 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Crab: Learning Certifiably Fair Predictive Models in the Presence of Selection Bias
Dec 21, 2022
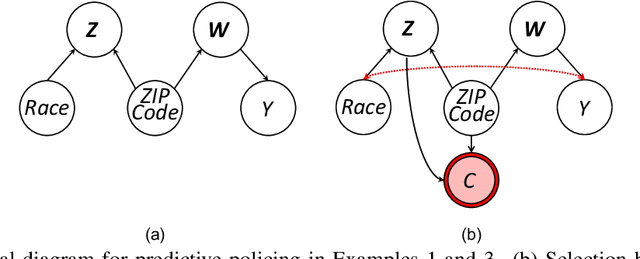
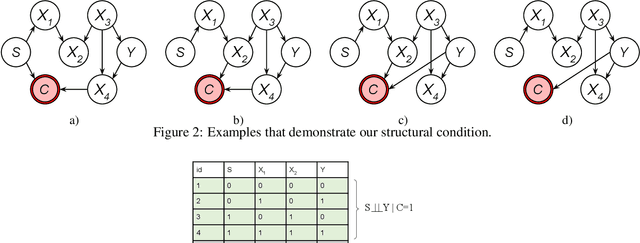
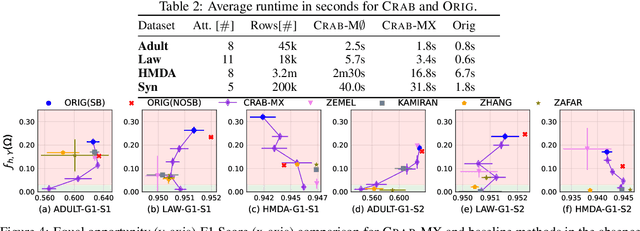
A recent explosion of research focuses on developing methods and tools for building fair predictive models. However, most of this work relies on the assumption that the training and testing data are representative of the target population on which the model will be deployed. However, real-world training data often suffer from selection bias and are not representative of the target population for many reasons, including the cost and feasibility of collecting and labeling data, historical discrimination, and individual biases. In this paper, we introduce a new framework for certifying and ensuring the fairness of predictive models trained on biased data. We take inspiration from query answering over incomplete and inconsistent databases to present and formalize the problem of consistent range approximation (CRA) of answers to queries about aggregate information for the target population. We aim to leverage background knowledge about the data collection process, biased data, and limited or no auxiliary data sources to compute a range of answers for aggregate queries over the target population that are consistent with available information. We then develop methods that use CRA of such aggregate queries to build predictive models that are certifiably fair on the target population even when no external information about that population is available during training. We evaluate our methods on real data and demonstrate improvements over state of the art. Significantly, we show that enforcing fairness using our methods can lead to predictive models that are not only fair, but more accurate on the target population.
Contextual Conservative Q-Learning for Offline Reinforcement Learning
Jan 16, 2023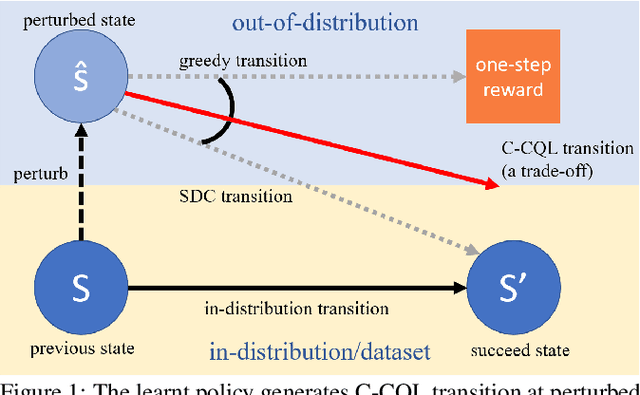
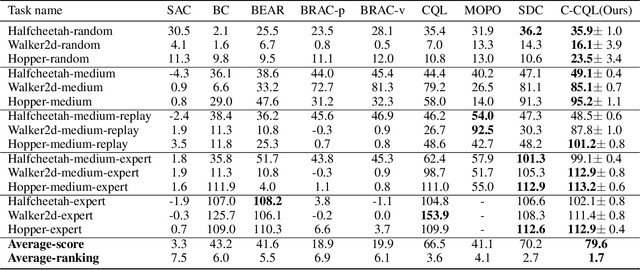
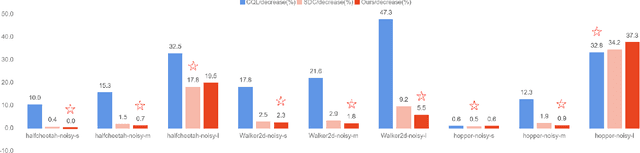
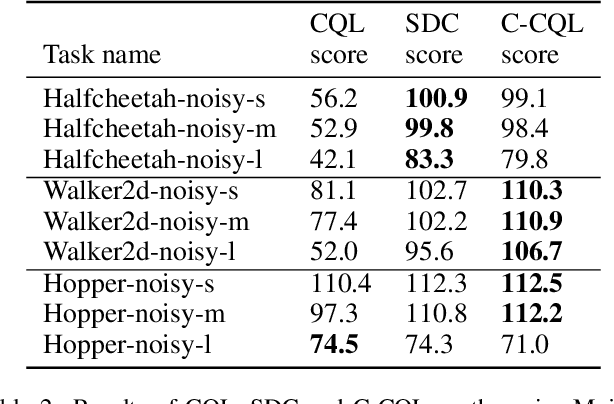
Offline reinforcement learning learns an effective policy on offline datasets without online interaction, and it attracts persistent research attention due to its potential of practical application. However, extrapolation error generated by distribution shift will still lead to the overestimation for those actions that transit to out-of-distribution(OOD) states, which degrades the reliability and robustness of the offline policy. In this paper, we propose Contextual Conservative Q-Learning(C-CQL) to learn a robustly reliable policy through the contextual information captured via an inverse dynamics model. With the supervision of the inverse dynamics model, it tends to learn a policy that generates stable transition at perturbed states, for the fact that pertuebed states are a common kind of OOD states. In this manner, we enable the learnt policy more likely to generate transition that destines to the empirical next state distributions of the offline dataset, i.e., robustly reliable transition. Besides, we theoretically reveal that C-CQL is the generalization of the Conservative Q-Learning(CQL) and aggressive State Deviation Correction(SDC). Finally, experimental results demonstrate the proposed C-CQL achieves the state-of-the-art performance in most environments of offline Mujoco suite and a noisy Mujoco setting.
Lightweight integration of 3D features to improve 2D image segmentation
Dec 16, 2022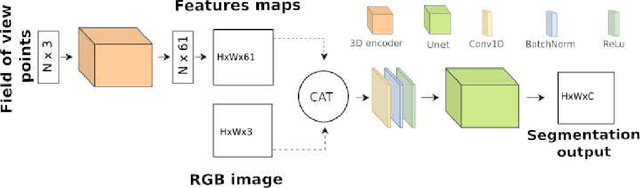

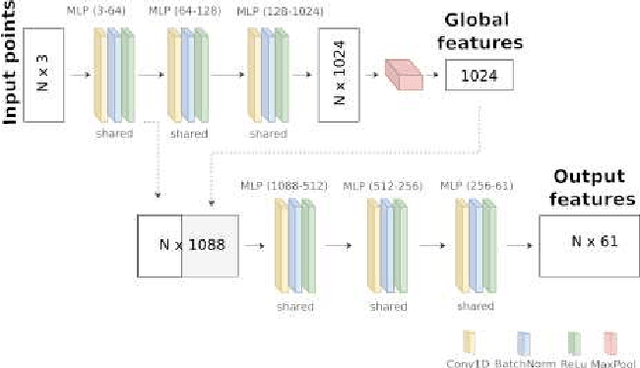

Scene understanding is a major challenge of today's computer vision. Center to this task is image segmentation, since scenes are often provided as a set of pictures. Nowadays, many such datasets also provide 3D geometry information given as a 3D point cloud acquired by a laser scanner or a depth camera. To exploit this geometric information, many current approaches rely on both a 2D loss and 3D loss, requiring not only 2D per pixel labels but also 3D per point labels. However obtaining a 3D groundtruth is challenging, time-consuming and error-prone. In this paper, we show that image segmentation can benefit from 3D geometric information without requiring any 3D groundtruth, by training the geometric feature extraction with a 2D segmentation loss in an end-to-end fashion. Our method starts by extracting a map of 3D features directly from the point cloud by using a lightweight and simple 3D encoder neural network. The 3D feature map is then used as an additional input to a classical image segmentation network. During training, the 3D features extraction is optimized for the segmentation task by back-propagation through the entire pipeline. Our method exhibits state-of-the-art performance with much lighter input dataset requirements, since no 3D groundtruth is required.
Swing Distillation: A Privacy-Preserving Knowledge Distillation Framework
Dec 16, 2022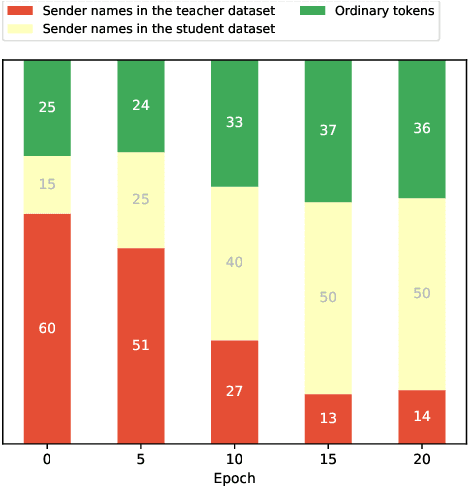
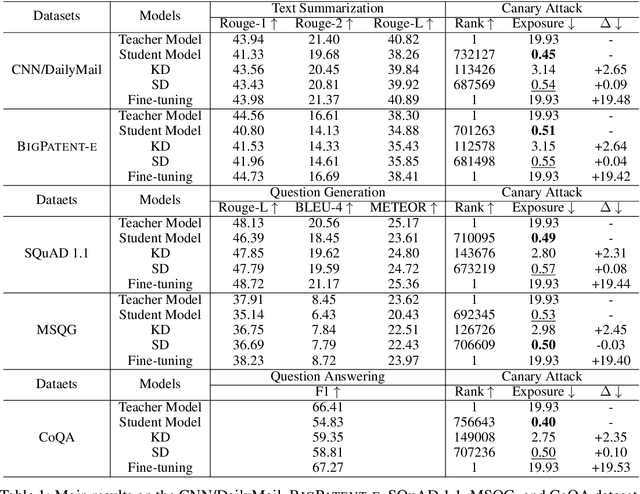
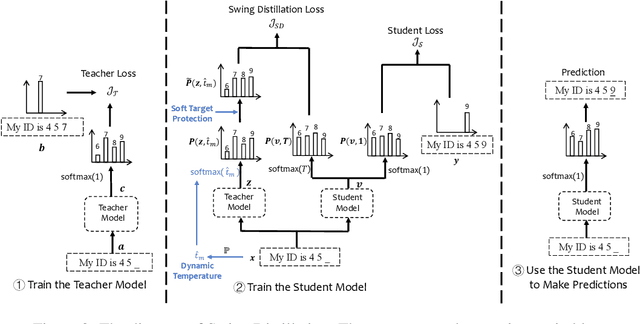
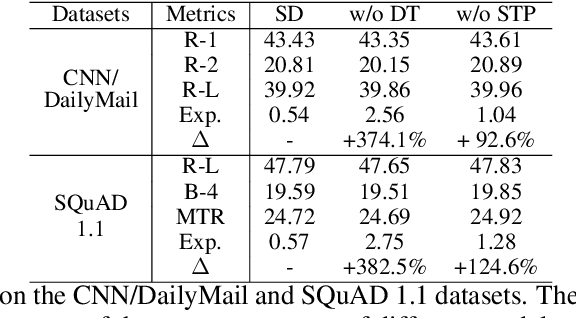
Knowledge distillation (KD) has been widely used for model compression and knowledge transfer. Typically, a big teacher model trained on sufficient data transfers knowledge to a small student model. However, despite the success of KD, little effort has been made to study whether KD leaks the training data of the teacher model. In this paper, we experimentally reveal that KD suffers from the risk of privacy leakage. To alleviate this issue, we propose a novel knowledge distillation method, swing distillation, which can effectively protect the private information of the teacher model from flowing to the student model. In our framework, the temperature coefficient is dynamically and adaptively adjusted according to the degree of private information contained in the data, rather than a predefined constant hyperparameter. It assigns different temperatures to tokens according to the likelihood that a token in a position contains private information. In addition, we inject noise into soft targets provided to the student model, in order to avoid unshielded knowledge transfer. Experiments on multiple datasets and tasks demonstrate that the proposed swing distillation can significantly reduce (by over 80% in terms of canary exposure) the risk of privacy leakage in comparison to KD with competitive or better performance. Furthermore, swing distillation is robust against the increasing privacy budget.
Probing Deep Speaker Embeddings for Speaker-related Tasks
Dec 14, 2022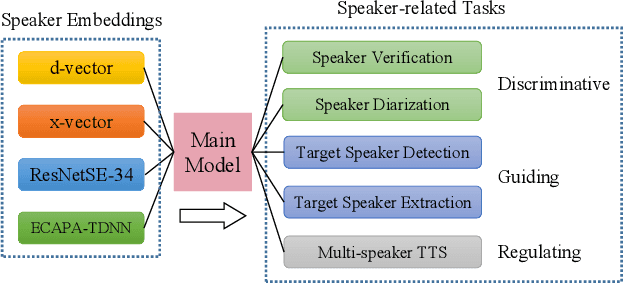

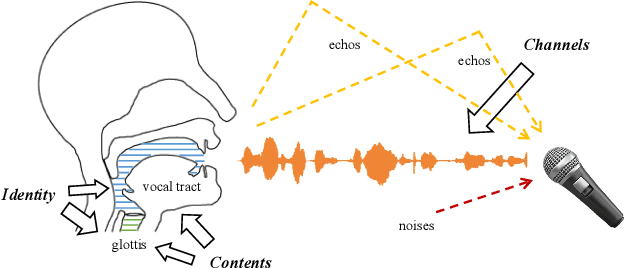
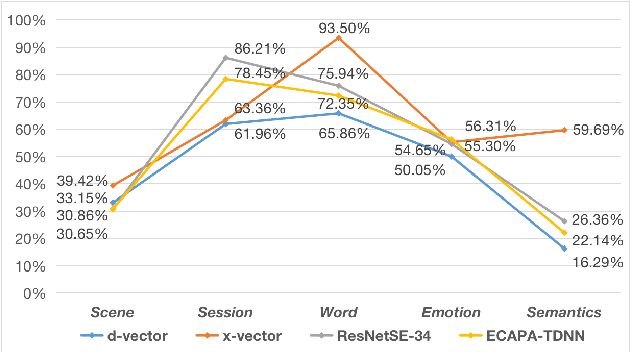
Deep speaker embeddings have shown promising results in speaker recognition, as well as in other speaker-related tasks. However, some issues are still under explored, for instance, the information encoded in these representations and their influence on downstream tasks. Four deep speaker embeddings are studied in this paper, namely, d-vector, x-vector, ResNetSE-34 and ECAPA-TDNN. Inspired by human voice mechanisms, we explored possibly encoded information from perspectives of identity, contents and channels; Based on this, experiments were conducted on three categories of speaker-related tasks to further explore impacts of different deep embeddings, including discriminative tasks (speaker verification and diarization), guiding tasks (target speaker detection and extraction) and regulating tasks (multi-speaker text-to-speech). Results show that all deep embeddings encoded channel and content information in addition to speaker identity, but the extent could vary and their performance on speaker-related tasks can be tremendously different: ECAPA-TDNN is dominant in discriminative tasks, and d-vector leads the guiding tasks, while regulating task is less sensitive to the choice of speaker representations. These may benefit future research utilizing speaker embeddings.
Unsupervised Detection of Contextualized Embedding Bias with Application to Ideology
Dec 14, 2022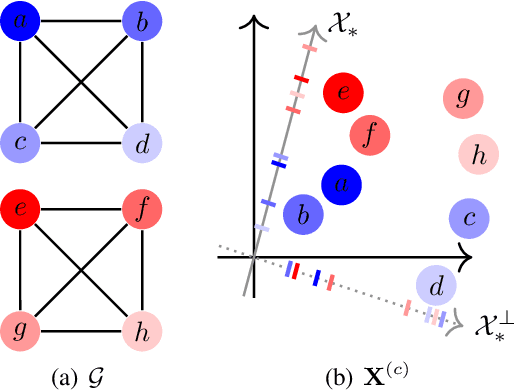

We propose a fully unsupervised method to detect bias in contextualized embeddings. The method leverages the assortative information latently encoded by social networks and combines orthogonality regularization, structured sparsity learning, and graph neural networks to find the embedding subspace capturing this information. As a concrete example, we focus on the phenomenon of ideological bias: we introduce the concept of an ideological subspace, show how it can be found by applying our method to online discussion forums, and present techniques to probe it. Our experiments suggest that the ideological subspace encodes abstract evaluative semantics and reflects changes in the political left-right spectrum during the presidency of Donald Trump.
ROIFormer: Semantic-Aware Region of Interest Transformer for Efficient Self-Supervised Monocular Depth Estimation
Dec 12, 2022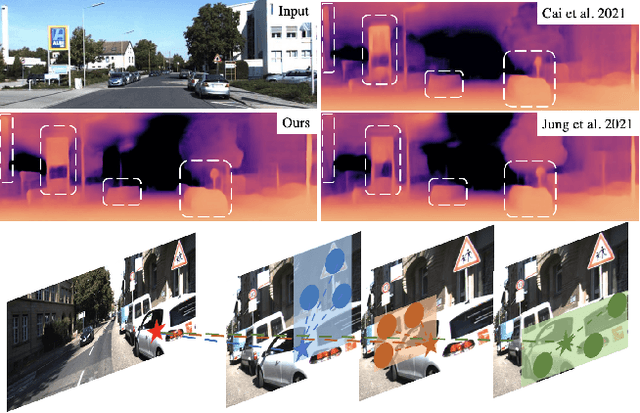
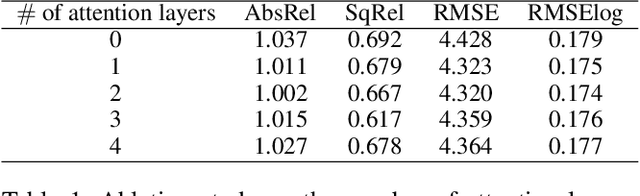
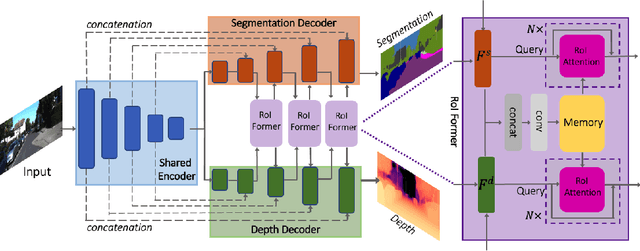
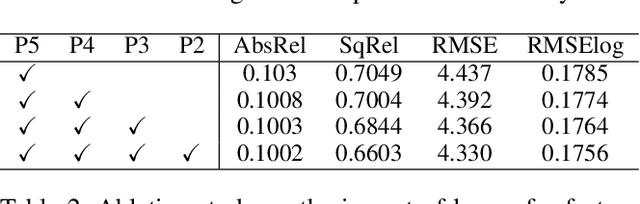
The exploration of mutual-benefit cross-domains has shown great potential toward accurate self-supervised depth estimation. In this work, we revisit feature fusion between depth and semantic information and propose an efficient local adaptive attention method for geometric aware representation enhancement. Instead of building global connections or deforming attention across the feature space without restraint, we bound the spatial interaction within a learnable region of interest. In particular, we leverage geometric cues from semantic information to learn local adaptive bounding boxes to guide unsupervised feature aggregation. The local areas preclude most irrelevant reference points from attention space, yielding more selective feature learning and faster convergence. We naturally extend the paradigm into a multi-head and hierarchic way to enable the information distillation in different semantic levels and improve the feature discriminative ability for fine-grained depth estimation. Extensive experiments on the KITTI dataset show that our proposed method establishes a new state-of-the-art in self-supervised monocular depth estimation task, demonstrating the effectiveness of our approach over former Transformer variants.
Attentional Graph Convolutional Network for Structure-aware Audio-Visual Scene Classification
Dec 31, 2022
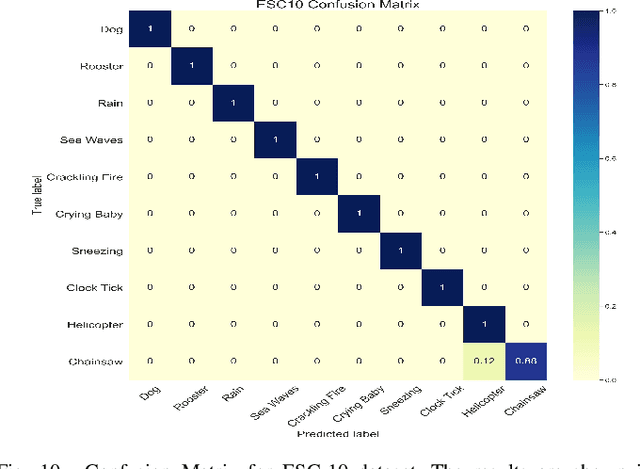
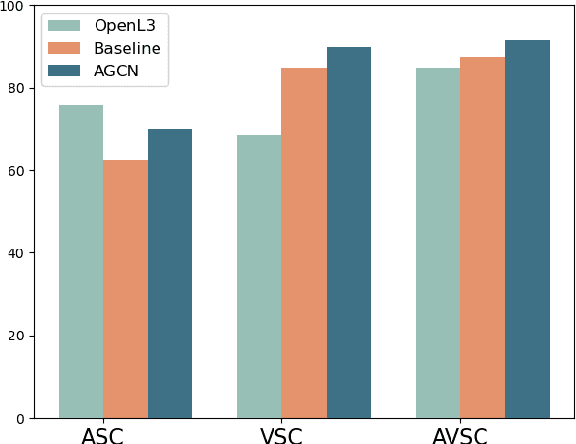
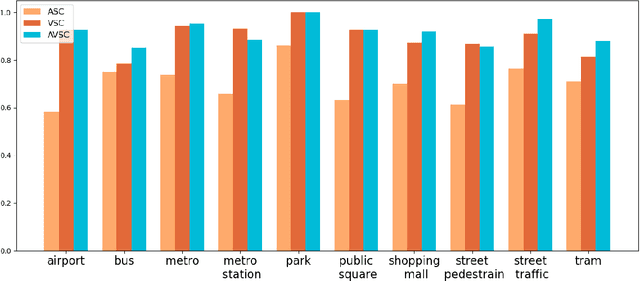
Audio-Visual scene understanding is a challenging problem due to the unstructured spatial-temporal relations that exist in the audio signals and spatial layouts of different objects and various texture patterns in the visual images. Recently, many studies have focused on abstracting features from convolutional neural networks while the learning of explicit semantically relevant frames of sound signals and visual images has been overlooked. To this end, we present an end-to-end framework, namely attentional graph convolutional network (AGCN), for structure-aware audio-visual scene representation. First, the spectrogram of sound and input image is processed by a backbone network for feature extraction. Then, to build multi-scale hierarchical information of input features, we utilize an attention fusion mechanism to aggregate features from multiple layers of the backbone network. Notably, to well represent the salient regions and contextual information of audio-visual inputs, the salient acoustic graph (SAG) and contextual acoustic graph (CAG), salient visual graph (SVG), and contextual visual graph (CVG) are constructed for the audio-visual scene representation. Finally, the constructed graphs pass through a graph convolutional network for structure-aware audio-visual scene recognition. Extensive experimental results on the audio, visual and audio-visual scene recognition datasets show that promising results have been achieved by the AGCN methods. Visualizing graphs on the spectrograms and images have been presented to show the effectiveness of proposed CAG/SAG and CVG/SVG that could focus on the salient and semantic relevant regions.
RECOMMED: A Comprehensive Pharmaceutical Recommendation System
Dec 31, 2022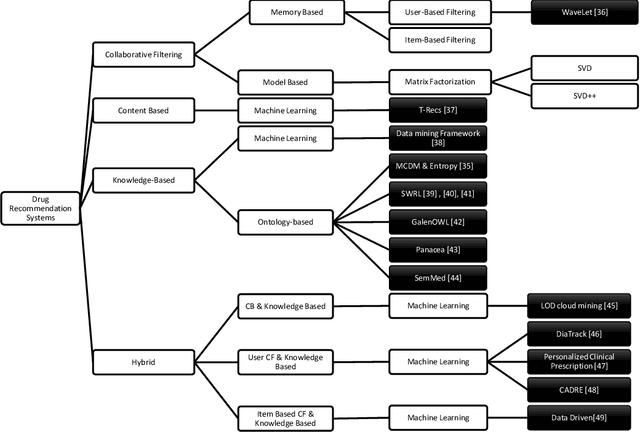
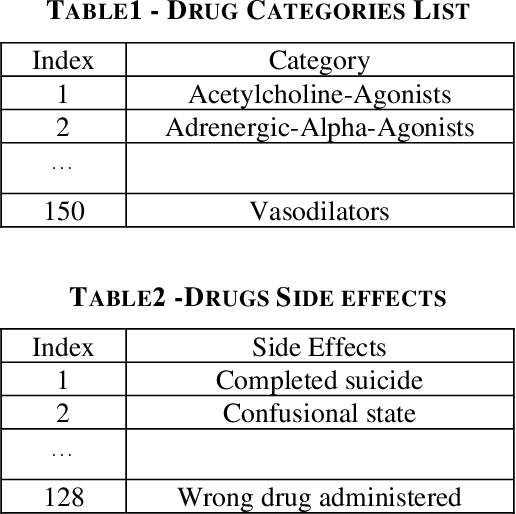
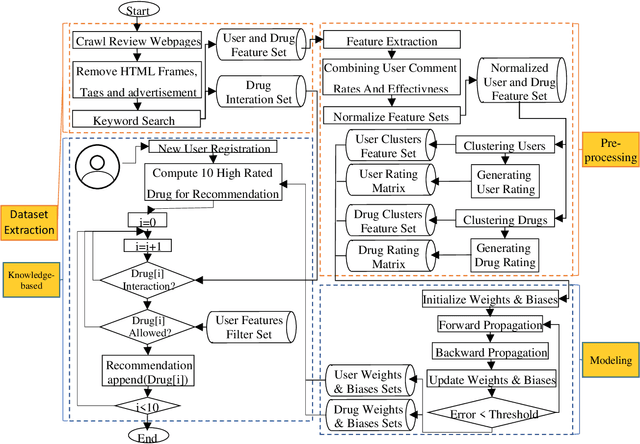
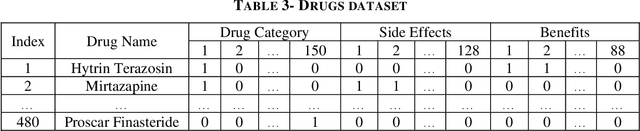
A comprehensive pharmaceutical recommendation system was designed based on the patients and drugs features extracted from Drugs.com and Druglib.com. First, data from these databases were combined, and a dataset of patients and drug information was built. Secondly, the patients and drugs were clustered, and then the recommendation was performed using different ratings provided by patients, and importantly by the knowledge obtained from patients and drug specifications, and considering drug interactions. To the best of our knowledge, we are the first group to consider patients conditions and history in the proposed approach for selecting a specific medicine appropriate for that particular user. Our approach applies artificial intelligence (AI) models for the implementation. Sentiment analysis using natural language processing approaches is employed in pre-processing along with neural network-based methods and recommender system algorithms for modeling the system. In our work, patients conditions and drugs features are used for making two models based on matrix factorization. Then we used drug interaction to filter drugs with severe or mild interactions with other drugs. We developed a deep learning model for recommending drugs by using data from 2304 patients as a training set, and then we used data from 660 patients as our validation set. After that, we used knowledge from critical information about drugs and combined the outcome of the model into a knowledge-based system with the rules obtained from constraints on taking medicine.
Tacchi: A Pluggable and Low Computational Cost Elastomer Deformation Simulator for Optical Tactile Sensors
Jan 19, 2023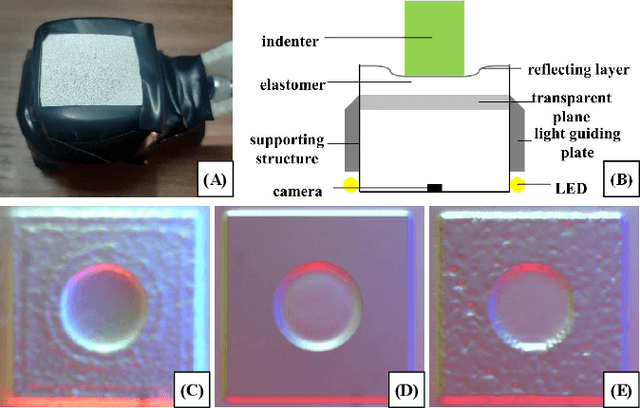
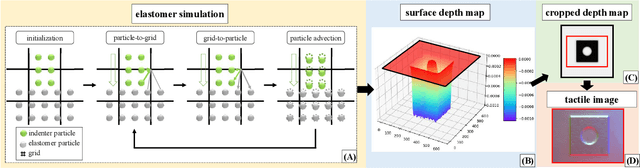
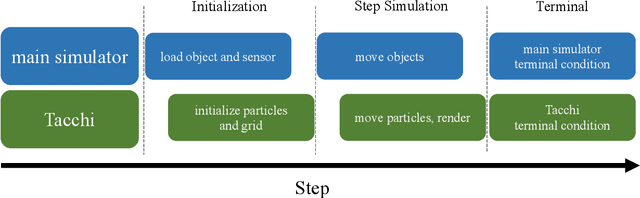

Simulation is widely applied in robotics research to save time and resources. There have been several works to simulate optical tactile sensors that leverage either a smoothing method or Finite Element Method (FEM). However, elastomer deformation physics is not considered in the former method, whereas the latter requires a massive amount of computational resources like a computer cluster. In this work, we propose a pluggable and low computational cost simulator using the Taichi programming language for simulating optical tactile sensors, named as Tacchi . It reconstructs elastomer deformation using particles, which allows deformed elastomer surfaces to be rendered into tactile images and reveals contact information without suffering from high computational costs. Tacchi facilitates creating realistic tactile images in simulation, e.g., ones that capture wear-and-tear defects on object surfaces. In addition, the proposed Tacchi can be integrated with robotics simulators for a robot system simulation. Experiment results showed that Tacchi can produce images with better similarity to real images and achieved higher Sim2Real accuracy compared to the existing methods. Moreover, it can be connected with MuJoCo and Gazebo with only the requirement of 1G memory space in GPU compared to a computer cluster applied for FEM. With Tacchi, physical robot simulation with optical tactile sensors becomes possible. All the materials in this paper are available at https://github.com/zixichen007115/Tacchi .