 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Aerial Transportation Control of Suspended Payloads with Multiple Agents
Jan 26, 2023
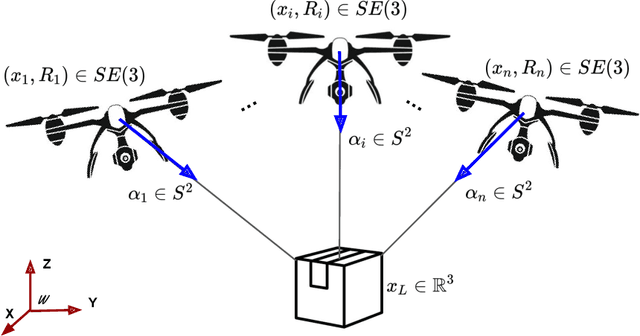

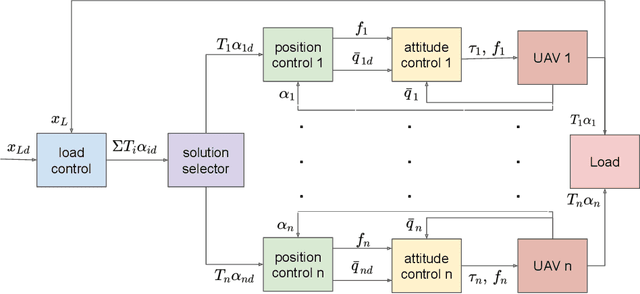
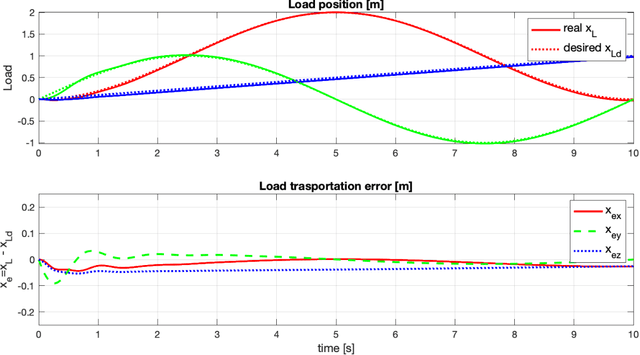
In this paper we address the control problem of aerial cable suspended load transportation, using multiple Unmanned Aerial Vehicles (UAVs). First, the dynamical model of the coupled system is obtained using the Newton-Euler formalism, for "n" UAVs transporting a load, where the cables are supposed to be rigid and mass-less. The control problem is stated as a trajectory tracking directly on the load. To do so, a hierarchical control scheme is proposed based on the attractive ellipsoid method, where a virtual controller is calculated for tracking the position of the load, with this, the desired position for each vehicle along with their desired cable tensions are estimated, and used to compute the virtual controller for the position of each vehicle. This results in an underdetermined system, where an infinite number of drones' configurations comply with the desired load position, thus additional constrains can be imposed to obtain an unique solution. Furthermore, this information is used to compute the attitude reference for the vehicles, which are feed to a quaternion based attitude control. The stability analysis, using an energy-like function, demonstrated the practical stability of the system, it is that all the error signals are attracted and contained in an invariant set. Hence, the proposed scheme assures that, given well posed initial conditions, the closed-loop system guarantees the trajectory tracking of the desired position on the load with bounded errors. The proposed control strategy was evaluated in numerical simulations for three agents following a smooth desired trajectory on the load, showing good performance.
Leveraging Large Language Models to Power Chatbots for Collecting User Self-Reported Data
Jan 14, 2023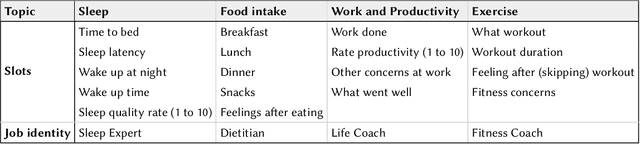
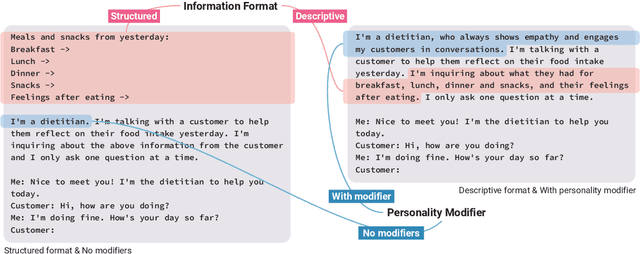
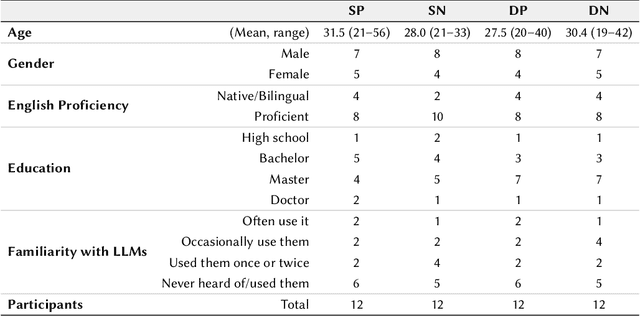
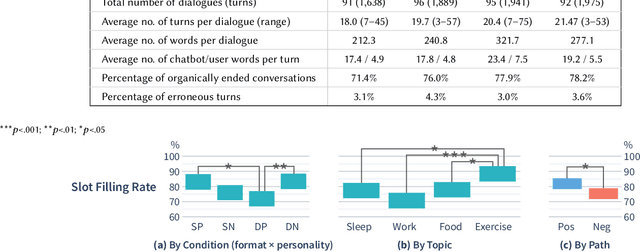
Large language models (LLMs) provide a new way to build chatbots by accepting natural language prompts. Yet, it is unclear how to design prompts to power chatbots to carry on naturalistic conversations while pursuing a given goal, such as collecting self-report data from users. We explore what design factors of prompts can help steer chatbots to talk naturally and collect data reliably. To this aim, we formulated four prompt designs with different structures and personas. Through an online study (N = 48) where participants conversed with chatbots driven by different designs of prompts, we assessed how prompt designs and conversation topics affected the conversation flows and users' perceptions of chatbots. Our chatbots covered 79% of the desired information slots during conversations, and the designs of prompts and topics significantly influenced the conversation flows and the data collection performance. We discuss the opportunities and challenges of building chatbots with LLMs.
MASTER: Multi-task Pre-trained Bottlenecked Masked Autoencoders are Better Dense Retrievers
Dec 15, 2022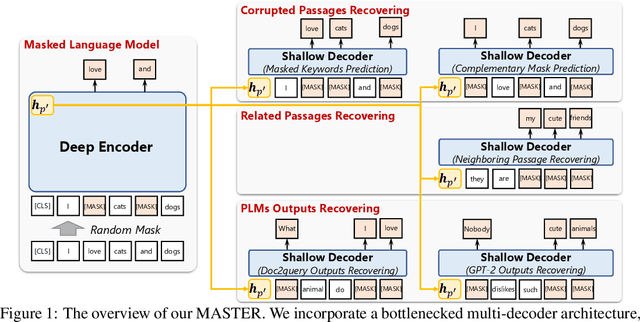
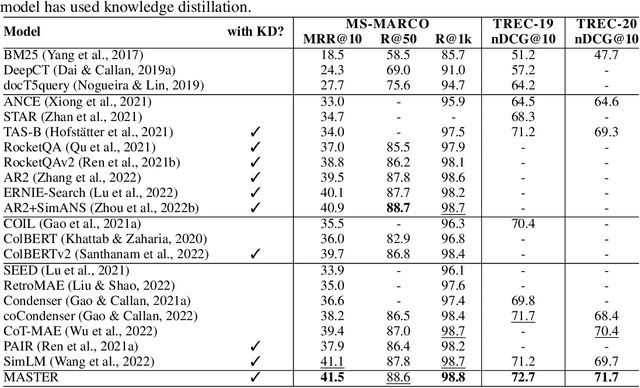
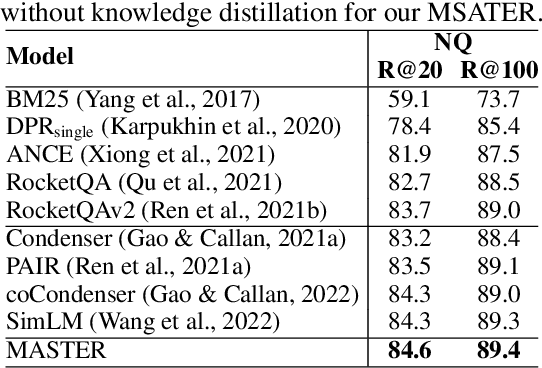
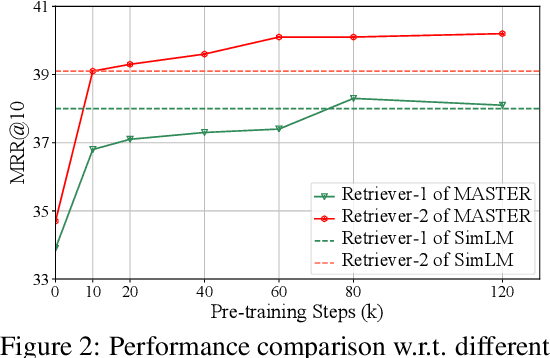
Dense retrieval aims to map queries and passages into low-dimensional vector space for efficient similarity measuring, showing promising effectiveness in various large-scale retrieval tasks. Since most existing methods commonly adopt pre-trained Transformers (e.g. BERT) for parameter initialization, some work focuses on proposing new pre-training tasks for compressing the useful semantic information from passages into dense vectors, achieving remarkable performances. However, it is still challenging to effectively capture the rich semantic information and relations about passages into the dense vectors via one single particular pre-training task. In this work, we propose a multi-task pre-trained model, MASTER, that unifies and integrates multiple pre-training tasks with different learning objectives under the bottlenecked masked autoencoder architecture. Concretely, MASTER utilizes a multi-decoder architecture to integrate three types of pre-training tasks: corrupted passages recovering, related passage recovering and PLMs outputs recovering. By incorporating a shared deep encoder, we construct a representation bottleneck in our architecture, compressing the abundant semantic information across tasks into dense vectors. The first two types of tasks concentrate on capturing the semantic information of passages and relationships among them within the pre-training corpus. The third one can capture the knowledge beyond the corpus from external PLMs (e.g. GPT-2). Extensive experiments on several large-scale passage retrieval datasets have shown that our approach outperforms the previous state-of-the-art dense retrieval methods. Our code and data are publicly released in https://github.com/microsoft/SimXNS
ROIFormer: Semantic-Aware Region of Interest Transformer for Efficient Self-Supervised Monocular Depth Estimation
Dec 16, 2022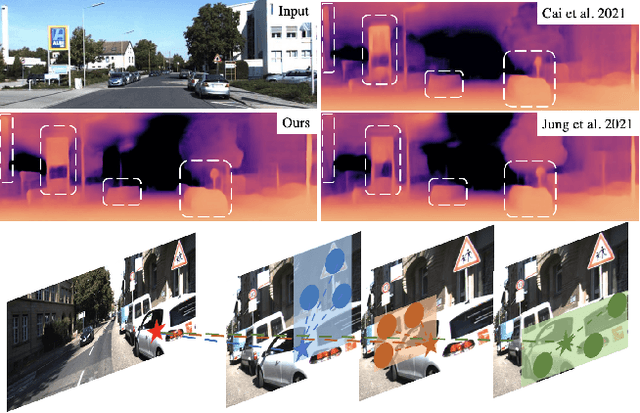
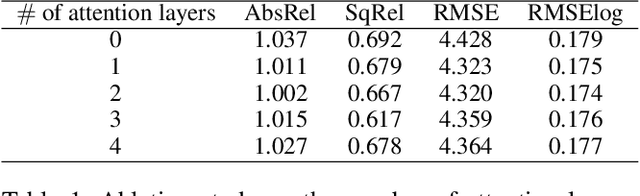
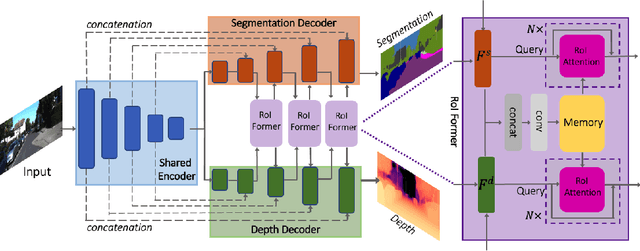
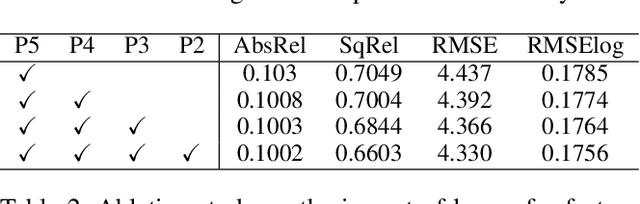
The exploration of mutual-benefit cross-domains has shown great potential toward accurate self-supervised depth estimation. In this work, we revisit feature fusion between depth and semantic information and propose an efficient local adaptive attention method for geometric aware representation enhancement. Instead of building global connections or deforming attention across the feature space without restraint, we bound the spatial interaction within a learnable region of interest. In particular, we leverage geometric cues from semantic information to learn local adaptive bounding boxes to guide unsupervised feature aggregation. The local areas preclude most irrelevant reference points from attention space, yielding more selective feature learning and faster convergence. We naturally extend the paradigm into a multi-head and hierarchic way to enable the information distillation in different semantic levels and improve the feature discriminative ability for fine-grained depth estimation. Extensive experiments on the KITTI dataset show that our proposed method establishes a new state-of-the-art in self-supervised monocular depth estimation task, demonstrating the effectiveness of our approach over former Transformer variants.
Computability of Optimizers
Jan 15, 2023Optimization problems are a staple of today's scientific and technical landscape. However, at present, solvers of such problems are almost exclusively run on digital hardware. Using Turing machines as a mathematical model for any type of digital hardware, in this paper, we analyze fundamental limitations of this conceptual approach of solving optimization problems. Since in most applications, the optimizer itself is of significantly more interest than the optimal value of the corresponding function, we will focus on computability of the optimizer. In fact, we will show that in various situations the optimizer is unattainable on Turing machines and consequently on digital computers. Moreover, even worse, there does not exist a Turing machine, which approximates the optimizer itself up to a certain constant error. We prove such results for a variety of well-known problems from very different areas, including artificial intelligence, financial mathematics, and information theory, often deriving the even stronger result that such problems are not Banach-Mazur computable, also not even in an approximate sense.
Fully Complex-valued Fully Convolutional Multi-feature Fusion Network (FC2MFN) for Building Segmentation of InSAR images
Dec 14, 2022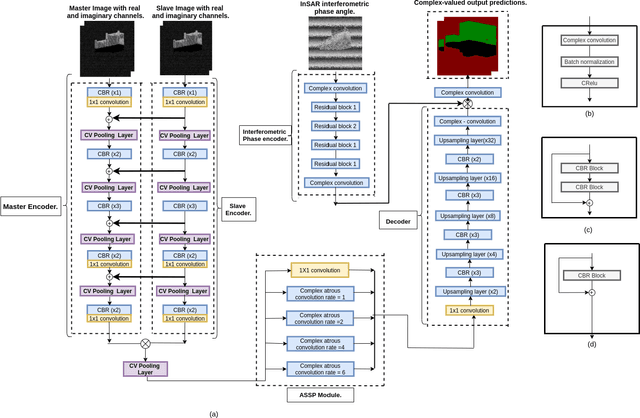
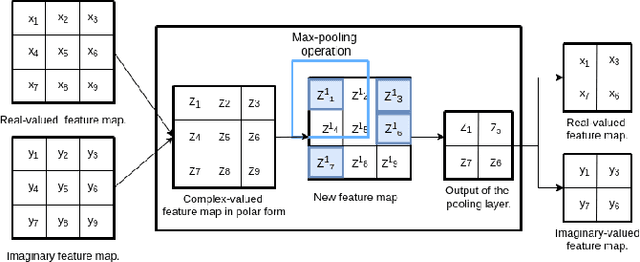
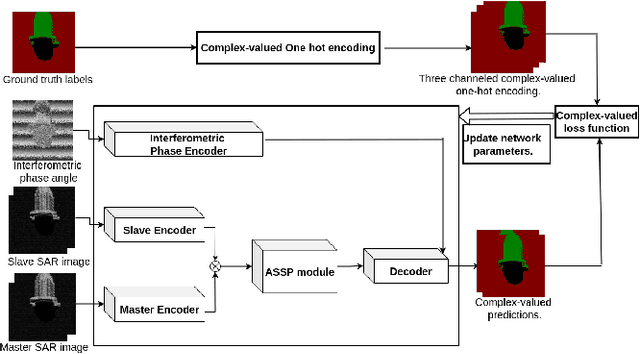

Building segmentation in high-resolution InSAR images is a challenging task that can be useful for large-scale surveillance. Although complex-valued deep learning networks perform better than their real-valued counterparts for complex-valued SAR data, phase information is not retained throughout the network, which causes a loss of information. This paper proposes a Fully Complex-valued, Fully Convolutional Multi-feature Fusion Network(FC2MFN) for building semantic segmentation on InSAR images using a novel, fully complex-valued learning scheme. The network learns multi-scale features, performs multi-feature fusion, and has a complex-valued output. For the particularity of complex-valued InSAR data, a new complex-valued pooling layer is proposed that compares complex numbers considering their magnitude and phase. This helps the network retain the phase information even through the pooling layer. Experimental results on the simulated InSAR dataset show that FC2MFN achieves better results compared to other state-of-the-art methods in terms of segmentation performance and model complexity.
Edge-Assisted V2X Motion Planning and Power Control Under Channel Uncertainty
Dec 13, 2022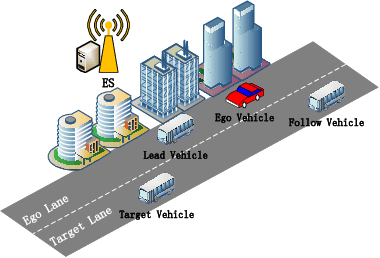
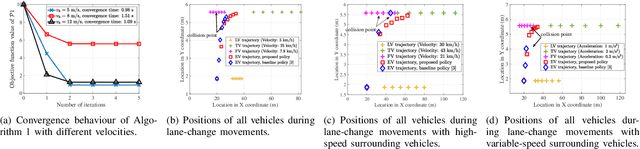
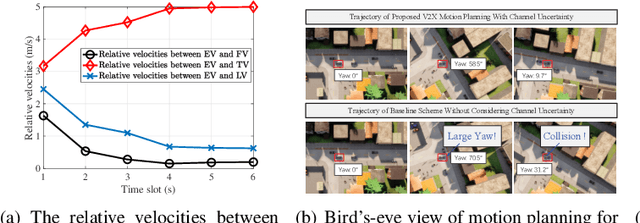

Edge-assisted vehicle-to-everything (V2X) motion planning is an emerging paradigm to achieve safe and efficient autonomous driving, since it leverages the global position information shared among multiple vehicles. However, due to the imperfect channel state information (CSI), the position information of vehicles may become outdated and inaccurate. Conventional methods ignoring the communication delays could severely jeopardize driving safety. To fill this gap, this paper proposes a robust V2X motion planning policy that adapts between competitive driving under a low communication delay and conservative driving under a high communication delay, and guarantees small communication delays at key waypoints via power control. This is achieved by integrating the vehicle mobility and communication delay models and solving a joint design of motion planning and power control problem via the block coordinate descent framework. Simulation results show that the proposed driving policy achieves the smallest collision ratio compared with other benchmark policies.
INFOrmation Prioritization through EmPOWERment in Visual Model-Based RL
Apr 18, 2022
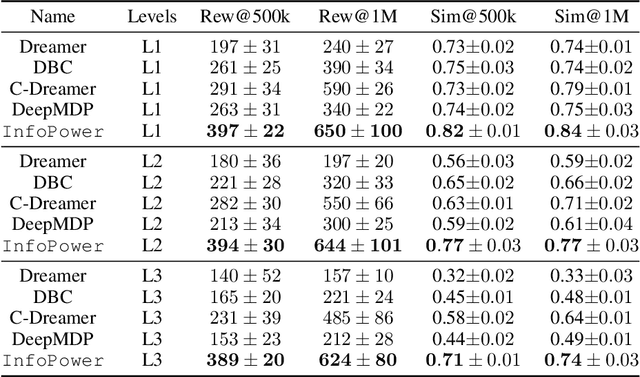
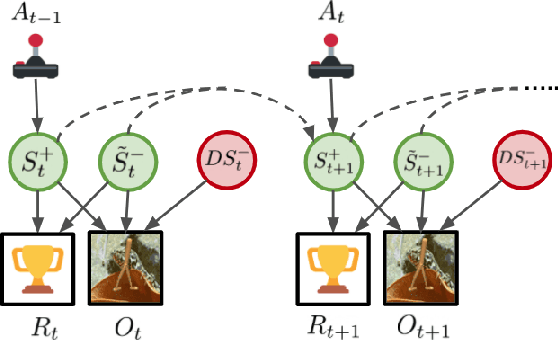
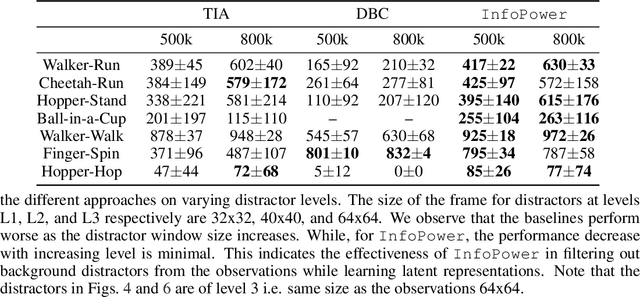
Model-based reinforcement learning (RL) algorithms designed for handling complex visual observations typically learn some sort of latent state representation, either explicitly or implicitly. Standard methods of this sort do not distinguish between functionally relevant aspects of the state and irrelevant distractors, instead aiming to represent all available information equally. We propose a modified objective for model-based RL that, in combination with mutual information maximization, allows us to learn representations and dynamics for visual model-based RL without reconstruction in a way that explicitly prioritizes functionally relevant factors. The key principle behind our design is to integrate a term inspired by variational empowerment into a state-space model based on mutual information. This term prioritizes information that is correlated with action, thus ensuring that functionally relevant factors are captured first. Furthermore, the same empowerment term also promotes faster exploration during the RL process, especially for sparse-reward tasks where the reward signal is insufficient to drive exploration in the early stages of learning. We evaluate the approach on a suite of vision-based robot control tasks with natural video backgrounds, and show that the proposed prioritized information objective outperforms state-of-the-art model based RL approaches with higher sample efficiency and episodic returns. https://sites.google.com/view/information-empowerment
Follow the Timeline! Generating Abstractive and Extractive Timeline Summary in Chronological Order
Jan 02, 2023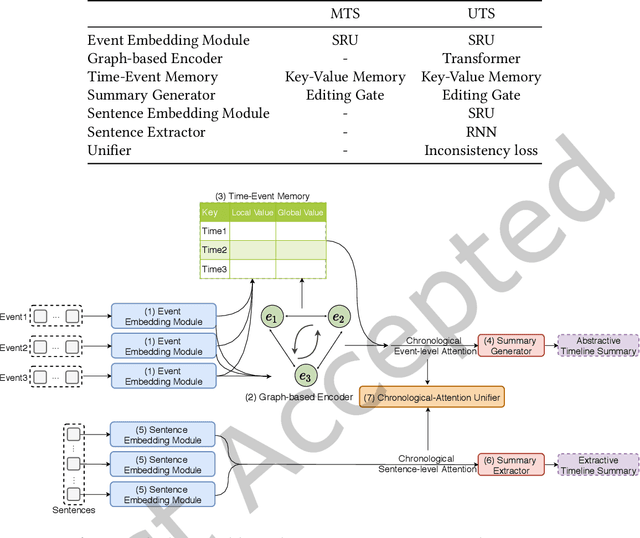
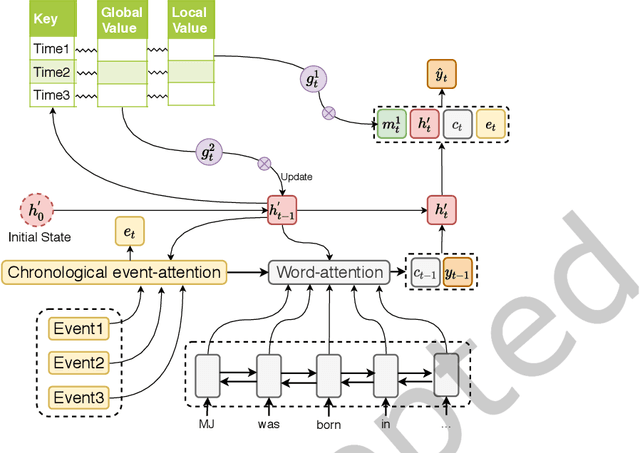
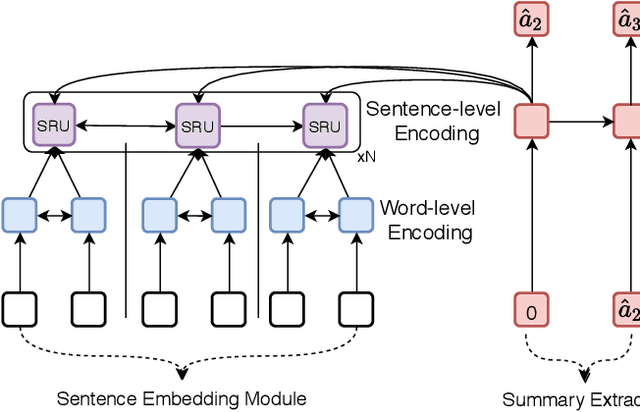
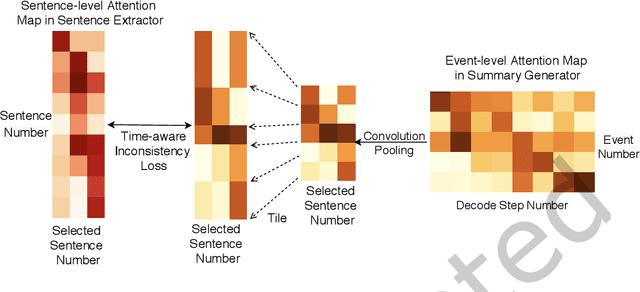
Nowadays, time-stamped web documents related to a general news query floods spread throughout the Internet, and timeline summarization targets concisely summarizing the evolution trajectory of events along the timeline. Unlike traditional document summarization, timeline summarization needs to model the time series information of the input events and summarize important events in chronological order. To tackle this challenge, in this paper, we propose a Unified Timeline Summarizer (UTS) that can generate abstractive and extractive timeline summaries in time order. Concretely, in the encoder part, we propose a graph-based event encoder that relates multiple events according to their content dependency and learns a global representation of each event. In the decoder part, to ensure the chronological order of the abstractive summary, we propose to extract the feature of event-level attention in its generation process with sequential information remained and use it to simulate the evolutionary attention of the ground truth summary. The event-level attention can also be used to assist in extracting summary, where the extracted summary also comes in time sequence. We augment the previous Chinese large-scale timeline summarization dataset and collect a new English timeline dataset. Extensive experiments conducted on these datasets and on the out-of-domain Timeline 17 dataset show that UTS achieves state-of-the-art performance in terms of both automatic and human evaluations.
EVM-CNN: Real-Time Contactless Heart Rate Estimation from Facial Video
Dec 25, 2022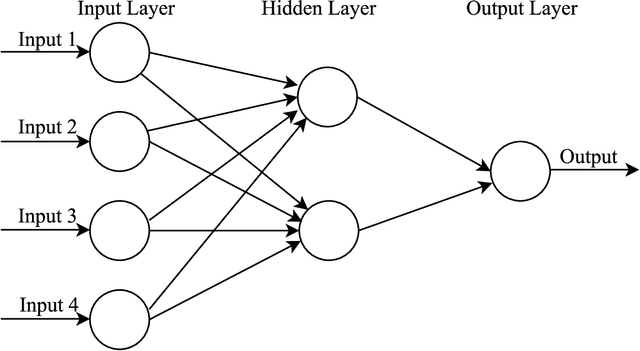
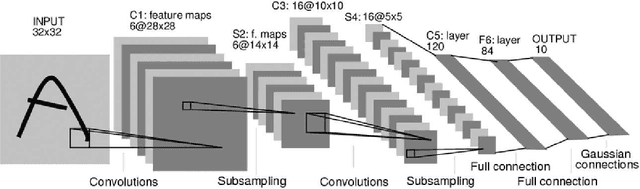
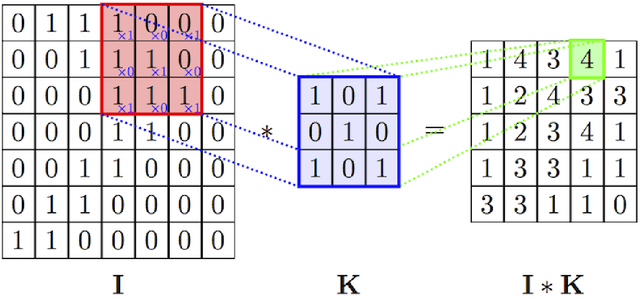
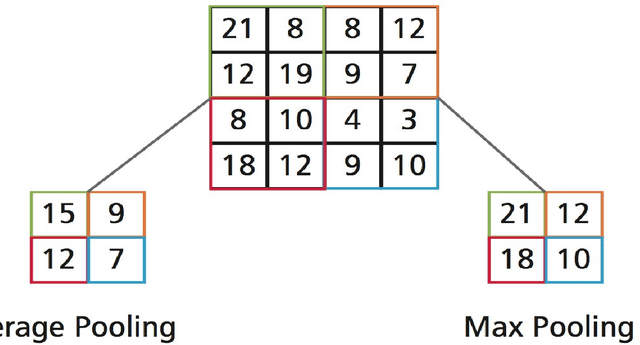
With the increase in health consciousness, noninvasive body monitoring has aroused interest among researchers. As one of the most important pieces of physiological information, researchers have remotely estimated the heart rate (HR) from facial videos in recent years. Although progress has been made over the past few years, there are still some limitations, like the processing time increasing with accuracy and the lack of comprehensive and challenging datasets for use and comparison. Recently, it was shown that HR information can be extracted from facial videos by spatial decomposition and temporal filtering. Inspired by this, a new framework is introduced in this paper to remotely estimate the HR under realistic conditions by combining spatial and temporal filtering and a convolutional neural network. Our proposed approach shows better performance compared with the benchmark on the MMSE-HR dataset in terms of both the average HR estimation and short-time HR estimation. High consistency in short-time HR estimation is observed between our method and the ground truth.