 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Unsupervised Representation Learning from Pre-trained Diffusion Probabilistic Models
Jan 01, 2023
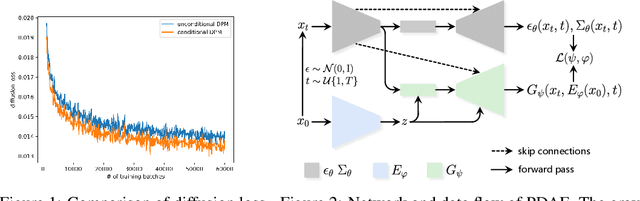
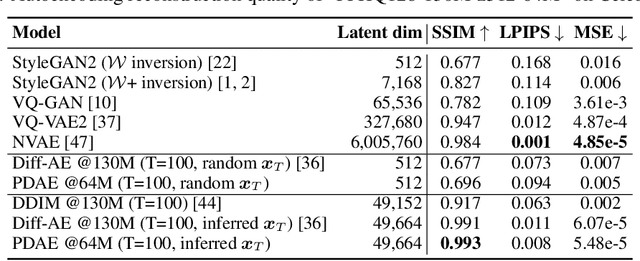


Diffusion Probabilistic Models (DPMs) have shown a powerful capacity of generating high-quality image samples. Recently, diffusion autoencoders (Diff-AE) have been proposed to explore DPMs for representation learning via autoencoding. Their key idea is to jointly train an encoder for discovering meaningful representations from images and a conditional DPM as the decoder for reconstructing images. Considering that training DPMs from scratch will take a long time and there have existed numerous pre-trained DPMs, we propose \textbf{P}re-trained \textbf{D}PM \textbf{A}uto\textbf{E}ncoding (\textbf{PDAE}), a general method to adapt existing pre-trained DPMs to the decoders for image reconstruction, with better training efficiency and performance than Diff-AE. Specifically, we find that the reason that pre-trained DPMs fail to reconstruct an image from its latent variables is due to the information loss of forward process, which causes a gap between their predicted posterior mean and the true one. From this perspective, the classifier-guided sampling method can be explained as computing an extra mean shift to fill the gap, reconstructing the lost class information in samples. These imply that the gap corresponds to the lost information of the image, and we can reconstruct the image by filling the gap. Drawing inspiration from this, we employ a trainable model to predict a mean shift according to encoded representation and train it to fill as much gap as possible, in this way, the encoder is forced to learn as much information as possible from images to help the filling. By reusing a part of network of pre-trained DPMs and redesigning the weighting scheme of diffusion loss, PDAE can learn meaningful representations from images efficiently. Extensive experiments demonstrate the effectiveness, efficiency and flexibility of PDAE.
Deteksi Depresi dan Kecemasan Pengguna Twitter Menggunakan Bidirectional LSTM
Jan 11, 2023The most common mental disorders experienced by a person in daily life are depression and anxiety. Social stigma makes people with depression and anxiety neglected by their surroundings. Therefore, they turn to social media like Twitter for support. Detecting users with potential depression and anxiety disorders through textual data is not easy because they do not explicitly discuss their mental state. It takes a model that can identify potential users who experience depression and anxiety on textual data to get treatment earlier. Text classification techniques can achieve this. One approach that can be used is LSTM as an RNN architecture development in dealing with vanishing gradient problems. Standard LSTM does not capture enough information because it can only read sentences from one direction. Meanwhile, Bidirectional LSTM (BiLSTM) is a two-way LSTM that can capture information without ignoring the context and meaning of a sentence. The proposed BiLSTM model is higher than all traditional machine learning models and standard LSTMs. Based on the test results, the highest accuracy obtained by BiLSTM reached 94.12%. This study has succeeded in developing a model for the detection of depression and anxiety in Twitter users.
Multi-UAV Path Learning for Age and Power Optimization in IoT with UAV Battery Recharge
Jan 09, 2023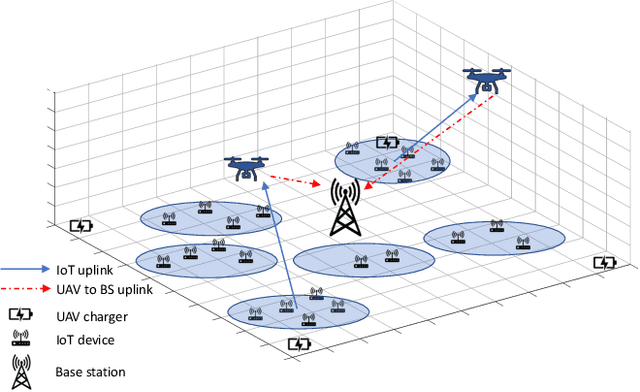
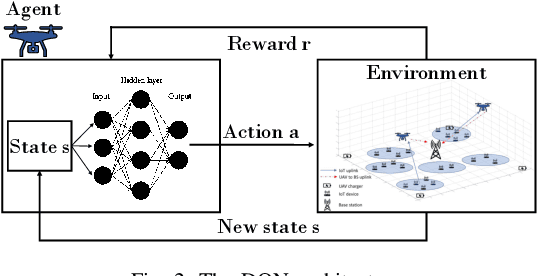
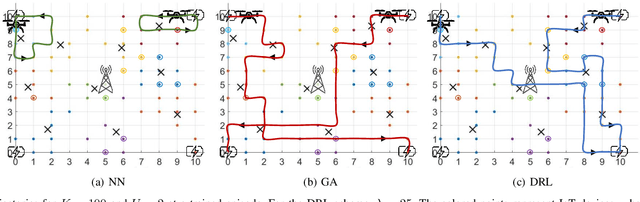
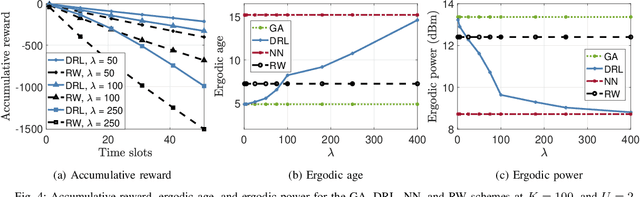
In many emerging Internet of Things (IoT) applications, the freshness of the is an important design criterion. Age of Information (AoI) quantifies the freshness of the received information or status update. This work considers a setup of deployed IoT devices in an IoT network; multiple unmanned aerial vehicles (UAVs) serve as mobile relay nodes between the sensors and the base station. We formulate an optimization problem to jointly plan the UAVs' trajectory, while minimizing the AoI of the received messages and the devices' energy consumption. The solution accounts for the UAVs' battery lifetime and flight time to recharging depots to ensure the UAVs' green operation. The complex optimization problem is efficiently solved using a deep reinforcement learning algorithm. In particular, we propose a deep Q-network, which works as a function approximation to estimate the state-action value function. The proposed scheme is quick to converge and results in a lower ergodic age and ergodic energy consumption when compared with benchmark algorithms such as greedy algorithm (GA), nearest neighbour (NN), and random-walk (RW).
De Novo Molecular Generation via Connection-aware Motif Mining
Feb 02, 2023
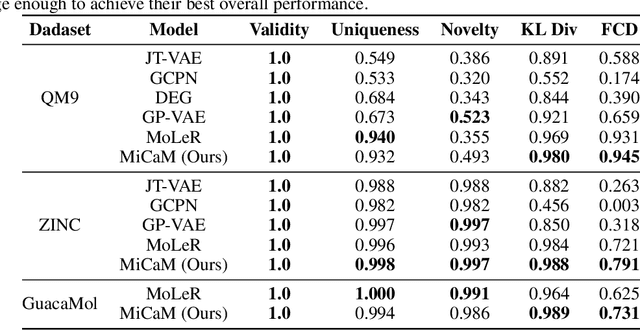
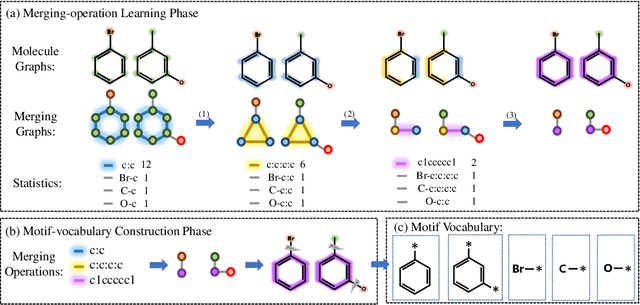
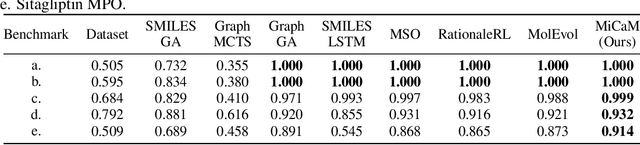
De novo molecular generation is an essential task for science discovery. Recently, fragment-based deep generative models have attracted much research attention due to their flexibility in generating novel molecules based on existing molecule fragments. However, the motif vocabulary, i.e., the collection of frequent fragments, is usually built upon heuristic rules, which brings difficulties to capturing common substructures from large amounts of molecules. In this work, we propose a new method, MiCaM, to generate molecules based on mined connection-aware motifs. Specifically, it leverages a data-driven algorithm to automatically discover motifs from a molecule library by iteratively merging subgraphs based on their frequency. The obtained motif vocabulary consists of not only molecular motifs (i.e., the frequent fragments), but also their connection information, indicating how the motifs are connected with each other. Based on the mined connection-aware motifs, MiCaM builds a connection-aware generator, which simultaneously picks up motifs and determines how they are connected. We test our method on distribution-learning benchmarks (i.e., generating novel molecules to resemble the distribution of a given training set) and goal-directed benchmarks (i.e., generating molecules with target properties), and achieve significant improvements over previous fragment-based baselines. Furthermore, we demonstrate that our method can effectively mine domain-specific motifs for different tasks.
Open-Set Multi-Source Multi-Target Domain Adaptation
Feb 02, 2023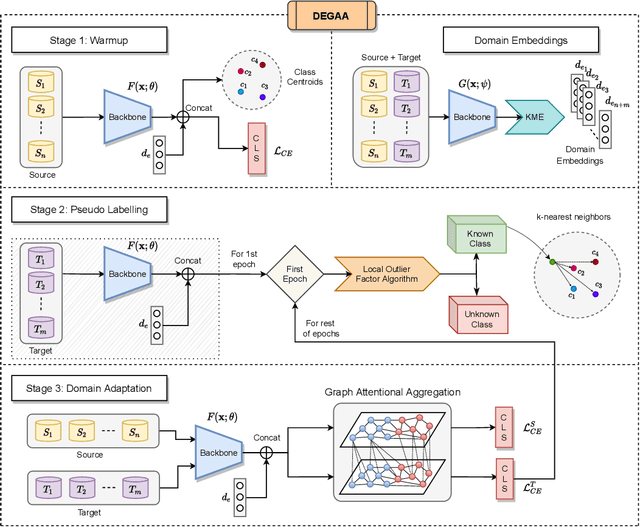
Single-Source Single-Target Domain Adaptation (1S1T) aims to bridge the gap between a labelled source domain and an unlabelled target domain. Despite 1S1T being a well-researched topic, they are typically not deployed to the real world. Methods like Multi-Source Domain Adaptation and Multi-Target Domain Adaptation have evolved to model real-world problems but still do not generalise well. The fact that most of these methods assume a common label-set between source and target is very restrictive. Recent Open-Set Domain Adaptation methods handle unknown target labels but fail to generalise in multiple domains. To overcome these difficulties, first, we propose a novel generic domain adaptation (DA) setting named Open-Set Multi-Source Multi-Target Domain Adaptation (OS-nSmT), with n and m being number of source and target domains respectively. Next, we propose a graph attention based framework named DEGAA which can capture information from multiple source and target domains without knowing the exact label-set of the target. We argue that our method, though offered for multiple sources and multiple targets, can also be agnostic to various other DA settings. To check the robustness and versatility of DEGAA, we put forward ample experiments and ablation studies.
GANalyzer: Analysis and Manipulation of GANs Latent Space for Controllable Face Synthesis
Feb 02, 2023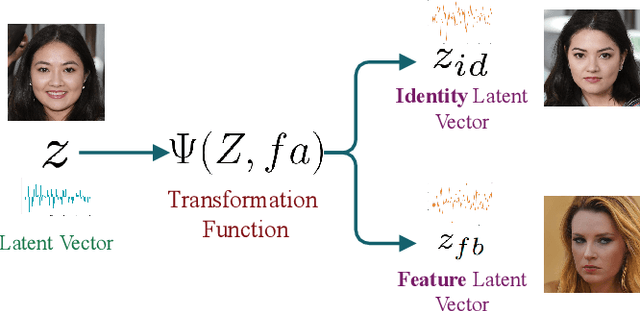

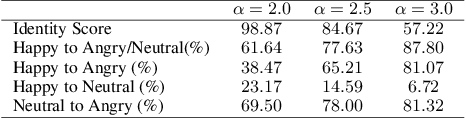

Generative Adversarial Networks (GANs) are capable of synthesizing high-quality facial images. Despite their success, GANs do not provide any information about the relationship between the input vectors and the generated images. Currently, facial GANs are trained on imbalanced datasets, which generate less diverse images. For example, more than 77% of 100K images that we randomly synthesized using the StyleGAN3 are classified as Happy, and only around 3% are Angry. The problem even becomes worse when a mixture of facial attributes is desired: less than 1% of the generated samples are Angry Woman, and only around 2% are Happy Black. To address these problems, this paper proposes a framework, called GANalyzer, for the analysis, and manipulation of the latent space of well-trained GANs. GANalyzer consists of a set of transformation functions designed to manipulate latent vectors for a specific facial attribute such as facial Expression, Age, Gender, and Race. We analyze facial attribute entanglement in the latent space of GANs and apply the proposed transformation for editing the disentangled facial attributes. Our experimental results demonstrate the strength of GANalyzer in editing facial attributes and generating any desired faces. We also create and release a balanced photo-realistic human face dataset. Our code is publicly available on GitHub.
Goal Alignment: A Human-Aware Account of Value Alignment Problem
Feb 02, 2023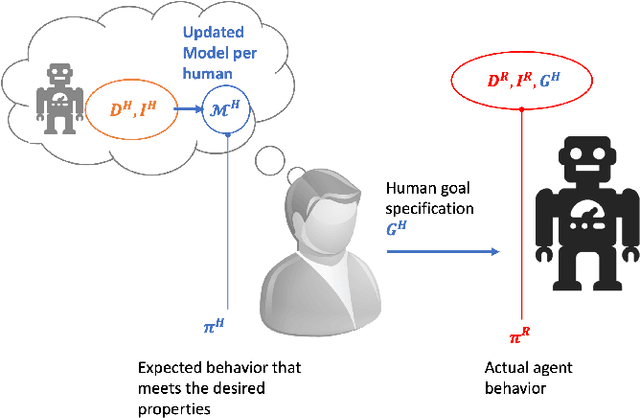
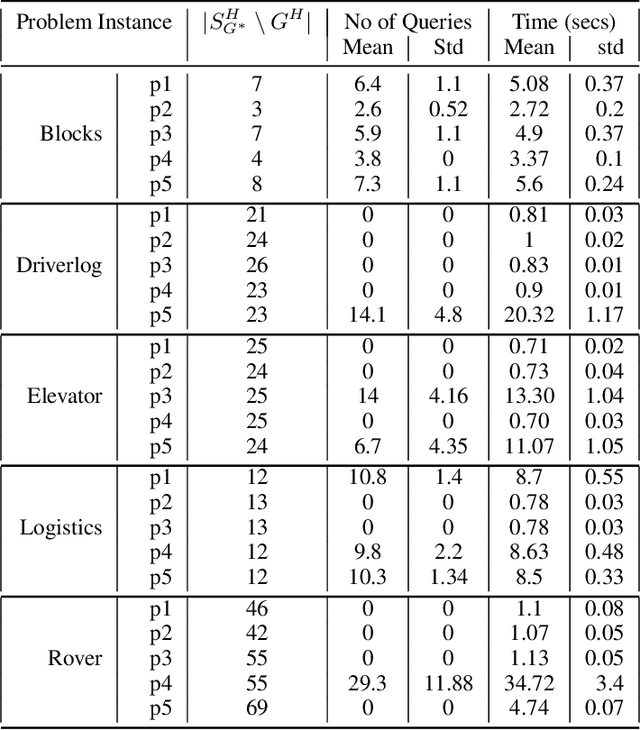
Value alignment problems arise in scenarios where the specified objectives of an AI agent don't match the true underlying objective of its users. The problem has been widely argued to be one of the central safety problems in AI. Unfortunately, most existing works in value alignment tend to focus on issues that are primarily related to the fact that reward functions are an unintuitive mechanism to specify objectives. However, the complexity of the objective specification mechanism is just one of many reasons why the user may have misspecified their objective. A foundational cause for misalignment that is being overlooked by these works is the inherent asymmetry in human expectations about the agent's behavior and the behavior generated by the agent for the specified objective. To address this lacuna, we propose a novel formulation for the value alignment problem, named goal alignment that focuses on a few central challenges related to value alignment. In doing so, we bridge the currently disparate research areas of value alignment and human-aware planning. Additionally, we propose a first-of-its-kind interactive algorithm that is capable of using information generated under incorrect beliefs about the agent, to determine the true underlying goal of the user.
Neural Common Neighbor with Completion for Link Prediction
Feb 02, 2023
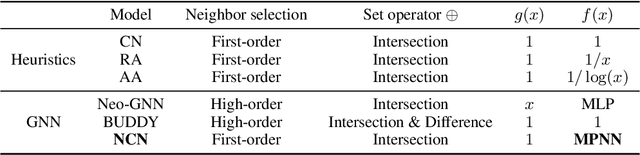
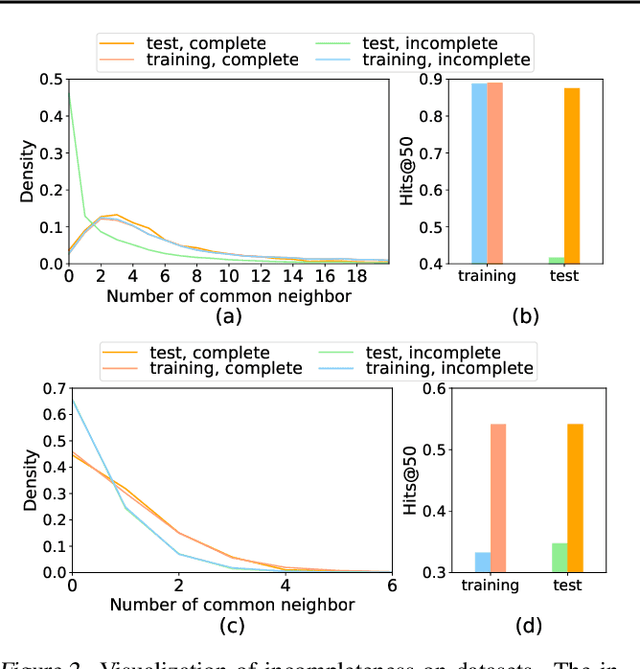
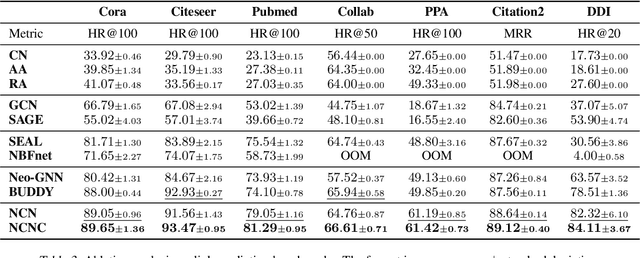
Despite its outstanding performance in various graph tasks, vanilla Message Passing Neural Network (MPNN) usually fails in link prediction tasks, as it only uses representations of two individual target nodes and ignores the pairwise relation between them. To capture the pairwise relations, some models add manual features to the input graph and use the output of MPNN to produce pairwise representations. In contrast, others directly use manual features as pairwise representations. Though this simplification avoids applying a GNN to each link individually and thus improves scalability, these models still have much room for performance improvement due to the hand-crafted and unlearnable pairwise features. To upgrade performance while maintaining scalability, we propose Neural Common Neighbor (NCN), which uses learnable pairwise representations. To further boost NCN, we study the unobserved link problem. The incompleteness of the graph is ubiquitous and leads to distribution shifts between the training and test set, loss of common neighbor information, and performance degradation of models. Therefore, we propose two intervention methods: common neighbor completion and target link removal. Combining the two methods with NCN, we propose Neural Common Neighbor with Completion (NCNC). NCN and NCNC outperform recent strong baselines by large margins. NCNC achieves state-of-the-art performance in link prediction tasks.
Practical Differentially Private Hyperparameter Tuning with Subsampling
Jan 27, 2023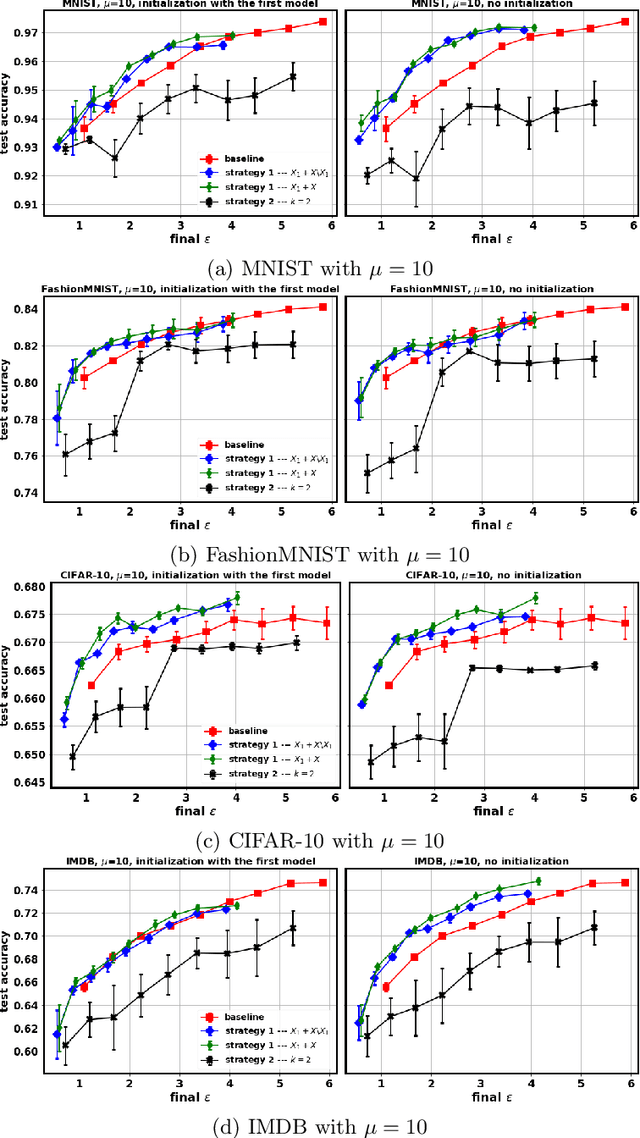
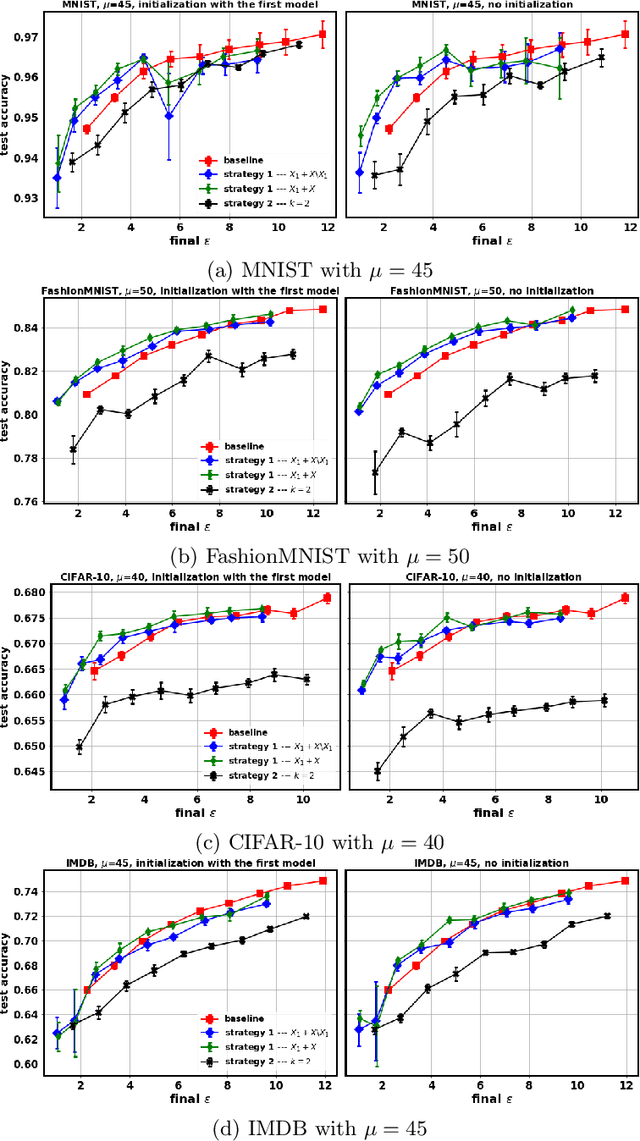

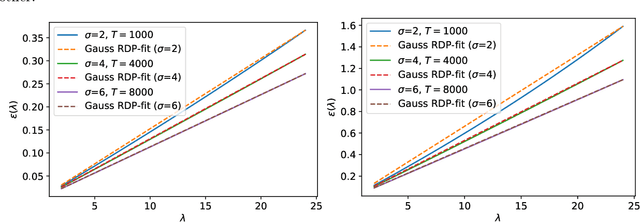
Tuning all the hyperparameters of differentially private (DP) machine learning (ML) algorithms often requires use of sensitive data and this may leak private information via hyperparameter values. Recently, Papernot and Steinke (2022) proposed a certain class of DP hyperparameter tuning algorithms, where the number of random search samples is randomized itself. Commonly, these algorithms still considerably increase the DP privacy parameter $\varepsilon$ over non-tuned DP ML model training and can be computationally heavy as evaluating each hyperparameter candidate requires a new training run. We focus on lowering both the DP bounds and the computational complexity of these methods by using only a random subset of the sensitive data for the hyperparameter tuning and by extrapolating the optimal values from the small dataset to a larger dataset. We provide a R\'enyi differential privacy analysis for the proposed method and experimentally show that it consistently leads to better privacy-utility trade-off than the baseline method by Papernot and Steinke (2022).
Candidate Soups: Fusing Candidate Results Improves Translation Quality for Non-Autoregressive Translation
Jan 27, 2023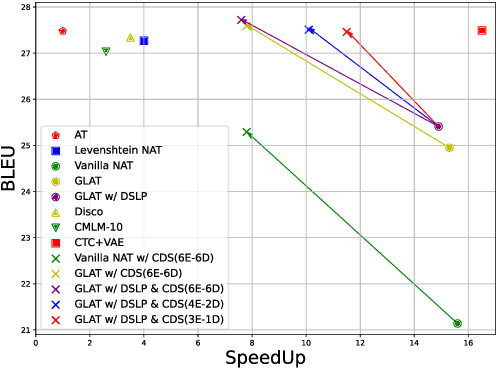
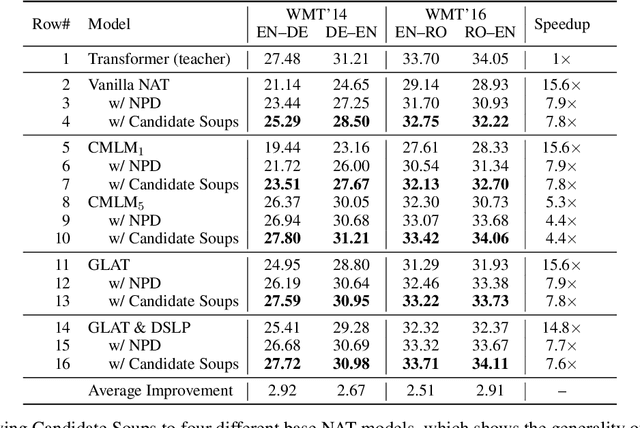

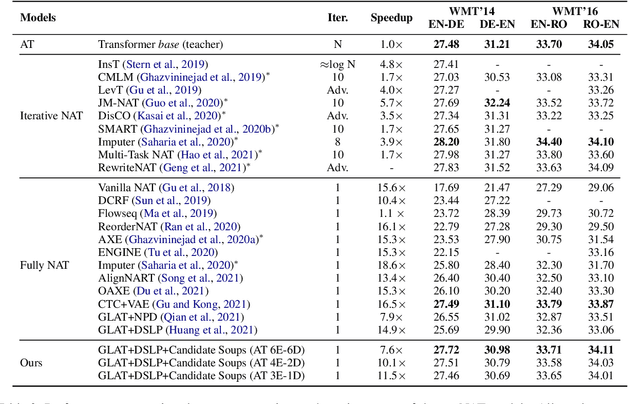
Non-autoregressive translation (NAT) model achieves a much faster inference speed than the autoregressive translation (AT) model because it can simultaneously predict all tokens during inference. However, its translation quality suffers from degradation compared to AT. And existing NAT methods only focus on improving the NAT model's performance but do not fully utilize it. In this paper, we propose a simple but effective method called "Candidate Soups," which can obtain high-quality translations while maintaining the inference speed of NAT models. Unlike previous approaches that pick the individual result and discard the remainders, Candidate Soups (CDS) can fully use the valuable information in the different candidate translations through model uncertainty. Extensive experiments on two benchmarks (WMT'14 EN-DE and WMT'16 EN-RO) demonstrate the effectiveness and generality of our proposed method, which can significantly improve the translation quality of various base models. More notably, our best variant outperforms the AT model on three translation tasks with 7.6 times speedup.