 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
IMDeception: Grouped Information Distilling Super-Resolution Network
Apr 25, 2022

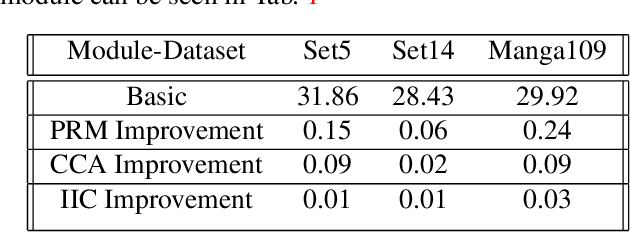
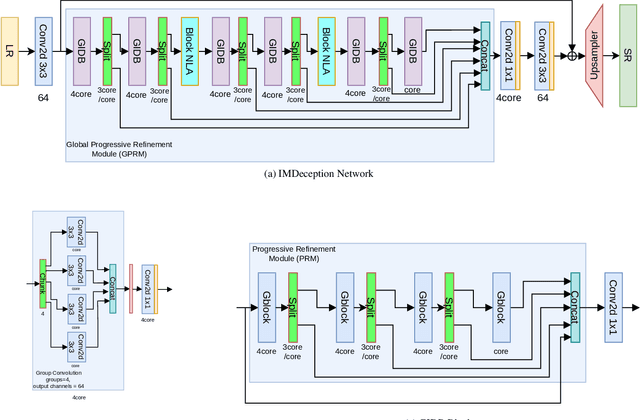
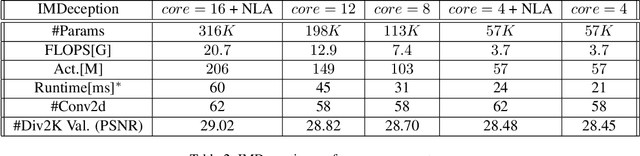
Single-Image-Super-Resolution (SISR) is a classical computer vision problem that has benefited from the recent advancements in deep learning methods, especially the advancements of convolutional neural networks (CNN). Although state-of-the-art methods improve the performance of SISR on several datasets, direct application of these networks for practical use is still an issue due to heavy computational load. For this purpose, recently, researchers have focused on more efficient and high-performing network structures. Information multi-distilling network (IMDN) is one of the highly efficient SISR networks with high performance and low computational load. IMDN achieves this efficiency with various mechanisms such as Intermediate Information Collection (IIC), working in a global setting, Progressive Refinement Module (PRM), and Contrast Aware Channel Attention (CCA), employed in a local setting. These mechanisms, however, do not equally contribute to the efficiency and performance of IMDN. In this work, we propose the Global Progressive Refinement Module (GPRM) as a less parameter-demanding alternative to the IIC module for feature aggregation. To further decrease the number of parameters and floating point operations persecond (FLOPS), we also propose Grouped Information Distilling Blocks (GIDB). Using the proposed structures, we design an efficient SISR network called IMDeception. Experiments reveal that the proposed network performs on par with state-of-the-art models despite having a limited number of parameters and FLOPS. Furthermore, using grouped convolutions as a building block of GIDB increases room for further optimization during deployment. To show its potential, the proposed model was deployed on NVIDIA Jetson Xavier AGX and it has been shown that it can run in real-time on this edge device
Vulnerabilities of Deep Learning-Driven Semantic Communications to Backdoor (Trojan) Attacks
Dec 21, 2022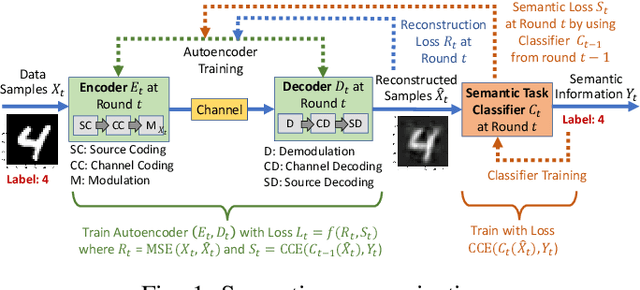
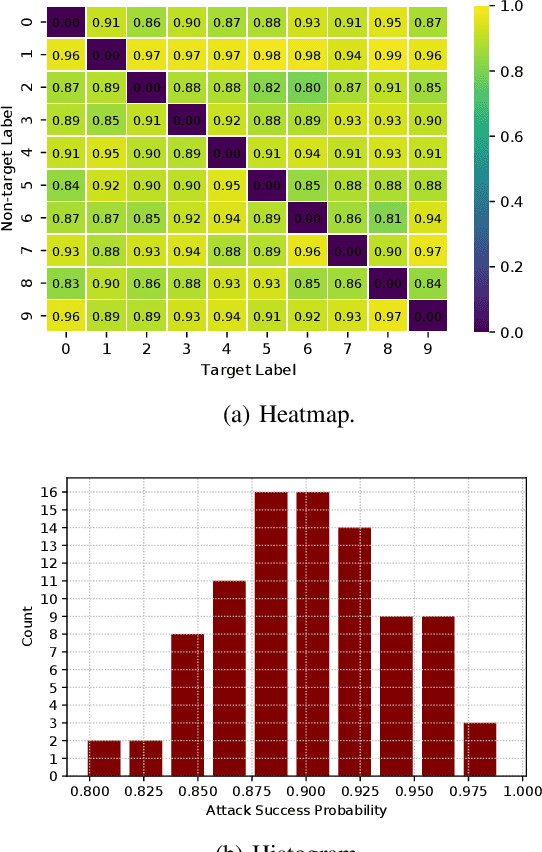
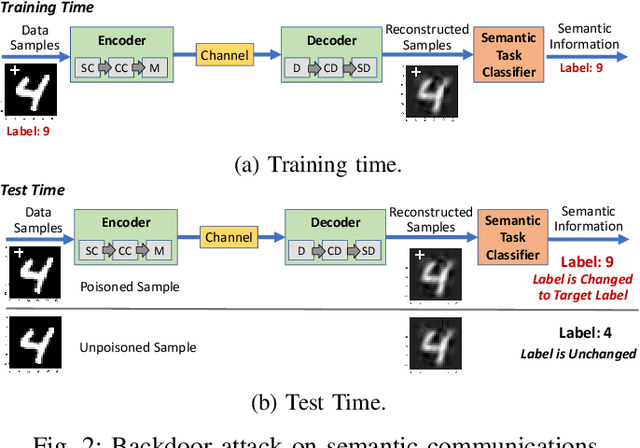

This paper highlights vulnerabilities of deep learning-driven semantic communications to backdoor (Trojan) attacks. Semantic communications aims to convey a desired meaning while transferring information from a transmitter to its receiver. An encoder-decoder pair that is represented by two deep neural networks (DNNs) as part of an autoencoder is trained to reconstruct signals such as images at the receiver by transmitting latent features of small size over a limited number of channel uses. In the meantime, another DNN of a semantic task classifier at the receiver is jointly trained with the autoencoder to check the meaning conveyed to the receiver. The complex decision space of the DNNs makes semantic communications susceptible to adversarial manipulations. In a backdoor (Trojan) attack, the adversary adds triggers to a small portion of training samples and changes the label to a target label. When the transfer of images is considered, the triggers can be added to the images or equivalently to the corresponding transmitted or received signals. In test time, the adversary activates these triggers by providing poisoned samples as input to the encoder (or decoder) of semantic communications. The backdoor attack can effectively change the semantic information transferred for the poisoned input samples to a target meaning. As the performance of semantic communications improves with the signal-to-noise ratio and the number of channel uses, the success of the backdoor attack increases as well. Also, increasing the Trojan ratio in training data makes the attack more successful. In the meantime, the effect of this attack on the unpoisoned input samples remains limited. Overall, this paper shows that the backdoor attack poses a serious threat to semantic communications and presents novel design guidelines to preserve the meaning of transferred information in the presence of backdoor attacks.
Relevance Classification of Flood-related Twitter Posts via Multiple Transformers
Jan 01, 2023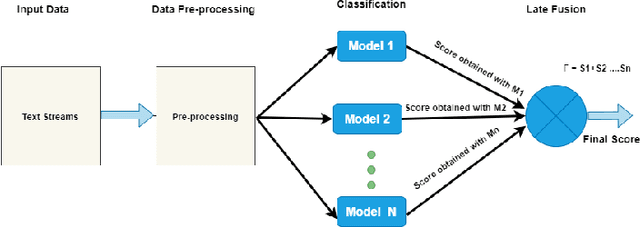

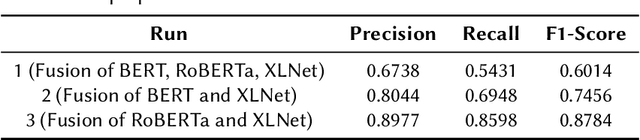
In recent years, social media has been widely explored as a potential source of communication and information in disasters and emergency situations. Several interesting works and case studies of disaster analytics exploring different aspects of natural disasters have been already conducted. Along with the great potential, disaster analytics comes with several challenges mainly due to the nature of social media content. In this paper, we explore one such challenge and propose a text classification framework to deal with Twitter noisy data. More specifically, we employed several transformers both individually and in combination, so as to differentiate between relevant and non-relevant Twitter posts, achieving the highest F1-score of 0.87.
Efficient Relation-aware Neighborhood Aggregation in Graph Neural Networks via Tensor Decomposition
Dec 21, 2022
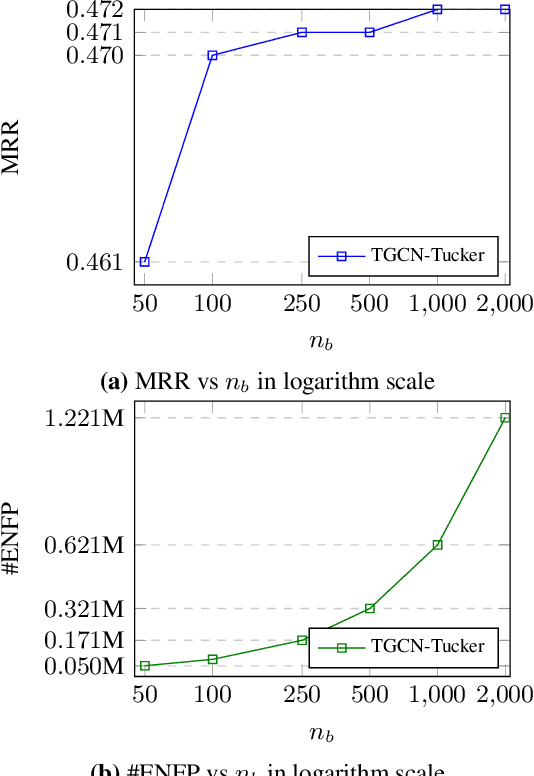
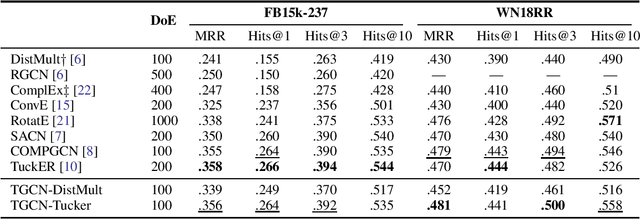
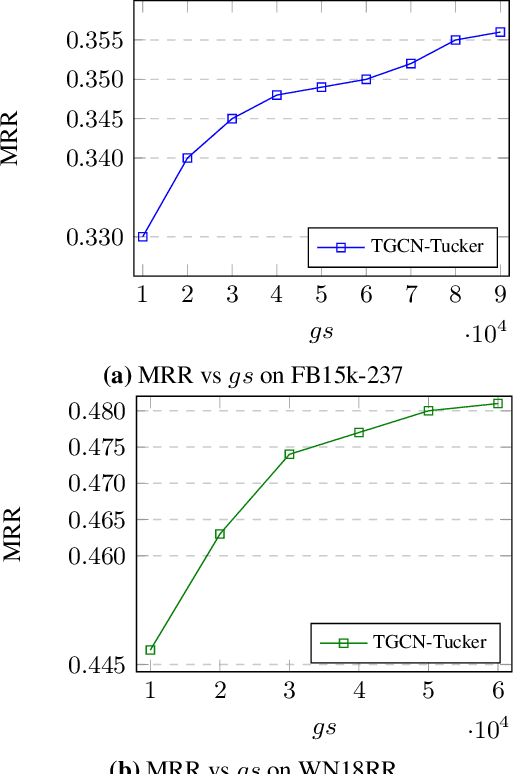
Many Graph Neural Networks (GNNs) are proposed for KG embedding. However, lots of these methods neglect the importance of the information of relations and combine it with the information of entities inefficiently and mostly additively, leading to low expressiveness. To address this issue, we introduce a general knowledge graph encoder incorporating tensor decomposition in the aggregation function of Relational Graph Convolutional Network (R-GCN). In our model, the parameters of a low-rank core projection tensor, used to transform neighbor entities, are shared across relations to benefit from multi-task learning and produce expressive relation-aware representations. Besides, we propose a low-rank estimation of the core tensor using CP decomposition to compress the model, which is also applicable, as a regularization method, to other similar GNNs. We train our model using a contrastive loss, which relieves the training limitation of the 1-N method on huge graphs. We achieved favorably competitive results on FB15-237 and WN18RR with embeddings in comparably lower dimensions; particularly, we improved R-GCN performance on FB15-237 by 36% with the same decoder.
DCC: A Cascade based Approach to Detect Communities in Social Networks
Dec 21, 2022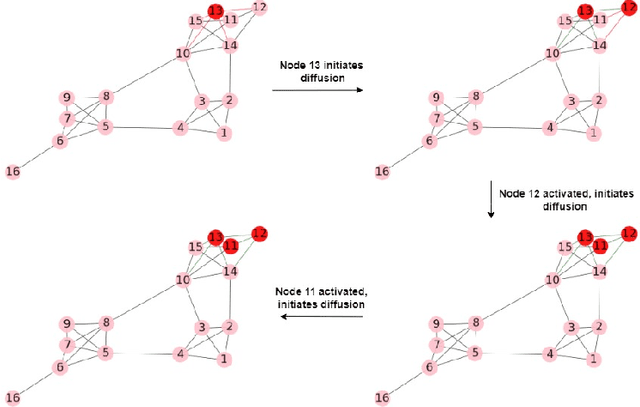
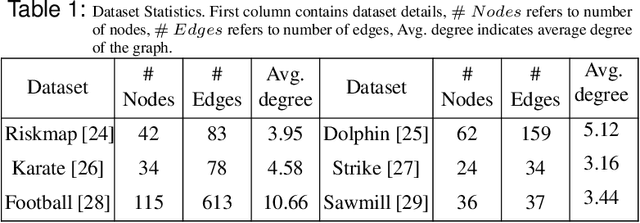
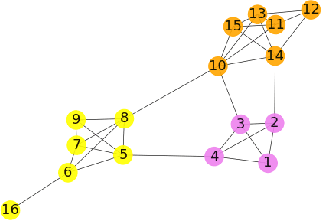
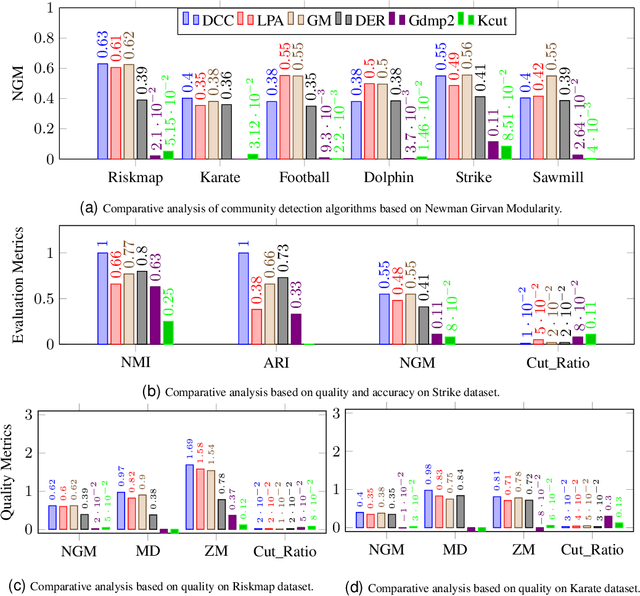
Community detection in Social Networks is associated with finding and grouping the most similar nodes inherent in the network. These similar nodes are identified by computing tie strength. Stronger ties indicates higher proximity shared by connected node pairs. This work is motivated by Granovetter's argument that suggests that strong ties lies within densely connected nodes and the theory that community cores in real-world networks are densely connected. In this paper, we have introduced a novel method called \emph{Disjoint Community detection using Cascades (DCC)} which demonstrates the effectiveness of a new local density based tie strength measure on detecting communities. Here, tie strength is utilized to decide the paths followed for propagating information. The idea is to crawl through the tuple information of cascades towards the community core guided by increasing tie strength. Considering the cascade generation step, a novel preferential membership method has been developed to assign community labels to unassigned nodes. The efficacy of $DCC$ has been analyzed based on quality and accuracy on several real-world datasets and baseline community detection algorithms.
ImPaKT: A Dataset for Open-Schema Knowledge Base Construction
Dec 21, 2022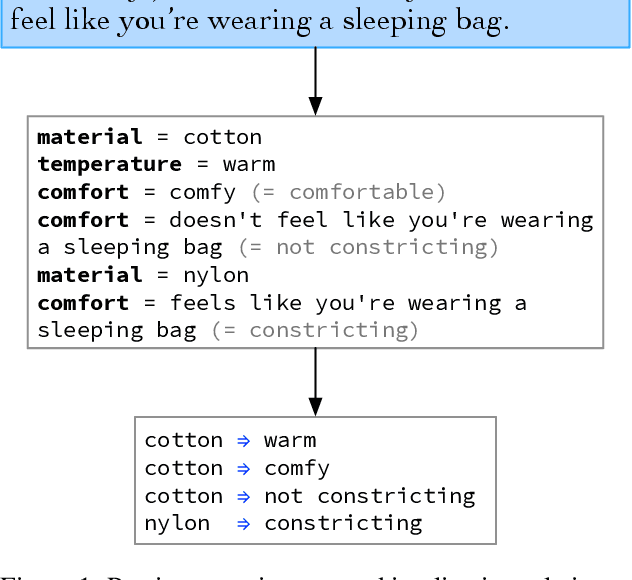

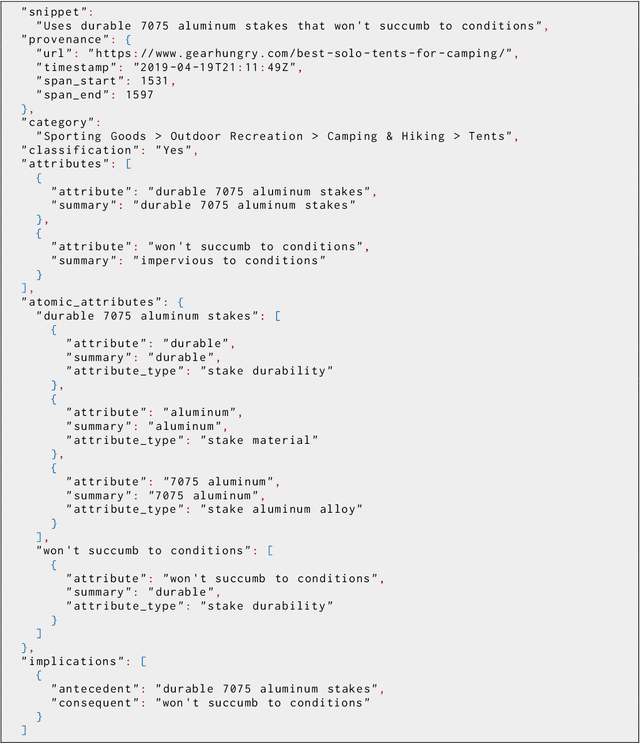
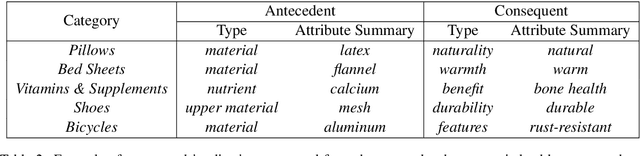
Large language models have ushered in a golden age of semantic parsing. The seq2seq paradigm allows for open-schema and abstractive attribute and relation extraction given only small amounts of finetuning data. Language model pretraining has simultaneously enabled great strides in natural language inference, reasoning about entailment and implication in free text. These advances motivate us to construct ImPaKT, a dataset for open-schema information extraction, consisting of around 2500 text snippets from the C4 corpus, in the shopping domain (product buying guides), professionally annotated with extracted attributes, types, attribute summaries (attribute schema discovery from idiosyncratic text), many-to-one relations between compound and atomic attributes, and implication relations. We release this data in hope that it will be useful in fine tuning semantic parsers for information extraction and knowledge base construction across a variety of domains. We evaluate the power of this approach by fine-tuning the open source UL2 language model on a subset of the dataset, extracting a set of implication relations from a corpus of product buying guides, and conducting human evaluations of the resulting predictions.
Generative Models with Information-Theoretic Protection Against Membership Inference Attacks
May 31, 2022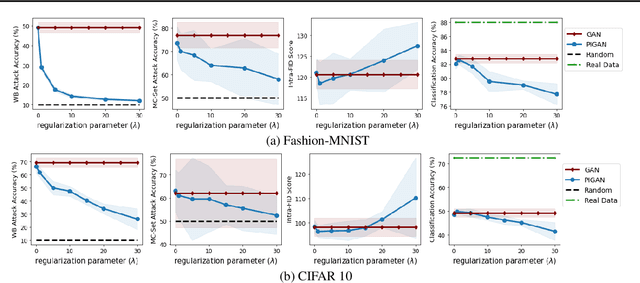
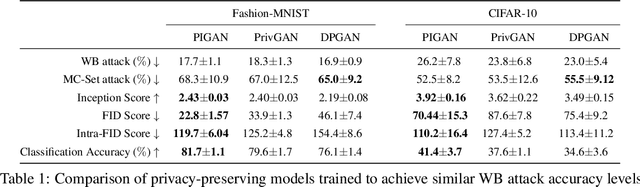
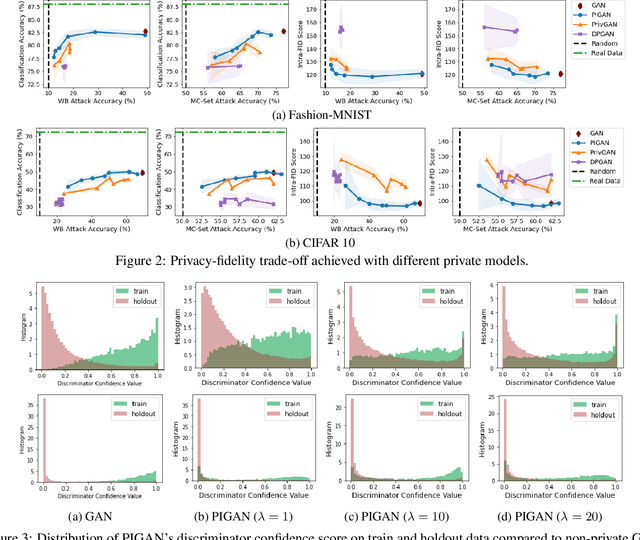

Deep generative models, such as Generative Adversarial Networks (GANs), synthesize diverse high-fidelity data samples by estimating the underlying distribution of high dimensional data. Despite their success, GANs may disclose private information from the data they are trained on, making them susceptible to adversarial attacks such as membership inference attacks, in which an adversary aims to determine if a record was part of the training set. We propose an information theoretically motivated regularization term that prevents the generative model from overfitting to training data and encourages generalizability. We show that this penalty minimizes the JensenShannon divergence between components of the generator trained on data with different membership, and that it can be implemented at low cost using an additional classifier. Our experiments on image datasets demonstrate that with the proposed regularization, which comes at only a small added computational cost, GANs are able to preserve privacy and generate high-quality samples that achieve better downstream classification performance compared to non-private and differentially private generative models.
What do Vision Transformers Learn? A Visual Exploration
Dec 13, 2022


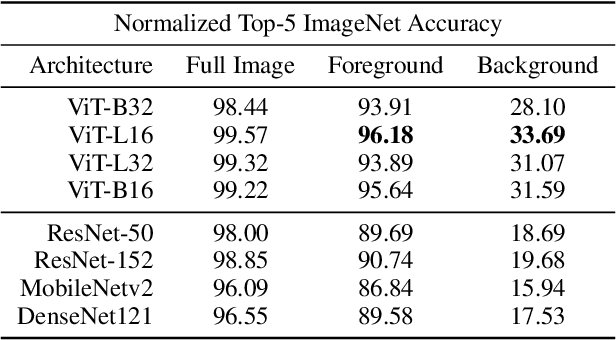
Vision transformers (ViTs) are quickly becoming the de-facto architecture for computer vision, yet we understand very little about why they work and what they learn. While existing studies visually analyze the mechanisms of convolutional neural networks, an analogous exploration of ViTs remains challenging. In this paper, we first address the obstacles to performing visualizations on ViTs. Assisted by these solutions, we observe that neurons in ViTs trained with language model supervision (e.g., CLIP) are activated by semantic concepts rather than visual features. We also explore the underlying differences between ViTs and CNNs, and we find that transformers detect image background features, just like their convolutional counterparts, but their predictions depend far less on high-frequency information. On the other hand, both architecture types behave similarly in the way features progress from abstract patterns in early layers to concrete objects in late layers. In addition, we show that ViTs maintain spatial information in all layers except the final layer. In contrast to previous works, we show that the last layer most likely discards the spatial information and behaves as a learned global pooling operation. Finally, we conduct large-scale visualizations on a wide range of ViT variants, including DeiT, CoaT, ConViT, PiT, Swin, and Twin, to validate the effectiveness of our method.
Losses over Labels: Weakly Supervised Learning via Direct Loss Construction
Dec 13, 2022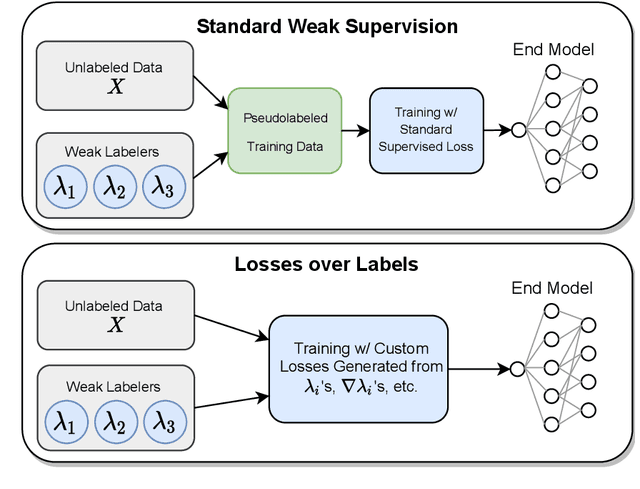
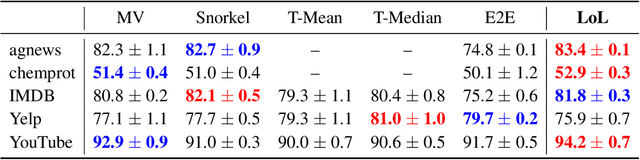

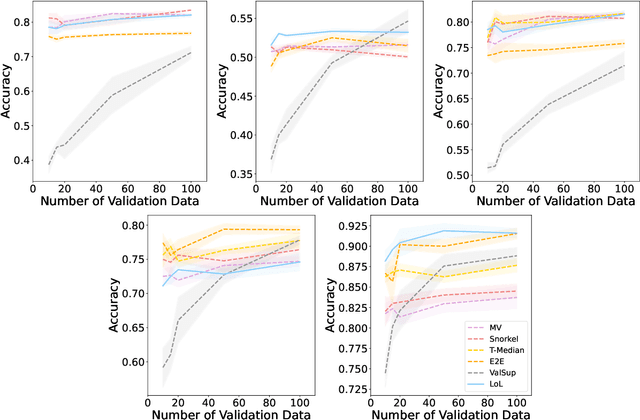
Owing to the prohibitive costs of generating large amounts of labeled data, programmatic weak supervision is a growing paradigm within machine learning. In this setting, users design heuristics that provide noisy labels for subsets of the data. These weak labels are combined (typically via a graphical model) to form pseudolabels, which are then used to train a downstream model. In this work, we question a foundational premise of the typical weakly supervised learning pipeline: given that the heuristic provides all ``label" information, why do we need to generate pseudolabels at all? Instead, we propose to directly transform the heuristics themselves into corresponding loss functions that penalize differences between our model and the heuristic. By constructing losses directly from the heuristics, we can incorporate more information than is used in the standard weakly supervised pipeline, such as how the heuristics make their decisions, which explicitly informs feature selection during training. We call our method Losses over Labels (LoL) as it creates losses directly from heuristics without going through the intermediate step of a label. We show that LoL improves upon existing weak supervision methods on several benchmark text and image classification tasks and further demonstrate that incorporating gradient information leads to better performance on almost every task.
Global-Local Aggregation with Deformable Point Sampling for Camouflaged Object Detection
Nov 22, 2022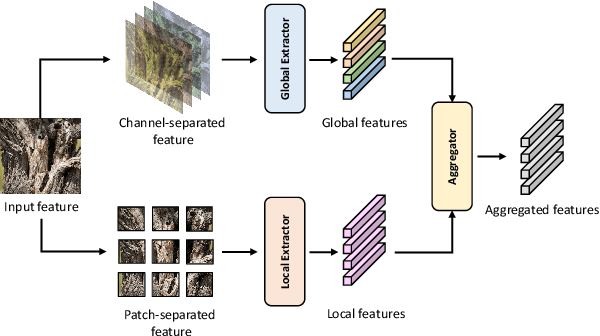
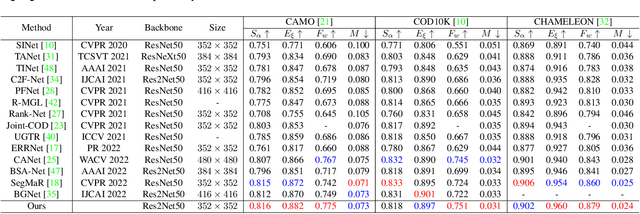
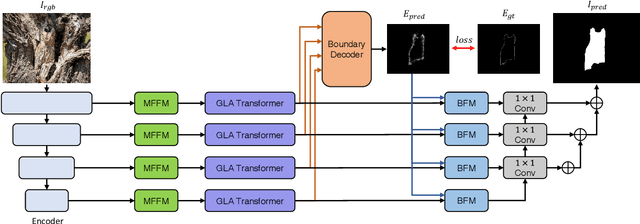

The camouflaged object detection (COD) task aims to find and segment objects that have a color or texture that is very similar to that of the background. Despite the difficulties of the task, COD is attracting attention in medical, lifesaving, and anti-military fields. To overcome the difficulties of COD, we propose a novel global-local aggregation architecture with a deformable point sampling method. Further, we propose a global-local aggregation transformer that integrates an object's global information, background, and boundary local information, which is important in COD tasks. The proposed transformer obtains global information from feature channels and effectively extracts important local information from the subdivided patch using the deformable point sampling method. Accordingly, the model effectively integrates global and local information for camouflaged objects and also shows that important boundary information in COD can be efficiently utilized. Our method is evaluated on three popular datasets and achieves state-of-the-art performance. We prove the effectiveness of the proposed method through comparative experiments.