 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Removing Non-Stationary Knowledge From Pre-Trained Language Models for Entity-Level Sentiment Classification in Finance
Jan 25, 2023
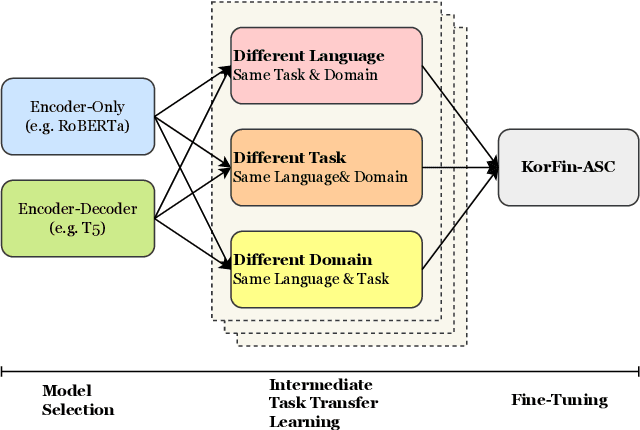

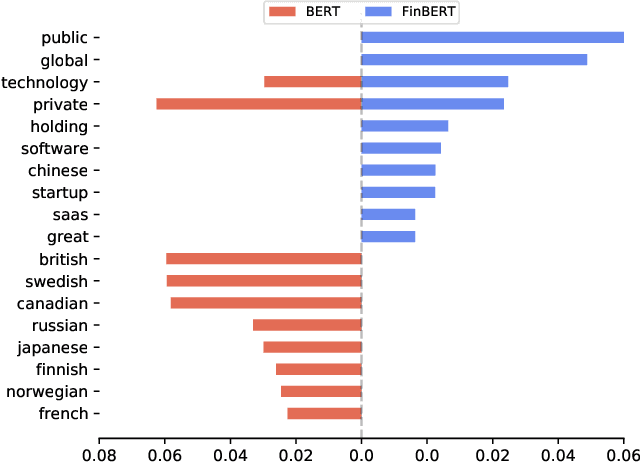
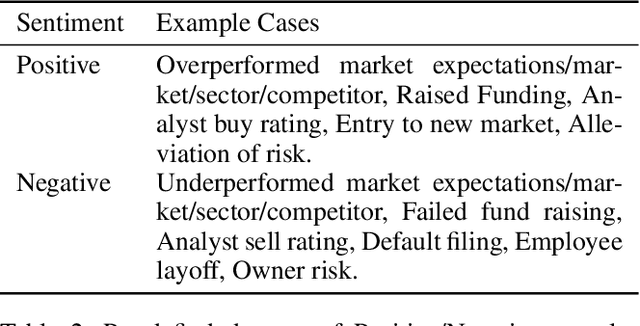
Extraction of sentiment signals from news text, stock message boards, and business reports, for stock movement prediction, has been a rising field of interest in finance. Building upon past literature, the most recent works attempt to better capture sentiment from sentences with complex syntactic structures by introducing aspect-level sentiment classification (ASC). Despite the growing interest, however, fine-grained sentiment analysis has not been fully explored in non-English literature due to the shortage of annotated finance-specific data. Accordingly, it is necessary for non-English languages to leverage datasets and pre-trained language models (PLM) of different domains, languages, and tasks to best their performance. To facilitate finance-specific ASC research in the Korean language, we build KorFinASC, a Korean aspect-level sentiment classification dataset for finance consisting of 12,613 human-annotated samples, and explore methods of intermediate transfer learning. Our experiments indicate that past research has been ignorant towards the potentially wrong knowledge of financial entities encoded during the training phase, which has overestimated the predictive power of PLMs. In our work, we use the term "non-stationary knowledge'' to refer to information that was previously correct but is likely to change, and present "TGT-Masking'', a novel masking pattern to restrict PLMs from speculating knowledge of the kind. Finally, through a series of transfer learning with TGT-Masking applied we improve 22.63% of classification accuracy compared to standalone models on KorFinASC.
The Linear Capacity of Single-Server Individually-Private Information Retrieval with Side Information
Feb 24, 2022This paper considers the problem of single-server Individually-Private Information Retrieval with side information (IPIR). In this problem, there is a remote server that stores a dataset of $K$ messages, and there is a user that initially knows $M$ of these messages, and wants to retrieve $D$ other messages belonging to the dataset. The goal of the user is to retrieve the $D$ desired messages by downloading the minimum amount of information from the server while revealing no information about whether an individual message is one of the $D$ desired messages. In this work, we focus on linear IPIR schemes, i.e., the IPIR schemes in which the user downloads only linear combinations of the original messages from the server. We prove a converse bound on the download rate of any linear IPIR scheme for all $K,D,M$, and show the achievability of this bound for all $K,D,M$ satisfying a certain divisibility condition. Our results characterize the linear capacity of IPIR, which is defined as the maximum achievable download rate over all linear IPIR schemes, for a wide range of values of $K,D,M$.
Learning Transformations To Reduce the Geometric Shift in Object Detection
Jan 13, 2023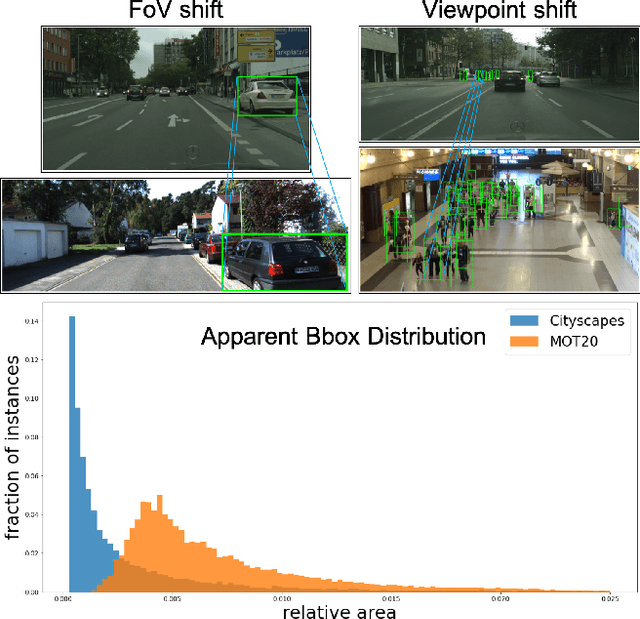
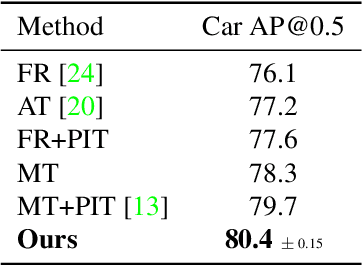


The performance of modern object detectors drops when the test distribution differs from the training one. Most of the methods that address this focus on object appearance changes caused by, e.g., different illumination conditions, or gaps between synthetic and real images. Here, by contrast, we tackle geometric shifts emerging from variations in the image capture process, or due to the constraints of the environment causing differences in the apparent geometry of the content itself. We introduce a self-training approach that learns a set of geometric transformations to minimize these shifts without leveraging any labeled data in the new domain, nor any information about the cameras. We evaluate our method on two different shifts, i.e., a camera's field of view (FoV) change and a viewpoint change. Our results evidence that learning geometric transformations helps detectors to perform better in the target domains.
MASTER: Multi-task Pre-trained Bottlenecked Masked Autoencoders are Better Dense Retrievers
Dec 15, 2022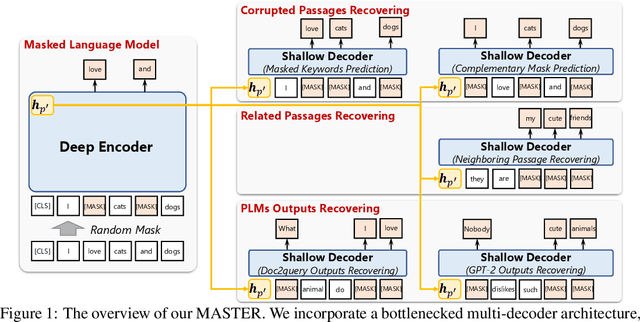
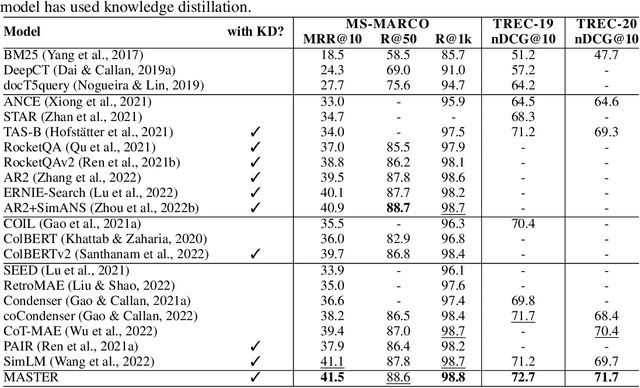
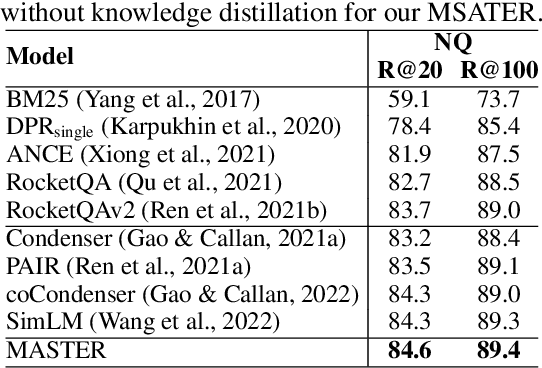
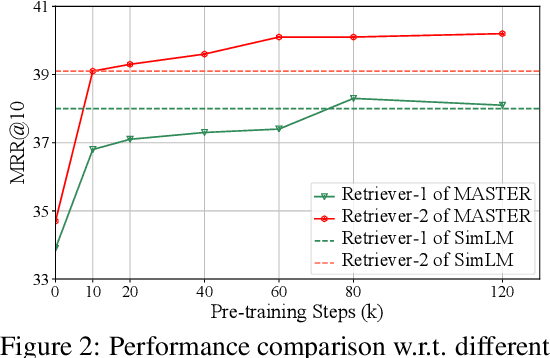
Dense retrieval aims to map queries and passages into low-dimensional vector space for efficient similarity measuring, showing promising effectiveness in various large-scale retrieval tasks. Since most existing methods commonly adopt pre-trained Transformers (e.g. BERT) for parameter initialization, some work focuses on proposing new pre-training tasks for compressing the useful semantic information from passages into dense vectors, achieving remarkable performances. However, it is still challenging to effectively capture the rich semantic information and relations about passages into the dense vectors via one single particular pre-training task. In this work, we propose a multi-task pre-trained model, MASTER, that unifies and integrates multiple pre-training tasks with different learning objectives under the bottlenecked masked autoencoder architecture. Concretely, MASTER utilizes a multi-decoder architecture to integrate three types of pre-training tasks: corrupted passages recovering, related passage recovering and PLMs outputs recovering. By incorporating a shared deep encoder, we construct a representation bottleneck in our architecture, compressing the abundant semantic information across tasks into dense vectors. The first two types of tasks concentrate on capturing the semantic information of passages and relationships among them within the pre-training corpus. The third one can capture the knowledge beyond the corpus from external PLMs (e.g. GPT-2). Extensive experiments on several large-scale passage retrieval datasets have shown that our approach outperforms the previous state-of-the-art dense retrieval methods. Our code and data are publicly released in https://github.com/microsoft/SimXNS
ROIFormer: Semantic-Aware Region of Interest Transformer for Efficient Self-Supervised Monocular Depth Estimation
Dec 16, 2022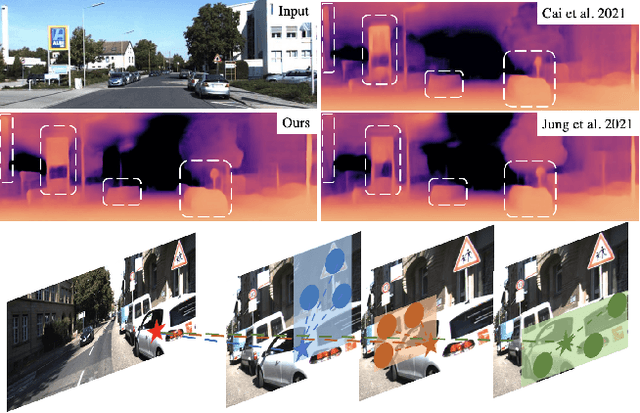
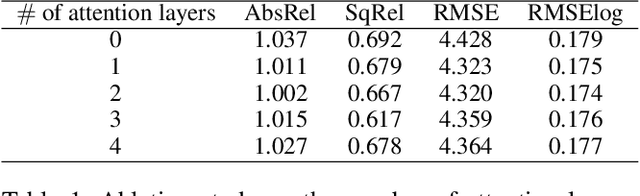
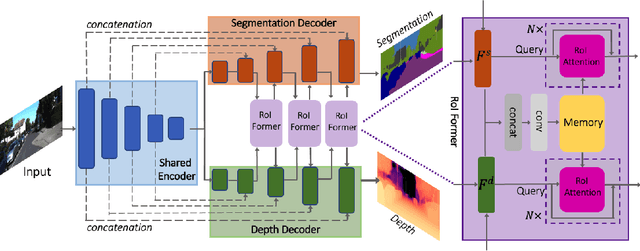
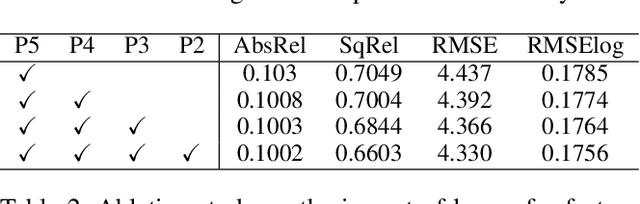
The exploration of mutual-benefit cross-domains has shown great potential toward accurate self-supervised depth estimation. In this work, we revisit feature fusion between depth and semantic information and propose an efficient local adaptive attention method for geometric aware representation enhancement. Instead of building global connections or deforming attention across the feature space without restraint, we bound the spatial interaction within a learnable region of interest. In particular, we leverage geometric cues from semantic information to learn local adaptive bounding boxes to guide unsupervised feature aggregation. The local areas preclude most irrelevant reference points from attention space, yielding more selective feature learning and faster convergence. We naturally extend the paradigm into a multi-head and hierarchic way to enable the information distillation in different semantic levels and improve the feature discriminative ability for fine-grained depth estimation. Extensive experiments on the KITTI dataset show that our proposed method establishes a new state-of-the-art in self-supervised monocular depth estimation task, demonstrating the effectiveness of our approach over former Transformer variants.
SPTS v2: Single-Point Scene Text Spotting
Jan 04, 2023
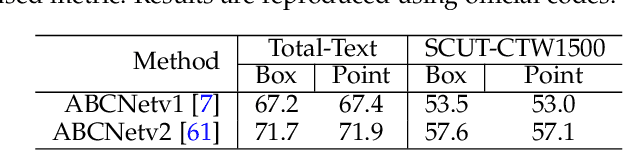

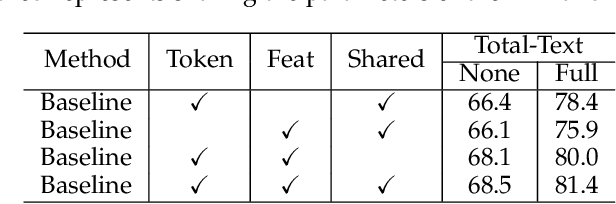
End-to-end scene text spotting has made significant progress due to its intrinsic synergy between text detection and recognition. Previous methods commonly regard manual annotations such as horizontal rectangles, rotated rectangles, quadrangles,and polygons as a prerequisite, which are much more expensive than using single-point. For the first time, we demonstrate that training scene text spotting models can be achieved with an extremely low-cost single-point annotation by the proposed framework, termed SPTS v2. SPTS v2 reserves the advantage of the auto-regressive Transformer with an Instance Assignment Decoder (IAD) through sequentially predicting the center points of all text instances inside the same predicting sequence, while with a Parallel Recognition Decoder (PRD) for text recognition in parallel. These two decoders share the same parameters and are interactively connected with a simple but effective information transmission process to pass the gradient and information. Comprehensive experiments on various existing benchmark datasets demonstrate the SPTS v2 can outperform previous state-of-the-art single-point text spotters with fewer parameters while achieving 14x faster inference speed. Most importantly, within the scope of our SPTS v2, extensive experiments further reveal an important phenomenon that single-point serves as the optimal setting for the scene text spotting compared to non-point, rectangular bounding box, and polygonal bounding box. Such an attempt provides a significant opportunity for scene text spotting applications beyond the realms of existing paradigms. Code is available at https://github.com/shannanyinxiang/SPTS.
Fully Complex-valued Fully Convolutional Multi-feature Fusion Network (FC2MFN) for Building Segmentation of InSAR images
Dec 14, 2022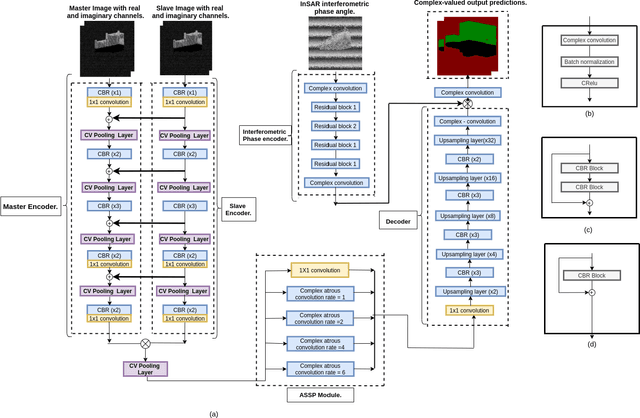
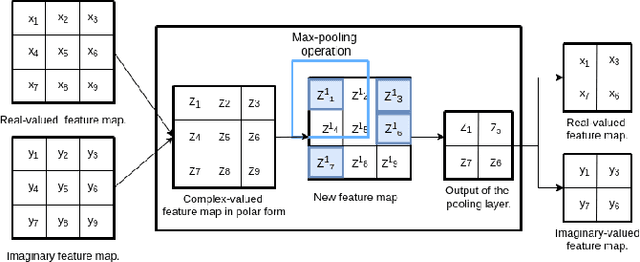
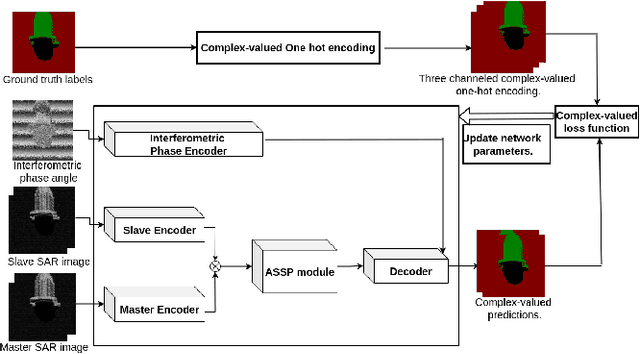

Building segmentation in high-resolution InSAR images is a challenging task that can be useful for large-scale surveillance. Although complex-valued deep learning networks perform better than their real-valued counterparts for complex-valued SAR data, phase information is not retained throughout the network, which causes a loss of information. This paper proposes a Fully Complex-valued, Fully Convolutional Multi-feature Fusion Network(FC2MFN) for building semantic segmentation on InSAR images using a novel, fully complex-valued learning scheme. The network learns multi-scale features, performs multi-feature fusion, and has a complex-valued output. For the particularity of complex-valued InSAR data, a new complex-valued pooling layer is proposed that compares complex numbers considering their magnitude and phase. This helps the network retain the phase information even through the pooling layer. Experimental results on the simulated InSAR dataset show that FC2MFN achieves better results compared to other state-of-the-art methods in terms of segmentation performance and model complexity.
Edge-Assisted V2X Motion Planning and Power Control Under Channel Uncertainty
Dec 13, 2022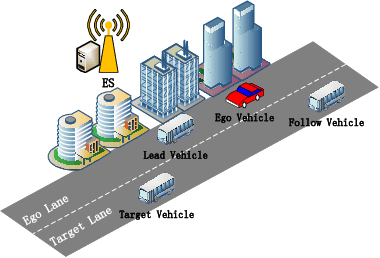
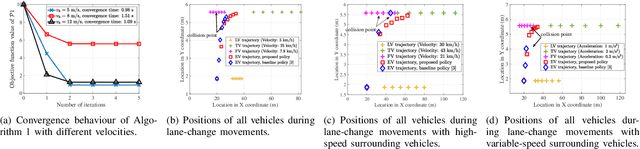
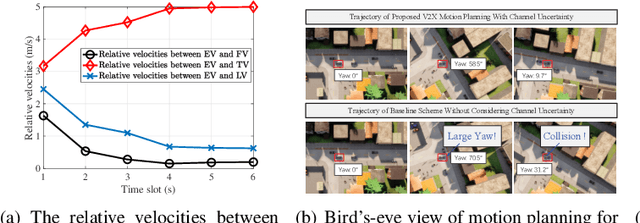

Edge-assisted vehicle-to-everything (V2X) motion planning is an emerging paradigm to achieve safe and efficient autonomous driving, since it leverages the global position information shared among multiple vehicles. However, due to the imperfect channel state information (CSI), the position information of vehicles may become outdated and inaccurate. Conventional methods ignoring the communication delays could severely jeopardize driving safety. To fill this gap, this paper proposes a robust V2X motion planning policy that adapts between competitive driving under a low communication delay and conservative driving under a high communication delay, and guarantees small communication delays at key waypoints via power control. This is achieved by integrating the vehicle mobility and communication delay models and solving a joint design of motion planning and power control problem via the block coordinate descent framework. Simulation results show that the proposed driving policy achieves the smallest collision ratio compared with other benchmark policies.
Improving Performance of Object Detection using the Mechanisms of Visual Recognition in Humans
Jan 23, 2023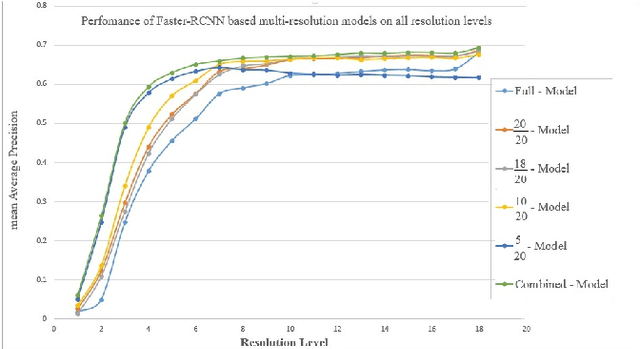
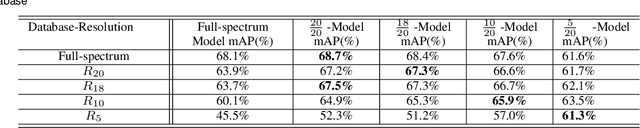

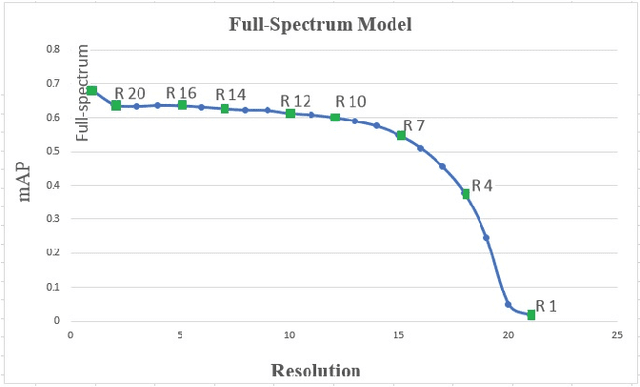
Object recognition systems are usually trained and evaluated on high resolution images. However, in real world applications, it is common that the images have low resolutions or have small sizes. In this study, we first track the performance of the state-of-the-art deep object recognition network, Faster- RCNN, as a function of image resolution. The results reveals negative effects of low resolution images on recognition performance. They also show that different spatial frequencies convey different information about the objects in recognition process. It means multi-resolution recognition system can provides better insight into optimal selection of features that results in better recognition of objects. This is similar to the mechanisms of the human visual systems that are able to implement multi-scale representation of a visual scene simultaneously. Then, we propose a multi-resolution object recognition framework rather than a single-resolution network. The proposed framework is evaluated on the PASCAL VOC2007 database. The experimental results show the performance of our adapted multi-resolution Faster-RCNN framework outperforms the single-resolution Faster-RCNN on input images with various resolutions with an increase in the mean Average Precision (mAP) of 9.14% across all resolutions and 1.2% on the full-spectrum images. Furthermore, the proposed model yields robustness of the performance over a wide range of spatial frequencies.
Triplet Contrastive Learning for Unsupervised Vehicle Re-identification
Jan 23, 2023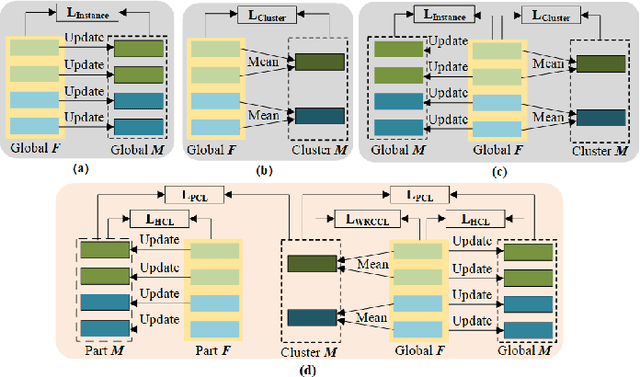
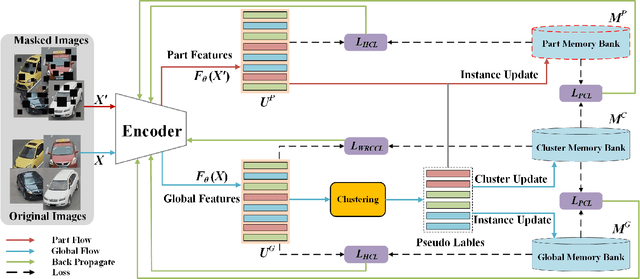
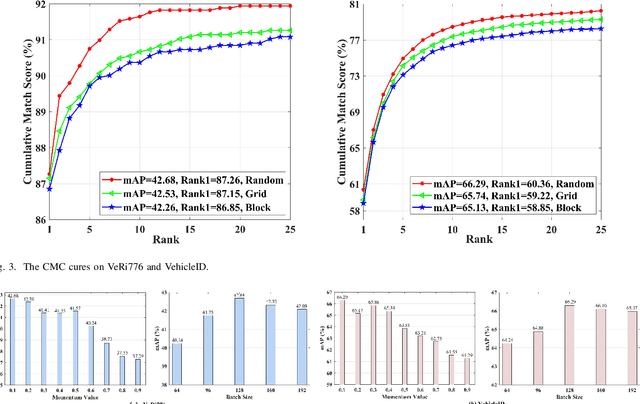

Part feature learning is a critical technology for finegrained semantic understanding in vehicle re-identification. However, recent unsupervised re-identification works exhibit serious gradient collapse issues when directly modeling the part features and global features. To address this problem, in this paper, we propose a novel Triplet Contrastive Learning framework (TCL) which leverages cluster features to bridge the part features and global features. Specifically, TCL devises three memory banks to store the features according to their attributes and proposes a proxy contrastive loss (PCL) to make contrastive learning between adjacent memory banks, thus presenting the associations between the part and global features as a transition of the partcluster and cluster-global associations. Since the cluster memory bank deals with all the instance features, it can summarize them into a discriminative feature representation. To deeply exploit the instance information, TCL proposes two additional loss functions. For the inter-class instance, a hybrid contrastive loss (HCL) re-defines the sample correlations by approaching the positive cluster features and leaving the all negative instance features. For the intra-class instances, a weighted regularization cluster contrastive loss (WRCCL) refines the pseudo labels by penalizing the mislabeled images according to the instance similarity. Extensive experiments show that TCL outperforms many state-of-the-art unsupervised vehicle re-identification approaches. The code will be available at https://github.com/muzishen/TCL.