 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
TractGraphCNN: anatomically informed graph CNN for classification using diffusion MRI tractography
Jan 05, 2023
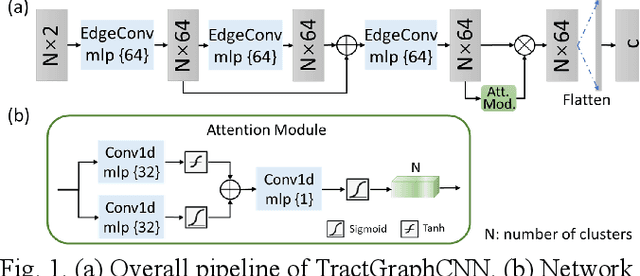
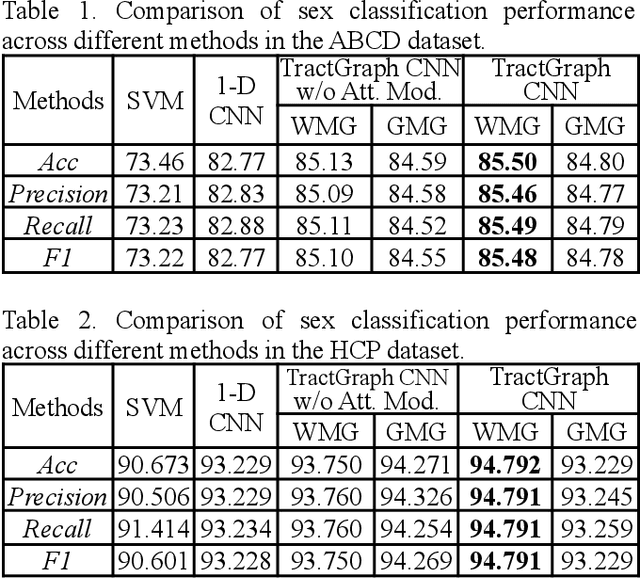
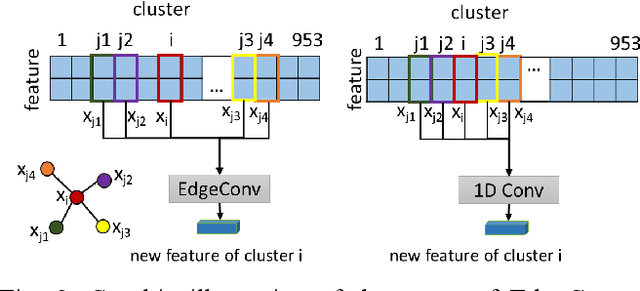
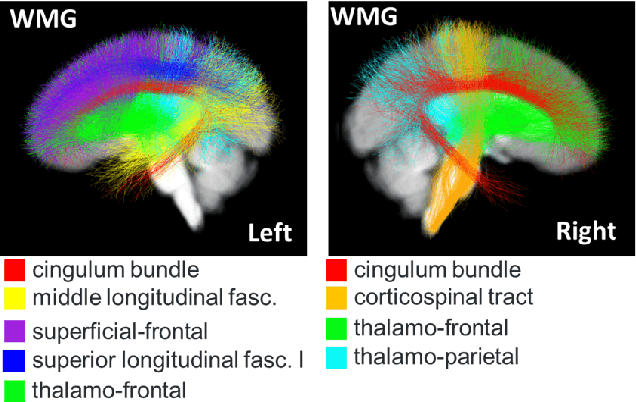
The structure and variability of the brain's connections can be investigated via prediction of non-imaging phenotypes using neural networks. However, known neuroanatomical relationships between input features are generally ignored in network design. We propose TractGraphCNN, a novel, anatomically informed graph CNN framework for machine learning tasks using diffusion MRI tractography. An EdgeConv module aggregates features from anatomically similar white matter connections indicated by graph edges, and an attention module enables interpretation of predictive white matter tracts. Results in a sex prediction testbed task demonstrate strong performance of TractGraphCNN in two large datasets (HCP and ABCD). Graphs informed by white matter geometry demonstrate higher performance than graphs informed by gray matter connectivity. Overall, the bilateral cingulum and left middle longitudinal fasciculus are consistently highly predictive of sex. This work shows the potential of incorporating anatomical information, especially known anatomical similarities between input features, to guide convolutions in neural networks.
SPRING: Situated Conversation Agent Pretrained with Multimodal Questions from Incremental Layout Graph
Jan 05, 2023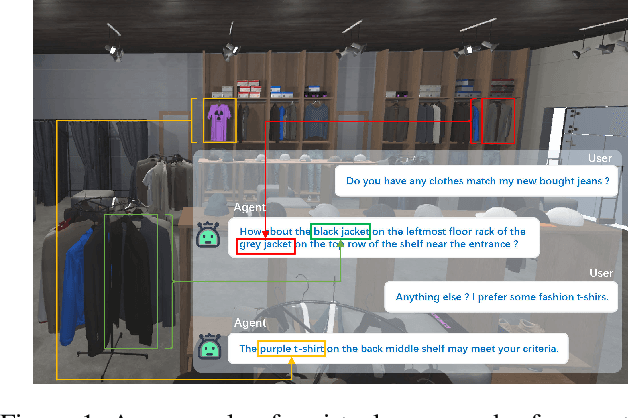

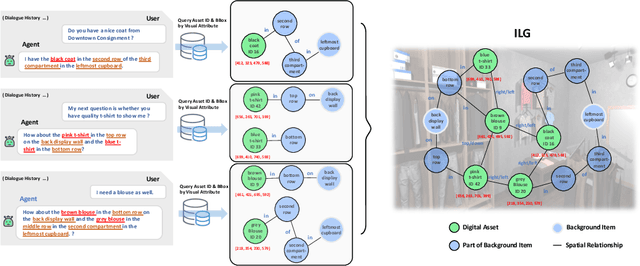
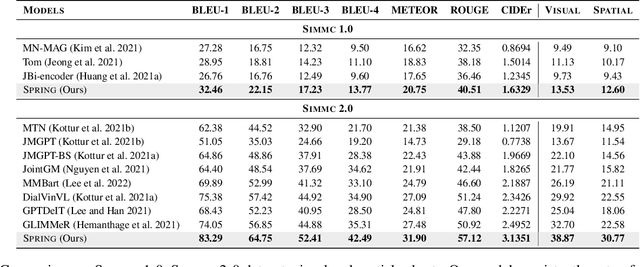
Existing multimodal conversation agents have shown impressive abilities to locate absolute positions or retrieve attributes in simple scenarios, but they fail to perform well when complex relative positions and information alignments are involved, which poses a bottleneck in response quality. In this paper, we propose a Situated Conversation Agent Petrained with Multimodal Questions from INcremental Layout Graph (SPRING) with abilities of reasoning multi-hops spatial relations and connecting them with visual attributes in crowded situated scenarios. Specifically, we design two types of Multimodal Question Answering (MQA) tasks to pretrain the agent. All QA pairs utilized during pretraining are generated from novel Incremental Layout Graphs (ILG). QA pair difficulty labels automatically annotated by ILG are used to promote MQA-based Curriculum Learning. Experimental results verify the SPRING's effectiveness, showing that it significantly outperforms state-of-the-art approaches on both SIMMC 1.0 and SIMMC 2.0 datasets.
Query-Driven Knowledge Base Completion using Multimodal Path Fusion over Multimodal Knowledge Graph
Dec 04, 2022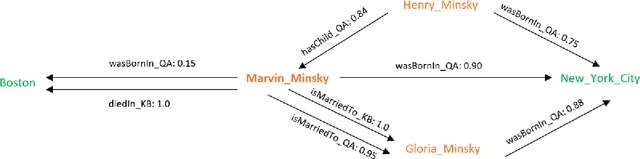

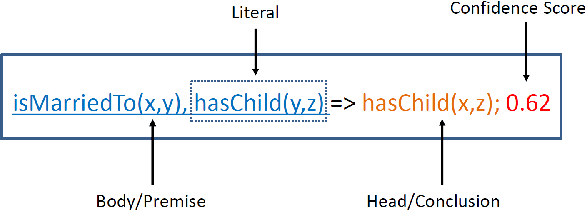
Over the past few years, large knowledge bases have been constructed to store massive amounts of knowledge. However, these knowledge bases are highly incomplete, for example, over 70% of people in Freebase have no known place of birth. To solve this problem, we propose a query-driven knowledge base completion system with multimodal fusion of unstructured and structured information. To effectively fuse unstructured information from the Web and structured information in knowledge bases to achieve good performance, our system builds multimodal knowledge graphs based on question answering and rule inference. We propose a multimodal path fusion algorithm to rank candidate answers based on different paths in the multimodal knowledge graphs, achieving much better performance than question answering, rule inference and a baseline fusion algorithm. To improve system efficiency, query-driven techniques are utilized to reduce the runtime of our system, providing fast responses to user queries. Extensive experiments have been conducted to demonstrate the effectiveness and efficiency of our system.
AirfRANS: High Fidelity Computational Fluid Dynamics Dataset for Approximating Reynolds-Averaged Navier-Stokes Solutions
Jan 06, 2023
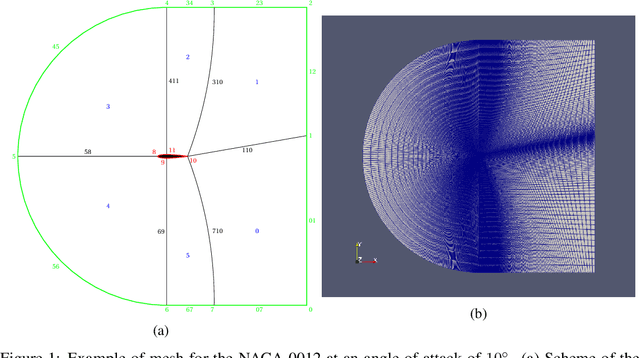


Surrogate models are necessary to optimize meaningful quantities in physical dynamics as their recursive numerical resolutions are often prohibitively expensive. It is mainly the case for fluid dynamics and the resolution of Navier-Stokes equations. However, despite the fast-growing field of data-driven models for physical systems, reference datasets representing real-world phenomena are lacking. In this work, we develop AirfRANS, a dataset for studying the two-dimensional incompressible steady-state Reynolds-Averaged Navier-Stokes equations over airfoils at a subsonic regime and for different angles of attacks. We also introduce metrics on the stress forces at the surface of geometries and visualization of boundary layers to assess the capabilities of models to accurately predict the meaningful information of the problem. Finally, we propose deep learning baselines on four machine learning tasks to study AirfRANS under different constraints for generalization considerations: big and scarce data regime, Reynolds number, and angle of attack extrapolation.
Topics as Entity Clusters: Entity-based Topics from Language Models and Graph Neural Networks
Jan 06, 2023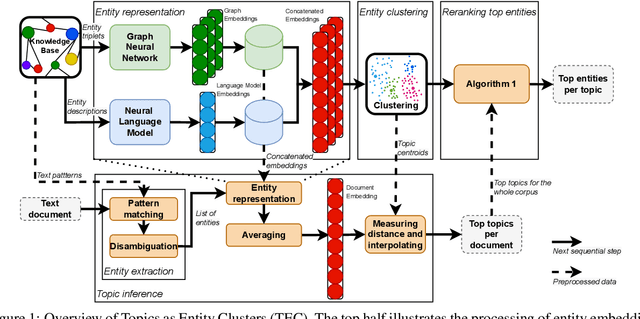
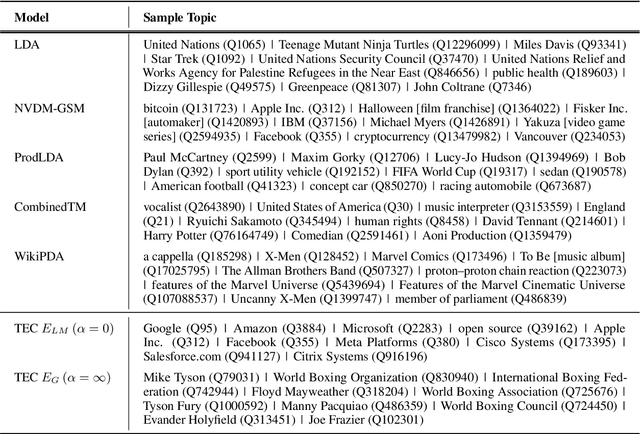
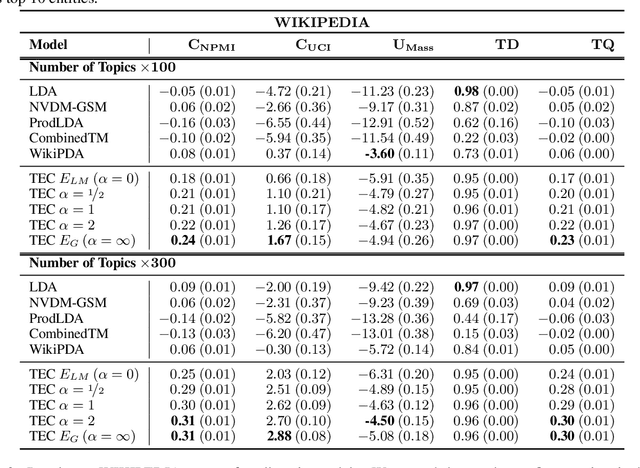
Topic models aim to reveal the latent structure behind a corpus, typically conducted over a bag-of-words representation of documents. In the context of topic modeling, most vocabulary is either irrelevant for uncovering underlying topics or contains strong relationships with relevant concepts, impacting the interpretability of these topics. Furthermore, their limited expressiveness and dependency on language demand considerable computation resources. Hence, we propose a novel approach for cluster-based topic modeling that employs conceptual entities. Entities are language-agnostic representations of real-world concepts rich in relational information. To this end, we extract vector representations of entities from (i) an encyclopedic corpus using a language model; and (ii) a knowledge base using a graph neural network. We demonstrate that our approach consistently outperforms other state-of-the-art topic models across coherency metrics and find that the explicit knowledge encoded in the graph-based embeddings provides more coherent topics than the implicit knowledge encoded with the contextualized embeddings of language models.
Optimization of the energy efficiency in Smart Internet of Vehicles assisted by MEC
Jan 14, 2023Smart Internet of Vehicles (IoV) as a promising application in Internet of Things (IoT) emerges with the development of the fifth generation mobile communication (5G). Nevertheless, the heterogeneous requirements of sufficient battery capacity, powerful computing ability and energy efficiency for electric vehicles face great challenges due to the explosive data growth in 5G and the sixth generation of mobile communication (6G) networks. In order to alleviate the deficiencies mentioned above, this paper proposes a mobile edge computing (MEC) enabled IoV system, in which electric vehicle nodes (eVNs) upload and download data through an anchor node (AN) which is integrated with a MEC server. Meanwhile, the anchor node transmitters radio signal to electric vehicles with simultaneous wireless information and power transfer (SWIPT) technology so as to compensate the battery limitation of eletric vehicles. Moreover, the spectrum efficiency is further improved by multi-input and multi-output (MIMO) and full-duplex (FD) technologies which is equipped at the anchor node. In consideration of the issues above, we maximize the average energy efficiency of electric vehicles by jointly optimize the CPU frequency, vehicle transmitting power, computing tasks and uplink rate. Since the problem is nonconvex, we propose a novel alternate interior-point iterative scheme (AIIS) under the constraints of computing tasks, energy consumption and time latency. Results and discussion section verifies the effectiveness of the proposed AIIS scheme comparing with the benchmark schemes.
* 17 pages, 9 figures, EURASIP J. Adv. Signal Process
Graph Topology Learning Under Privacy Constraints
Jan 17, 2023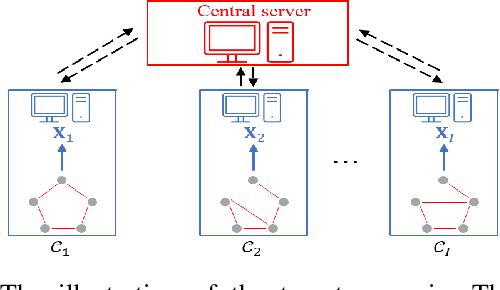
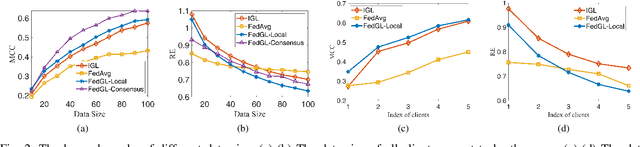
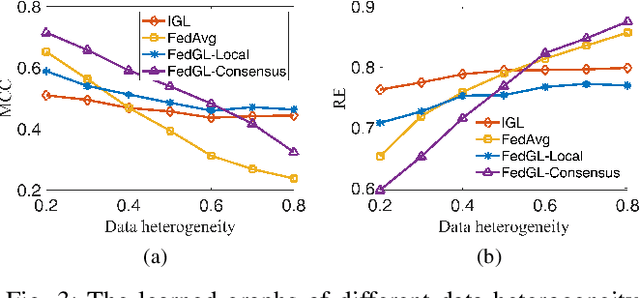
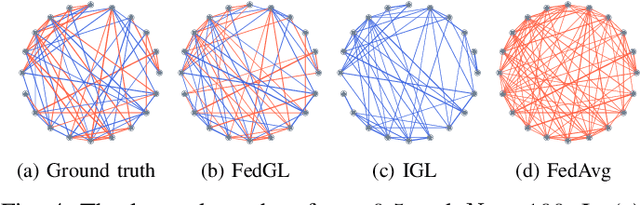
Graph learning, which aims to infer the underlying topology behind high dimension data, has attracted intense attention. In this study, we shed a new light on graph learning by considering a pragmatic scenario where data are privacy sensitive and located in separated clients (devices or organizations). The main difficulty in learning graphs in this scenario is that we cannot process all the data in a central server, because the data are not allowed to leave the local clients due to privacy concerns. The problem becomes more challenging when data of different clients are non-IID, since it is unreasonable to learn a global graph for heterogeneous data. To address these issues, we propose a novel framework in which a personalized graph for each client and a consensus graph are jointly learned in a federated fashion. Specifically, we commute model updates instead of raw data to the central server in the proposed federated algorithm. A provable convergence analysis shows that the algorithm enjoys $\mathcal{O}(1/T)$ convergence rate. To further enhance privacy, we design a deferentially privacy algorithm to prevent the information of the raw data from being leaked when transferring model updates. A theoretical guidance is provided on how to ensure that the algorithm satisfies differential privacy. We also analyze the impact of differential privacy on the convergence of our algorithm. Finally, extensive experiments on both synthetic and real world data are carried out to validate the proposed models and algorithms. Experimental results illustrate that our framework is able to learn graphs effectively in the target scenario.
Cooperation Learning Enhanced Colonic Polyp Segmentation Based on Transformer-CNN Fusion
Jan 17, 2023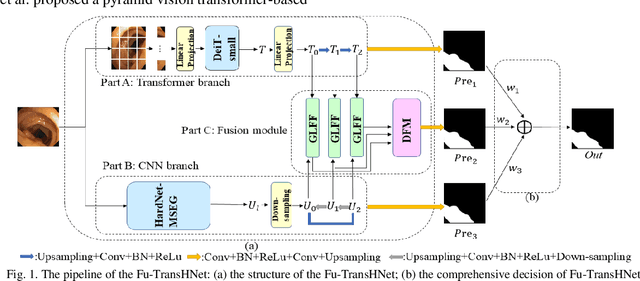
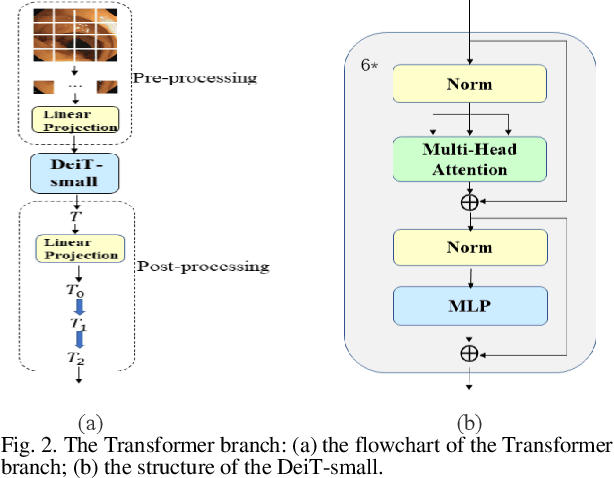
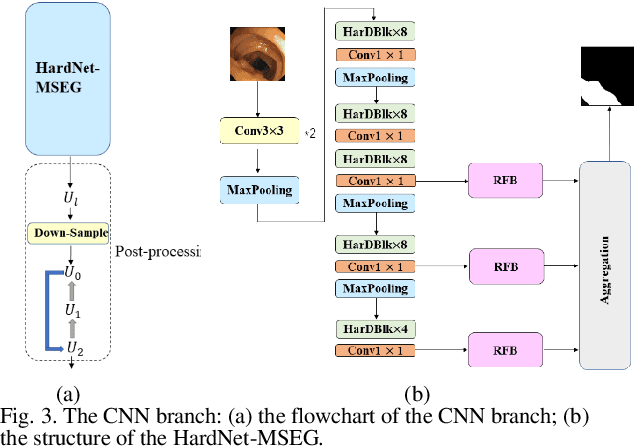
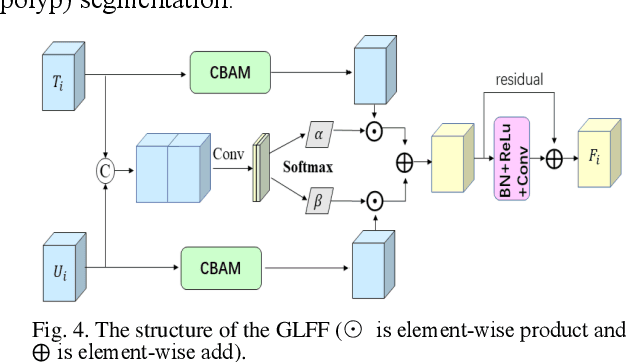
Traditional segmentation methods for colonic polyps are mainly designed based on low-level features. They could not accurately extract the location of small colonic polyps. Although the existing deep learning methods can improve the segmentation accuracy, their effects are still unsatisfied. To meet the above challenges, we propose a hybrid network called Fusion-Transformer-HardNetMSEG (i.e., Fu-TransHNet) in this study. Fu-TransHNet uses deep learning of different mechanisms to fuse each other and is enhanced with multi-view collaborative learning techniques. Firstly, the Fu-TransHNet utilizes the Transformer branch and the CNN branch to realize the global feature learning and local feature learning, respectively. Secondly, a fusion module is designed to integrate the features from two branches. The fusion module consists of two parts: 1) the Global-Local Feature Fusion (GLFF) part and 2) the Dense Fusion of Multi-scale features (DFM) part. The former is built to compensate the feature information mission from two branches at the same scale; the latter is constructed to enhance the feature representation. Thirdly, the above two branches and fusion modules utilize multi-view cooperative learning techniques to obtain their respective weights that denote their importance and then make a final decision comprehensively. Experimental results showed that the Fu-TransHNet network was superior to the existing methods on five widely used benchmark datasets. In particular, on the ETIS-LaribPolypDB dataset containing many small-target colonic polyps, the mDice obtained by Fu-TransHNet were 12.4% and 6.2% higher than the state-of-the-art methods HardNet-MSEG and TransFuse-s, respectively.
Preserving Privacy in Surgical Video Analysis Using Artificial Intelligence: A Deep Learning Classifier to Identify Out-of-Body Scenes in Endoscopic Videos
Jan 17, 2023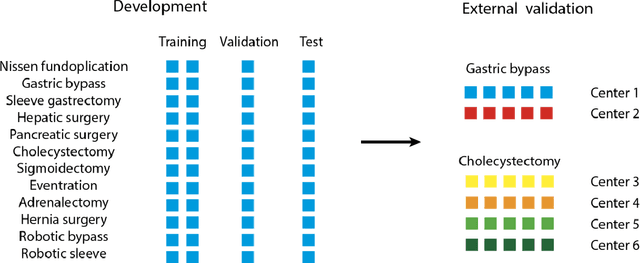
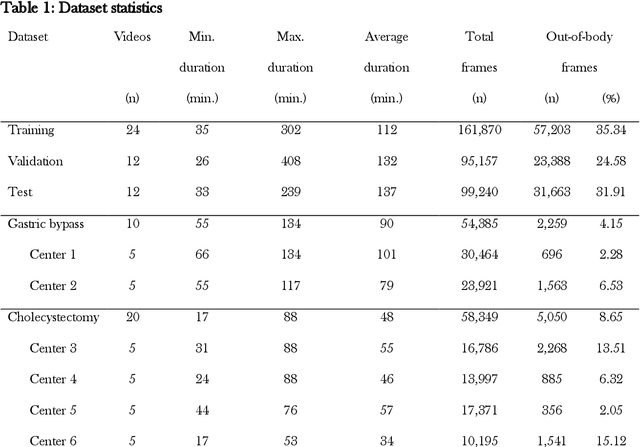
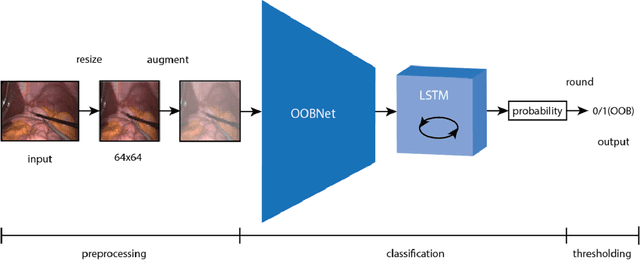
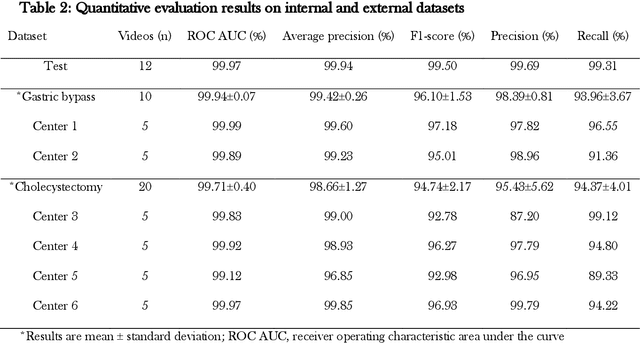
Objective: To develop and validate a deep learning model for the identification of out-of-body images in endoscopic videos. Background: Surgical video analysis facilitates education and research. However, video recordings of endoscopic surgeries can contain privacy-sensitive information, especially if out-of-body scenes are recorded. Therefore, identification of out-of-body scenes in endoscopic videos is of major importance to preserve the privacy of patients and operating room staff. Methods: A deep learning model was trained and evaluated on an internal dataset of 12 different types of laparoscopic and robotic surgeries. External validation was performed on two independent multicentric test datasets of laparoscopic gastric bypass and cholecystectomy surgeries. All images extracted from the video datasets were annotated as inside or out-of-body. Model performance was evaluated compared to human ground truth annotations measuring the receiver operating characteristic area under the curve (ROC AUC). Results: The internal dataset consisting of 356,267 images from 48 videos and the two multicentric test datasets consisting of 54,385 and 58,349 images from 10 and 20 videos, respectively, were annotated. Compared to ground truth annotations, the model identified out-of-body images with 99.97% ROC AUC on the internal test dataset. Mean $\pm$ standard deviation ROC AUC on the multicentric gastric bypass dataset was 99.94$\pm$0.07% and 99.71$\pm$0.40% on the multicentric cholecystectomy dataset, respectively. Conclusion: The proposed deep learning model can reliably identify out-of-body images in endoscopic videos. The trained model is publicly shared. This facilitates privacy preservation in surgical video analysis.
IDMS: Instance Depth for Multi-scale Monocular 3D Object Detection
Dec 03, 2022
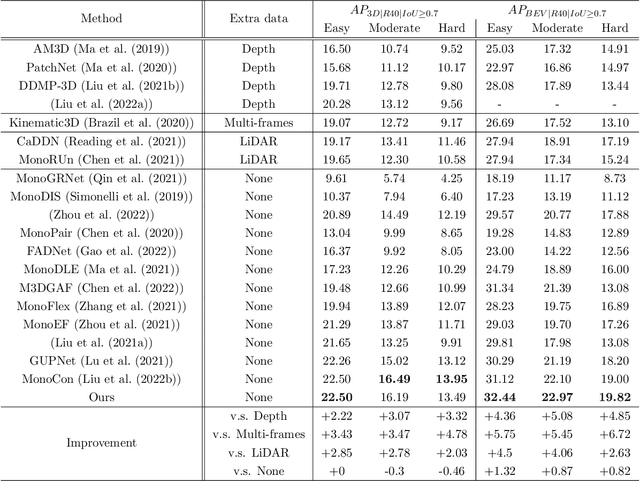
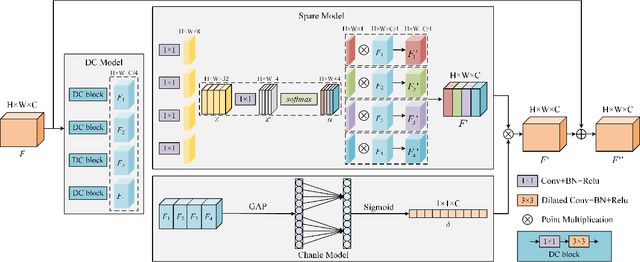
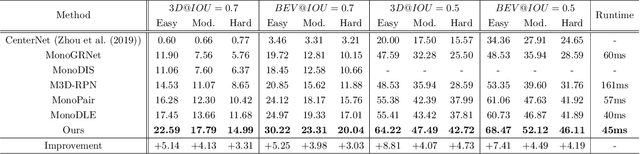
Due to the lack of depth information of images and poor detection accuracy in monocular 3D object detection, we proposed the instance depth for multi-scale monocular 3D object detection method. Firstly, to enhance the model's processing ability for different scale targets, a multi-scale perception module based on dilated convolution is designed, and the depth features containing multi-scale information are re-refined from both spatial and channel directions considering the inconsistency between feature maps of different scales. Firstly, we designed a multi-scale perception module based on dilated convolution to enhance the model's processing ability for different scale targets. The depth features containing multi-scale information are re-refined from spatial and channel directions considering the inconsistency between feature maps of different scales. Secondly, so as to make the model obtain better 3D perception, this paper proposed to use the instance depth information as an auxiliary learning task to enhance the spatial depth feature of the 3D target and use the sparse instance depth to supervise the auxiliary task. Finally, by verifying the proposed algorithm on the KITTI test set and evaluation set, the experimental results show that compared with the baseline method, the proposed method improves by 5.27\% in AP40 in the car category, effectively improving the detection performance of the monocular 3D object detection algorithm.
* Journal of Machine Learning Research