 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Uncovering Adversarial Risks of Test-Time Adaptation
Jan 29, 2023
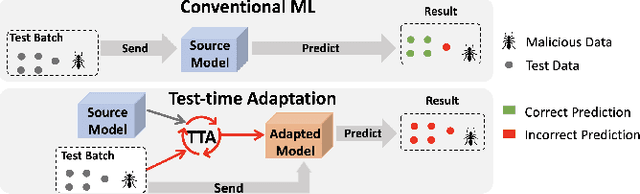
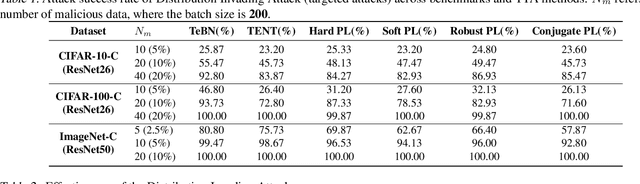
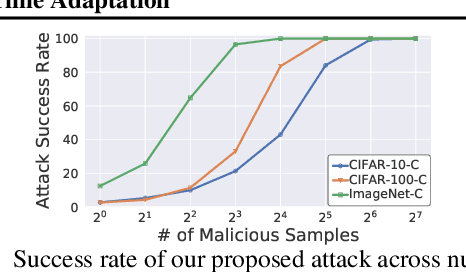
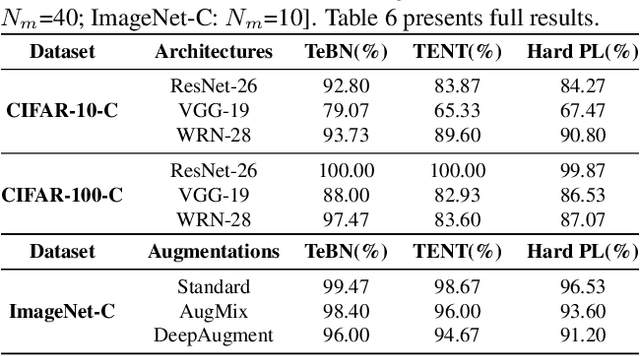
Recently, test-time adaptation (TTA) has been proposed as a promising solution for addressing distribution shifts. It allows a base model to adapt to an unforeseen distribution during inference by leveraging the information from the batch of (unlabeled) test data. However, we uncover a novel security vulnerability of TTA based on the insight that predictions on benign samples can be impacted by malicious samples in the same batch. To exploit this vulnerability, we propose Distribution Invading Attack (DIA), which injects a small fraction of malicious data into the test batch. DIA causes models using TTA to misclassify benign and unperturbed test data, providing an entirely new capability for adversaries that is infeasible in canonical machine learning pipelines. Through comprehensive evaluations, we demonstrate the high effectiveness of our attack on multiple benchmarks across six TTA methods. In response, we investigate two countermeasures to robustify the existing insecure TTA implementations, following the principle of "security by design". Together, we hope our findings can make the community aware of the utility-security tradeoffs in deploying TTA and provide valuable insights for developing robust TTA approaches.
Smooth Non-Stationary Bandits
Jan 29, 2023
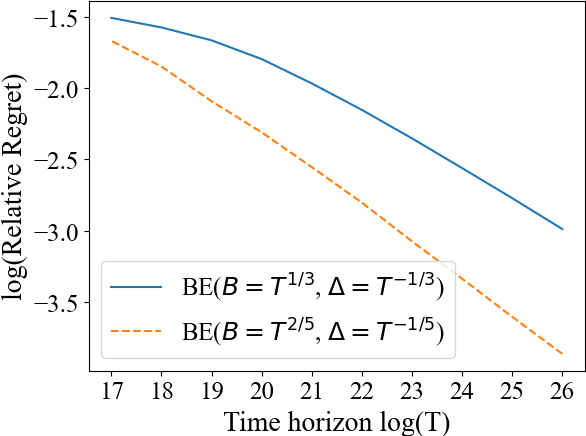
In many applications of online decision making, the environment is non-stationary and it is therefore crucial to use bandit algorithms that handle changes. Most existing approaches are designed to protect against non-smooth changes, constrained only by total variation or Lipschitzness over time, where they guarantee $T^{2/3}$ regret. However, in practice environments are often changing {\it smoothly}, so such algorithms may incur higher-than-necessary regret in these settings and do not leverage information on the {\it rate of change}. In this paper, we study a non-stationary two-arm bandit problem where we assume an arm's mean reward is a $\beta$-H\"older function over (normalized) time, meaning it is $(\beta-1)$-times Lipschitz-continuously differentiable. We show the first {\it separation} between the smooth and non-smooth regimes by presenting a policy with $T^{3/5}$ regret for $\beta=2$. We complement this result by a $T^{\frac{\beta+1}{2\beta+1}}$ lower bound for any integer $\beta\ge 1$, which matches our upper bound for $\beta=2$.
Fair Decision-making Under Uncertainty
Jan 29, 2023
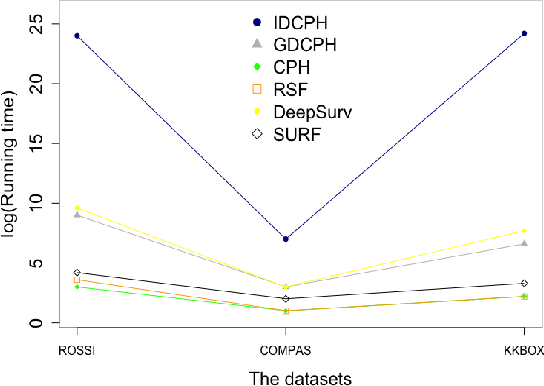

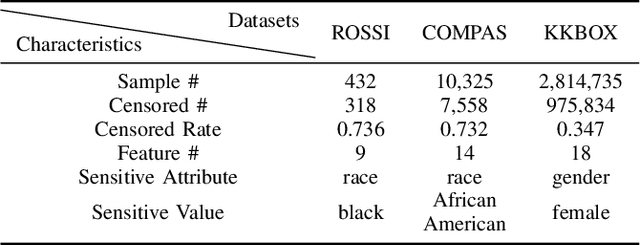
There has been concern within the artificial intelligence (AI) community and the broader society regarding the potential lack of fairness of AI-based decision-making systems. Surprisingly, there is little work quantifying and guaranteeing fairness in the presence of uncertainty which is prevalent in many socially sensitive applications, ranging from marketing analytics to actuarial analysis and recidivism prediction instruments. To this end, we study a longitudinal censored learning problem subject to fairness constraints, where we require that algorithmic decisions made do not affect certain individuals or social groups negatively in the presence of uncertainty on class label due to censorship. We argue that this formulation has a broader applicability to practical scenarios concerning fairness. We show how the newly devised fairness notions involving censored information and the general framework for fair predictions in the presence of censorship allow us to measure and mitigate discrimination under uncertainty that bridges the gap with real-world applications. Empirical evaluations on real-world discriminated datasets with censorship demonstrate the practicality of our approach.
Graph Mixer Networks
Jan 29, 2023
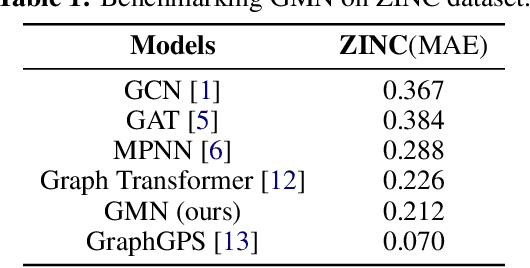
In recent years, the attention mechanism has demonstrated superior performance in various tasks, leading to the emergence of GAT and Graph Transformer models that utilize this mechanism to extract relational information from graph-structured data. However, the high computational cost associated with the Transformer block, as seen in Vision Transformers, has motivated the development of alternative architectures such as MLP-Mixers, which have been shown to improve performance in image tasks while reducing the computational cost. Despite the effectiveness of Transformers in graph-based tasks, their computational efficiency remains a concern. The logic behind MLP-Mixers, which addresses this issue in image tasks, has the potential to be applied to graph-structured data as well. In this paper, we propose the Graph Mixer Network (GMN), also referred to as Graph Nasreddin Nets (GNasNets), a framework that incorporates the principles of MLP-Mixers for graph-structured data. Using a PNA model with multiple aggregators as the foundation, our proposed GMN has demonstrated improved performance compared to Graph Transformers. The source code is available publicly at https://github.com/asarigun/GraphMixerNetworks.
The Influences of Color and Shape Features in Visual Contrastive Learning
Jan 29, 2023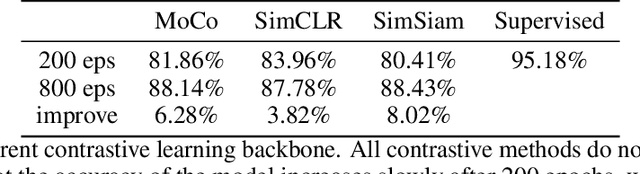



In the field of visual representation learning, performance of contrastive learning has been catching up with the supervised method which is commonly a classification convolutional neural network. However, most of the research work focuses on improving the accuracy of downstream tasks such as image classification and object detection. For visual contrastive learning, the influences of individual image features (e.g., color and shape) to model performance remain ambiguous. This paper investigates such influences by designing various ablation experiments, the results of which are evaluated by specifically designed metrics. While these metrics are not invented by us, we first use them in the field of representation evaluation. Specifically, we assess the contribution of two primary image features (i.e., color and shape) in a quantitative way. Experimental results show that compared with supervised representations, contrastive representations tend to cluster with objects of similar color in the representation space, and contain less shape information than supervised representations. Finally, we discuss that the current data augmentation is responsible for these results. We believe that exploring an unsupervised augmentation method that
Investigating Information Inconsistency in Multilingual Open-Domain Question Answering
May 25, 2022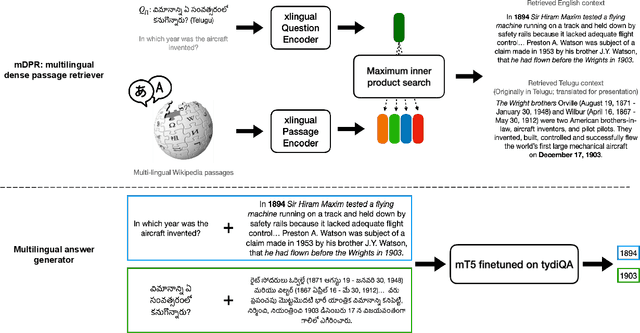

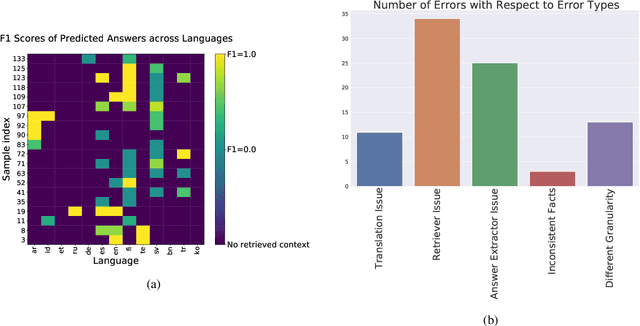
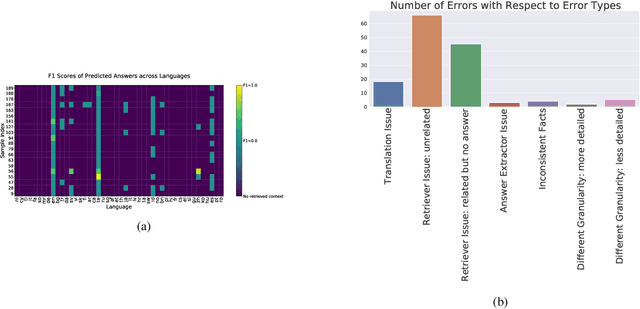
Retrieval based open-domain QA systems use retrieved documents and answer-span selection over retrieved documents to find best-answer candidates. We hypothesize that multilingual Question Answering (QA) systems are prone to information inconsistency when it comes to documents written in different languages, because these documents tend to provide a model with varying information about the same topic. To understand the effects of the biased availability of information and cultural influence, we analyze the behavior of multilingual open-domain question answering models with a focus on retrieval bias. We analyze if different retriever models present different passages given the same question in different languages on TyDi QA and XOR-TyDi QA, two multilingualQA datasets. We speculate that the content differences in documents across languages might reflect cultural divergences and/or social biases.
Generalizable Black-Box Adversarial Attack with Meta Learning
Jan 01, 2023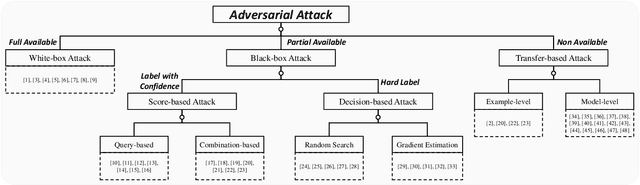
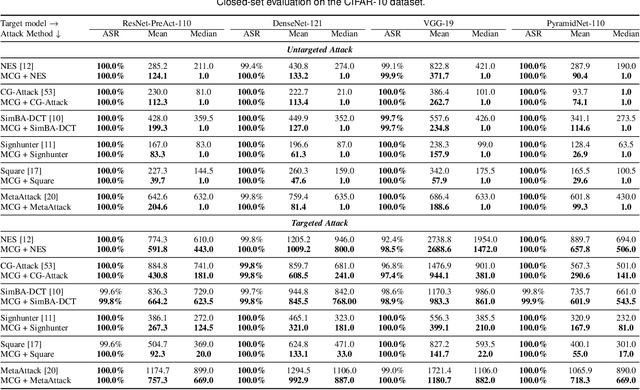
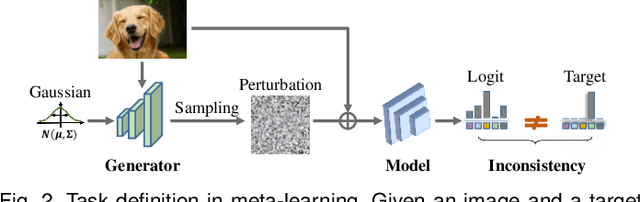
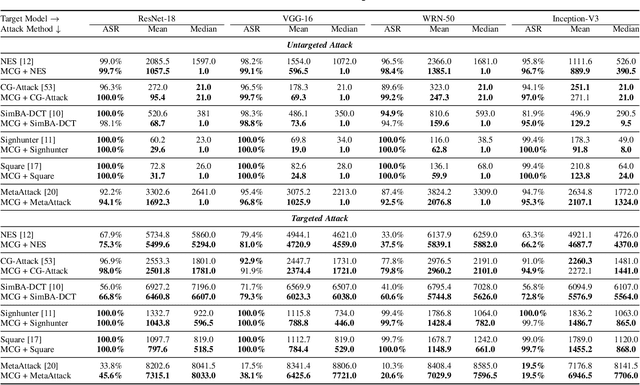
In the scenario of black-box adversarial attack, the target model's parameters are unknown, and the attacker aims to find a successful adversarial perturbation based on query feedback under a query budget. Due to the limited feedback information, existing query-based black-box attack methods often require many queries for attacking each benign example. To reduce query cost, we propose to utilize the feedback information across historical attacks, dubbed example-level adversarial transferability. Specifically, by treating the attack on each benign example as one task, we develop a meta-learning framework by training a meta-generator to produce perturbations conditioned on benign examples. When attacking a new benign example, the meta generator can be quickly fine-tuned based on the feedback information of the new task as well as a few historical attacks to produce effective perturbations. Moreover, since the meta-train procedure consumes many queries to learn a generalizable generator, we utilize model-level adversarial transferability to train the meta-generator on a white-box surrogate model, then transfer it to help the attack against the target model. The proposed framework with the two types of adversarial transferability can be naturally combined with any off-the-shelf query-based attack methods to boost their performance, which is verified by extensive experiments.
Optimization of Image Transmission in a Cooperative Semantic Communication Networks
Jan 01, 2023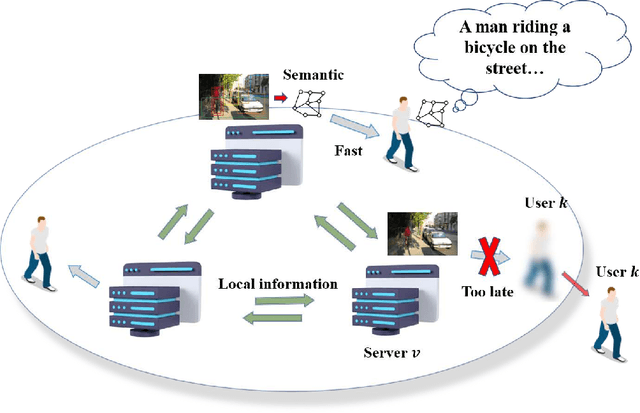
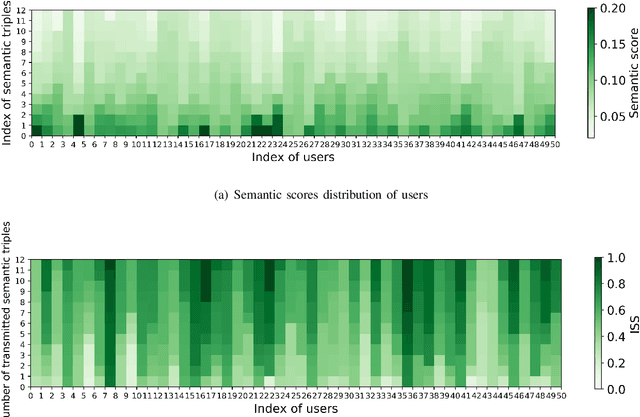
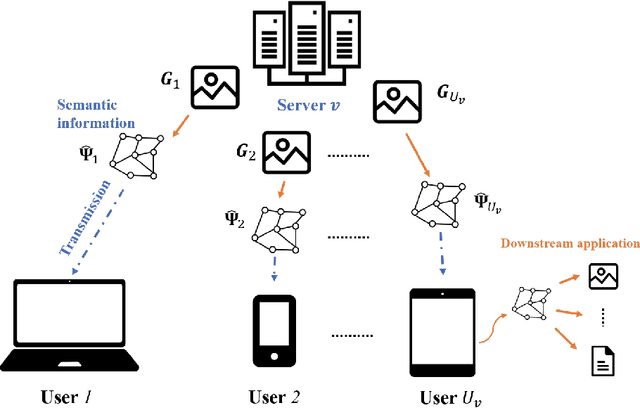
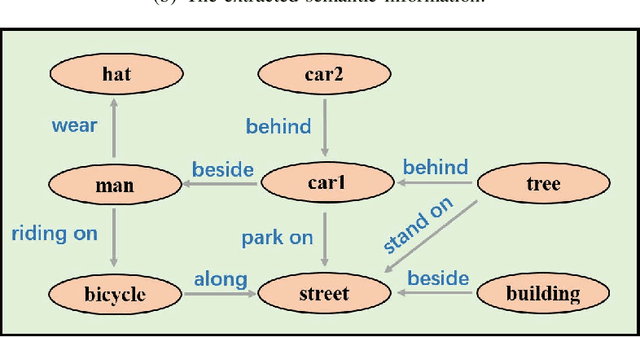
In this paper, a semantic communication framework for image transmission is developed. In the investigated framework, a set of servers cooperatively transmit images to a set of users utilizing semantic communication techniques. To evaluate the performance of studied semantic communication system, a multimodal metric is proposed to measure the correlation between the extracted semantic information and the original image. To meet the ISS requirement of each user, each server must jointly determine the semantic information to be transmitted and the resource blocks (RBs) used for semantic information transmission. We formulate this problem as an optimization problem aiming to minimize each server's transmission latency while reaching the ISS requirement. To solve this problem, a value decomposition based entropy-maximized multi-agent reinforcement learning (RL) is proposed, which enables servers to coordinate for training and execute RB allocation in a distributed manner to approach to a globally optimal performance with less training iterations. Compared to traditional multi-agent RL, the proposed RL improves the valuable action exploration of servers and the probability of finding a globally optimal RB allocation policy based on local observation. Simulation results show that the proposed algorithm can reduce the transmission delay by up to 16.1% compared to traditional multi-agent RL.
Dual-interest Factorization-heads Attention for Sequential Recommendation
Feb 09, 2023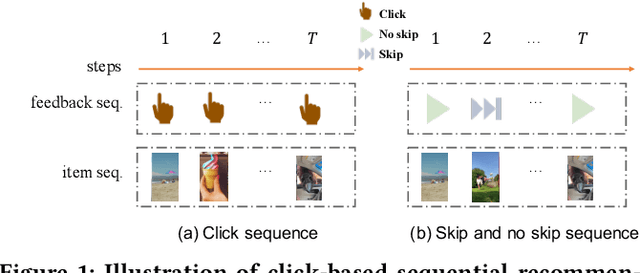
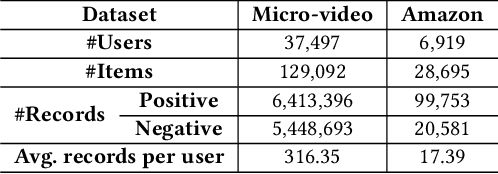
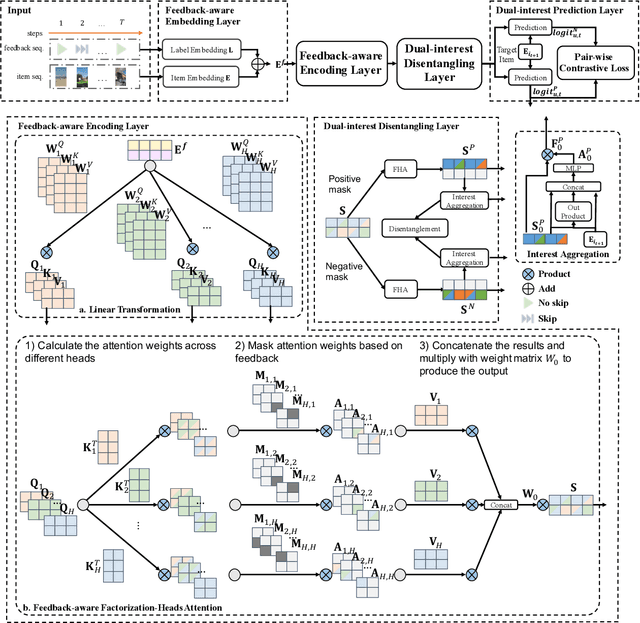
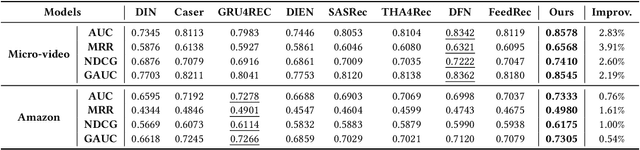
Accurate user interest modeling is vital for recommendation scenarios. One of the effective solutions is the sequential recommendation that relies on click behaviors, but this is not elegant in the video feed recommendation where users are passive in receiving the streaming contents and return skip or no-skip behaviors instead of active click behavior. Here skip and no-skip behaviors can be treated as negative and positive feedback, respectively. Indeed, skip and no-skip are not simply positive or negative correlated, so it is challenging to capture the transition pattern of positive and negative feedback. To do so, FeedRec has exploited a shared vanilla Transformer and grouped each feedback into different Transformers. Indeed, such a task may be challenging for the vanilla Transformer because head interaction of multi-heads attention does not consider different types of feedback. In this paper, we propose Dual-interest Factorization-heads Attention for Sequential Recommendation (short for DFAR) consisting of feedback-aware encoding layer, dual-interest disentangling layer and prediction layer. In the feedback-aware encoding layer, we first suppose each head of multi-heads attention can capture specific feedback relations. Then we further propose factorization-heads attention which can mask specific head interaction and inject feedback information so as to factorize the relation between different types of feedback. Additionally, we propose a dual-interest disentangling layer to decouple positive and negative interests before performing disentanglement on their representations. Finally, we evolve the positive and negative interests by corresponding towers whose outputs are contrastive by BPR loss. Experiments on two real-world datasets show the superiority of our proposed method against state-of-the-art baselines. Further ablation study and visualization also sustain its effectiveness.
A Biomedical Knowledge Graph for Biomarker Discovery in Cancer
Feb 09, 2023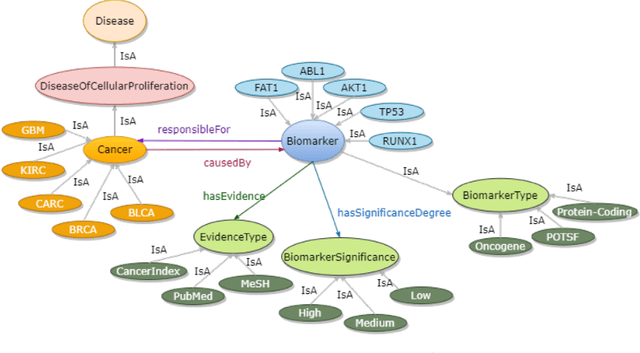
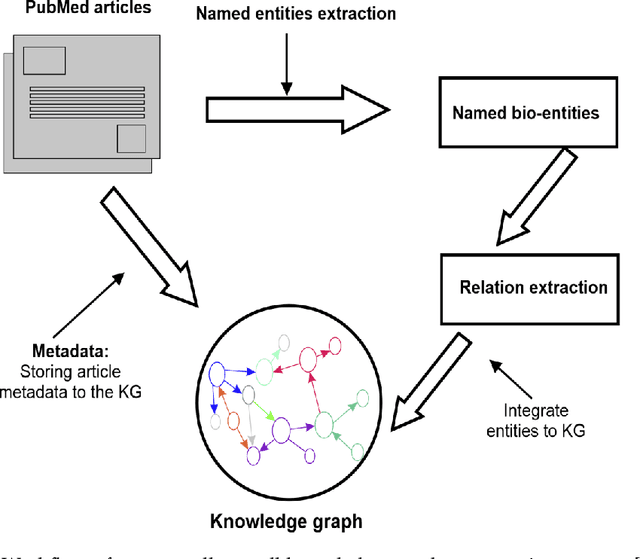

Structured and unstructured data and facts about drugs, genes, protein, viruses, and their mechanism are spread across a huge number of scientific articles. These articles are a large-scale knowledge source and can have a huge impact on disseminating knowledge about the mechanisms of certain biological processes. A domain-specific knowledge graph~(KG) is an explicit conceptualization of a specific subject-matter domain represented w.r.t semantically interrelated entities and relations. A KG can be constructed by integrating such facts and data and be used for data integration, exploration, and federated queries. However, exploration and querying large-scale KGs is tedious for certain groups of users due to a lack of knowledge about underlying data assets or semantic technologies. Such a KG will not only allow deducing new knowledge and question answering(QA) but also allows domain experts to explore. Since cross-disciplinary explanations are important for accurate diagnosis, it is important to query the KG to provide interactive explanations about learned biomarkers. Inspired by these, we construct a domain-specific KG, particularly for cancer-specific biomarker discovery. The KG is constructed by integrating cancer-related knowledge and facts from multiple sources. First, we construct a domain-specific ontology, which we call OncoNet Ontology (ONO). The ONO ontology is developed to enable semantic reasoning for verification of the predictions for relations between diseases and genes. The KG is then developed and enriched by harmonizing the ONO, additional metadata schemas, ontologies, controlled vocabularies, and additional concepts from external sources using a BERT-based information extraction method. BioBERT and SciBERT are finetuned with the selected articles crawled from PubMed. We listed down some queries and some examples of QA and deducing knowledge based on the KG.