 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Choose, not Hoard: Information-to-Model Matching for Artificial Intelligence in O-RAN
Aug 01, 2022
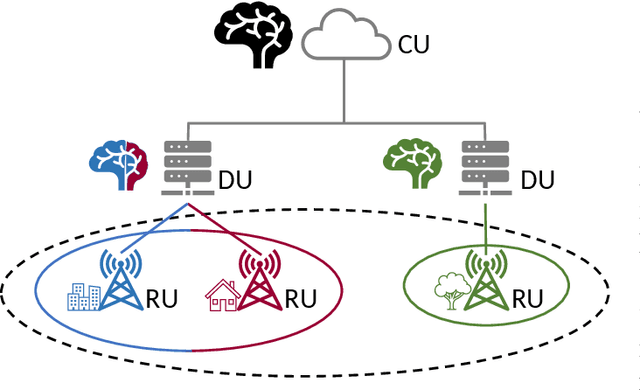
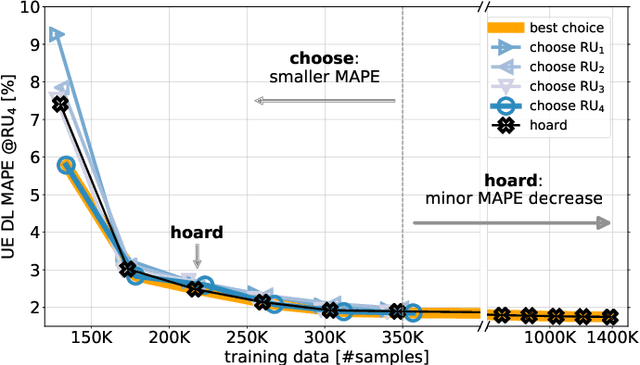
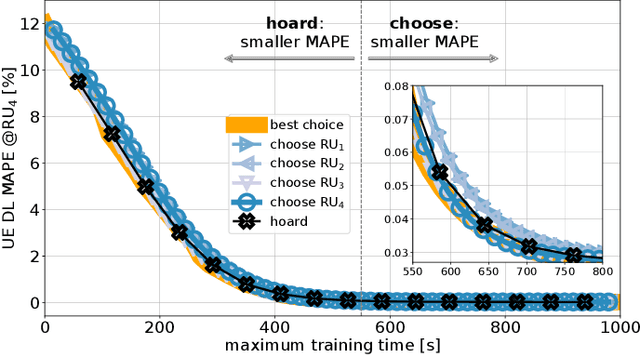
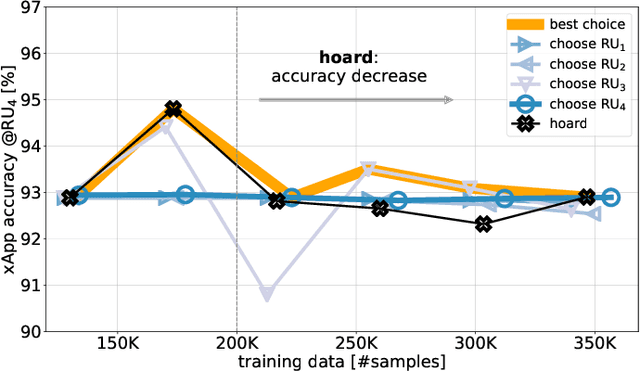
Open Radio Access Network (O-RAN) is an emerging paradigm, whereby virtualized network infrastructure elements from different vendors communicate via open, standardized interfaces. A key element therein is the RAN Intelligent Controller (RIC), an Artificial Intelligence (AI)-based controller. Traditionally, all data available in the network has been used to train a single AI model to use at the RIC. In this paper we introduce, discuss, and evaluate the creation of multiple AI model instances at different RICs, leveraging information from some (or all) locations for their training. This brings about a flexible relationship between gNBs, the AI models used to control them, and the data such models are trained with. Experiments with real-world traces show how using multiple AI model instances that choose training data from specific locations improve the performance of traditional approaches.
Explainability of Text Processing and Retrieval Methods: A Critical Survey
Dec 14, 2022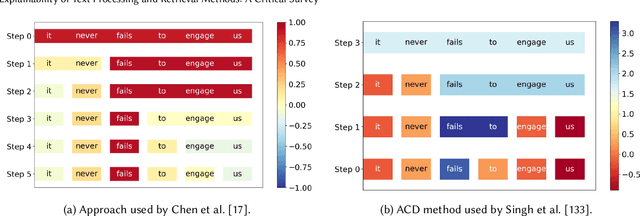
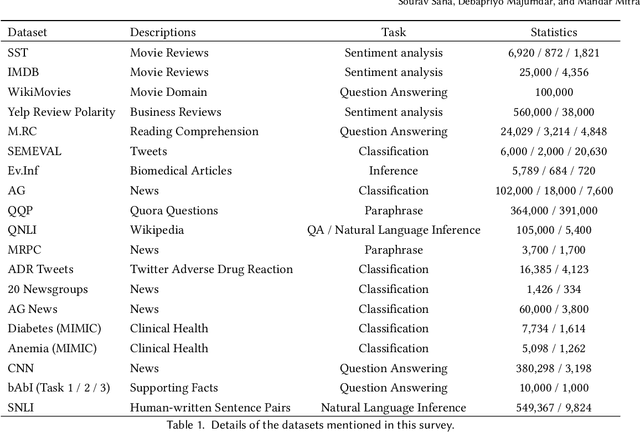
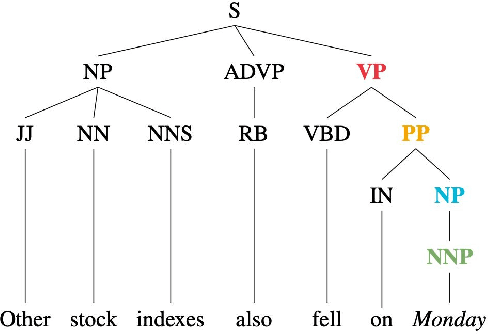
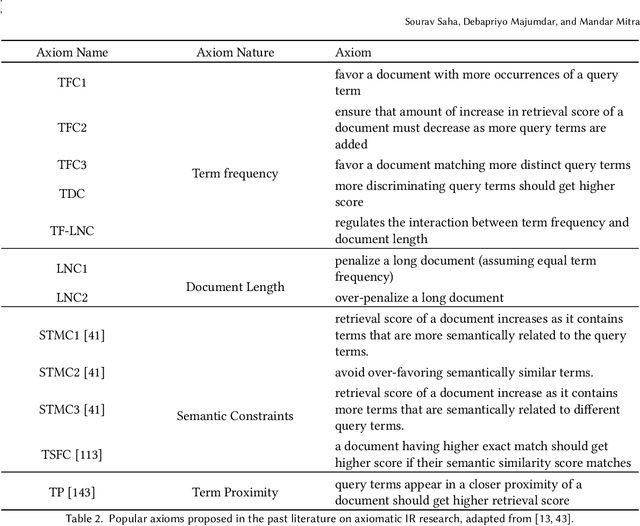
Deep Learning and Machine Learning based models have become extremely popular in text processing and information retrieval. However, the non-linear structures present inside the networks make these models largely inscrutable. A significant body of research has focused on increasing the transparency of these models. This article provides a broad overview of research on the explainability and interpretability of natural language processing and information retrieval methods. More specifically, we survey approaches that have been applied to explain word embeddings, sequence modeling, attention modules, transformers, BERT, and document ranking. The concluding section suggests some possible directions for future research on this topic.
The Role of Reusable and Single-Use Side Information in Private Information Retrieval
Jan 27, 2022This paper introduces the problem of Private Information Retrieval with Reusable and Single-use Side Information (PIR-RSSI). In this problem, one or more remote servers store identical copies of a set of $K$ messages, and there is a user that initially knows $M$ of these messages, and wants to privately retrieve one other message from the set of $K$ messages. The objective is to design a retrieval scheme in which the user downloads the minimum amount of information from the server(s) while the identity of the message wanted by the user and the identities of an $M_1$-subset of the $M$ messages known by the user (referred to as reusable side information) are protected, but the identities of the remaining $M_2=M-M_1$ messages known by the user (referred to as single-use side information) do not need to be protected. The PIR-RSSI problem reduces to the classical Private Information Retrieval (PIR) problem when ${M_1=M_2=0}$, and reduces to the problem of PIR with Private Side Information or PIR with Side Information when ${M_1\geq 1,M_2=0}$ or ${M_1=0,M_2\geq 1}$, respectively. In this work, we focus on the single-server setting of the PIR-RSSI problem. We characterize the capacity of this setting for the cases of ${M_1=1,M_2\geq 1}$ and ${M_1\geq 1,M_2=1}$, where the capacity is defined as the maximum achievable download rate over all PIR-RSSI schemes. Our results show that for sufficiently small values of $K$, the single-use side information messages can help in reducing the download cost only if they are kept private; and for larger values of $K$, the reusable side information messages cannot help in reducing the download cost.
Can Peanuts Fall in Love with Distributional Semantics?
Jan 20, 2023
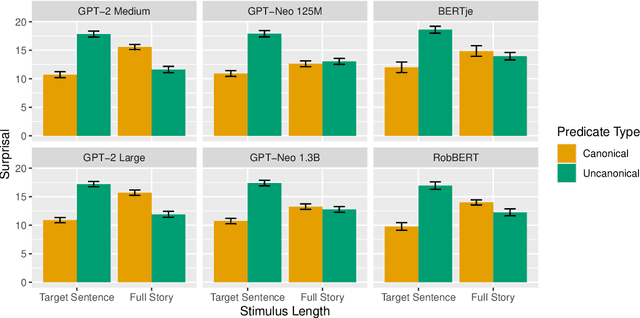
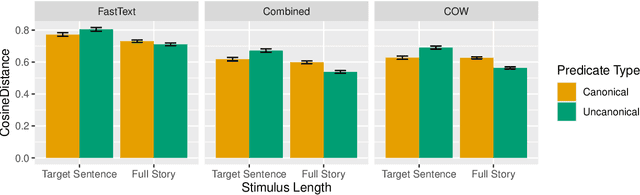
The context in which a sentence appears can drastically alter our expectations about upcoming words - for example, following a short story involving an anthropomorphic peanut, experimental participants are more likely to expect the sentence 'the peanut was in love' than 'the peanut was salted', as indexed by N400 amplitude (Nieuwland & van Berkum, 2006). This rapid and dynamic updating of comprehenders' expectations about the kind of events that a peanut may take part in based on context has been explained using the construct of Situation Models - updated mental representations of key elements of an event under discussion, in this case, the peanut protagonist. However, recent work showing that N400 amplitude can be predicted based on distributional information alone raises the question whether situation models are in fact necessary for the kinds of contextual effects observed in previous work. To investigate this question, we attempt to model the results of Nieuwland and van Berkum (2006) using six computational language models and three sets of word vectors, none of which have explicit situation models or semantic grounding. We find that the effect found by Nieuwland and van Berkum (2006) can be fully modeled by two language models and two sets of word vectors, with others showing a reduced effect. Thus, at least some processing effects normally explained through situation models may not in fact require explicit situation models.
Efficient Long Sequence Modeling via State Space Augmented Transformer
Dec 15, 2022
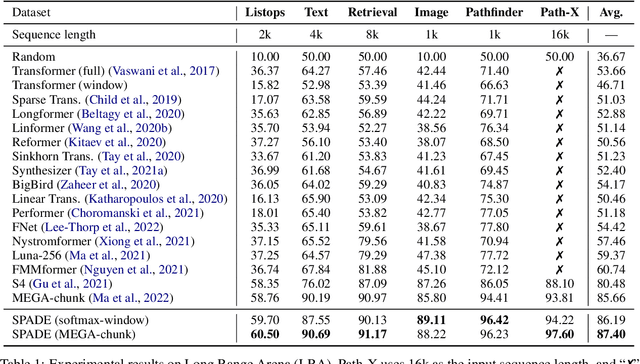

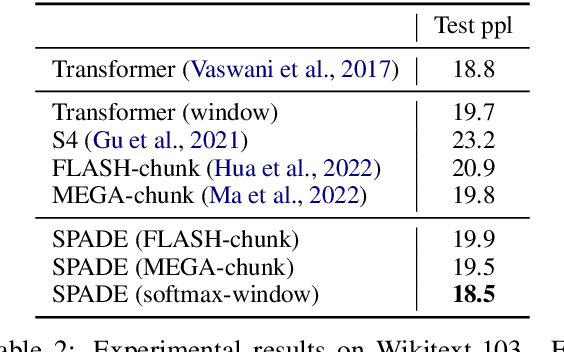
Transformer models have achieved superior performance in various natural language processing tasks. However, the quadratic computational cost of the attention mechanism limits its practicality for long sequences. There are existing attention variants that improve the computational efficiency, but they have limited ability to effectively compute global information. In parallel to Transformer models, state space models (SSMs) are tailored for long sequences, but they are not flexible enough to capture complicated local information. We propose SPADE, short for $\underline{\textbf{S}}$tate s$\underline{\textbf{P}}$ace $\underline{\textbf{A}}$ugmente$\underline{\textbf{D}}$ Transform$\underline{\textbf{E}}$r. Specifically, we augment a SSM into the bottom layer of SPADE, and we employ efficient local attention methods for the other layers. The SSM augments global information, which complements the lack of long-range dependency issue in local attention methods. Experimental results on the Long Range Arena benchmark and language modeling tasks demonstrate the effectiveness of the proposed method. To further demonstrate the scalability of SPADE, we pre-train large encoder-decoder models and present fine-tuning results on natural language understanding and natural language generation tasks.
Goal-guided Transformer-enabled Reinforcement Learning for Efficient Autonomous Navigation
Jan 01, 2023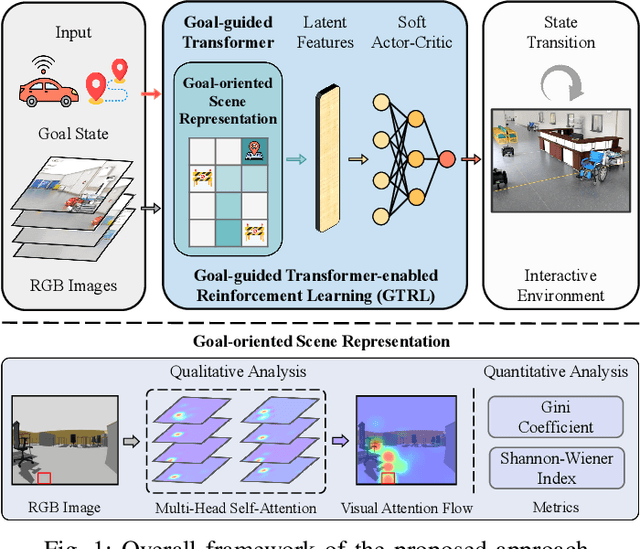
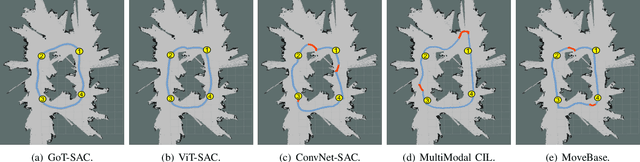
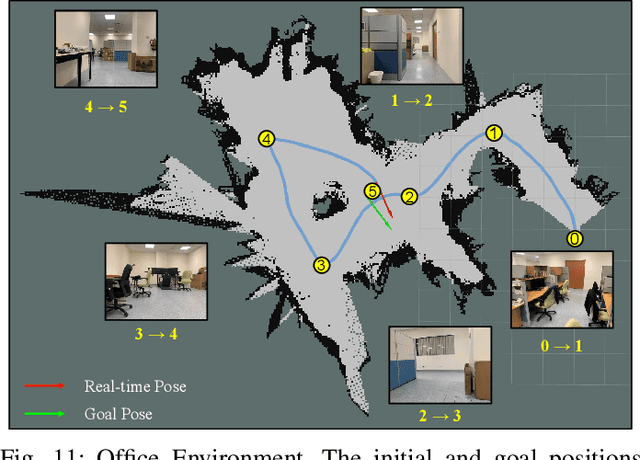
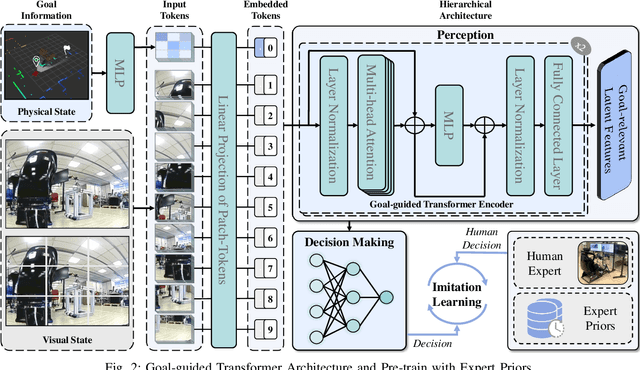
Despite some successful applications of goal-driven navigation, existing deep reinforcement learning-based approaches notoriously suffers from poor data efficiency issue. One of the reasons is that the goal information is decoupled from the perception module and directly introduced as a condition of decision-making, resulting in the goal-irrelevant features of the scene representation playing an adversary role during the learning process. In light of this, we present a novel Goal-guided Transformer-enabled reinforcement learning (GTRL) approach by considering the physical goal states as an input of the scene encoder for guiding the scene representation to couple with the goal information and realizing efficient autonomous navigation. More specifically, we propose a novel variant of the Vision Transformer as the backbone of the perception system, namely Goal-guided Transformer (GoT), and pre-train it with expert priors to boost the data efficiency. Subsequently, a reinforcement learning algorithm is instantiated for the decision-making system, taking the goal-oriented scene representation from the GoT as the input and generating decision commands. As a result, our approach motivates the scene representation to concentrate mainly on goal-relevant features, which substantially enhances the data efficiency of the DRL learning process, leading to superior navigation performance. Both simulation and real-world experimental results manifest the superiority of our approach in terms of data efficiency, performance, robustness, and sim-to-real generalization, compared with other state-of-art baselines. Demonstration videos are available at \colorb{https://youtu.be/93LGlGvaN0c.
Minimally Invasive Live Tissue High-fidelity Thermophysical Modeling using Real-time Thermography
Jan 23, 2023

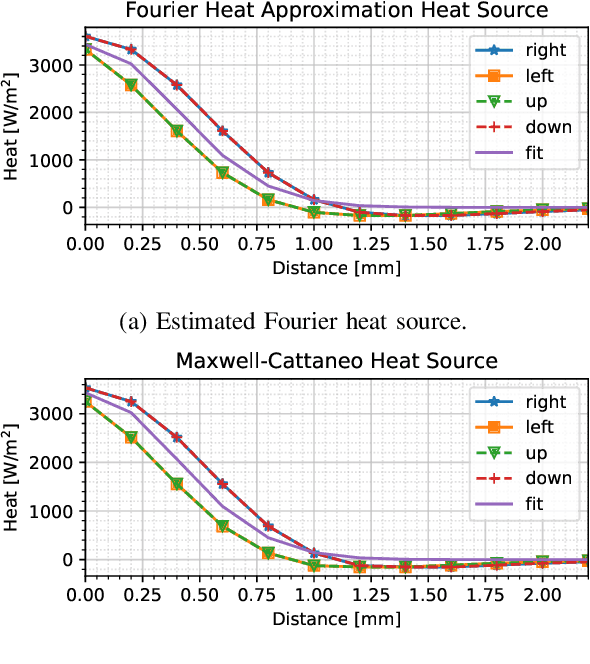
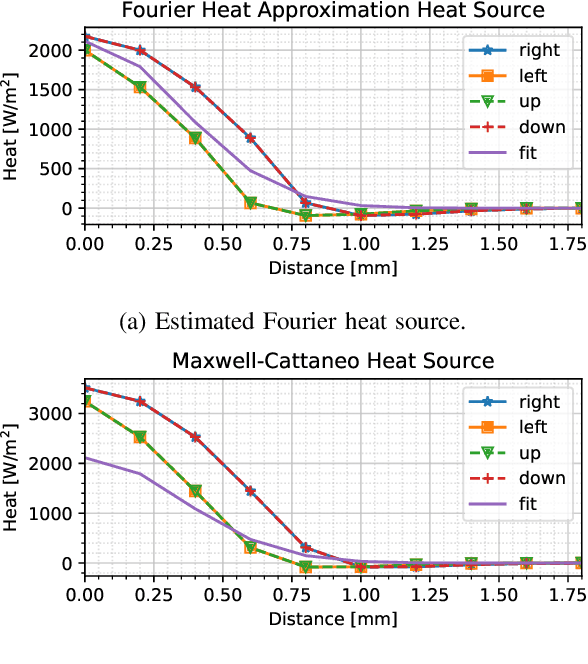
We present a novel thermodynamic parameter estimation framework for energy-based surgery on live tissue, with direct applications to tissue characterization during electrosurgery. This framework addresses the problem of estimating tissue-specific thermodynamics in real-time, which would enable accurate prediction of thermal damage impact to the tissue and damage-conscious planning of electrosurgical procedures. Our approach provides basic thermodynamic information such as thermal diffusivity, and also allows for obtaining the thermal relaxation time and a model of the heat source, yielding in real-time a controlled hyperbolic thermodynamics model. The latter accounts for the finite thermal propagation time necessary for modeling of the electrosurgical action, in which the probe motion speed often surpasses the speed of thermal propagation in the tissue operated on. Our approach relies solely on thermographer feedback and a knowledge of the power level and position of the electrosurgical pencil, imposing only very minor adjustments to normal electrosurgery to obtain a high-fidelity model of the tissue-probe interaction. Our method is minimally invasive and can be performed in situ. We apply our method first to simulated data based on porcine muscle tissue to verify its accuracy and then to in vivo liver tissue, and compare the results with those from the literature. This comparison shows that parameterizing the Maxwell--Cattaneo model through the framework proposed yields a noticeably higher fidelity real-time adaptable representation of the thermodynamic tissue response to the electrosurgical impact than currently available. A discussion on the differences between the live and the dead tissue thermodynamics is also provided.
Multimodal Inverse Cloze Task for Knowledge-based Visual Question Answering
Jan 11, 2023


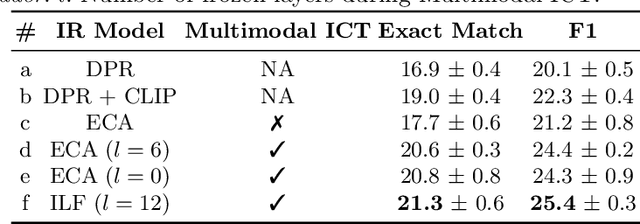
We present a new pre-training method, Multimodal Inverse Cloze Task, for Knowledge-based Visual Question Answering about named Entities (KVQAE). KVQAE is a recently introduced task that consists in answering questions about named entities grounded in a visual context using a Knowledge Base. Therefore, the interaction between the modalities is paramount to retrieve information and must be captured with complex fusion models. As these models require a lot of training data, we design this pre-training task from existing work in textual Question Answering. It consists in considering a sentence as a pseudo-question and its context as a pseudo-relevant passage and is extended by considering images near texts in multimodal documents. Our method is applicable to different neural network architectures and leads to a 9% relative-MRR and 15% relative-F1 gain for retrieval and reading comprehension, respectively, over a no-pre-training baseline.
Target Defense against Sequentially Arriving Intruders
Dec 13, 2022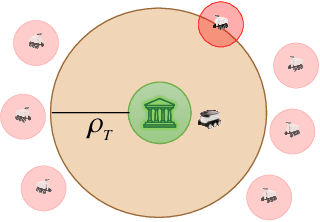
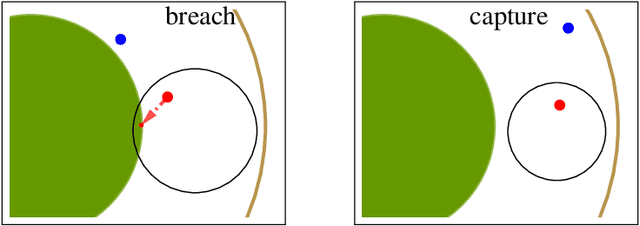
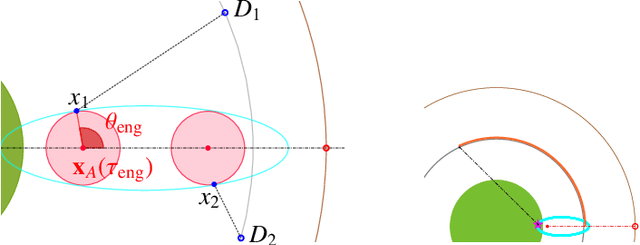
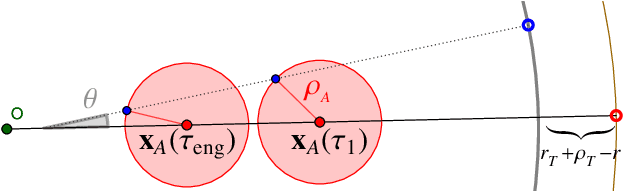
We consider a variant of the target defense problem where a single defender is tasked to capture a sequence of incoming intruders. The intruders' objective is to breach the target boundary without being captured by the defender. As soon as the current intruder breaches the target or gets captured by the defender, the next intruder appears at a random location on a fixed circle surrounding the target. Therefore, the defender's final location at the end of the current game becomes its initial location for the next game. Thus, the players pick strategies that are advantageous for the current as well as for the future games. Depending on the information available to the players, each game is divided into two phases: partial information and full information phase. Under some assumptions on the sensing and speed capabilities, we analyze the agents' strategies in both phases. We derive equilibrium strategies for both the players to optimize the capture percentage using the notions of engagement surface and capture circle. We quantify the percentage of capture for both finite and infinite sequences of incoming intruders.
NLIP: Noise-robust Language-Image Pre-training
Jan 04, 2023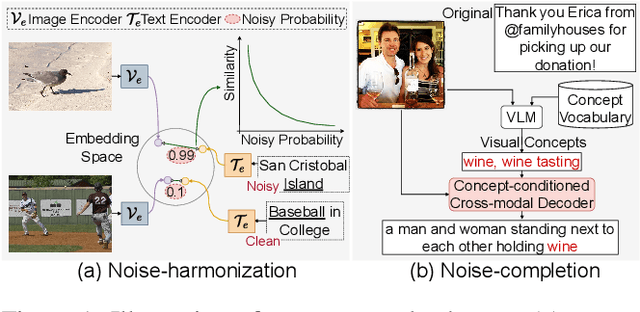
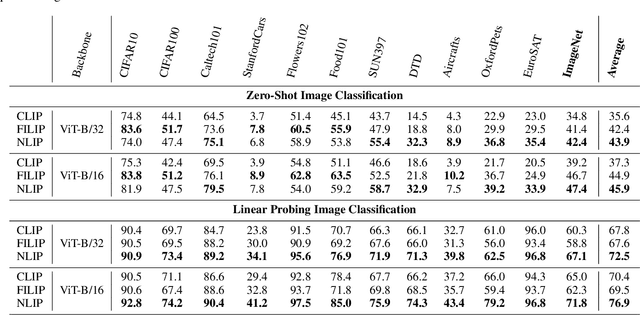
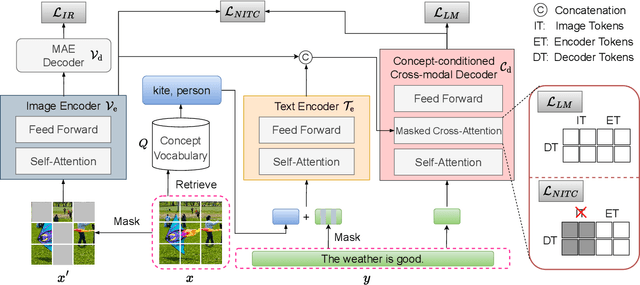
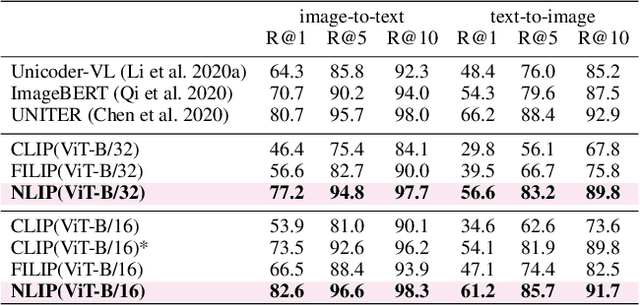
Large-scale cross-modal pre-training paradigms have recently shown ubiquitous success on a wide range of downstream tasks, e.g., zero-shot classification, retrieval and image captioning. However, their successes highly rely on the scale and quality of web-crawled data that naturally contain incomplete and noisy information (e.g., wrong or irrelevant content). Existing works either design manual rules to clean data or generate pseudo-targets as auxiliary signals for reducing noise impact, which do not explicitly tackle both the incorrect and incomplete challenges simultaneously. In this paper, to automatically mitigate the impact of noise by solely mining over existing data, we propose a principled Noise-robust Language-Image Pre-training framework (NLIP) to stabilize pre-training via two schemes: noise-harmonization and noise-completion. First, in noise-harmonization scheme, NLIP estimates the noise probability of each pair according to the memorization effect of cross-modal transformers, then adopts noise-adaptive regularization to harmonize the cross-modal alignments with varying degrees. Second, in noise-completion scheme, to enrich the missing object information of text, NLIP injects a concept-conditioned cross-modal decoder to obtain semantic-consistent synthetic captions to complete noisy ones, which uses the retrieved visual concepts (i.e., objects' names) for the corresponding image to guide captioning generation. By collaboratively optimizing noise-harmonization and noise-completion schemes, our NLIP can alleviate the common noise effects during image-text pre-training in a more efficient way. Extensive experiments show the significant performance improvements of our NLIP using only 26M data over existing pre-trained models (e.g., CLIP, FILIP and BLIP) on 12 zero-shot classification datasets, MSCOCO image captioning and zero-shot image-text retrieval tasks.