 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Generative-Contrastive Learning for Self-Supervised Latent Representations of 3D Shapes from Multi-Modal Euclidean Input
Jan 11, 2023
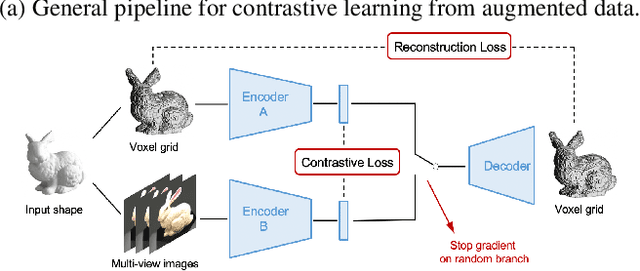
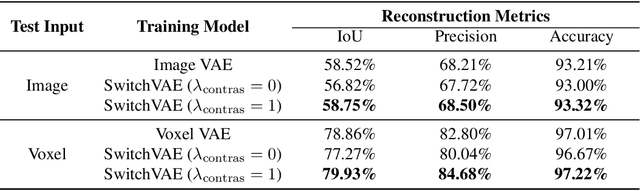
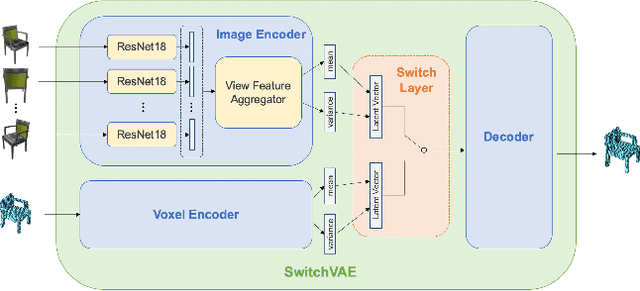
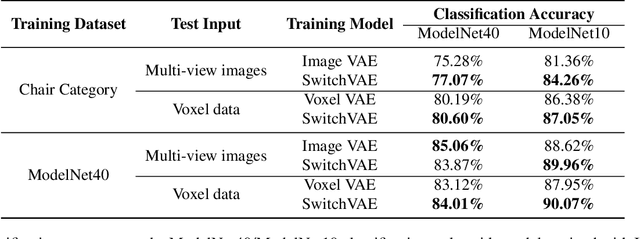
We propose a combined generative and contrastive neural architecture for learning latent representations of 3D volumetric shapes. The architecture uses two encoder branches for voxel grids and multi-view images from the same underlying shape. The main idea is to combine a contrastive loss between the resulting latent representations with an additional reconstruction loss. That helps to avoid collapsing the latent representations as a trivial solution for minimizing the contrastive loss. A novel switching scheme is used to cross-train two encoders with a shared decoder. The switching scheme also enables the stop gradient operation on a random branch. Further classification experiments show that the latent representations learned with our self-supervised method integrate more useful information from the additional input data implicitly, thus leading to better reconstruction and classification performance.
Edge-Assisted V2X Motion Planning and Power Control Under Channel Uncertainty
Dec 13, 2022
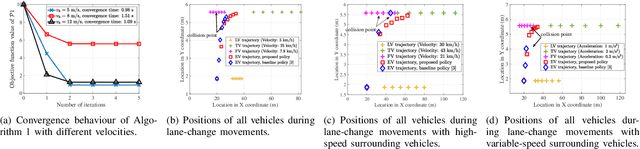
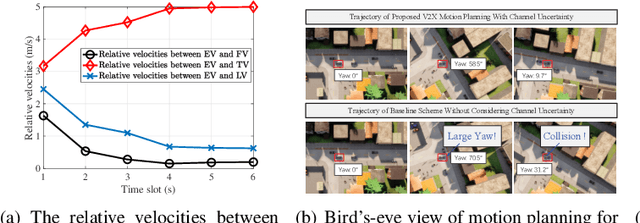

Edge-assisted vehicle-to-everything (V2X) motion planning is an emerging paradigm to achieve safe and efficient autonomous driving, since it leverages the global position information shared among multiple vehicles. However, due to the imperfect channel state information (CSI), the position information of vehicles may become outdated and inaccurate. Conventional methods ignoring the communication delays could severely jeopardize driving safety. To fill this gap, this paper proposes a robust V2X motion planning policy that adapts between competitive driving under a low communication delay and conservative driving under a high communication delay, and guarantees small communication delays at key waypoints via power control. This is achieved by integrating the vehicle mobility and communication delay models and solving a joint design of motion planning and power control problem via the block coordinate descent framework. Simulation results show that the proposed driving policy achieves the smallest collision ratio compared with other benchmark policies.
EVM-CNN: Real-Time Contactless Heart Rate Estimation from Facial Video
Dec 25, 2022
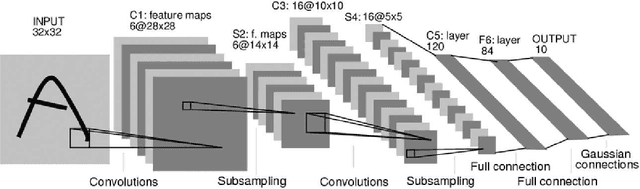
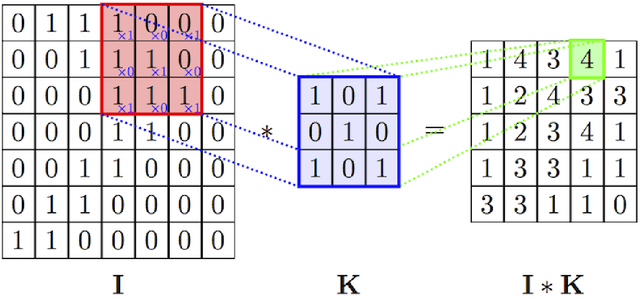
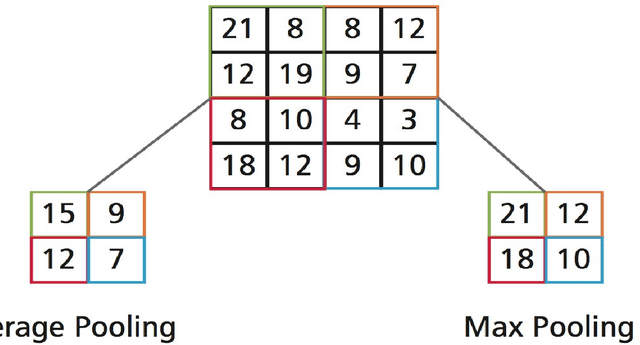
With the increase in health consciousness, noninvasive body monitoring has aroused interest among researchers. As one of the most important pieces of physiological information, researchers have remotely estimated the heart rate (HR) from facial videos in recent years. Although progress has been made over the past few years, there are still some limitations, like the processing time increasing with accuracy and the lack of comprehensive and challenging datasets for use and comparison. Recently, it was shown that HR information can be extracted from facial videos by spatial decomposition and temporal filtering. Inspired by this, a new framework is introduced in this paper to remotely estimate the HR under realistic conditions by combining spatial and temporal filtering and a convolutional neural network. Our proposed approach shows better performance compared with the benchmark on the MMSE-HR dataset in terms of both the average HR estimation and short-time HR estimation. High consistency in short-time HR estimation is observed between our method and the ground truth.
High-Order Conditional Mutual Information Maximization for dealing with High-Order Dependencies in Feature Selection
Jul 18, 2022
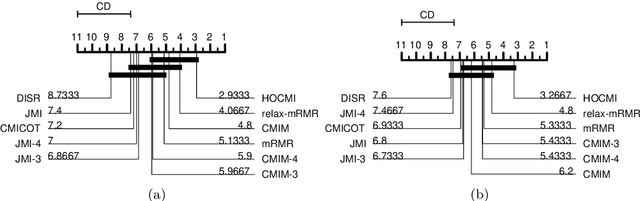
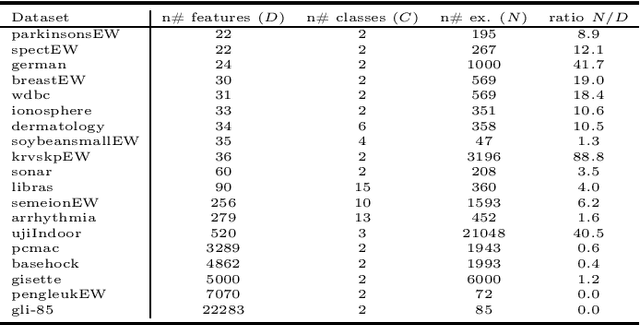
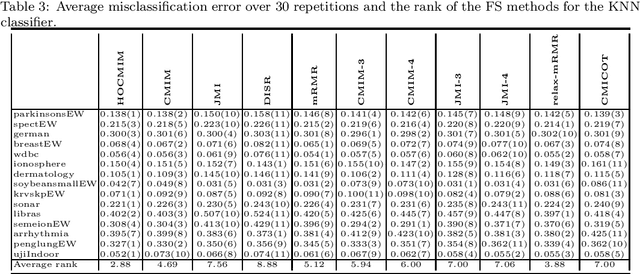
This paper presents a novel feature selection method based on the conditional mutual information (CMI). The proposed High Order Conditional Mutual Information Maximization (HOCMIM) incorporates high order dependencies into the feature selection procedure and has a straightforward interpretation due to its bottom-up derivation. The HOCMIM is derived from the CMI's chain expansion and expressed as a maximization optimization problem. The maximization problem is solved using a greedy search procedure, which speeds up the entire feature selection process. The experiments are run on a set of benchmark datasets (20 in total). The HOCMIM is compared with eighteen state-of-the-art feature selection algorithms, from the results of two supervised learning classifiers (Support Vector Machine and K-Nearest Neighbor). The HOCMIM achieves the best results in terms of accuracy and shows to be faster than high order feature selection counterparts.
A Marker-based Neural Network System for Extracting Social Determinants of Health
Dec 24, 2022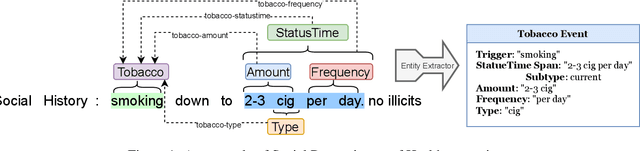
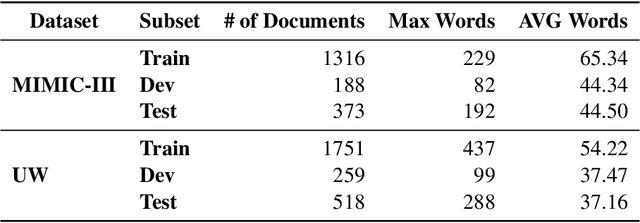
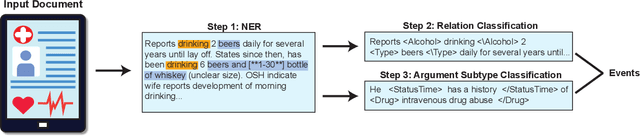
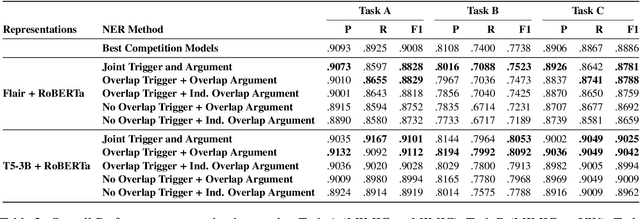
Objective. The impact of social determinants of health (SDoH) on patients' healthcare quality and the disparity is well-known. Many SDoH items are not coded in structured forms in electronic health records. These items are often captured in free-text clinical notes, but there are limited methods for automatically extracting them. We explore a multi-stage pipeline involving named entity recognition (NER), relation classification (RC), and text classification methods to extract SDoH information from clinical notes automatically. Materials and Methods. The study uses the N2C2 Shared Task data, which was collected from two sources of clinical notes: MIMIC-III and University of Washington Harborview Medical Centers. It contains 4480 social history sections with full annotation for twelve SDoHs. In order to handle the issue of overlapping entities, we developed a novel marker-based NER model. We used it in a multi-stage pipeline to extract SDoH information from clinical notes. Results. Our marker-based system outperformed the state-of-the-art span-based models at handling overlapping entities based on the overall Micro-F1 score performance. It also achieved state-of-the-art performance compared to the shared task methods. Conclusion. The major finding of this study is that the multi-stage pipeline effectively extracts SDoH information from clinical notes. This approach can potentially improve the understanding and tracking of SDoHs in clinical settings. However, error propagation may be an issue, and further research is needed to improve the extraction of entities with complex semantic meanings and low-resource entities using external knowledge.
Bidirectional Propagation for Cross-Modal 3D Object Detection
Jan 22, 2023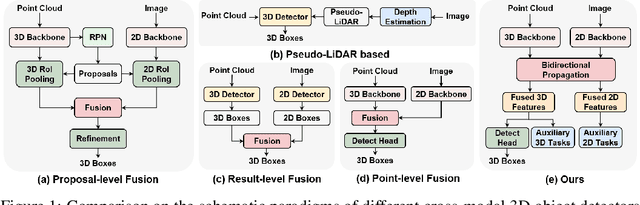
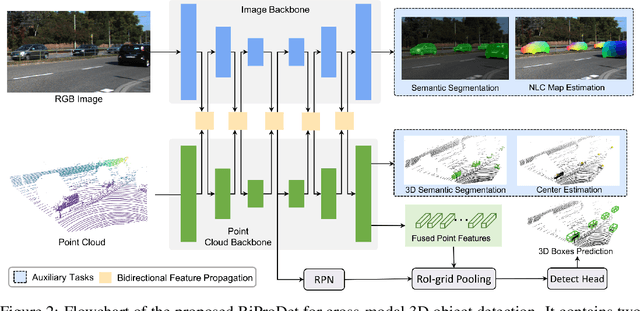
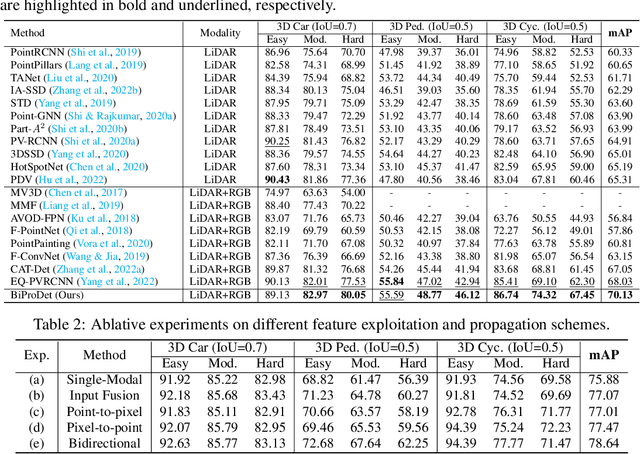
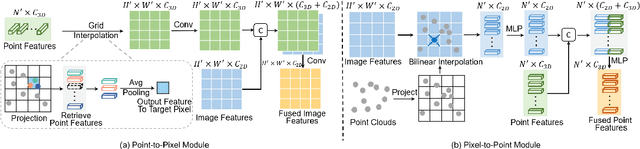
Recent works have revealed the superiority of feature-level fusion for cross-modal 3D object detection, where fine-grained feature propagation from 2D image pixels to 3D LiDAR points has been widely adopted for performance improvement. Still, the potential of heterogeneous feature propagation between 2D and 3D domains has not been fully explored. In this paper, in contrast to existing pixel-to-point feature propagation, we investigate an opposite point-to-pixel direction, allowing point-wise features to flow inversely into the 2D image branch. Thus, when jointly optimizing the 2D and 3D streams, the gradients back-propagated from the 2D image branch can boost the representation ability of the 3D backbone network working on LiDAR point clouds. Then, combining pixel-to-point and point-to-pixel information flow mechanisms, we construct an bidirectional feature propagation framework, dubbed BiProDet. In addition to the architectural design, we also propose normalized local coordinates map estimation, a new 2D auxiliary task for the training of the 2D image branch, which facilitates learning local spatial-aware features from the image modality and implicitly enhances the overall 3D detection performance. Extensive experiments and ablation studies validate the effectiveness of our method. Notably, we rank $\mathbf{1^{\mathrm{st}}}$ on the highly competitive KITTI benchmark on the cyclist class by the time of submission. The source code is available at https://github.com/Eaphan/BiProDet.
Ensemble Transfer Learning for Multilingual Coreference Resolution
Jan 22, 2023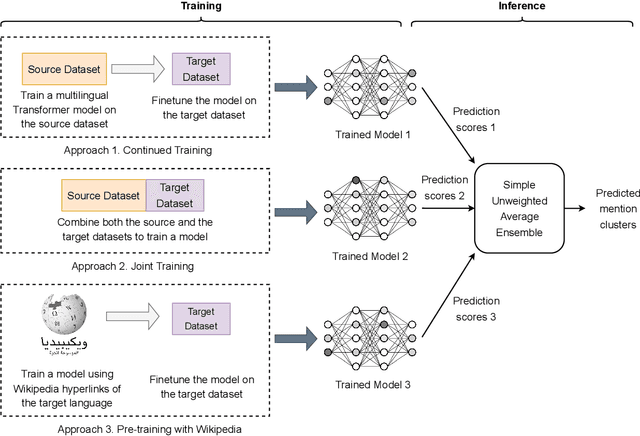
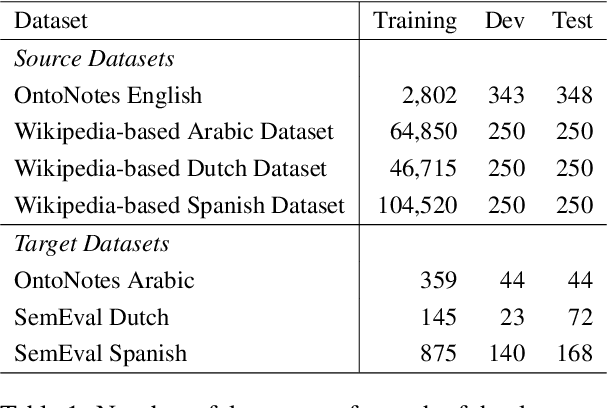
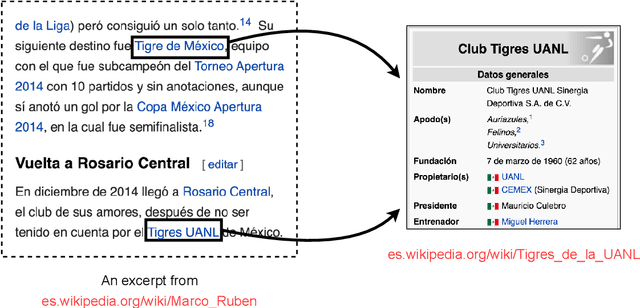
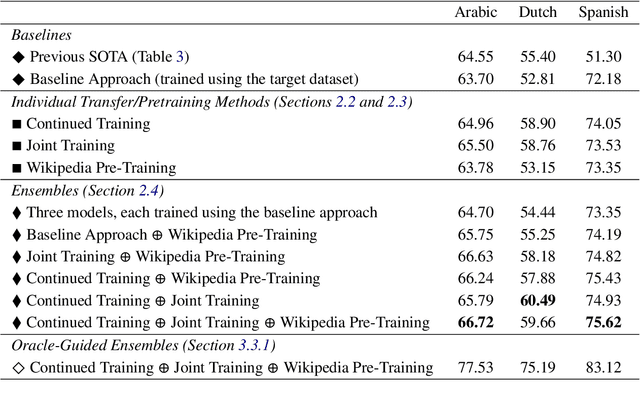
Entity coreference resolution is an important research problem with many applications, including information extraction and question answering. Coreference resolution for English has been studied extensively. However, there is relatively little work for other languages. A problem that frequently occurs when working with a non-English language is the scarcity of annotated training data. To overcome this challenge, we design a simple but effective ensemble-based framework that combines various transfer learning (TL) techniques. We first train several models using different TL methods. Then, during inference, we compute the unweighted average scores of the models' predictions to extract the final set of predicted clusters. Furthermore, we also propose a low-cost TL method that bootstraps coreference resolution models by utilizing Wikipedia anchor texts. Leveraging the idea that the coreferential links naturally exist between anchor texts pointing to the same article, our method builds a sizeable distantly-supervised dataset for the target language that consists of tens of thousands of documents. We can pre-train a model on the pseudo-labeled dataset before finetuning it on the final target dataset. Experimental results on two benchmark datasets, OntoNotes and SemEval, confirm the effectiveness of our methods. Our best ensembles consistently outperform the baseline approach of simple training by up to 7.68% in the F1 score. These ensembles also achieve new state-of-the-art results for three languages: Arabic, Dutch, and Spanish.
Search-Based Task and Motion Planning for Hybrid Systems: Agile Autonomous Vehicles
Jan 25, 2023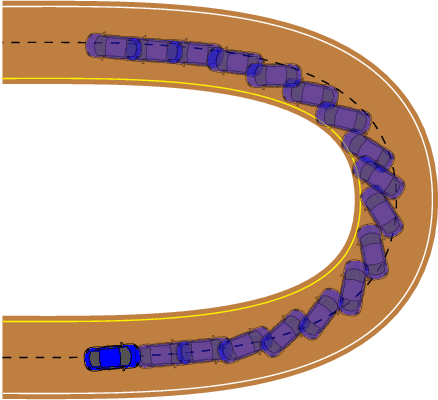
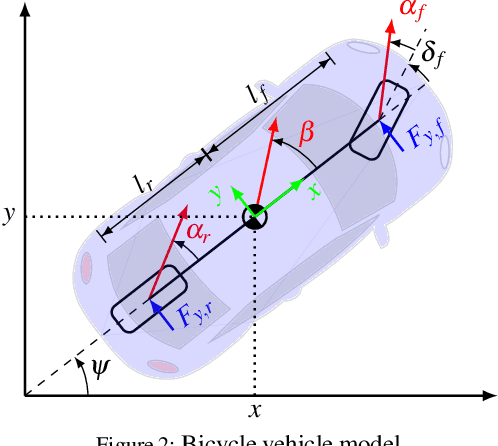
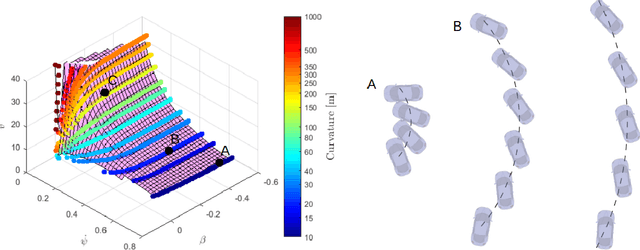
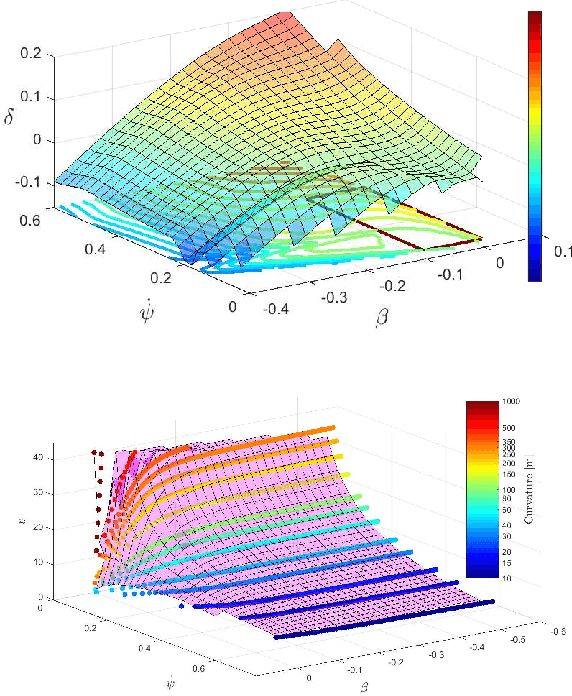
To achieve optimal robot behavior in dynamic scenarios we need to consider complex dynamics in a predictive manner. In the vehicle dynamics community, it is well know that to achieve time-optimal driving on low surface, the vehicle should utilize drifting. Hence many authors have devised rules to split circuits and employ drifting on some segments. These rules are suboptimal and do not generalize to arbitrary circuit shapes (e.g., S-like curves). So, the question "When to go into which mode and how to drive in it?" remains unanswered. To choose the suitable mode (discrete decision), the algorithm needs information about the feasibility of the continuous motion in that mode. This makes it a class of Task and Motion Planning (TAMP) problems, which are known to be hard to solve optimally in real-time. In the AI planning community, search methods are commonly used. However, they cannot be directly applied to TAMP problems due to the continuous component. Here, we present a search-based method that effectively solves this problem and efficiently searches in a highly dimensional state space with nonlinear and unstable dynamics. The space of the possible trajectories is explored by sampling different combinations of motion primitives guided by the search. Our approach allows to use multiple locally approximated models to generate motion primitives (e.g., learned models of drifting) and effectively simplify the problem without losing accuracy. The algorithm performance is evaluated in simulated driving on a mixed-track with segments of different curvatures (right and left). Our code is available at https://git.io/JenvB
Enriching Relation Extraction with OpenIE
Dec 19, 2022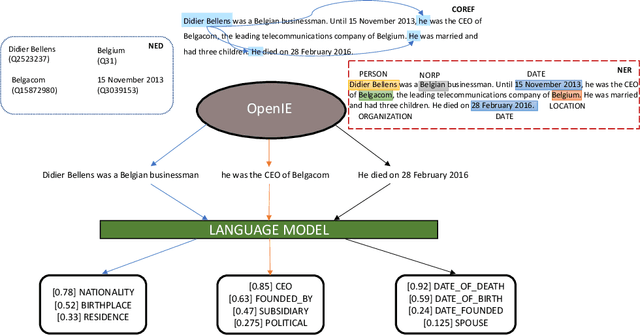
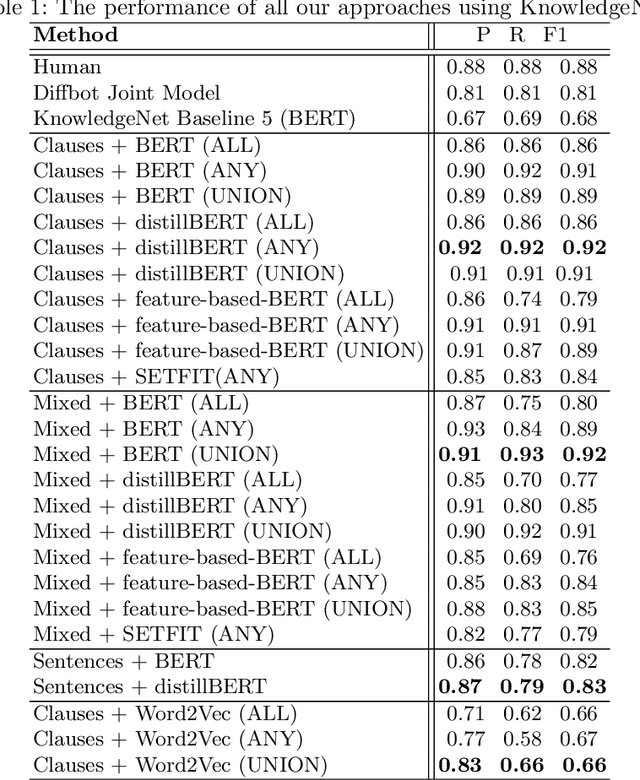
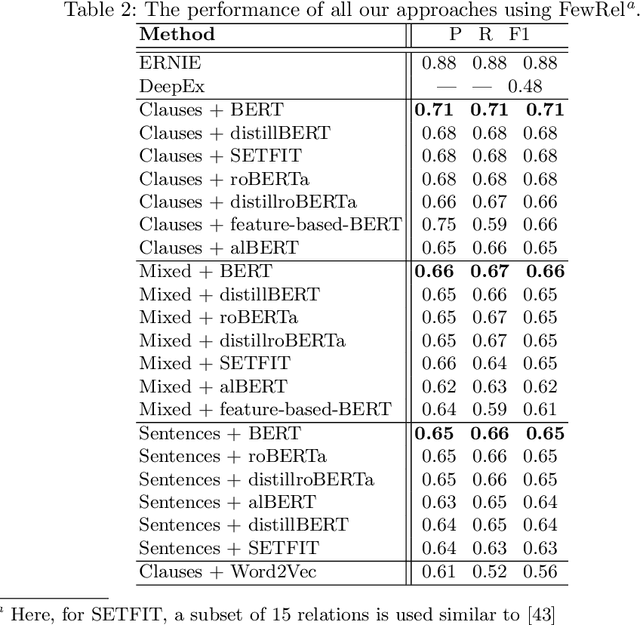
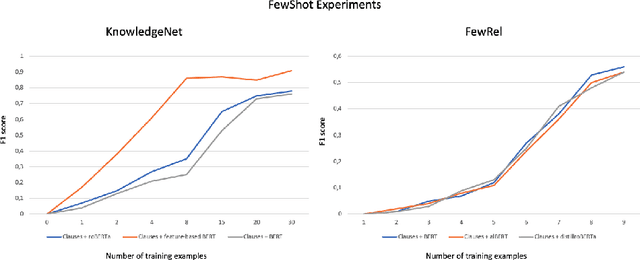
Relation extraction (RE) is a sub-discipline of information extraction (IE) which focuses on the prediction of a relational predicate from a natural-language input unit (such as a sentence, a clause, or even a short paragraph consisting of multiple sentences and/or clauses). Together with named-entity recognition (NER) and disambiguation (NED), RE forms the basis for many advanced IE tasks such as knowledge-base (KB) population and verification. In this work, we explore how recent approaches for open information extraction (OpenIE) may help to improve the task of RE by encoding structured information about the sentences' principal units, such as subjects, objects, verbal phrases, and adverbials, into various forms of vectorized (and hence unstructured) representations of the sentences. Our main conjecture is that the decomposition of long and possibly convoluted sentences into multiple smaller clauses via OpenIE even helps to fine-tune context-sensitive language models such as BERT (and its plethora of variants) for RE. Our experiments over two annotated corpora, KnowledgeNet and FewRel, demonstrate the improved accuracy of our enriched models compared to existing RE approaches. Our best results reach 92% and 71% of F1 score for KnowledgeNet and FewRel, respectively, proving the effectiveness of our approach on competitive benchmarks.
Penalised regression with multiple sources of prior effects
Dec 16, 2022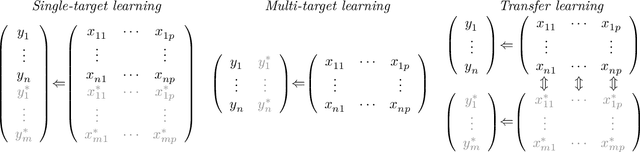
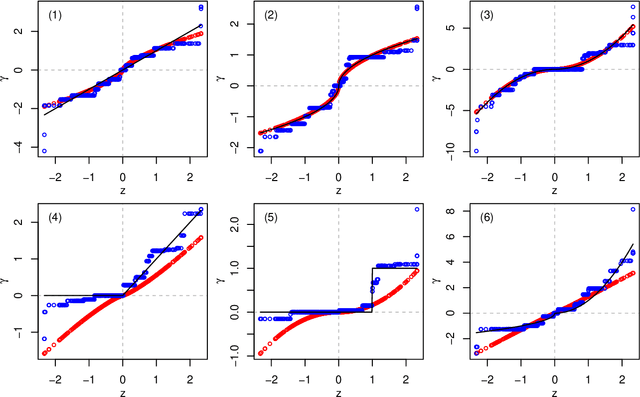
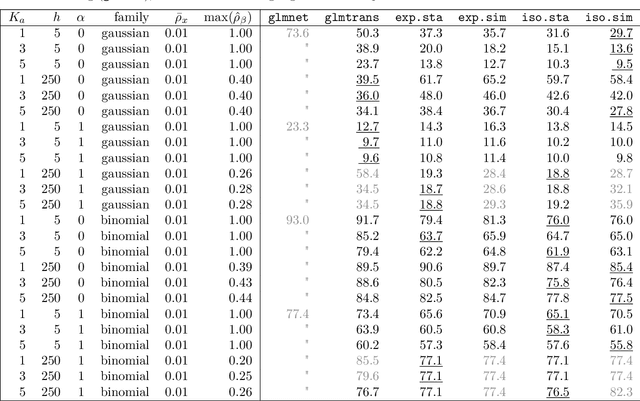
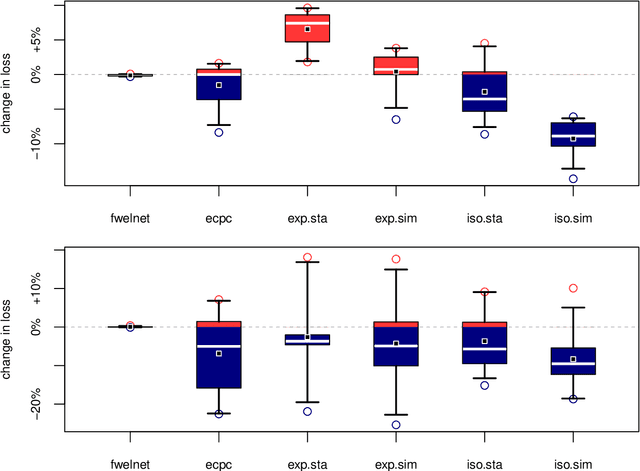
In many high-dimensional prediction or classification tasks, complementary data on the features are available, e.g. prior biological knowledge on (epi)genetic markers. Here we consider tasks with numerical prior information that provide an insight into the importance (weight) and the direction (sign) of the feature effects, e.g. regression coefficients from previous studies. We propose an approach for integrating multiple sources of such prior information into penalised regression. If suitable co-data are available, this improves the predictive performance, as shown by simulation and application. The proposed method is implemented in the R package `transreg' (https://github.com/lcsb-bds/transreg).