 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Reinforcement Learning for Uplink Multi-Carrier Non-Orthogonal Multiple Access Resource Allocation Using Buffer State Information
Aug 31, 2022
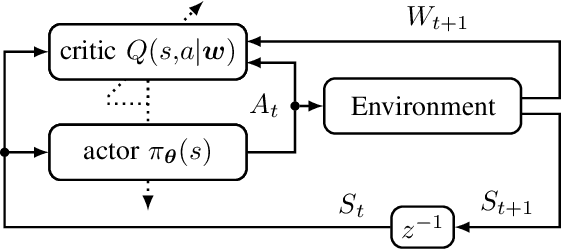
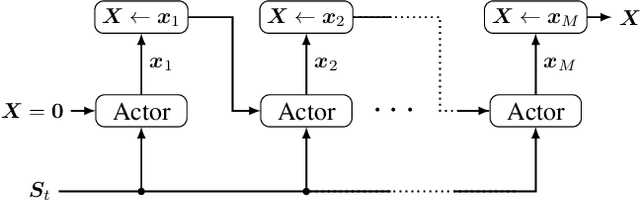
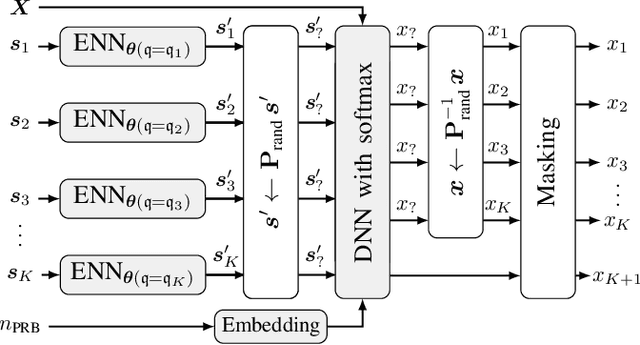
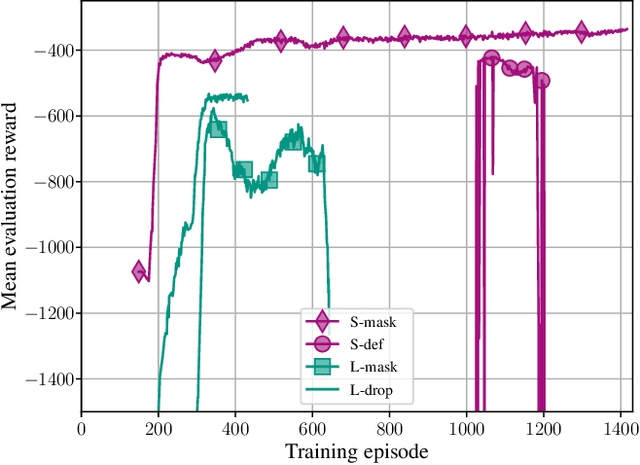
For orthogonal multiple access (OMA) systems, the number of served user equipments (UEs) is limited to the number of available orthogonal resources. On the other hand, non-orthogonal multiple access (NOMA) schemes allow multiple UEs to use the same orthogonal resource. This extra degree of freedom introduces new challenges for resource allocation. Buffer state information (BSI), like the size and age of packets waiting for transmission, can be used to improve scheduling in OMA systems. In this paper, we investigate the impact of BSI on the performance of a centralized scheduler in an uplink multi-carrier NOMA scenario with UEs having various data rate and latency requirements. To handle the large combinatorial space of allocating UEs to the resources, we propose a novel scheduler based on actor-critic reinforcement learning incorporating BSI. Training and evaluation are carried out using Nokia's "wireless suite". We propose various novel techniques to both stabilize and speed up training. The proposed scheduler outperforms benchmark schedulers.
Persona-Based Conversational AI: State of the Art and Challenges
Dec 04, 2022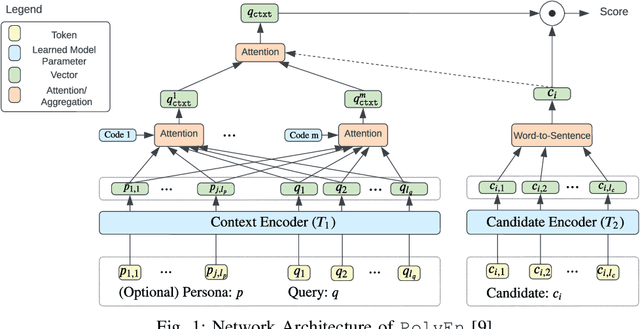
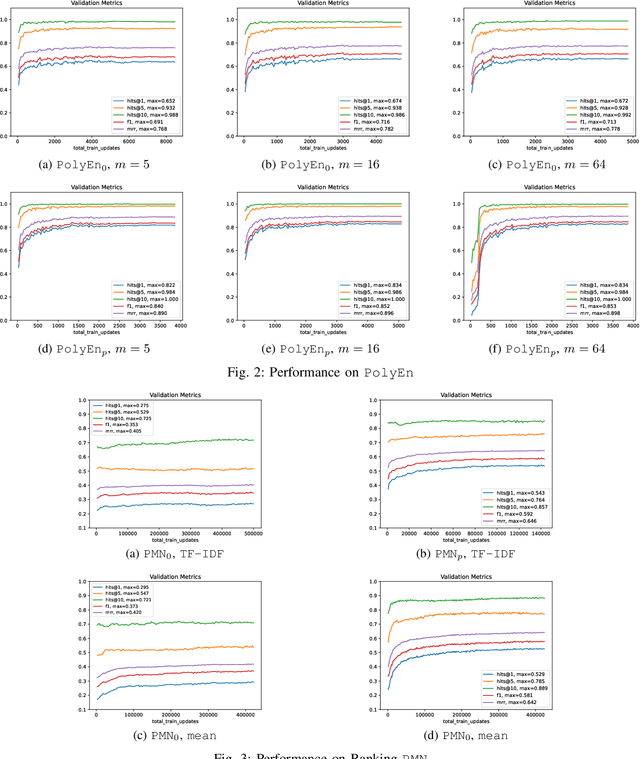
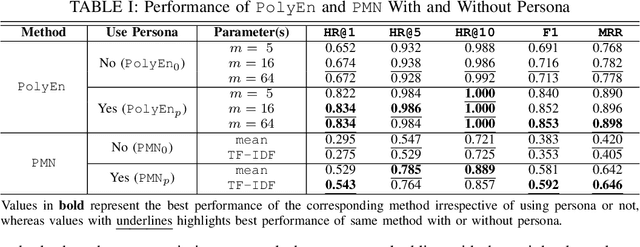
Conversational AI has become an increasingly prominent and practical application of machine learning. However, existing conversational AI techniques still suffer from various limitations. One such limitation is a lack of well-developed methods for incorporating auxiliary information that could help a model understand conversational context better. In this paper, we explore how persona-based information could help improve the quality of response generation in conversations. First, we provide a literature review focusing on the current state-of-the-art methods that utilize persona information. We evaluate two strong baseline methods, the Ranking Profile Memory Network and the Poly-Encoder, on the NeurIPS ConvAI2 benchmark dataset. Our analysis elucidates the importance of incorporating persona information into conversational systems. Additionally, our study highlights several limitations with current state-of-the-art methods and outlines challenges and future research directions for advancing personalized conversational AI technology.
Bidirectional Propagation for Cross-Modal 3D Object Detection
Jan 22, 2023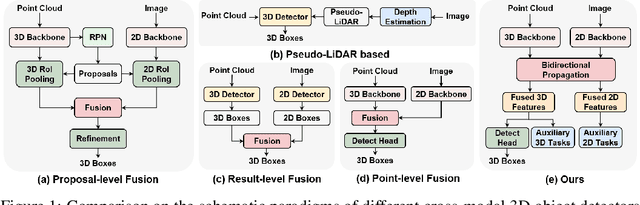
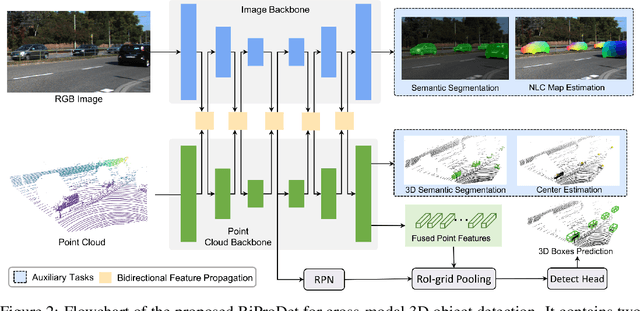
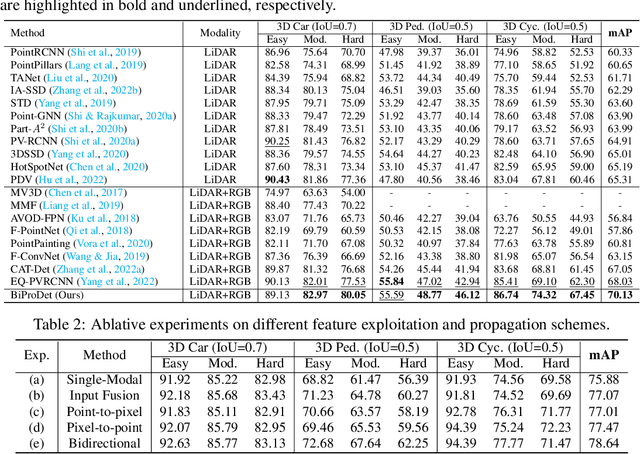
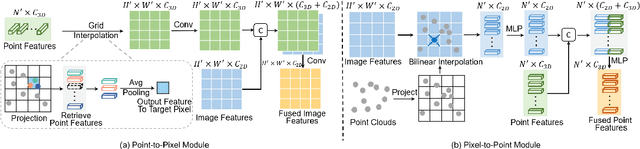
Recent works have revealed the superiority of feature-level fusion for cross-modal 3D object detection, where fine-grained feature propagation from 2D image pixels to 3D LiDAR points has been widely adopted for performance improvement. Still, the potential of heterogeneous feature propagation between 2D and 3D domains has not been fully explored. In this paper, in contrast to existing pixel-to-point feature propagation, we investigate an opposite point-to-pixel direction, allowing point-wise features to flow inversely into the 2D image branch. Thus, when jointly optimizing the 2D and 3D streams, the gradients back-propagated from the 2D image branch can boost the representation ability of the 3D backbone network working on LiDAR point clouds. Then, combining pixel-to-point and point-to-pixel information flow mechanisms, we construct an bidirectional feature propagation framework, dubbed BiProDet. In addition to the architectural design, we also propose normalized local coordinates map estimation, a new 2D auxiliary task for the training of the 2D image branch, which facilitates learning local spatial-aware features from the image modality and implicitly enhances the overall 3D detection performance. Extensive experiments and ablation studies validate the effectiveness of our method. Notably, we rank $\mathbf{1^{\mathrm{st}}}$ on the highly competitive KITTI benchmark on the cyclist class by the time of submission. The source code is available at https://github.com/Eaphan/BiProDet.
Ensemble Transfer Learning for Multilingual Coreference Resolution
Jan 22, 2023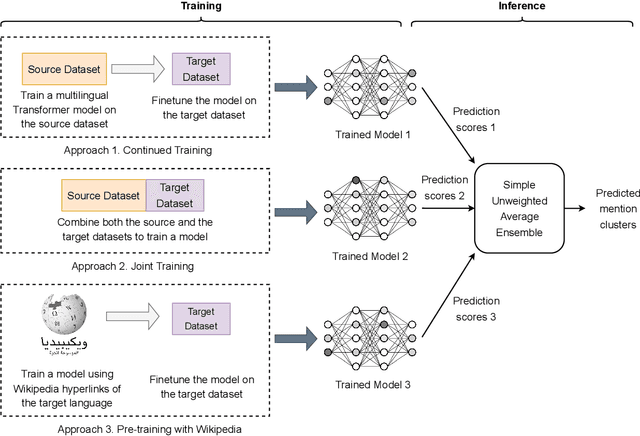
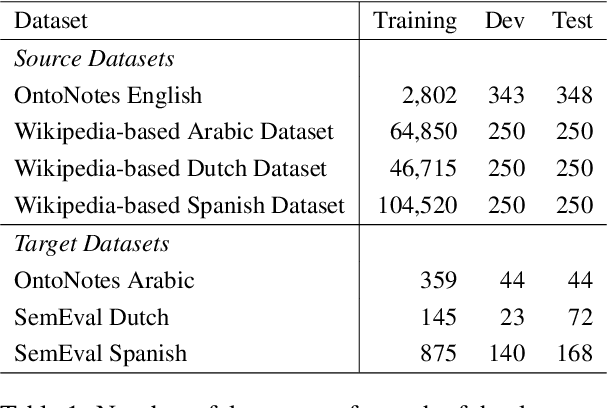
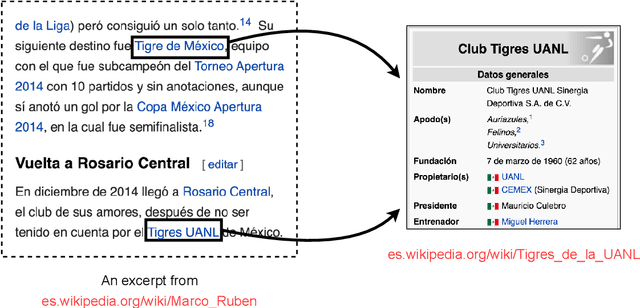
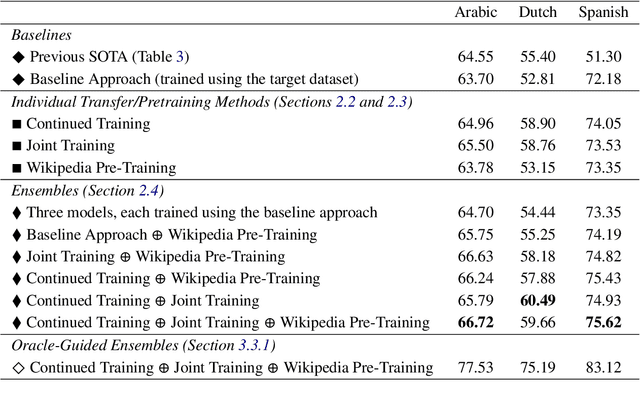
Entity coreference resolution is an important research problem with many applications, including information extraction and question answering. Coreference resolution for English has been studied extensively. However, there is relatively little work for other languages. A problem that frequently occurs when working with a non-English language is the scarcity of annotated training data. To overcome this challenge, we design a simple but effective ensemble-based framework that combines various transfer learning (TL) techniques. We first train several models using different TL methods. Then, during inference, we compute the unweighted average scores of the models' predictions to extract the final set of predicted clusters. Furthermore, we also propose a low-cost TL method that bootstraps coreference resolution models by utilizing Wikipedia anchor texts. Leveraging the idea that the coreferential links naturally exist between anchor texts pointing to the same article, our method builds a sizeable distantly-supervised dataset for the target language that consists of tens of thousands of documents. We can pre-train a model on the pseudo-labeled dataset before finetuning it on the final target dataset. Experimental results on two benchmark datasets, OntoNotes and SemEval, confirm the effectiveness of our methods. Our best ensembles consistently outperform the baseline approach of simple training by up to 7.68% in the F1 score. These ensembles also achieve new state-of-the-art results for three languages: Arabic, Dutch, and Spanish.
Learning Deep MRI Reconstruction Models from Scratch in Low-Data Regimes
Jan 06, 2023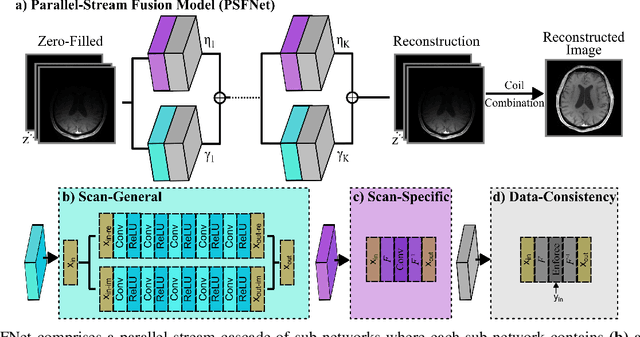
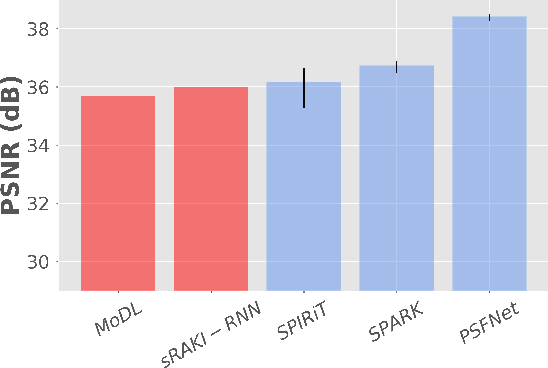
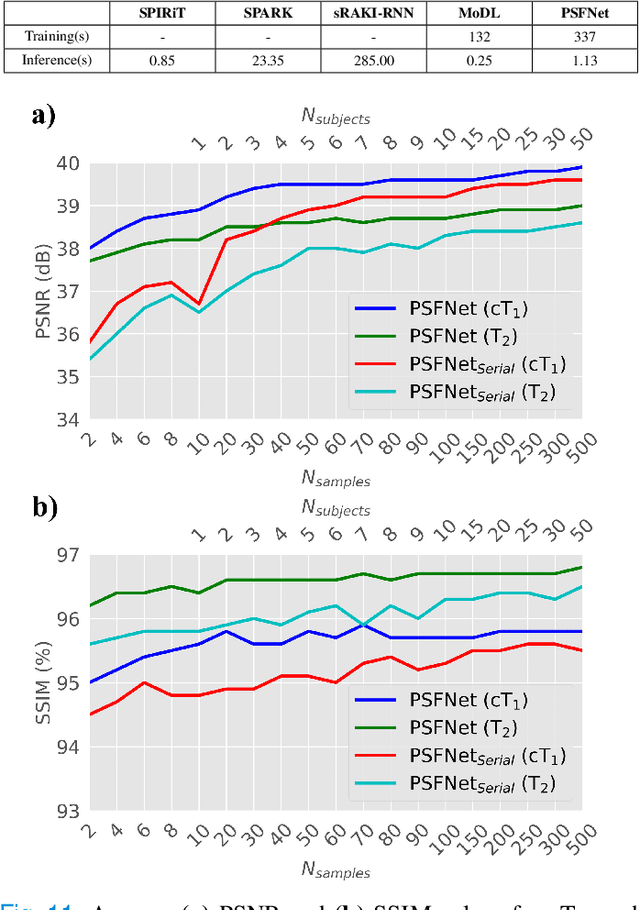
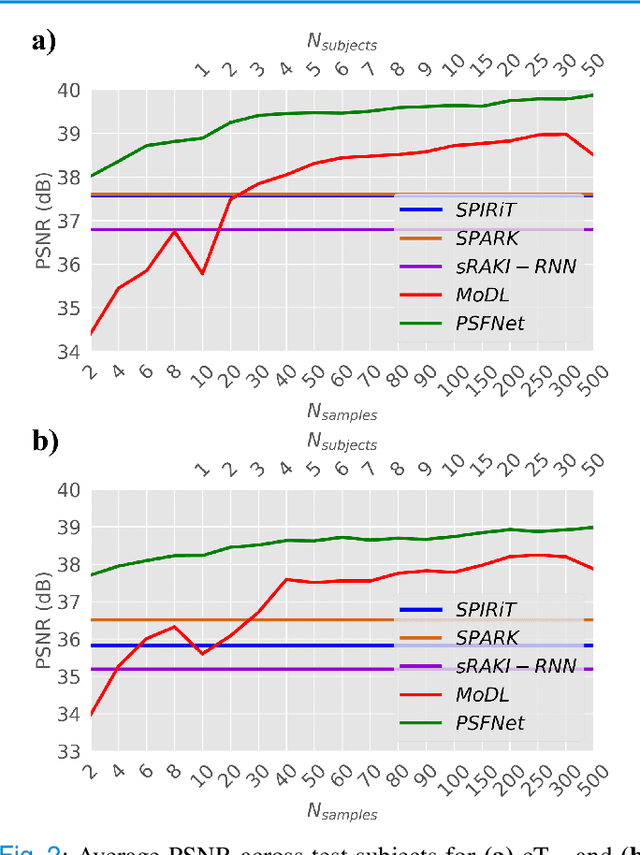
Magnetic resonance imaging (MRI) is an essential diagnostic tool that suffers from prolonged scan times. Reconstruction methods can alleviate this limitation by recovering clinically usable images from accelerated acquisitions. In particular, learning-based methods promise performance leaps by employing deep neural networks as data-driven priors. A powerful approach uses scan-specific (SS) priors that leverage information regarding the underlying physical signal model for reconstruction. SS priors are learned on each individual test scan without the need for a training dataset, albeit they suffer from computationally burdening inference with nonlinear networks. An alternative approach uses scan-general (SG) priors that instead leverage information regarding the latent features of MRI images for reconstruction. SG priors are frozen at test time for efficiency, albeit they require learning from a large training dataset. Here, we introduce a novel parallel-stream fusion model (PSFNet) that synergistically fuses SS and SG priors for performant MRI reconstruction in low-data regimes, while maintaining competitive inference times to SG methods. PSFNet implements its SG prior based on a nonlinear network, yet it forms its SS prior based on a linear network to maintain efficiency. A pervasive framework for combining multiple priors in MRI reconstruction is algorithmic unrolling that uses serially alternated projections, causing error propagation under low-data regimes. To alleviate error propagation, PSFNet combines its SS and SG priors via a novel parallel-stream architecture with learnable fusion parameters. Demonstrations are performed on multi-coil brain MRI for varying amounts of training data. PSFNet outperforms SG methods in low-data regimes, and surpasses SS methods with few tens of training samples.
RME-GAN: A Learning Framework for Radio Map Estimation based on Conditional Generative Adversarial Network
Dec 24, 2022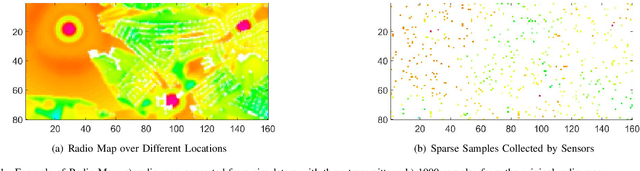
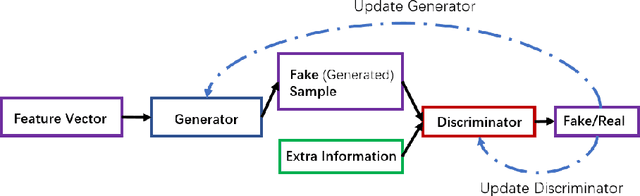
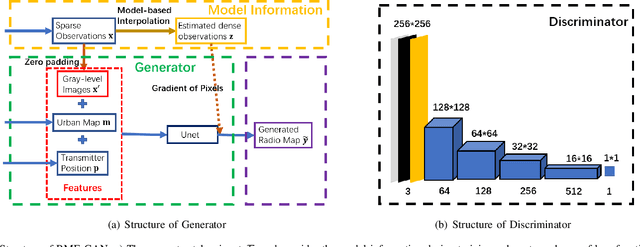

Outdoor radio map estimation is an important tool for network planning and resource management in modern Internet of Things (IoT) and cellular systems. Radio map describes spatial signal strength distribution and provides network coverage information. A practical goal is to estimate fine-resolution radio maps from sparse radio strength measurements. However, non-uniformly positioned measurements and access obstacles can make it difficult for accurate radio map estimation (RME) and spectrum planning in many outdoor environments. In this work, we develop a two-phase learning framework for radio map estimation by integrating radio propagation model and designing a conditional generative adversarial network (cGAN). We first explore global information to extract the radio propagation patterns. We then focus on the local features to estimate the effect of shadowing on radio maps in order to train and optimize the cGAN. Our experimental results demonstrate the efficacy of the proposed framework for radio map estimation based on generative models from sparse observations in outdoor scenarios.
Search-Based Task and Motion Planning for Hybrid Systems: Agile Autonomous Vehicles
Jan 25, 2023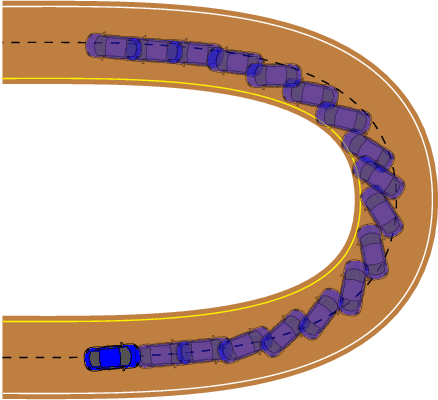
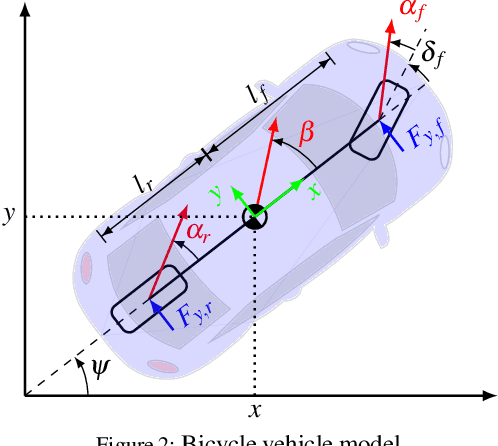
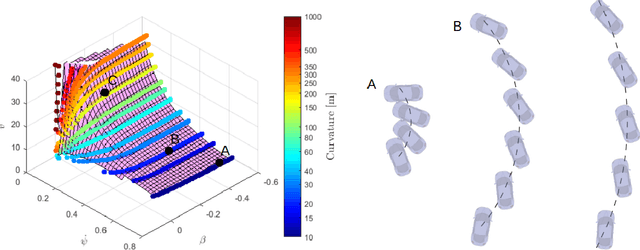
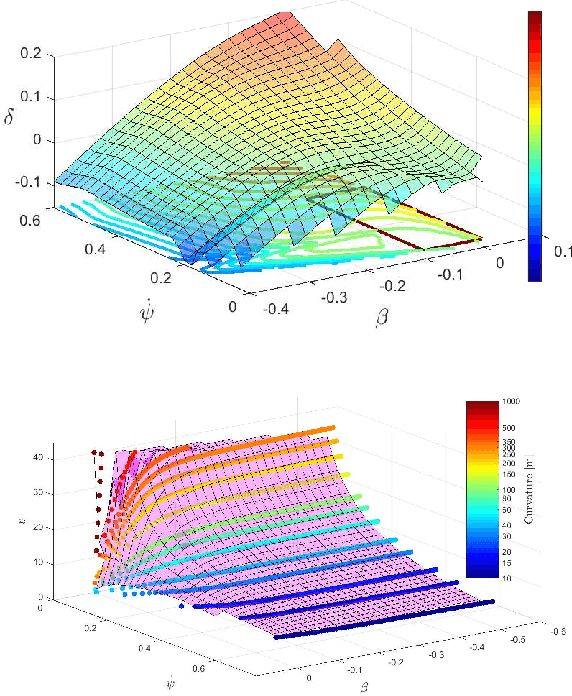
To achieve optimal robot behavior in dynamic scenarios we need to consider complex dynamics in a predictive manner. In the vehicle dynamics community, it is well know that to achieve time-optimal driving on low surface, the vehicle should utilize drifting. Hence many authors have devised rules to split circuits and employ drifting on some segments. These rules are suboptimal and do not generalize to arbitrary circuit shapes (e.g., S-like curves). So, the question "When to go into which mode and how to drive in it?" remains unanswered. To choose the suitable mode (discrete decision), the algorithm needs information about the feasibility of the continuous motion in that mode. This makes it a class of Task and Motion Planning (TAMP) problems, which are known to be hard to solve optimally in real-time. In the AI planning community, search methods are commonly used. However, they cannot be directly applied to TAMP problems due to the continuous component. Here, we present a search-based method that effectively solves this problem and efficiently searches in a highly dimensional state space with nonlinear and unstable dynamics. The space of the possible trajectories is explored by sampling different combinations of motion primitives guided by the search. Our approach allows to use multiple locally approximated models to generate motion primitives (e.g., learned models of drifting) and effectively simplify the problem without losing accuracy. The algorithm performance is evaluated in simulated driving on a mixed-track with segments of different curvatures (right and left). Our code is available at https://git.io/JenvB
Learning Trajectory-Conditioned Relations to Predict Pedestrian Crossing Behavior
Jan 14, 2023
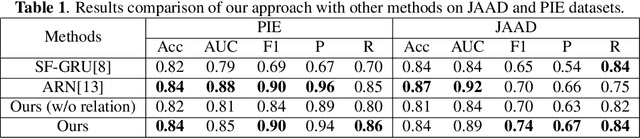
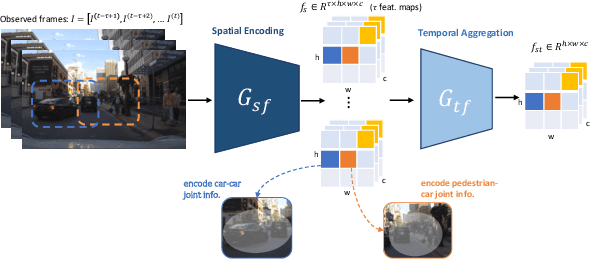
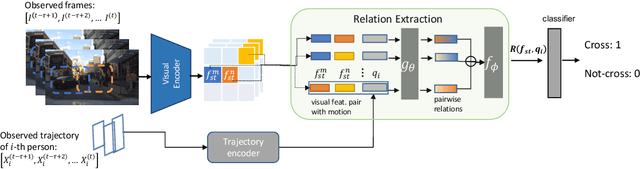
In smart transportation, intelligent systems avoid potential collisions by predicting the intent of traffic agents, especially pedestrians. Pedestrian intent, defined as future action, e.g., start crossing, can be dependent on traffic surroundings. In this paper, we develop a framework to incorporate such dependency given observed pedestrian trajectory and scene frames. Our framework first encodes regional joint information between a pedestrian and surroundings over time into feature-map vectors. The global relation representations are then extracted from pairwise feature-map vectors to estimate intent with past trajectory condition. We evaluate our approach on two public datasets and compare against two state-of-the-art approaches. The experimental results demonstrate that our method helps to inform potential risks during crossing events with 0.04 improvement in F1-score on JAAD dataset and 0.01 improvement in recall on PIE dataset. Furthermore, we conduct ablation experiments to confirm the contribution of the relation extraction in our framework.
Deepfake Detection using Biological Features: A Survey
Jan 14, 2023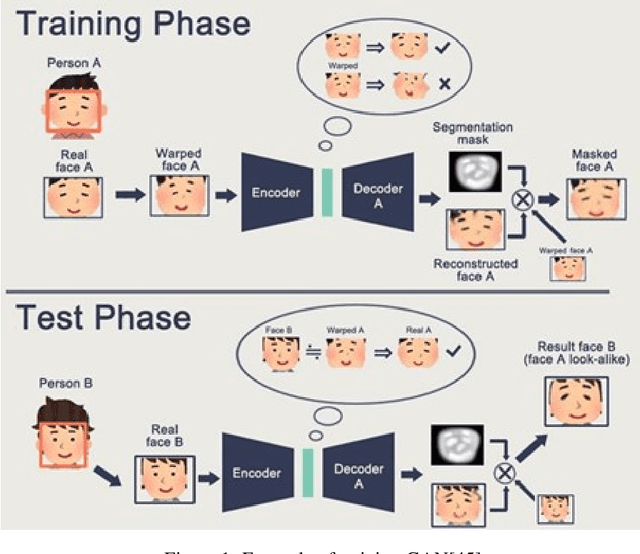
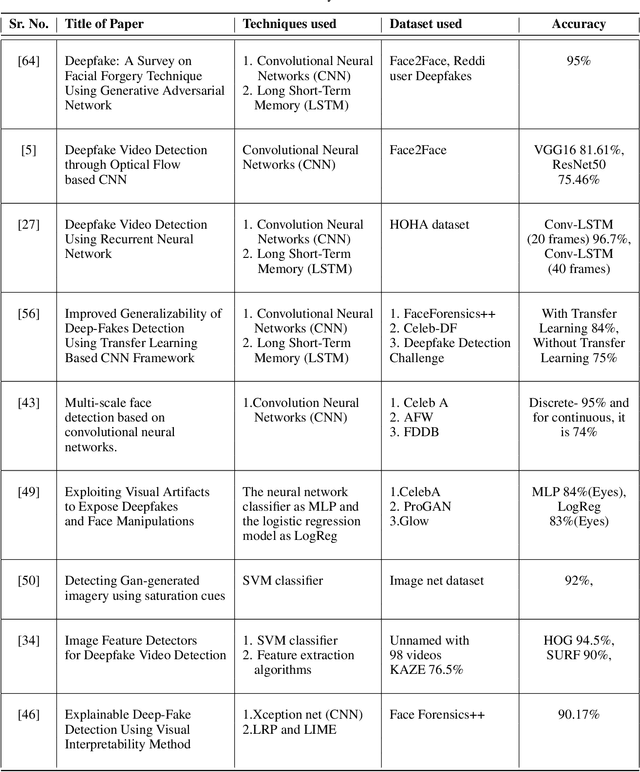
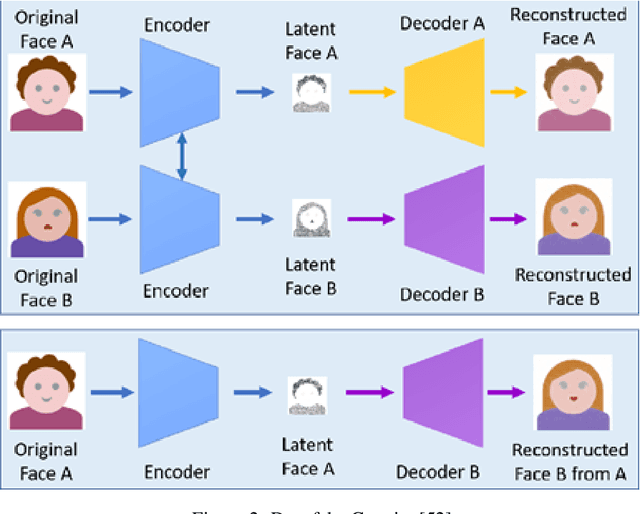
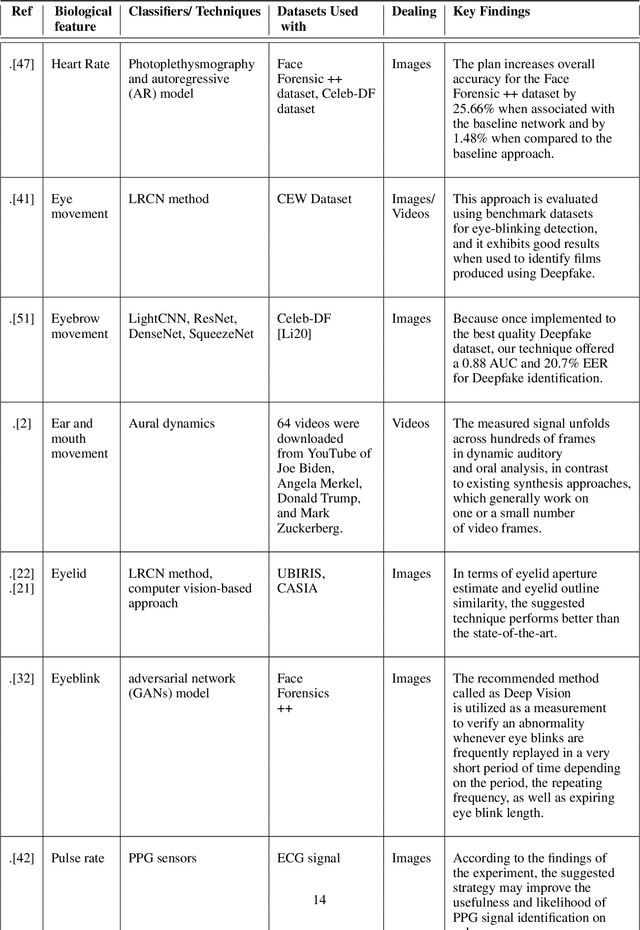
Deepfake is a deep learning-based technique that makes it easy to change or modify images and videos. In investigations and court, visual evidence is commonly employed, but these pieces of evidence may now be suspect due to technological advancements in deepfake. Deepfakes have been used to blackmail individuals, plan terrorist attacks, disseminate false information, defame individuals, and foment political turmoil. This study describes the history of deepfake, its development and detection, and the challenges based on physiological measurements such as eyebrow recognition, eye blinking detection, eye movement detection, ear and mouth detection, and heartbeat detection. The study also proposes a scope in this field and compares the different biological features and their classifiers. Deepfakes are created using the generative adversarial network (GANs) model, and were once easy to detect by humans due to visible artifacts. However, as technology has advanced, deepfakes have become highly indistinguishable from natural images, making it important to review detection methods.
Mobile Localization Techniques Oriented to Tangible Web
Dec 12, 2022We implemented a system able to locate people indoor, with the purpose of providing assistive services. Such approach is particularly important for the Art, for providing information on exhibitions, art galleries and museums, and to allow the access to the cultural heritage patrimony to people with disabilities. The system may provide also very important information and input to elderly people, helping them to perceive more deeply the reality and the beauty of art. The system is based on Beacons, very small and low power consumption devices, and Human Body Communication protocols. The Beacons, Bluetooth Low Energy devices, allow to obtain a position information related to predetermined reference points, and through proximity algorithms, locate a person or an object of interest. The position obtained has an error that depends from the interferences present in the area. The union of Beacons with Human Body Communication, a recent wireless technology that exploits the human body as a transmission channel, makes it possible to increase the accuracy of localization. The basic idea is to exploit the localization derived from Beacons to start a search for an electrical signal transmitted by the human body and to distinguish the position according to the information contained in the signal. The signal is transmitted by capacitance to the human body and revealed by a special resonant circuit (antenna) adapted to the microphone input of the mobile device.