicting proper semantic of masked tokens. Better visual representations could, in turn, improve the text encoder via the image-text alignment objective, which is essential for the effective MIM target transformation. Extensive experimental results demonstrate that our method not only enjoys the best of previous MIM and CLIP but also achieves further improvements on various tasks due to their mutual benefits. RILS exhibits advanced transferability on downstream classification, detection, and segmentation, especially for low-shot regimes. Code will be made available at https://github.com/hustvl/RILS.
Leveraging Vision-Language Models for Granular Market Change Prediction
Jan 17, 2023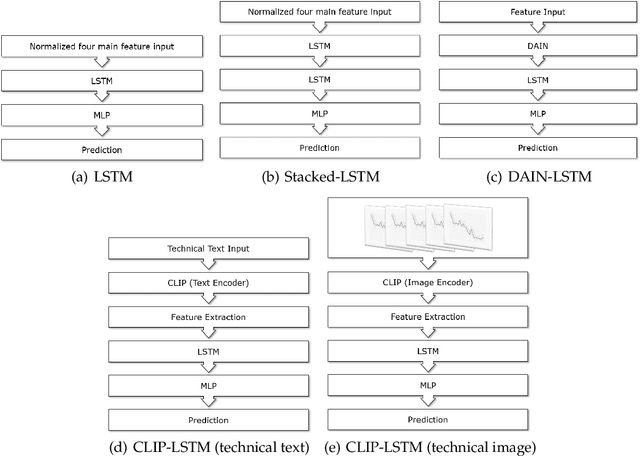

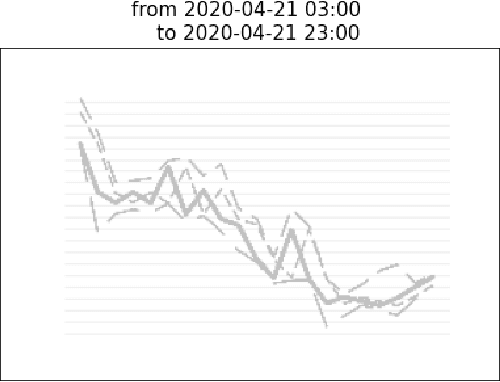
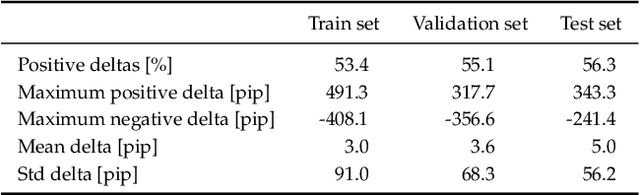
Predicting future direction of stock markets using the historical data has been a fundamental component in financial forecasting. This historical data contains the information of a stock in each specific time span, such as the opening, closing, lowest, and highest price. Leveraging this data, the future direction of the market is commonly predicted using various time-series models such as Long-Short Term Memory networks. This work proposes modeling and predicting market movements with a fundamentally new approach, namely by utilizing image and byte-based number representation of the stock data processed with the recently introduced Vision-Language models. We conduct a large set of experiments on the hourly stock data of the German share index and evaluate various architectures on stock price prediction using historical stock data. We conduct a comprehensive evaluation of the results with various metrics to accurately depict the actual performance of various approaches. Our evaluation results show that our novel approach based on representation of stock data as text (bytes) and image significantly outperforms strong deep learning-based baselines.
A Distributed Machine Learning-Based Approach for IRS-Enhanced Cell-Free MIMO Networks
Jan 19, 2023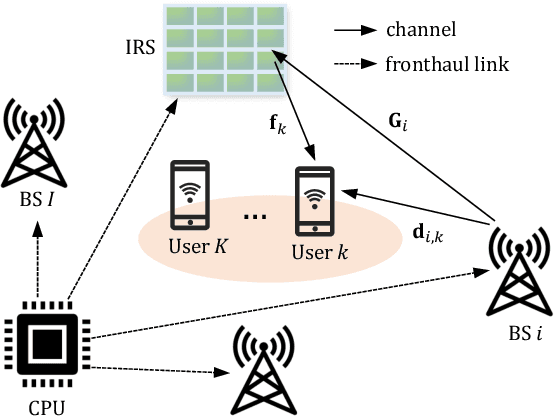
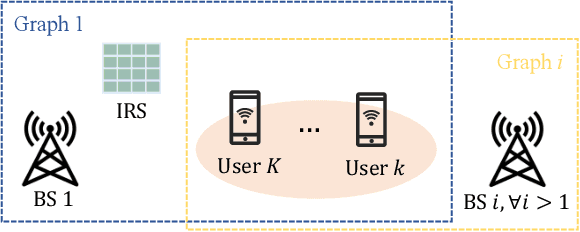
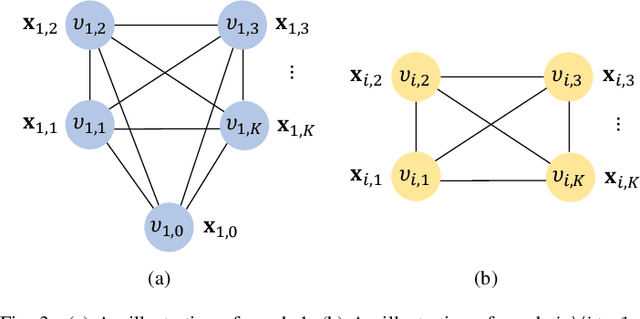
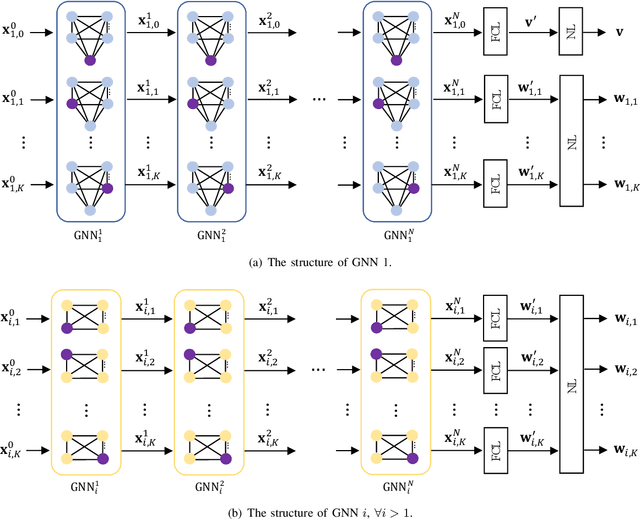
In cell-free multiple input multiple output (MIMO) networks, multiple base stations (BSs) can collaborate to achieve high spectral efficiency. Nevertheless, high penetration loss due to large blockages in harsh propagation environments is often an issue that severely degrades communication performance. Considering that intelligent reflecting surface (IRS) is capable of constructing digitally controllable reflection links in a low-cost manner, we investigate an IRS-enhanced downlink cell-free MIMO network in this paper. We aim to maximize the sum rate of all the users by jointly optimizing the transmit beamforming at the BSs and the reflection coefficients at the IRS. To address the optimization problem, we propose a fully distributed machine learning algorithm. Compared with the conventional iterative optimization algorithms that require a central processing at the central processing unit and large amount of channel state information and signaling exchange among the BSs, each BS can locally design its beamforming vector in the proposed algorithm. Meanwhile, the IRS reflection coefficients are determined by one of the BSs. Simulation results show that the deployment of IRS can significantly boost the sum user rate and that the proposed algorithm outperforms the benchmark methods.
Continuously Reliable Detection of New-Normal Misinformation: Semantic Masking and Contrastive Smoothing in High-Density Latent Regions
Jan 19, 2023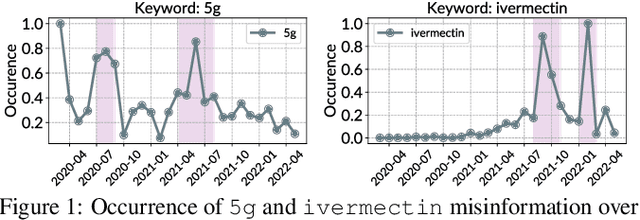

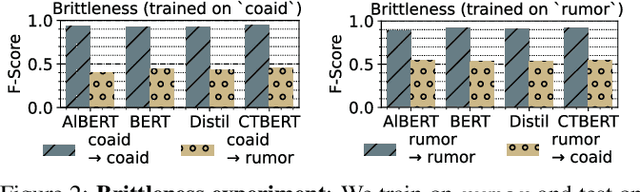
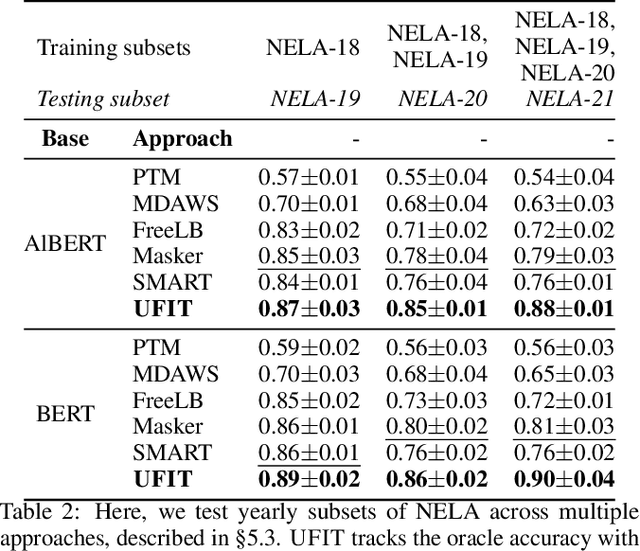
Toxic misinformation campaigns have caused significant societal harm, e.g., affecting elections and COVID-19 information awareness. Unfortunately, despite successes of (gold standard) retrospective studies of misinformation that confirmed their harmful effects after the fact, they arrive too late for timely intervention and reduction of such harm. By design, misinformation evades retrospective classifiers by exploiting two properties we call new-normal: (1) never-seen-before novelty that cause inescapable generalization challenges for previous classifiers, and (2) massive but short campaigns that end before they can be manually annotated for new classifier training. To tackle these challenges, we propose UFIT, which combines two techniques: semantic masking of strong signal keywords to reduce overfitting, and intra-proxy smoothness regularization of high-density regions in the latent space to improve reliability and maintain accuracy. Evaluation of UFIT on public new-normal misinformation data shows over 30% improvement over existing approaches on future (and unseen) campaigns. To the best of our knowledge, UFIT is the first successful effort to achieve such high level of generalization on new-normal misinformation data with minimal concession (1 to 5%) of accuracy compared to oracles trained with full knowledge of all campaigns.
Estimating Remaining Lifespan from the Face
Jan 19, 2023
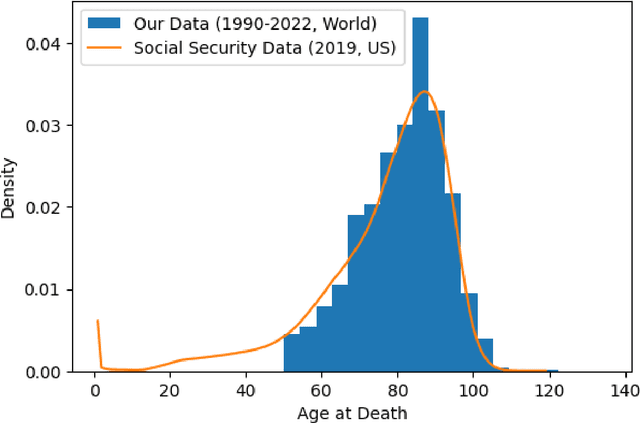

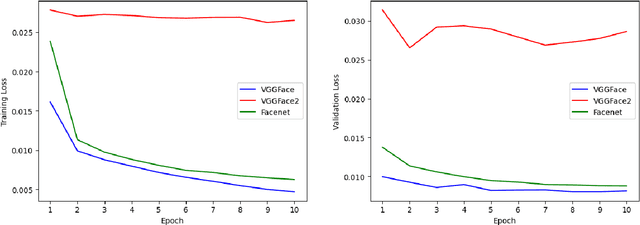
The face is a rich source of information that can be utilized to infer a person's biological age, sex, phenotype, genetic defects, and health status. All of these factors are relevant for predicting an individual's remaining lifespan. In this study, we collected a dataset of over 24,000 images (from Wikidata/Wikipedia) of individuals who died of natural causes, along with the number of years between when the image was taken and when the person passed away. We made this dataset publicly available. We fine-tuned multiple Convolutional Neural Network (CNN) models on this data, at best achieving a mean absolute error of 8.3 years in the validation data using VGGFace. However, the model's performance diminishes when the person was younger at the time of the image. To demonstrate the potential applications of our remaining lifespan model, we present examples of using it to estimate the average loss of life (in years) due to the COVID-19 pandemic and to predict the increase in life expectancy that might result from a health intervention such as weight loss. Additionally, we discuss the ethical considerations associated with such models.
FECANet: Boosting Few-Shot Semantic Segmentation with Feature-Enhanced Context-Aware Network
Jan 19, 2023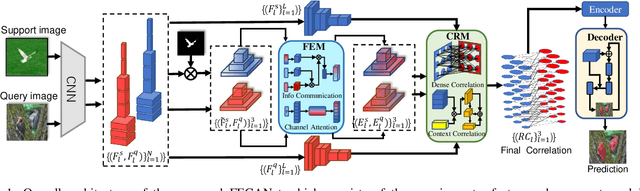
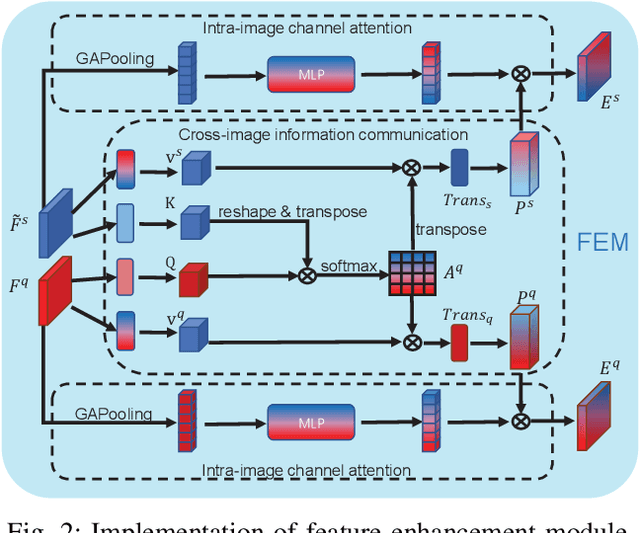
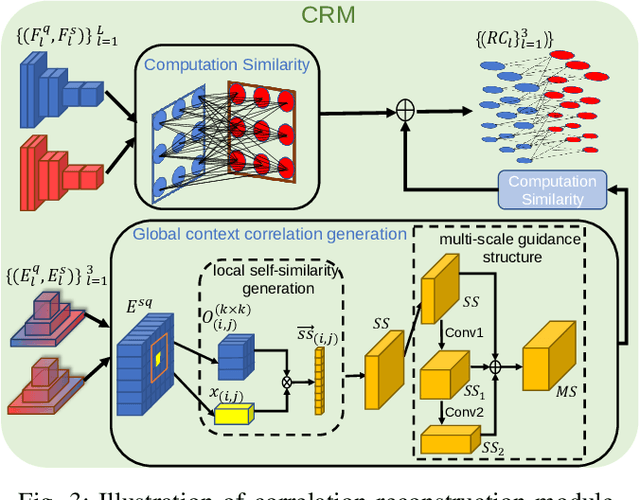

Few-shot semantic segmentation is the task of learning to locate each pixel of the novel class in the query image with only a few annotated support images. The current correlation-based methods construct pair-wise feature correlations to establish the many-to-many matching because the typical prototype-based approaches cannot learn fine-grained correspondence relations. However, the existing methods still suffer from the noise contained in naive correlations and the lack of context semantic information in correlations. To alleviate these problems mentioned above, we propose a Feature-Enhanced Context-Aware Network (FECANet). Specifically, a feature enhancement module is proposed to suppress the matching noise caused by inter-class local similarity and enhance the intra-class relevance in the naive correlation. In addition, we propose a novel correlation reconstruction module that encodes extra correspondence relations between foreground and background and multi-scale context semantic features, significantly boosting the encoder to capture a reliable matching pattern. Experiments on PASCAL-$5^i$ and COCO-$20^i$ datasets demonstrate that our proposed FECANet leads to remarkable improvement compared to previous state-of-the-arts, demonstrating its effectiveness.