 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Example-Based Explainable AI and its Application for Remote Sensing Image Classification
Feb 03, 2023
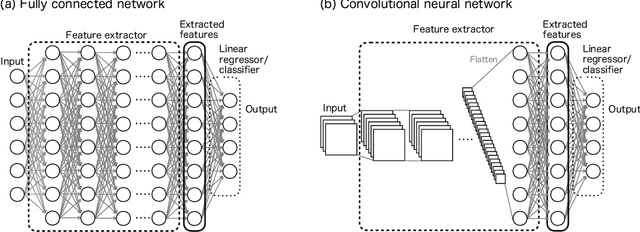
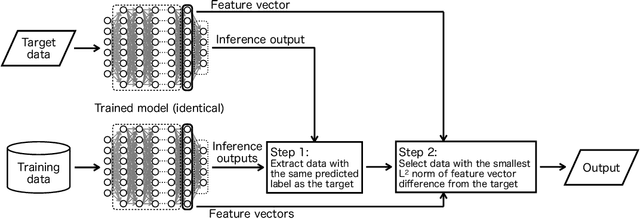


We present a method of explainable artificial intelligence (XAI), "What I Know (WIK)", to provide additional information to verify the reliability of a deep learning model by showing an example of an instance in a training dataset that is similar to the input data to be inferred and demonstrate it in a remote sensing image classification task. One of the expected roles of XAI methods is verifying whether inferences of a trained machine learning model are valid for an application, and it is an important factor that what datasets are used for training the model as well as the model architecture. Our data-centric approach can help determine whether the training dataset is sufficient for each inference by checking the selected example data. If the selected example looks similar to the input data, we can confirm that the model was not trained on a dataset with a feature distribution far from the feature of the input data. With this method, the criteria for selecting an example are not merely data similarity with the input data but also data similarity in the context of the model task. Using a remote sensing image dataset from the Sentinel-2 satellite, the concept was successfully demonstrated with reasonably selected examples. This method can be applied to various machine-learning tasks, including classification and regression.
Deep Reinforcement Learning for Online Error Detection in Cyber-Physical Systems
Feb 03, 2023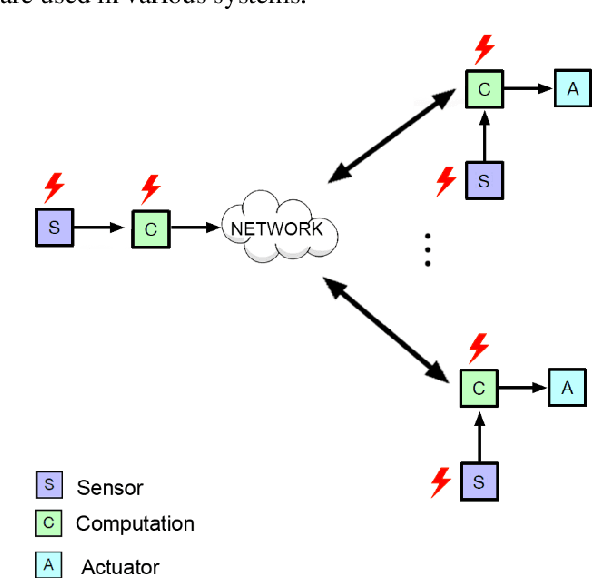
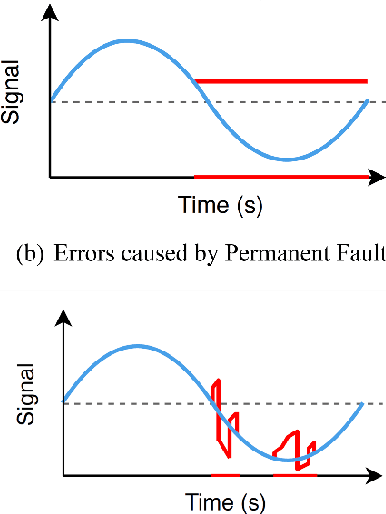
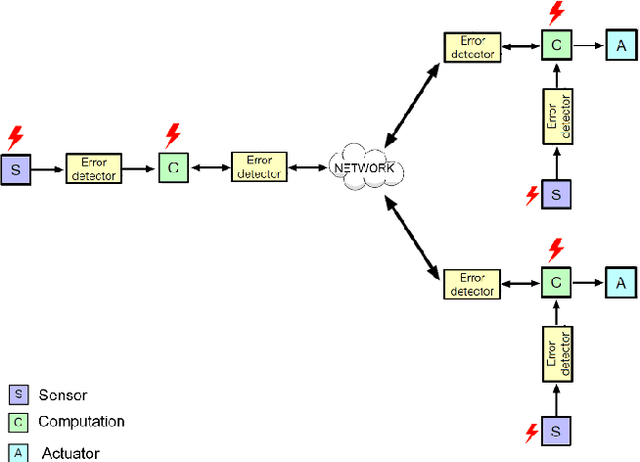
Reliability is one of the major design criteria in Cyber-Physical Systems (CPSs). This is because of the existence of some critical applications in CPSs and their failure is catastrophic. Therefore, employing strong error detection and correction mechanisms in CPSs is inevitable. CPSs are composed of a variety of units, including sensors, networks, and microcontrollers. Each of these units is probable to be in a faulty state at any time and the occurred fault can result in erroneous output. The fault may cause the units of CPS to malfunction and eventually crash. Traditional fault-tolerant approaches include redundancy time, hardware, information, and/or software. However, these approaches impose significant overheads besides their low error coverage, which limits their applicability. In addition, the interval between error occurrence and detection is too long in these approaches. In this paper, based on Deep Reinforcement Learning (DRL), a new error detection approach is proposed that not only detects errors with high accuracy but also can perform error detection at the moment due to very low inference time. The proposed approach can categorize different types of errors from normal data and predict whether the system will fail. The evaluation results illustrate that the proposed approach has improved more than 2x in terms of accuracy and more than 5x in terms of inference time compared to other approaches.
Graph-Based Compensated Wavelet Lifting for Scalable Lossless Coding of Dynamic Medical Data
Feb 03, 2023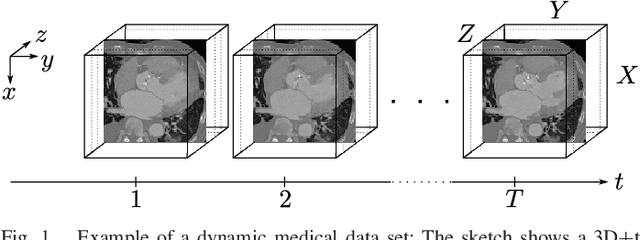
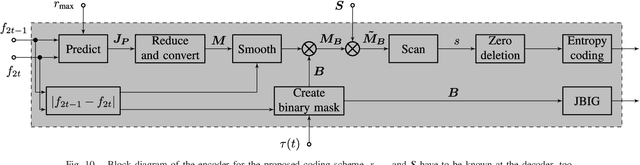
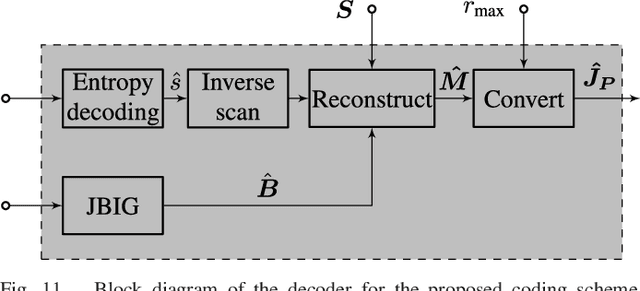

Lossless compression of dynamic 2D+t and 3D+t medical data is challenging regarding the huge amount of data, the characteristics of the inherent noise, and the high bit depth. Beyond that, a scalable representation is often required in telemedicine applications. Motion Compensated Temporal Filtering works well for lossless compression of medical volume data and additionally provides temporal, spatial, and quality scalability features. To achieve a high quality lowpass subband, which shall be used as a downscaled representative of the original data, graph-based motion compensation was recently introduced to this framework. However, encoding the motion information, which is stored in adjacency matrices, is not well investigated so far. This work focuses on coding these adjacency matrices to make the graph-based motion compensation feasible for data compression. We propose a novel coding scheme based on constructing so-called motion maps. This allows for the first time to compare the performance of graph-based motion compensation to traditional block- and mesh-based approaches. For high quality lowpass subbands our method is able to outperform the block- and mesh-based approaches by increasing the visual quality in terms of PSNR by 0.53dB and 0.28dB for CT data, as well as 1.04dB and 1.90dB for MR data, respectively, while the bit rate is reduced at the same time.
Stochastic Policy Gradient Methods: Improved Sample Complexity for Fisher-non-degenerate Policies
Feb 03, 2023
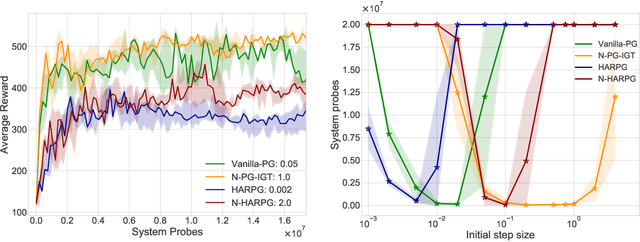
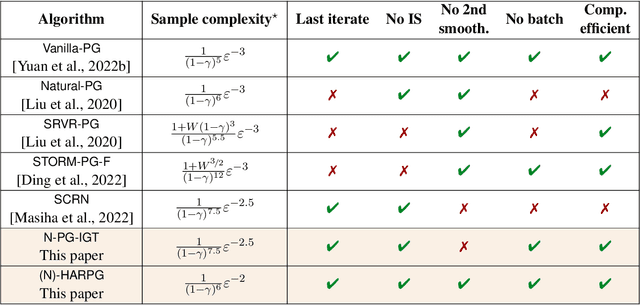
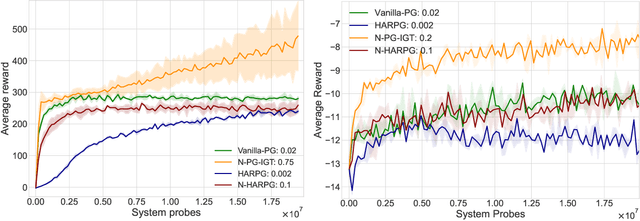
Recently, the impressive empirical success of policy gradient (PG) methods has catalyzed the development of their theoretical foundations. Despite the huge efforts directed at the design of efficient stochastic PG-type algorithms, the understanding of their convergence to a globally optimal policy is still limited. In this work, we develop improved global convergence guarantees for a general class of Fisher-non-degenerate parameterized policies which allows to address the case of continuous state action spaces. First, we propose a Normalized Policy Gradient method with Implicit Gradient Transport (N-PG-IGT) and derive a $\tilde{\mathcal{O}}(\varepsilon^{-2.5})$ sample complexity of this method for finding a global $\varepsilon$-optimal policy. Improving over the previously known $\tilde{\mathcal{O}}(\varepsilon^{-3})$ complexity, this algorithm does not require the use of importance sampling or second-order information and samples only one trajectory per iteration. Second, we further improve this complexity to $\tilde{ \mathcal{\mathcal{O}} }(\varepsilon^{-2})$ by considering a Hessian-Aided Recursive Policy Gradient ((N)-HARPG) algorithm enhanced with a correction based on a Hessian-vector product. Interestingly, both algorithms are $(i)$ simple and easy to implement: single-loop, do not require large batches of trajectories and sample at most two trajectories per iteration; $(ii)$ computationally and memory efficient: they do not require expensive subroutines at each iteration and can be implemented with memory linear in the dimension of parameters.
AMD-HookNet for Glacier Front Segmentation
Feb 06, 2023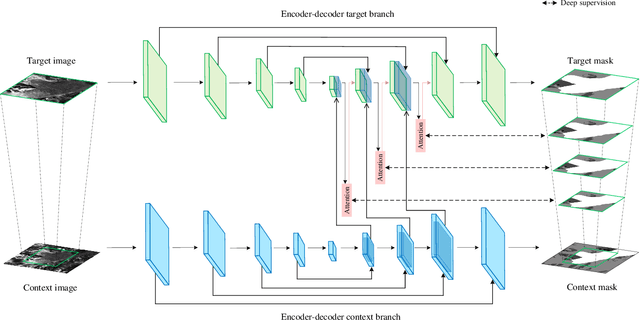

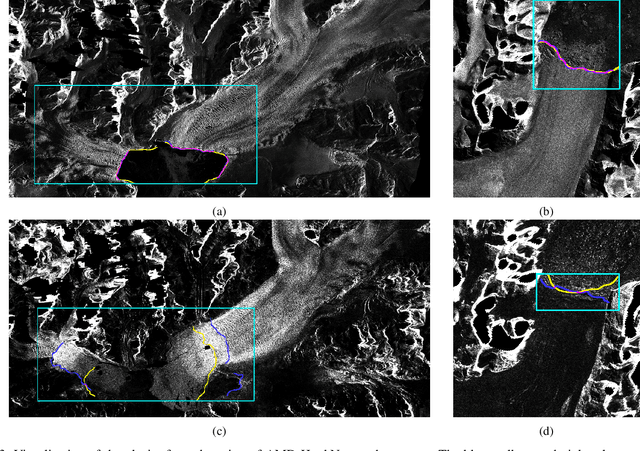
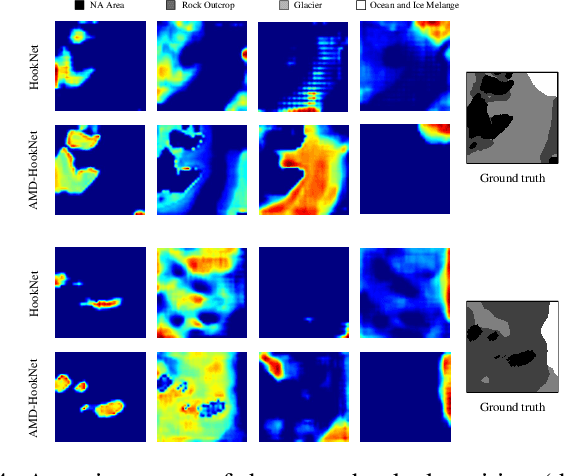
Knowledge on changes in glacier calving front positions is important for assessing the status of glaciers. Remote sensing imagery provides the ideal database for monitoring calving front positions, however, it is not feasible to perform this task manually for all calving glaciers globally due to time-constraints. Deep learning-based methods have shown great potential for glacier calving front delineation from optical and radar satellite imagery. The calving front is represented as a single thin line between the ocean and the glacier, which makes the task vulnerable to inaccurate predictions. The limited availability of annotated glacier imagery leads to a lack of data diversity (not all possible combinations of different weather conditions, terminus shapes, sensors, etc. are present in the data), which exacerbates the difficulty of accurate segmentation. In this paper, we propose Attention-Multi-hooking-Deep-supervision HookNet (AMD-HookNet), a novel glacier calving front segmentation framework for synthetic aperture radar (SAR) images. The proposed method aims to enhance the feature representation capability through multiple information interactions between low-resolution and high-resolution inputs based on a two-branch U-Net. The attention mechanism, integrated into the two branch U-Net, aims to interact between the corresponding coarse and fine-grained feature maps. This allows the network to automatically adjust feature relationships, resulting in accurate pixel-classification predictions. Extensive experiments and comparisons on the challenging glacier segmentation benchmark dataset CaFFe show that our AMD-HookNet achieves a mean distance error of 438 m to the ground truth outperforming the current state of the art by 42%, which validates its effectiveness.
Investigating Information Inconsistency in Multilingual Open-Domain Question Answering
May 25, 2022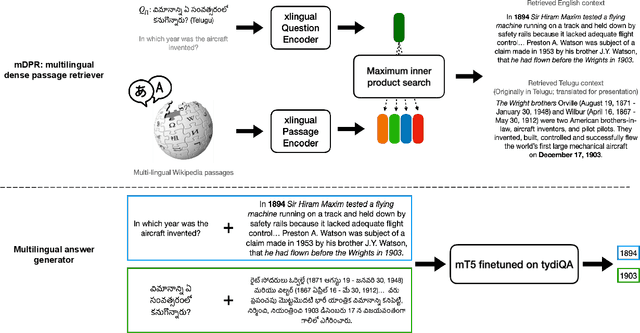

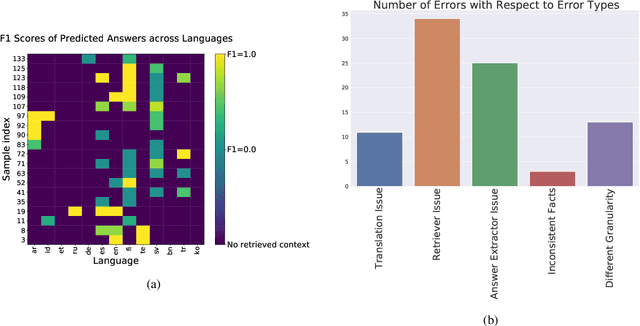
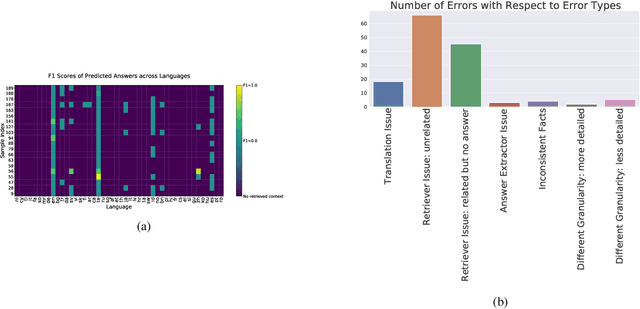
Retrieval based open-domain QA systems use retrieved documents and answer-span selection over retrieved documents to find best-answer candidates. We hypothesize that multilingual Question Answering (QA) systems are prone to information inconsistency when it comes to documents written in different languages, because these documents tend to provide a model with varying information about the same topic. To understand the effects of the biased availability of information and cultural influence, we analyze the behavior of multilingual open-domain question answering models with a focus on retrieval bias. We analyze if different retriever models present different passages given the same question in different languages on TyDi QA and XOR-TyDi QA, two multilingualQA datasets. We speculate that the content differences in documents across languages might reflect cultural divergences and/or social biases.
Beyond web-scraping: Crowd-sourcing a geographically diverse image dataset
Jan 05, 2023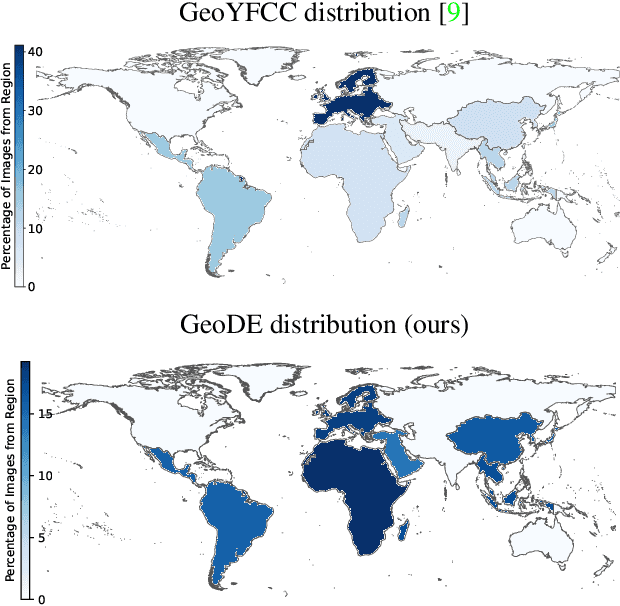
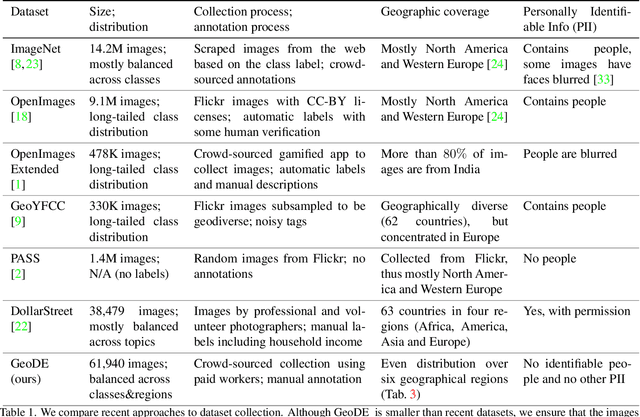


Current dataset collection methods typically scrape large amounts of data from the web. While this technique is extremely scalable, data collected in this way tends to reinforce stereotypical biases, can contain personally identifiable information, and typically originates from Europe and North America. In this work, we rethink the dataset collection paradigm and introduce GeoDE, a geographically diverse dataset with 61,940 images from 40 classes and 6 world regions, and no personally identifiable information, collected through crowd-sourcing. We analyse GeoDE to understand differences in images collected in this manner compared to web-scraping. Despite the smaller size of this dataset, we demonstrate its use as both an evaluation and training dataset, highlight shortcomings in current models, as well as show improved performances when even small amounts of GeoDE (1000 - 2000 images per region) are added to a training dataset. We release the full dataset and code at https://geodiverse-data-collection.cs.princeton.edu/
A Network Science perspective of Graph Convolutional Networks: A survey
Jan 12, 2023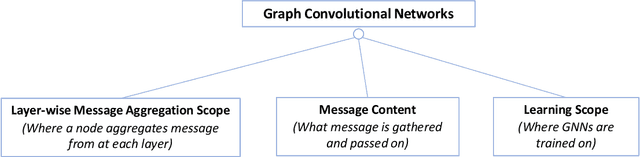
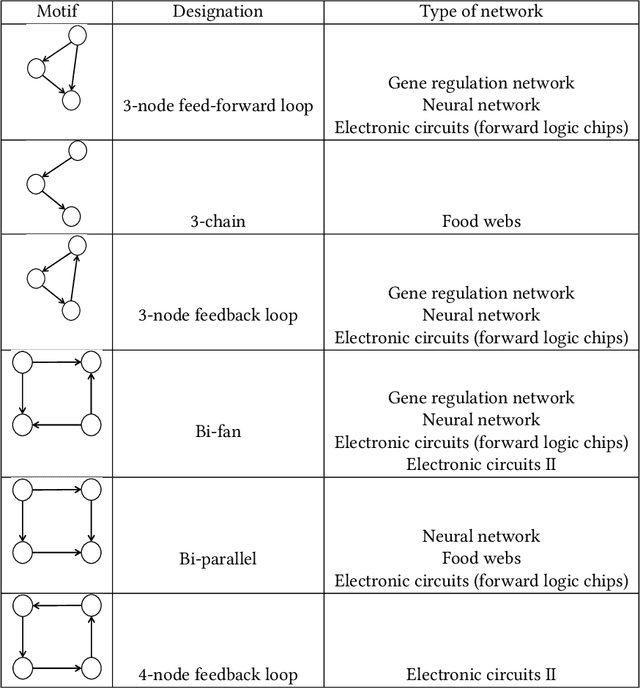
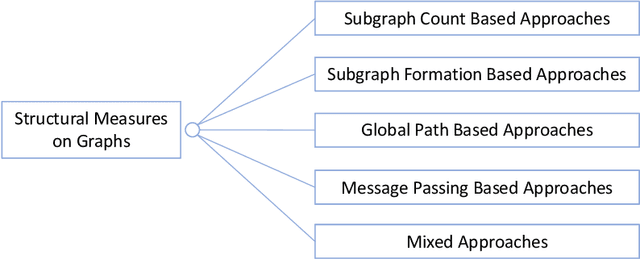
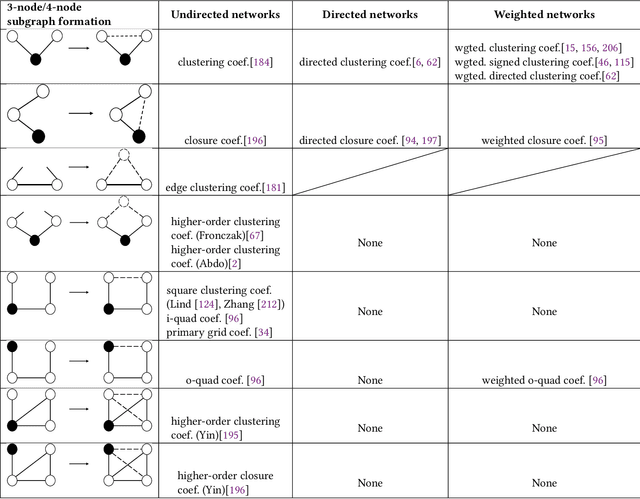
The mining and exploitation of graph structural information have been the focal points in the study of complex networks. Traditional structural measures in Network Science focus on the analysis and modelling of complex networks from the perspective of network structure, such as the centrality measures, the clustering coefficient, and motifs and graphlets, and they have become basic tools for studying and understanding graphs. In comparison, graph neural networks, especially graph convolutional networks (GCNs), are particularly effective at integrating node features into graph structures via neighbourhood aggregation and message passing, and have been shown to significantly improve the performances in a variety of learning tasks. These two classes of methods are, however, typically treated separately with limited references to each other. In this work, aiming to establish relationships between them, we provide a network science perspective of GCNs. Our novel taxonomy classifies GCNs from three structural information angles, i.e., the layer-wise message aggregation scope, the message content, and the overall learning scope. Moreover, as a prerequisite for reviewing GCNs via a network science perspective, we also summarise traditional structural measures and propose a new taxonomy for them. Finally and most importantly, we draw connections between traditional structural approaches and graph convolutional networks, and discuss potential directions for future research.
Phase-shifted Adversarial Training
Jan 12, 2023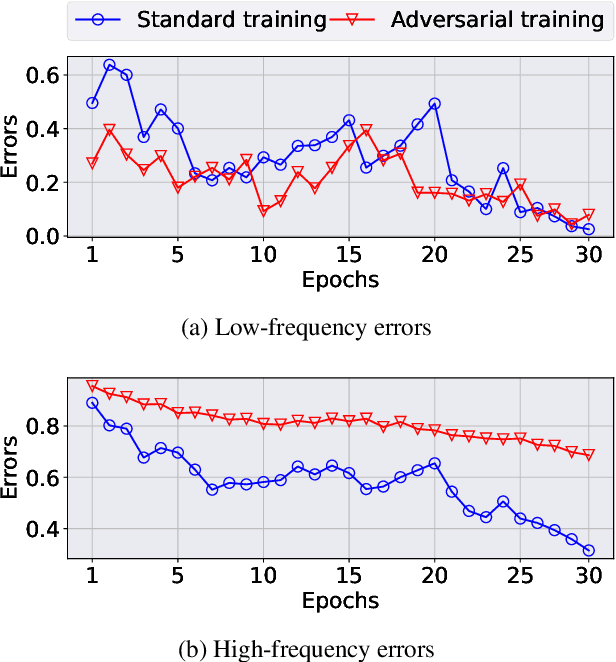
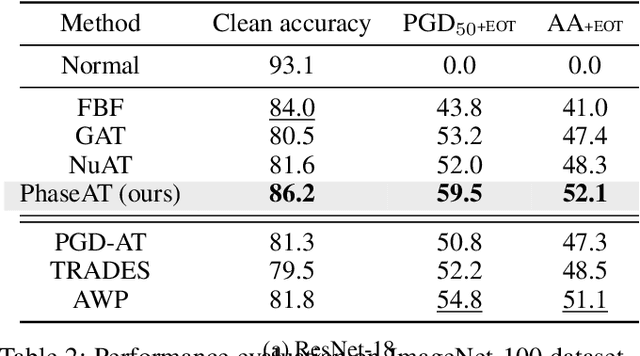
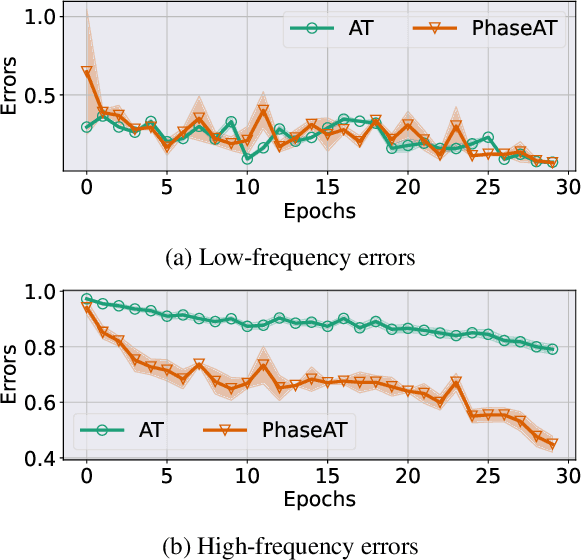
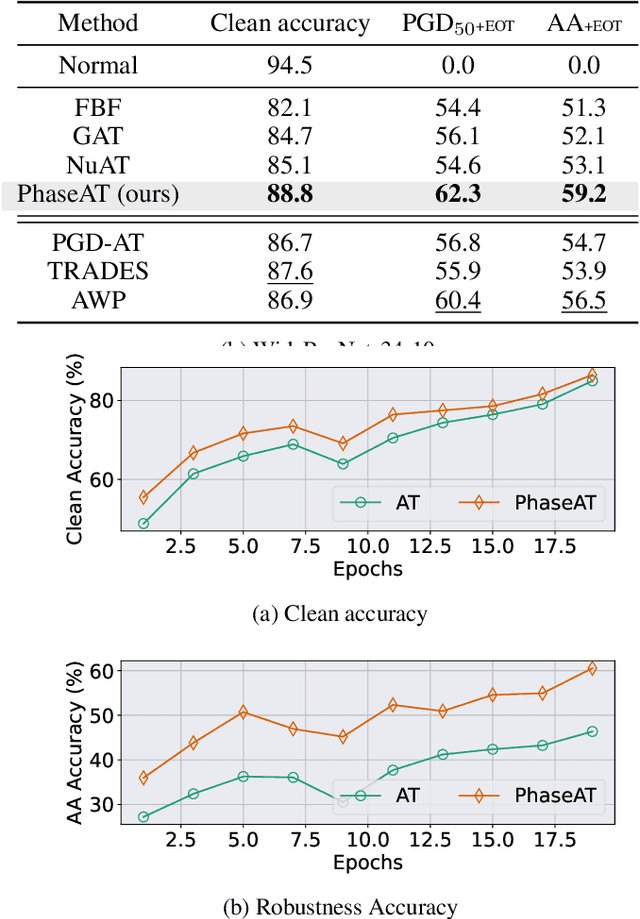
Adversarial training has been considered an imperative component for safely deploying neural network-based applications to the real world. To achieve stronger robustness, existing methods primarily focus on how to generate strong attacks by increasing the number of update steps, regularizing the models with the smoothed loss function, and injecting the randomness into the attack. Instead, we analyze the behavior of adversarial training through the lens of response frequency. We empirically discover that adversarial training causes neural networks to have low convergence to high-frequency information, resulting in highly oscillated predictions near each data. To learn high-frequency contents efficiently and effectively, we first prove that a universal phenomenon of frequency principle, i.e., \textit{lower frequencies are learned first}, still holds in adversarial training. Based on that, we propose phase-shifted adversarial training (PhaseAT) in which the model learns high-frequency components by shifting these frequencies to the low-frequency range where the fast convergence occurs. For evaluations, we conduct the experiments on CIFAR-10 and ImageNet with the adaptive attack carefully designed for reliable evaluation. Comprehensive results show that PhaseAT significantly improves the convergence for high-frequency information. This results in improved adversarial robustness by enabling the model to have smoothed predictions near each data.
Against Algorithmic Exploitation of Human Vulnerabilities
Jan 12, 2023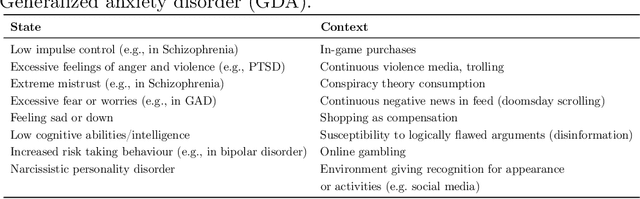
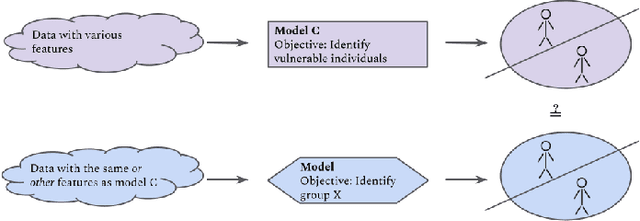
Decisions such as which movie to watch next, which song to listen to, or which product to buy online, are increasingly influenced by recommender systems and user models that incorporate information on users' past behaviours, preferences, and digitally created content. Machine learning models that enable recommendations and that are trained on user data may unintentionally leverage information on human characteristics that are considered vulnerabilities, such as depression, young age, or gambling addiction. The use of algorithmic decisions based on latent vulnerable state representations could be considered manipulative and could have a deteriorating impact on the condition of vulnerable individuals. In this paper, we are concerned with the problem of machine learning models inadvertently modelling vulnerabilities, and want to raise awareness for this issue to be considered in legislation and AI ethics. Hence, we define and describe common vulnerabilities, and illustrate cases where they are likely to play a role in algorithmic decision-making. We propose a set of requirements for methods to detect the potential for vulnerability modelling, detect whether vulnerable groups are treated differently by a model, and detect whether a model has created an internal representation of vulnerability. We conclude that explainable artificial intelligence methods may be necessary for detecting vulnerability exploitation by machine learning-based recommendation systems.