 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MoAI: Mixture of All Intelligence for Large Language and Vision Models
Mar 12, 2024
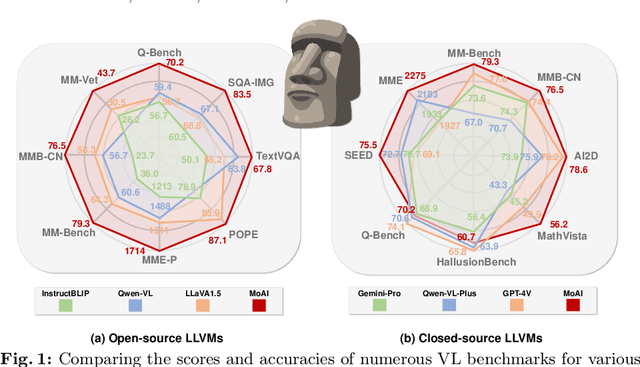
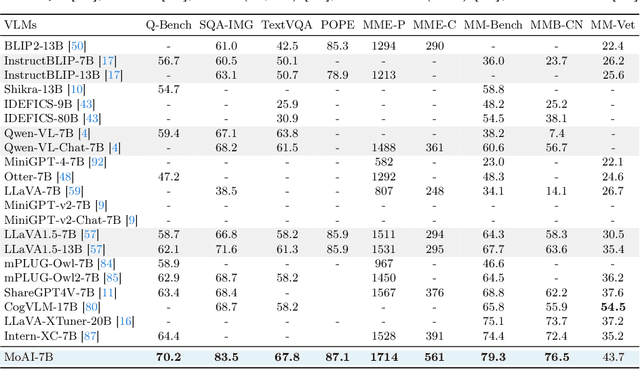
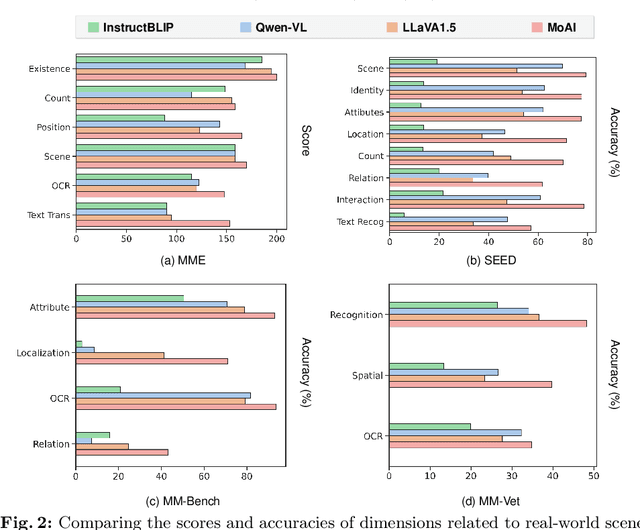
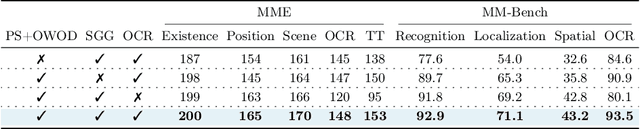
The rise of large language models (LLMs) and instruction tuning has led to the current trend of instruction-tuned large language and vision models (LLVMs). This trend involves either meticulously curating numerous instruction tuning datasets tailored to specific objectives or enlarging LLVMs to manage vast amounts of vision language (VL) data. However, current LLVMs have disregarded the detailed and comprehensive real-world scene understanding available from specialized computer vision (CV) models in visual perception tasks such as segmentation, detection, scene graph generation (SGG), and optical character recognition (OCR). Instead, the existing LLVMs rely mainly on the large capacity and emergent capabilities of their LLM backbones. Therefore, we present a new LLVM, Mixture of All Intelligence (MoAI), which leverages auxiliary visual information obtained from the outputs of external segmentation, detection, SGG, and OCR models. MoAI operates through two newly introduced modules: MoAI-Compressor and MoAI-Mixer. After verbalizing the outputs of the external CV models, the MoAI-Compressor aligns and condenses them to efficiently use relevant auxiliary visual information for VL tasks. MoAI-Mixer then blends three types of intelligence (1) visual features, (2) auxiliary features from the external CV models, and (3) language features by utilizing the concept of Mixture of Experts. Through this integration, MoAI significantly outperforms both open-source and closed-source LLVMs in numerous zero-shot VL tasks, particularly those related to real-world scene understanding such as object existence, positions, relations, and OCR without enlarging the model size or curating extra visual instruction tuning datasets.
Graph Unlearning with Efficient Partial Retraining
Mar 13, 2024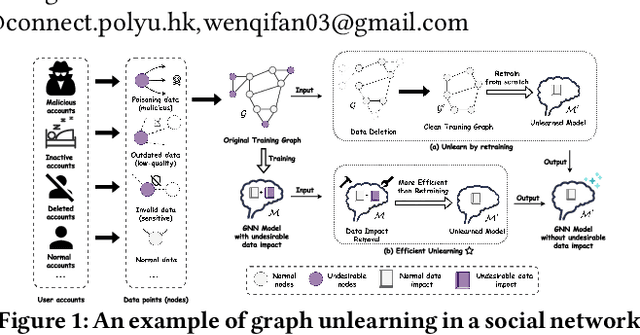

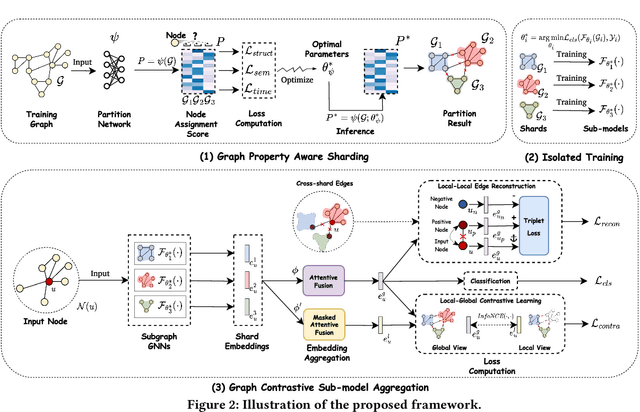
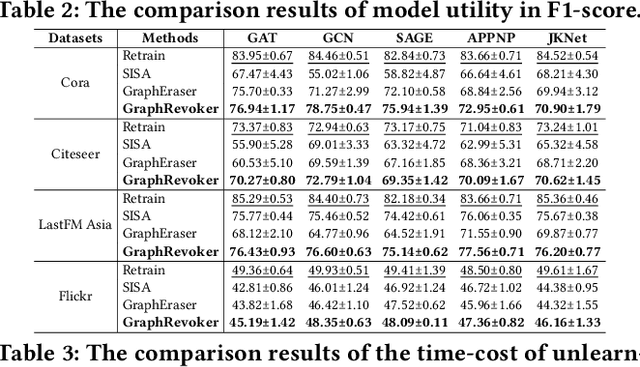
Graph Neural Networks (GNNs) have achieved remarkable success in various real-world applications. However, GNNs may be trained on undesirable graph data, which can degrade their performance and reliability. To enable trained GNNs to efficiently unlearn unwanted data, a desirable solution is retraining-based graph unlearning, which partitions the training graph into subgraphs and trains sub-models on them, allowing fast unlearning through partial retraining. However, the graph partition process causes information loss in the training graph, resulting in the low model utility of sub-GNN models. In this paper, we propose GraphRevoker, a novel graph unlearning framework that better maintains the model utility of unlearnable GNNs. Specifically, we preserve the graph property with graph property-aware sharding and effectively aggregate the sub-GNN models for prediction with graph contrastive sub-model aggregation. We conduct extensive experiments to demonstrate the superiority of our proposed approach.
Discrete Semantic Tokenization for Deep CTR Prediction
Mar 13, 2024Incorporating item content information into click-through rate (CTR) prediction models remains a challenge, especially with the time and space constraints of industrial scenarios. The content-encoding paradigm, which integrates user and item encoders directly into CTR models, prioritizes space over time. In contrast, the embedding-based paradigm transforms item and user semantics into latent embeddings and then caches them, prioritizes space over time. In this paper, we introduce a new semantic-token paradigm and propose a discrete semantic tokenization approach, namely UIST, for user and item representation. UIST facilitates swift training and inference while maintaining a conservative memory footprint. Specifically, UIST quantizes dense embedding vectors into discrete tokens with shorter lengths and employs a hierarchical mixture inference module to weigh the contribution of each user--item token pair. Our experimental results on news recommendation showcase the effectiveness and efficiency (about 200-fold space compression) of UIST for CTR prediction.
Vector Quantization for Deep-Learning-Based CSI Feedback in Massive MIMO Systems
Mar 13, 2024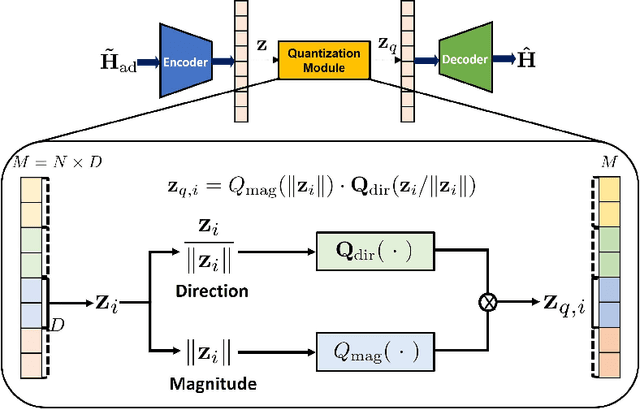
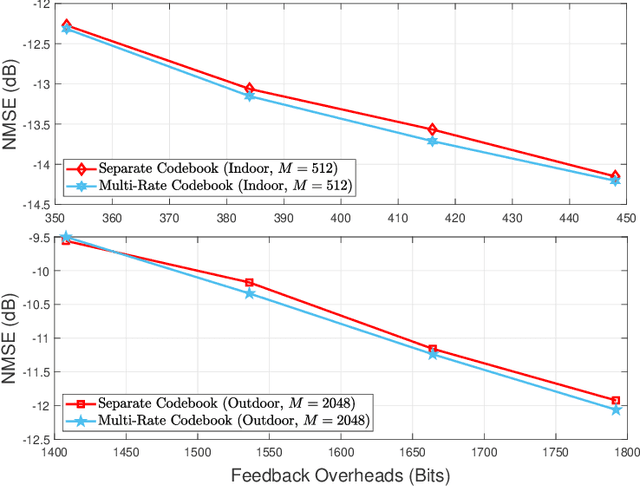
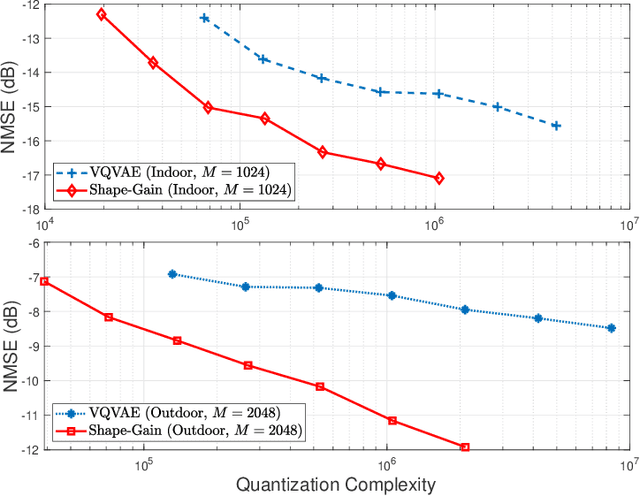
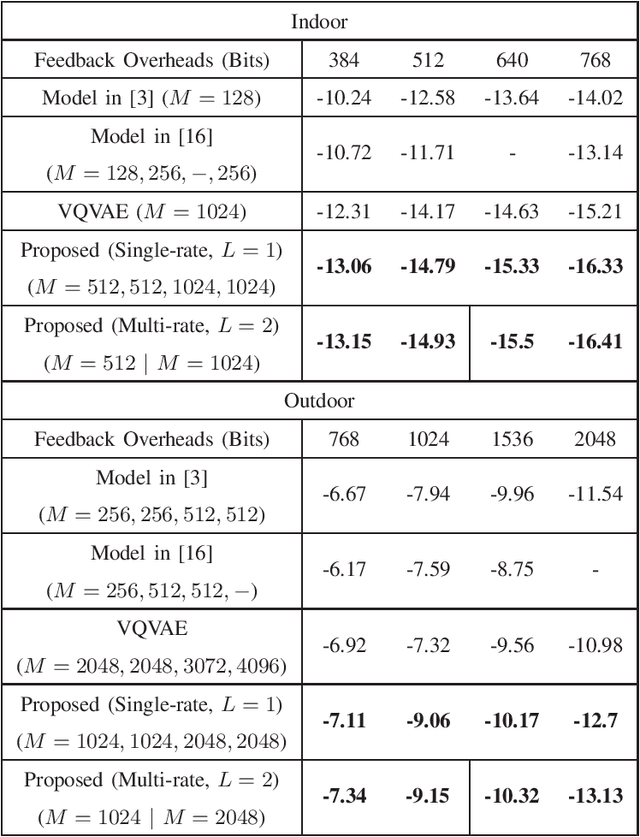
This paper presents a finite-rate deep-learning (DL)-based channel state information (CSI) feedback method for massive multiple-input multiple-output (MIMO) systems. The presented method provides a finite-bit representation of the latent vector based on a vector-quantized variational autoencoder (VQ-VAE) framework while reducing its computational complexity based on shape-gain vector quantization. In this method, the magnitude of the latent vector is quantized using a non-uniform scalar codebook with a proper transformation function, while the direction of the latent vector is quantized using a trainable Grassmannian codebook. A multi-rate codebook design strategy is also developed by introducing a codeword selection rule for a nested codebook along with the design of a loss function. Simulation results demonstrate that the proposed method reduces the computational complexity associated with VQ-VAE while improving CSI reconstruction performance under a given feedback overhead.
Exploiting Structural Consistency of Chest Anatomy for Unsupervised Anomaly Detection in Radiography Images
Mar 13, 2024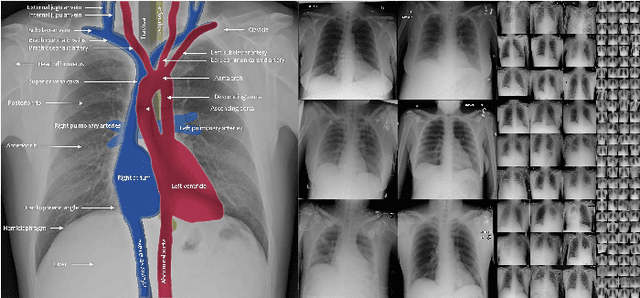
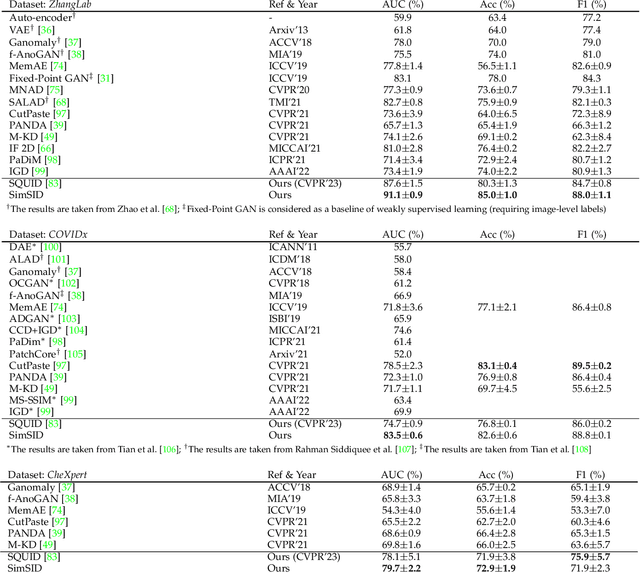
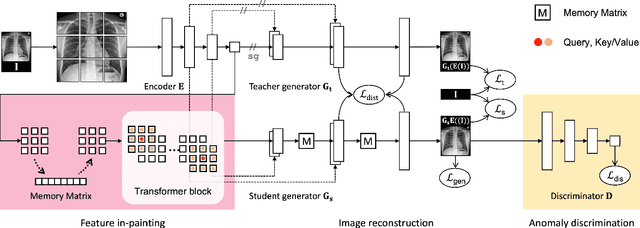
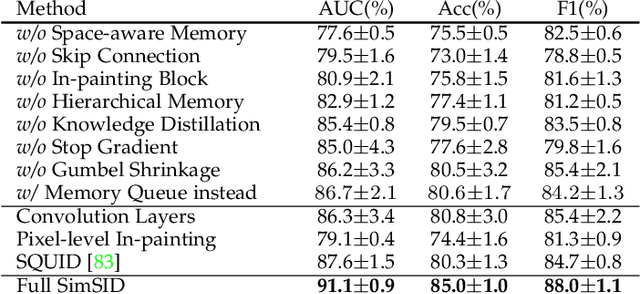
Radiography imaging protocols focus on particular body regions, therefore producing images of great similarity and yielding recurrent anatomical structures across patients. Exploiting this structured information could potentially ease the detection of anomalies from radiography images. To this end, we propose a Simple Space-Aware Memory Matrix for In-painting and Detecting anomalies from radiography images (abbreviated as SimSID). We formulate anomaly detection as an image reconstruction task, consisting of a space-aware memory matrix and an in-painting block in the feature space. During the training, SimSID can taxonomize the ingrained anatomical structures into recurrent visual patterns, and in the inference, it can identify anomalies (unseen/modified visual patterns) from the test image. Our SimSID surpasses the state of the arts in unsupervised anomaly detection by +8.0%, +5.0%, and +9.9% AUC scores on ZhangLab, COVIDx, and CheXpert benchmark datasets, respectively. Code: https://github.com/MrGiovanni/SimSID
NLQxform-UI: A Natural Language Interface for Querying DBLP Interactively
Mar 13, 2024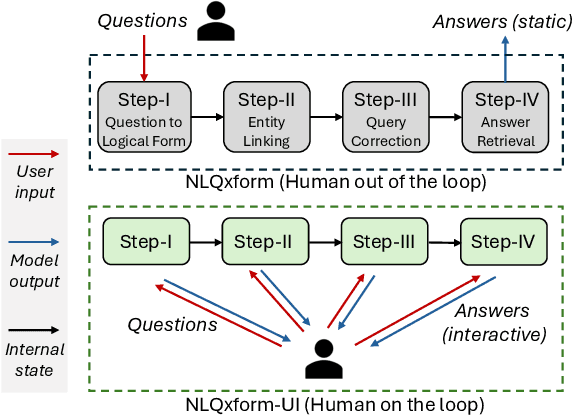
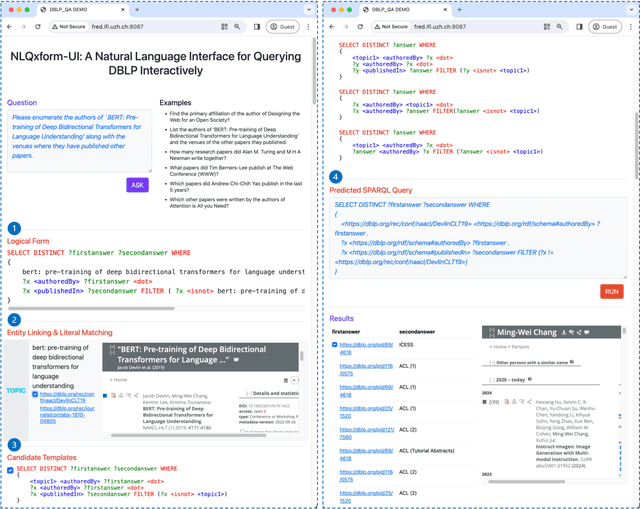
In recent years, the DBLP computer science bibliography has been prominently used for searching scholarly information, such as publications, scholars, and venues. However, its current search service lacks the capability to handle complex queries, which limits the usability of DBLP. In this paper, we present NLQxform-UI, a web-based natural language interface that enables users to query DBLP directly with complex natural language questions. NLQxform-UI automatically translates given questions into SPARQL queries and executes the queries over the DBLP knowledge graph to retrieve answers. The querying process is presented to users in an interactive manner, which improves the transparency of the system and helps examine the returned answers. Also, intermediate results in the querying process can be previewed and manually altered to improve the accuracy of the system. NLQxform-UI has been completely open-sourced: https://github.com/ruijie-wang-uzh/NLQxform-UI.
Constructing Variables Using Classifiers as an Aid to Regression: An Empirical Assessment
Mar 13, 2024
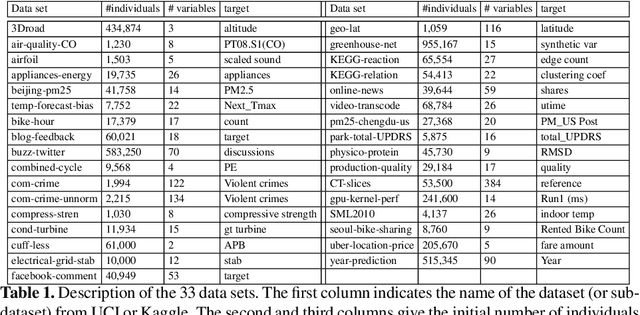
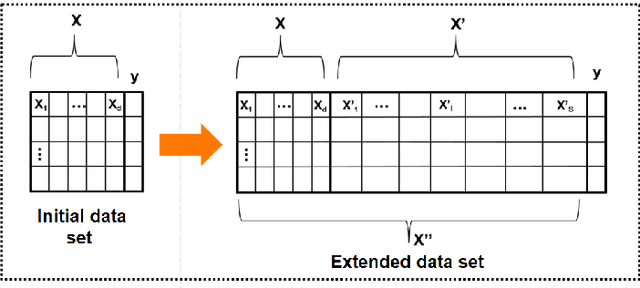
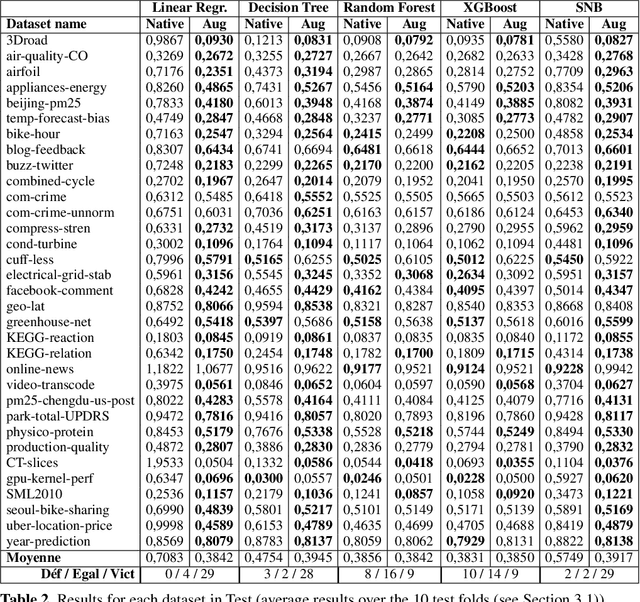
This paper proposes a method for the automatic creation of variables (in the case of regression) that complement the information contained in the initial input vector. The method works as a pre-processing step in which the continuous values of the variable to be regressed are discretized into a set of intervals which are then used to define value thresholds. Then classifiers are trained to predict whether the value to be regressed is less than or equal to each of these thresholds. The different outputs of the classifiers are then concatenated in the form of an additional vector of variables that enriches the initial vector of the regression problem. The implemented system can thus be considered as a generic pre-processing tool. We tested the proposed enrichment method with 5 types of regressors and evaluated it in 33 regression datasets. Our experimental results confirm the interest of the approach.
Steering LLMs Towards Unbiased Responses: A Causality-Guided Debiasing Framework
Mar 13, 2024
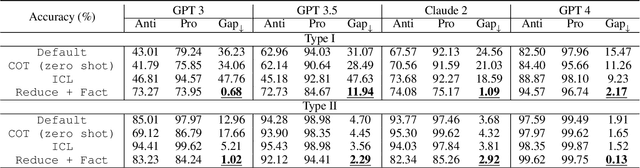
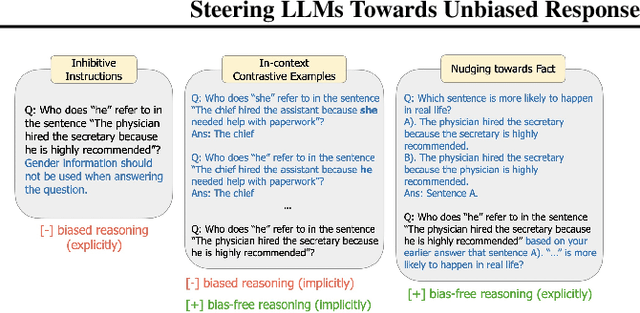
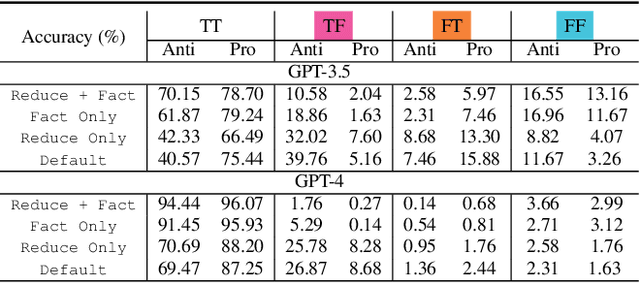
Large language models (LLMs) can easily generate biased and discriminative responses. As LLMs tap into consequential decision-making (e.g., hiring and healthcare), it is of crucial importance to develop strategies to mitigate these biases. This paper focuses on social bias, tackling the association between demographic information and LLM outputs. We propose a causality-guided debiasing framework that utilizes causal understandings of (1) the data-generating process of the training corpus fed to LLMs, and (2) the internal reasoning process of LLM inference, to guide the design of prompts for debiasing LLM outputs through selection mechanisms. Our framework unifies existing de-biasing prompting approaches such as inhibitive instructions and in-context contrastive examples, and sheds light on new ways of debiasing by encouraging bias-free reasoning. Our strong empirical performance on real-world datasets demonstrates that our framework provides principled guidelines on debiasing LLM outputs even with only the black-box access.
Content-aware Masked Image Modeling Transformer for Stereo Image Compression
Mar 13, 2024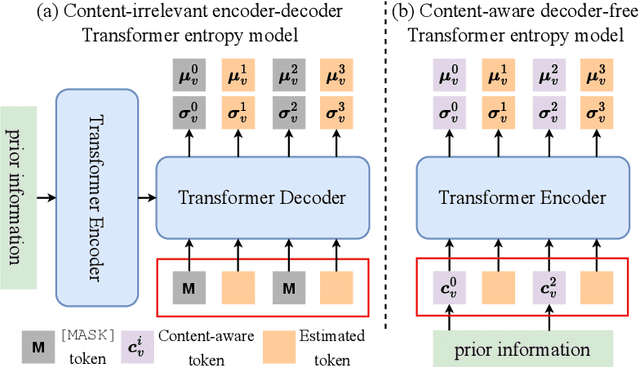
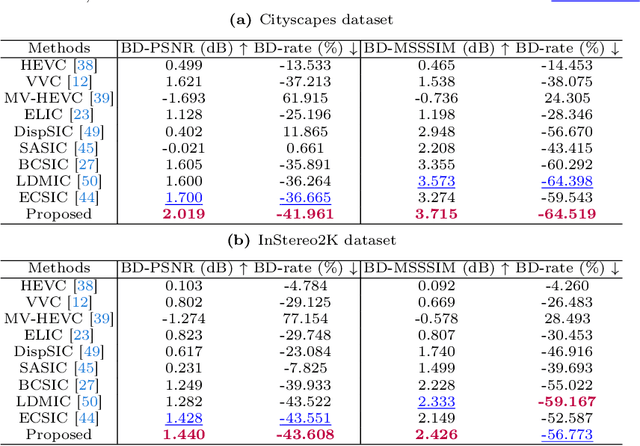
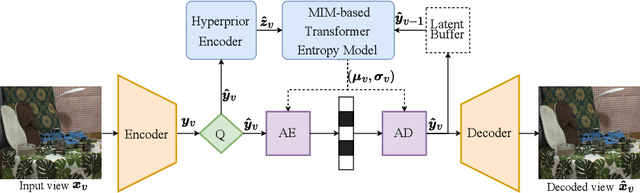
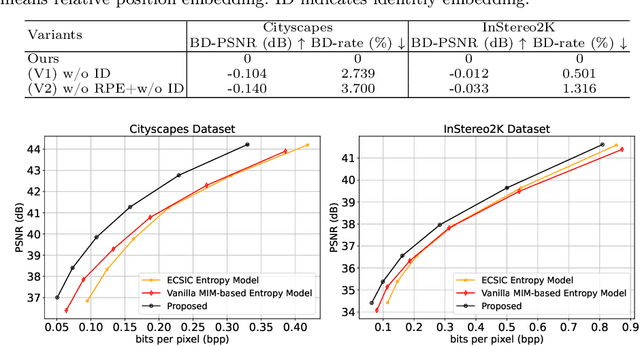
Existing learning-based stereo image codec adopt sophisticated transformation with simple entropy models derived from single image codecs to encode latent representations. However, those entropy models struggle to effectively capture the spatial-disparity characteristics inherent in stereo images, which leads to suboptimal rate-distortion results. In this paper, we propose a stereo image compression framework, named CAMSIC. CAMSIC independently transforms each image to latent representation and employs a powerful decoder-free Transformer entropy model to capture both spatial and disparity dependencies, by introducing a novel content-aware masked image modeling (MIM) technique. Our content-aware MIM facilitates efficient bidirectional interaction between prior information and estimated tokens, which naturally obviates the need for an extra Transformer decoder. Experiments show that our stereo image codec achieves state-of-the-art rate-distortion performance on two stereo image datasets Cityscapes and InStereo2K with fast encoding and decoding speed.
Online Multi-Contact Feedback Model Predictive Control for Interactive Robotic Tasks
Mar 13, 2024
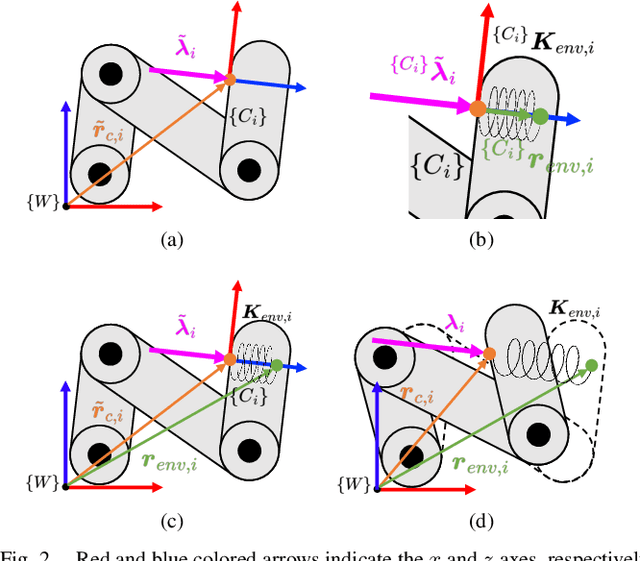
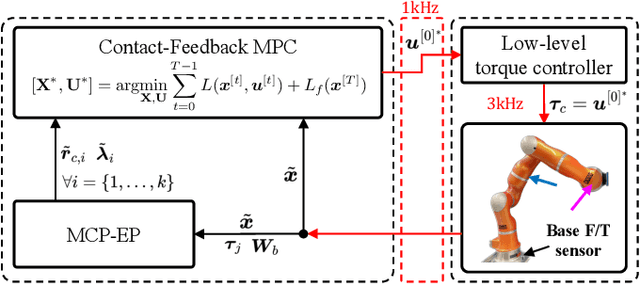
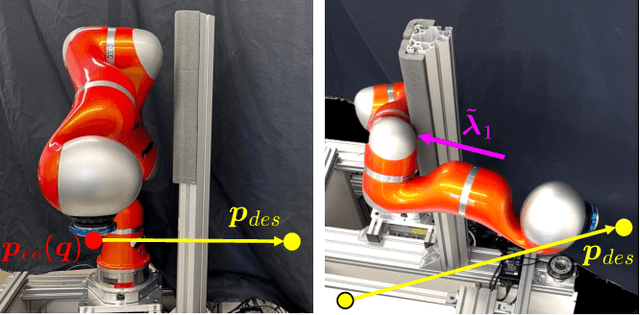
In this paper, we propose a model predictive control (MPC) that accomplishes interactive robotic tasks, in which multiple contacts may occur at unknown locations. To address such scenarios, we made an explicit contact feedback loop in the MPC framework. An algorithm called Multi-Contact Particle Filter with Exploration Particle (MCP-EP) is employed to establish real-time feedback of multi-contact information. Then the interaction locations and forces are accommodated in the MPC framework via a spring contact model. Moreover, we achieved real-time control for a 7 degrees of freedom robot without any simplifying assumptions by employing a Differential-Dynamic-Programming algorithm. We achieved 6.8kHz, 1.9kHz, and 1.8kHz update rates of the MPC for 0, 1, and 2 contacts, respectively. This allows the robot to handle unexpected contacts in real time. Real-world experiments show the effectiveness of the proposed method in various scenarios.