 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
VANP: Learning Where to See for Navigation with Self-Supervised Vision-Action Pre-Training
Mar 12, 2024

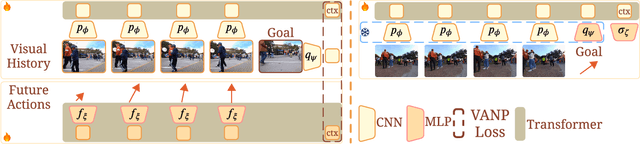

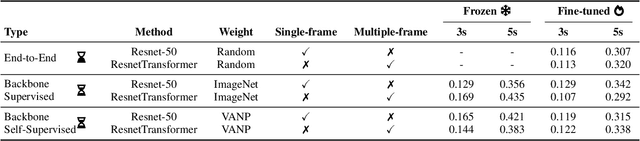
Humans excel at efficiently navigating through crowds without collision by focusing on specific visual regions relevant to navigation. However, most robotic visual navigation methods rely on deep learning models pre-trained on vision tasks, which prioritize salient objects -- not necessarily relevant to navigation and potentially misleading. Alternative approaches train specialized navigation models from scratch, requiring significant computation. On the other hand, self-supervised learning has revolutionized computer vision and natural language processing, but its application to robotic navigation remains underexplored due to the difficulty of defining effective self-supervision signals. Motivated by these observations, in this work, we propose a Self-Supervised Vision-Action Model for Visual Navigation Pre-Training (VANP). Instead of detecting salient objects that are beneficial for tasks such as classification or detection, VANP learns to focus only on specific visual regions that are relevant to the navigation task. To achieve this, VANP uses a history of visual observations, future actions, and a goal image for self-supervision, and embeds them using two small Transformer Encoders. Then, VANP maximizes the information between the embeddings by using a mutual information maximization objective function. We demonstrate that most VANP-extracted features match with human navigation intuition. VANP achieves comparable performance as models learned end-to-end with half the training time and models trained on a large-scale, fully supervised dataset, i.e., ImageNet, with only 0.08% data.
Frequency Decoupling for Motion Magnification via Multi-Level Isomorphic Architecture
Mar 12, 2024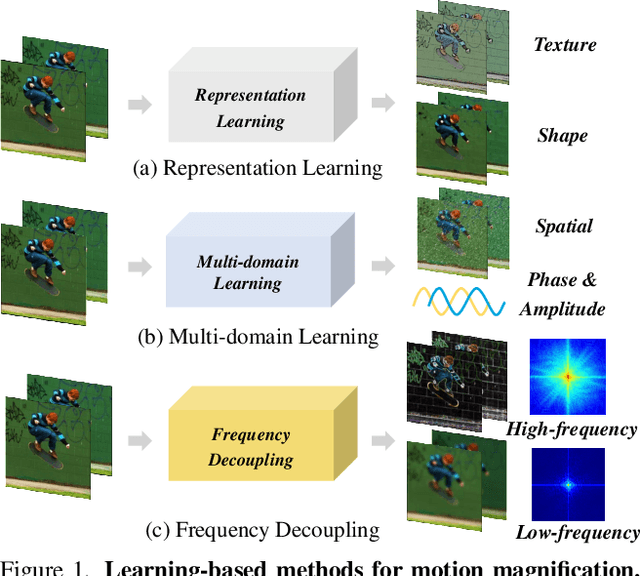
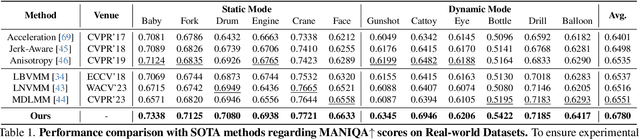
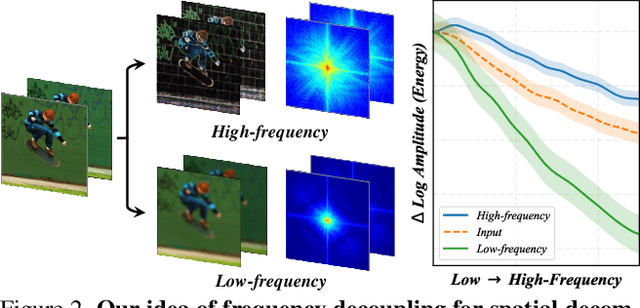
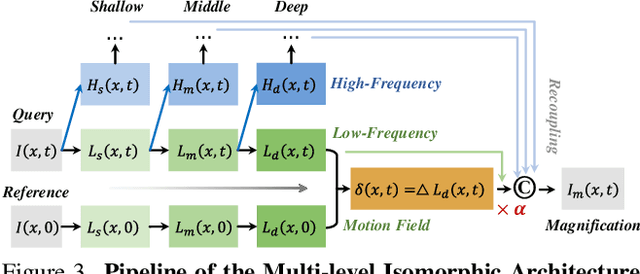
Video Motion Magnification (VMM) aims to reveal subtle and imperceptible motion information of objects in the macroscopic world. Prior methods directly model the motion field from the Eulerian perspective by Representation Learning that separates shape and texture or Multi-domain Learning from phase fluctuations. Inspired by the frequency spectrum, we observe that the low-frequency components with stable energy always possess spatial structure and less noise, making them suitable for modeling the subtle motion field. To this end, we present FD4MM, a new paradigm of Frequency Decoupling for Motion Magnification with a Multi-level Isomorphic Architecture to capture multi-level high-frequency details and a stable low-frequency structure (motion field) in video space. Since high-frequency details and subtle motions are susceptible to information degradation due to their inherent subtlety and unavoidable external interference from noise, we carefully design Sparse High/Low-pass Filters to enhance the integrity of details and motion structures, and a Sparse Frequency Mixer to promote seamless recoupling. Besides, we innovatively design a contrastive regularization for this task to strengthen the model's ability to discriminate irrelevant features, reducing undesired motion magnification. Extensive experiments on both Real-world and Synthetic Datasets show that our FD4MM outperforms SOTA methods. Meanwhile, FD4MM reduces FLOPs by 1.63$\times$ and boosts inference speed by 1.68$\times$ than the latest method. Our code is available at https://github.com/Jiafei127/FD4MM.
Local positional graphs and attentive local features for a data and runtime-efficient hierarchical place recognition pipeline
Mar 15, 2024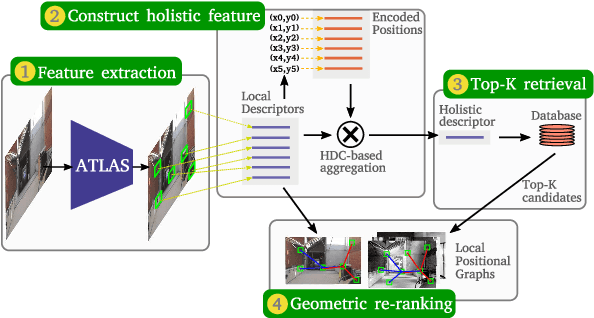
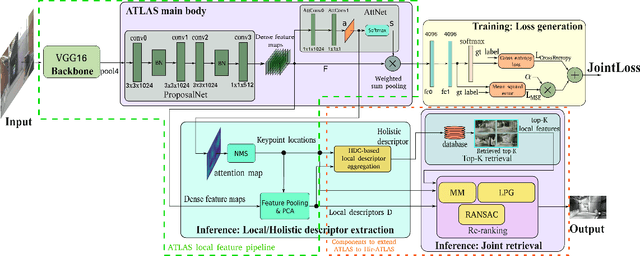

Large-scale applications of Visual Place Recognition (VPR) require computationally efficient approaches. Further, a well-balanced combination of data-based and training-free approaches can decrease the required amount of training data and effort and can reduce the influence of distribution shifts between the training and application phases. This paper proposes a runtime and data-efficient hierarchical VPR pipeline that extends existing approaches and presents novel ideas. There are three main contributions: First, we propose Local Positional Graphs (LPG), a training-free and runtime-efficient approach to encode spatial context information of local image features. LPG can be combined with existing local feature detectors and descriptors and considerably improves the image-matching quality compared to existing techniques in our experiments. Second, we present Attentive Local SPED (ATLAS), an extension of our previous local features approach with an attention module that improves the feature quality while maintaining high data efficiency. The influence of the proposed modifications is evaluated in an extensive ablation study. Third, we present a hierarchical pipeline that exploits hyperdimensional computing to use the same local features as holistic HDC-descriptors for fast candidate selection and for candidate reranking. We combine all contributions in a runtime and data-efficient VPR pipeline that shows benefits over the state-of-the-art method Patch-NetVLAD on a large collection of standard place recognition datasets with 15$\%$ better performance in VPR accuracy, 54$\times$ faster feature comparison speed, and 55$\times$ less descriptor storage occupancy, making our method promising for real-world high-performance large-scale VPR in changing environments. Code will be made available with publication of this paper.
Smart Resource Allocation at mmWave/THz Frequencies with Cooperative Rate-Splitting
Mar 14, 2024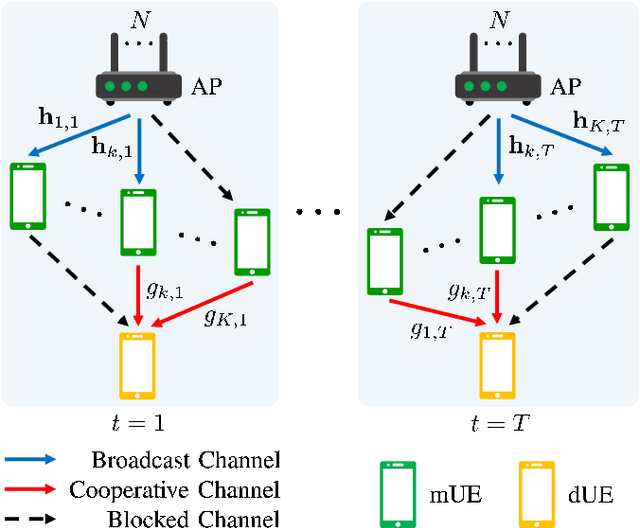
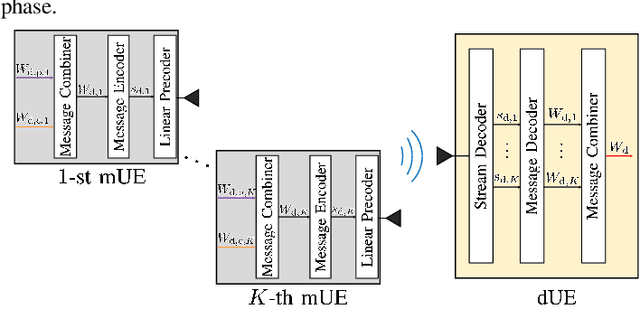
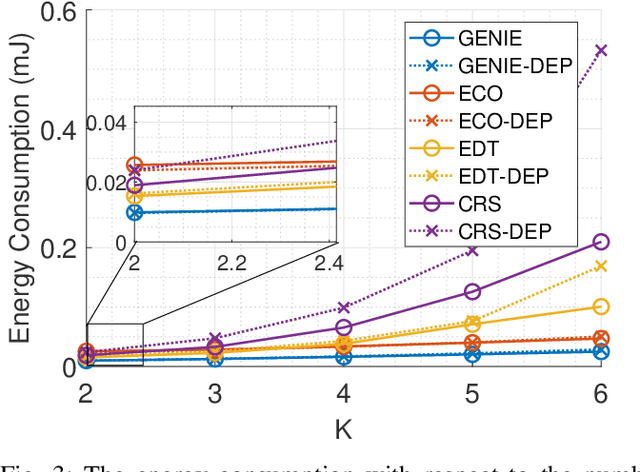
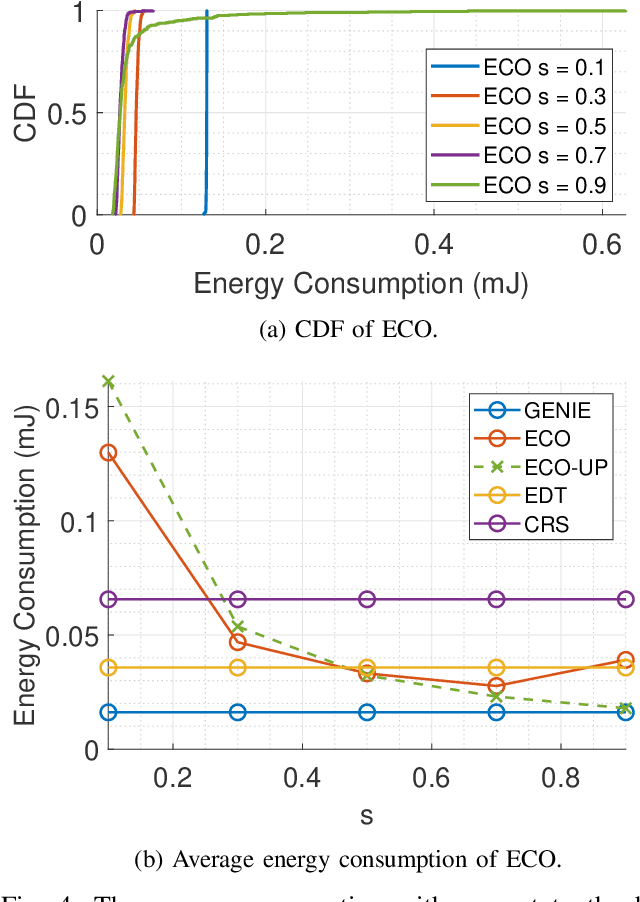
In this paper, we propose algorithms to minimize the energy consumption in millimeter wave/terahertz multi-user downlink communication systems. To ensure coverage in blockage-vulnerable high frequency systems, we consider cooperative rate-splitting (CRS) and transmission over multiple time blocks, where via CRS, multiple users cooperate to assist a blocked user. Moreover, we show that transmission over multiple time blocks provides benefits through smart resource allocation. We first propose a communication framework named improved distinct extraction-based CRS (iDeCRS) that utilizes the benefits of rate-splitting. With our transmission framework, we derive a performance benchmark assuming genie channel state information (CSI), i.e., the channels of the present and future time blocks are known, denoted as GENIE. Using the results from GENIE, we derive a novel efficiency constrained optimization (ECO) algorithm assuming instantaneous CSI. In addition, a simple but effective even data transmission (EDT) algorithm that promotes steady transmission along the time blocks is proposed. Simulation results show that ECO and EDT have satisfactory performances compared to GENIE. The results also show that ECO outperforms EDT when many users are cooperating, and vise versa.
From Graph to Word Bag: Introducing Domain Knowledge to Confusing Charge Prediction
Mar 14, 2024
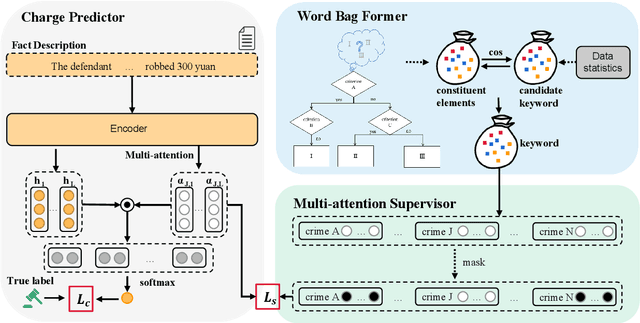
Confusing charge prediction is a challenging task in legal AI, which involves predicting confusing charges based on fact descriptions. While existing charge prediction methods have shown impressive performance, they face significant challenges when dealing with confusing charges, such as Snatch and Robbery. In the legal domain, constituent elements play a pivotal role in distinguishing confusing charges. Constituent elements are fundamental behaviors underlying criminal punishment and have subtle distinctions among charges. In this paper, we introduce a novel From Graph to Word Bag (FWGB) approach, which introduces domain knowledge regarding constituent elements to guide the model in making judgments on confusing charges, much like a judge's reasoning process. Specifically, we first construct a legal knowledge graph containing constituent elements to help select keywords for each charge, forming a word bag. Subsequently, to guide the model's attention towards the differentiating information for each charge within the context, we expand the attention mechanism and introduce a new loss function with attention supervision through words in the word bag. We construct the confusing charges dataset from real-world judicial documents. Experiments demonstrate the effectiveness of our method, especially in maintaining exceptional performance in imbalanced label distributions.
Diffusion-TS: Interpretable Diffusion for General Time Series Generation
Mar 14, 2024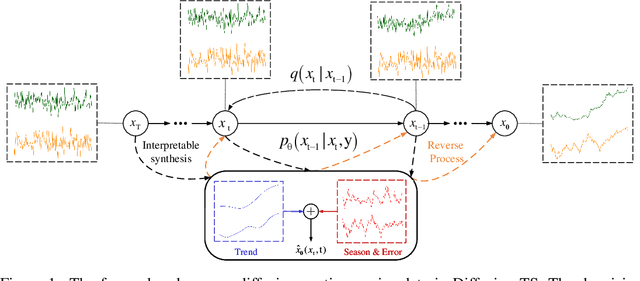
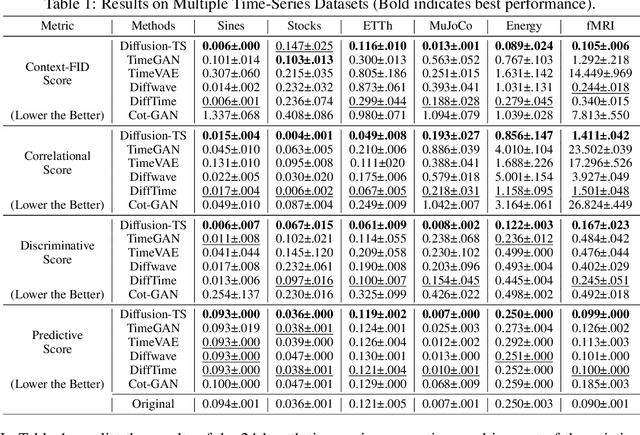
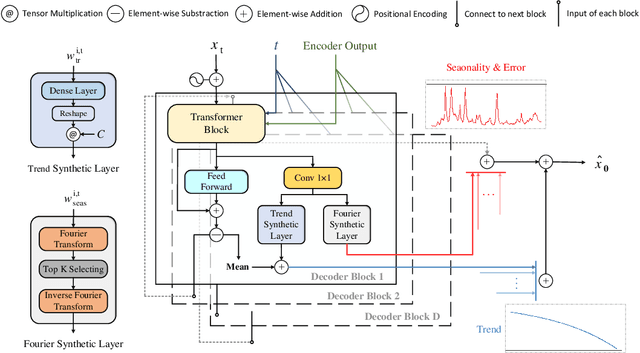
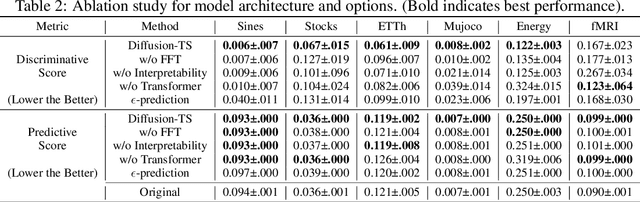
Denoising diffusion probabilistic models (DDPMs) are becoming the leading paradigm for generative models. It has recently shown breakthroughs in audio synthesis, time series imputation and forecasting. In this paper, we propose Diffusion-TS, a novel diffusion-based framework that generates multivariate time series samples of high quality by using an encoder-decoder transformer with disentangled temporal representations, in which the decomposition technique guides Diffusion-TS to capture the semantic meaning of time series while transformers mine detailed sequential information from the noisy model input. Different from existing diffusion-based approaches, we train the model to directly reconstruct the sample instead of the noise in each diffusion step, combining a Fourier-based loss term. Diffusion-TS is expected to generate time series satisfying both interpretablity and realness. In addition, it is shown that the proposed Diffusion-TS can be easily extended to conditional generation tasks, such as forecasting and imputation, without any model changes. This also motivates us to further explore the performance of Diffusion-TS under irregular settings. Finally, through qualitative and quantitative experiments, results show that Diffusion-TS achieves the state-of-the-art results on various realistic analyses of time series.
Attention-based Class-Conditioned Alignment for Multi-Source Domain Adaptive Object Detection
Mar 14, 2024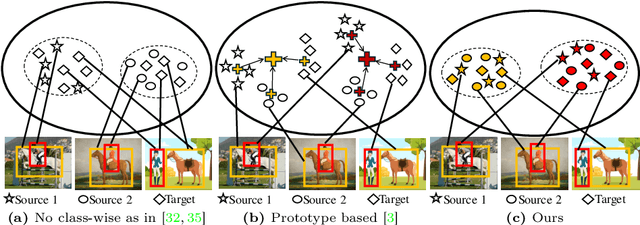

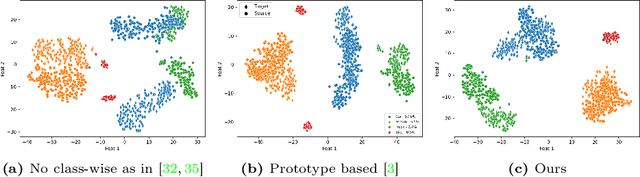
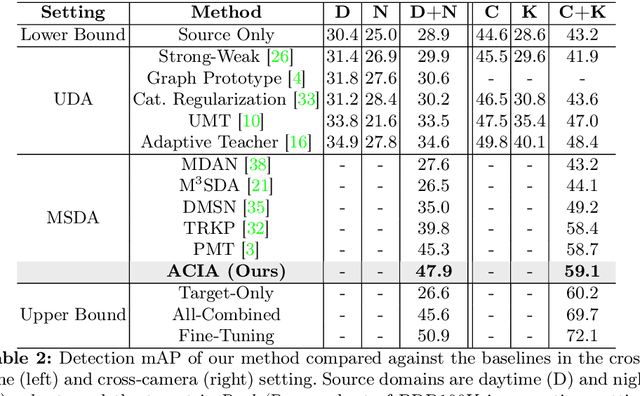
Domain adaptation methods for object detection (OD) strive to mitigate the impact of distribution shifts by promoting feature alignment across source and target domains. Multi-source domain adaptation (MSDA) allows leveraging multiple annotated source datasets, and unlabeled target data to improve the accuracy and robustness of the detection model. Most state-of-the-art MSDA methods for OD perform feature alignment in a class-agnostic manner. This is challenging since the objects have unique modal information due to variations in object appearance across domains. A recent prototype-based approach proposed a class-wise alignment, yet it suffers from error accumulation due to noisy pseudo-labels which can negatively affect adaptation with imbalanced data. To overcome these limitations, we propose an attention-based class-conditioned alignment scheme for MSDA that aligns instances of each object category across domains. In particular, an attention module coupled with an adversarial domain classifier allows learning domain-invariant and class-specific instance representations. Experimental results on multiple benchmarking MSDA datasets indicate that our method outperforms the state-of-the-art methods and is robust to class imbalance. Our code is available at https://github.com/imatif17/ACIA.
DF4LCZ: A SAM-Empowered Data Fusion Framework for Scene-Level Local Climate Zone Classification
Mar 14, 2024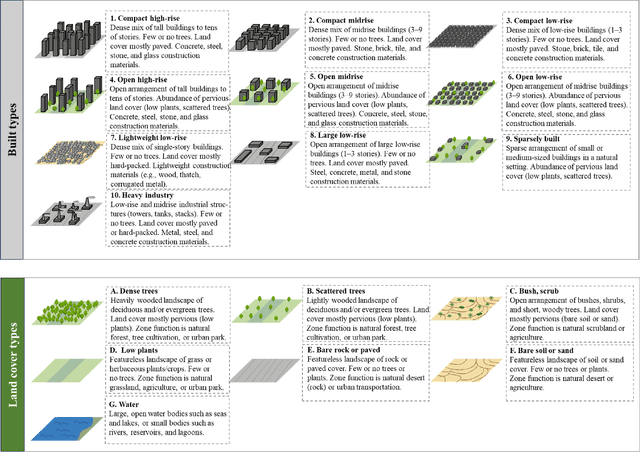
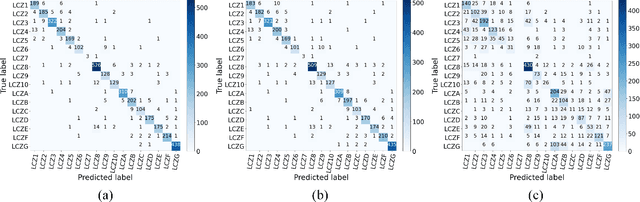
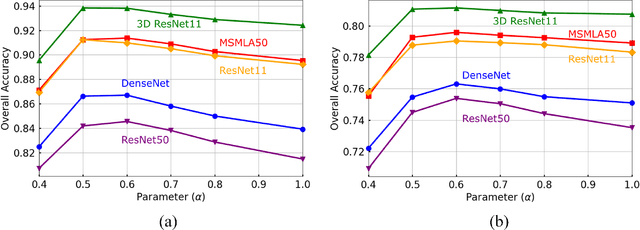
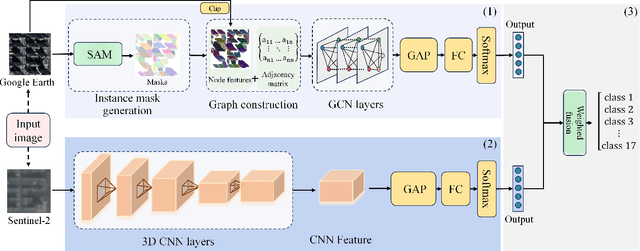
Recent advancements in remote sensing (RS) technologies have shown their potential in accurately classifying local climate zones (LCZs). However, traditional scene-level methods using convolutional neural networks (CNNs) often struggle to integrate prior knowledge of ground objects effectively. Moreover, commonly utilized data sources like Sentinel-2 encounter difficulties in capturing detailed ground object information. To tackle these challenges, we propose a data fusion method that integrates ground object priors extracted from high-resolution Google imagery with Sentinel-2 multispectral imagery. The proposed method introduces a novel Dual-stream Fusion framework for LCZ classification (DF4LCZ), integrating instance-based location features from Google imagery with the scene-level spatial-spectral features extracted from Sentinel-2 imagery. The framework incorporates a Graph Convolutional Network (GCN) module empowered by the Segment Anything Model (SAM) to enhance feature extraction from Google imagery. Simultaneously, the framework employs a 3D-CNN architecture to learn the spectral-spatial features of Sentinel-2 imagery. Experiments are conducted on a multi-source remote sensing image dataset specifically designed for LCZ classification, validating the effectiveness of the proposed DF4LCZ. The related code and dataset are available at https://github.com/ctrlovefly/DF4LCZ.
Soften to Defend: Towards Adversarial Robustness via Self-Guided Label Refinement
Mar 14, 2024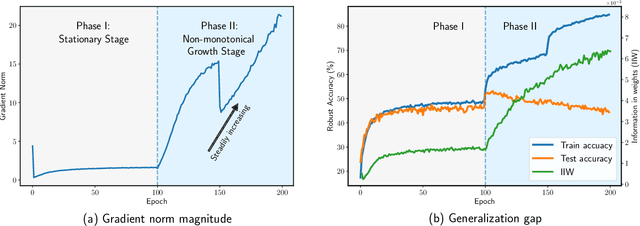

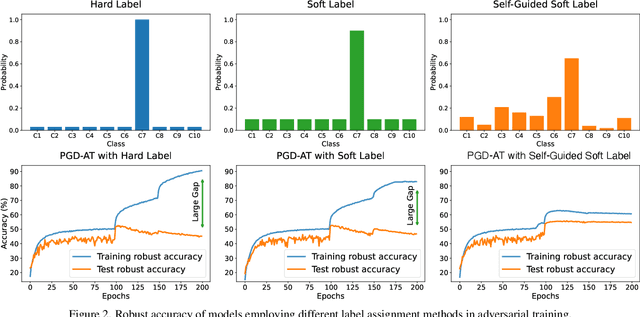
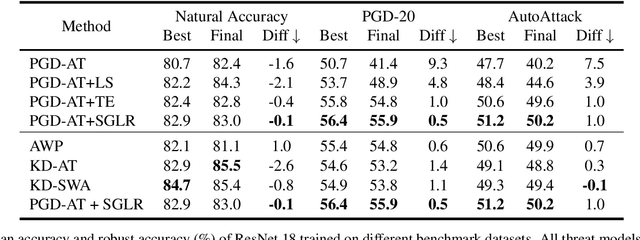
Adversarial training (AT) is currently one of the most effective ways to obtain the robustness of deep neural networks against adversarial attacks. However, most AT methods suffer from robust overfitting, i.e., a significant generalization gap in adversarial robustness between the training and testing curves. In this paper, we first identify a connection between robust overfitting and the excessive memorization of noisy labels in AT from a view of gradient norm. As such label noise is mainly caused by a distribution mismatch and improper label assignments, we are motivated to propose a label refinement approach for AT. Specifically, our Self-Guided Label Refinement first self-refines a more accurate and informative label distribution from over-confident hard labels, and then it calibrates the training by dynamically incorporating knowledge from self-distilled models into the current model and thus requiring no external teachers. Empirical results demonstrate that our method can simultaneously boost the standard accuracy and robust performance across multiple benchmark datasets, attack types, and architectures. In addition, we also provide a set of analyses from the perspectives of information theory to dive into our method and suggest the importance of soft labels for robust generalization.
Touch-GS: Visual-Tactile Supervised 3D Gaussian Splatting
Mar 14, 2024
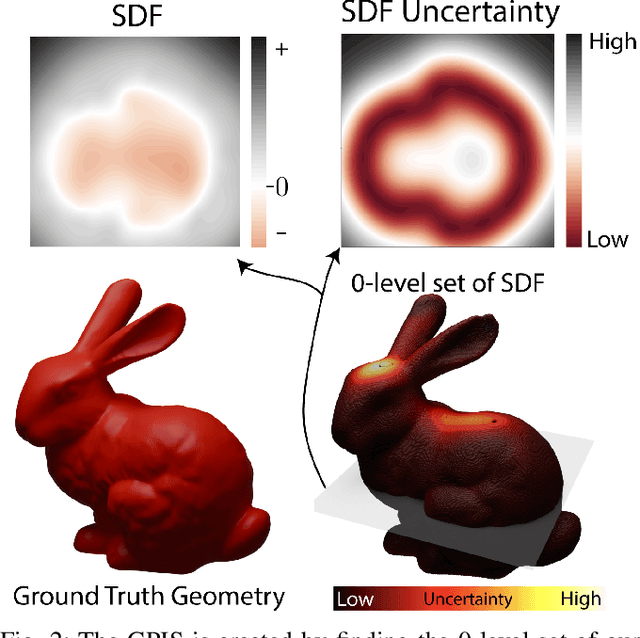
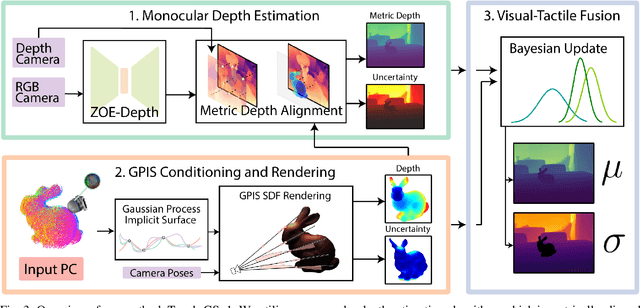
In this work, we propose a novel method to supervise 3D Gaussian Splatting (3DGS) scenes using optical tactile sensors. Optical tactile sensors have become widespread in their use in robotics for manipulation and object representation; however, raw optical tactile sensor data is unsuitable to directly supervise a 3DGS scene. Our representation leverages a Gaussian Process Implicit Surface to implicitly represent the object, combining many touches into a unified representation with uncertainty. We merge this model with a monocular depth estimation network, which is aligned in a two stage process, coarsely aligning with a depth camera and then finely adjusting to match our touch data. For every training image, our method produces a corresponding fused depth and uncertainty map. Utilizing this additional information, we propose a new loss function, variance weighted depth supervised loss, for training the 3DGS scene model. We leverage the DenseTact optical tactile sensor and RealSense RGB-D camera to show that combining touch and vision in this manner leads to quantitatively and qualitatively better results than vision or touch alone in a few-view scene syntheses on opaque as well as on reflective and transparent objects. Please see our project page at http://armlabstanford.github.io/touch-gs