 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Distributed LSTM-Learning from Differentially Private Label Proportions
Jan 15, 2023
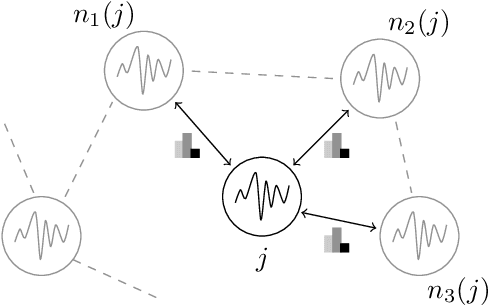
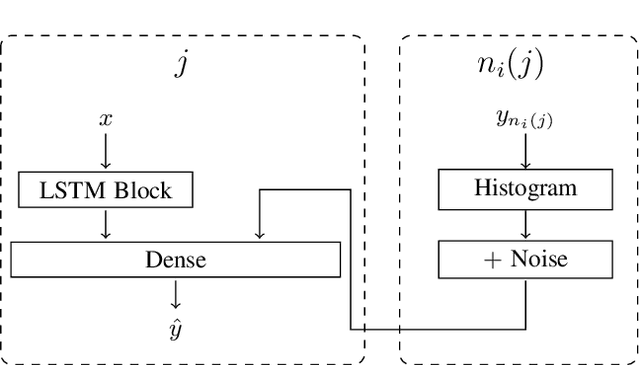
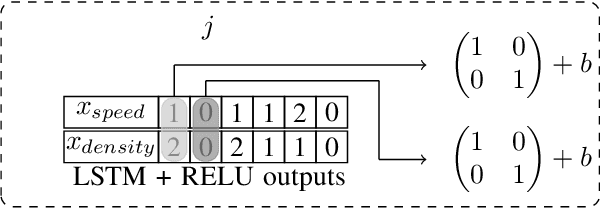
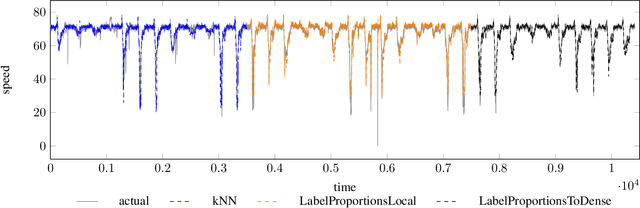
Data privacy and decentralised data collection has become more and more popular in recent years. In order to solve issues with privacy, communication bandwidth and learning from spatio-temporal data, we will propose two efficient models which use Differential Privacy and decentralized LSTM-Learning: One, in which a Long Short Term Memory (LSTM) model is learned for extracting local temporal node constraints and feeding them into a Dense-Layer (LabelProportionToLocal). The other approach extends the first one by fetching histogram data from the neighbors and joining the information with the LSTM output (LabelProportionToDense). For evaluation two popular datasets are used: Pems-Bay and METR-LA. Additionally, we provide an own dataset, which is based on LuST. The evaluation will show the tradeoff between performance and data privacy.
k-Means SubClustering: A Differentially Private Algorithm with Improved Clustering Quality
Jan 07, 2023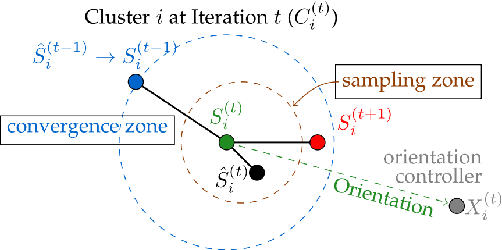
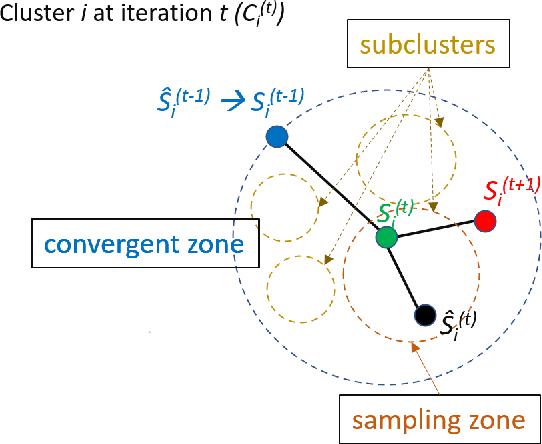
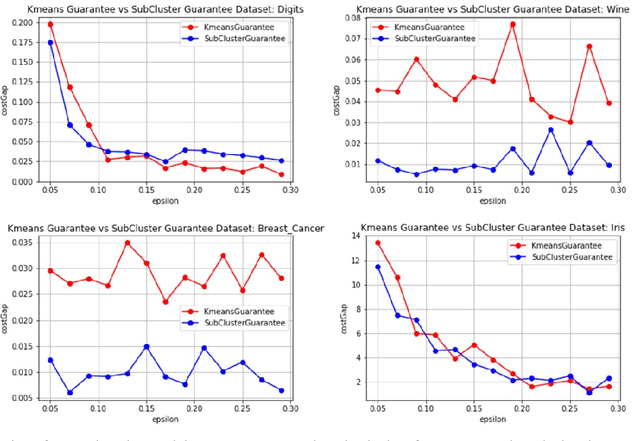
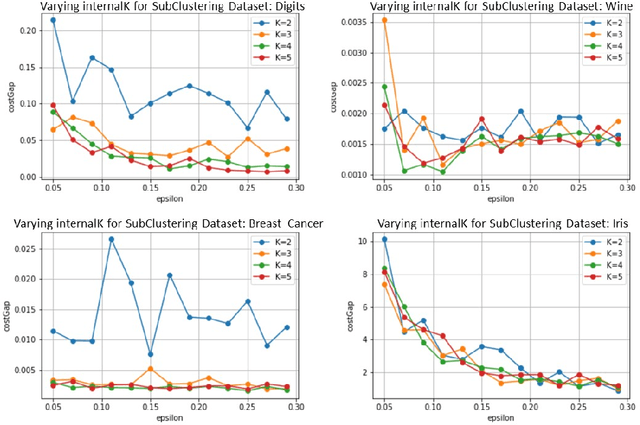
In today's data-driven world, the sensitivity of information has been a significant concern. With this data and additional information on the person's background, one can easily infer an individual's private data. Many differentially private iterative algorithms have been proposed in interactive settings to protect an individual's privacy from these inference attacks. The existing approaches adapt the method to compute differentially private(DP) centroids by iterative Llyod's algorithm and perturbing the centroid with various DP mechanisms. These DP mechanisms do not guarantee convergence of differentially private iterative algorithms and degrade the quality of the cluster. Thus, in this work, we further extend the previous work on 'Differentially Private k-Means Clustering With Convergence Guarantee' by taking it as our baseline. The novelty of our approach is to sub-cluster the clusters and then select the centroid which has a higher probability of moving in the direction of the future centroid. At every Lloyd's step, the centroids are injected with the noise using the exponential DP mechanism. The results of the experiments indicate that our approach outperforms the current state-of-the-art method, i.e., the baseline algorithm, in terms of clustering quality while maintaining the same differential privacy requirements. The clustering quality significantly improved by 4.13 and 2.83 times than baseline for the Wine and Breast_Cancer dataset, respectively.
MIND: Maximum Mutual Information Based Neural Decoder
May 14, 2022

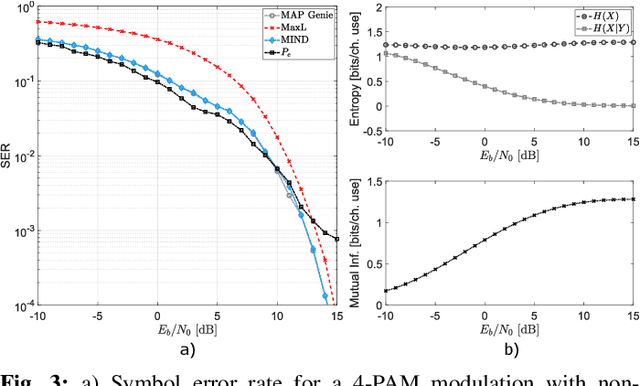
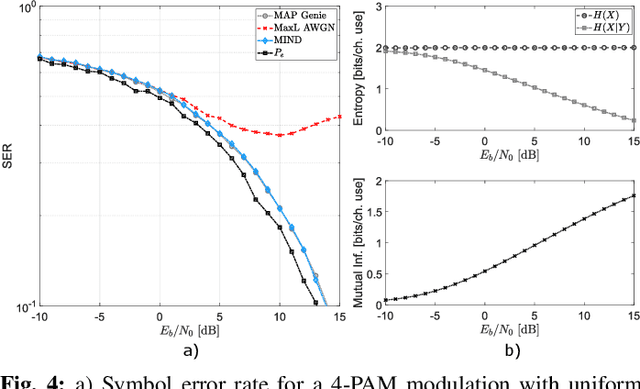
We are assisting at a growing interest in the development of learning architectures with application to digital communication systems. Herein, we consider the detection/decoding problem. We aim at developing an optimal neural architecture for such a task. The definition of the optimal criterion is a fundamental step. We propose to use the mutual information (MI) of the channel input-output signal pair. The computation of the MI is a formidable task, and for the majority of communication channels it is unknown. Therefore, the MI has to be learned. For such an objective, we propose a novel neural MI estimator based on a discriminative formulation. This leads to the derivation of the mutual information neural decoder (MIND). The developed neural architecture is capable not only to solve the decoding problem in unknown channels, but also to return an estimate of the average MI achieved with the coding scheme, as well as the decoding error probability. Several numerical results are reported and compared with maximum a-posteriori (MAP) and maximum likelihood (MaxL) decoding strategies.
A Comparison between RSMA, SDMA, and OMA in Multibeam LEO Satellite Systems
Jan 24, 2023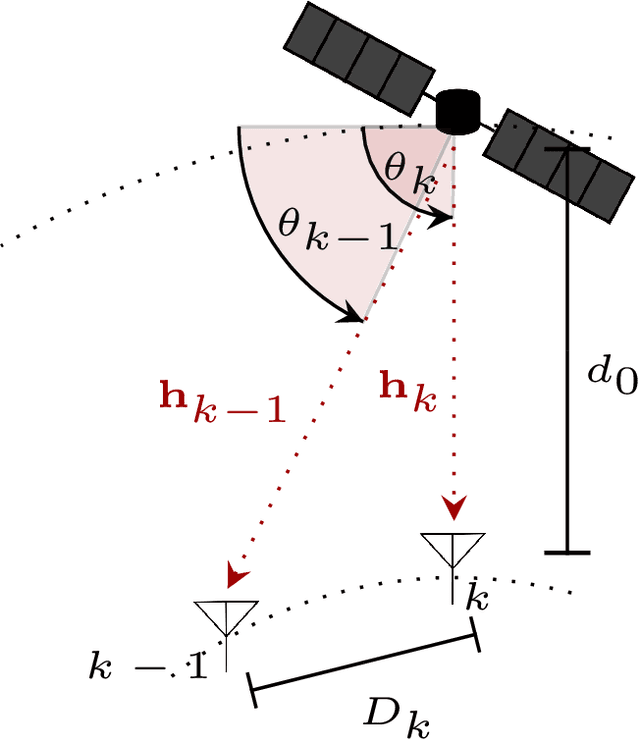
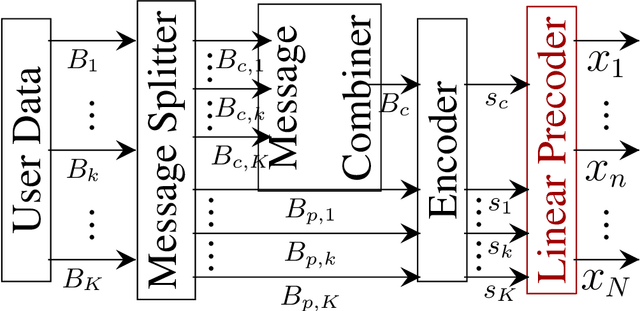
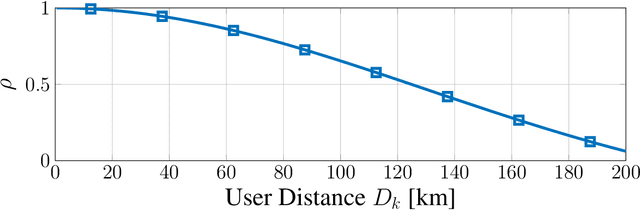
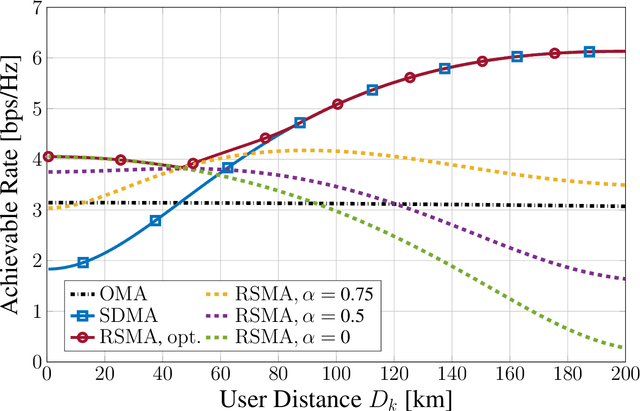
Low Earth orbit (LEO) satellite systems enable close to global coverage and are therefore expected to become important pillars of future communication standards. However, a particular challenge faced by LEO satellites is the high orbital velocities due to which a precise channel estimation is difficult. We model this influence as an erroneous angle of departure (AoD), which corresponds to imperfect channel state information (CSI) at the transmitter (CSIT). Poor CSIT and non-orthogonal user channels degrade the performance of space-division multiple access (SDMA) precoding by increasing inter-user interference (IUI). In contrast to SDMA, there is no IUI in orthogonal multiple access (OMA), but it requires orthogonal time or frequency resources for each user. Rate-splitting multiple access (RSMA), unifying SDMA, OMA, and non-orthogonal multiple access (NOMA), has recently been proven to be a flexible approach for robust interference management considering imperfect CSIT. In this paper, we investigate RSMA as a promising strategy to manage IUI in LEO satellite downlink systems caused by non-orthogonal user channels as well as imperfect CSIT. We evaluate the optimal configuration of RSMA depending on the geometrical constellation between the satellite and users.
Differentially Private Natural Language Models: Recent Advances and Future Directions
Jan 22, 2023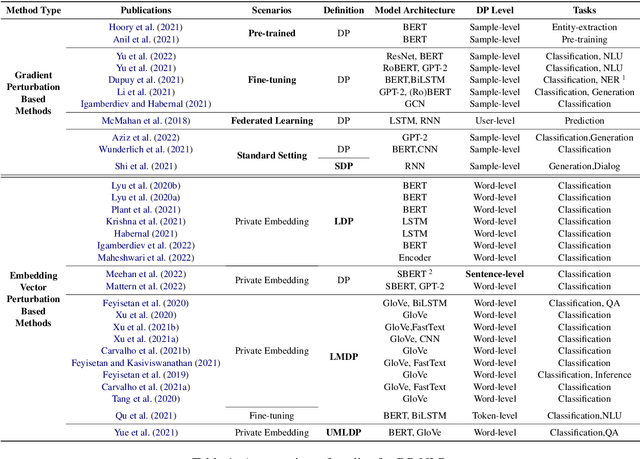
Recent developments in deep learning have led to great success in various natural language processing (NLP) tasks. However, these applications may involve data that contain sensitive information. Therefore, how to achieve good performance while also protect privacy of sensitive data is a crucial challenge in NLP. To preserve privacy, Differential Privacy (DP), which can prevent reconstruction attacks and protect against potential side knowledge, is becoming a de facto technique for private data analysis. In recent years, NLP in DP models (DP-NLP) has been studied from different perspectives, which deserves a comprehensive review. In this paper, we provide the first systematic review of recent advances on DP deep learning models in NLP. In particular, we first discuss some differences and additional challenges of DP-NLP compared with the standard DP deep learning. Then we investigate some existing work on DP-NLP and present its recent developments from two aspects: gradient perturbation based methods and embedding vector perturbation based methods. We also discuss some challenges and future directions of this topic.
Efficient Scopeformer: Towards Scalable and Rich Feature Extraction for Intracranial Hemorrhage Detection
Feb 01, 2023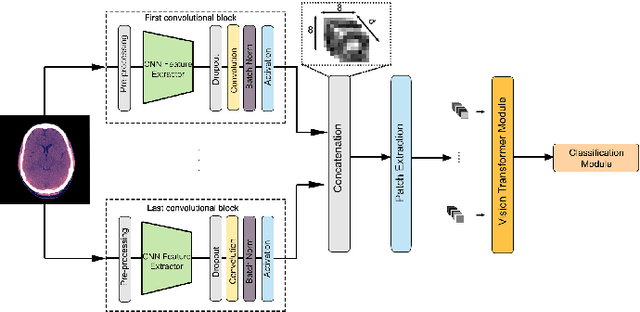
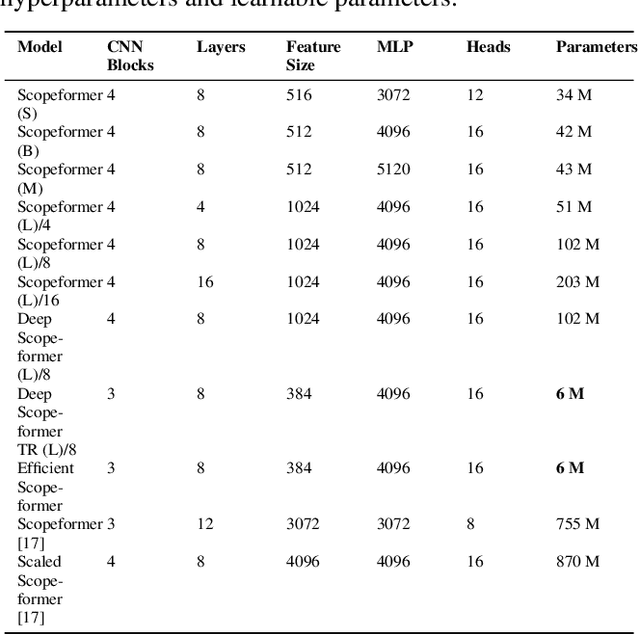
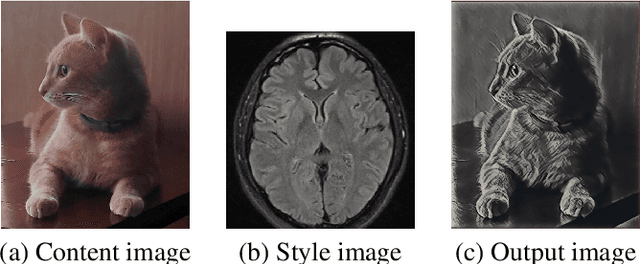
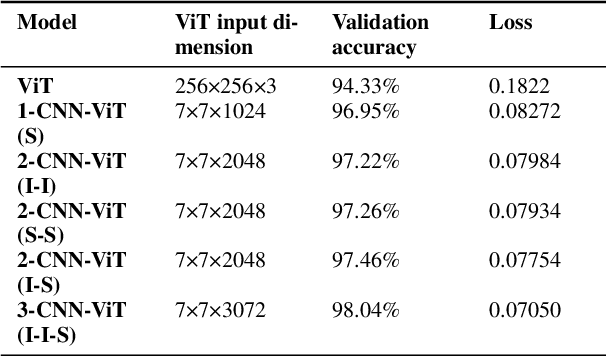
The quality and richness of feature maps extracted by convolution neural networks (CNNs) and vision Transformers (ViTs) directly relate to the robust model performance. In medical computer vision, these information-rich features are crucial for detecting rare cases within large datasets. This work presents the "Scopeformer," a novel multi-CNN-ViT model for intracranial hemorrhage classification in computed tomography (CT) images. The Scopeformer architecture is scalable and modular, which allows utilizing various CNN architectures as the backbone with diversified output features and pre-training strategies. We propose effective feature projection methods to reduce redundancies among CNN-generated features and to control the input size of ViTs. Extensive experiments with various Scopeformer models show that the model performance is proportional to the number of convolutional blocks employed in the feature extractor. Using multiple strategies, including diversifying the pre-training paradigms for CNNs, different pre-training datasets, and style transfer techniques, we demonstrate an overall improvement in the model performance at various computational budgets. Later, we propose smaller compute-efficient Scopeformer versions with three different types of input and output ViT configurations. Efficient Scopeformers use four different pre-trained CNN architectures as feature extractors to increase feature richness. Our best Efficient Scopeformer model achieved an accuracy of 96.94\% and a weighted logarithmic loss of 0.083 with an eight times reduction in the number of trainable parameters compared to the base Scopeformer. Another version of the Efficient Scopeformer model further reduced the parameter space by almost 17 times with negligible performance reduction. Hybrid CNNs and ViTs might provide the desired feature richness for developing accurate medical computer vision models
An automated, geometry-based method for the analysis of hippocampal thickness
Feb 01, 2023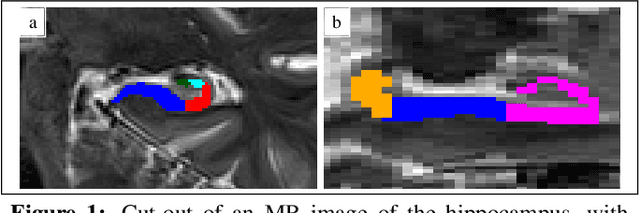
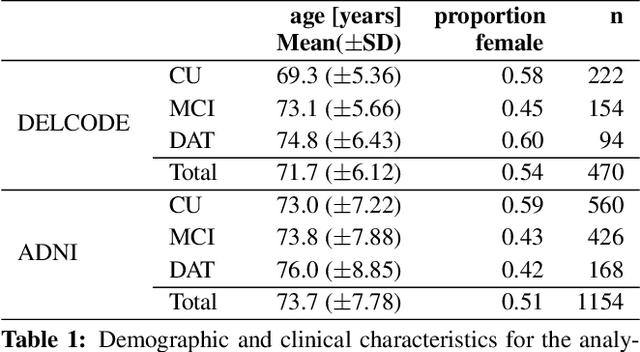
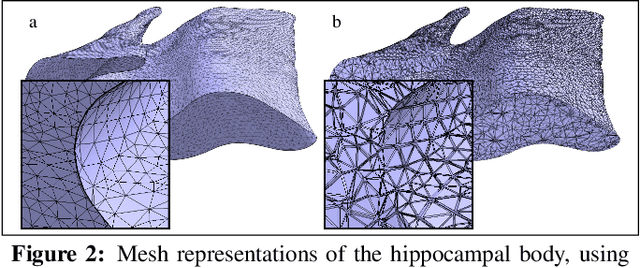
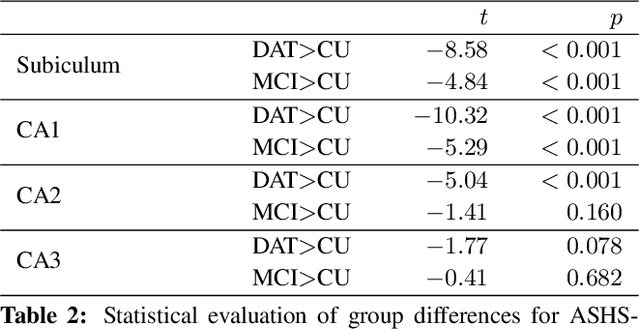
The hippocampus is one of the most studied neuroanatomical structures due to its involvement in attention, learning, and memory as well as its atrophy in ageing, neurological, and psychiatric diseases. Hippocampal shape changes, however, are complex and cannot be fully characterized by a single summary metric such as hippocampal volume as determined from MR images. In this work, we propose an automated, geometry-based approach for the unfolding, point-wise correspondence, and local analysis of hippocampal shape features such as thickness and curvature. Starting from an automated segmentation of hippocampal subfields, we create a 3D tetrahedral mesh model as well as a 3D intrinsic coordinate system of the hippocampal body. From this coordinate system, we derive local curvature and thickness estimates as well as a 2D sheet for hippocampal unfolding. We evaluate the performance of our algorithm with a series of experiments to quantify neurodegenerative changes in Mild Cognitive Impairment and Alzheimer's disease dementia. We find that hippocampal thickness estimates detect known differences between clinical groups and can determine the location of these effects on the hippocampal sheet. Further, thickness estimates improve classification of clinical groups and cognitively unimpaired controls when added as an additional predictor. Comparable results are obtained with different datasets and segmentation algorithms. Taken together, we replicate canonical findings on hippocampal volume/shape changes in dementia, extend them by gaining insight into their spatial localization on the hippocampal sheet, and provide additional, complementary information beyond traditional measures. We provide a new set of sensitive processing and analysis tools for the analysis of hippocampal geometry that allows comparisons across studies without relying on image registration or requiring manual intervention.
Multi-Reference Image Super-Resolution: A Posterior Fusion Approach
Dec 20, 2022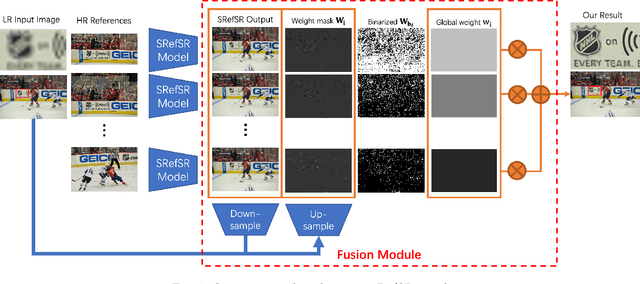

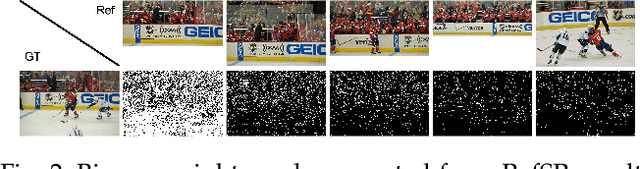
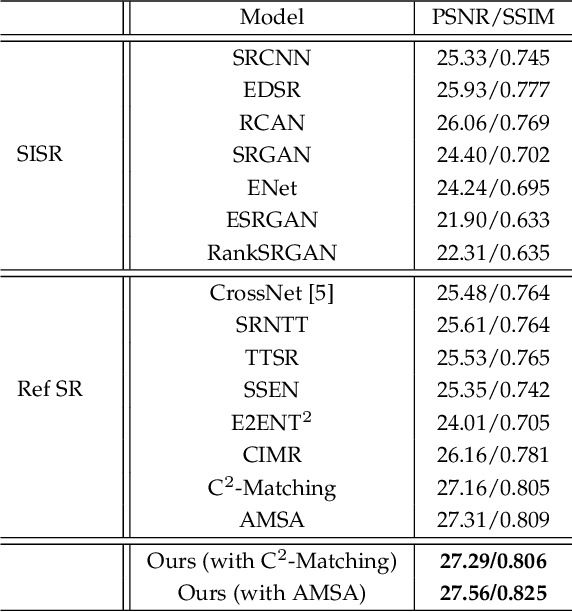
Reference-based Super-resolution (RefSR) approaches have recently been proposed to overcome the ill-posed problem of image super-resolution by providing additional information from a high-resolution image. Multi-reference super-resolution extends this approach by allowing more information to be incorporated. This paper proposes a 2-step-weighting posterior fusion approach to combine the outputs of RefSR models with multiple references. Extensive experiments on the CUFED5 dataset demonstrate that the proposed methods can be applied to various state-of-the-art RefSR models to get a consistent improvement in image quality.
Power Control for 6G Industrial Wireless Subnetworks: A Graph Neural Network Approach
Dec 30, 2022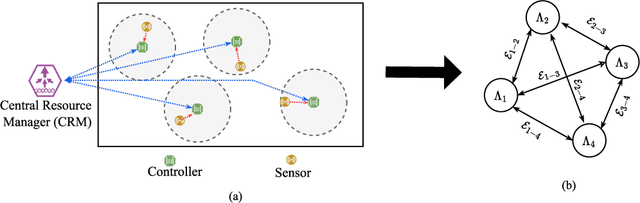
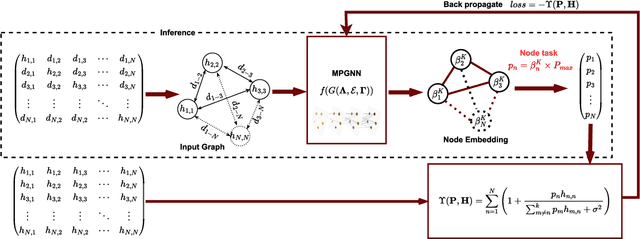
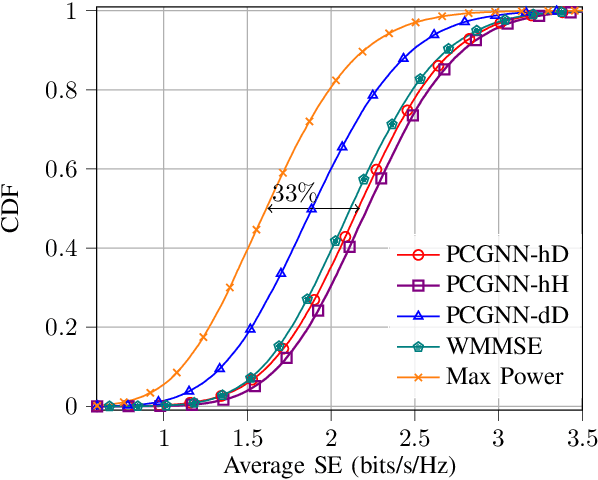
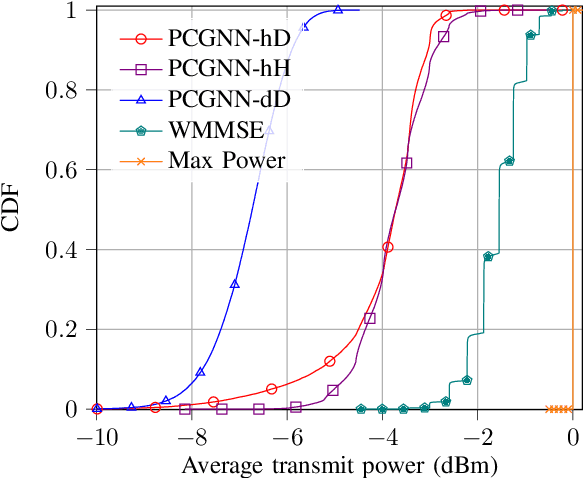
6th Generation (6G) industrial wireless subnetworks are expected to replace wired connectivity for control operation in robots and production modules. Interference management techniques such as centralized power control can improve spectral efficiency in dense deployments of such subnetworks. However, existing solutions for centralized power control may require full channel state information (CSI) of all the desired and interfering links, which may be cumbersome and time-consuming to obtain in dense deployments. This paper presents a novel solution for centralized power control for industrial subnetworks based on Graph Neural Networks (GNNs). The proposed method only requires the subnetwork positioning information, usually known at the central controller, and the knowledge of the desired link channel gain during the execution phase. Simulation results show that our solution achieves similar spectral efficiency as the benchmark schemes requiring full CSI in runtime operations. Also, robustness to changes in the deployment density and environment characteristics with respect to the training phase is verified.
Unifying Molecular and Textual Representations via Multi-task Language Modelling
Jan 29, 2023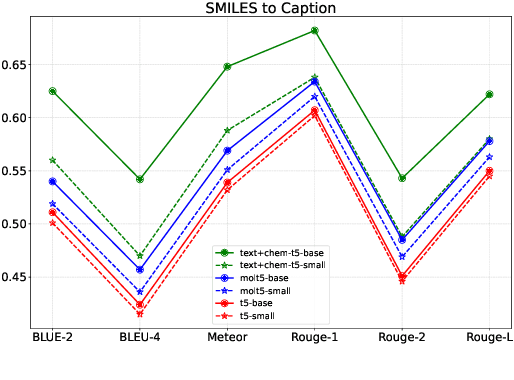
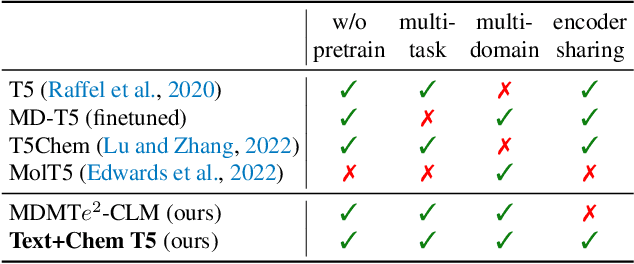
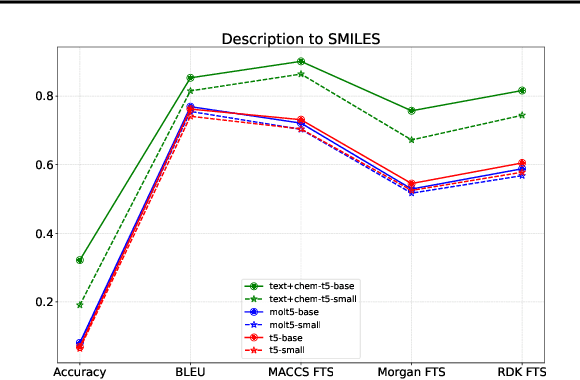
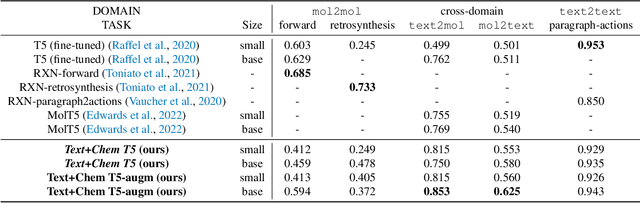
The recent advances in neural language models have also been successfully applied to the field of chemistry, offering generative solutions for classical problems in molecular design and synthesis planning. These new methods have the potential to optimize laboratory operations and fuel a new era of data-driven automation in scientific discovery. However, specialized models are still typically required for each task, leading to the need for problem-specific fine-tuning and neglecting task interrelations. The main obstacle in this field is the lack of a unified representation between natural language and chemical representations, complicating and limiting human-machine interaction. Here, we propose a multi-domain, multi-task language model to solve a wide range of tasks in both the chemical and natural language domains. By leveraging multi-task learning, our model can handle chemical and natural language concurrently, without requiring expensive pre-training on single domains or task-specific models. Interestingly, sharing weights across domains remarkably improves our model when benchmarked against state-of-the-art baselines on single-domain and cross-domain tasks. In particular, sharing information across domains and tasks gives rise to large improvements in cross-domain tasks, the magnitude of which increase with scale, as measured by more than a dozen of relevant metrics. Our work suggests that such models can robustly and efficiently accelerate discovery in physical sciences by superseding problem-specific fine-tuning and enhancing human-model interactions.