 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Maximizing Use-Case Specificity through Precision Model Tuning
Dec 29, 2022
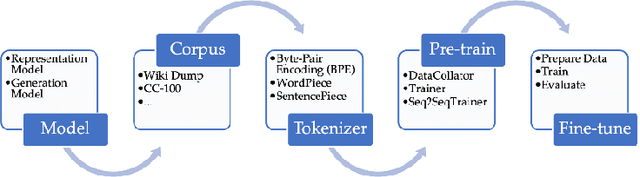
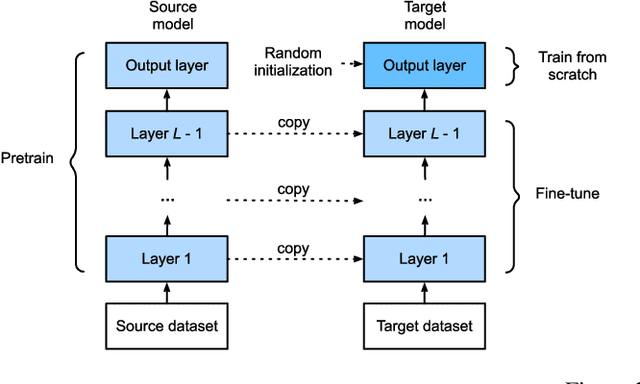
Language models have become increasingly popular in recent years for tasks like information retrieval. As use-cases become oriented toward specific domains, fine-tuning becomes default for standard performance. To fine-tune these models for specific tasks and datasets, it is necessary to carefully tune the model's hyperparameters and training techniques. In this paper, we present an in-depth analysis of the performance of four transformer-based language models on the task of biomedical information retrieval. The models we consider are DeepMind's RETRO (7B parameters), GPT-J (6B parameters), GPT-3 (175B parameters), and BLOOM (176B parameters). We compare their performance on the basis of relevance, accuracy, and interpretability, using a large corpus of 480000 research papers on protein structure/function prediction as our dataset. Our findings suggest that smaller models, with <10B parameters and fine-tuned on domain-specific datasets, tend to outperform larger language models on highly specific questions in terms of accuracy, relevancy, and interpretability by a significant margin (+50% on average). However, larger models do provide generally better results on broader prompts.
Scalable Batch Acquisition for Deep Bayesian Active Learning
Jan 13, 2023
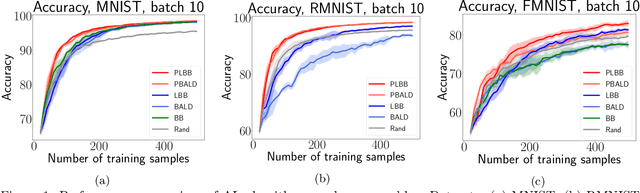
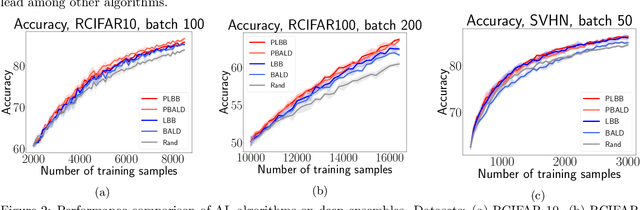

In deep active learning, it is especially important to choose multiple examples to markup at each step to work efficiently, especially on large datasets. At the same time, existing solutions to this problem in the Bayesian setup, such as BatchBALD, have significant limitations in selecting a large number of examples, associated with the exponential complexity of computing mutual information for joint random variables. We, therefore, present the Large BatchBALD algorithm, which gives a well-grounded approximation to the BatchBALD method that aims to achieve comparable quality while being more computationally efficient. We provide a complexity analysis of the algorithm, showing a reduction in computation time, especially for large batches. Furthermore, we present an extensive set of experimental results on image and text data, both on toy datasets and larger ones such as CIFAR-100.
Learning-based Optimal Admission Control in a Single Server Queuing System
Dec 21, 2022We consider a long-term average profit maximizing admission control problem in an M/M/1 queuing system with a known arrival rate but an unknown service rate. With a fixed reward collected upon service completion and a cost per unit of time enforced on customers waiting in the queue, a dispatcher decides upon arrivals whether to admit the arriving customer or not based on the full history of observations of the queue-length of the system. \cite[Econometrica]{Naor} showed that if all the parameters of the model are known, then it is optimal to use a static threshold policy - admit if the queue-length is less than a predetermined threshold and otherwise not. We propose a learning-based dispatching algorithm and characterize its regret with respect to optimal dispatch policies for the full information model of \cite{Naor}. We show that the algorithm achieves an $O(1)$ regret when all optimal thresholds with full information are non-zero, and achieves an $O(\ln^{3+\epsilon}(N))$ regret in the case that an optimal threshold with full information is $0$ (i.e., an optimal policy is to reject all arrivals), where $N$ is the number of arrivals and $\epsilon>0$.
Interaction-level Membership Inference Attack Against Federated Recommender Systems
Jan 26, 2023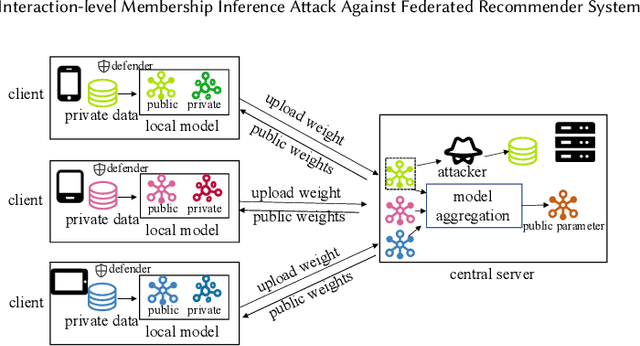

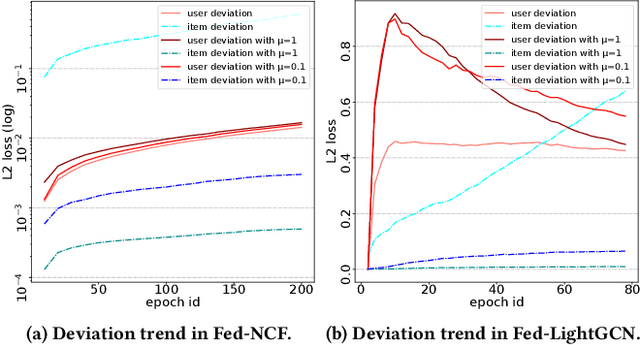

The marriage of federated learning and recommender system (FedRec) has been widely used to address the growing data privacy concerns in personalized recommendation services. In FedRecs, users' attribute information and behavior data (i.e., user-item interaction data) are kept locally on their personal devices, therefore, it is considered a fairly secure approach to protect user privacy. As a result, the privacy issue of FedRecs is rarely explored. Unfortunately, several recent studies reveal that FedRecs are vulnerable to user attribute inference attacks, highlighting the privacy concerns of FedRecs. In this paper, we further investigate the privacy problem of user behavior data (i.e., user-item interactions) in FedRecs. Specifically, we perform the first systematic study on interaction-level membership inference attacks on FedRecs. An interaction-level membership inference attacker is first designed, and then the classical privacy protection mechanism, Local Differential Privacy (LDP), is adopted to defend against the membership inference attack. Unfortunately, the empirical analysis shows that LDP is not effective against such new attacks unless the recommendation performance is largely compromised. To mitigate the interaction-level membership attack threats, we design a simple yet effective defense method to significantly reduce the attacker's inference accuracy without losing recommendation performance. Extensive experiments are conducted with two widely used FedRecs (Fed-NCF and Fed-LightGCN) on three real-world recommendation datasets (MovieLens-100K, Steam-200K, and Amazon Cell Phone), and the experimental results show the effectiveness of our solutions.
Scientific Paper Extractive Summarization Enhanced by Citation Graphs
Dec 08, 2022In a citation graph, adjacent paper nodes share related scientific terms and topics. The graph thus conveys unique structure information of document-level relatedness that can be utilized in the paper summarization task, for exploring beyond the intra-document information. In this work, we focus on leveraging citation graphs to improve scientific paper extractive summarization under different settings. We first propose a Multi-granularity Unsupervised Summarization model (MUS) as a simple and low-cost solution to the task. MUS finetunes a pre-trained encoder model on the citation graph by link prediction tasks. Then, the abstract sentences are extracted from the corresponding paper considering multi-granularity information. Preliminary results demonstrate that citation graph is helpful even in a simple unsupervised framework. Motivated by this, we next propose a Graph-based Supervised Summarization model (GSS) to achieve more accurate results on the task when large-scale labeled data are available. Apart from employing the link prediction as an auxiliary task, GSS introduces a gated sentence encoder and a graph information fusion module to take advantage of the graph information to polish the sentence representation. Experiments on a public benchmark dataset show that MUS and GSS bring substantial improvements over the prior state-of-the-art model.
* 10 pages, 4 figure
Robust Human Identity Anonymization using Pose Estimation
Jan 10, 2023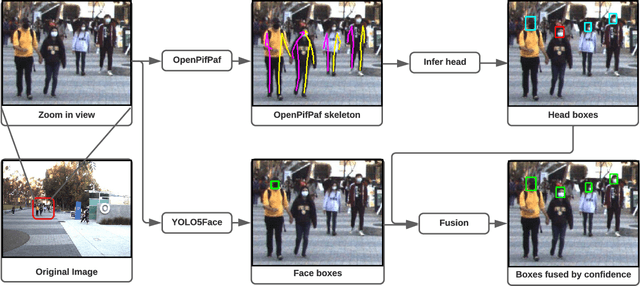
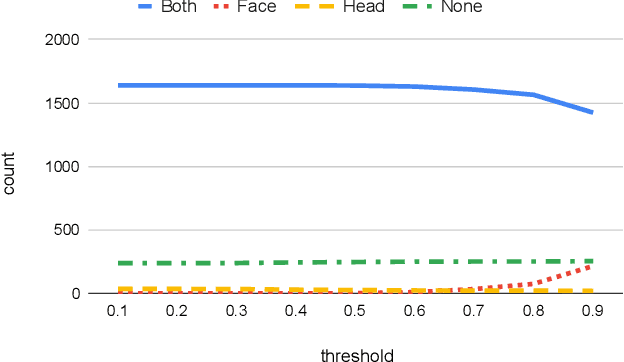
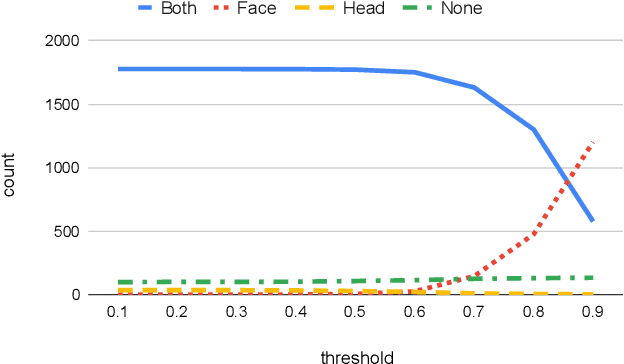
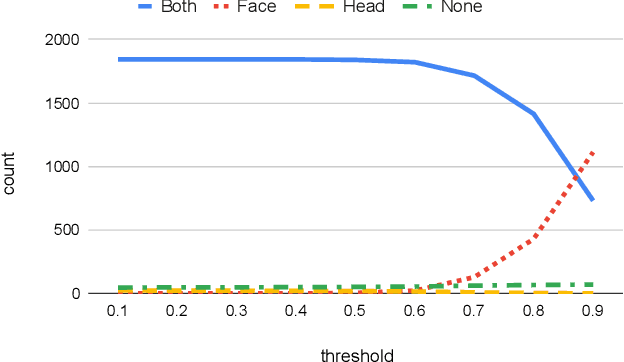
Many outdoor autonomous mobile platforms require more human identity anonymized data to power their data-driven algorithms. The human identity anonymization should be robust so that less manual intervention is needed, which remains a challenge for current face detection and anonymization systems. In this paper, we propose to use the skeleton generated from the state-of-the-art human pose estimation model to help localize human heads. We develop criteria to evaluate the performance and compare it with the face detection approach. We demonstrate that the proposed algorithm can reduce missed faces and thus better protect the identity information for the pedestrians. We also develop a confidence-based fusion method to further improve the performance.
* Source code will be available at https://github.com/AutonomousVehicleLaboratory/anonymization
Scattered or Connected? An Optimized Parameter-efficient Tuning Approach for Information Retrieval
Aug 21, 2022
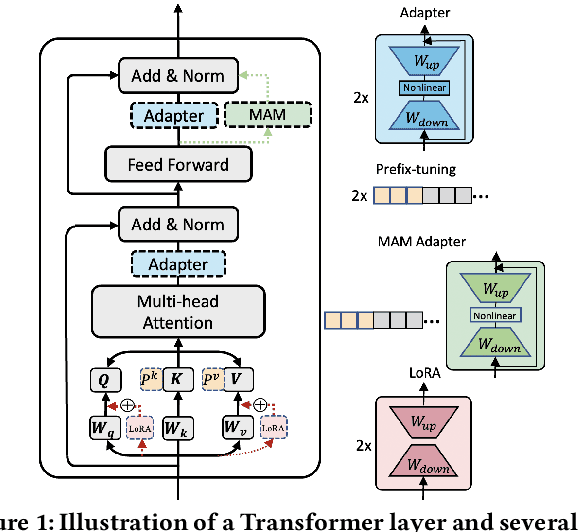
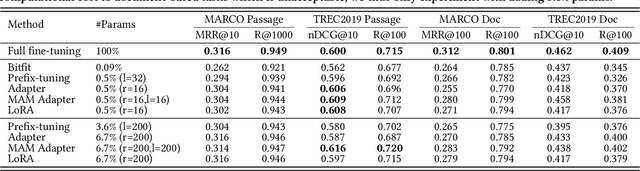
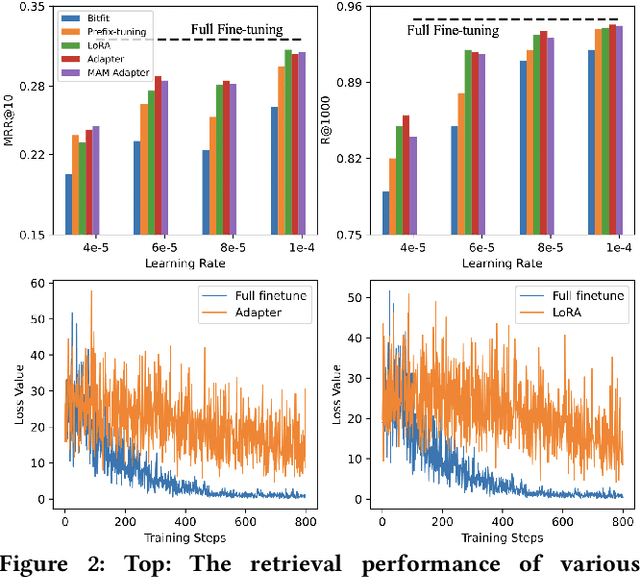
Pre-training and fine-tuning have achieved significant advances in the information retrieval (IR). A typical approach is to fine-tune all the parameters of large-scale pre-trained models (PTMs) on downstream tasks. As the model size and the number of tasks increase greatly, such approach becomes less feasible and prohibitively expensive. Recently, a variety of parameter-efficient tuning methods have been proposed in natural language processing (NLP) that only fine-tune a small number of parameters while still attaining strong performance. Yet there has been little effort to explore parameter-efficient tuning for IR. In this work, we first conduct a comprehensive study of existing parameter-efficient tuning methods at both the retrieval and re-ranking stages. Unlike the promising results in NLP, we find that these methods cannot achieve comparable performance to full fine-tuning at both stages when updating less than 1\% of the original model parameters. More importantly, we find that the existing methods are just parameter-efficient, but not learning-efficient as they suffer from unstable training and slow convergence. To analyze the underlying reason, we conduct a theoretical analysis and show that the separation of the inserted trainable modules makes the optimization difficult. To alleviate this issue, we propose to inject additional modules alongside the \acp{PTM} to make the original scattered modules connected. In this way, all the trainable modules can form a pathway to smooth the loss surface and thus help stabilize the training process. Experiments at both retrieval and re-ranking stages show that our method outperforms existing parameter-efficient methods significantly, and achieves comparable or even better performance over full fine-tuning.
GPViT: A High Resolution Non-Hierarchical Vision Transformer with Group Propagation
Dec 13, 2022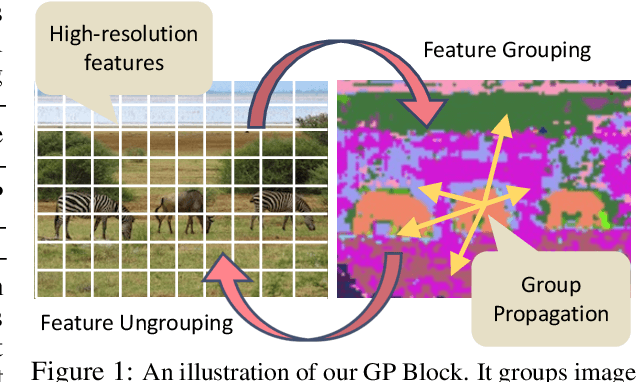
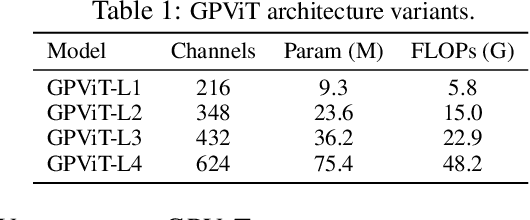
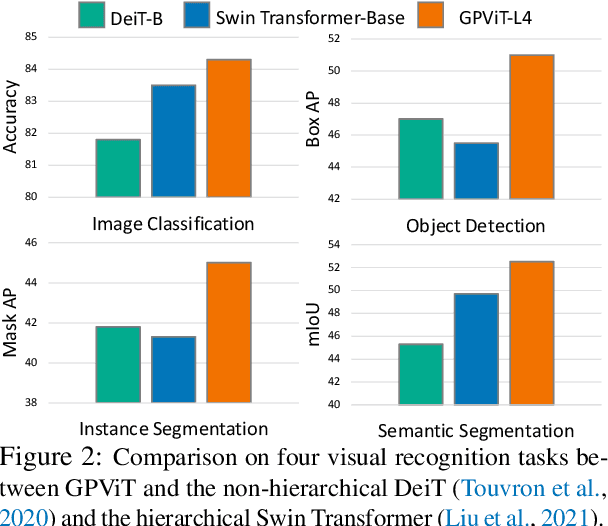
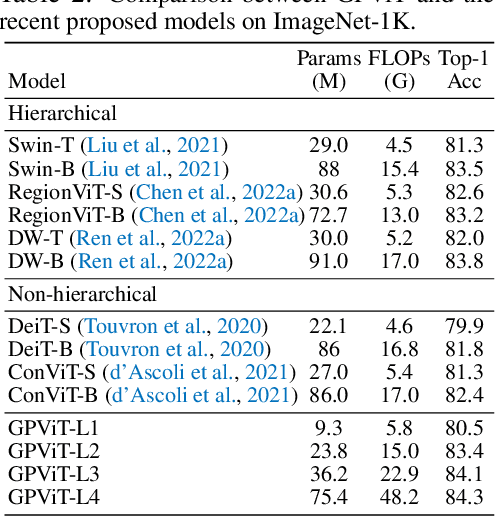
We present the Group Propagation Vision Transformer (GPViT): a novel nonhierarchical (i.e. non-pyramidal) transformer model designed for general visual recognition with high-resolution features. High-resolution features (or tokens) are a natural fit for tasks that involve perceiving fine-grained details such as detection and segmentation, but exchanging global information between these features is expensive in memory and computation because of the way self-attention scales. We provide a highly efficient alternative Group Propagation Block (GP Block) to exchange global information. In each GP Block, features are first grouped together by a fixed number of learnable group tokens; we then perform Group Propagation where global information is exchanged between the grouped features; finally, global information in the updated grouped features is returned back to the image features through a transformer decoder. We evaluate GPViT on a variety of visual recognition tasks including image classification, semantic segmentation, object detection, and instance segmentation. Our method achieves significant performance gains over previous works across all tasks, especially on tasks that require high-resolution outputs, for example, our GPViT-L3 outperforms Swin Transformer-B by 2.0 mIoU on ADE20K semantic segmentation with only half as many parameters. Code and pre-trained models are available at https://github.com/ChenhongyiYang/GPViT .
High-Order Conditional Mutual Information Maximization for dealing with High-Order Dependencies in Feature Selection
Jul 18, 2022
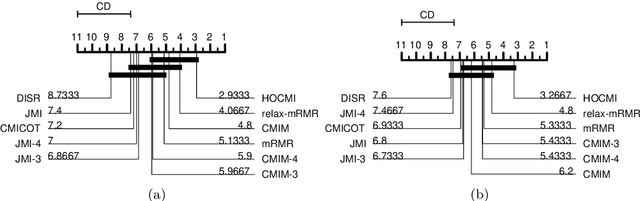
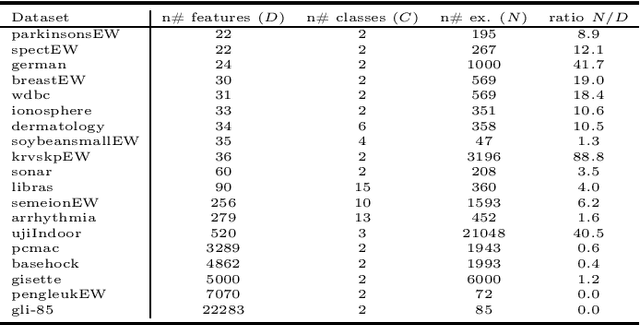
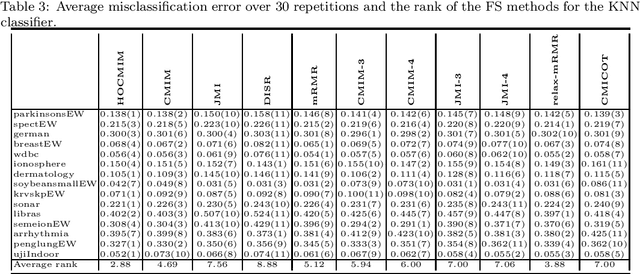
This paper presents a novel feature selection method based on the conditional mutual information (CMI). The proposed High Order Conditional Mutual Information Maximization (HOCMIM) incorporates high order dependencies into the feature selection procedure and has a straightforward interpretation due to its bottom-up derivation. The HOCMIM is derived from the CMI's chain expansion and expressed as a maximization optimization problem. The maximization problem is solved using a greedy search procedure, which speeds up the entire feature selection process. The experiments are run on a set of benchmark datasets (20 in total). The HOCMIM is compared with eighteen state-of-the-art feature selection algorithms, from the results of two supervised learning classifiers (Support Vector Machine and K-Nearest Neighbor). The HOCMIM achieves the best results in terms of accuracy and shows to be faster than high order feature selection counterparts.
White-box Inference Attacks against Centralized Machine Learning and Federated Learning
Dec 15, 2022


With the development of information science and technology, various industries have generated massive amounts of data, and machine learning is widely used in the analysis of big data. However, if the privacy of machine learning applications' customers cannot be guaranteed, it will cause security threats and losses to users' personal privacy information and service providers. Therefore, the issue of privacy protection of machine learning has received wide attention. For centralized machine learning models, we evaluate the impact of different neural network layers, gradient, gradient norm, and fine-tuned models on member inference attack performance with prior knowledge; For the federated learning model, we discuss the location of the attacker in the target model and its attack mode. The results show that the centralized machine learning model shows more serious member information leakage in all aspects, and the accuracy of the attacker in the central parameter server is significantly higher than the local Inference attacks as participants.