 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improving the Adversarial Robustness of NLP Models by Information Bottleneck
Jun 11, 2022
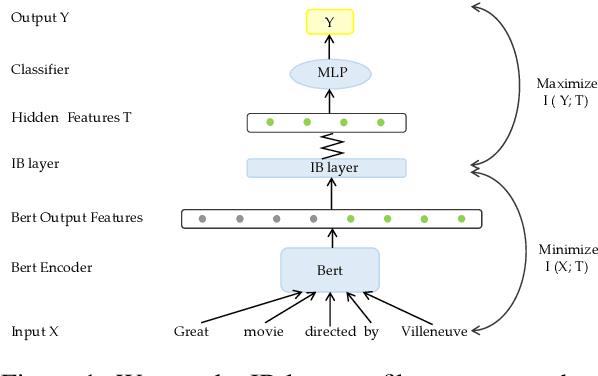
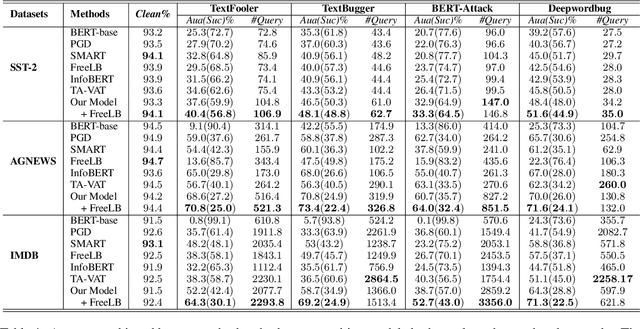
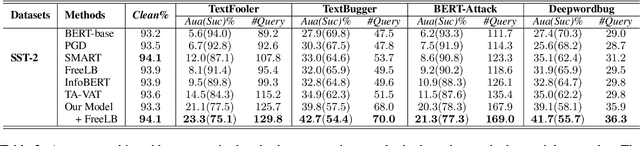
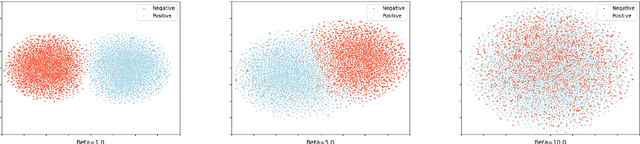
Existing studies have demonstrated that adversarial examples can be directly attributed to the presence of non-robust features, which are highly predictive, but can be easily manipulated by adversaries to fool NLP models. In this study, we explore the feasibility of capturing task-specific robust features, while eliminating the non-robust ones by using the information bottleneck theory. Through extensive experiments, we show that the models trained with our information bottleneck-based method are able to achieve a significant improvement in robust accuracy, exceeding performances of all the previously reported defense methods while suffering almost no performance drop in clean accuracy on SST-2, AGNEWS and IMDB datasets.
BERT-Embedding and Citation Network Analysis based Query Expansion Technique for Scholarly Search
Jan 26, 2023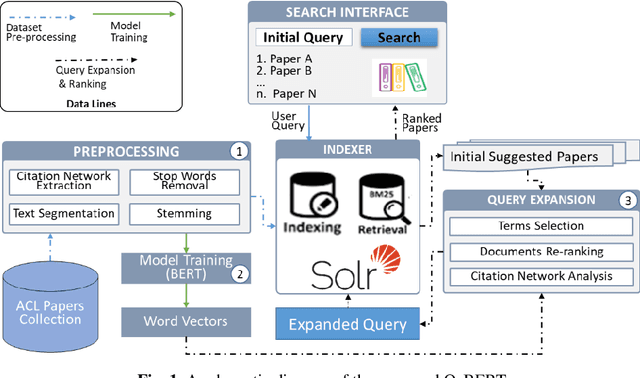
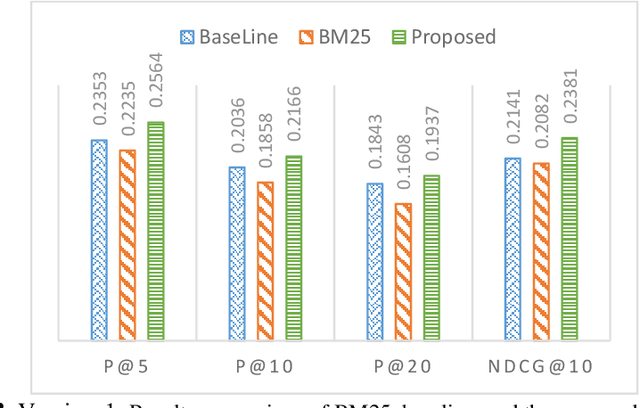
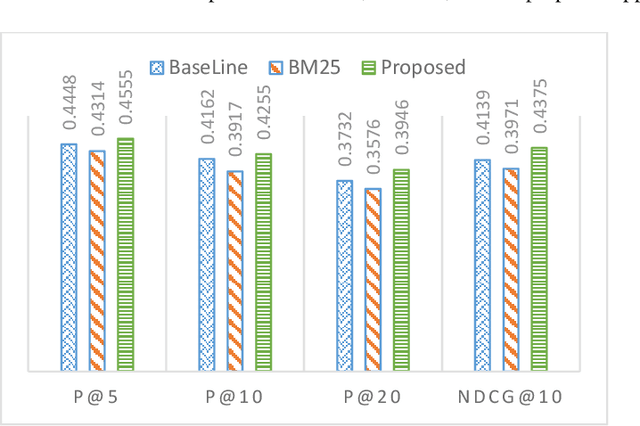
The enormous growth of research publications has made it challenging for academic search engines to bring the most relevant papers against the given search query. Numerous solutions have been proposed over the years to improve the effectiveness of academic search, including exploiting query expansion and citation analysis. Query expansion techniques mitigate the mismatch between the language used in a query and indexed documents. However, these techniques can suffer from introducing non-relevant information while expanding the original query. Recently, contextualized model BERT to document retrieval has been quite successful in query expansion. Motivated by such issues and inspired by the success of BERT, this paper proposes a novel approach called QeBERT. QeBERT exploits BERT-based embedding and Citation Network Analysis (CNA) in query expansion for improving scholarly search. Specifically, we use the context-aware BERT-embedding and CNA for query expansion in Pseudo-Relevance Feedback (PRF) fash-ion. Initial experimental results on the ACL dataset show that BERT-embedding can provide a valuable augmentation to query expansion and improve search relevance when combined with CNA.
I-24 MOTION: An instrument for freeway traffic science
Jan 26, 2023
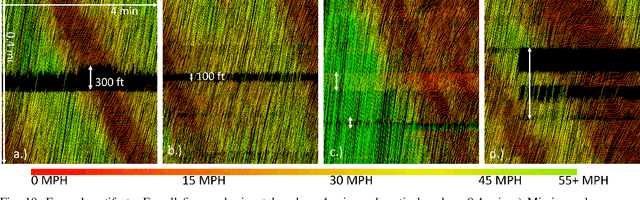
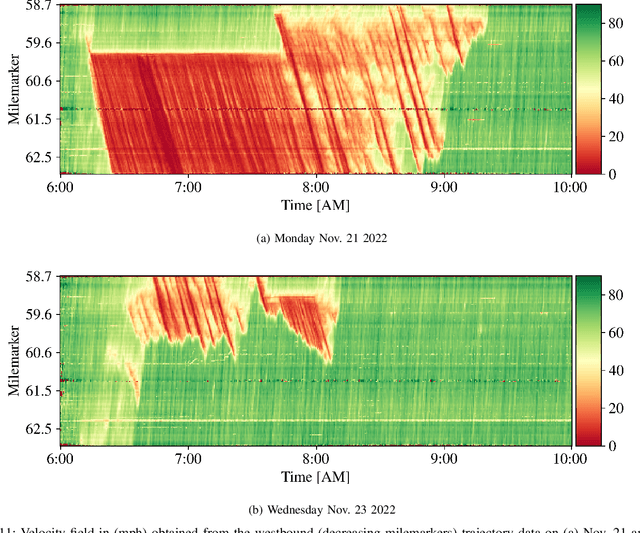
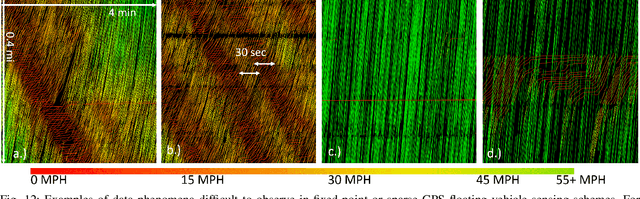
The Interstate-24 MObility Technology Interstate Observation Network (I-24 MOTION) is a new instrument for traffic science located near Nashville, Tennessee. I-24 MOTION consists of 276 pole-mounted high-resolution traffic cameras that provide seamless coverage of approximately 4.2 miles I-24, a 4-5 lane (each direction) freeway with frequently observed congestion. The cameras are connected via fiber optic network to a compute facility where vehicle trajectories are extracted from the video imagery using computer vision techniques. Approximately 230 million vehicle miles of travel occur within I-24 MOTION annually. The main output of the instrument are vehicle trajectory datasets that contain the position of each vehicle on the freeway, as well as other supplementary information vehicle dimensions and class. This article describes the design and creation of the instrument, and provides the first publicly available datasets generated from the instrument. The datasets published with this article contains at least 4 hours of vehicle trajectory data for each of 10 days. As the system continues to mature, all trajectory data will be made publicly available at i24motion.org/data.
Jointist: Simultaneous Improvement of Multi-instrument Transcription and Music Source Separation via Joint Training
Feb 02, 2023
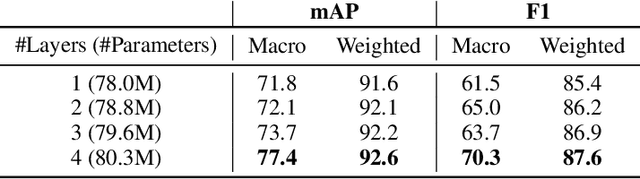
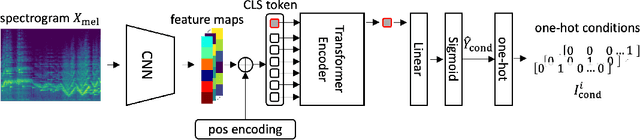
In this paper, we introduce Jointist, an instrument-aware multi-instrument framework that is capable of transcribing, recognizing, and separating multiple musical instruments from an audio clip. Jointist consists of an instrument recognition module that conditions the other two modules: a transcription module that outputs instrument-specific piano rolls, and a source separation module that utilizes instrument information and transcription results. The joint training of the transcription and source separation modules serves to improve the performance of both tasks. The instrument module is optional and can be directly controlled by human users. This makes Jointist a flexible user-controllable framework. Our challenging problem formulation makes the model highly useful in the real world given that modern popular music typically consists of multiple instruments. Its novelty, however, necessitates a new perspective on how to evaluate such a model. In our experiments, we assess the proposed model from various aspects, providing a new evaluation perspective for multi-instrument transcription. Our subjective listening study shows that Jointist achieves state-of-the-art performance on popular music, outperforming existing multi-instrument transcription models such as MT3. We conducted experiments on several downstream tasks and found that the proposed method improved transcription by more than 1 percentage points (ppt.), source separation by 5 SDR, downbeat detection by 1.8 ppt., chord recognition by 1.4 ppt., and key estimation by 1.4 ppt., when utilizing transcription results obtained from Jointist. Demo available at \url{https://jointist.github.io/Demo}.
Lower Bounds for Learning in Revealing POMDPs
Feb 02, 2023
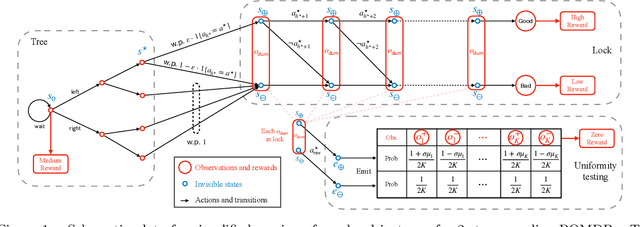
This paper studies the fundamental limits of reinforcement learning (RL) in the challenging \emph{partially observable} setting. While it is well-established that learning in Partially Observable Markov Decision Processes (POMDPs) requires exponentially many samples in the worst case, a surge of recent work shows that polynomial sample complexities are achievable under the \emph{revealing condition} -- A natural condition that requires the observables to reveal some information about the unobserved latent states. However, the fundamental limits for learning in revealing POMDPs are much less understood, with existing lower bounds being rather preliminary and having substantial gaps from the current best upper bounds. We establish strong PAC and regret lower bounds for learning in revealing POMDPs. Our lower bounds scale polynomially in all relevant problem parameters in a multiplicative fashion, and achieve significantly smaller gaps against the current best upper bounds, providing a solid starting point for future studies. In particular, for \emph{multi-step} revealing POMDPs, we show that (1) the latent state-space dependence is at least $\Omega(S^{1.5})$ in the PAC sample complexity, which is notably harder than the $\widetilde{\Theta}(S)$ scaling for fully-observable MDPs; (2) Any polynomial sublinear regret is at least $\Omega(T^{2/3})$, suggesting its fundamental difference from the \emph{single-step} case where $\widetilde{O}(\sqrt{T})$ regret is achievable. Technically, our hard instance construction adapts techniques in \emph{distribution testing}, which is new to the RL literature and may be of independent interest.
Approximation of optimization problems with constraints through kernel Sum-Of-Squares
Jan 16, 2023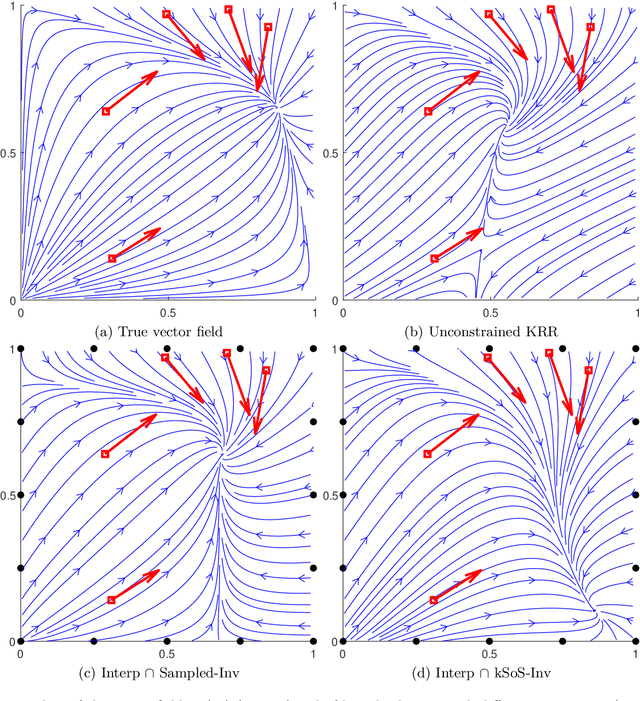
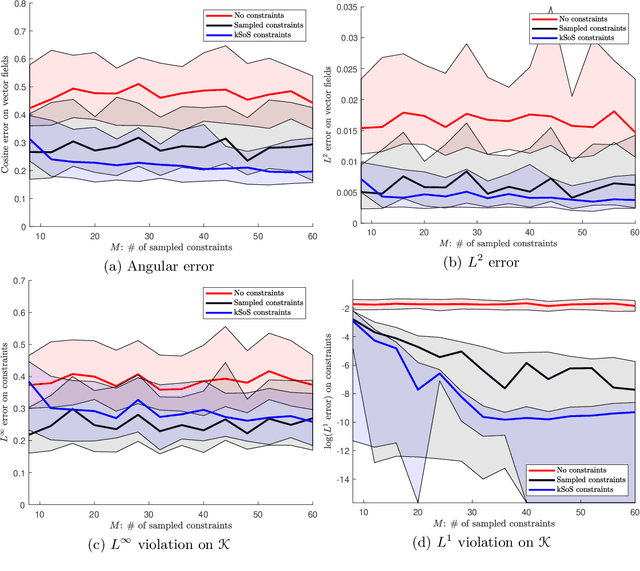
Handling an infinite number of inequality constraints in infinite-dimensional spaces occurs in many fields, from global optimization to optimal transport. These problems have been tackled individually in several previous articles through kernel Sum-Of-Squares (kSoS) approximations. We propose here a unified theorem to prove convergence guarantees for these schemes. Inequalities are turned into equalities to a class of nonnegative kSoS functions. This enables the use of scattering inequalities to mitigate the curse of dimensionality in sampling the constraints, leveraging the assumed smoothness of the functions appearing in the problem. This approach is illustrated in learning vector fields with side information, here the invariance of a set.
A Semi-supervised Approach for Activity Recognition from Indoor Trajectory Data
Jan 11, 2023
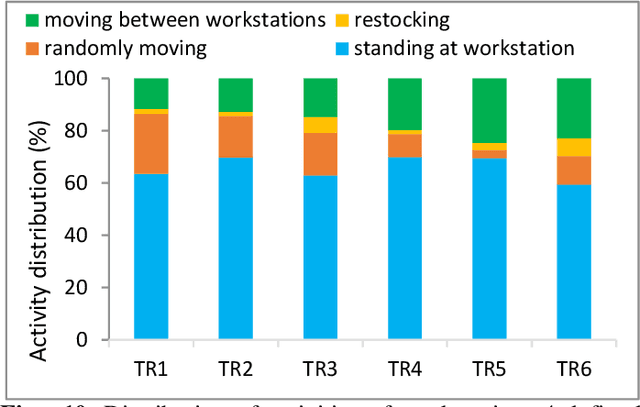
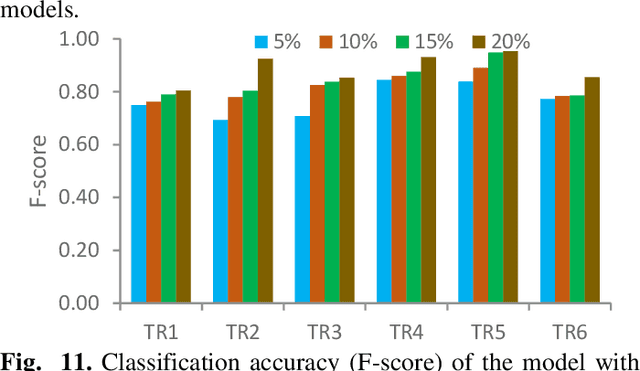
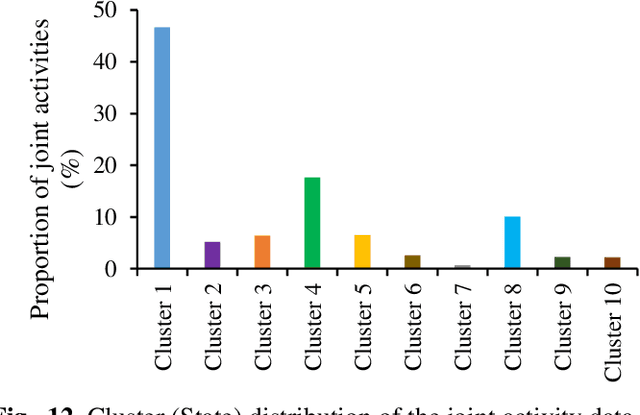
The increasingly wide usage of location aware sensors has made it possible to collect large volume of trajectory data in diverse application domains. Machine learning allows to study the activities or behaviours of moving objects (e.g., people, vehicles, robot) using such trajectory data with rich spatiotemporal information to facilitate informed strategic and operational decision making. In this study, we consider the task of classifying the activities of moving objects from their noisy indoor trajectory data in a collaborative manufacturing environment. Activity recognition can help manufacturing companies to develop appropriate management policies, and optimise safety, productivity, and efficiency. We present a semi-supervised machine learning approach that first applies an information theoretic criterion to partition a long trajectory into a set of segments such that the object exhibits homogeneous behaviour within each segment. The segments are then labelled automatically based on a constrained hierarchical clustering method. Finally, a deep learning classification model based on convolutional neural networks is trained on trajectory segments and the generated pseudo labels. The proposed approach has been evaluated on a dataset containing indoor trajectories of multiple workers collected from a tricycle assembly workshop. The proposed approach is shown to achieve high classification accuracy (F-score varies between 0.81 to 0.95 for different trajectories) using only a small proportion of labelled trajectory segments.
PIER: Permutation-Level Interest-Based End-to-End Re-ranking Framework in E-commerce
Feb 06, 2023

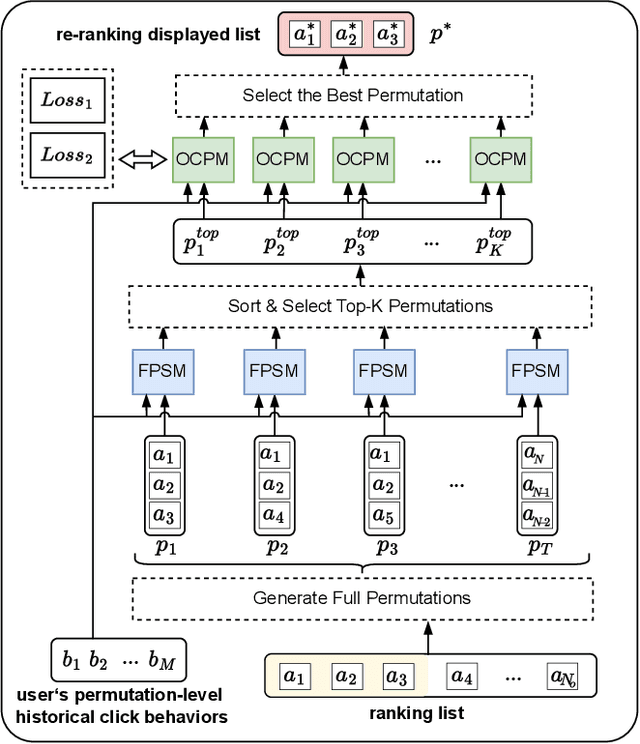
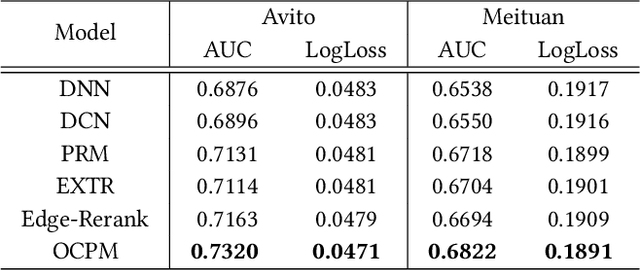
Re-ranking draws increased attention on both academics and industries, which rearranges the ranking list by modeling the mutual influence among items to better meet users' demands. Many existing re-ranking methods directly take the initial ranking list as input, and generate the optimal permutation through a well-designed context-wise model, which brings the evaluation-before-reranking problem. Meanwhile, evaluating all candidate permutations brings unacceptable computational costs in practice. Thus, to better balance efficiency and effectiveness, online systems usually use a two-stage architecture which uses some heuristic methods such as beam-search to generate a suitable amount of candidate permutations firstly, which are then fed into the evaluation model to get the optimal permutation. However, existing methods in both stages can be improved through the following aspects. As for generation stage, heuristic methods only use point-wise prediction scores and lack an effective judgment. As for evaluation stage, most existing context-wise evaluation models only consider the item context and lack more fine-grained feature context modeling. This paper presents a novel end-to-end re-ranking framework named PIER to tackle the above challenges which still follows the two-stage architecture and contains two mainly modules named FPSM and OCPM. We apply SimHash in FPSM to select top-K candidates from the full permutation based on user's permutation-level interest in an efficient way. Then we design a novel omnidirectional attention mechanism in OCPM to capture the context information in the permutation. Finally, we jointly train these two modules end-to-end by introducing a comparative learning loss. Offline experiment results demonstrate that PIER outperforms baseline models on both public and industrial datasets, and we have successfully deployed PIER on Meituan food delivery platform.
Augmenting Softmax Information for Selective Classification with Out-of-Distribution Data
Jul 15, 2022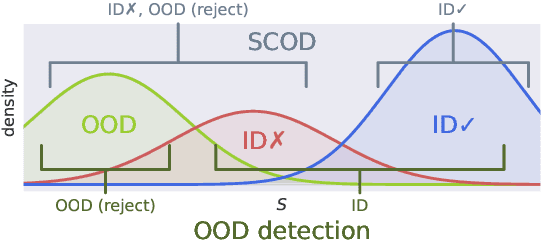
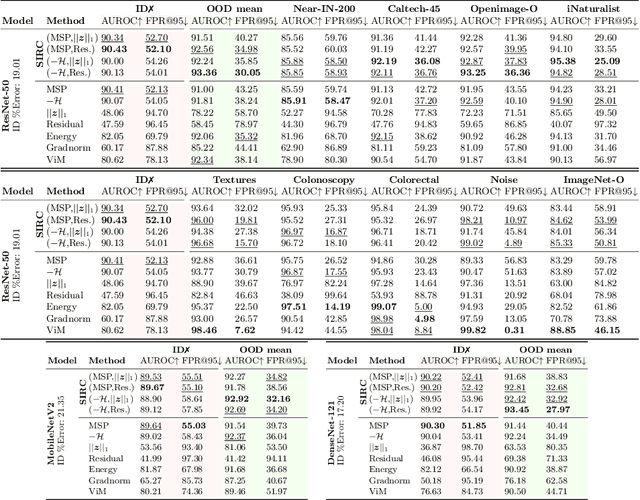
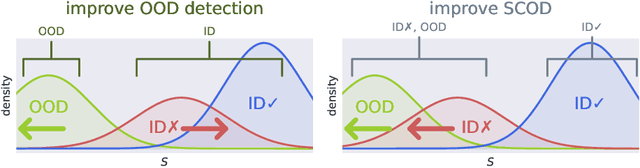
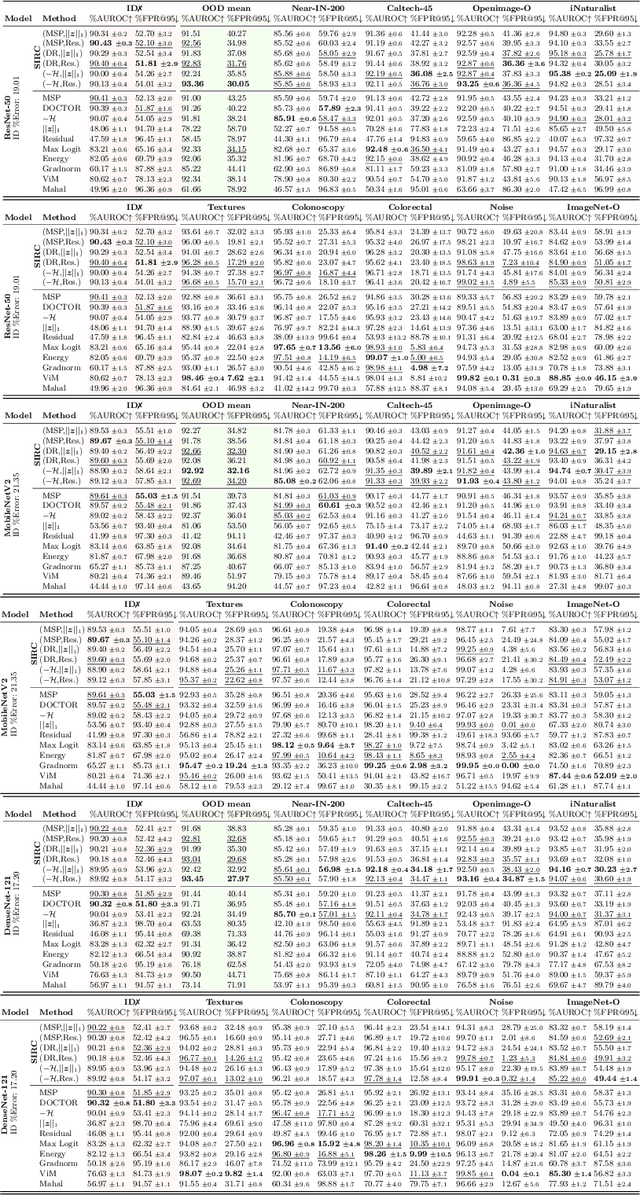
Detecting out-of-distribution (OOD) data is a task that is receiving an increasing amount of research attention in the domain of deep learning for computer vision. However, the performance of detection methods is generally evaluated on the task in isolation, rather than also considering potential downstream tasks in tandem. In this work, we examine selective classification in the presence of OOD data (SCOD). That is to say, the motivation for detecting OOD samples is to reject them so their impact on the quality of predictions is reduced. We show under this task specification, that existing post-hoc methods perform quite differently compared to when evaluated only on OOD detection. This is because it is no longer an issue to conflate in-distribution (ID) data with OOD data if the ID data is going to be misclassified. However, the conflation within ID data of correct and incorrect predictions becomes undesirable. We also propose a novel method for SCOD, Softmax Information Retaining Combination (SIRC), that augments softmax-based confidence scores with feature-agnostic information such that their ability to identify OOD samples is improved without sacrificing separation between correct and incorrect ID predictions. Experiments on a wide variety of ImageNet-scale datasets and convolutional neural network architectures show that SIRC is able to consistently match or outperform the baseline for SCOD, whilst existing OOD detection methods fail to do so.
Timely Opportunistic Gossiping in Dense Networks
Jan 02, 2023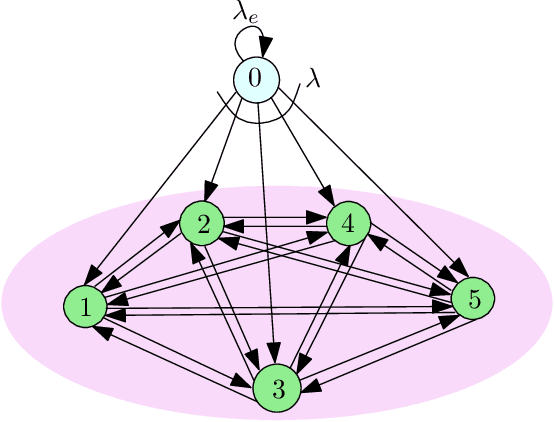
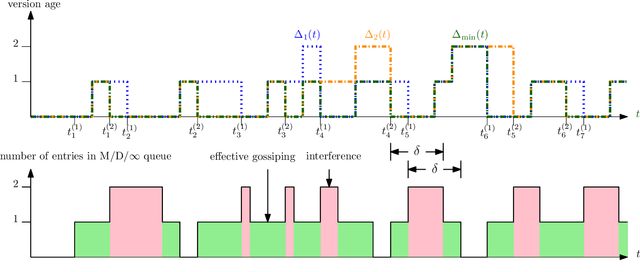

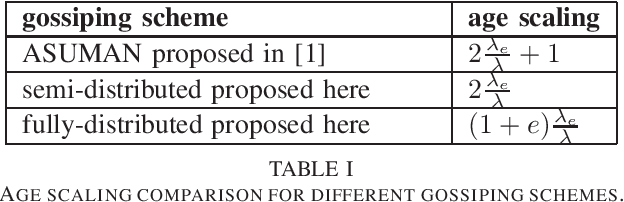
We consider gossiping in a fully-connected wireless network consisting of $n$ nodes. The network receives Poisson updates from a source, which generates new information. The nodes gossip their available information with the neighboring nodes to maintain network timeliness. In this work, we propose two gossiping schemes, one semi-distributed and the other one fully-distributed. In the semi-distributed scheme, the freshest nodes use pilot signals to interact with the network and gossip with the full available update rate $B$. In the fully-distributed scheme, each node gossips for a fixed amount of time duration with the full update rate $B$. Both schemes achieve $O(1)$ age scaling, and the semi-distributed scheme has the best age performance for any symmetric randomized gossiping policy. We compare the results with the recently proposed ASUMAN scheme, which also gives $O(1)$ age performance, but the nodes need to be age-aware.