 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards Models that Can See and Read
Jan 18, 2023
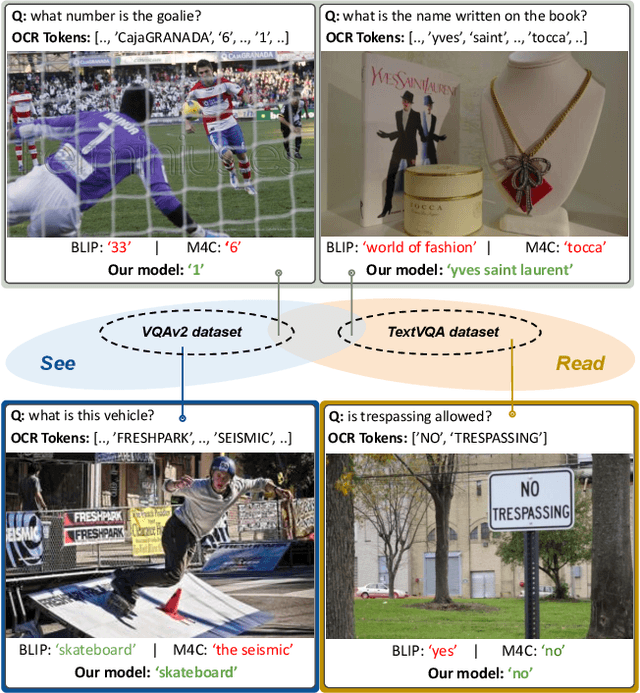

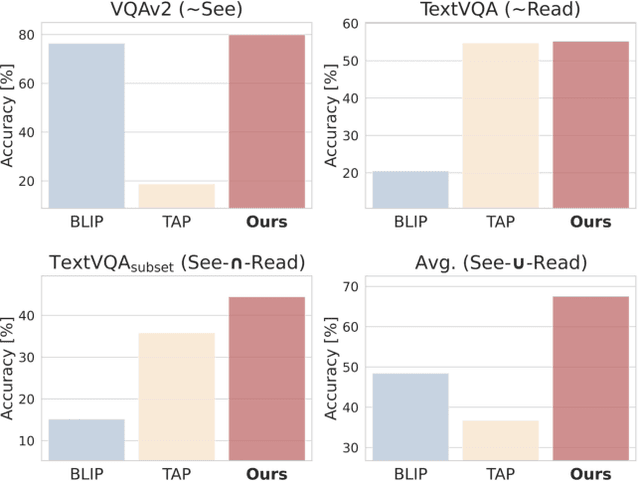
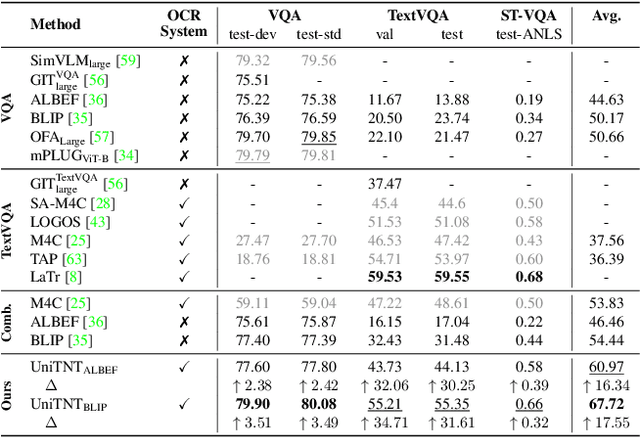
Visual Question Answering (VQA) and Image Captioning (CAP), which are among the most popular vision-language tasks, have analogous scene-text versions that require reasoning from the text in the image. Despite the obvious resemblance between them, the two are treated independently, yielding task-specific methods that can either see or read, but not both. In this work, we conduct an in-depth analysis of this phenomenon and propose UniTNT, a Unified Text-Non-Text approach, which grants existing multimodal architectures scene-text understanding capabilities. Specifically, we treat scene-text information as an additional modality, fusing it with any pretrained encoder-decoder-based architecture via designated modules. Thorough experiments reveal that UniTNT leads to the first single model that successfully handles both task types. Moreover, we show that scene-text understanding capabilities can boost vision-language models' performance on VQA and CAP by up to 3.49% and 0.7 CIDEr, respectively.
Position-Aware Contrastive Alignment for Referring Image Segmentation
Dec 27, 2022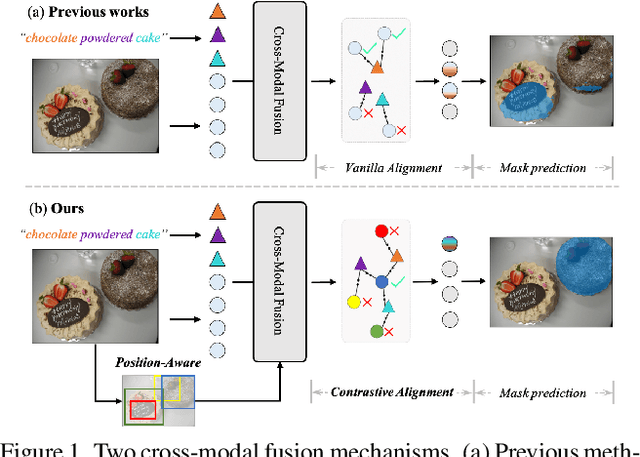

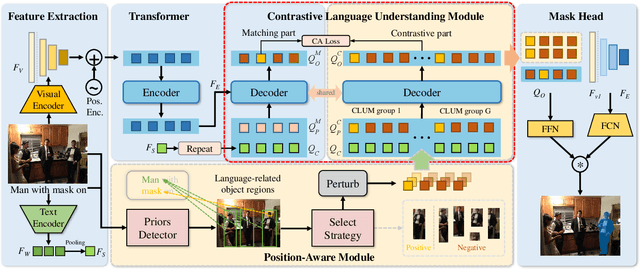
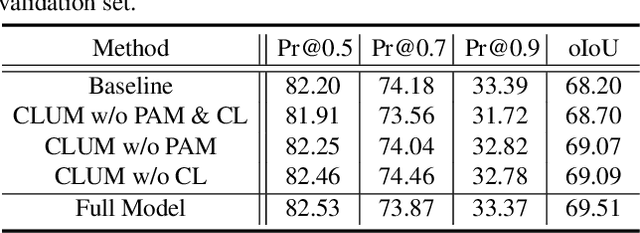
Referring image segmentation aims to segment the target object described by a given natural language expression. Typically, referring expressions contain complex relationships between the target and its surrounding objects. The main challenge of this task is to understand the visual and linguistic content simultaneously and to find the referred object accurately among all instances in the image. Currently, the most effective way to solve the above problem is to obtain aligned multi-modal features by computing the correlation between visual and linguistic feature modalities under the supervision of the ground-truth mask. However, existing paradigms have difficulty in thoroughly understanding visual and linguistic content due to the inability to perceive information directly about surrounding objects that refer to the target. This prevents them from learning aligned multi-modal features, which leads to inaccurate segmentation. To address this issue, we present a position-aware contrastive alignment network (PCAN) to enhance the alignment of multi-modal features by guiding the interaction between vision and language through prior position information. Our PCAN consists of two modules: 1) Position Aware Module (PAM), which provides position information of all objects related to natural language descriptions, and 2) Contrastive Language Understanding Module (CLUM), which enhances multi-modal alignment by comparing the features of the referred object with those of related objects. Extensive experiments on three benchmarks demonstrate our PCAN performs favorably against the state-of-the-art methods. Our code will be made publicly available.
Oversquashing in GNNs through the lens of information contraction and graph expansion
Aug 06, 2022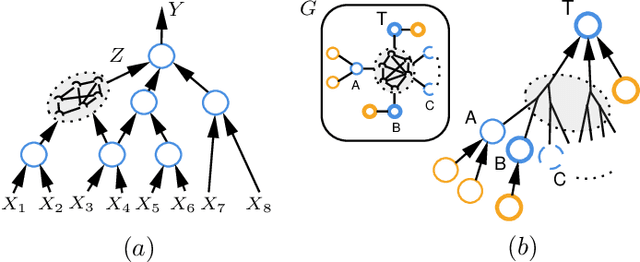
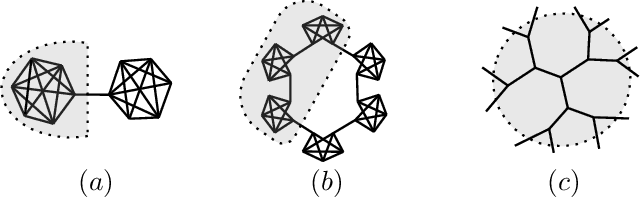
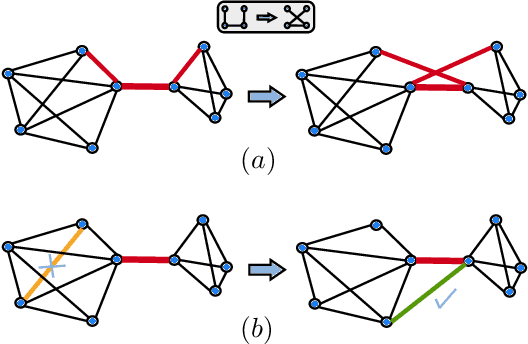
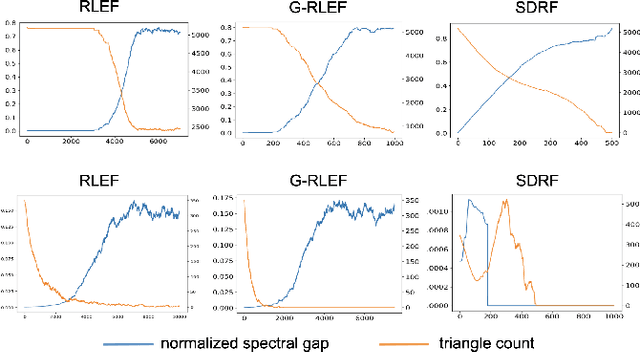
The quality of signal propagation in message-passing graph neural networks (GNNs) strongly influences their expressivity as has been observed in recent works. In particular, for prediction tasks relying on long-range interactions, recursive aggregation of node features can lead to an undesired phenomenon called "oversquashing". We present a framework for analyzing oversquashing based on information contraction. Our analysis is guided by a model of reliable computation due to von Neumann that lends a new insight into oversquashing as signal quenching in noisy computation graphs. Building on this, we propose a graph rewiring algorithm aimed at alleviating oversquashing. Our algorithm employs a random local edge flip primitive motivated by an expander graph construction. We compare the spectral expansion properties of our algorithm with that of an existing curvature-based non-local rewiring strategy. Synthetic experiments show that while our algorithm in general has a slower rate of expansion, it is overall computationally cheaper, preserves the node degrees exactly and never disconnects the graph.
Everything is Connected: Graph Neural Networks
Jan 19, 2023In many ways, graphs are the main modality of data we receive from nature. This is due to the fact that most of the patterns we see, both in natural and artificial systems, are elegantly representable using the language of graph structures. Prominent examples include molecules (represented as graphs of atoms and bonds), social networks and transportation networks. This potential has already been seen by key scientific and industrial groups, with already-impacted application areas including traffic forecasting, drug discovery, social network analysis and recommender systems. Further, some of the most successful domains of application for machine learning in previous years -- images, text and speech processing -- can be seen as special cases of graph representation learning, and consequently there has been significant exchange of information between these areas. The main aim of this short survey is to enable the reader to assimilate the key concepts in the area, and position graph representation learning in a proper context with related fields.
Towards Rigorous Understanding of Neural Networks via Semantics-preserving Transformations
Jan 19, 2023
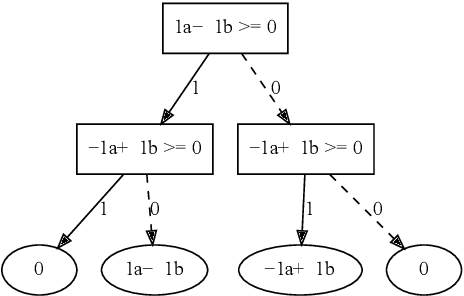
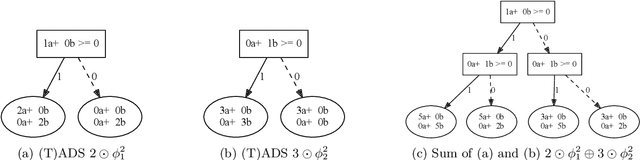
In this paper we present an algebraic approach to the precise and global verification and explanation of \emph{Rectifier Neural Networks}, a subclass of \emph{Piece-wise Linear Neural Networks} (PLNNs), i.e., networks that semantically represent piece-wise affine functions. Key to our approach is the symbolic execution of these networks that allows the construction of semantically equivalent \emph{Typed Affine Decision Structures} (TADS). Due to their deterministic and sequential nature, TADS can, similarly to decision trees, be considered as white-box models and therefore as precise solutions to the model and outcome explanation problem. TADS are linear algebras which allows one to elegantly compare Rectifier Networks for equivalence or similarity, both with precise diagnostic information in case of failure, and to characterize their classification potential by precisely characterizing the set of inputs that are specifically classified or the set of inputs where two network-based classifiers differ. All phenomena are illustrated along a detailed discussion of a minimal, illustrative example: the continuous XOR function.
Spatio-Temporal Context Modeling for Road Obstacle Detection
Jan 19, 2023Road obstacle detection is an important problem for vehicle driving safety. In this paper, we aim to obtain robust road obstacle detection based on spatio-temporal context modeling. Firstly, a data-driven spatial context model of the driving scene is constructed with the layouts of the training data. Then, obstacles in the input image are detected via the state-of-the-art object detection algorithms, and the results are combined with the generated scene layout. In addition, to further improve the performance and robustness, temporal information in the image sequence is taken into consideration, and the optical flow is obtained in the vicinity of the detected objects to track the obstacles across neighboring frames. Qualitative and quantitative experiments were conducted on the Small Obstacle Detection (SOD) dataset and the Lost and Found dataset. The results indicate that our method with spatio-temporal context modeling is superior to existing methods for road obstacle detection.
Spatially Covariant Lesion Segmentation
Jan 19, 2023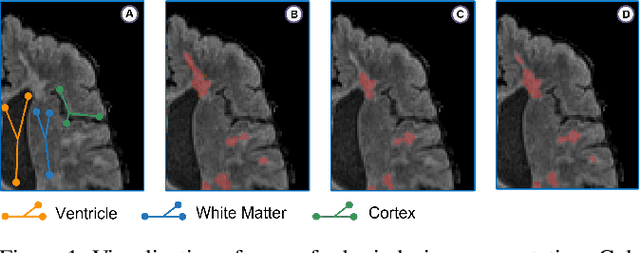
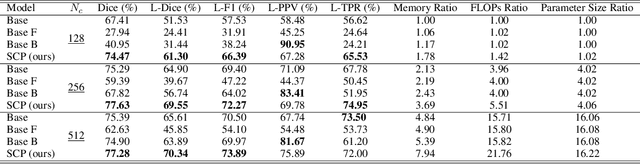
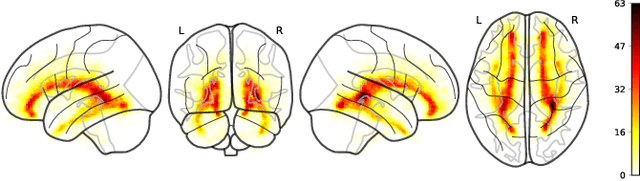
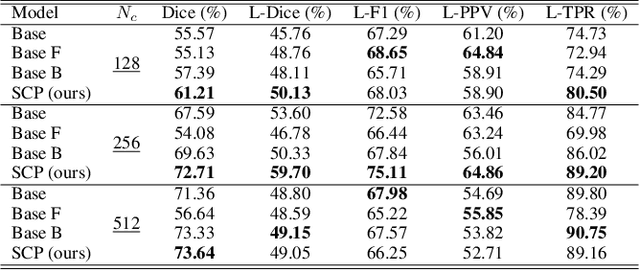
Compared to natural images, medical images usually show stronger visual patterns and therefore this adds flexibility and elasticity to resource-limited clinical applications by injecting proper priors into neural networks. In this paper, we propose spatially covariant pixel-aligned classifier (SCP) to improve the computational efficiency and meantime maintain or increase accuracy for lesion segmentation. SCP relaxes the spatial invariance constraint imposed by convolutional operations and optimizes an underlying implicit function that maps image coordinates to network weights, the parameters of which are obtained along with the backbone network training and later used for generating network weights to capture spatially covariant contextual information. We demonstrate the effectiveness and efficiency of the proposed SCP using two lesion segmentation tasks from different imaging modalities: white matter hyperintensity segmentation in magnetic resonance imaging and liver tumor segmentation in contrast-enhanced abdominal computerized tomography. The network using SCP has achieved 23.8%, 64.9% and 74.7% reduction in GPU memory usage, FLOPs, and network size with similar or better accuracy for lesion segmentation.
An Approximate Algorithm for Maximum Inner Product Search over Streaming Sparse Vectors
Jan 25, 2023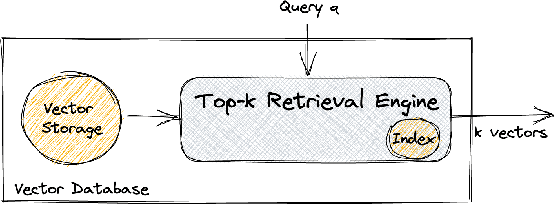
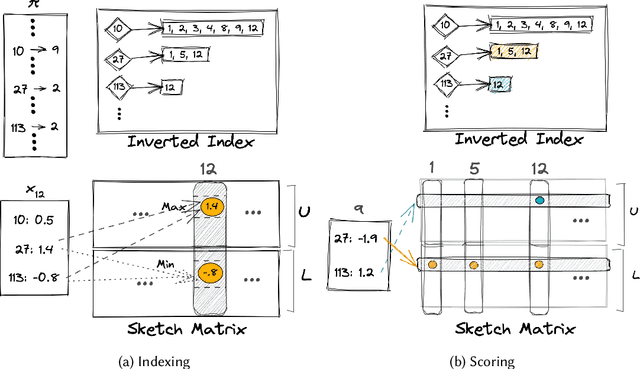
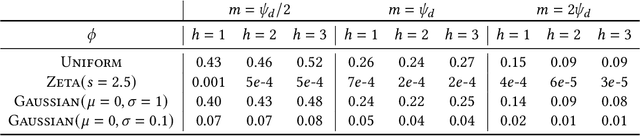
Maximum Inner Product Search or top-k retrieval on sparse vectors is well-understood in information retrieval, with a number of mature algorithms that solve it exactly. However, all existing algorithms are tailored to text and frequency-based similarity measures. To achieve optimal memory footprint and query latency, they rely on the near stationarity of documents and on laws governing natural languages. We consider, instead, a setup in which collections are streaming -- necessitating dynamic indexing -- and where indexing and retrieval must work with arbitrarily distributed real-valued vectors. As we show, existing algorithms are no longer competitive in this setup, even against naive solutions. We investigate this gap and present a novel approximate solution, called Sinnamon, that can efficiently retrieve the top-k results for sparse real valued vectors drawn from arbitrary distributions. Notably, Sinnamon offers levers to trade-off memory consumption, latency, and accuracy, making the algorithm suitable for constrained applications and systems. We give theoretical results on the error introduced by the approximate nature of the algorithm, and present an empirical evaluation of its performance on two hardware platforms and synthetic and real-valued datasets. We conclude by laying out concrete directions for future research on this general top-k retrieval problem over sparse vectors.
Efficient Flow-Guided Multi-frame De-fencing
Jan 25, 2023

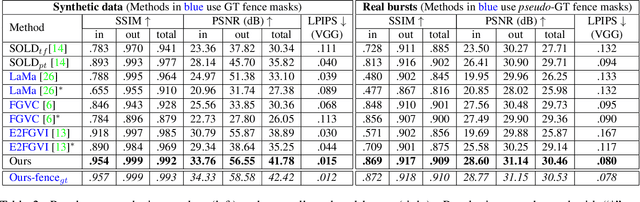
Taking photographs ''in-the-wild'' is often hindered by fence obstructions that stand between the camera user and the scene of interest, and which are hard or impossible to avoid. De-fencing is the algorithmic process of automatically removing such obstructions from images, revealing the invisible parts of the scene. While this problem can be formulated as a combination of fence segmentation and image inpainting, this often leads to implausible hallucinations of the occluded regions. Existing multi-frame approaches rely on propagating information to a selected keyframe from its temporal neighbors, but they are often inefficient and struggle with alignment of severely obstructed images. In this work we draw inspiration from the video completion literature and develop a simplified framework for multi-frame de-fencing that computes high quality flow maps directly from obstructed frames and uses them to accurately align frames. Our primary focus is efficiency and practicality in a real-world setting: the input to our algorithm is a short image burst (5 frames) - a data modality commonly available in modern smartphones - and the output is a single reconstructed keyframe, with the fence removed. Our approach leverages simple yet effective CNN modules, trained on carefully generated synthetic data, and outperforms more complicated alternatives real bursts, both quantitatively and qualitatively, while running real-time.
* 16 pages, 12 figures. Published at the Winter Conference on Application of Computer Vision (WACV) 2023
From Baseline to Top Performer: A Reproducibility Study of Approaches at the TREC 2021 Conversational Assistance Track
Jan 25, 2023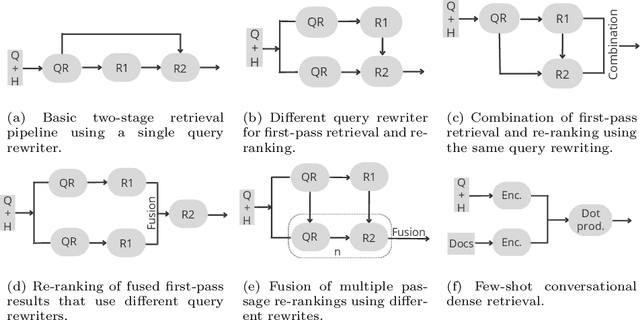

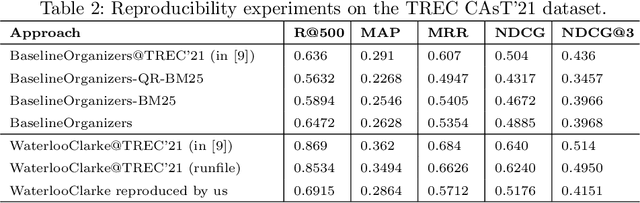
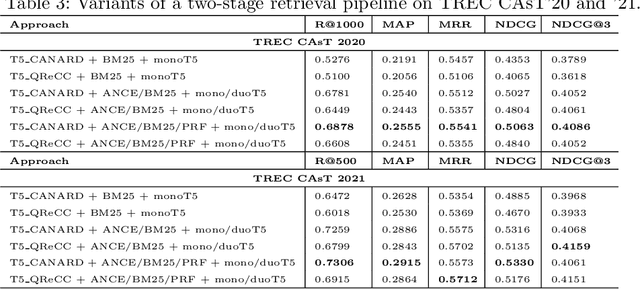
This paper reports on an effort of reproducing the organizers' baseline as well as the top performing participant submission at the 2021 edition of the TREC Conversational Assistance track. TREC systems are commonly regarded as reference points for effectiveness comparison. Yet, the papers accompanying them have less strict requirements than peer-reviewed publications, which can make reproducibility challenging. Our results indicate that key practical information is indeed missing. While the results can be reproduced within a 19% relative margin with respect to the main evaluation measure, the relative difference between the baseline and the top performing approach shrinks from the reported 18% to 5%. Additionally, we report on a new set of experiments aimed at understanding the impact of various pipeline components. We show that end-to-end system performance can indeed benefit from advanced retrieval techniques in either stage of a two-stage retrieval pipeline. We also measure the impact of the dataset used for fine-tuning the query rewriter and find that employing different query rewriting methods in different stages of the retrieval pipeline might be beneficial. Moreover, these results are shown to generalize across the 2020 and 2021 editions of the track. We conclude our study with a list of lessons learned and practical suggestions.