 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Query-Driven Knowledge Base Completion using Multimodal Path Fusion over Multimodal Knowledge Graph
Dec 04, 2022
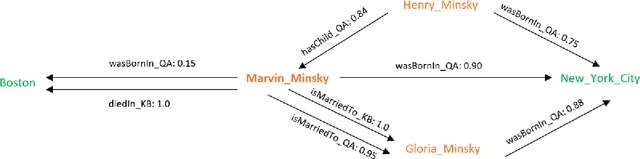

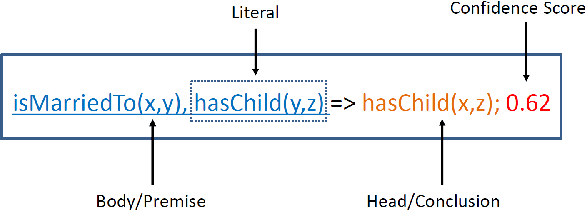
Over the past few years, large knowledge bases have been constructed to store massive amounts of knowledge. However, these knowledge bases are highly incomplete, for example, over 70% of people in Freebase have no known place of birth. To solve this problem, we propose a query-driven knowledge base completion system with multimodal fusion of unstructured and structured information. To effectively fuse unstructured information from the Web and structured information in knowledge bases to achieve good performance, our system builds multimodal knowledge graphs based on question answering and rule inference. We propose a multimodal path fusion algorithm to rank candidate answers based on different paths in the multimodal knowledge graphs, achieving much better performance than question answering, rule inference and a baseline fusion algorithm. To improve system efficiency, query-driven techniques are utilized to reduce the runtime of our system, providing fast responses to user queries. Extensive experiments have been conducted to demonstrate the effectiveness and efficiency of our system.
GreenDB -- A Dataset and Benchmark for Extraction of Sustainability Information of Consumer Goods
Jul 29, 2022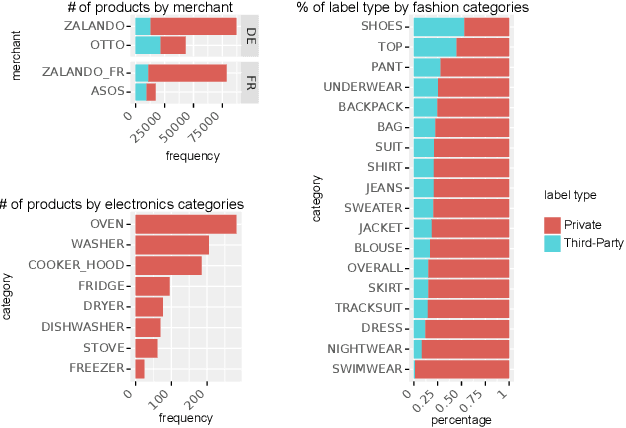
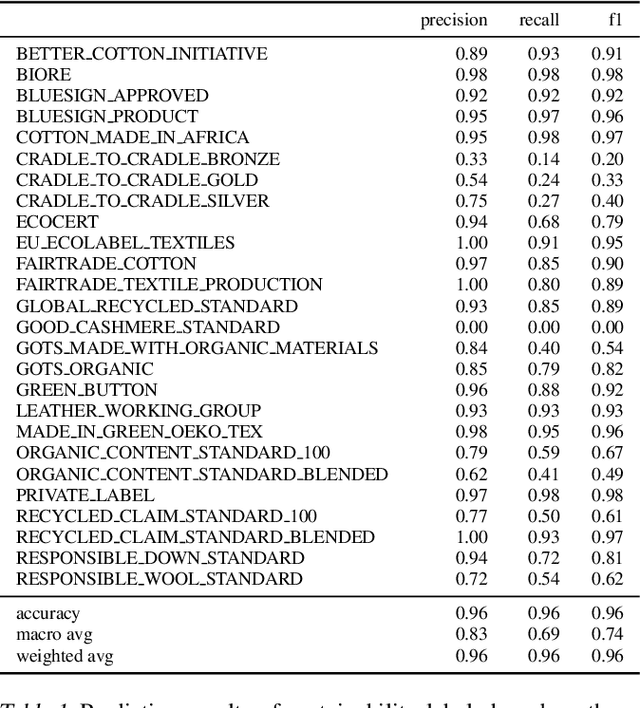
The production, shipping, usage, and disposal of consumer goods have a substantial impact on greenhouse gas emissions and the depletion of resources. Machine Learning (ML) can help to foster sustainable consumption patterns by accounting for sustainability aspects in product search or recommendations of modern retail platforms. However, the lack of large high quality publicly available product data with trustworthy sustainability information impedes the development of ML technology that can help to reach our sustainability goals. Here we present GreenDB, a database that collects products from European online shops on a weekly basis. As proxy for the products' sustainability, it relies on sustainability labels, which are evaluated by experts. The GreenDB schema extends the well-known schema.org Product definition and can be readily integrated into existing product catalogs. We present initial results demonstrating that ML models trained with our data can reliably (F1 score 96%) predict the sustainability label of products. These contributions can help to complement existing e-commerce experiences and ultimately encourage users to more sustainable consumption patterns.
Noise Reduction in Medical Images
Jan 04, 2023Objectives: Analyze the types of studies and algorithms that are most applied, Identify the anatomical regions treated. Determine the application of parallel techniques used in studies carried out between 2010 and 2022 in research on noise reduction in medical images. Methodology: A systematic review of the literature on noise reduction in medical images in the last 12 years was carried out. The observation technique was applied to extract the information and the indicators (type of study, treated anatomical region, algorithm and or method and the application of parallel computing) were recorded in a data sheet. Results: Most of the studies have been developed in anatomical regions such as: Brain, Bones, Heart, Breast, Lung and Visual system. In the articles investigated, 14 are applied through parallel computing. Conclution: Noise reduction in medical images can contribute to better quality images and thus make a more accurate and effective diagnosis.
Text sampling strategies for predicting missing bibliographic links
Jan 04, 2023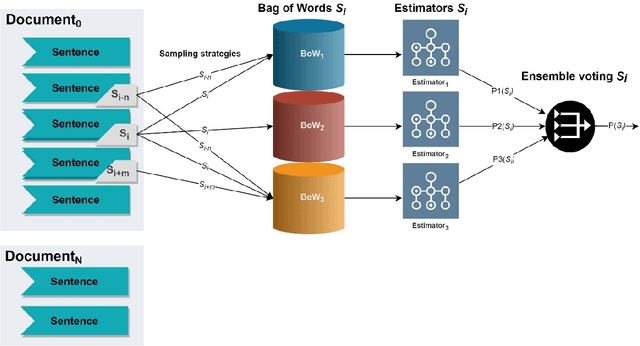
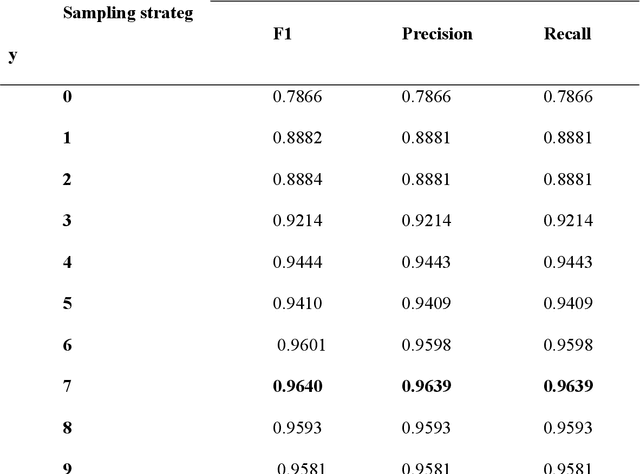
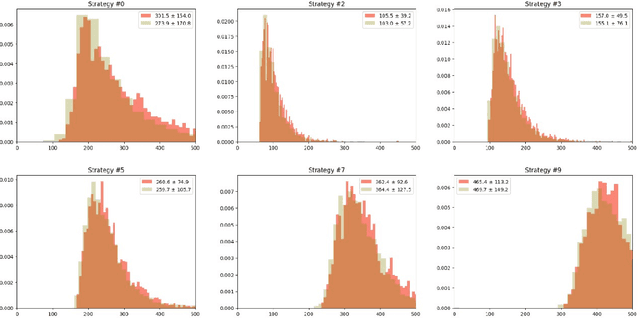
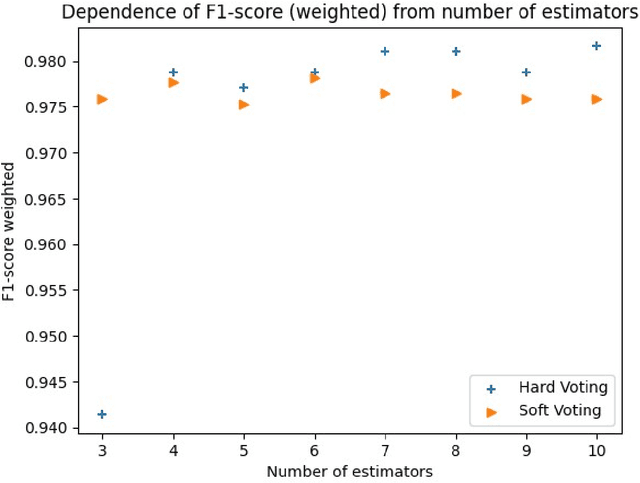
The paper proposes various strategies for sampling text data when performing automatic sentence classification for the purpose of detecting missing bibliographic links. We construct samples based on sentences as semantic units of the text and add their immediate context which consists of several neighboring sentences. We examine a number of sampling strategies that differ in context size and position. The experiment is carried out on the collection of STEM scientific papers. Including the context of sentences into samples improves the result of their classification. We automatically determine the optimal sampling strategy for a given text collection by implementing an ensemble voting when classifying the same data sampled in different ways. Sampling strategy taking into account the sentence context with hard voting procedure leads to the classification accuracy of 98% (F1-score). This method of detecting missing bibliographic links can be used in recommendation engines of applied intelligent information systems.
Counterfactual Explanations for Land Cover Mapping in a Multi-class Setting
Jan 04, 2023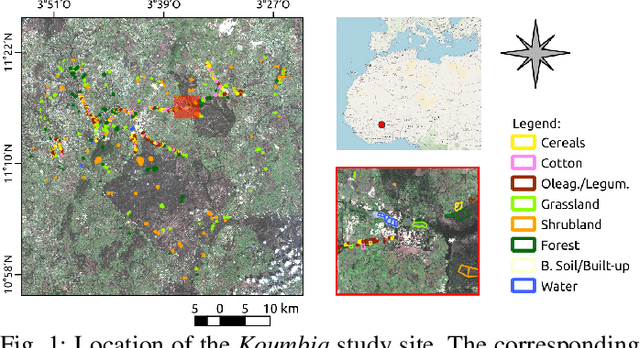
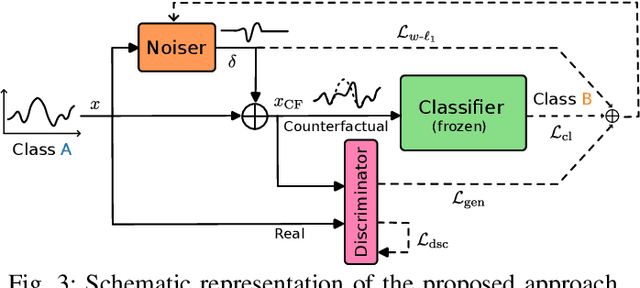
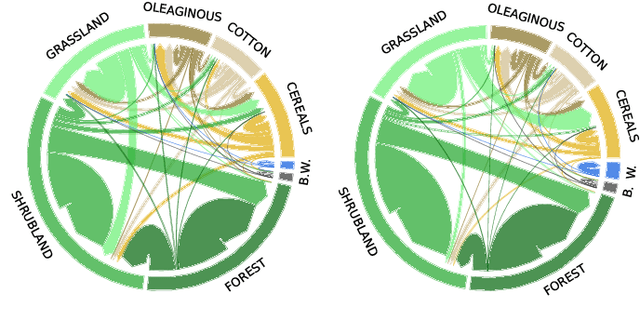
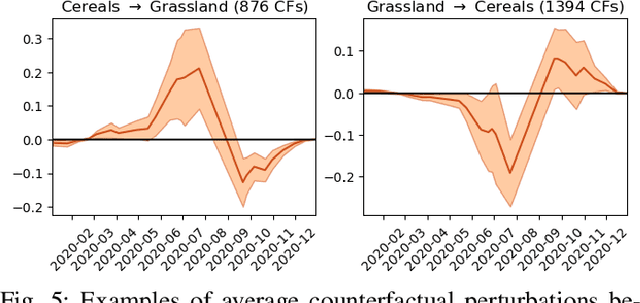
Counterfactual explanations are an emerging tool to enhance interpretability of deep learning models. Given a sample, these methods seek to find and display to the user similar samples across the decision boundary. In this paper, we propose a generative adversarial counterfactual approach for satellite image time series in a multi-class setting for the land cover classification task. One of the distinctive features of the proposed approach is the lack of prior assumption on the targeted class for a given counterfactual explanation. This inherent flexibility allows for the discovery of interesting information on the relationship between land cover classes. The other feature consists of encouraging the counterfactual to differ from the original sample only in a small and compact temporal segment. These time-contiguous perturbations allow for a much sparser and, thus, interpretable solution. Furthermore, plausibility/realism of the generated counterfactual explanations is enforced via the proposed adversarial learning strategy.
Towards mapping the contemporary art world with ArtLM: an art-specific NLP model
Dec 15, 2022
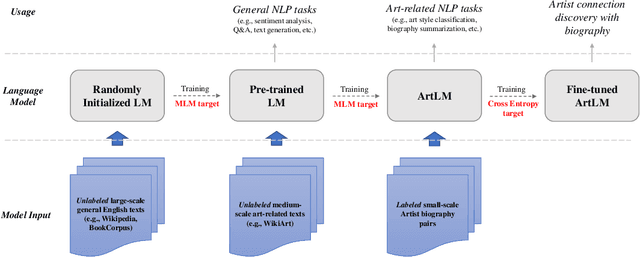
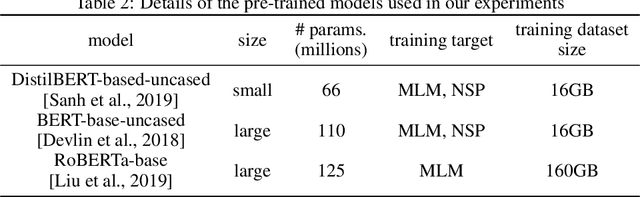

With an increasing amount of data in the art world, discovering artists and artworks suitable to collectors' tastes becomes a challenge. It is no longer enough to use visual information, as contextual information about the artist has become just as important in contemporary art. In this work, we present a generic Natural Language Processing framework (called ArtLM) to discover the connections among contemporary artists based on their biographies. In this approach, we first continue to pre-train the existing general English language models with a large amount of unlabelled art-related data. We then fine-tune this new pre-trained model with our biography pair dataset manually annotated by a team of professionals in the art industry. With extensive experiments, we demonstrate that our ArtLM achieves 85.6% accuracy and 84.0% F1 score and outperforms other baseline models. We also provide a visualisation and a qualitative analysis of the artist network built from ArtLM's outputs.
The KITMUS Test: Evaluating Knowledge Integration from Multiple Sources in Natural Language Understanding Systems
Dec 15, 2022
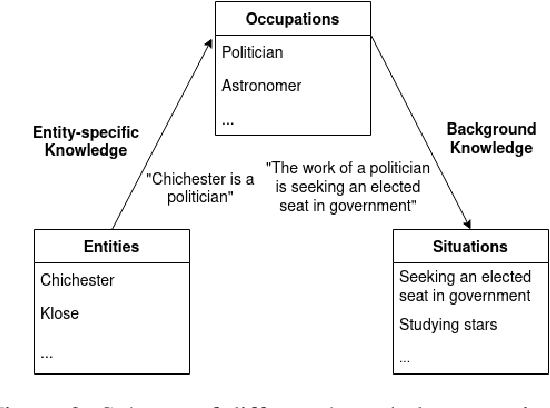

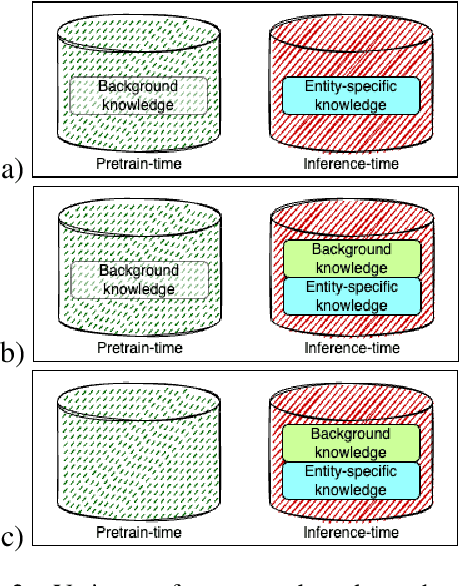
Many state-of-the-art natural language understanding (NLU) models are based on pretrained neural language models. These models often make inferences using information from multiple sources. An important class of such inferences are those that require both background knowledge, presumably contained in a model's pretrained parameters, and instance-specific information that is supplied at inference time. However, the integration and reasoning abilities of NLU models in the presence of multiple knowledge sources have been largely understudied. In this work, we propose a test suite of coreference resolution tasks that require reasoning over multiple facts. Our dataset is organized into subtasks that differ in terms of which knowledge sources contain relevant facts. We evaluate state-of-the-art coreference resolution models on our dataset. Our results indicate that several models struggle to reason on-the-fly over knowledge observed both at pretrain time and at inference time. However, with task-specific training, a subset of models demonstrates the ability to integrate certain knowledge types from multiple sources.
Demonstration of machine-learning-enhanced Bayesian quantum state estimation
Dec 15, 2022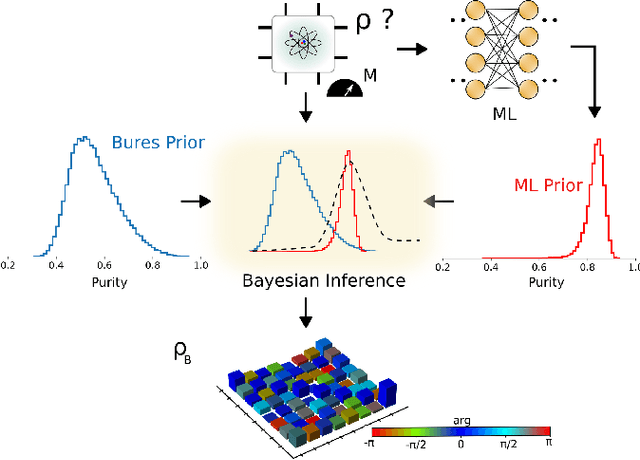
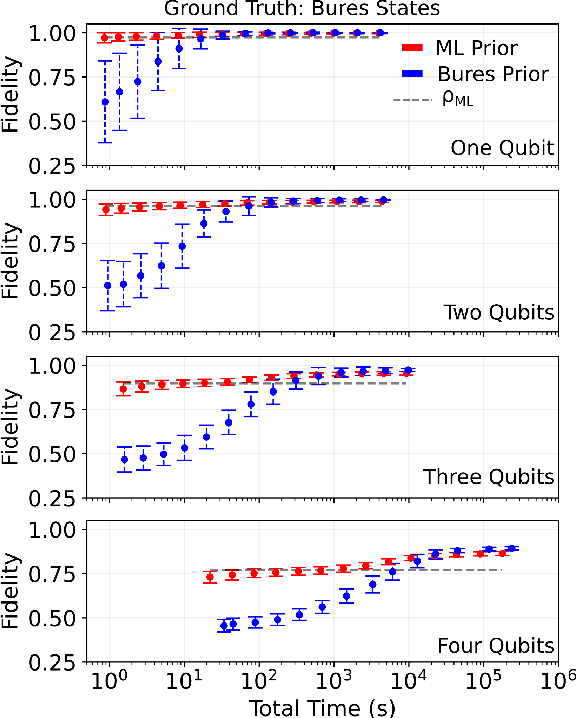
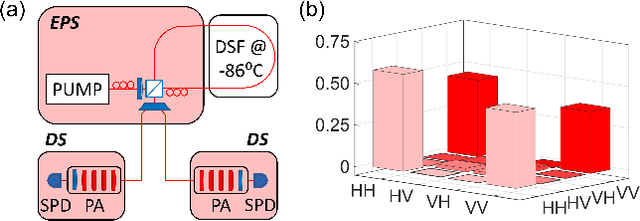
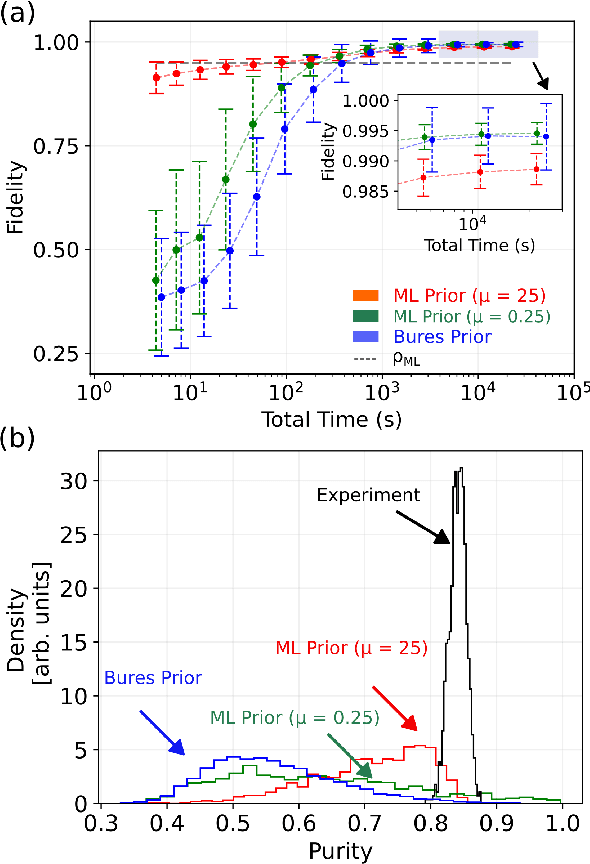
Machine learning (ML) has found broad applicability in quantum information science in topics as diverse as experimental design, state classification, and even studies on quantum foundations. Here, we experimentally realize an approach for defining custom prior distributions that are automatically tuned using ML for use with Bayesian quantum state estimation methods. Previously, researchers have looked to Bayesian quantum state tomography due to its unique advantages like natural uncertainty quantification, the return of reliable estimates under any measurement condition, and minimal mean-squared error. However, practical challenges related to long computation times and conceptual issues concerning how to incorporate prior knowledge most suitably can overshadow these benefits. Using both simulated and experimental measurement results, we demonstrate that ML-defined prior distributions reduce net convergence times and provide a natural way to incorporate both implicit and explicit information directly into the prior distribution. These results constitute a promising path toward practical implementations of Bayesian quantum state tomography.
Multi-Projection Fusion and Refinement Network for Salient Object Detection in 360° Omnidirectional Image
Dec 23, 2022
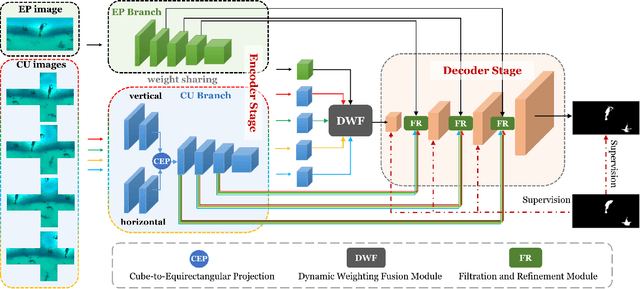
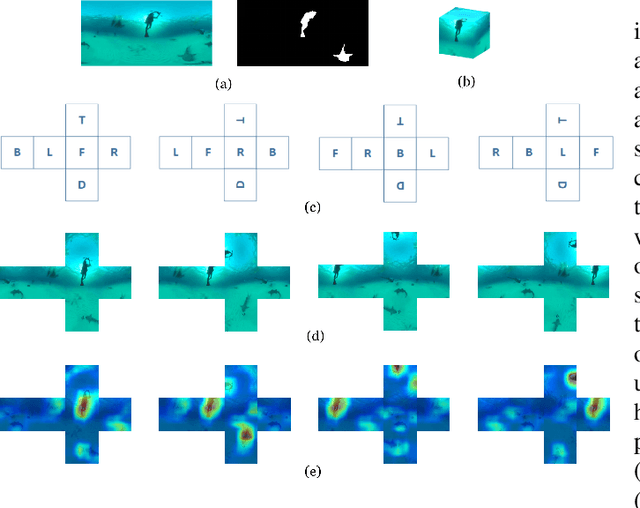
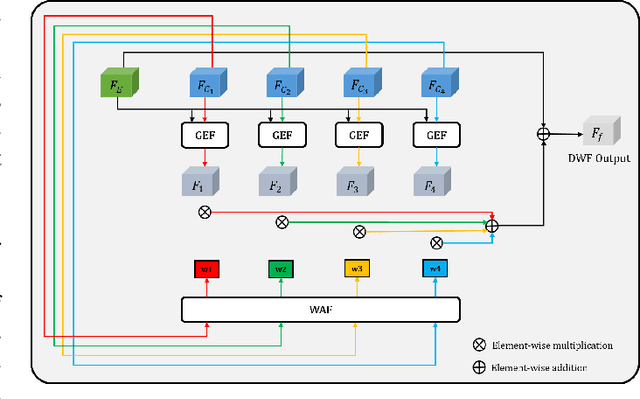
Salient object detection (SOD) aims to determine the most visually attractive objects in an image. With the development of virtual reality technology, 360{\deg} omnidirectional image has been widely used, but the SOD task in 360{\deg} omnidirectional image is seldom studied due to its severe distortions and complex scenes. In this paper, we propose a Multi-Projection Fusion and Refinement Network (MPFR-Net) to detect the salient objects in 360{\deg} omnidirectional image. Different from the existing methods, the equirectangular projection image and four corresponding cube-unfolding images are embedded into the network simultaneously as inputs, where the cube-unfolding images not only provide supplementary information for equirectangular projection image, but also ensure the object integrity of the cube-map projection. In order to make full use of these two projection modes, a Dynamic Weighting Fusion (DWF) module is designed to adaptively integrate the features of different projections in a complementary and dynamic manner from the perspective of inter and intra features. Furthermore, in order to fully explore the way of interaction between encoder and decoder features, a Filtration and Refinement (FR) module is designed to suppress the redundant information between the feature itself and the feature. Experimental results on two omnidirectional datasets demonstrate that the proposed approach outperforms the state-of-the-art methods both qualitatively and quantitatively.
IDMS: Instance Depth for Multi-scale Monocular 3D Object Detection
Dec 03, 2022
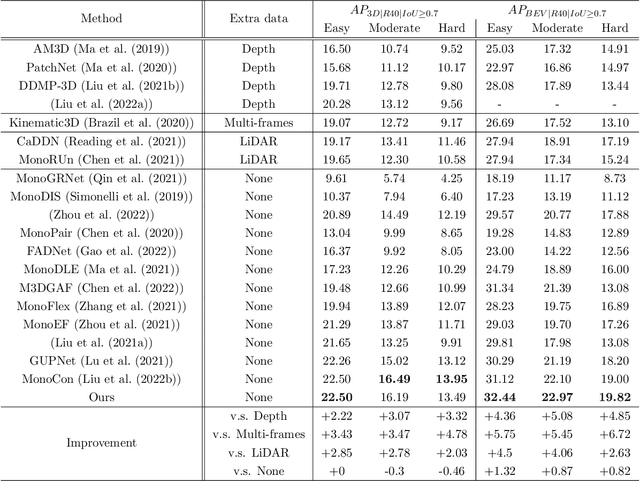
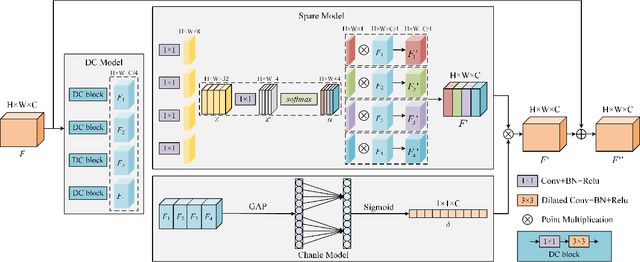
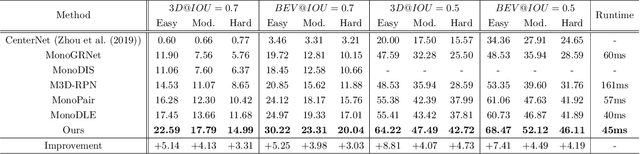
Due to the lack of depth information of images and poor detection accuracy in monocular 3D object detection, we proposed the instance depth for multi-scale monocular 3D object detection method. Firstly, to enhance the model's processing ability for different scale targets, a multi-scale perception module based on dilated convolution is designed, and the depth features containing multi-scale information are re-refined from both spatial and channel directions considering the inconsistency between feature maps of different scales. Firstly, we designed a multi-scale perception module based on dilated convolution to enhance the model's processing ability for different scale targets. The depth features containing multi-scale information are re-refined from spatial and channel directions considering the inconsistency between feature maps of different scales. Secondly, so as to make the model obtain better 3D perception, this paper proposed to use the instance depth information as an auxiliary learning task to enhance the spatial depth feature of the 3D target and use the sparse instance depth to supervise the auxiliary task. Finally, by verifying the proposed algorithm on the KITTI test set and evaluation set, the experimental results show that compared with the baseline method, the proposed method improves by 5.27\% in AP40 in the car category, effectively improving the detection performance of the monocular 3D object detection algorithm.
* Journal of Machine Learning Research