 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CLAM: Selective Clarification for Ambiguous Questions with Large Language Models
Dec 15, 2022
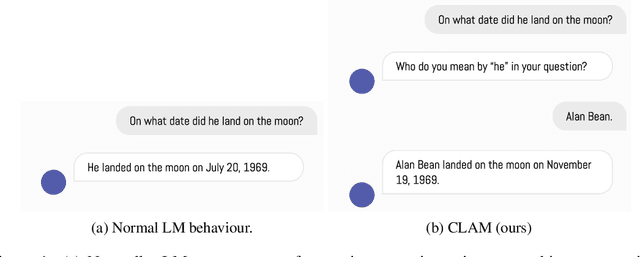

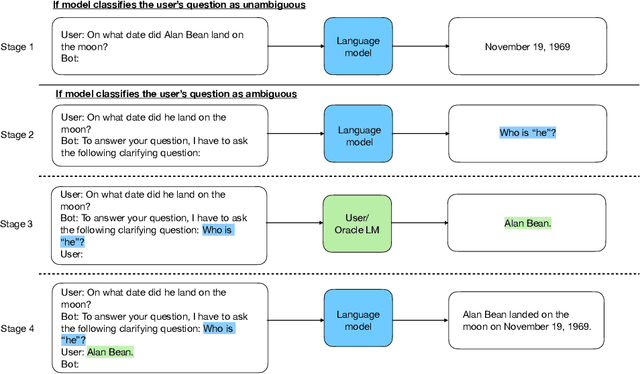

State-of-the-art language models are often accurate on many question-answering benchmarks with well-defined questions. Yet, in real settings questions are often unanswerable without asking the user for clarifying information. We show that current SotA models often do not ask the user for clarification when presented with imprecise questions and instead provide incorrect answers or "hallucinate". To address this, we introduce CLAM, a framework that first uses the model to detect ambiguous questions, and if an ambiguous question is detected, prompts the model to ask the user for clarification. Furthermore, we show how to construct a scalable and cost-effective automatic evaluation protocol using an oracle language model with privileged information to provide clarifying information. We show that our method achieves a 20.15 percentage point accuracy improvement over SotA on a novel ambiguous question-answering answering data set derived from TriviaQA.
Statistical Physics of Deep Neural Networks: Initialization toward Optimal Channels
Dec 04, 2022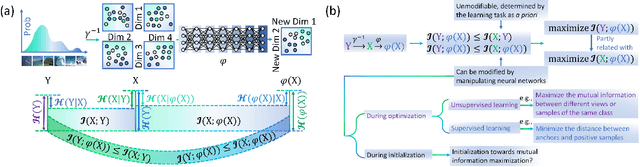
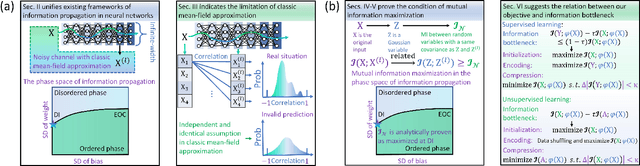
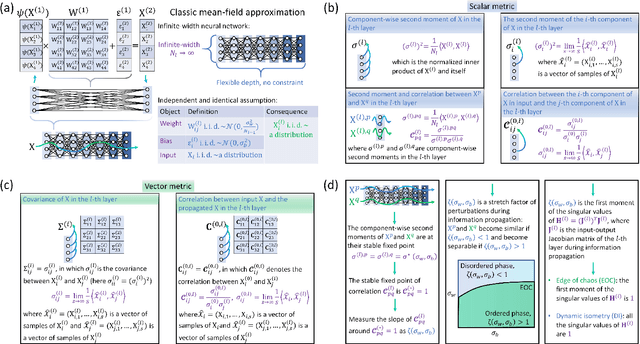
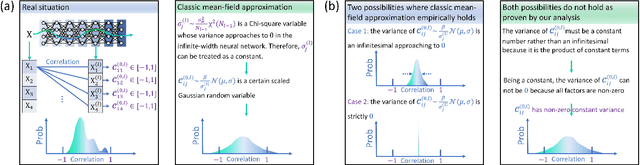
In deep learning, neural networks serve as noisy channels between input data and its representation. This perspective naturally relates deep learning with the pursuit of constructing channels with optimal performance in information transmission and representation. While considerable efforts are concentrated on realizing optimal channel properties during network optimization, we study a frequently overlooked possibility that neural networks can be initialized toward optimal channels. Our theory, consistent with experimental validation, identifies primary mechanics underlying this unknown possibility and suggests intrinsic connections between statistical physics and deep learning. Unlike the conventional theories that characterize neural networks applying the classic mean-filed approximation, we offer analytic proof that this extensively applied simplification scheme is not valid in studying neural networks as information channels. To fill this gap, we develop a corrected mean-field framework applicable for characterizing the limiting behaviors of information propagation in neural networks without strong assumptions on inputs. Based on it, we propose an analytic theory to prove that mutual information maximization is realized between inputs and propagated signals when neural networks are initialized at dynamic isometry, a case where information transmits via norm-preserving mappings. These theoretical predictions are validated by experiments on real neural networks, suggesting the robustness of our theory against finite-size effects. Finally, we analyze our findings with information bottleneck theory to confirm the precise relations among dynamic isometry, mutual information maximization, and optimal channel properties in deep learning.
AI-Based Framework for Understanding Car Following Behaviors of Drivers in A Naturalistic Driving Environment
Jan 23, 2023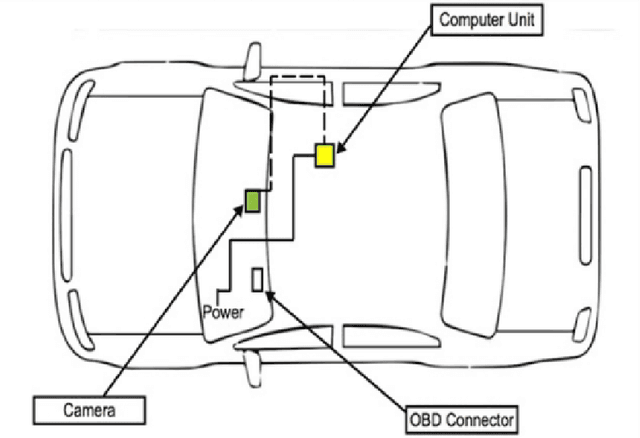
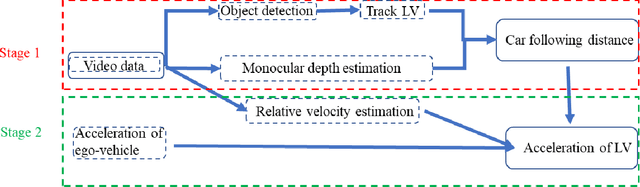
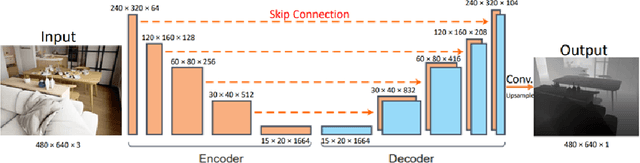
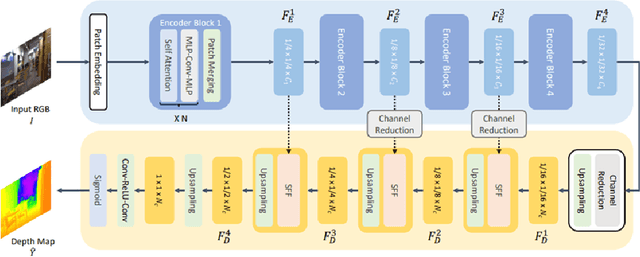
The most common type of accident on the road is a rear-end crash. These crashes have a significant negative impact on traffic flow and are frequently fatal. To gain a more practical understanding of these scenarios, it is necessary to accurately model car following behaviors that result in rear-end crashes. Numerous studies have been carried out to model drivers' car-following behaviors; however, the majority of these studies have relied on simulated data, which may not accurately represent real-world incidents. Furthermore, most studies are restricted to modeling the ego vehicle's acceleration, which is insufficient to explain the behavior of the ego vehicle. As a result, the current study attempts to address these issues by developing an artificial intelligence framework for extracting features relevant to understanding driver behavior in a naturalistic environment. Furthermore, the study modeled the acceleration of both the ego vehicle and the leading vehicle using extracted information from NDS videos. According to the study's findings, young people are more likely to be aggressive drivers than elderly people. In addition, when modeling the ego vehicle's acceleration, it was discovered that the relative velocity between the ego vehicle and the leading vehicle was more important than the distance between the two vehicles.
CircNet: Meshing 3D Point Clouds with Circumcenter Detection
Jan 23, 2023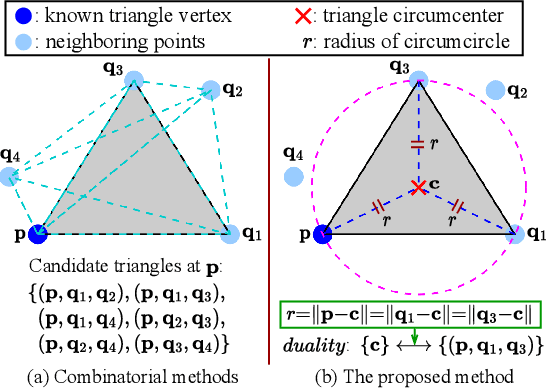
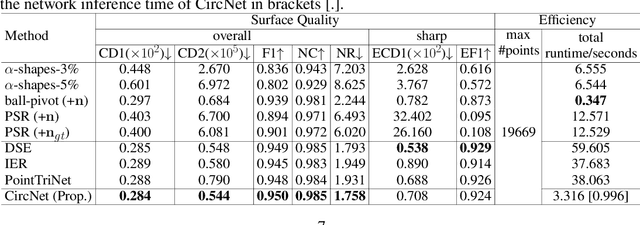
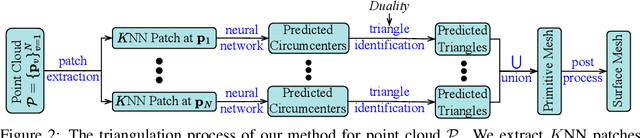
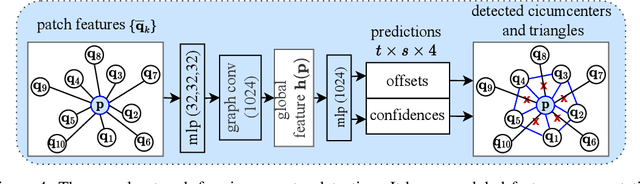
Reconstructing 3D point clouds into triangle meshes is a key problem in computational geometry and surface reconstruction. Point cloud triangulation solves this problem by providing edge information to the input points. Since no vertex interpolation is involved, it is beneficial to preserve sharp details on the surface. Taking advantage of learning-based techniques in triangulation, existing methods enumerate the complete combinations of candidate triangles, which is both complex and inefficient. In this paper, we leverage the duality between a triangle and its circumcenter, and introduce a deep neural network that detects the circumcenters to achieve point cloud triangulation. Specifically, we introduce multiple anchor priors to divide the neighborhood space of each point. The neural network then learns to predict the presences and locations of circumcenters under the guidance of those anchors. We extract the triangles dual to the detected circumcenters to form a primitive mesh, from which an edge-manifold mesh is produced via simple post-processing. Unlike existing learning-based triangulation methods, the proposed method bypasses an exhaustive enumeration of triangle combinations and local surface parameterization. We validate the efficiency, generalization, and robustness of our method on prominent datasets of both watertight and open surfaces. The code and trained models are provided at https://github.com/Ruitao-L/CircNet.
Mutual information estimation for graph convolutional neural networks
Mar 31, 2022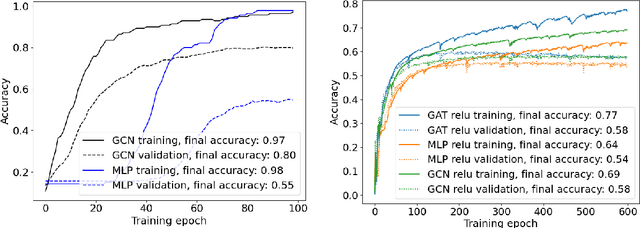
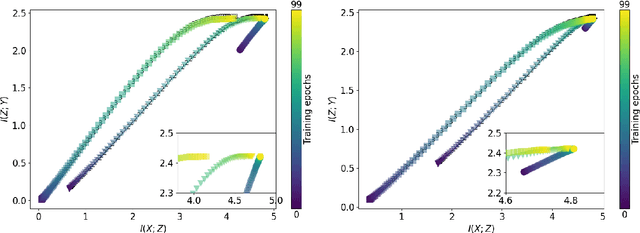
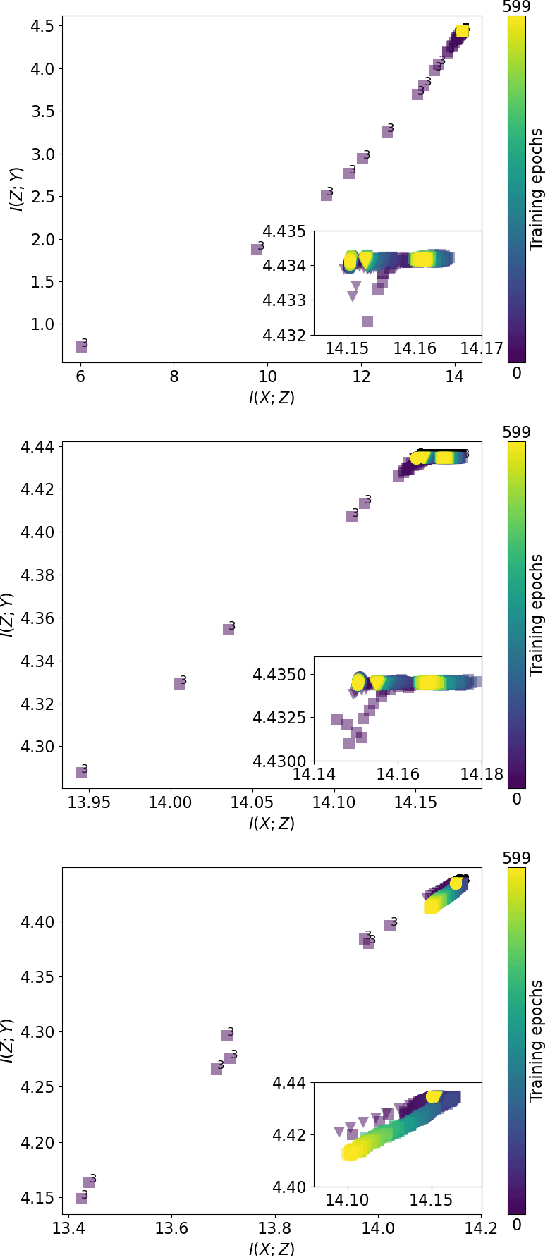
Measuring model performance is a key issue for deep learning practitioners. However, we often lack the ability to explain why a specific architecture attains superior predictive accuracy for a given data set. Often, validation accuracy is used as a performance heuristic quantifying how well a network generalizes to unseen data, but it does not capture anything about the information flow in the model. Mutual information can be used as a measure of the quality of internal representations in deep learning models, and the information plane may provide insights into whether the model exploits the available information in the data. The information plane has previously been explored for fully connected neural networks and convolutional architectures. We present an architecture-agnostic method for tracking a network's internal representations during training, which are then used to create the mutual information plane. The method is exemplified for graph-based neural networks fitted on citation data. We compare how the inductive bias introduced in graph-based architectures changes the mutual information plane relative to a fully connected neural network.
* Northern Lights Deep Learning proceedings, 8 pages, 3 figures
Recovering Surveillance Video Using RF Cues
Dec 27, 2022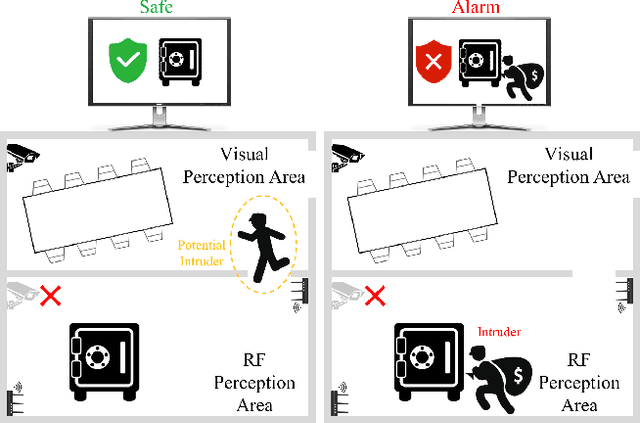
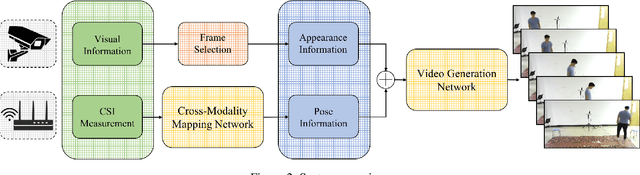
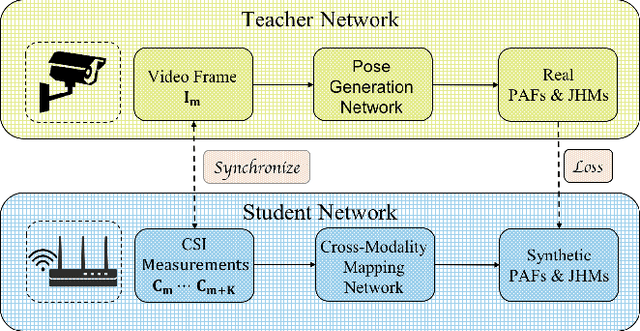

Video capture is the most extensively utilized human perception source due to its intuitively understandable nature. A desired video capture often requires multiple environmental conditions such as ample ambient-light, unobstructed space, and proper camera angle. In contrast, wireless measurements are more ubiquitous and have fewer environmental constraints. In this paper, we propose CSI2Video, a novel cross-modal method that leverages only WiFi signals from commercial devices and a source of human identity information to recover fine-grained surveillance video in a real-time manner. Specifically, two tailored deep neural networks are designed to conduct cross-modal mapping and video generation tasks respectively. We make use of an auto-encoder-based structure to extract pose features from WiFi frames. Afterward, both extracted pose features and identity information are merged to generate synthetic surveillance video. Our solution generates realistic surveillance videos without any expensive wireless equipment and has ubiquitous, cheap, and real-time characteristics.
Causal Falsification of Digital Twins
Jan 19, 2023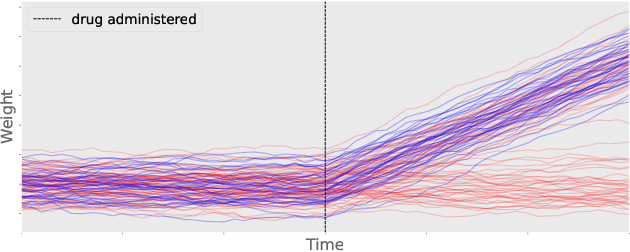
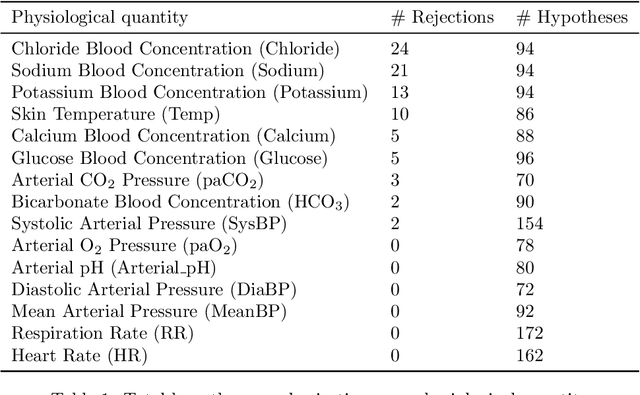
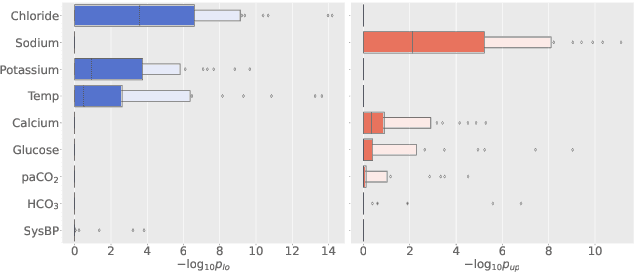
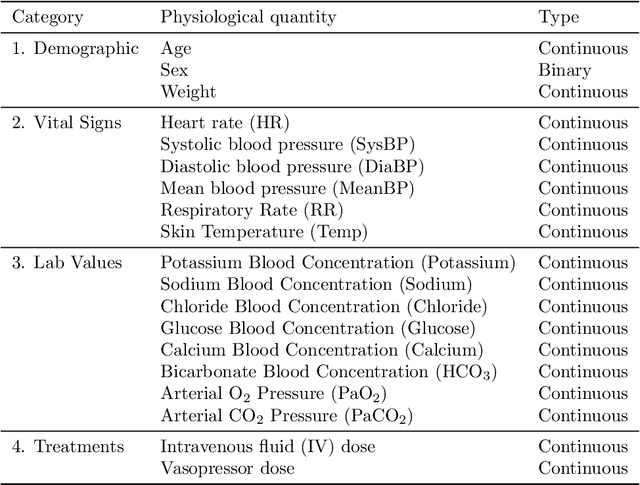
Digital twins hold substantial promise in many applications, but rigorous procedures for assessing their accuracy are essential for their widespread deployment in safety-critical settings. By formulating this task within the framework of causal inference, we show it is not possible to certify that a twin is "correct" using real-world observational data unless potentially tenuous assumptions are made about the data-generating process. To avoid these assumptions, we propose an assessment strategy that instead aims to find cases where the twin is not correct, and present a general-purpose statistical procedure for doing so that may be used across a wide variety of applications and twin models. Our approach yields reliable and actionable information about the twin under only the assumption of an i.i.d. dataset of real-world observations, and in particular remains sound even in the presence of arbitrary unmeasured confounding. We demonstrate the effectiveness of our methodology via a large-scale case study involving sepsis modelling within the Pulse Physiology Engine, which we assess using the MIMIC-III dataset of ICU patients.
ClusterLog: Clustering Logs for Effective Log-based Anomaly Detection
Jan 19, 2023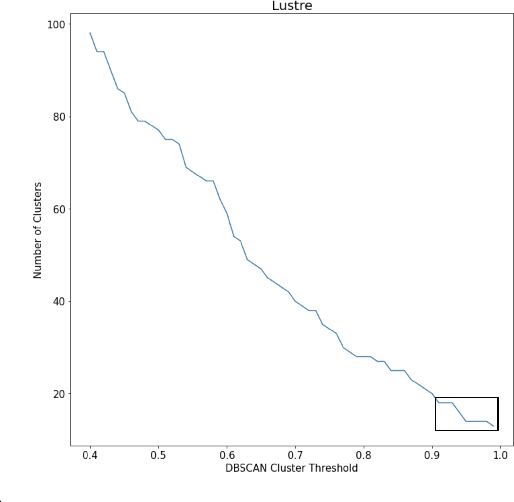
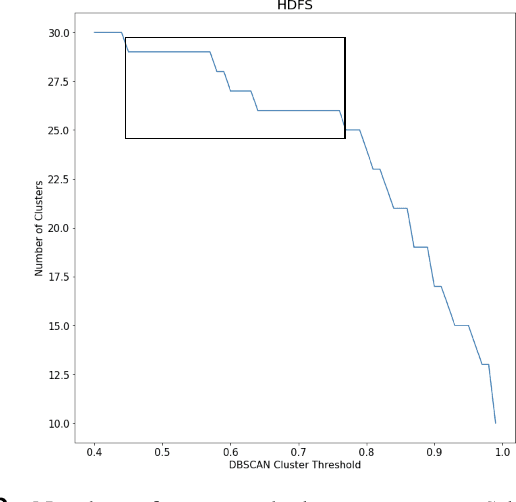
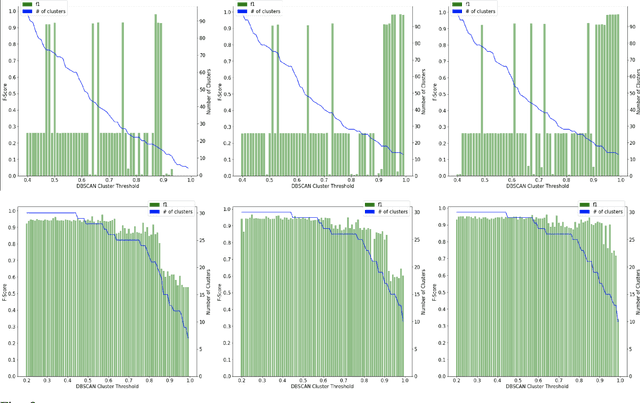
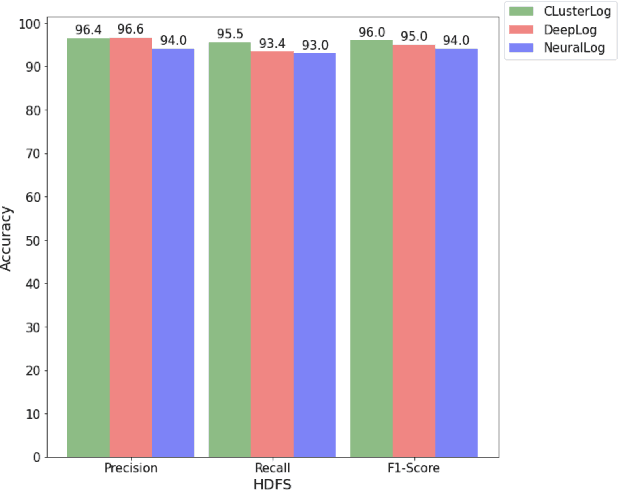
With the increasing prevalence of scalable file systems in the context of High Performance Computing (HPC), the importance of accurate anomaly detection on runtime logs is increasing. But as it currently stands, many state-of-the-art methods for log-based anomaly detection, such as DeepLog, have encountered numerous challenges when applied to logs from many parallel file systems (PFSes), often due to their irregularity and ambiguity in time-based log sequences. To circumvent these problems, this study proposes ClusterLog, a log pre-processing method that clusters the temporal sequence of log keys based on their semantic similarity. By grouping semantically and sentimentally similar logs, this approach aims to represent log sequences with the smallest amount of unique log keys, intending to improve the ability of a downstream sequence-based model to effectively learn the log patterns. The preliminary results of ClusterLog indicate not only its effectiveness in reducing the granularity of log sequences without the loss of important sequence information but also its generalizability to different file systems' logs.
Diagnose Like a Pathologist: Transformer-Enabled Hierarchical Attention-Guided Multiple Instance Learning for Whole Slide Image Classification
Jan 19, 2023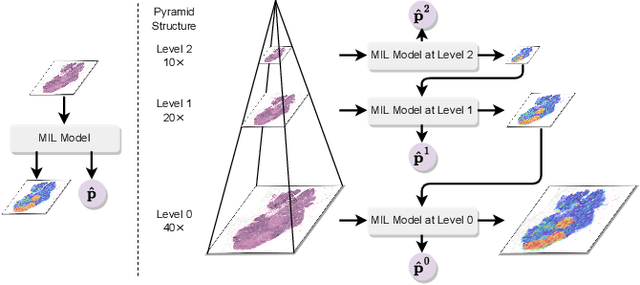

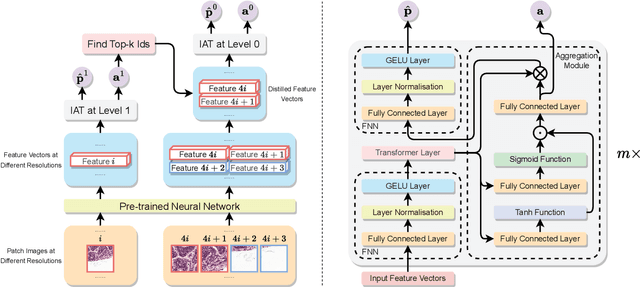
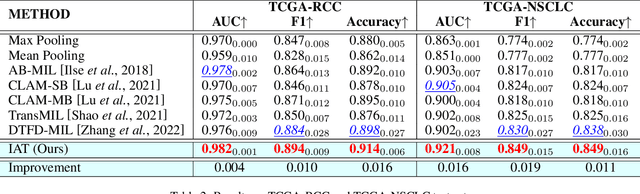
Multiple Instance Learning (MIL) and transformers are increasingly popular in histopathology Whole Slide Image (WSI) classification. However, unlike human pathologists who selectively observe specific regions of histopathology tissues under different magnifications, most methods do not incorporate multiple resolutions of the WSIs, hierarchically and attentively, thereby leading to a loss of focus on the WSIs and information from other resolutions. To resolve this issue, we propose the Hierarchical Attention-Guided Multiple Instance Learning framework to fully exploit the WSIs, which can dynamically and attentively discover the discriminative regions across multiple resolutions of the WSIs. Within this framework, to further enhance the performance of the transformer and obtain a more holistic WSI (bag) representation, we propose an Integrated Attention Transformer, consisting of multiple Integrated Attention Modules, which is the combination of a transformer layer and an aggregation module that produces a bag representation based on every instance representation in that bag. The results of the experiments show that our method achieved state-of-the-art performances on multiple datasets, including Camelyon16, TCGA-RCC, TCGA-NSCLC, and our in-house IMGC dataset.
FE-TCM: Filter-Enhanced Transformer Click Model for Web Search
Jan 19, 2023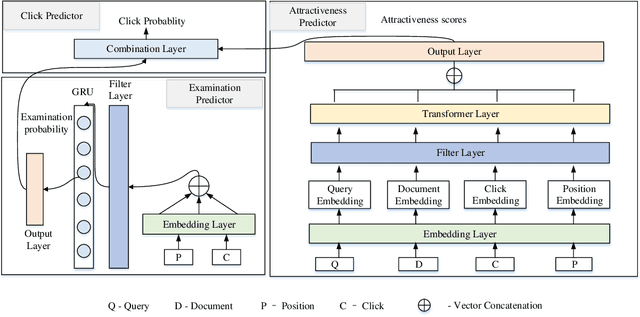


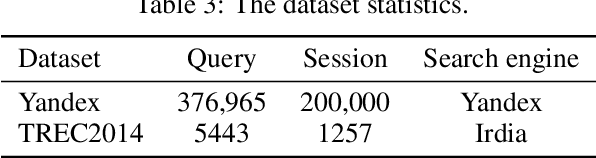
Constructing click models and extracting implicit relevance feedback information from the interaction between users and search engines are very important to improve the ranking of search results. Using neural network to model users' click behaviors has become one of the effective methods to construct click models. In this paper, We use Transformer as the backbone network of feature extraction, add filter layer innovatively, and propose a new Filter-Enhanced Transformer Click Model (FE-TCM) for web search. Firstly, in order to reduce the influence of noise on user behavior data, we use the learnable filters to filter log noise. Secondly, following the examination hypothesis, we model the attraction estimator and examination predictor respectively to output the attractiveness scores and examination probabilities. A novel transformer model is used to learn the deeper representation among different features. Finally, we apply the combination functions to integrate attractiveness scores and examination probabilities into the click prediction. From our experiments on two real-world session datasets, it is proved that FE-TCM outperforms the existing click models for the click prediction.