 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Poly-View Contrastive Learning
Mar 08, 2024


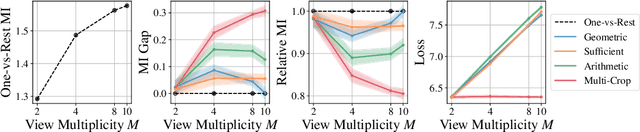
Contrastive learning typically matches pairs of related views among a number of unrelated negative views. Views can be generated (e.g. by augmentations) or be observed. We investigate matching when there are more than two related views which we call poly-view tasks, and derive new representation learning objectives using information maximization and sufficient statistics. We show that with unlimited computation, one should maximize the number of related views, and with a fixed compute budget, it is beneficial to decrease the number of unique samples whilst increasing the number of views of those samples. In particular, poly-view contrastive models trained for 128 epochs with batch size 256 outperform SimCLR trained for 1024 epochs at batch size 4096 on ImageNet1k, challenging the belief that contrastive models require large batch sizes and many training epochs.
Self-seeding and Multi-intent Self-instructing LLMs for Generating Intent-aware Information-Seeking dialogs
Feb 18, 2024Identifying user intents in information-seeking dialogs is crucial for a system to meet user's information needs. Intent prediction (IP) is challenging and demands sufficient dialogs with human-labeled intents for training. However, manually annotating intents is resource-intensive. While large language models (LLMs) have been shown to be effective in generating synthetic data, there is no study on using LLMs to generate intent-aware information-seeking dialogs. In this paper, we focus on leveraging LLMs for zero-shot generation of large-scale, open-domain, and intent-aware information-seeking dialogs. We propose SOLID, which has novel self-seeding and multi-intent self-instructing schemes. The former improves the generation quality by using the LLM's own knowledge scope to initiate dialog generation; the latter prompts the LLM to generate utterances sequentially, and mitigates the need for manual prompt design by asking the LLM to autonomously adapt its prompt instruction when generating complex multi-intent utterances. Furthermore, we propose SOLID-RL, which is further trained to generate a dialog in one step on the data generated by SOLID. We propose a length-based quality estimation mechanism to assign varying weights to SOLID-generated dialogs based on their quality during the training process of SOLID-RL. We use SOLID and SOLID-RL to generate more than 300k intent-aware dialogs, surpassing the size of existing datasets. Experiments show that IP methods trained on dialogs generated by SOLID and SOLID-RL achieve better IP quality than ones trained on human-generated dialogs.
A spatiotemporal style transfer algorithm for dynamic visual stimulus generation
Mar 07, 2024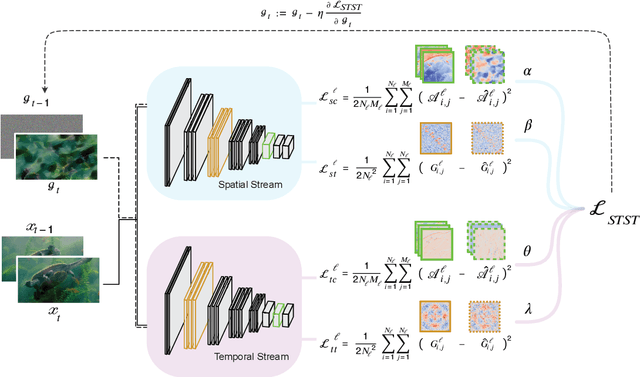
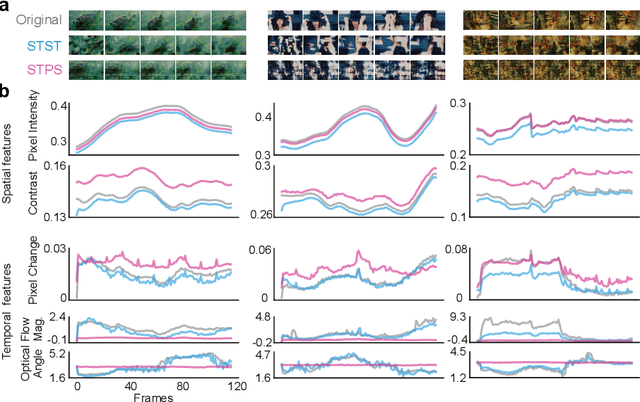
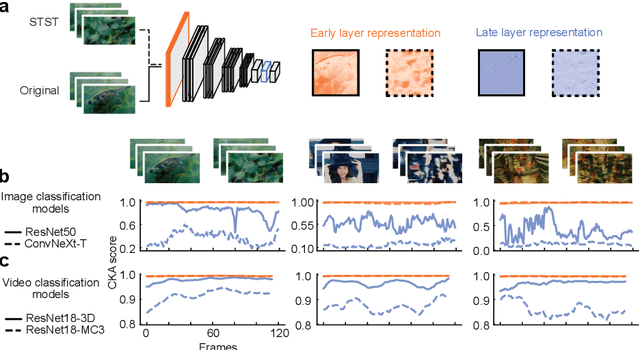
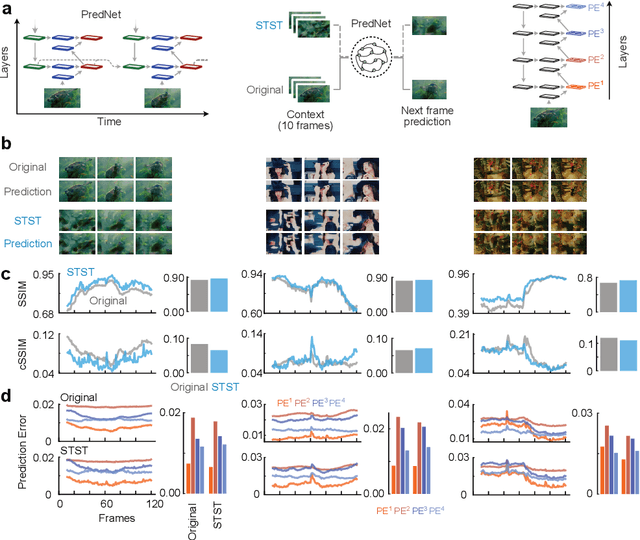
Understanding how visual information is encoded in biological and artificial systems often requires vision scientists to generate appropriate stimuli to test specific hypotheses. Although deep neural network models have revolutionized the field of image generation with methods such as image style transfer, available methods for video generation are scarce. Here, we introduce the Spatiotemporal Style Transfer (STST) algorithm, a dynamic visual stimulus generation framework that allows powerful manipulation and synthesis of video stimuli for vision research. It is based on a two-stream deep neural network model that factorizes spatial and temporal features to generate dynamic visual stimuli whose model layer activations are matched to those of input videos. As an example, we show that our algorithm enables the generation of model metamers, dynamic stimuli whose layer activations within our two-stream model are matched to those of natural videos. We show that these generated stimuli match the low-level spatiotemporal features of their natural counterparts but lack their high-level semantic features, making it a powerful paradigm to study object recognition. Late layer activations in deep vision models exhibited a lower similarity between natural and metameric stimuli compared to early layers, confirming the lack of high-level information in the generated stimuli. Finally, we use our generated stimuli to probe the representational capabilities of predictive coding deep networks. These results showcase potential applications of our algorithm as a versatile tool for dynamic stimulus generation in vision science.
Large Language Model-driven Meta-structure Discovery in Heterogeneous Information Network
Feb 18, 2024Heterogeneous information networks (HIN) have gained increasing popularity for being able to capture complex relations between nodes of diverse types. Meta-structure was proposed to identify important patterns of relations on HIN, which has been proven effective for extracting rich semantic information and facilitating graph neural networks to learn expressive representations. However, hand-crafted meta-structures pose challenges for scaling up, which draws wide research attention for developing automatic meta-structure search algorithms. Previous efforts concentrate on searching for meta-structures with good empirical prediction performance, overlooking explainability. Thus, they often produce meta-structures prone to overfitting and incomprehensible to humans. To address this, we draw inspiration from the emergent reasoning abilities of large language models (LLMs). We propose a novel REasoning meta-STRUCTure search (ReStruct) framework that integrates LLM reasoning into the evolutionary procedure. ReStruct uses a grammar translator to encode meta-structures into natural language sentences, and leverages the reasoning power of LLMs to evaluate semantically feasible meta-structures. ReStruct also employs performance-oriented evolutionary operations. These two competing forces jointly optimize for semantic explainability and empirical performance of meta-structures. We also design a differential LLM explainer that can produce natural language explanations for the discovered meta-structures, and refine the explanation by reasoning through the search history. Experiments on five datasets demonstrate ReStruct achieve SOTA performance in node classification and link recommendation tasks. Additionally, a survey study involving 73 graduate students shows that the meta-structures and natural language explanations generated by ReStruct are substantially more comprehensible.
Examination Minutes Measurement of Single-Antenna-Element Beamforming
Mar 07, 2024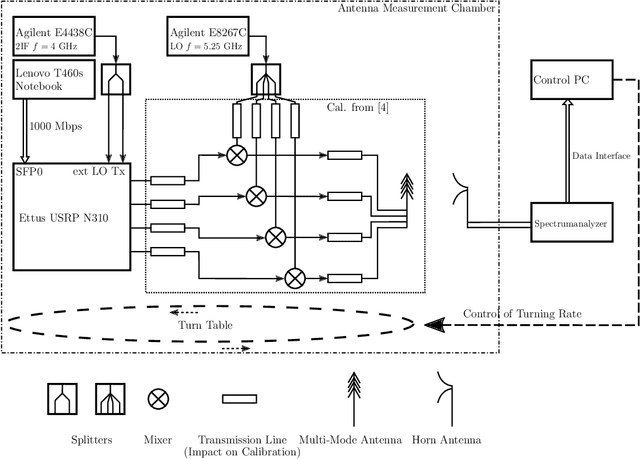
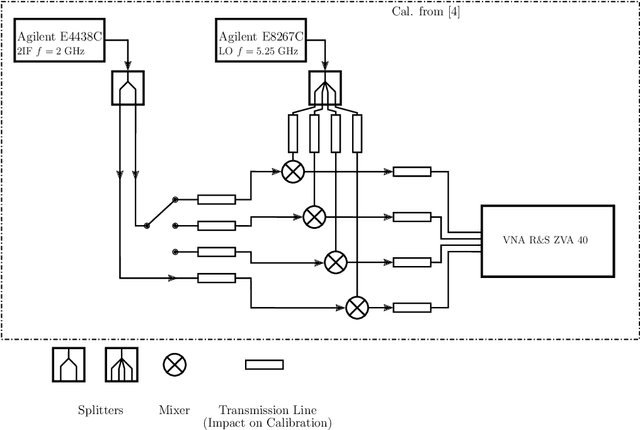


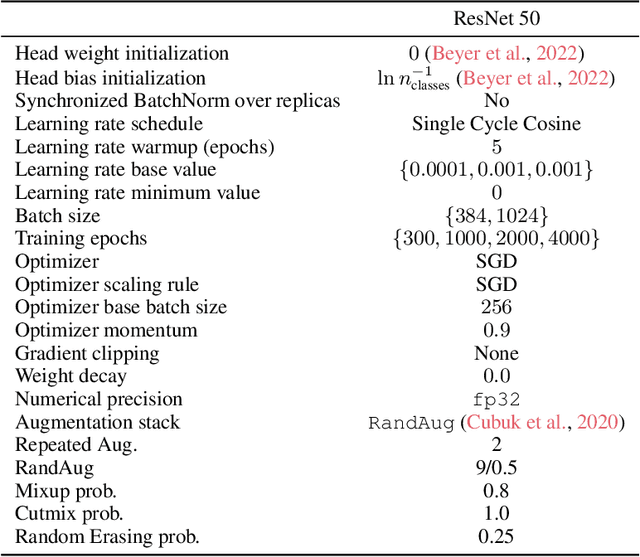
This document shall provide all knowledge gained in conjunction and preparation with the conducted measurements in the antenna measurement chamber of the Institute of Microwave and Wireless Systems (IMW) of the Leibniz University of Hannover (LUH). The measurements have been prepared and conducted by Lukas Grundmann, IMW, and Nils L. Johannsen, Chair of Information and Coding Theory (ICT) of the Christian- Albrechts-University (CAU) of Kiel. This minute shall allow a simpler understanding and quicker reapplication of the required calibrations and system setup for the measurements of further antennas.
Unity by Diversity: Improved Representation Learning in Multimodal VAEs
Mar 08, 2024
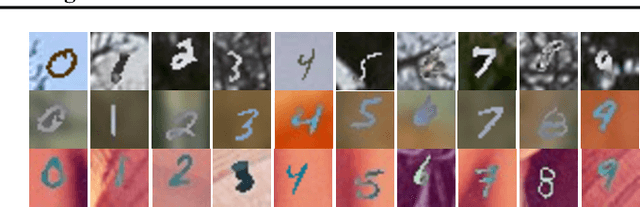
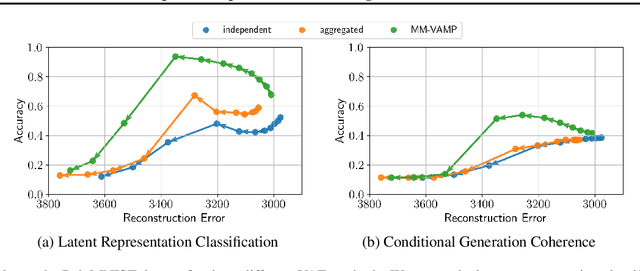
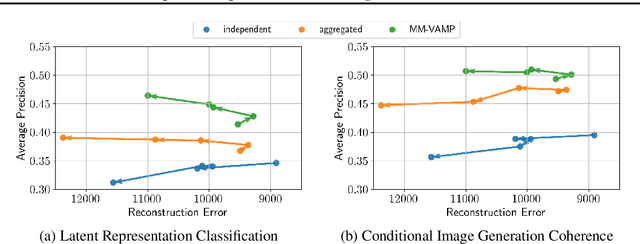
Variational Autoencoders for multimodal data hold promise for many tasks in data analysis, such as representation learning, conditional generation, and imputation. Current architectures either share the encoder output, decoder input, or both across modalities to learn a shared representation. Such architectures impose hard constraints on the model. In this work, we show that a better latent representation can be obtained by replacing these hard constraints with a soft constraint. We propose a new mixture-of-experts prior, softly guiding each modality's latent representation towards a shared aggregate posterior. This approach results in a superior latent representation and allows each encoding to preserve information from its uncompressed original features better. In extensive experiments on multiple benchmark datasets and a challenging real-world neuroscience data set, we show improved learned latent representations and imputation of missing data modalities compared to existing methods.
Binaural Speech Enhancement Using Deep Complex Convolutional Transformer Networks
Mar 08, 2024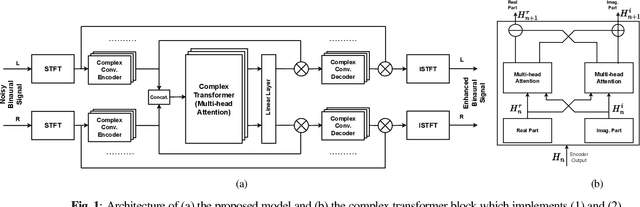
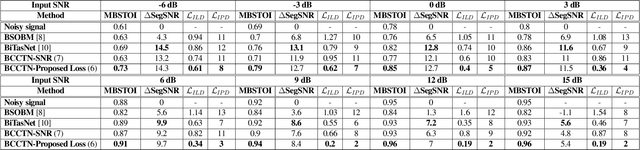
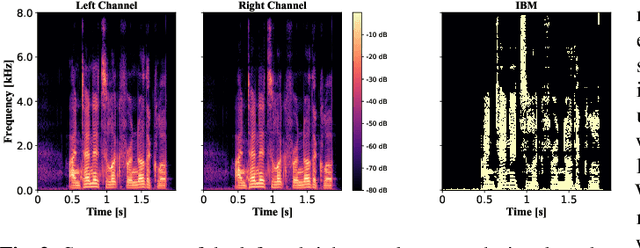
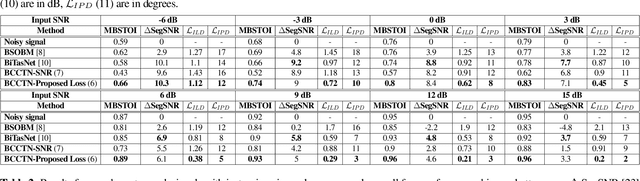
Studies have shown that in noisy acoustic environments, providing binaural signals to the user of an assistive listening device may improve speech intelligibility and spatial awareness. This paper presents a binaural speech enhancement method using a complex convolutional neural network with an encoder-decoder architecture and a complex multi-head attention transformer. The model is trained to estimate individual complex ratio masks in the time-frequency domain for the left and right-ear channels of binaural hearing devices. The model is trained using a novel loss function that incorporates the preservation of spatial information along with speech intelligibility improvement and noise reduction. Simulation results for acoustic scenarios with a single target speaker and isotropic noise of various types show that the proposed method improves the estimated binaural speech intelligibility and preserves the binaural cues better in comparison with several baseline algorithms.
DualBEV: CNN is All You Need in View Transformation
Mar 08, 2024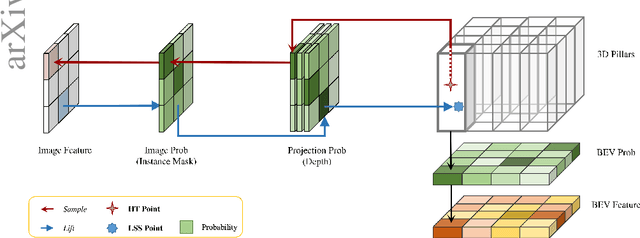


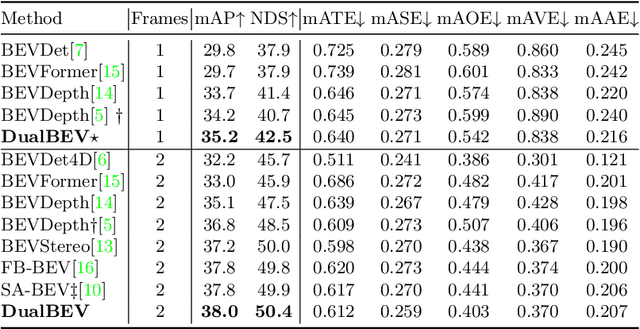
Camera-based Bird's-Eye-View (BEV) perception often struggles between adopting 3D-to-2D or 2D-to-3D view transformation (VT). The 3D-to-2D VT typically employs resource intensive Transformer to establish robust correspondences between 3D and 2D feature, while the 2D-to-3D VT utilizes the Lift-Splat-Shoot (LSS) pipeline for real-time application, potentially missing distant information. To address these limitations, we propose DualBEV, a unified framework that utilizes a shared CNN-based feature transformation incorporating three probabilistic measurements for both strategies. By considering dual-view correspondences in one-stage, DualBEV effectively bridges the gap between these strategies, harnessing their individual strengths. Our method achieves state-of-the-art performance without Transformer, delivering comparable efficiency to the LSS approach, with 55.2% mAP and 63.4% NDS on the nuScenes test set. Code will be released at https://github.com/PeidongLi/DualBEV.
LEO- and RIS-Empowered User Tracking: A Riemannian Manifold Approach
Mar 09, 2024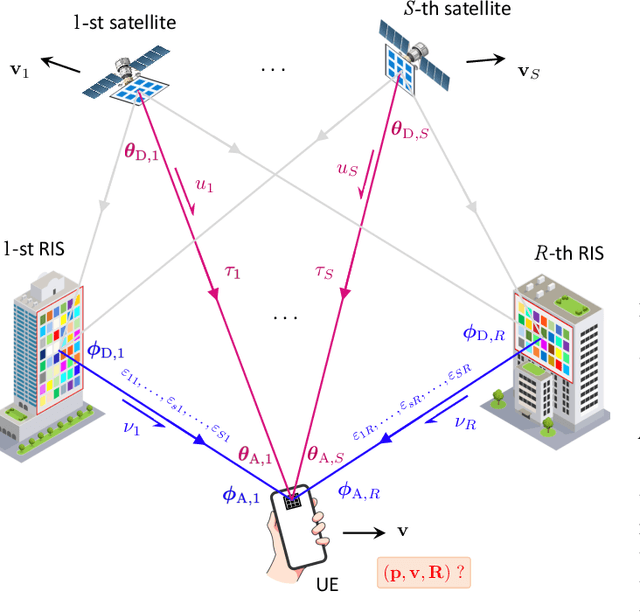
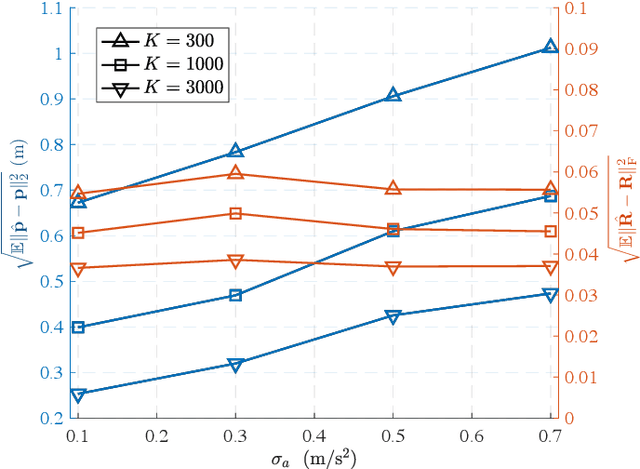
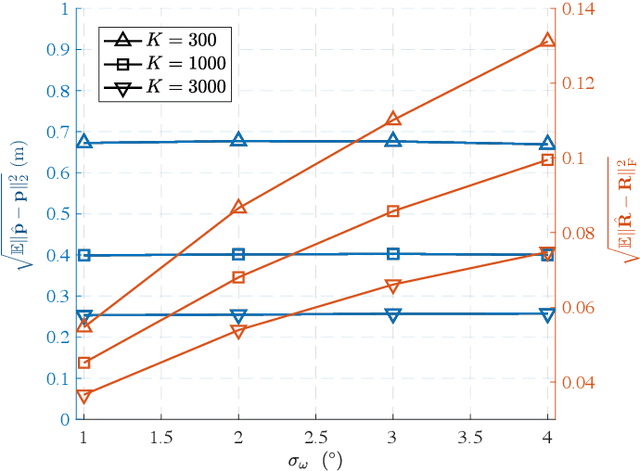
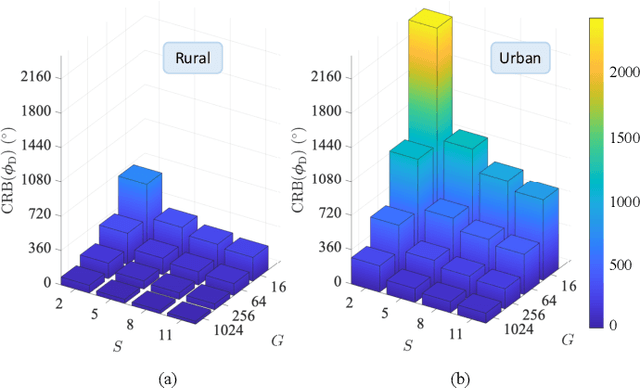
Low Earth orbit (LEO) satellites and reconfigurable intelligent surfaces (RISs) have recently drawn significant attention as two transformative technologies, and the synergy between them emerges as a promising paradigm for providing cross-environment communication and positioning services. This paper investigates an integrated terrestrial and non-terrestrial wireless network that leverages LEO satellites and RISs to achieve simultaneous tracking of the 3D position, 3D velocity, and 3D orientation of user equipment (UE). To address inherent challenges including nonlinear observation function, constrained UE state, and unknown observation statistics, we develop a Riemannian manifold-based unscented Kalman filter (UKF) method. This method propagates statistics over nonlinear functions using generated sigma points and maintains state constraints through projection onto the defined manifold space. Additionally, by employing Fisher information matrices (FIMs) of the sigma points, a belief assignment principle is proposed to approximate the unknown observation covariance matrix, thereby ensuring accurate measurement updates in the UKF procedure. Numerical results demonstrate a substantial enhancement in tracking accuracy facilitated by RIS integration, despite urban signal reception challenges from LEO satellites. In addition, extensive simulations underscore the superior performance of the proposed tracking method and FIM-based belief assignment over the adopted benchmarks. Furthermore, the robustness of the proposed UKF is verified across various uncertainty levels.
HAM-TTS: Hierarchical Acoustic Modeling for Token-Based Zero-Shot Text-to-Speech with Model and Data Scaling
Mar 09, 2024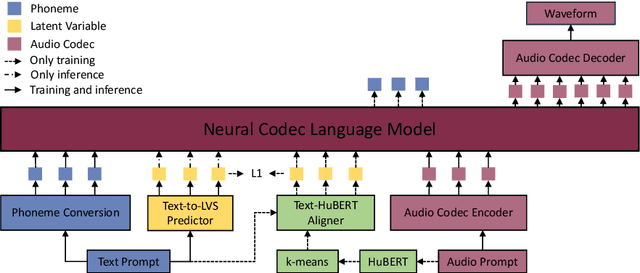
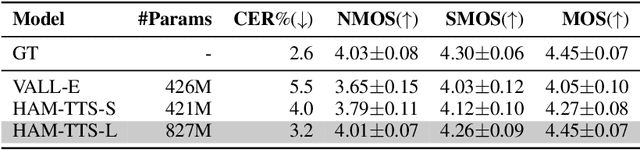
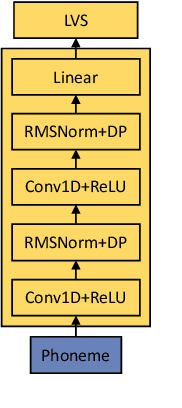
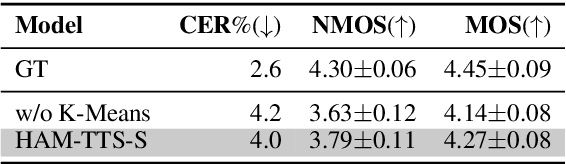
Token-based text-to-speech (TTS) models have emerged as a promising avenue for generating natural and realistic speech, yet they grapple with low pronunciation accuracy, speaking style and timbre inconsistency, and a substantial need for diverse training data. In response, we introduce a novel hierarchical acoustic modeling approach complemented by a tailored data augmentation strategy and train it on the combination of real and synthetic data, scaling the data size up to 650k hours, leading to the zero-shot TTS model with 0.8B parameters. Specifically, our method incorporates a latent variable sequence containing supplementary acoustic information based on refined self-supervised learning (SSL) discrete units into the TTS model by a predictor. This significantly mitigates pronunciation errors and style mutations in synthesized speech. During training, we strategically replace and duplicate segments of the data to enhance timbre uniformity. Moreover, a pretrained few-shot voice conversion model is utilized to generate a plethora of voices with identical content yet varied timbres. This facilitates the explicit learning of utterance-level one-to-many mappings, enriching speech diversity and also ensuring consistency in timbre. Comparative experiments (Demo page: https://anonymous.4open.science/w/ham-tts/)demonstrate our model's superiority over VALL-E in pronunciation precision and maintaining speaking style, as well as timbre continuity.