 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Investigation of Japanese PnG BERT language model in text-to-speech synthesis for pitch accent language
Dec 16, 2022

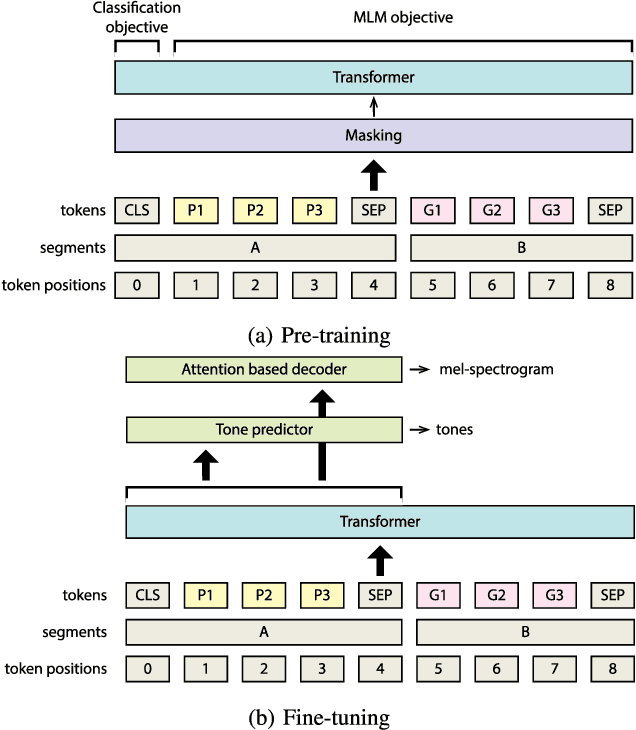
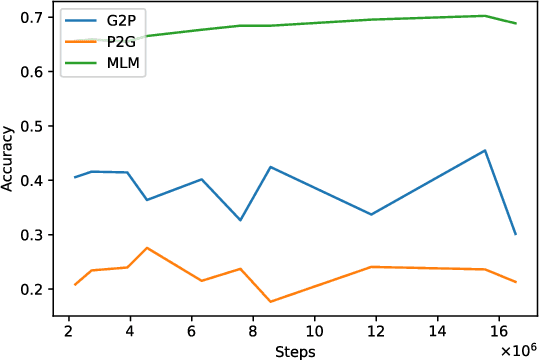
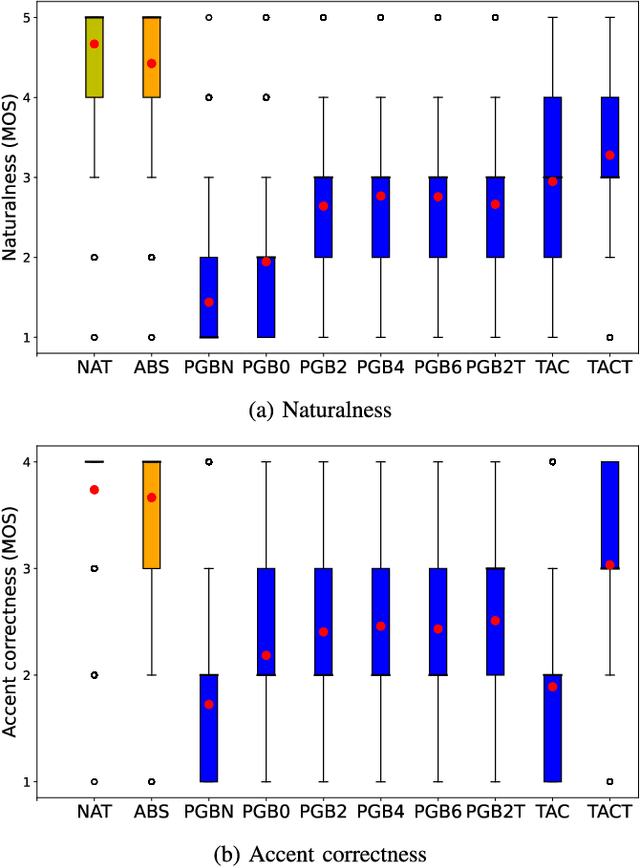
End-to-end text-to-speech synthesis (TTS) can generate highly natural synthetic speech from raw text. However, rendering the correct pitch accents is still a challenging problem for end-to-end TTS. To tackle the challenge of rendering correct pitch accent in Japanese end-to-end TTS, we adopt PnG~BERT, a self-supervised pretrained model in the character and phoneme domain for TTS. We investigate the effects of features captured by PnG~BERT on Japanese TTS by modifying the fine-tuning condition to determine the conditions helpful inferring pitch accents. We manipulate content of PnG~BERT features from being text-oriented to speech-oriented by changing the number of fine-tuned layers during TTS. In addition, we teach PnG~BERT pitch accent information by fine-tuning with tone prediction as an additional downstream task. Our experimental results show that the features of PnG~BERT captured by pretraining contain information helpful inferring pitch accent, and PnG~BERT outperforms baseline Tacotron on accent correctness in a listening test.
Common Practices and Taxonomy in Deep Multi-view Fusion for Remote Sensing Applications
Dec 20, 2022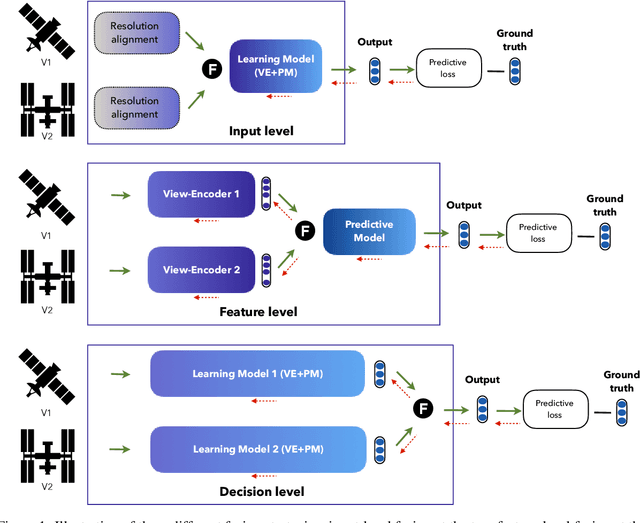

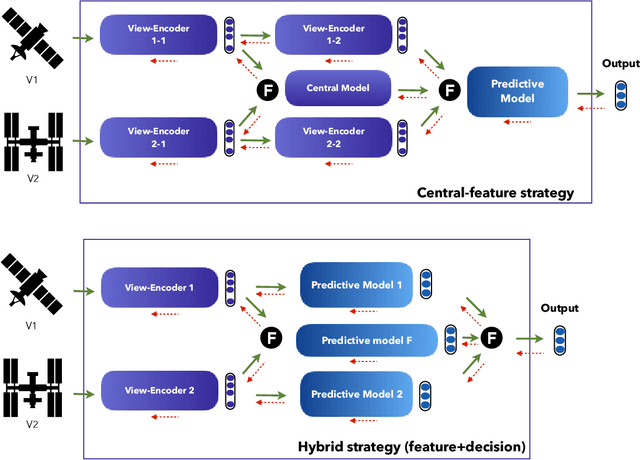
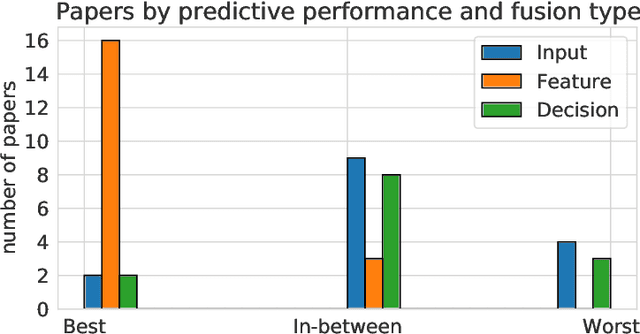
The advances in remote sensing technologies have boosted applications for Earth observation. These technologies provide multiple observations or views with different levels of information. They might contain static or temporary views with different levels of resolution, in addition to having different types and amounts of noise due to sensor calibration or deterioration. A great variety of deep learning models have been applied to fuse the information from these multiple views, known as deep multi-view or multi-modal fusion learning. However, the approaches in the literature vary greatly since different terminology is used to refer to similar concepts or different illustrations are given to similar techniques. This article gathers works on multi-view fusion for Earth observation by focusing on the common practices and approaches used in the literature. We summarize and structure insights from several different publications concentrating on unifying points and ideas. In this manuscript, we provide a harmonized terminology while at the same time mentioning the various alternative terms that are used in literature. The topics covered by the works reviewed focus on supervised learning with the use of neural network models. We hope this review, with a long list of recent references, can support future research and lead to a unified advance in the area.
Scheduling with Predictions
Dec 20, 2022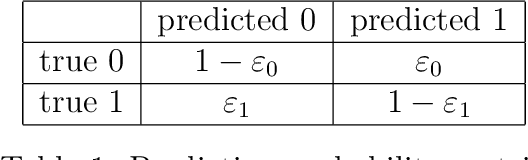
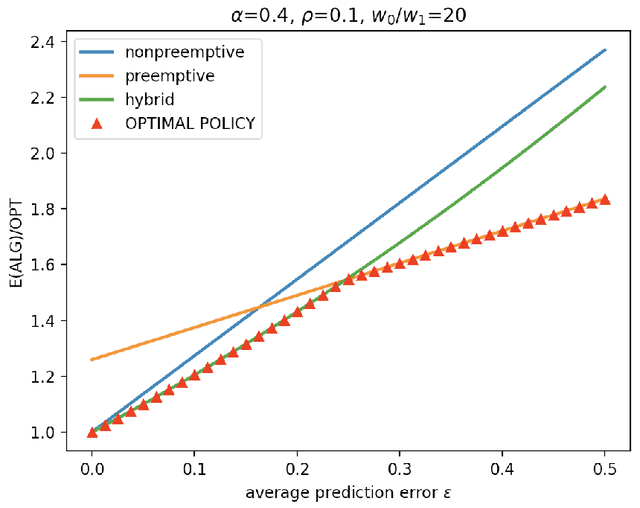

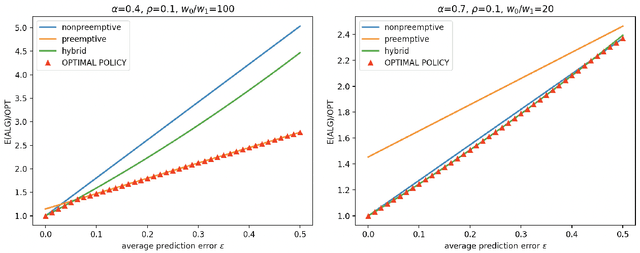
There is significant interest in deploying machine learning algorithms for diagnostic radiology, as modern learning techniques have made it possible to detect abnormalities in medical images within minutes. While machine-assisted diagnoses cannot yet reliably replace human reviews of images by a radiologist, they could inform prioritization rules for determining the order by which to review patient cases so that patients with time-sensitive conditions could benefit from early intervention. We study this scenario by formulating it as a learning-augmented online scheduling problem. We are given information about each arriving patient's urgency level in advance, but these predictions are inevitably error-prone. In this formulation, we face the challenges of decision making under imperfect information, and of responding dynamically to prediction error as we observe better data in real-time. We propose a simple online policy and show that this policy is in fact the best possible in certain stylized settings. We also demonstrate that our policy achieves the two desiderata of online algorithms with predictions: consistency (performance improvement with prediction accuracy) and robustness (protection against the worst case). We complement our theoretical findings with empirical evaluations of the policy under settings that more accurately reflect clinical scenarios in the real world.
Towards Unsupervised Visual Reasoning: Do Off-The-Shelf Features Know How to Reason?
Dec 20, 2022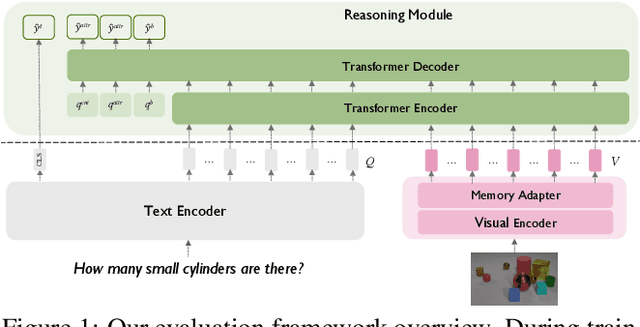
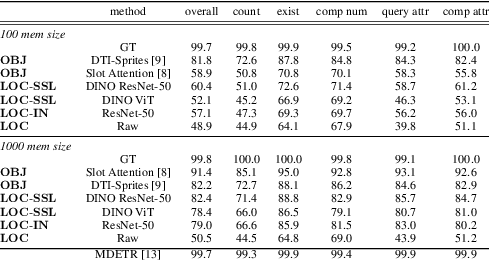
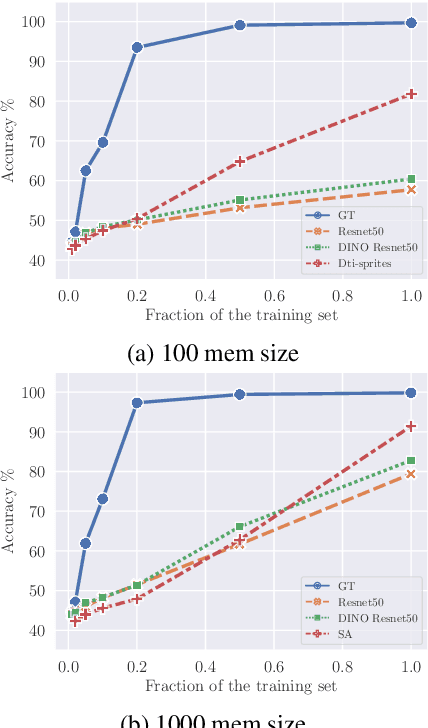

Recent advances in visual representation learning allowed to build an abundance of powerful off-the-shelf features that are ready-to-use for numerous downstream tasks. This work aims to assess how well these features preserve information about the objects, such as their spatial location, their visual properties and their relative relationships. We propose to do so by evaluating them in the context of visual reasoning, where multiple objects with complex relationships and different attributes are at play. More specifically, we introduce a protocol to evaluate visual representations for the task of Visual Question Answering. In order to decouple visual feature extraction from reasoning, we design a specific attention-based reasoning module which is trained on the frozen visual representations to be evaluated, in a spirit similar to standard feature evaluations relying on shallow networks. We compare two types of visual representations, densely extracted local features and object-centric ones, against the performances of a perfect image representation using ground truth. Our main findings are two-fold. First, despite excellent performances on classical proxy tasks, such representations fall short for solving complex reasoning problem. Second, object-centric features better preserve the critical information necessary to perform visual reasoning. In our proposed framework we show how to methodologically approach this evaluation.
Semi-autonomous Prosthesis Control Using Minimal Depth Information and Vibrotactile Feedback
Oct 02, 2022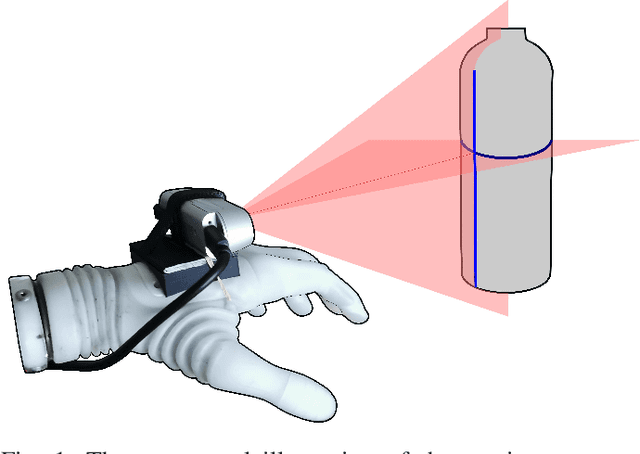
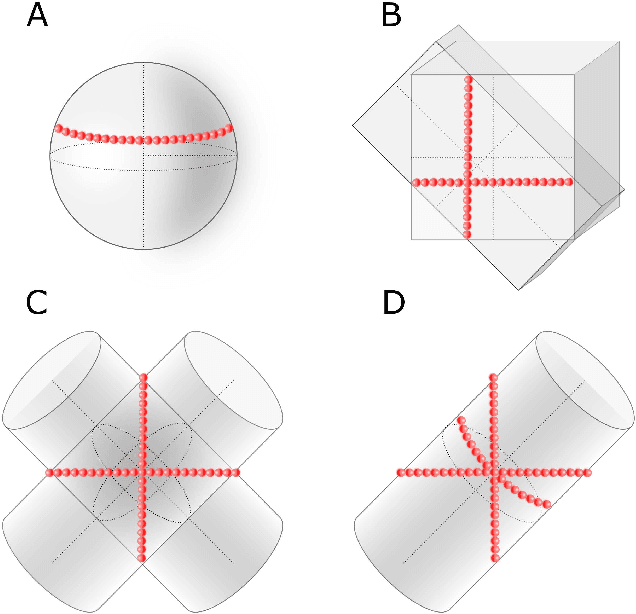
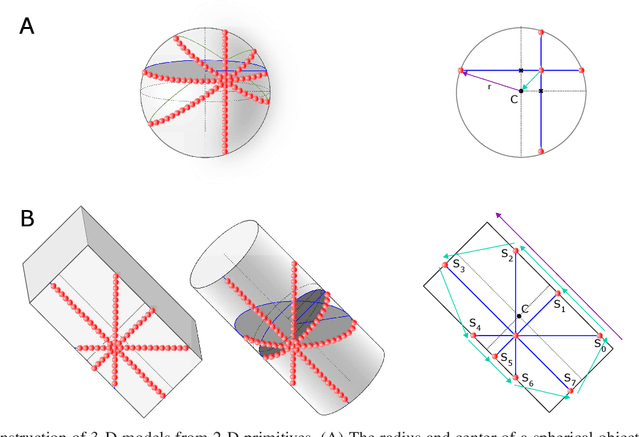
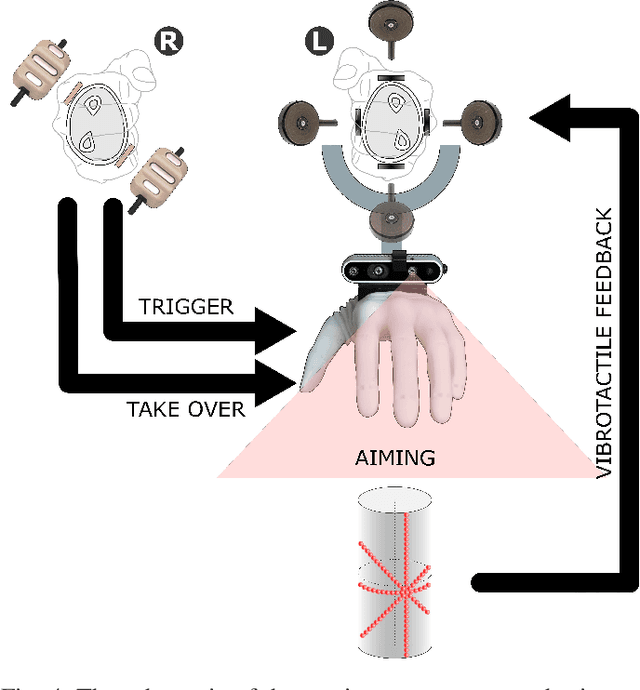
A semi-autonomous prosthesis control based on computer vision can be used to improve performance while decreasing the cognitive burden, especially when using advanced systems with multiple functions. However, a drawback of this approach is that it relies on the complex processing of a significant amount of data (e.g., a point cloud provided by a depth sensor), which can be a challenge when deploying such a system onto an embedded prosthesis controller. In the present study, therefore, we propose a novel method to reconstruct the shape of the target object using minimal data. Specifically, four concurrent laser scanner lines provide partial contours of the object cross-section. Simple geometry is then used to reconstruct the dimensions and orientation of spherical, cylindrical and cuboid objects. The prototype system was implemented using depth sensor to simulate the scan lines and vibrotactile feedback to aid the user during aiming of the laser towards the target object. The prototype was tested on ten able-bodied volunteers who used the semi-autonomous prosthesis to grasp a set of ten objects of different shape, size and orientation. The novel prototype was compared against the benchmark system, which used the full depth data. The results showed that novel system could be used to successfully handle all the objects, and that the performance improved with training, although it was still somewhat worse compared to the benchmark. The present study is therefore an important step towards building a compact system for embedded depth sensing specialized for prosthesis grasping.
LaneAF: Robust Multi-Lane Detection with Affinity Fields
Dec 22, 2022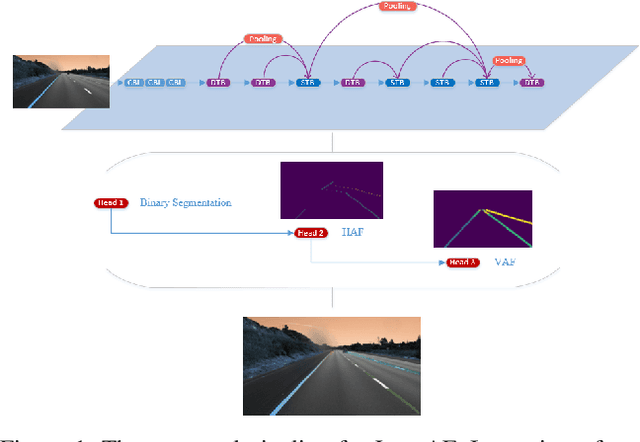
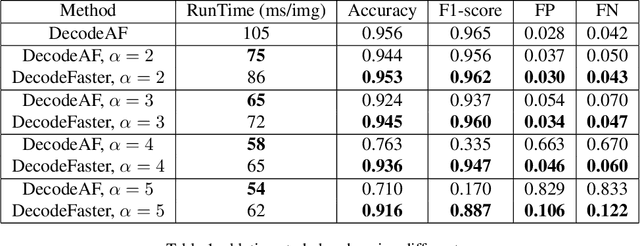
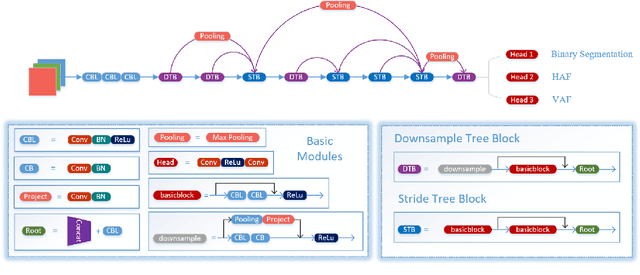
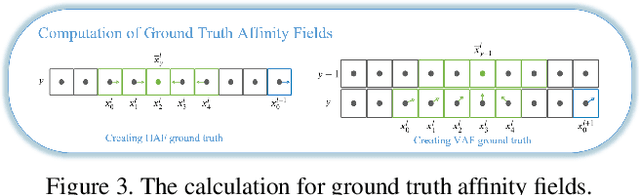
Lane detection is a long-standing task and a basic module in autonomous driving. The task is to detect the lane of the current driving road, and provide relevant information such as the ID, direction, curvature, width, length, with visualization. Our work is based on CNN backbone DLA-34, along with Affinity Fields, aims to achieve robust detection of various lanes without assuming the number of lanes. Besides, we investigate novel decoding methods to achieve more efficient lane detection algorithm.
Semi-Supervised Heterogeneous Graph Learning with Multi-level Data Augmentation
Nov 30, 2022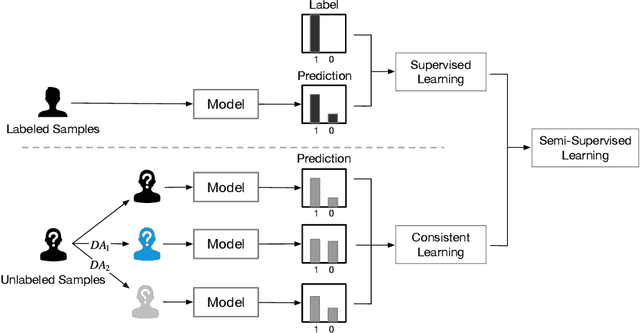


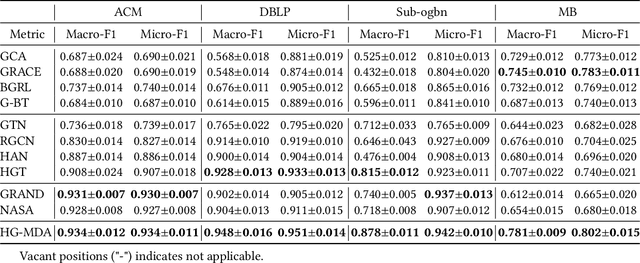
In recent years, semi-supervised graph learning with data augmentation (DA) is currently the most commonly used and best-performing method to enhance model robustness in sparse scenarios with few labeled samples. Differing from homogeneous graph, DA in heterogeneous graph has greater challenges: heterogeneity of information requires DA strategies to effectively handle heterogeneous relations, which considers the information contribution of different types of neighbors and edges to the target nodes. Furthermore, over-squashing of information is caused by the negative curvature that formed by the non-uniformity distribution and strong clustering in complex graph. To address these challenges, this paper presents a novel method named Semi-Supervised Heterogeneous Graph Learning with Multi-level Data Augmentation (HG-MDA). For the problem of heterogeneity of information in DA, node and topology augmentation strategies are proposed for the characteristics of heterogeneous graph. And meta-relation-based attention is applied as one of the indexes for selecting augmented nodes and edges. For the problem of over-squashing of information, triangle based edge adding and removing are designed to alleviate the negative curvature and bring the gain of topology. Finally, the loss function consists of the cross-entropy loss for labeled data and the consistency regularization for unlabeled data. In order to effectively fuse the prediction results of various DA strategies, the sharpening is used. Existing experiments on public datasets, i.e., ACM, DBLP, OGB, and industry dataset MB show that HG-MDA outperforms current SOTA models. Additionly, HG-MDA is applied to user identification in internet finance scenarios, helping the business to add 30% key users, and increase loans and balances by 3.6%, 11.1%, and 9.8%.
Counterfactual Explanations for Concepts in $\mathcal{ELH}$
Jan 12, 2023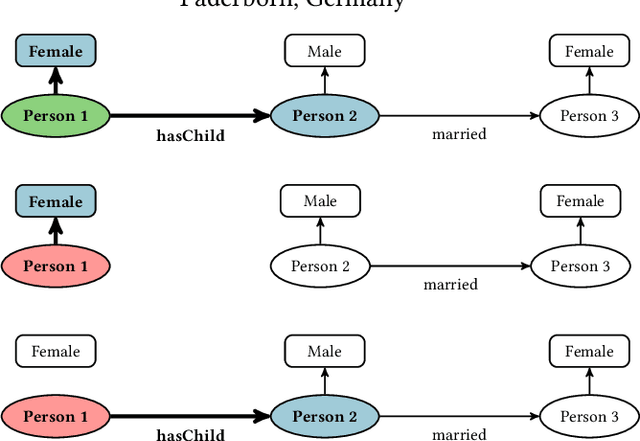
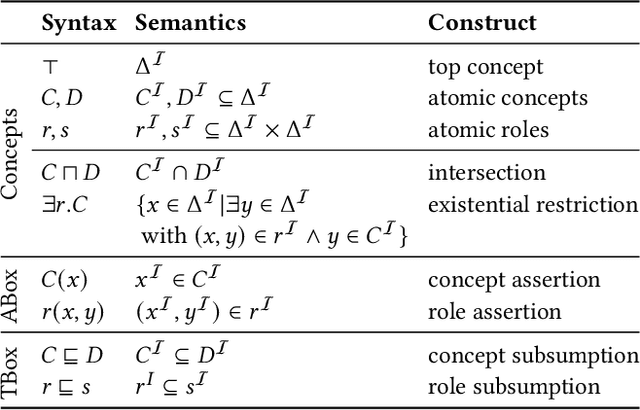
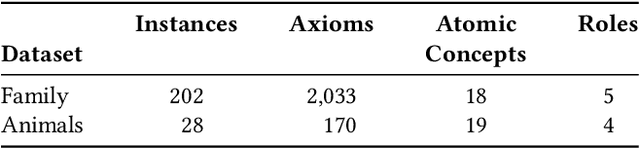
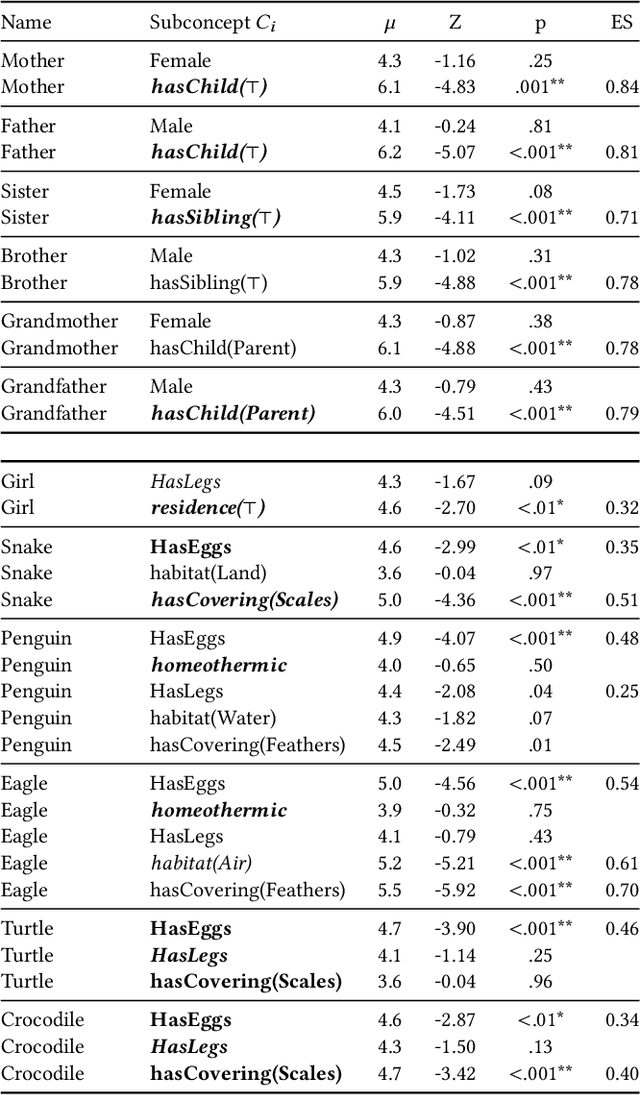
Knowledge bases are widely used for information management on the web, enabling high-impact applications such as web search, question answering, and natural language processing. They also serve as the backbone for automatic decision systems, e.g. for medical diagnostics and credit scoring. As stakeholders affected by these decisions would like to understand their situation and verify fair decisions, a number of explanation approaches have been proposed using concepts in description logics. However, the learned concepts can become long and difficult to fathom for non-experts, even when verbalized. Moreover, long concepts do not immediately provide a clear path of action to change one's situation. Counterfactuals answering the question "How must feature values be changed to obtain a different classification?" have been proposed as short, human-friendly explanations for tabular data. In this paper, we transfer the notion of counterfactuals to description logics and propose the first algorithm for generating counterfactual explanations in the description logic $\mathcal{ELH}$. Counterfactual candidates are generated from concepts and the candidates with fewest feature changes are selected as counterfactuals. In case of multiple counterfactuals, we rank them according to the likeliness of their feature combinations. For evaluation, we conduct a user survey to investigate which of the generated counterfactual candidates are preferred for explanation by participants. In a second study, we explore possible use cases for counterfactual explanations.
Towards High Performance One-Stage Human Pose Estimation
Jan 12, 2023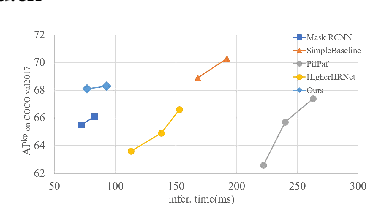
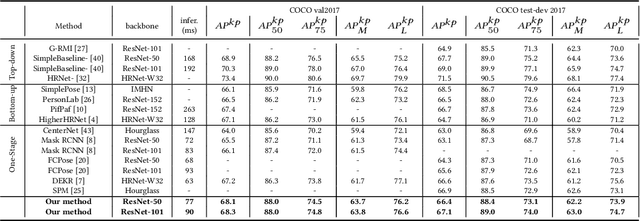
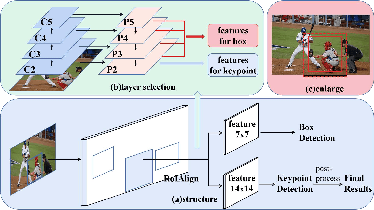
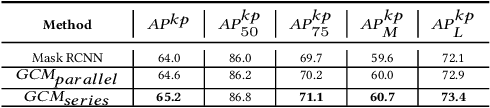
Making top-down human pose estimation method present both good performance and high efficiency is appealing. Mask RCNN can largely improve the efficiency by conducting person detection and pose estimation in a single framework, as the features provided by the backbone are able to be shared by the two tasks. However, the performance is not as good as traditional two-stage methods. In this paper, we aim to largely advance the human pose estimation results of Mask-RCNN and still keep the efficiency. Specifically, we make improvements on the whole process of pose estimation, which contains feature extraction and keypoint detection. The part of feature extraction is ensured to get enough and valuable information of pose. Then, we introduce a Global Context Module into the keypoints detection branch to enlarge the receptive field, as it is crucial to successful human pose estimation. On the COCO val2017 set, our model using the ResNet-50 backbone achieves an AP of 68.1, which is 2.6 higher than Mask RCNN (AP of 65.5). Compared to the classic two-stage top-down method SimpleBaseline, our model largely narrows the performance gap (68.1 AP vs. 68.9 AP) with a much faster inference speed (77 ms vs. 168 ms), demonstrating the effectiveness of the proposed method. Code is available at: https://github.com/lingl_space/maskrcnn_keypoint_refined.
* 5 pages, 5 figures, accepted at ACM Multimedia Asia (MMAsia) 2022
Radio Frequency Fingerprints Extraction for LTE-V2X: A Channel Estimation Based Methodology
Jan 04, 2023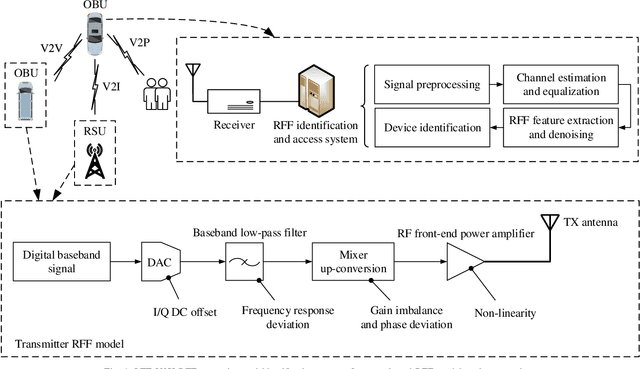
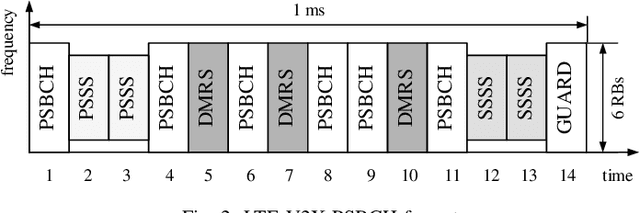
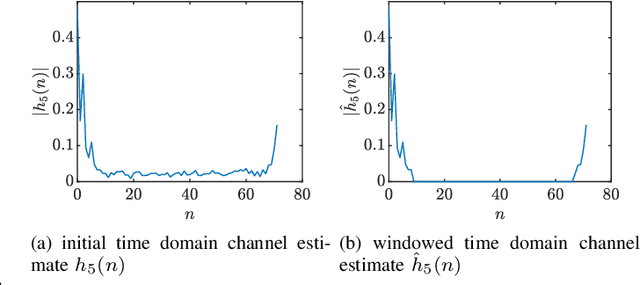
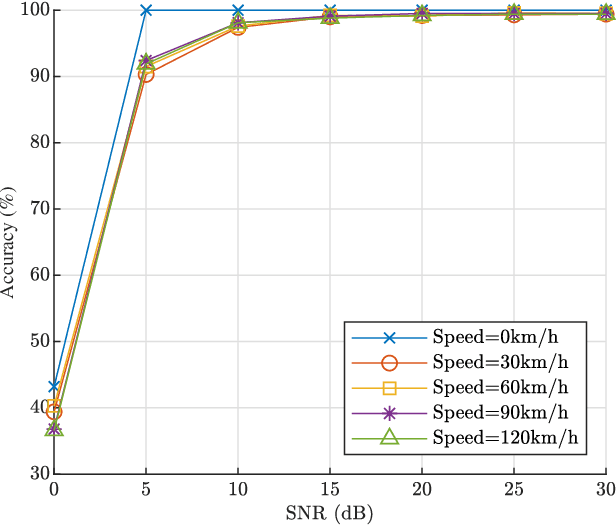
The vehicular-to-everything (V2X) technology has recently drawn a number of attentions from both academic and industrial areas. However, the openness of the wireless communication system makes it more vulnerable to identity impersonation and information tampering. How to employ the powerful radio frequency fingerprint (RFF) identification technology in V2X systems turns out to be a vital and also challenging task. In this paper, we propose a novel RFF extraction method for Long Term Evolution-V2X (LTE-V2X) systems. In order to conquer the difficulty of extracting transmitter RFF in the presence of wireless channel and receiver noise, we first estimate the wireless channel which excludes the RFF. Then, we remove the impact of the wireless channel based on the channel estimate and obtain initial RFF features. Finally, we conduct RFF denoising to enhance the quality of the initial RFF. Simulation and experiment results both demonstrate that our proposed RFF extraction scheme achieves a high identification accuracy. Furthermore, the performance is also robust to the vehicle speed.