 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Posterior sampling with CNN-based, Plug-and-Play regularization with applications to Post-Stack Seismic Inversion
Dec 30, 2022
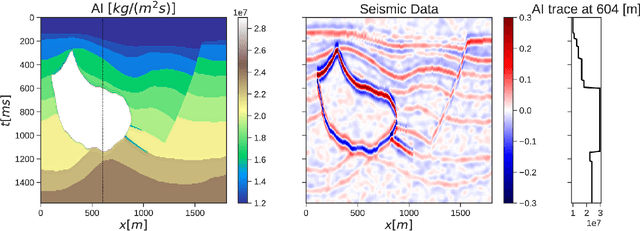
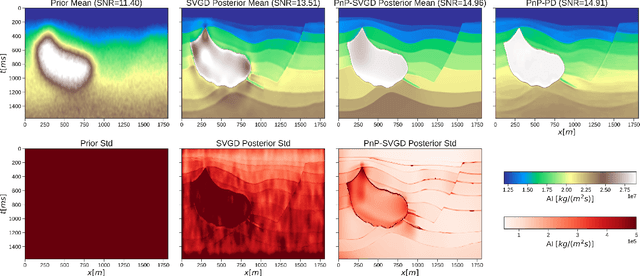
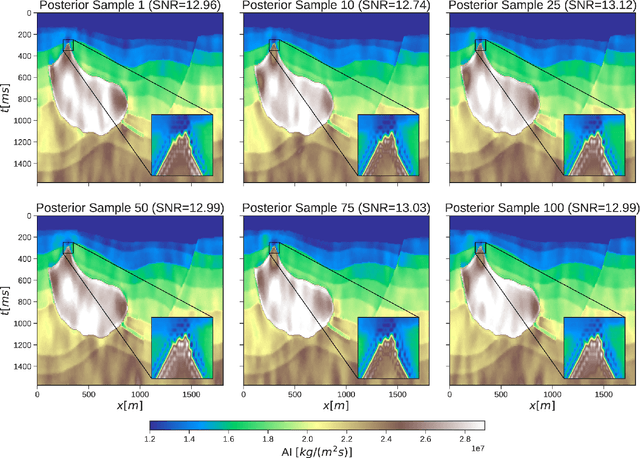
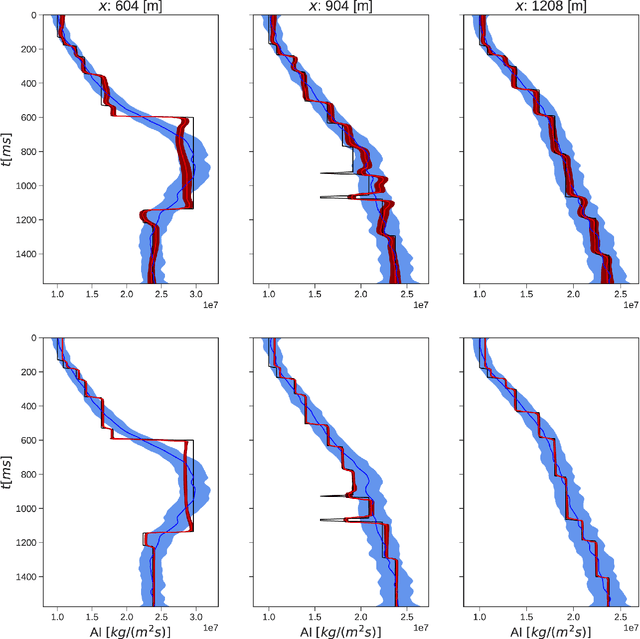
Uncertainty quantification is crucial to inverse problems, as it could provide decision-makers with valuable information about the inversion results. For example, seismic inversion is a notoriously ill-posed inverse problem due to the band-limited and noisy nature of seismic data. It is therefore of paramount importance to quantify the uncertainties associated to the inversion process to ease the subsequent interpretation and decision making processes. Within this framework of reference, sampling from a target posterior provides a fundamental approach to quantifying the uncertainty in seismic inversion. However, selecting appropriate prior information in a probabilistic inversion is crucial, yet non-trivial, as it influences the ability of a sampling-based inference in providing geological realism in the posterior samples. To overcome such limitations, we present a regularized variational inference framework that performs posterior inference by implicitly regularizing the Kullback-Leibler divergence loss with a CNN-based denoiser by means of the Plug-and-Play methods. We call this new algorithm Plug-and-Play Stein Variational Gradient Descent (PnP-SVGD) and demonstrate its ability in producing high-resolution, trustworthy samples representative of the subsurface structures, which we argue could be used for post-inference tasks such as reservoir modelling and history matching. To validate the proposed method, numerical tests are performed on both synthetic and field post-stack seismic data.
Choose, not Hoard: Information-to-Model Matching for Artificial Intelligence in O-RAN
Aug 01, 2022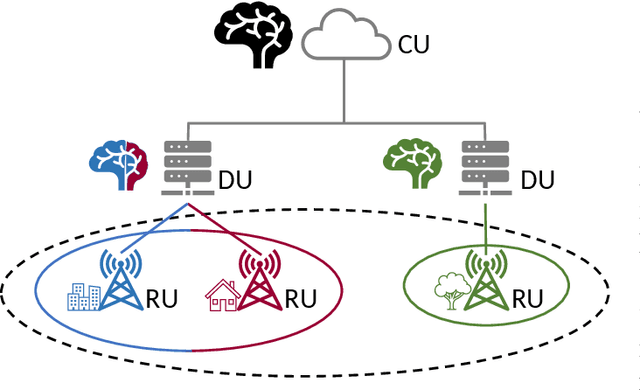
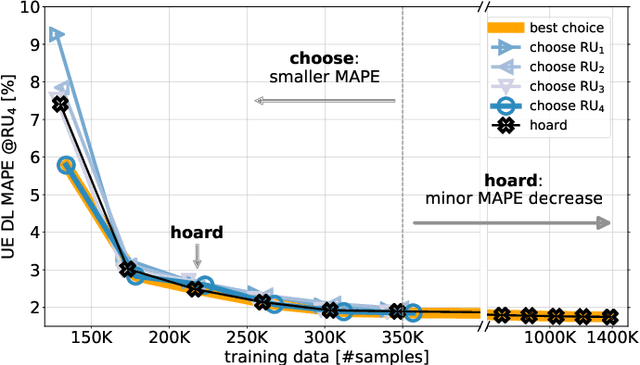
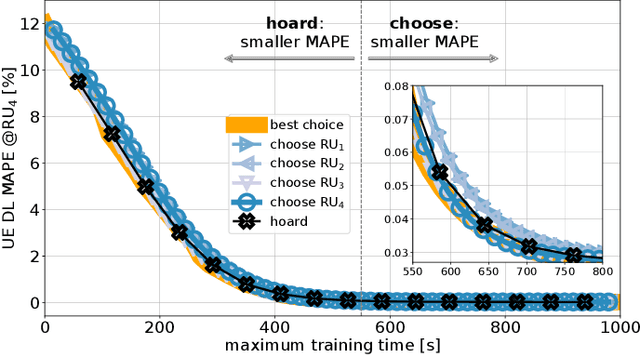
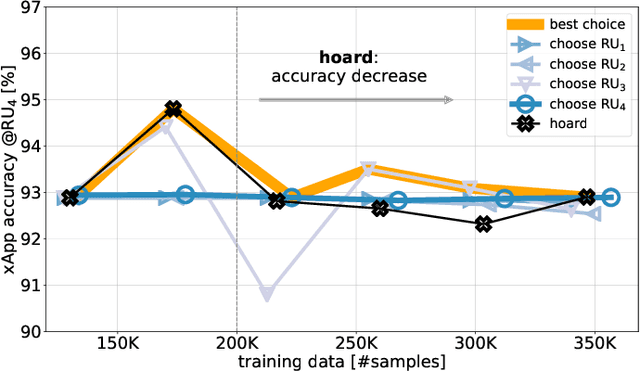
Open Radio Access Network (O-RAN) is an emerging paradigm, whereby virtualized network infrastructure elements from different vendors communicate via open, standardized interfaces. A key element therein is the RAN Intelligent Controller (RIC), an Artificial Intelligence (AI)-based controller. Traditionally, all data available in the network has been used to train a single AI model to use at the RIC. In this paper we introduce, discuss, and evaluate the creation of multiple AI model instances at different RICs, leveraging information from some (or all) locations for their training. This brings about a flexible relationship between gNBs, the AI models used to control them, and the data such models are trained with. Experiments with real-world traces show how using multiple AI model instances that choose training data from specific locations improve the performance of traditional approaches.
Towards mapping the contemporary art world with ArtLM: an art-specific NLP model
Dec 22, 2022
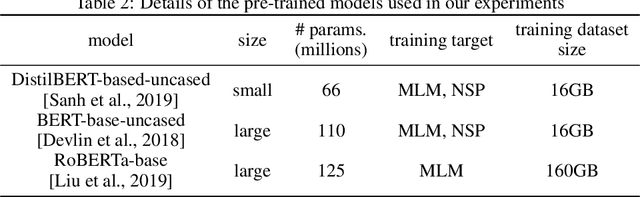

With an increasing amount of data in the art world, discovering artists and artworks suitable to collectors' tastes becomes a challenge. It is no longer enough to use visual information, as contextual information about the artist has become just as important in contemporary art. In this work, we present a generic Natural Language Processing framework (called ArtLM) to discover the connections among contemporary artists based on their biographies. In this approach, we first continue to pre-train the existing general English language models with a large amount of unlabelled art-related data. We then fine-tune this new pre-trained model with our biography pair dataset manually annotated by a team of professionals in the art industry. With extensive experiments, we demonstrate that our ArtLM achieves 85.6% accuracy and 84.0% F1 score and outperforms other baseline models. We also provide a visualisation and a qualitative analysis of the artist network built from ArtLM's outputs.
Multimodality Helps Unimodality: Cross-Modal Few-Shot Learning with Multimodal Models
Jan 18, 2023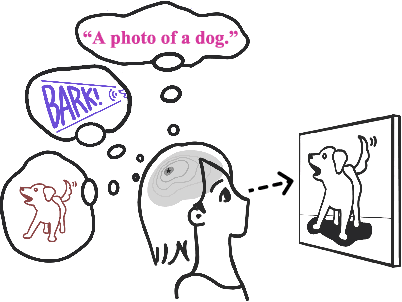

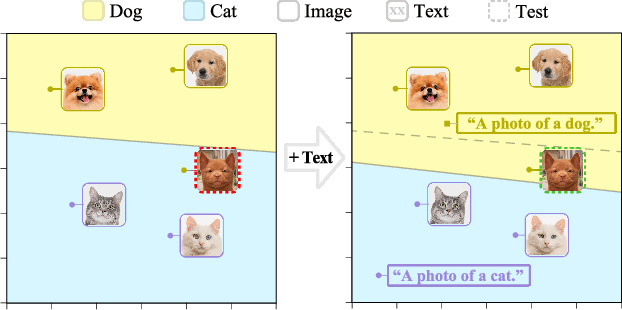
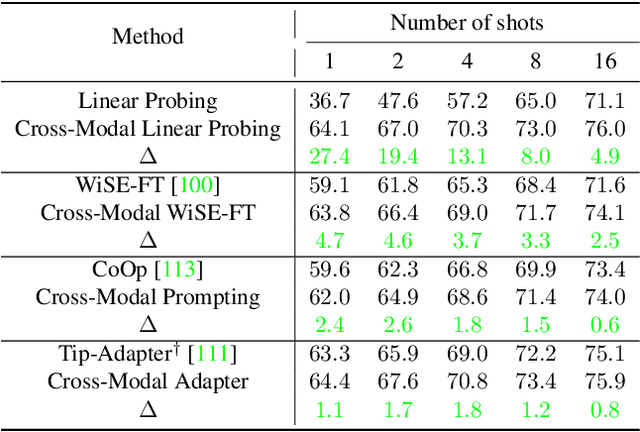
The ability to quickly learn a new task with minimal instruction - known as few-shot learning - is a central aspect of intelligent agents. Classical few-shot benchmarks make use of few-shot samples from a single modality, but such samples may not be sufficient to characterize an entire concept class. In contrast, humans use cross-modal information to learn new concepts efficiently. In this work, we demonstrate that one can indeed build a better ${\bf visual}$ dog classifier by ${\bf read}$ing about dogs and ${\bf listen}$ing to them bark. To do so, we exploit the fact that recent multimodal foundation models such as CLIP are inherently cross-modal, mapping different modalities to the same representation space. Specifically, we propose a simple cross-modal adaptation approach that learns from few-shot examples spanning different modalities. By repurposing class names as additional one-shot training samples, we achieve SOTA results with an embarrassingly simple linear classifier for vision-language adaptation. Furthermore, we show that our approach can benefit existing methods such as prefix tuning, adapters, and classifier ensembling. Finally, to explore other modalities beyond vision and language, we construct the first (to our knowledge) audiovisual few-shot benchmark and use cross-modal training to improve the performance of both image and audio classification.
MADAv2: Advanced Multi-Anchor Based Active Domain Adaptation Segmentation
Jan 18, 2023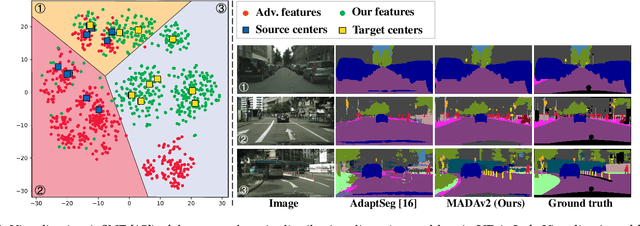
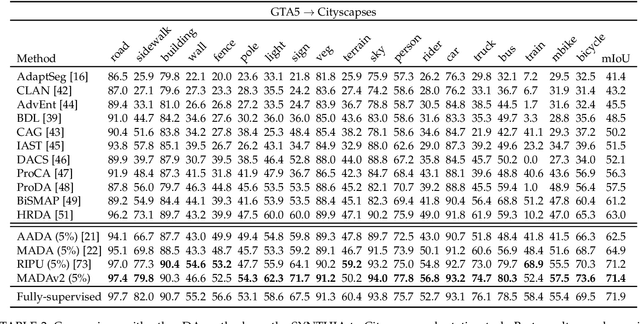
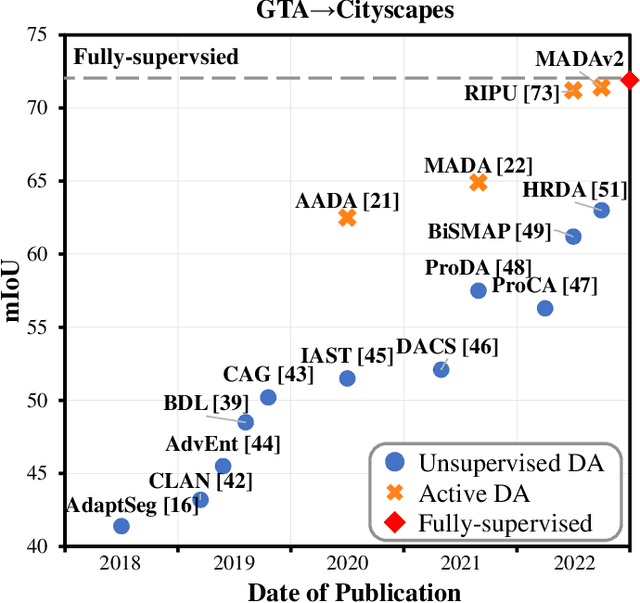

Unsupervised domain adaption has been widely adopted in tasks with scarce annotated data. Unfortunately, mapping the target-domain distribution to the source-domain unconditionally may distort the essential structural information of the target-domain data, leading to inferior performance. To address this issue, we firstly propose to introduce active sample selection to assist domain adaptation regarding the semantic segmentation task. By innovatively adopting multiple anchors instead of a single centroid, both source and target domains can be better characterized as multimodal distributions, in which way more complementary and informative samples are selected from the target domain. With only a little workload to manually annotate these active samples, the distortion of the target-domain distribution can be effectively alleviated, achieving a large performance gain. In addition, a powerful semi-supervised domain adaptation strategy is proposed to alleviate the long-tail distribution problem and further improve the segmentation performance. Extensive experiments are conducted on public datasets, and the results demonstrate that the proposed approach outperforms state-of-the-art methods by large margins and achieves similar performance to the fully-supervised upperbound, i.e., 71.4% mIoU on GTA5 and 71.8% mIoU on SYNTHIA. The effectiveness of each component is also verified by thorough ablation studies.
Generative Adversarial Networks to infer velocity components in rotating turbulent flows
Jan 18, 2023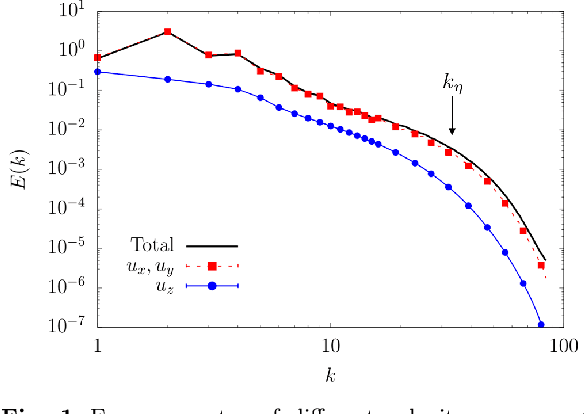
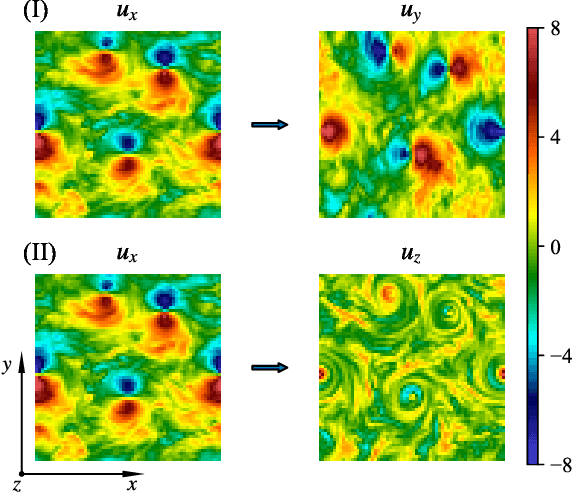
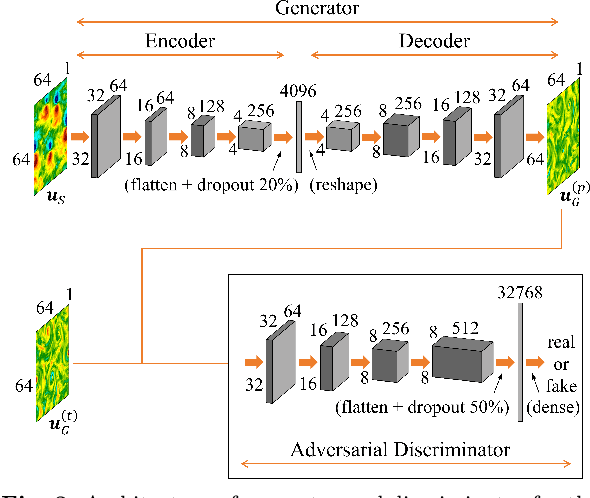

Inference problems for two-dimensional snapshots of rotating turbulent flows are studied. We perform a systematic quantitative benchmark of point-wise and statistical reconstruction capabilities of the linear Extended Proper Orthogonal Decomposition (EPOD) method, a non-linear Convolutional Neural Network (CNN) and a Generative Adversarial Network (GAN). We attack the important task of inferring one velocity component out of the measurement of a second one, and two cases are studied: (I) both components lay in the plane orthogonal to the rotation axis and (II) one of the two is parallel to the rotation axis. We show that EPOD method works well only for the former case where both components are strongly correlated, while CNN and GAN always outperform EPOD both concerning point-wise and statistical reconstructions. For case (II), when the input and output data are weakly correlated, all methods fail to reconstruct faithfully the point-wise information. In this case, only GAN is able to reconstruct the field in a statistical sense. The analysis is performed using both standard validation tools based on L2 spatial distance between the prediction and the ground truth and more sophisticated multi-scale analysis using wavelet decomposition. Statistical validation is based on standard Jensen-Shannon divergence between the probability density functions, spectral properties and multi-scale flatness.
Training Semantic Segmentation on Heterogeneous Datasets
Jan 18, 2023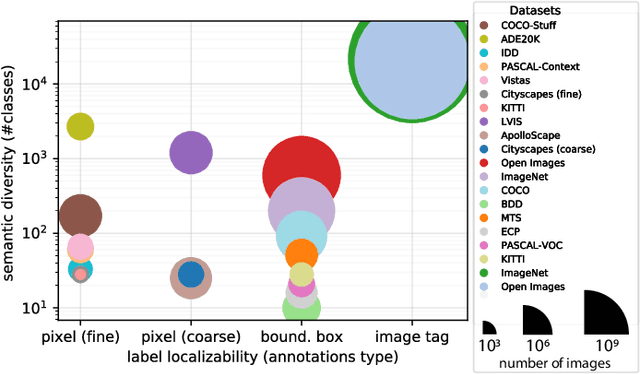
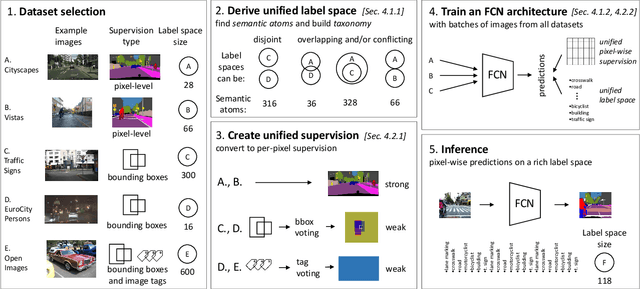
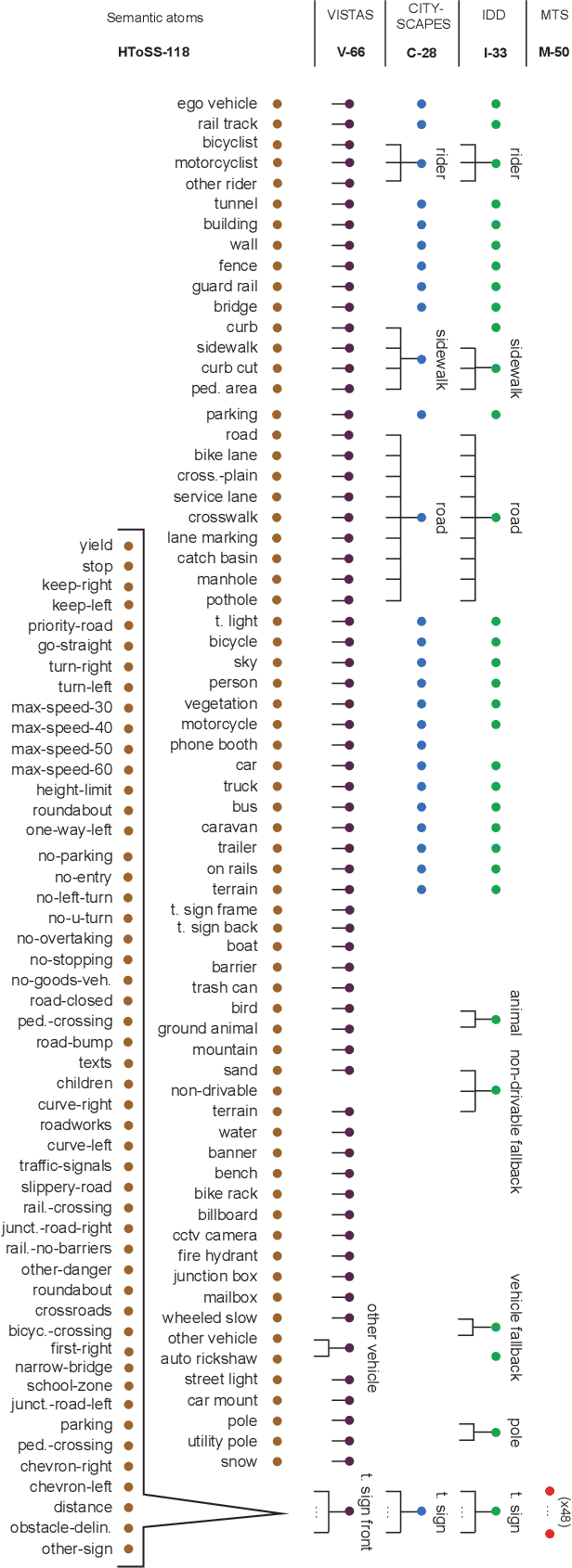
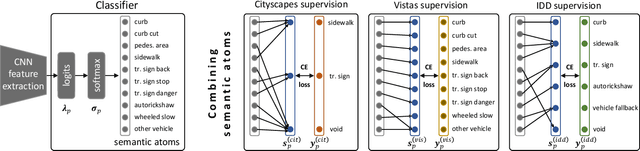
We explore semantic segmentation beyond the conventional, single-dataset homogeneous training and bring forward the problem of Heterogeneous Training of Semantic Segmentation (HTSS). HTSS involves simultaneous training on multiple heterogeneous datasets, i.e. datasets with conflicting label spaces and different (weak) annotation types from the perspective of semantic segmentation. The HTSS formulation exposes deep networks to a larger and previously unexplored aggregation of information that can potentially enhance semantic segmentation in three directions: i) performance: increased segmentation metrics on seen datasets, ii) generalization: improved segmentation metrics on unseen datasets, and iii) knowledgeability: increased number of recognizable semantic concepts. To research these benefits of HTSS, we propose a unified framework, that incorporates heterogeneous datasets in a single-network training pipeline following the established FCN standard. Our framework first curates heterogeneous datasets to bring them into a common format and then trains a single-backbone FCN on all of them simultaneously. To achieve this, it transforms weak annotations, which are incompatible with semantic segmentation, to per-pixel labels, and hierarchizes their label spaces into a universal taxonomy. The trained HTSS models demonstrate performance and generalization gains over a wide range of datasets and extend the inference label space entailing hundreds of semantic classes.
Towards a Holistic Understanding of Mathematical Questions with Contrastive Pre-training
Jan 18, 2023
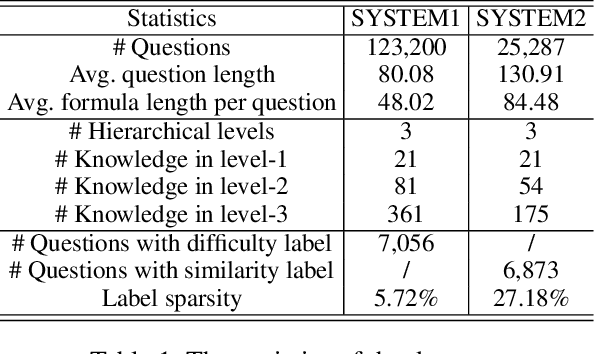
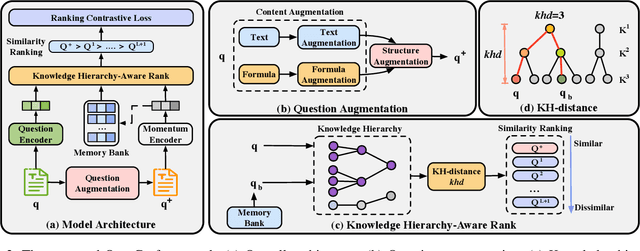
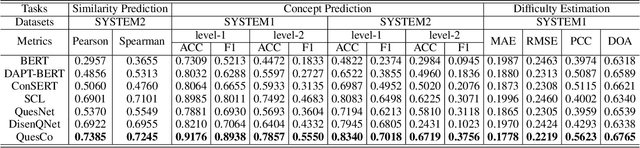
Understanding mathematical questions effectively is a crucial task, which can benefit many applications, such as difficulty estimation. Researchers have drawn much attention to designing pre-training models for question representations due to the scarcity of human annotations (e.g., labeling difficulty). However, unlike general free-format texts (e.g., user comments), mathematical questions are generally designed with explicit purposes and mathematical logic, and usually consist of more complex content, such as formulas, and related mathematical knowledge (e.g., Function). Therefore, the problem of holistically representing mathematical questions remains underexplored. To this end, in this paper, we propose a novel contrastive pre-training approach for mathematical question representations, namely QuesCo, which attempts to bring questions with more similar purposes closer. Specifically, we first design two-level question augmentations, including content-level and structure-level, which generate literally diverse question pairs with similar purposes. Then, to fully exploit hierarchical information of knowledge concepts, we propose a knowledge hierarchy-aware rank strategy (KHAR), which ranks the similarities between questions in a fine-grained manner. Next, we adopt a ranking contrastive learning task to optimize our model based on the augmented and ranked questions. We conduct extensive experiments on two real-world mathematical datasets. The experimental results demonstrate the effectiveness of our model.
NeRF in the Palm of Your Hand: Corrective Augmentation for Robotics via Novel-View Synthesis
Jan 18, 2023
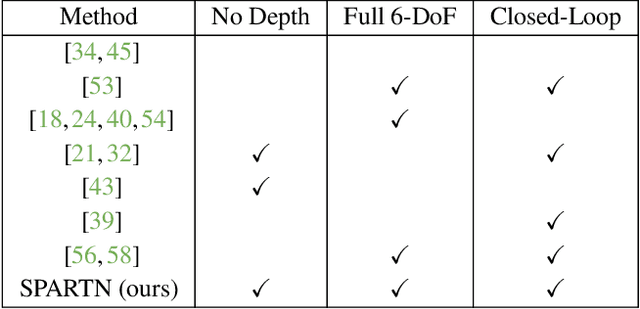
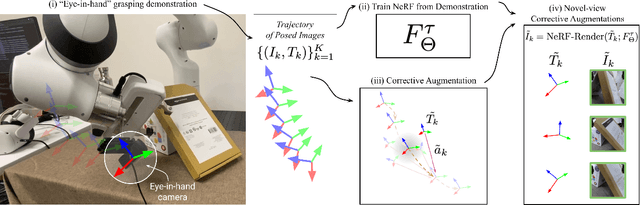

Expert demonstrations are a rich source of supervision for training visual robotic manipulation policies, but imitation learning methods often require either a large number of demonstrations or expensive online expert supervision to learn reactive closed-loop behaviors. In this work, we introduce SPARTN (Synthetic Perturbations for Augmenting Robot Trajectories via NeRF): a fully-offline data augmentation scheme for improving robot policies that use eye-in-hand cameras. Our approach leverages neural radiance fields (NeRFs) to synthetically inject corrective noise into visual demonstrations, using NeRFs to generate perturbed viewpoints while simultaneously calculating the corrective actions. This requires no additional expert supervision or environment interaction, and distills the geometric information in NeRFs into a real-time reactive RGB-only policy. In a simulated 6-DoF visual grasping benchmark, SPARTN improves success rates by 2.8$\times$ over imitation learning without the corrective augmentations and even outperforms some methods that use online supervision. It additionally closes the gap between RGB-only and RGB-D success rates, eliminating the previous need for depth sensors. In real-world 6-DoF robotic grasping experiments from limited human demonstrations, our method improves absolute success rates by $22.5\%$ on average, including objects that are traditionally challenging for depth-based methods. See video results at \url{https://bland.website/spartn}.
TikTalk: A Multi-Modal Dialogue Dataset for Real-World Chitchat
Jan 14, 2023
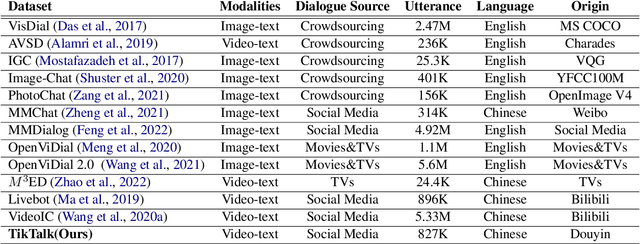
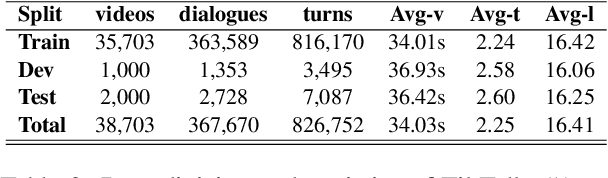
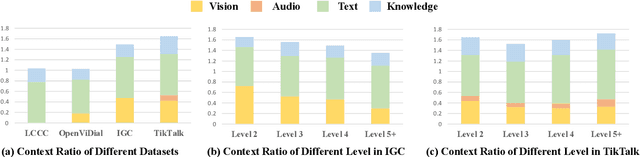
We present a novel multi-modal chitchat dialogue dataset-TikTalk aimed at facilitating the research of intelligent chatbots. It consists of the videos and corresponding dialogues users generate on video social applications. In contrast to existing multi-modal dialogue datasets, we construct dialogue corpora based on video comment-reply pairs, which is more similar to chitchat in real-world dialogue scenarios. Our dialogue context includes three modalities: text, vision, and audio. Compared with previous image-based dialogue datasets, the richer sources of context in TikTalk lead to a greater diversity of conversations. TikTalk contains over 38K videos and 367K dialogues. Data analysis shows that responses in TikTalk are in correlation with various contexts and external knowledge. It poses a great challenge for the deep understanding of multi-modal information and the generation of responses. We evaluate several baselines on three types of automatic metrics and conduct case studies. Experimental results demonstrate that there is still a large room for future improvement on TikTalk. Our dataset is available at \url{https://github.com/RUC-AIMind/TikTalk}.