 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-Sem Fusion: Multimodal Semantic Fusion for 3D Object Detection
Dec 10, 2022
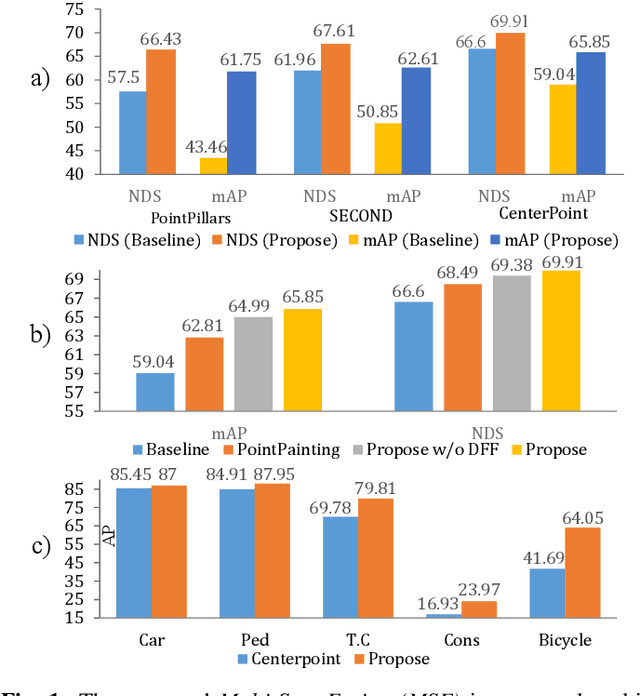
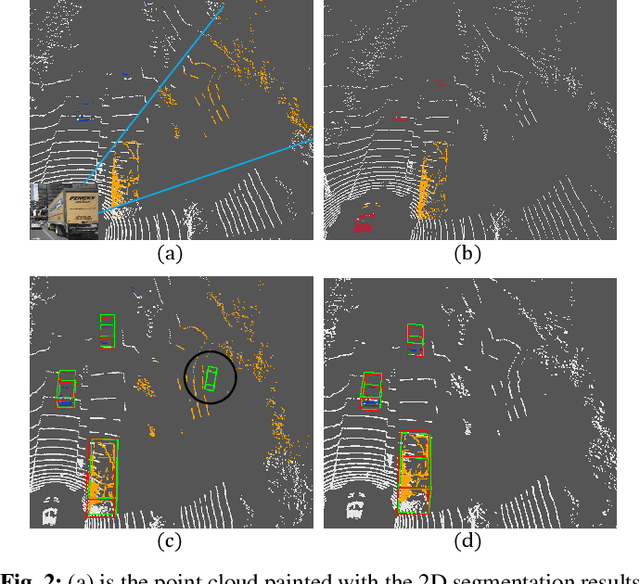
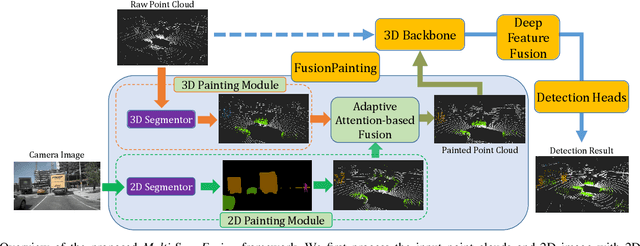
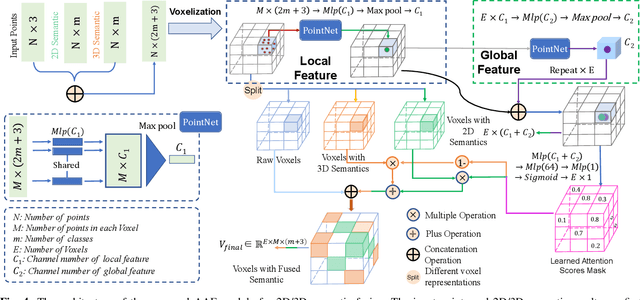
LiDAR-based 3D Object detectors have achieved impressive performances in many benchmarks, however, multisensors fusion-based techniques are promising to further improve the results. PointPainting, as a recently proposed framework, can add the semantic information from the 2D image into the 3D LiDAR point by the painting operation to boost the detection performance. However, due to the limited resolution of 2D feature maps, severe boundary-blurring effect happens during re-projection of 2D semantic segmentation into the 3D point clouds. To well handle this limitation, a general multimodal fusion framework MSF has been proposed to fuse the semantic information from both the 2D image and 3D points scene parsing results. Specifically, MSF includes three main modules. First, SOTA off-the-shelf 2D/3D semantic segmentation approaches are employed to generate the parsing results for 2D images and 3D point clouds. The 2D semantic information is further re-projected into the 3D point clouds with calibrated parameters. To handle the misalignment between the 2D and 3D parsing results, an AAF module is proposed to fuse them by learning an adaptive fusion score. Then the point cloud with the fused semantic label is sent to the following 3D object detectors. Furthermore, we propose a DFF module to aggregate deep features in different levels to boost the final detection performance. The effectiveness of the framework has been verified on two public large-scale 3D object detection benchmarks by comparing with different baselines. The experimental results show that the proposed fusion strategies can significantly improve the detection performance compared to the methods using only point clouds and the methods using only 2D semantic information. Most importantly, the proposed approach significantly outperforms other approaches and sets new SOTA results on the nuScenes testing benchmark.
TAAL: Test-time Augmentation for Active Learning in Medical Image Segmentation
Jan 16, 2023Deep learning methods typically depend on the availability of labeled data, which is expensive and time-consuming to obtain. Active learning addresses such effort by prioritizing which samples are best to annotate in order to maximize the performance of the task model. While frameworks for active learning have been widely explored in the context of classification of natural images, they have been only sparsely used in medical image segmentation. The challenge resides in obtaining an uncertainty measure that reveals the best candidate data for annotation. This paper proposes Test-time Augmentation for Active Learning (TAAL), a novel semi-supervised active learning approach for segmentation that exploits the uncertainty information offered by data transformations. Our method applies cross-augmentation consistency during training and inference to both improve model learning in a semi-supervised fashion and identify the most relevant unlabeled samples to annotate next. In addition, our consistency loss uses a modified version of the JSD to further improve model performance. By relying on data transformations rather than on external modules or simple heuristics typically used in uncertainty-based strategies, TAAL emerges as a simple, yet powerful task-agnostic semi-supervised active learning approach applicable to the medical domain. Our results on a publicly-available dataset of cardiac images show that TAAL outperforms existing baseline methods in both fully-supervised and semi-supervised settings. Our implementation is publicly available on https://github.com/melinphd/TAAL.
Adaptive Depth Graph Attention Networks
Jan 16, 2023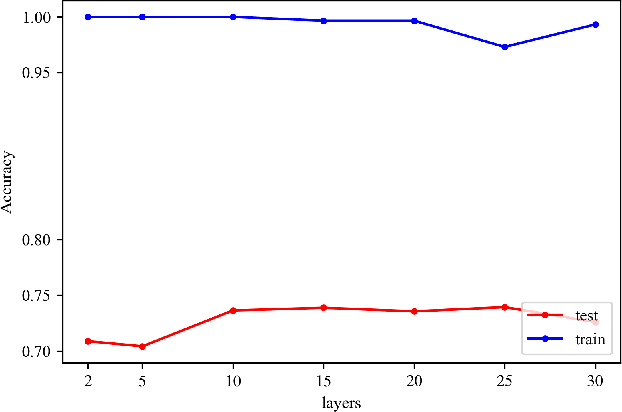

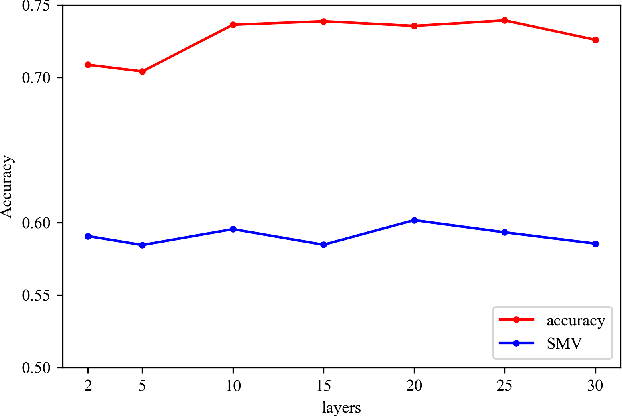

As one of the most popular GNN architectures, the graph attention networks (GAT) is considered the most advanced learning architecture for graph representation and has been widely used in various graph mining tasks with impressive results. However, since GAT was proposed, none of the existing studies have provided systematic insight into the relationship between the performance of GAT and the number of layers, which is a critical issue in guiding model performance improvement. In this paper, we perform a systematic experimental evaluation and based on the experimental results, we find two important facts: (1) the main factor limiting the accuracy of the GAT model as the number of layers increases is the oversquashing phenomenon; (2) among the previous improvements applied to the GNN model, only the residual connection can significantly improve the GAT model performance. We combine these two important findings to provide a theoretical explanation that it is the residual connection that mitigates the loss of original feature information due to oversquashing and thus improves the deep GAT model performance. This provides empirical insights and guidelines for researchers to design the GAT variant model with appropriate depth and well performance. To demonstrate the effectiveness of our proposed guidelines, we propose a GAT variant model-ADGAT that adaptively selects the number of layers based on the sparsity of the graph, and experimentally demonstrate that the effectiveness of our model is significantly improved over the original GAT.
$l_{1-2}$ GLasso: $L_{1-2}$ Regularized Multi-task Graphical Lasso for Joint Estimation of eQTL Mapping and Gene Network
Jan 04, 2023A critical problem in genetics is to discover how gene expression is regulated within cells. Two major tasks of regulatory association learning are : (i) identifying SNP-gene relationships, known as eQTL mapping, and (ii) determining gene-gene relationships, known as gene network estimation. To share information between these two tasks, we focus on the unified model for joint estimation of eQTL mapping and gene network, and propose a $L_{1-2}$ regularized multi-task graphical lasso, named $L_{1-2}$ GLasso. Numerical experiments on artificial datasets demonstrate the competitive performance of $L_{1-2}$ GLasso on capturing the true sparse structure of eQTL mapping and gene network. $L_{1-2}$ GLasso is further applied to real dataset of ADNI-1 and experimental results show that $L_{1 -2}$ GLasso can obtain sparser and more accurate solutions than other commonly-used methods.
DETR4D: Direct Multi-View 3D Object Detection with Sparse Attention
Dec 15, 2022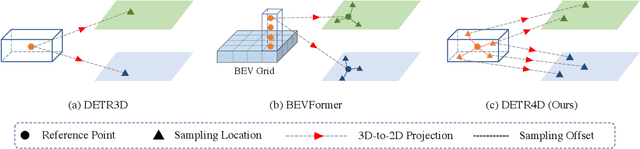
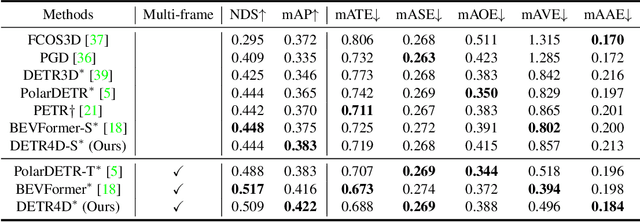
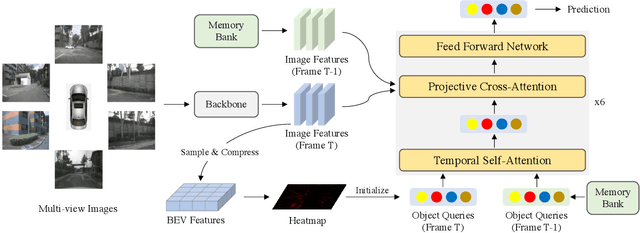
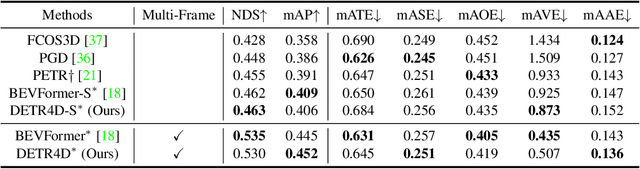
3D object detection with surround-view images is an essential task for autonomous driving. In this work, we propose DETR4D, a Transformer-based framework that explores sparse attention and direct feature query for 3D object detection in multi-view images. We design a novel projective cross-attention mechanism for query-image interaction to address the limitations of existing methods in terms of geometric cue exploitation and information loss for cross-view objects. In addition, we introduce a heatmap generation technique that bridges 3D and 2D spaces efficiently via query initialization. Furthermore, unlike the common practice of fusing intermediate spatial features for temporal aggregation, we provide a new perspective by introducing a novel hybrid approach that performs cross-frame fusion over past object queries and image features, enabling efficient and robust modeling of temporal information. Extensive experiments on the nuScenes dataset demonstrate the effectiveness and efficiency of the proposed DETR4D.
Random Information Sharing over Social Networks
Mar 04, 2022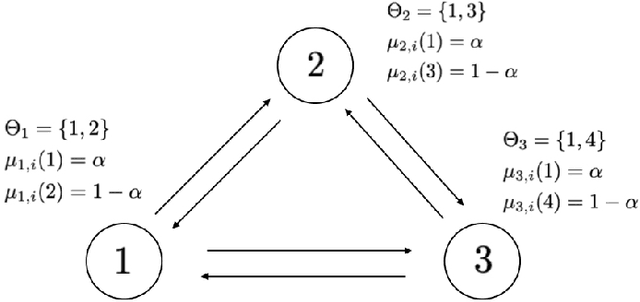
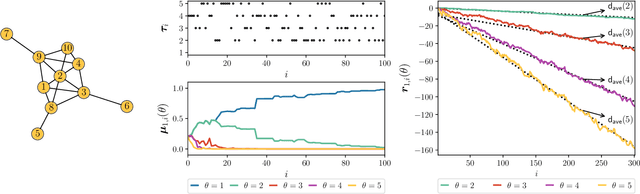
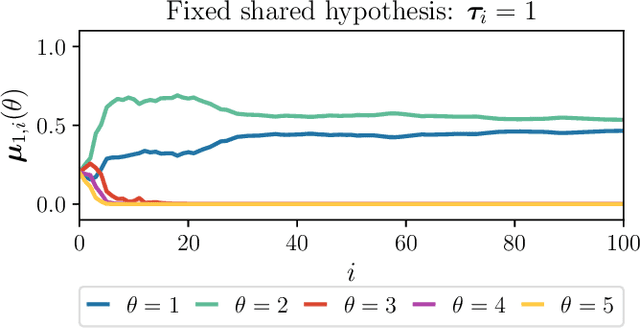

This work studies the learning process over social networks under partial and random information sharing. In traditional social learning, agents exchange full information with each other while trying to infer the true state of nature. We study the case where agents share information about only one hypothesis, i.e., the trending topic, which can be randomly changing at every iteration. We show that agents can learn the true hypothesis even if they do not discuss it, at rates comparable to traditional social learning. We also show that using one's own belief as a prior for estimating the neighbors' non-transmitted components might create opinion clusters that prevent learning with full confidence. This practice however avoids the complete rejection of the truth.
Multi-person 3D pose estimation from unlabelled data
Dec 16, 2022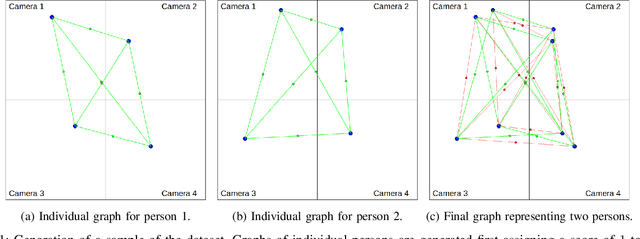
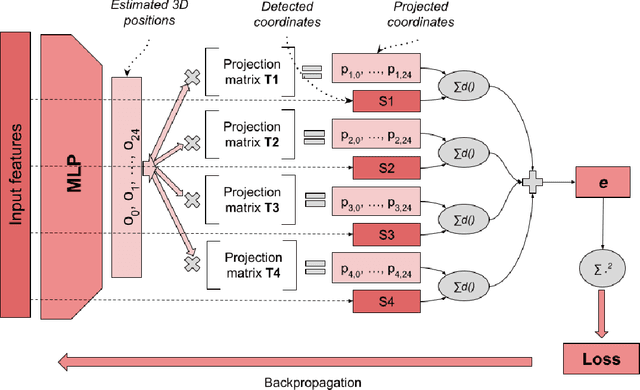

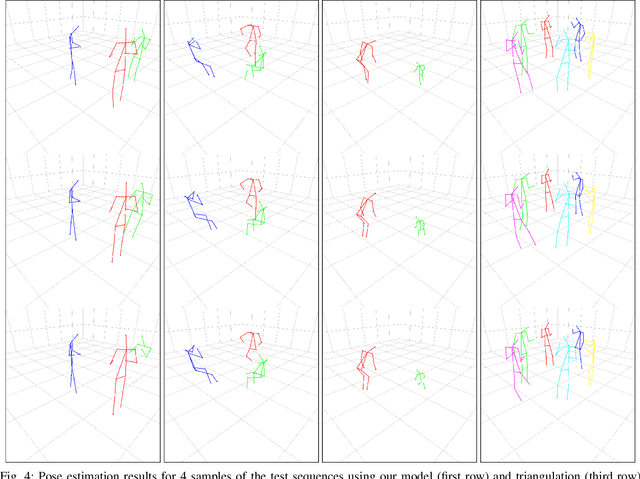
Its numerous applications make multi-human 3D pose estimation a remarkably impactful area of research. Nevertheless, assuming a multiple-view system composed of several regular RGB cameras, 3D multi-pose estimation presents several challenges. First of all, each person must be uniquely identified in the different views to separate the 2D information provided by the cameras. Secondly, the 3D pose estimation process from the multi-view 2D information of each person must be robust against noise and potential occlusions in the scenario. In this work, we address these two challenges with the help of deep learning. Specifically, we present a model based on Graph Neural Networks capable of predicting the cross-view correspondence of the people in the scenario along with a Multilayer Perceptron that takes the 2D points to yield the 3D poses of each person. These two models are trained in a self-supervised manner, thus avoiding the need for large datasets with 3D annotations.
Generalization Bounds for Inductive Matrix Completion in Low-noise Settings
Dec 16, 2022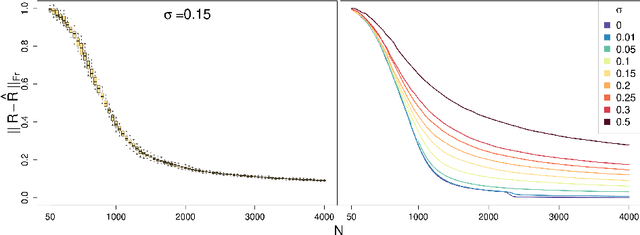
We study inductive matrix completion (matrix completion with side information) under an i.i.d. subgaussian noise assumption at a low noise regime, with uniform sampling of the entries. We obtain for the first time generalization bounds with the following three properties: (1) they scale like the standard deviation of the noise and in particular approach zero in the exact recovery case; (2) even in the presence of noise, they converge to zero when the sample size approaches infinity; and (3) for a fixed dimension of the side information, they only have a logarithmic dependence on the size of the matrix. Differently from many works in approximate recovery, we present results both for bounded Lipschitz losses and for the absolute loss, with the latter relying on Talagrand-type inequalities. The proofs create a bridge between two approaches to the theoretical analysis of matrix completion, since they consist in a combination of techniques from both the exact recovery literature and the approximate recovery literature.
* 30 Pages, 1 figure; Accepted for publication at AAAI 2023
Automated Cancer Subtyping via Vector Quantization Mutual Information Maximization
Jun 22, 2022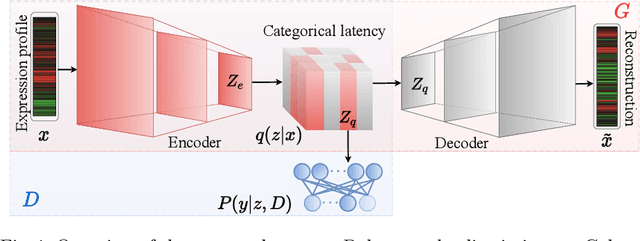
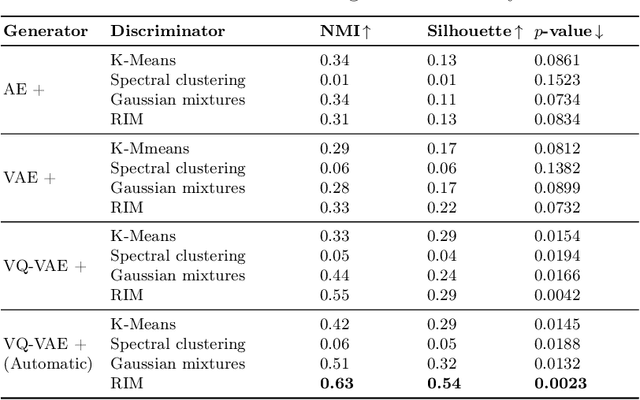
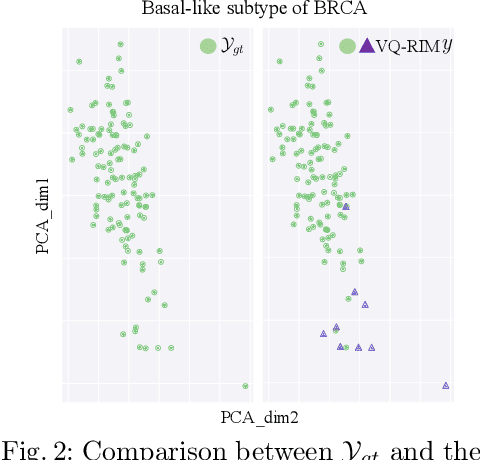
Cancer subtyping is crucial for understanding the nature of tumors and providing suitable therapy. However, existing labelling methods are medically controversial, and have driven the process of subtyping away from teaching signals. Moreover, cancer genetic expression profiles are high-dimensional, scarce, and have complicated dependence, thereby posing a serious challenge to existing subtyping models for outputting sensible clustering. In this study, we propose a novel clustering method for exploiting genetic expression profiles and distinguishing subtypes in an unsupervised manner. The proposed method adaptively learns categorical correspondence from latent representations of expression profiles to the subtypes output by the model. By maximizing the problem -- agnostic mutual information between input expression profiles and output subtypes, our method can automatically decide a suitable number of subtypes. Through experiments, we demonstrate that our proposed method can refine existing controversial labels, and, by further medical analysis, this refinement is proven to have a high correlation with cancer survival rates.
TractGraphCNN: anatomically informed graph CNN for classification using diffusion MRI tractography
Jan 05, 2023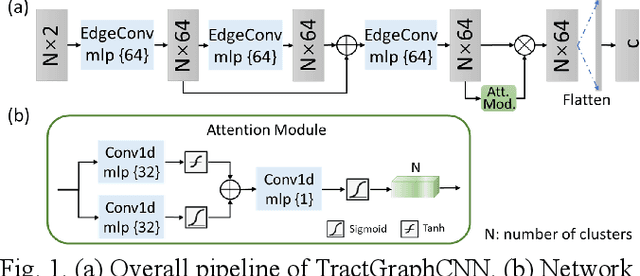
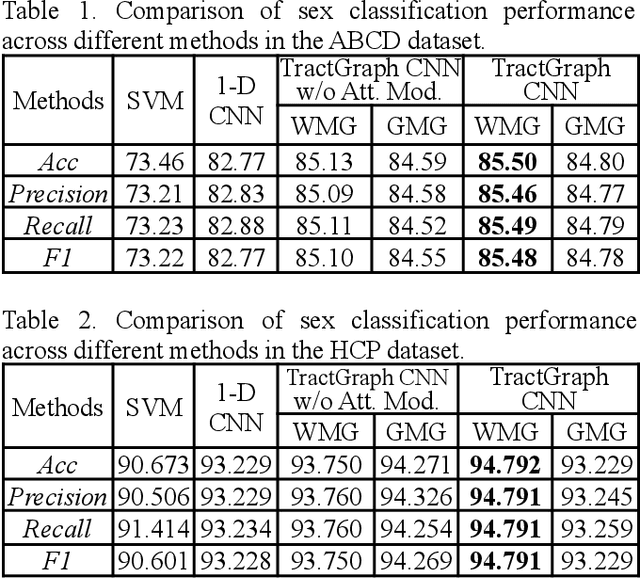
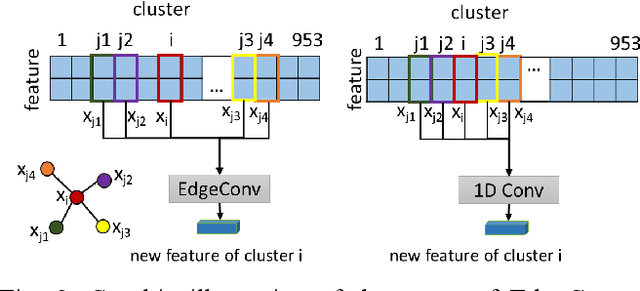
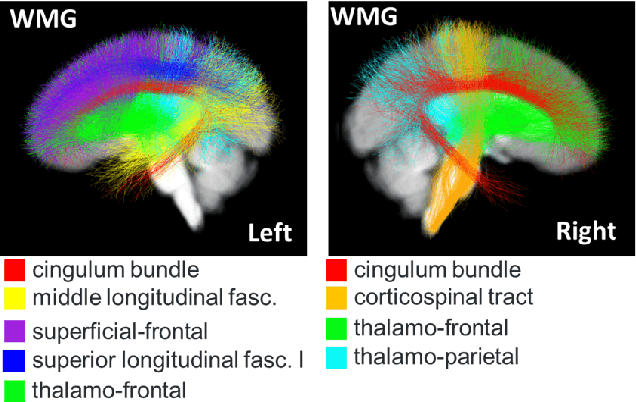
The structure and variability of the brain's connections can be investigated via prediction of non-imaging phenotypes using neural networks. However, known neuroanatomical relationships between input features are generally ignored in network design. We propose TractGraphCNN, a novel, anatomically informed graph CNN framework for machine learning tasks using diffusion MRI tractography. An EdgeConv module aggregates features from anatomically similar white matter connections indicated by graph edges, and an attention module enables interpretation of predictive white matter tracts. Results in a sex prediction testbed task demonstrate strong performance of TractGraphCNN in two large datasets (HCP and ABCD). Graphs informed by white matter geometry demonstrate higher performance than graphs informed by gray matter connectivity. Overall, the bilateral cingulum and left middle longitudinal fasciculus are consistently highly predictive of sex. This work shows the potential of incorporating anatomical information, especially known anatomical similarities between input features, to guide convolutions in neural networks.