 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Survey on Actionable Knowledge
Jan 23, 2023
Actionable Knowledge Discovery (AKD) is a crucial aspect of data mining that is gaining popularity and being applied in a wide range of domains. This is because AKD can extract valuable insights and information, also known as knowledge, from large datasets. The goal of this paper is to examine different research studies that focus on various domains and have different objectives. The paper will review and discuss the methods used in these studies in detail. AKD is a process of identifying and extracting actionable insights from data, which can be used to make informed decisions and improve business outcomes. It is a powerful tool for uncovering patterns and trends in data that can be used for various applications such as customer relationship management, marketing, and fraud detection. The research studies reviewed in this paper will explore different techniques and approaches for AKD in different domains, such as healthcare, finance, and telecommunications. The paper will provide a thorough analysis of the current state of AKD in the field and will review the main methods used by various research studies. Additionally, the paper will evaluate the advantages and disadvantages of each method and will discuss any novel or new solutions presented in the field. Overall, this paper aims to provide a comprehensive overview of the methods and techniques used in AKD and the impact they have on different domains.
Follow the Timeline! Generating Abstractive and Extractive Timeline Summary in Chronological Order
Jan 02, 2023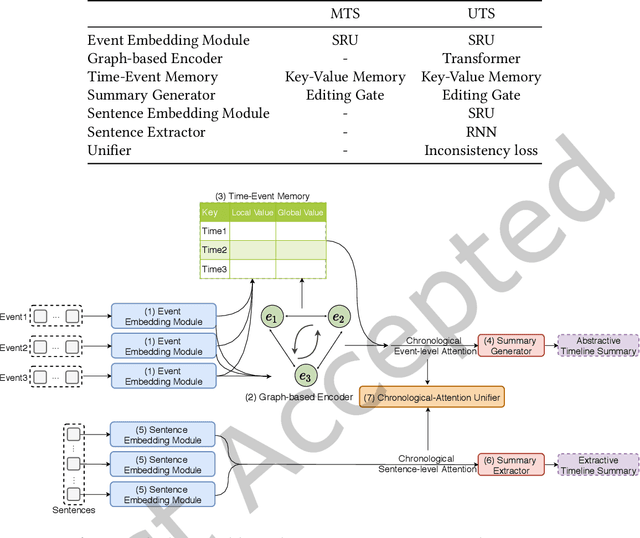
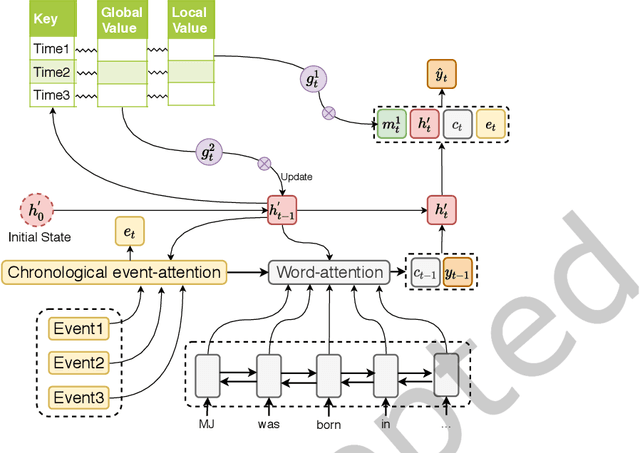
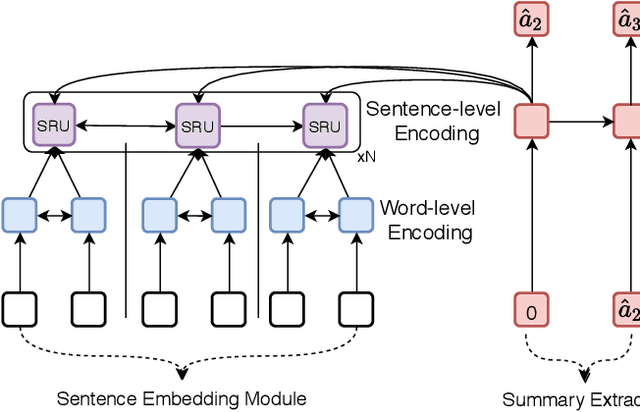
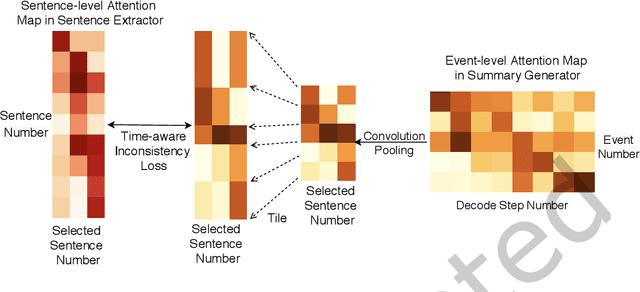
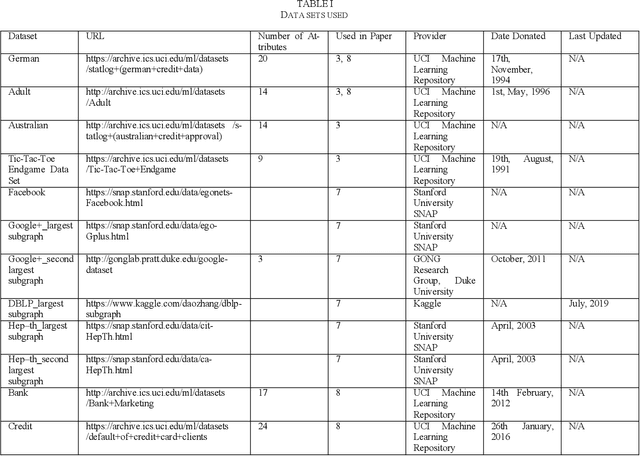
Nowadays, time-stamped web documents related to a general news query floods spread throughout the Internet, and timeline summarization targets concisely summarizing the evolution trajectory of events along the timeline. Unlike traditional document summarization, timeline summarization needs to model the time series information of the input events and summarize important events in chronological order. To tackle this challenge, in this paper, we propose a Unified Timeline Summarizer (UTS) that can generate abstractive and extractive timeline summaries in time order. Concretely, in the encoder part, we propose a graph-based event encoder that relates multiple events according to their content dependency and learns a global representation of each event. In the decoder part, to ensure the chronological order of the abstractive summary, we propose to extract the feature of event-level attention in its generation process with sequential information remained and use it to simulate the evolutionary attention of the ground truth summary. The event-level attention can also be used to assist in extracting summary, where the extracted summary also comes in time sequence. We augment the previous Chinese large-scale timeline summarization dataset and collect a new English timeline dataset. Extensive experiments conducted on these datasets and on the out-of-domain Timeline 17 dataset show that UTS achieves state-of-the-art performance in terms of both automatic and human evaluations.
EVM-CNN: Real-Time Contactless Heart Rate Estimation from Facial Video
Dec 25, 2022
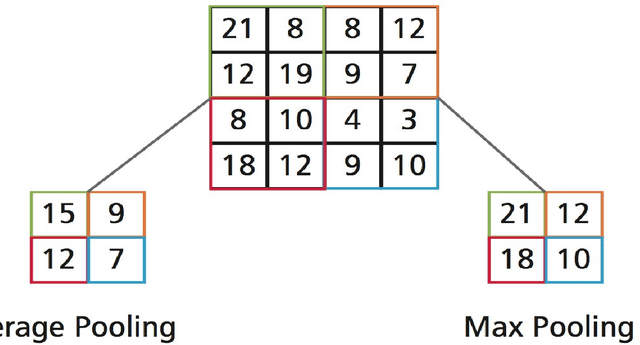
With the increase in health consciousness, noninvasive body monitoring has aroused interest among researchers. As one of the most important pieces of physiological information, researchers have remotely estimated the heart rate (HR) from facial videos in recent years. Although progress has been made over the past few years, there are still some limitations, like the processing time increasing with accuracy and the lack of comprehensive and challenging datasets for use and comparison. Recently, it was shown that HR information can be extracted from facial videos by spatial decomposition and temporal filtering. Inspired by this, a new framework is introduced in this paper to remotely estimate the HR under realistic conditions by combining spatial and temporal filtering and a convolutional neural network. Our proposed approach shows better performance compared with the benchmark on the MMSE-HR dataset in terms of both the average HR estimation and short-time HR estimation. High consistency in short-time HR estimation is observed between our method and the ground truth.
Information-theoretic Online Memory Selection for Continual Learning
Apr 10, 2022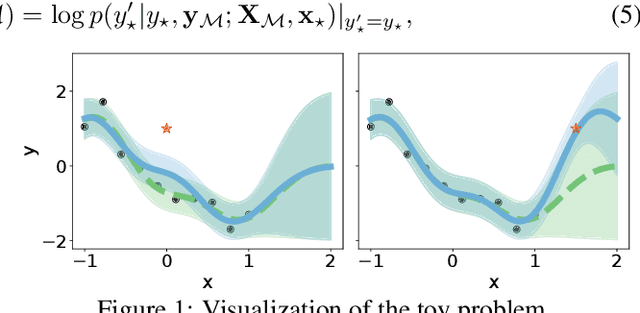
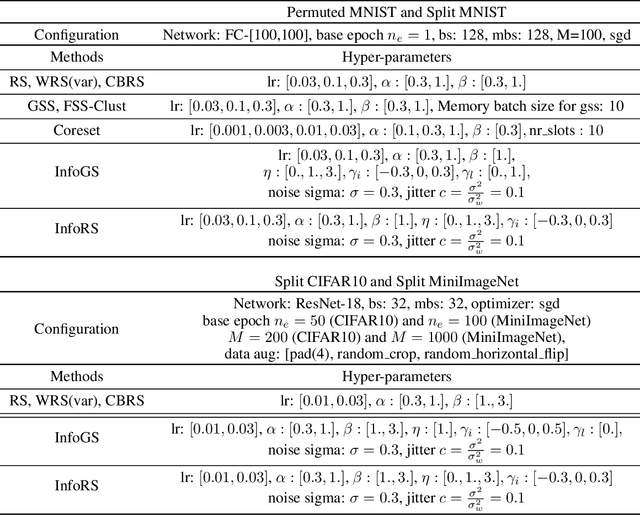
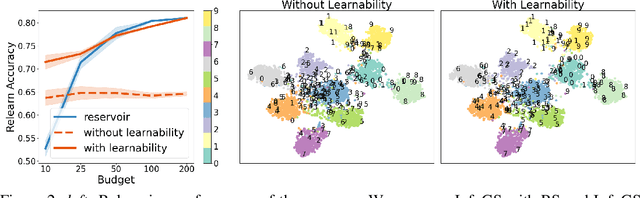
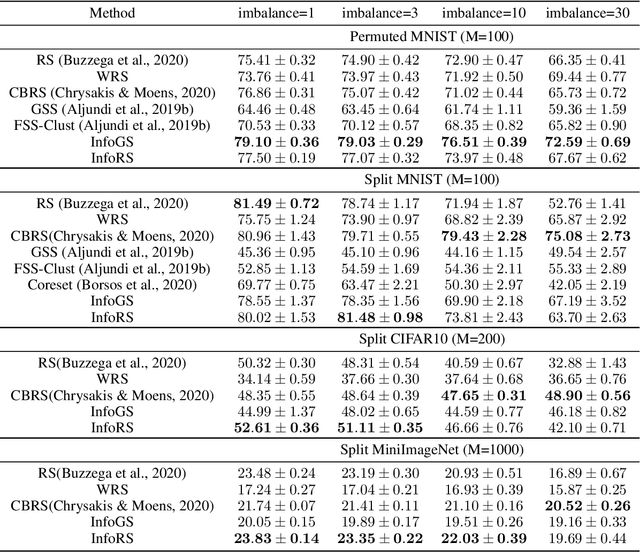
A challenging problem in task-free continual learning is the online selection of a representative replay memory from data streams. In this work, we investigate the online memory selection problem from an information-theoretic perspective. To gather the most information, we propose the \textit{surprise} and the \textit{learnability} criteria to pick informative points and to avoid outliers. We present a Bayesian model to compute the criteria efficiently by exploiting rank-one matrix structures. We demonstrate that these criteria encourage selecting informative points in a greedy algorithm for online memory selection. Furthermore, by identifying the importance of \textit{the timing to update the memory}, we introduce a stochastic information-theoretic reservoir sampler (InfoRS), which conducts sampling among selective points with high information. Compared to reservoir sampling, InfoRS demonstrates improved robustness against data imbalance. Finally, empirical performances over continual learning benchmarks manifest its efficiency and efficacy.
Aerial Transportation Control of Suspended Payloads with Multiple Agents
Jan 26, 2023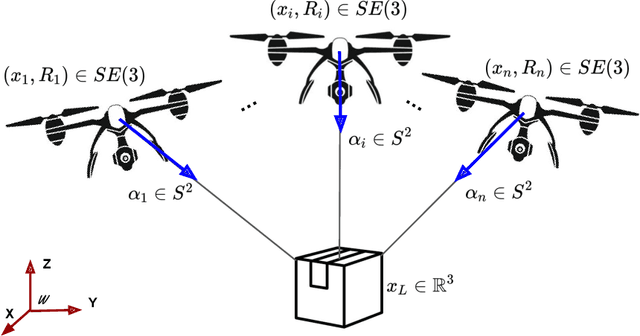

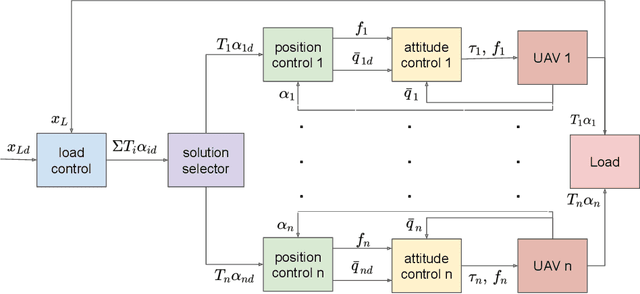
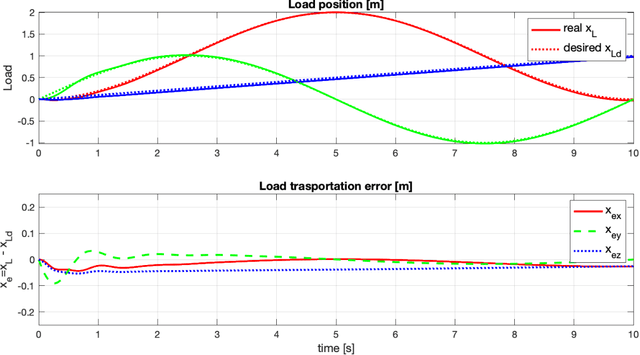
In this paper we address the control problem of aerial cable suspended load transportation, using multiple Unmanned Aerial Vehicles (UAVs). First, the dynamical model of the coupled system is obtained using the Newton-Euler formalism, for "n" UAVs transporting a load, where the cables are supposed to be rigid and mass-less. The control problem is stated as a trajectory tracking directly on the load. To do so, a hierarchical control scheme is proposed based on the attractive ellipsoid method, where a virtual controller is calculated for tracking the position of the load, with this, the desired position for each vehicle along with their desired cable tensions are estimated, and used to compute the virtual controller for the position of each vehicle. This results in an underdetermined system, where an infinite number of drones' configurations comply with the desired load position, thus additional constrains can be imposed to obtain an unique solution. Furthermore, this information is used to compute the attitude reference for the vehicles, which are feed to a quaternion based attitude control. The stability analysis, using an energy-like function, demonstrated the practical stability of the system, it is that all the error signals are attracted and contained in an invariant set. Hence, the proposed scheme assures that, given well posed initial conditions, the closed-loop system guarantees the trajectory tracking of the desired position on the load with bounded errors. The proposed control strategy was evaluated in numerical simulations for three agents following a smooth desired trajectory on the load, showing good performance.
Computability of Optimizers
Jan 15, 2023Optimization problems are a staple of today's scientific and technical landscape. However, at present, solvers of such problems are almost exclusively run on digital hardware. Using Turing machines as a mathematical model for any type of digital hardware, in this paper, we analyze fundamental limitations of this conceptual approach of solving optimization problems. Since in most applications, the optimizer itself is of significantly more interest than the optimal value of the corresponding function, we will focus on computability of the optimizer. In fact, we will show that in various situations the optimizer is unattainable on Turing machines and consequently on digital computers. Moreover, even worse, there does not exist a Turing machine, which approximates the optimizer itself up to a certain constant error. We prove such results for a variety of well-known problems from very different areas, including artificial intelligence, financial mathematics, and information theory, often deriving the even stronger result that such problems are not Banach-Mazur computable, also not even in an approximate sense.
A Marker-based Neural Network System for Extracting Social Determinants of Health
Dec 24, 2022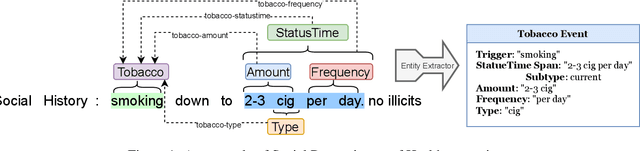
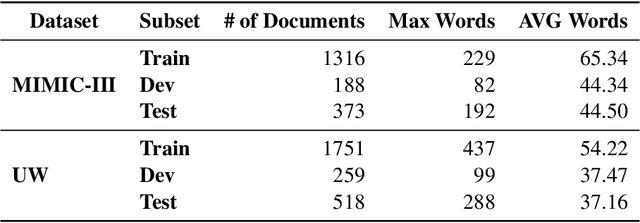
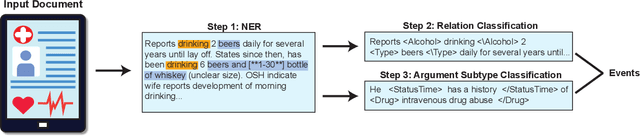
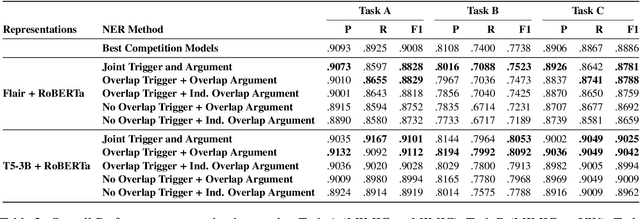
Objective. The impact of social determinants of health (SDoH) on patients' healthcare quality and the disparity is well-known. Many SDoH items are not coded in structured forms in electronic health records. These items are often captured in free-text clinical notes, but there are limited methods for automatically extracting them. We explore a multi-stage pipeline involving named entity recognition (NER), relation classification (RC), and text classification methods to extract SDoH information from clinical notes automatically. Materials and Methods. The study uses the N2C2 Shared Task data, which was collected from two sources of clinical notes: MIMIC-III and University of Washington Harborview Medical Centers. It contains 4480 social history sections with full annotation for twelve SDoHs. In order to handle the issue of overlapping entities, we developed a novel marker-based NER model. We used it in a multi-stage pipeline to extract SDoH information from clinical notes. Results. Our marker-based system outperformed the state-of-the-art span-based models at handling overlapping entities based on the overall Micro-F1 score performance. It also achieved state-of-the-art performance compared to the shared task methods. Conclusion. The major finding of this study is that the multi-stage pipeline effectively extracts SDoH information from clinical notes. This approach can potentially improve the understanding and tracking of SDoHs in clinical settings. However, error propagation may be an issue, and further research is needed to improve the extraction of entities with complex semantic meanings and low-resource entities using external knowledge.
STIP: A SpatioTemporal Information-Preserving and Perception-Augmented Model for High-Resolution Video Prediction
Jun 09, 2022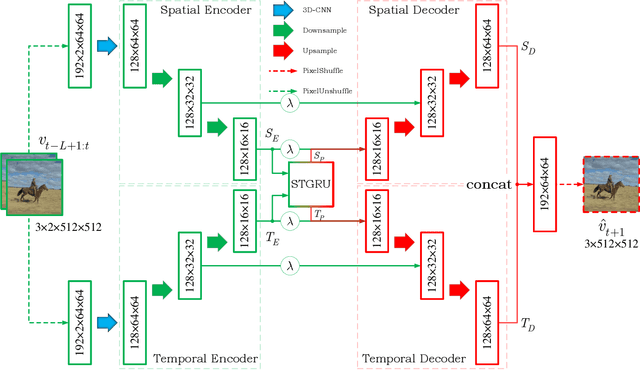
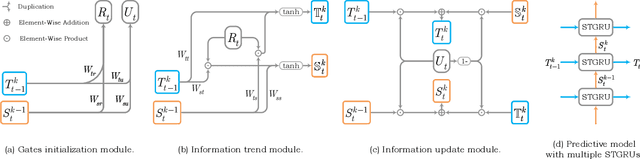
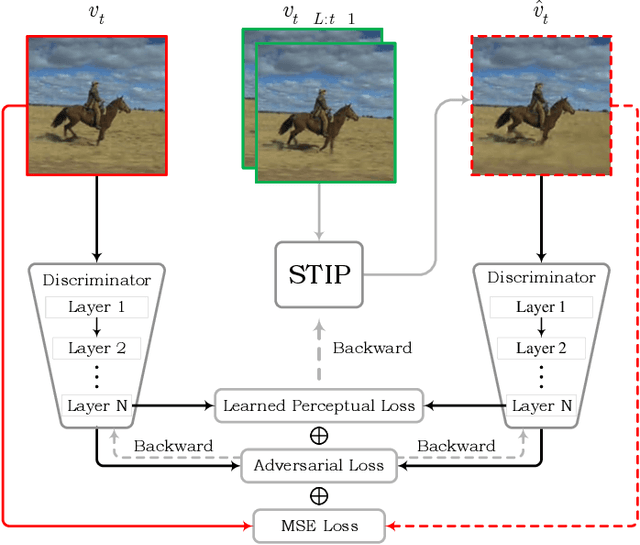

Although significant achievements have been achieved by recurrent neural network (RNN) based video prediction methods, their performance in datasets with high resolutions is still far from satisfactory because of the information loss problem and the perception-insensitive mean square error (MSE) based loss functions. In this paper, we propose a Spatiotemporal Information-Preserving and Perception-Augmented Model (STIP) to solve the above two problems. To solve the information loss problem, the proposed model aims to preserve the spatiotemporal information for videos during the feature extraction and the state transitions, respectively. Firstly, a Multi-Grained Spatiotemporal Auto-Encoder (MGST-AE) is designed based on the X-Net structure. The proposed MGST-AE can help the decoders recall multi-grained information from the encoders in both the temporal and spatial domains. In this way, more spatiotemporal information can be preserved during the feature extraction for high-resolution videos. Secondly, a Spatiotemporal Gated Recurrent Unit (STGRU) is designed based on the standard Gated Recurrent Unit (GRU) structure, which can efficiently preserve spatiotemporal information during the state transitions. The proposed STGRU can achieve more satisfactory performance with a much lower computation load compared with the popular Long Short-Term (LSTM) based predictive memories. Furthermore, to improve the traditional MSE loss functions, a Learned Perceptual Loss (LP-loss) is further designed based on the Generative Adversarial Networks (GANs), which can help obtain a satisfactory trade-off between the objective quality and the perceptual quality. Experimental results show that the proposed STIP can predict videos with more satisfactory visual quality compared with a variety of state-of-the-art methods. Source code has been available at \url{https://github.com/ZhengChang467/STIPHR}.
Penalised regression with multiple sources of prior effects
Dec 16, 2022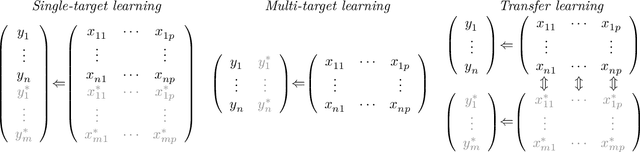
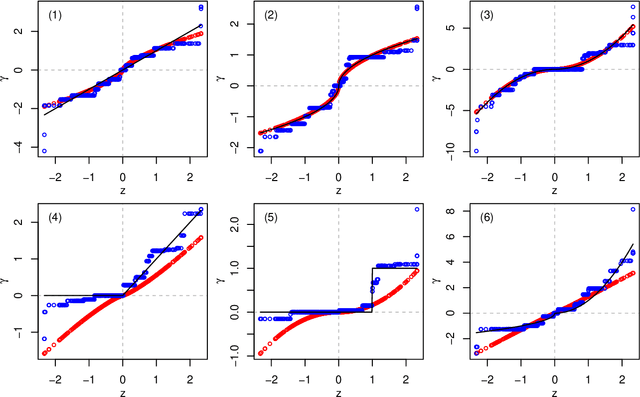
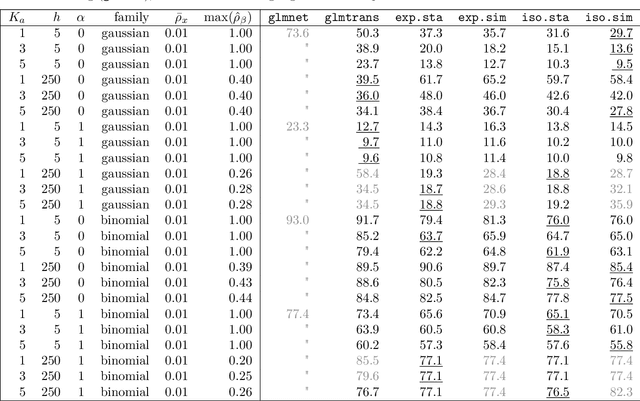
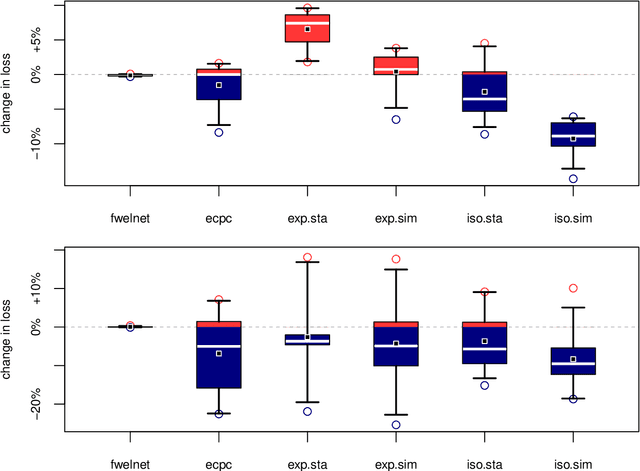
In many high-dimensional prediction or classification tasks, complementary data on the features are available, e.g. prior biological knowledge on (epi)genetic markers. Here we consider tasks with numerical prior information that provide an insight into the importance (weight) and the direction (sign) of the feature effects, e.g. regression coefficients from previous studies. We propose an approach for integrating multiple sources of such prior information into penalised regression. If suitable co-data are available, this improves the predictive performance, as shown by simulation and application. The proposed method is implemented in the R package `transreg' (https://github.com/lcsb-bds/transreg).
An advanced YOLOv3 method for small object detection
Dec 06, 2022
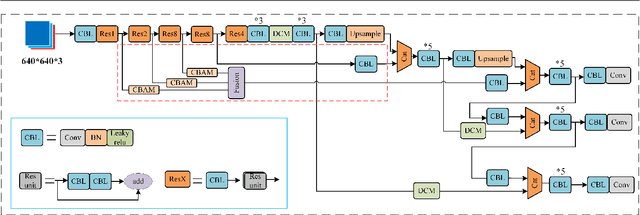
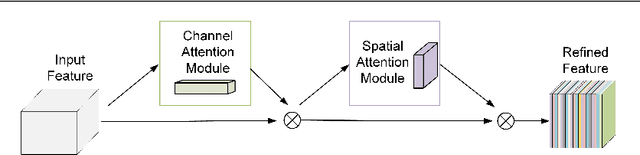
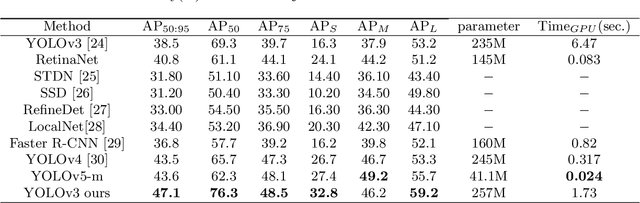
In recent years, object detection has achieved a very large performance improvement, but the detection result of small objects is still not very satisfactory. This work proposes a strategy based on feature fusion and dilated convolution that employs dilated convolution to broaden the receptive field of feature maps at various scales in order to address this issue. On the one hand, it can improve the detection accuracy of larger objects. On the other hand, it provides more contextual information for small objects, which is beneficial to improving the detection accuracy of small objects. The shallow semantic information of small objects is obtained by filtering out the noise in the feature map, and the feature information of more small objects is preserved by using multi-scale fusion feature module and attention mechanism. The fusion of these shallow feature information and deep semantic information can generate richer feature maps for small object detection. Experiments show that this method can have higher accuracy than the traditional YOLOv3 network in the detection of small objects and occluded objects. In addition, we achieve 32.8\% Mean Average Precision on the detection of small objects on MS COCO2017 test set. For 640*640 input, this method has 88.76\% mAP on the PASCAL VOC2012 dataset.