 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Mobile Localization Techniques Oriented to Tangible Web
Dec 12, 2022
We implemented a system able to locate people indoor, with the purpose of providing assistive services. Such approach is particularly important for the Art, for providing information on exhibitions, art galleries and museums, and to allow the access to the cultural heritage patrimony to people with disabilities. The system may provide also very important information and input to elderly people, helping them to perceive more deeply the reality and the beauty of art. The system is based on Beacons, very small and low power consumption devices, and Human Body Communication protocols. The Beacons, Bluetooth Low Energy devices, allow to obtain a position information related to predetermined reference points, and through proximity algorithms, locate a person or an object of interest. The position obtained has an error that depends from the interferences present in the area. The union of Beacons with Human Body Communication, a recent wireless technology that exploits the human body as a transmission channel, makes it possible to increase the accuracy of localization. The basic idea is to exploit the localization derived from Beacons to start a search for an electrical signal transmitted by the human body and to distinguish the position according to the information contained in the signal. The signal is transmitted by capacitance to the human body and revealed by a special resonant circuit (antenna) adapted to the microphone input of the mobile device.
Tracr: Compiled Transformers as a Laboratory for Interpretability
Jan 12, 2023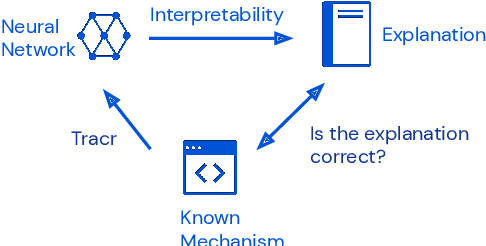
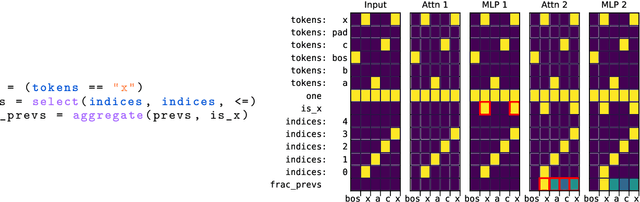
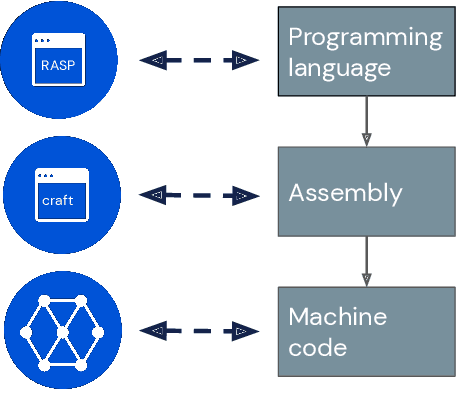
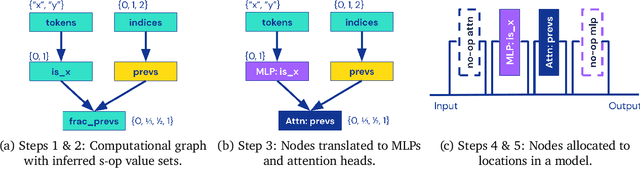
Interpretability research aims to build tools for understanding machine learning (ML) models. However, such tools are inherently hard to evaluate because we do not have ground truth information about how ML models actually work. In this work, we propose to build transformer models manually as a testbed for interpretability research. We introduce Tracr, a "compiler" for translating human-readable programs into weights of a transformer model. Tracr takes code written in RASP, a domain-specific language (Weiss et al. 2021), and translates it into weights for a standard, decoder-only, GPT-like transformer architecture. We use Tracr to create a range of ground truth transformers that implement programs including computing token frequencies, sorting, and Dyck-n parenthesis checking, among others. To enable the broader research community to explore and use compiled models, we provide an open-source implementation of Tracr at https://github.com/deepmind/tracr.
RIS-Assisted Receive Quadrature Spatial Modulation with Low-Complexity Greedy Detection
Jan 02, 2023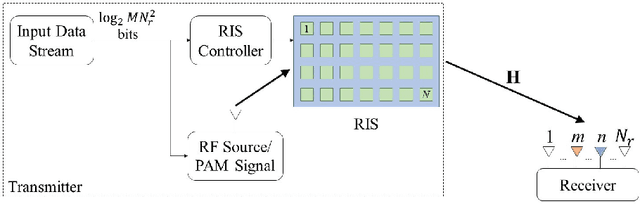
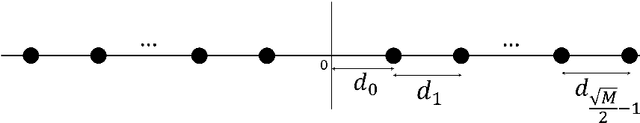
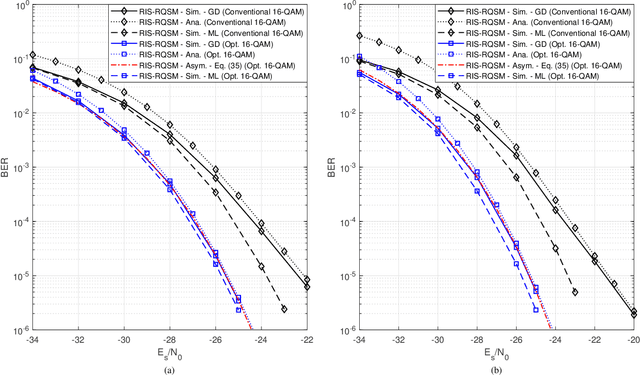
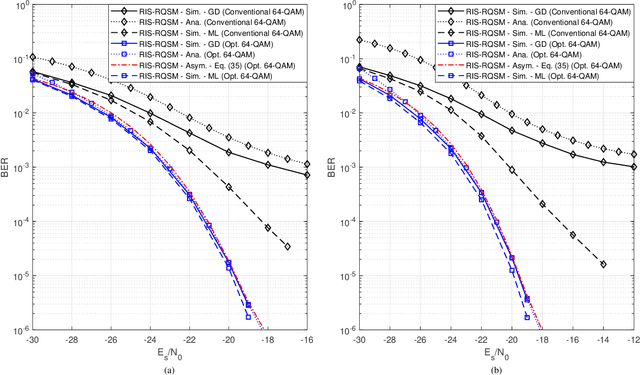
In this paper, we propose a novel reconfigurable intelligent surface (RIS)-assisted wireless communication scheme which uses the concept of spatial modulation, namely RIS-assisted receive quadrature spatial modulation (RIS-RQSM). In the proposed RIS-RQSM system, the information bits are conveyed via both the indices of the two selected receive antennas and the conventional in-phase/quadrature (IQ) modulation. We propose a novel methodology to adjust the phase shifts of the RIS elements in order to maximize the signal-to-noise ratio (SNR) and at the same time to construct two separate PAM symbols at the selected receive antennas, as the in-phase and quadrature components of the desired IQ symbol. An energy-based greedy detector (GD) is implemented at the receiver to efficiently detect the received signal with minimal channel state information (CSI) via the use of an appropriately designed one-tap pre-equalizer. We also derive a closed-form upper bound on the average bit error probability (ABEP) of the proposed RIS-RQSM system. Then, we formulate an optimization problem to minimize the ABEP in order to improve the performance of the system, which allows the GD to act as a near-optimal receiver. Extensive numerical results are provided to demonstrate the error rate performance of the system and to compare with that of a prominent benchmark scheme. The results verify the remarkable superiority of the proposed RIS-RQSM system over the benchmark scheme.
PLUE: Language Understanding Evaluation Benchmark for Privacy Policies in English
Dec 20, 2022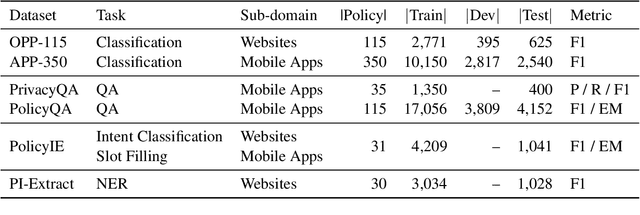
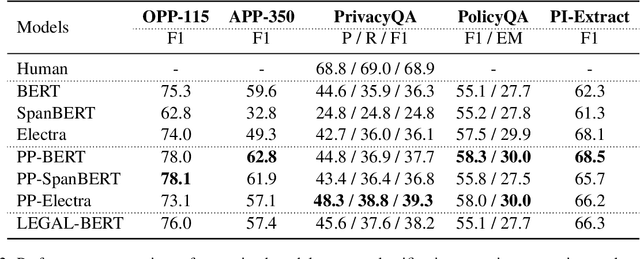
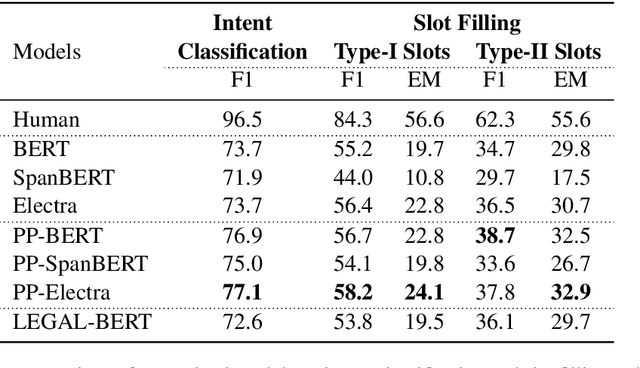
Privacy policies provide individuals with information about their rights and how their personal information is handled. Natural language understanding (NLU) technologies can support individuals and practitioners to understand better privacy practices described in lengthy and complex documents. However, existing efforts that use NLU technologies are limited by processing the language in a way exclusive to a single task focusing on certain privacy practices. To this end, we introduce the Privacy Policy Language Understanding Evaluation (PLUE) benchmark, a multi-task benchmark for evaluating the privacy policy language understanding across various tasks. We also collect a large corpus of privacy policies to enable privacy policy domain-specific language model pre-training. We demonstrate that domain-specific pre-training offers performance improvements across all tasks. We release the benchmark to encourage future research in this domain.
Causal conditional hidden Markov model for multimodal traffic prediction
Jan 19, 2023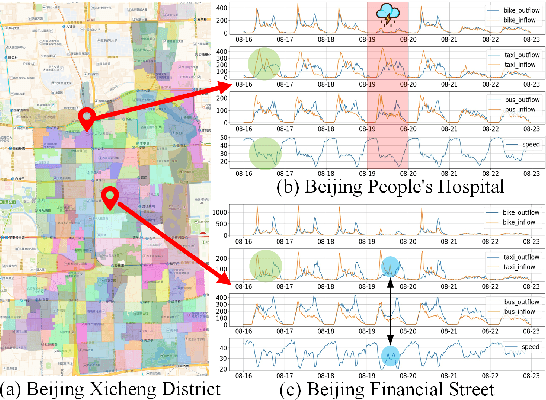

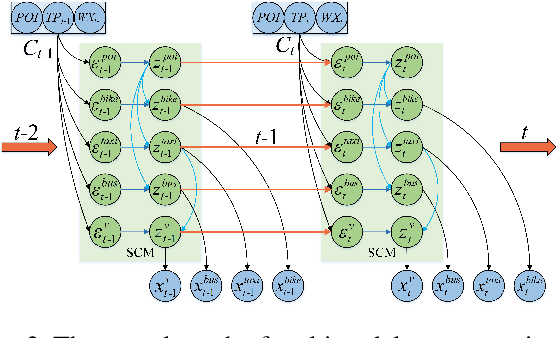

Multimodal traffic flow can reflect the health of the transportation system, and its prediction is crucial to urban traffic management. Recent works overemphasize spatio-temporal correlations of traffic flow, ignoring the physical concepts that lead to the generation of observations and their causal relationship. Spatio-temporal correlations are considered unstable under the influence of different conditions, and spurious correlations may exist in observations. In this paper, we analyze the physical concepts affecting the generation of multimode traffic flow from the perspective of the observation generation principle and propose a Causal Conditional Hidden Markov Model (CCHMM) to predict multimodal traffic flow. In the latent variables inference stage, a posterior network disentangles the causal representations of the concepts of interest from conditional information and observations, and a causal propagation module mines their causal relationship. In the data generation stage, a prior network samples the causal latent variables from the prior distribution and feeds them into the generator to generate multimodal traffic flow. We use a mutually supervised training method for the prior and posterior to enhance the identifiability of the model. Experiments on real-world datasets show that CCHMM can effectively disentangle causal representations of concepts of interest and identify causality, and accurately predict multimodal traffic flow.
Fast-BEV: Towards Real-time On-vehicle Bird's-Eye View Perception
Jan 19, 2023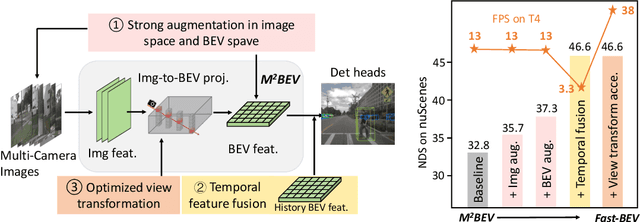
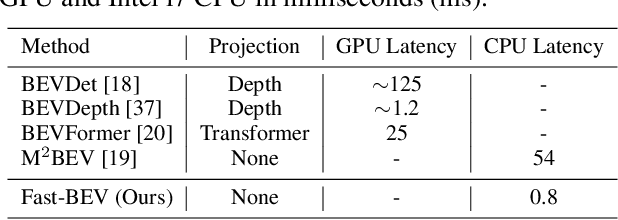
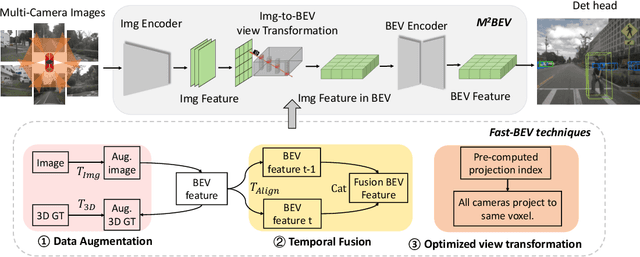
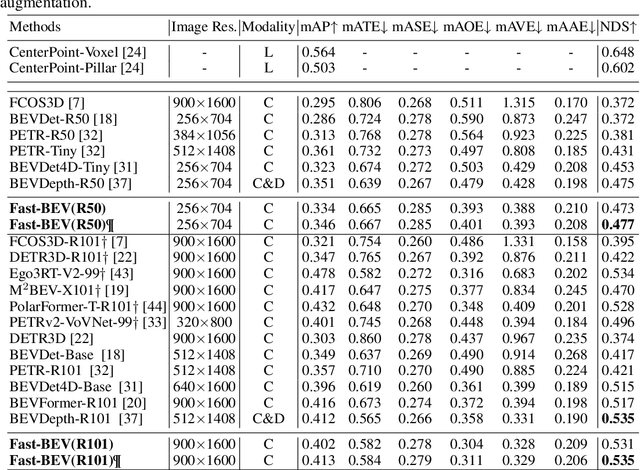
Recently, the pure camera-based Bird's-Eye-View (BEV) perception removes expensive Lidar sensors, making it a feasible solution for economical autonomous driving. However, most existing BEV solutions either suffer from modest performance or require considerable resources to execute on-vehicle inference. This paper proposes a simple yet effective framework, termed Fast-BEV, which is capable of performing real-time BEV perception on the on-vehicle chips. Towards this goal, we first empirically find that the BEV representation can be sufficiently powerful without expensive view transformation or depth representation. Starting from M2BEV baseline, we further introduce (1) a strong data augmentation strategy for both image and BEV space to avoid over-fitting (2) a multi-frame feature fusion mechanism to leverage the temporal information (3) an optimized deployment-friendly view transformation to speed up the inference. Through experiments, we show Fast-BEV model family achieves considerable accuracy and efficiency on edge. In particular, our M1 model (R18@256x704) can run over 50FPS on the Tesla T4 platform, with 47.0% NDS on the nuScenes validation set. Our largest model (R101@900x1600) establishes a new state-of-the-art 53.5% NDS on the nuScenes validation set. The code is released at: https://github.com/Sense-GVT/Fast-BEV.
* Accepted by NeurIPS2022_ML4AD on October 22, 2022
Incremental Learning for Neural Radiance Field with Uncertainty-Filtered Knowledge Distillation
Dec 21, 2022
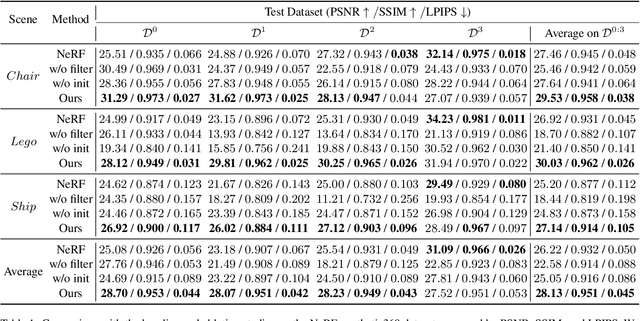
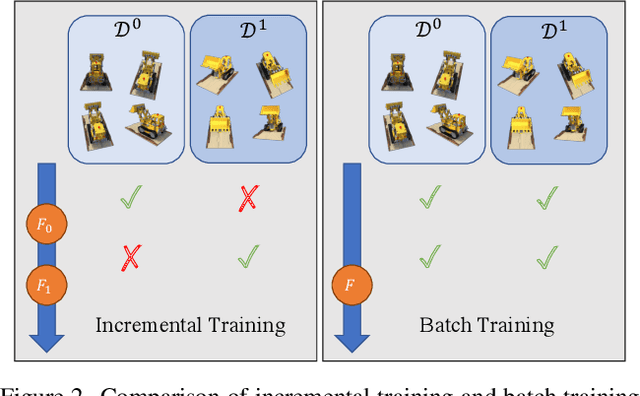
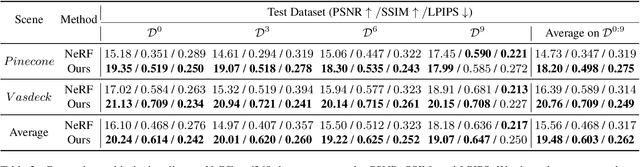
Recent neural radiance field (NeRF) representation has achieved great success in the tasks of novel view synthesis and 3D reconstruction. However, they suffer from the catastrophic forgetting problem when continuously learning from streaming data without revisiting the previous training data. This limitation prohibits the application of existing NeRF models to scenarios where images come in sequentially. In view of this, we explore the task of incremental learning for neural radiance field representation in this work. We first propose a student-teacher pipeline to mitigate the catastrophic forgetting problem. Specifically, we iterate the process of using the student as the teacher at the end of each incremental step and let the teacher guide the training of the student in the next step. In this way, the student network is able to learn new information from the streaming data and retain old knowledge from the teacher network simultaneously. Given that not all information from the teacher network is helpful since it is only trained with the old data, we further introduce a random inquirer and an uncertainty-based filter to filter useful information. We conduct experiments on the NeRF-synthetic360 and NeRF-real360 datasets, where our approach significantly outperforms the baselines by 7.3% and 25.2% in terms of PSNR. Furthermore, we also show that our approach can be applied to the large-scale camera facing-outwards dataset ScanNet, where we surpass the baseline by 60.0% in PSNR.
Feature Disentanglement Learning with Switching and Aggregation for Video-based Person Re-Identification
Dec 16, 2022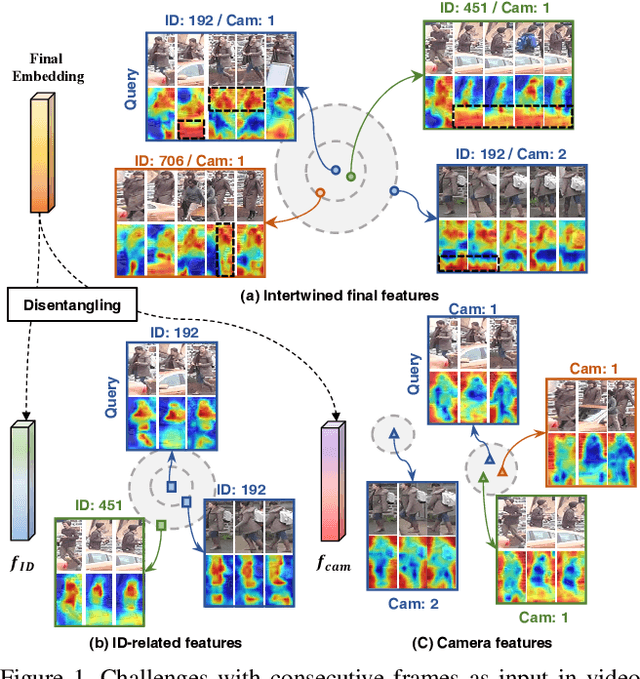
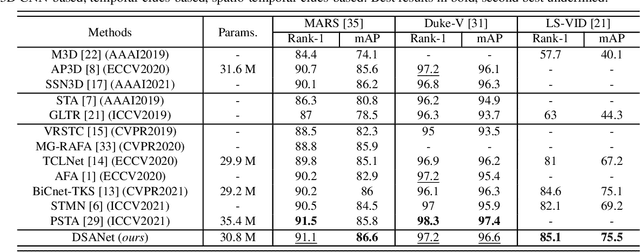
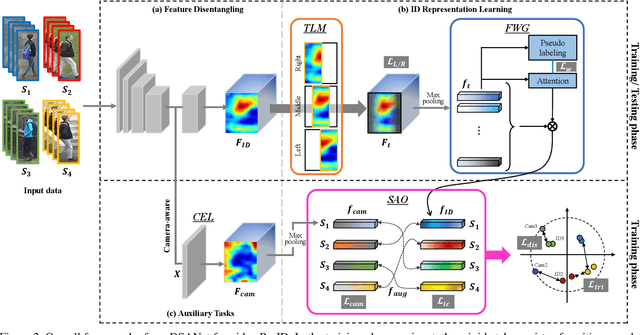
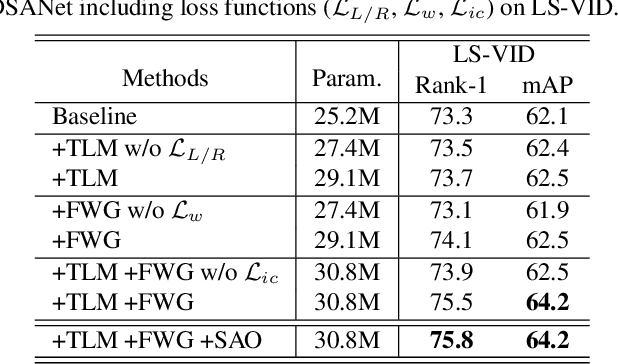
In video person re-identification (Re-ID), the network must consistently extract features of the target person from successive frames. Existing methods tend to focus only on how to use temporal information, which often leads to networks being fooled by similar appearances and same backgrounds. In this paper, we propose a Disentanglement and Switching and Aggregation Network (DSANet), which segregates the features representing identity and features based on camera characteristics, and pays more attention to ID information. We also introduce an auxiliary task that utilizes a new pair of features created through switching and aggregation to increase the network's capability for various camera scenarios. Furthermore, we devise a Target Localization Module (TLM) that extracts robust features against a change in the position of the target according to the frame flow and a Frame Weight Generation (FWG) that reflects temporal information in the final representation. Various loss functions for disentanglement learning are designed so that each component of the network can cooperate while satisfactorily performing its own role. Quantitative and qualitative results from extensive experiments demonstrate the superiority of DSANet over state-of-the-art methods on three benchmark datasets.
WIDER & CLOSER: Mixture of Short-channel Distillers for Zero-shot Cross-lingual Named Entity Recognition
Dec 07, 2022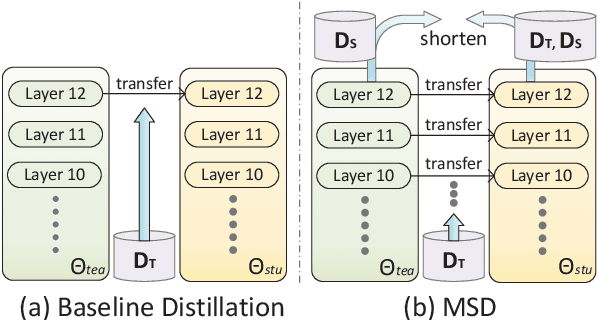
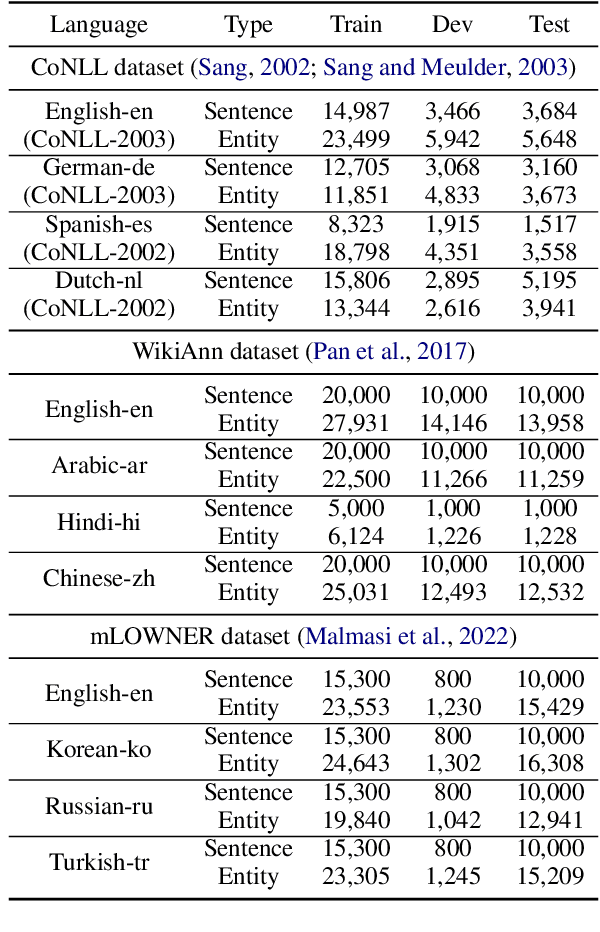
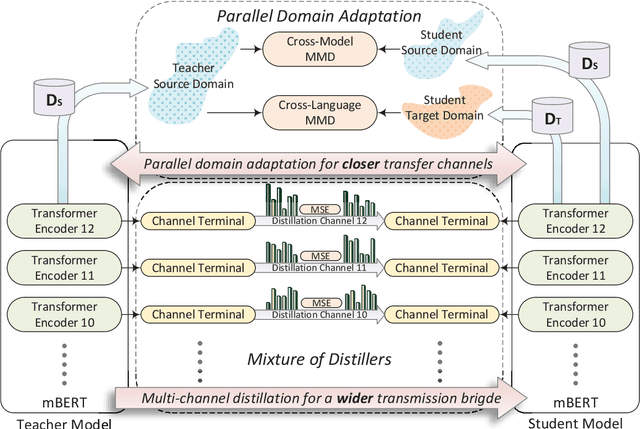
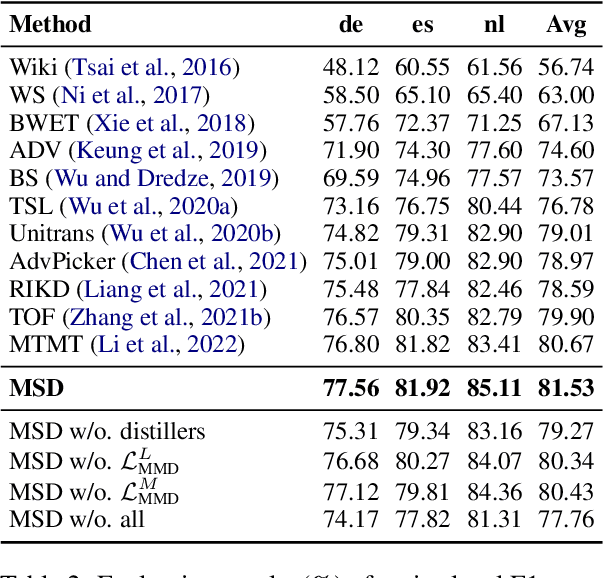
Zero-shot cross-lingual named entity recognition (NER) aims at transferring knowledge from annotated and rich-resource data in source languages to unlabeled and lean-resource data in target languages. Existing mainstream methods based on the teacher-student distillation framework ignore the rich and complementary information lying in the intermediate layers of pre-trained language models, and domain-invariant information is easily lost during transfer. In this study, a mixture of short-channel distillers (MSD) method is proposed to fully interact the rich hierarchical information in the teacher model and to transfer knowledge to the student model sufficiently and efficiently. Concretely, a multi-channel distillation framework is designed for sufficient information transfer by aggregating multiple distillers as a mixture. Besides, an unsupervised method adopting parallel domain adaptation is proposed to shorten the channels between the teacher and student models to preserve domain-invariant features. Experiments on four datasets across nine languages demonstrate that the proposed method achieves new state-of-the-art performance on zero-shot cross-lingual NER and shows great generalization and compatibility across languages and fields.
Multi Kernel Positional Embedding ConvNeXt for Polyp Segmentation
Jan 17, 2023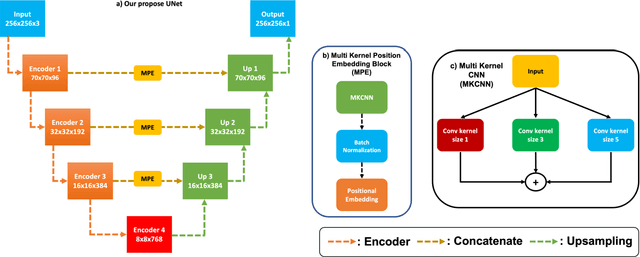
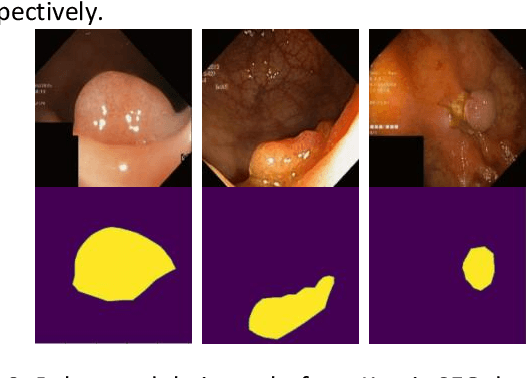
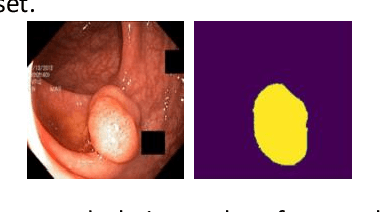
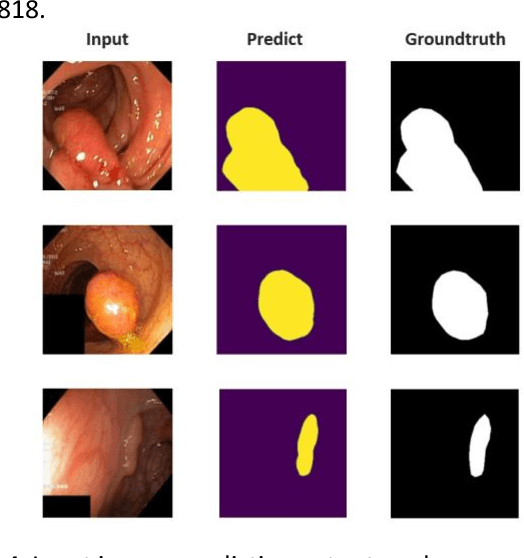
Medical image segmentation is the technique that helps doctor view and has a precise diagnosis, particularly in Colorectal Cancer. Specifically, with the increase in cases, the diagnosis and identification need to be faster and more accurate for many patients; in endoscopic images, the segmentation task has been vital to helping the doctor identify the position of the polyps or the ache in the system correctly. As a result, many efforts have been made to apply deep learning to automate polyp segmentation, mostly to ameliorate the U-shape structure. However, the simple skip connection scheme in UNet leads to deficient context information and the semantic gap between feature maps from the encoder and decoder. To deal with this problem, we propose a novel framework composed of ConvNeXt backbone and Multi Kernel Positional Embedding block. Thanks to the suggested module, our method can attain better accuracy and generalization in the polyps segmentation task. Extensive experiments show that our model achieves the Dice coefficient of 0.8818 and the IOU score of 0.8163 on the Kvasir-SEG dataset. Furthermore, on various datasets, we make competitive achievement results with other previous state-of-the-art methods.