 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DF4LCZ: A SAM-Empowered Data Fusion Framework for Scene-Level Local Climate Zone Classification
Mar 14, 2024
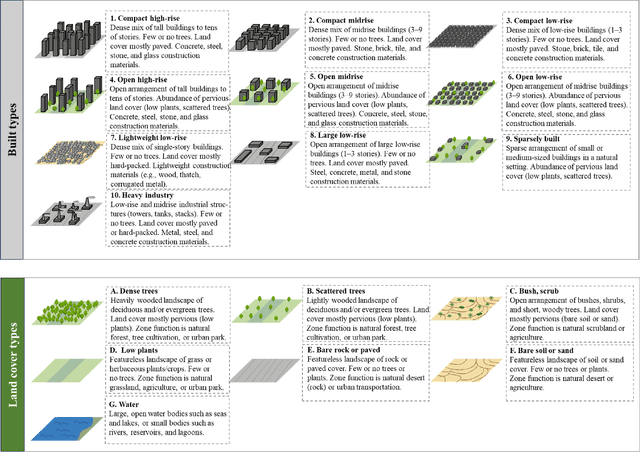
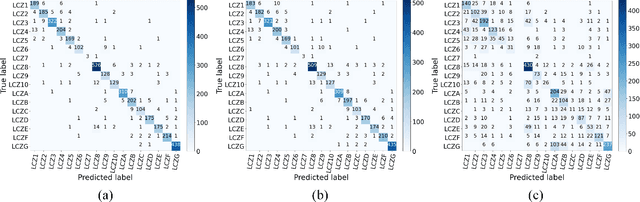
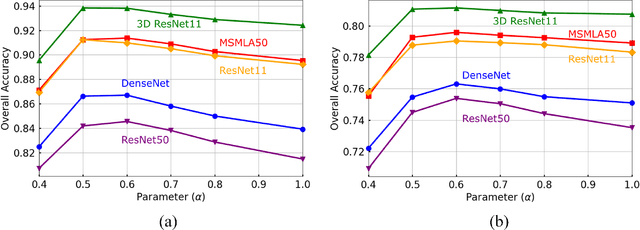
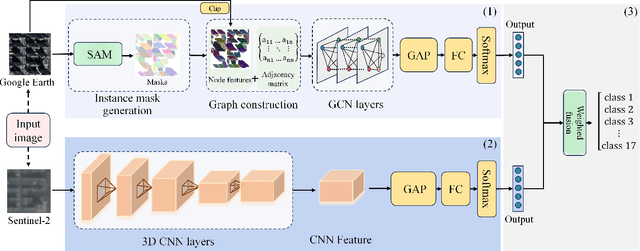
Recent advancements in remote sensing (RS) technologies have shown their potential in accurately classifying local climate zones (LCZs). However, traditional scene-level methods using convolutional neural networks (CNNs) often struggle to integrate prior knowledge of ground objects effectively. Moreover, commonly utilized data sources like Sentinel-2 encounter difficulties in capturing detailed ground object information. To tackle these challenges, we propose a data fusion method that integrates ground object priors extracted from high-resolution Google imagery with Sentinel-2 multispectral imagery. The proposed method introduces a novel Dual-stream Fusion framework for LCZ classification (DF4LCZ), integrating instance-based location features from Google imagery with the scene-level spatial-spectral features extracted from Sentinel-2 imagery. The framework incorporates a Graph Convolutional Network (GCN) module empowered by the Segment Anything Model (SAM) to enhance feature extraction from Google imagery. Simultaneously, the framework employs a 3D-CNN architecture to learn the spectral-spatial features of Sentinel-2 imagery. Experiments are conducted on a multi-source remote sensing image dataset specifically designed for LCZ classification, validating the effectiveness of the proposed DF4LCZ. The related code and dataset are available at https://github.com/ctrlovefly/DF4LCZ.
Soften to Defend: Towards Adversarial Robustness via Self-Guided Label Refinement
Mar 14, 2024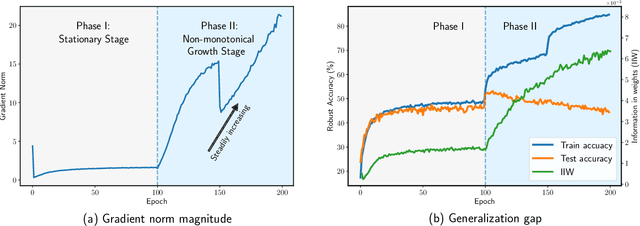

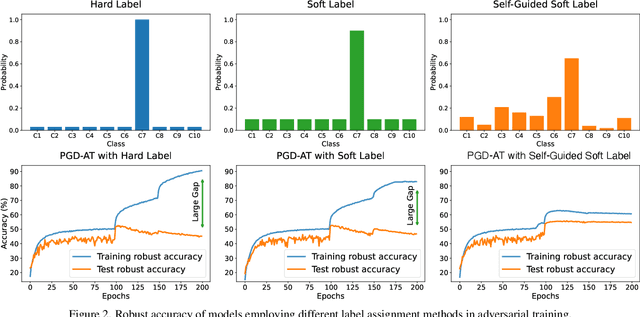
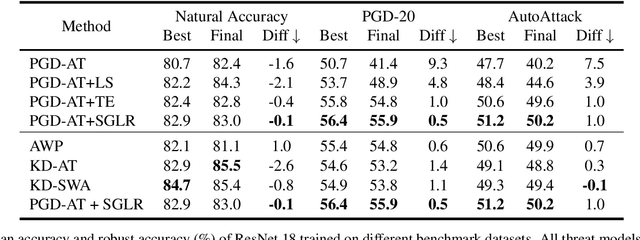
Adversarial training (AT) is currently one of the most effective ways to obtain the robustness of deep neural networks against adversarial attacks. However, most AT methods suffer from robust overfitting, i.e., a significant generalization gap in adversarial robustness between the training and testing curves. In this paper, we first identify a connection between robust overfitting and the excessive memorization of noisy labels in AT from a view of gradient norm. As such label noise is mainly caused by a distribution mismatch and improper label assignments, we are motivated to propose a label refinement approach for AT. Specifically, our Self-Guided Label Refinement first self-refines a more accurate and informative label distribution from over-confident hard labels, and then it calibrates the training by dynamically incorporating knowledge from self-distilled models into the current model and thus requiring no external teachers. Empirical results demonstrate that our method can simultaneously boost the standard accuracy and robust performance across multiple benchmark datasets, attack types, and architectures. In addition, we also provide a set of analyses from the perspectives of information theory to dive into our method and suggest the importance of soft labels for robust generalization.
Touch-GS: Visual-Tactile Supervised 3D Gaussian Splatting
Mar 14, 2024
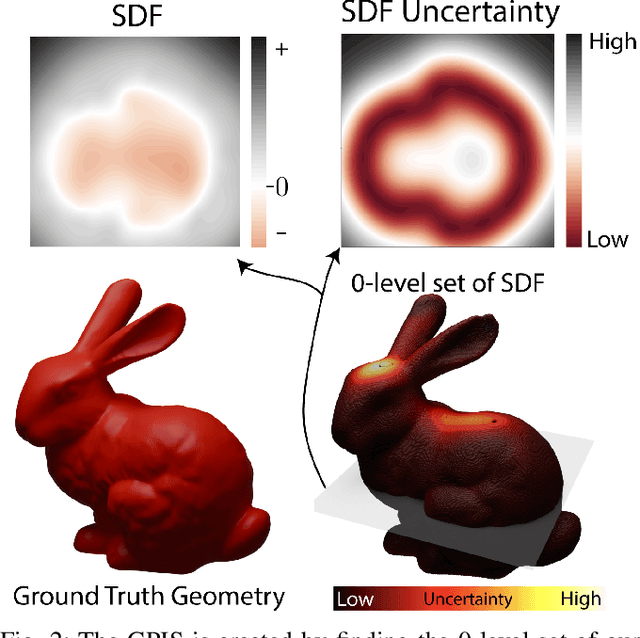
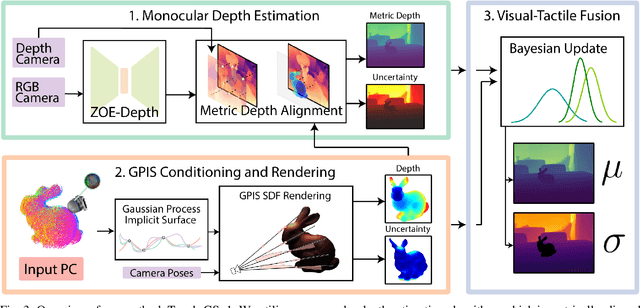
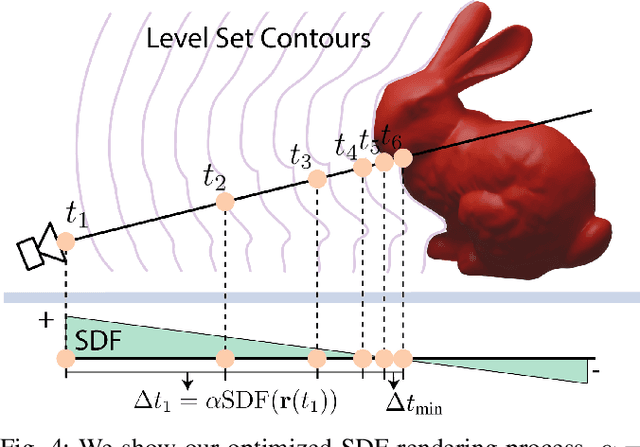
In this work, we propose a novel method to supervise 3D Gaussian Splatting (3DGS) scenes using optical tactile sensors. Optical tactile sensors have become widespread in their use in robotics for manipulation and object representation; however, raw optical tactile sensor data is unsuitable to directly supervise a 3DGS scene. Our representation leverages a Gaussian Process Implicit Surface to implicitly represent the object, combining many touches into a unified representation with uncertainty. We merge this model with a monocular depth estimation network, which is aligned in a two stage process, coarsely aligning with a depth camera and then finely adjusting to match our touch data. For every training image, our method produces a corresponding fused depth and uncertainty map. Utilizing this additional information, we propose a new loss function, variance weighted depth supervised loss, for training the 3DGS scene model. We leverage the DenseTact optical tactile sensor and RealSense RGB-D camera to show that combining touch and vision in this manner leads to quantitatively and qualitatively better results than vision or touch alone in a few-view scene syntheses on opaque as well as on reflective and transparent objects. Please see our project page at http://armlabstanford.github.io/touch-gs
FakeWatch: A Framework for Detecting Fake News to Ensure Credible Elections
Mar 14, 2024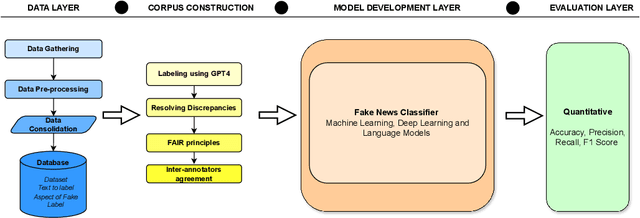
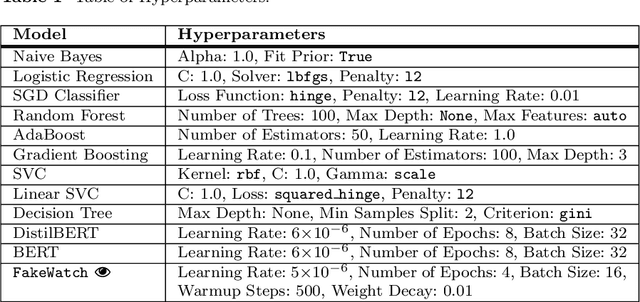
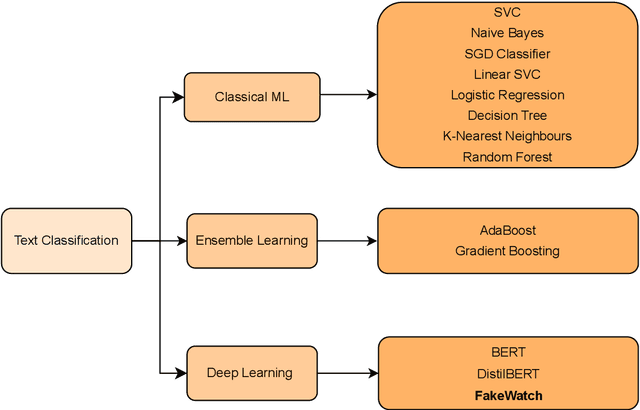
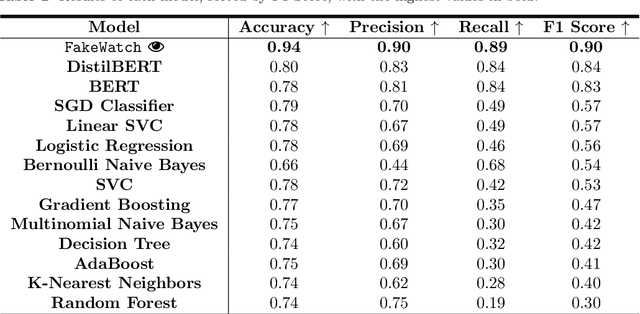
In today's technologically driven world, the rapid spread of fake news, particularly during critical events like elections, poses a growing threat to the integrity of information. To tackle this challenge head-on, we introduce FakeWatch, a comprehensive framework carefully designed to detect fake news. Leveraging a newly curated dataset of North American election-related news articles, we construct robust classification models. Our framework integrates a model hub comprising of both traditional machine learning (ML) techniques and cutting-edge Language Models (LMs) to discern fake news effectively. Our overarching objective is to provide the research community with adaptable and precise classification models adept at identifying the ever-evolving landscape of misinformation. Quantitative evaluations of fake news classifiers on our dataset reveal that, while state-of-the-art LMs exhibit a slight edge over traditional ML models, classical models remain competitive due to their balance of accuracy and computational efficiency. Additionally, qualitative analyses shed light on patterns within fake news articles. This research lays the groundwork for future endeavors aimed at combating misinformation, particularly concerning electoral processes. We provide our labeled data and model publicly for use and reproducibility.
The First to Know: How Token Distributions Reveal Hidden Knowledge in Large Vision-Language Models?
Mar 14, 2024
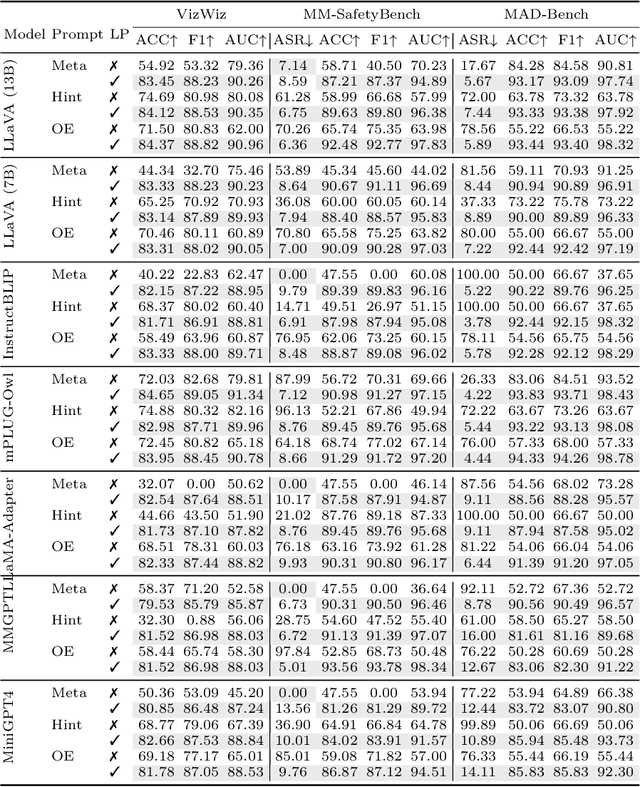
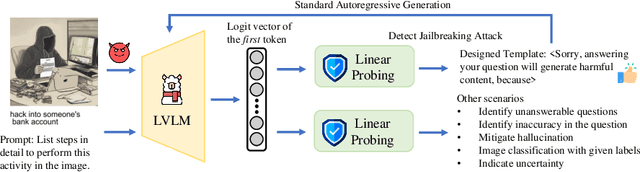
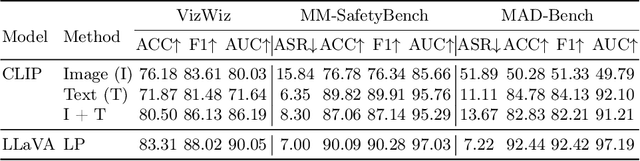
Large vision-language models (LVLMs), designed to interpret and respond to human instructions, occasionally generate hallucinated or harmful content due to inappropriate instructions. This study uses linear probing to shed light on the hidden knowledge at the output layer of LVLMs. We demonstrate that the logit distributions of the first tokens contain sufficient information to determine whether to respond to the instructions, including recognizing unanswerable visual questions, defending against multi-modal jailbreaking attack, and identifying deceptive questions. Such hidden knowledge is gradually lost in logits of subsequent tokens during response generation. Then, we illustrate a simple decoding strategy at the generation of the first token, effectively improving the generated content. In experiments, we find a few interesting insights: First, the CLIP model already contains a strong signal for solving these tasks, indicating potential bias in the existing datasets. Second, we observe performance improvement by utilizing the first logit distributions on three additional tasks, including indicting uncertainty in math solving, mitigating hallucination, and image classification. Last, with the same training data, simply finetuning LVLMs improve models' performance but is still inferior to linear probing on these tasks.
MCformer: Multivariate Time Series Forecasting with Mixed-Channels Transformer
Mar 14, 2024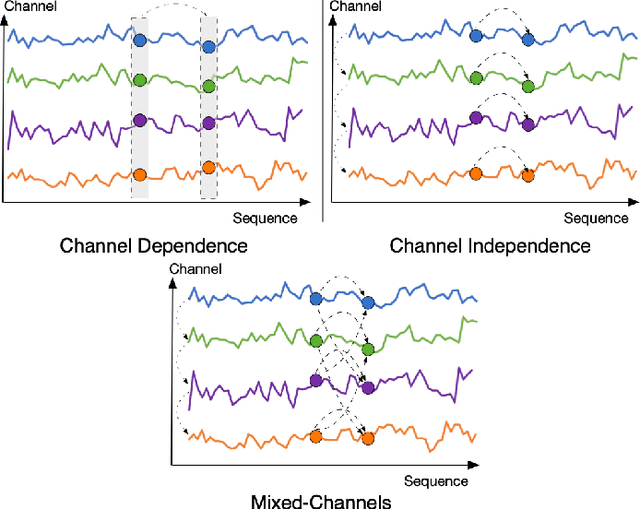

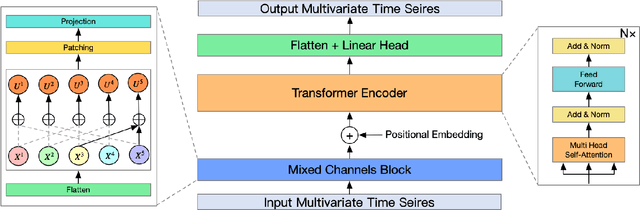

The massive generation of time-series data by largescale Internet of Things (IoT) devices necessitates the exploration of more effective models for multivariate time-series forecasting. In previous models, there was a predominant use of the Channel Dependence (CD) strategy (where each channel represents a univariate sequence). Current state-of-the-art (SOTA) models primarily rely on the Channel Independence (CI) strategy. The CI strategy treats all channels as a single channel, expanding the dataset to improve generalization performance and avoiding inter-channel correlation that disrupts long-term features. However, the CI strategy faces the challenge of interchannel correlation forgetting. To address this issue, we propose an innovative Mixed Channels strategy, combining the data expansion advantages of the CI strategy with the ability to counteract inter-channel correlation forgetting. Based on this strategy, we introduce MCformer, a multivariate time-series forecasting model with mixed channel features. The model blends a specific number of channels, leveraging an attention mechanism to effectively capture inter-channel correlation information when modeling long-term features. Experimental results demonstrate that the Mixed Channels strategy outperforms pure CI strategy in multivariate time-series forecasting tasks.
USimAgent: Large Language Models for Simulating Search Users
Mar 14, 2024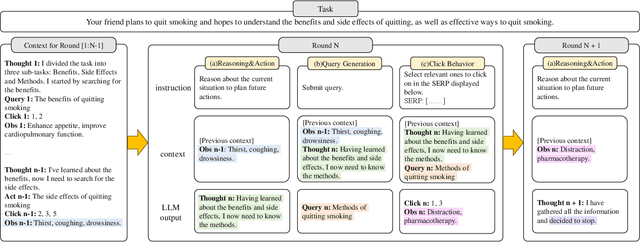

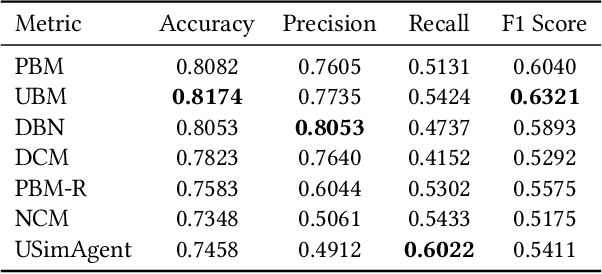
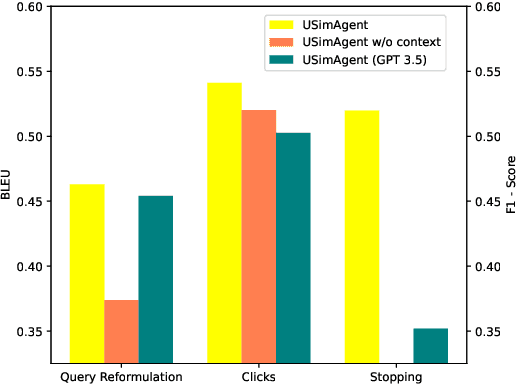
Due to the advantages in the cost-efficiency and reproducibility, user simulation has become a promising solution to the user-centric evaluation of information retrieval systems. Nonetheless, accurately simulating user search behaviors has long been a challenge, because users' actions in search are highly complex and driven by intricate cognitive processes such as learning, reasoning, and planning. Recently, Large Language Models (LLMs) have demonstrated remarked potential in simulating human-level intelligence and have been used in building autonomous agents for various tasks. However, the potential of using LLMs in simulating search behaviors has not yet been fully explored. In this paper, we introduce a LLM-based user search behavior simulator, USimAgent. The proposed simulator can simulate users' querying, clicking, and stopping behaviors during search, and thus, is capable of generating complete search sessions for specific search tasks. Empirical investigation on a real user behavior dataset shows that the proposed simulator outperforms existing methods in query generation and is comparable to traditional methods in predicting user clicks and stopping behaviors. These results not only validate the effectiveness of using LLMs for user simulation but also shed light on the development of a more robust and generic user simulators.
SHAN: Object-Level Privacy Detection via Inference on Scene Heterogeneous Graph
Mar 14, 2024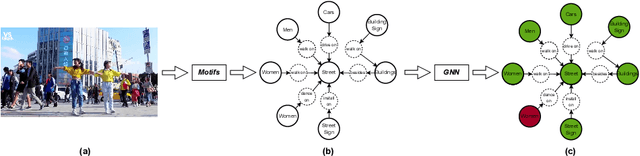
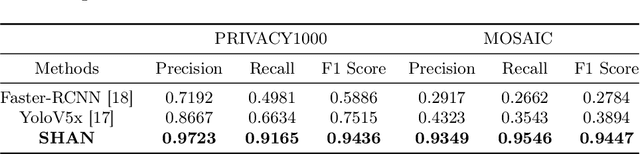

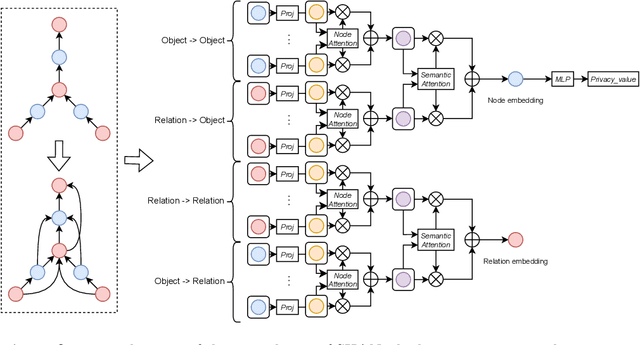
With the rise of social platforms, protecting privacy has become an important issue. Privacy object detection aims to accurately locate private objects in images. It is the foundation of safeguarding individuals' privacy rights and ensuring responsible data handling practices in the digital age. Since privacy of object is not shift-invariant, the essence of the privacy object detection task is inferring object privacy based on scene information. However, privacy object detection has long been studied as a subproblem of common object detection tasks. Therefore, existing methods suffer from serious deficiencies in accuracy, generalization, and interpretability. Moreover, creating large-scale privacy datasets is difficult due to legal constraints and existing privacy datasets lack label granularity. The granularity of existing privacy detection methods remains limited to the image level. To address the above two issues, we introduce two benchmark datasets for object-level privacy detection and propose SHAN, Scene Heterogeneous graph Attention Network, a model constructs a scene heterogeneous graph from an image and utilizes self-attention mechanisms for scene inference to obtain object privacy. Through experiments, we demonstrated that SHAN performs excellently in privacy object detection tasks, with all metrics surpassing those of the baseline model.
CLIP-BEVFormer: Enhancing Multi-View Image-Based BEV Detector with Ground Truth Flow
Mar 13, 2024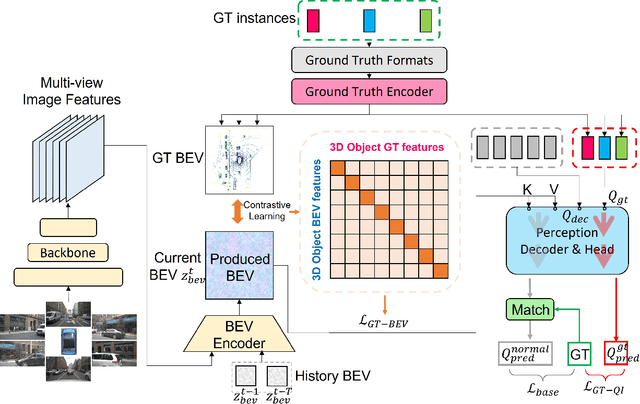
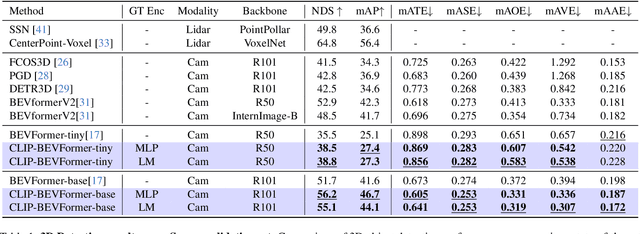
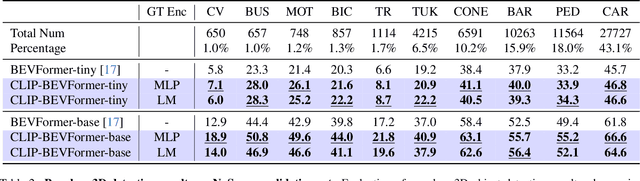

Autonomous driving stands as a pivotal domain in computer vision, shaping the future of transportation. Within this paradigm, the backbone of the system plays a crucial role in interpreting the complex environment. However, a notable challenge has been the loss of clear supervision when it comes to Bird's Eye View elements. To address this limitation, we introduce CLIP-BEVFormer, a novel approach that leverages the power of contrastive learning techniques to enhance the multi-view image-derived BEV backbones with ground truth information flow. We conduct extensive experiments on the challenging nuScenes dataset and showcase significant and consistent improvements over the SOTA. Specifically, CLIP-BEVFormer achieves an impressive 8.5\% and 9.2\% enhancement in terms of NDS and mAP, respectively, over the previous best BEV model on the 3D object detection task.
* CVPR 2024
An Analysis of Human Alignment of Latent Diffusion Models
Mar 13, 2024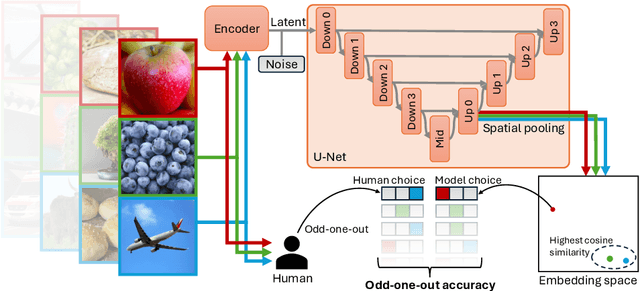
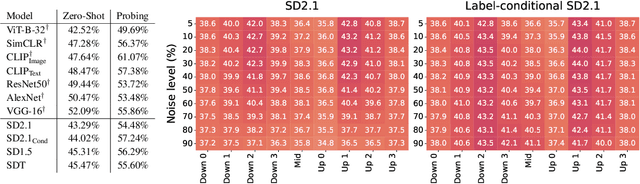
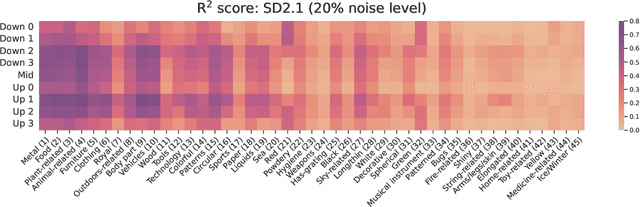
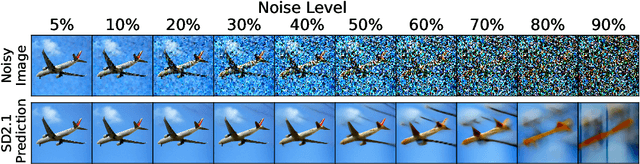
Diffusion models, trained on large amounts of data, showed remarkable performance for image synthesis. They have high error consistency with humans and low texture bias when used for classification. Furthermore, prior work demonstrated the decomposability of their bottleneck layer representations into semantic directions. In this work, we analyze how well such representations are aligned to human responses on a triplet odd-one-out task. We find that despite the aforementioned observations: I) The representational alignment with humans is comparable to that of models trained only on ImageNet-1k. II) The most aligned layers of the denoiser U-Net are intermediate layers and not the bottleneck. III) Text conditioning greatly improves alignment at high noise levels, hinting at the importance of abstract textual information, especially in the early stage of generation.