 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Detecting Histologic Glioblastoma Regions of Prognostic Relevance
Feb 01, 2023
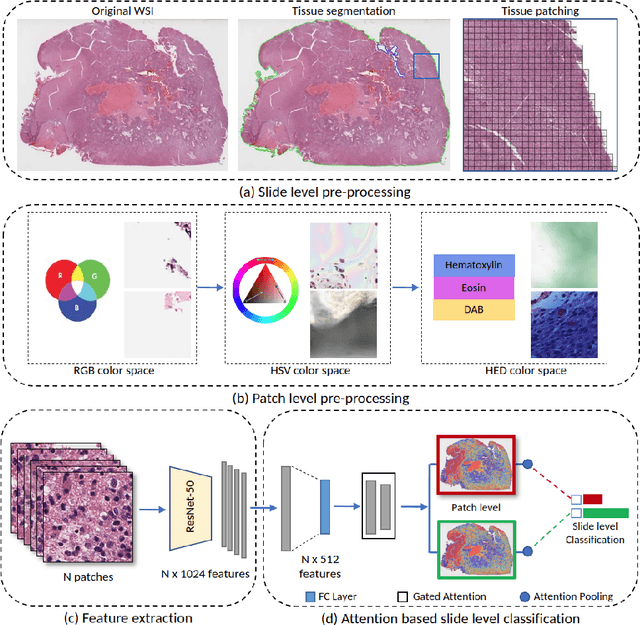
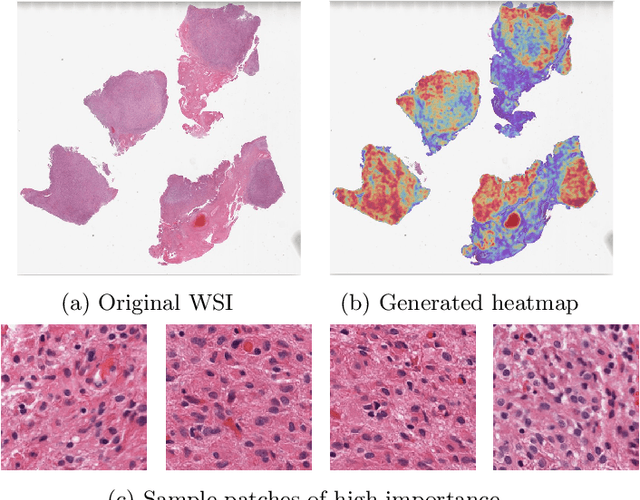

Glioblastoma is the most common and aggressive malignant adult tumor of the central nervous system, with grim prognosis and heterogeneous morphologic and molecular profiles. Since the adoption of the current standard of care treatment, 18 years ago, there are no substantial prognostic improvements noticed. Accurate prediction of patient overall survival (OS) from clinical histopathology whole slide images (WSI) using advanced computational methods could contribute to optimization of clinical decision making and patient management. Here, we focus on identifying prognostically relevant glioblastoma morphologic patterns on H&E stained WSI. The exact approach capitalizes on the comprehensive WSI curation of apparent artifactual content and on an interpretability mechanism via a weakly supervised attention based multiple instance learning algorithm that further utilizes clustering to constrain the search space. The automatically identified patterns of high diagnostic value are used to classify the WSI as representative of a short or a long survivor. Identifying tumor morphologic patterns associated with short and long OS will allow the clinical neuropathologist to provide additional prognostic information gleaned during microscopic assessment to the treating team, as well as suggest avenues of biological investigation for understanding and potentially treating glioblastoma.
Graph Neural Operators for Classification of Spatial Transcriptomics Data
Feb 01, 2023
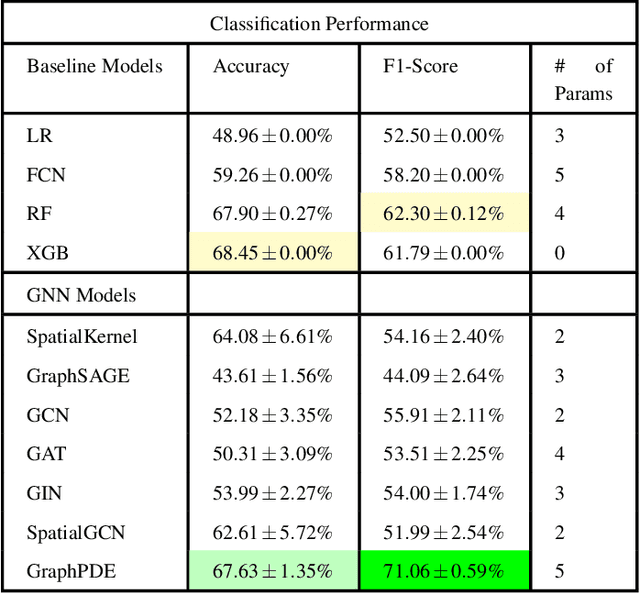
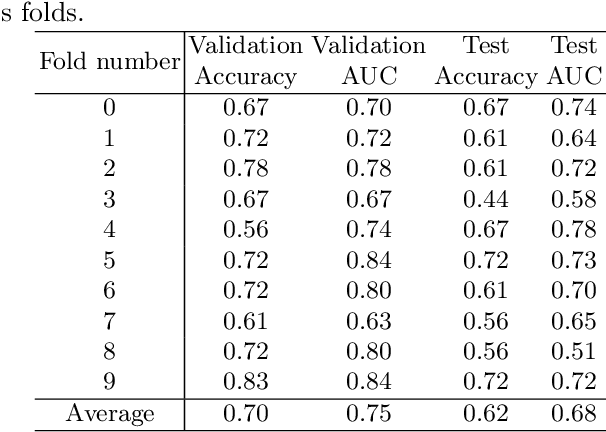
The inception of spatial transcriptomics has allowed improved comprehension of tissue architectures and the disentanglement of complex underlying biological, physiological, and pathological processes through their positional contexts. Recently, these contexts, and by extension the field, have seen much promise and elucidation with the application of graph learning approaches. In particular, neural operators have risen in regards to learning the mapping between infinite-dimensional function spaces. With basic to deep neural network architectures being data-driven, i.e. dependent on quality data for prediction, neural operators provide robustness by offering generalization among different resolutions despite low quality data. Graph neural operators are a variant that utilize graph networks to learn this mapping between function spaces. The aim of this research is to identify robust machine learning architectures that integrate spatial information to predict tissue types. Under this notion, we propose a study incorporating various graph neural network approaches to validate the efficacy of applying neural operators towards prediction of brain regions in mouse brain tissue samples as a proof of concept towards our purpose. We were able to achieve an F1 score of nearly 72% for the graph neural operator approach which outperformed all baseline and other graph network approaches.
Self-supervised Semi-implicit Graph Variational Auto-encoders with Masking
Feb 06, 2023

Generative graph self-supervised learning (SSL) aims to learn node representations by reconstructing the input graph data. However, most existing methods focus on unsupervised learning tasks only and very few work has shown its superiority over the state-of-the-art graph contrastive learning (GCL) models, especially on the classification task. While a very recent model has been proposed to bridge the gap, its performance on unsupervised learning tasks is still unknown. In this paper, to comprehensively enhance the performance of generative graph SSL against other GCL models on both unsupervised and supervised learning tasks, we propose the SeeGera model, which is based on the family of self-supervised variational graph auto-encoder (VGAE). Specifically, SeeGera adopts the semi-implicit variational inference framework, a hierarchical variational framework, and mainly focuses on feature reconstruction and structure/feature masking. On the one hand, SeeGera co-embeds both nodes and features in the encoder and reconstructs both links and features in the decoder. Since feature embeddings contain rich semantic information on features, they can be combined with node embeddings to provide fine-grained knowledge for feature reconstruction. On the other hand, SeeGera adds an additional layer for structure/feature masking to the hierarchical variational framework, which boosts the model generalizability. We conduct extensive experiments comparing SeeGera with 9 other state-of-the-art competitors. Our results show that SeeGera can compare favorably against other state-of-the-art GCL methods in a variety of unsupervised and supervised learning tasks.
Sifer: Overcoming simplicity bias in deep networks using a feature sieve
Jan 30, 2023
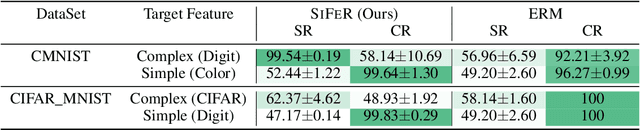
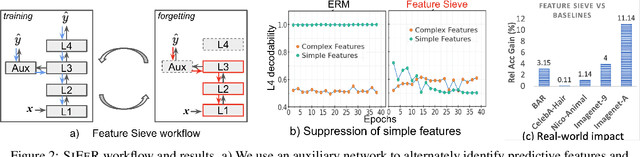
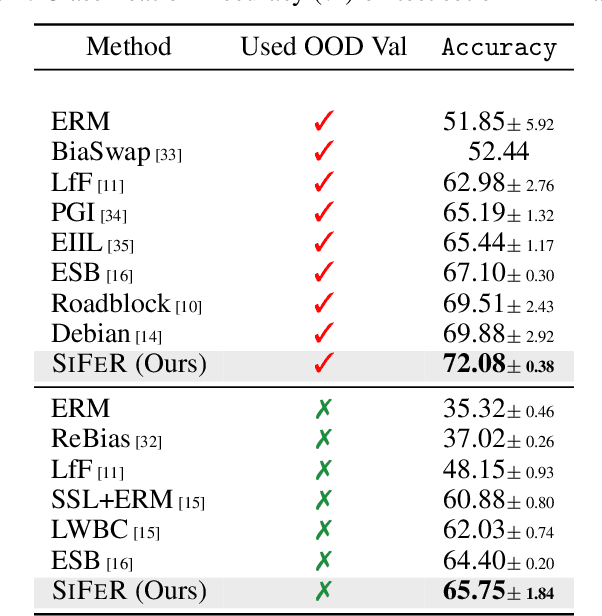
Simplicity bias is the concerning tendency of deep networks to over-depend on simple, weakly predictive features, to the exclusion of stronger, more complex features. This causes biased, incorrect model predictions in many real-world applications, exacerbated by incomplete training data containing spurious feature-label correlations. We propose a direct, interventional method for addressing simplicity bias in DNNs, which we call the feature sieve. We aim to automatically identify and suppress easily-computable spurious features in lower layers of the network, thereby allowing the higher network levels to extract and utilize richer, more meaningful representations. We provide concrete evidence of this differential suppression & enhancement of relevant features on both controlled datasets and real-world images, and report substantial gains on many real-world debiasing benchmarks (11.4% relative gain on Imagenet-A; 3.2% on BAR, etc). Crucially, we outperform many baselines that incorporate knowledge about known spurious or biased attributes, despite our method not using any such information. We believe that our feature sieve work opens up exciting new research directions in automated adversarial feature extraction & representation learning for deep networks.
I-24 MOTION: An instrument for freeway traffic science
Jan 30, 2023
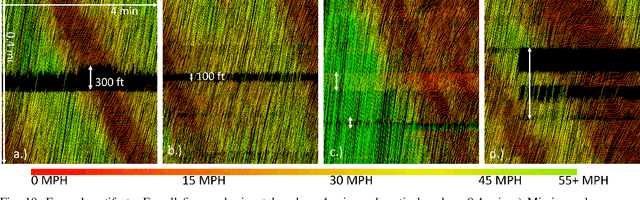
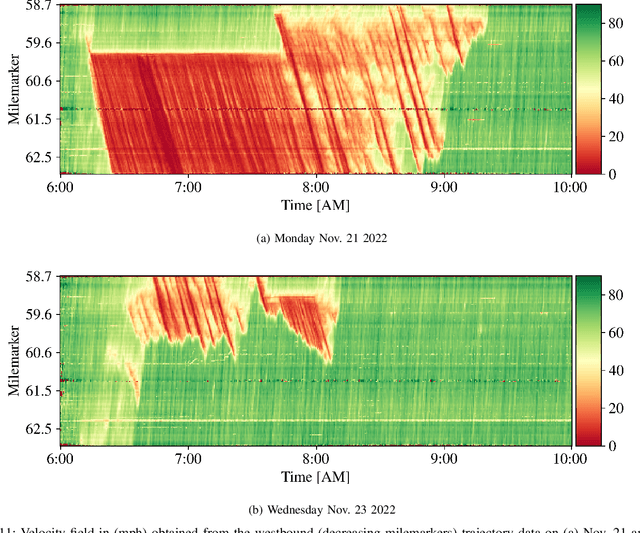
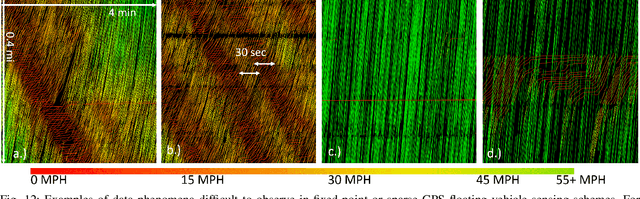
The Interstate-24 MObility Technology Interstate Observation Network (I-24 MOTION) is a new instrument for traffic science located near Nashville, Tennessee. I-24 MOTION consists of 276 pole-mounted high-resolution traffic cameras that provide seamless coverage of approximately 4.2 miles I-24, a 4-5 lane (each direction) freeway with frequently observed congestion. The cameras are connected via fiber optic network to a compute facility where vehicle trajectories are extracted from the video imagery using computer vision techniques. Approximately 230 million vehicle miles of travel occur within I-24 MOTION annually. The main output of the instrument are vehicle trajectory datasets that contain the position of each vehicle on the freeway, as well as other supplementary information vehicle dimensions and class. This article describes the design and creation of the instrument, and provides the first publicly available datasets generated from the instrument. The datasets published with this article contains at least 4 hours of vehicle trajectory data for each of 10 days. As the system continues to mature, all trajectory data will be made publicly available at i24motion.org/data.
N-Gram Nearest Neighbor Machine Translation
Jan 30, 2023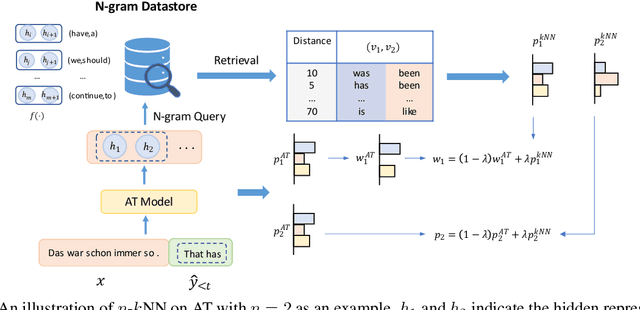
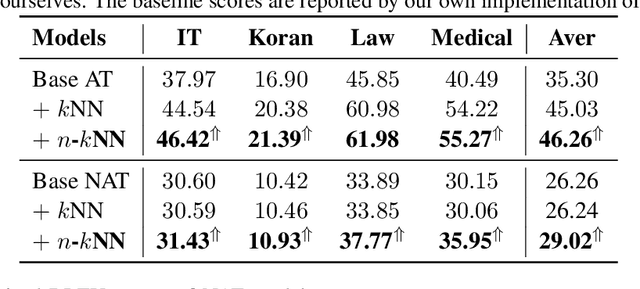
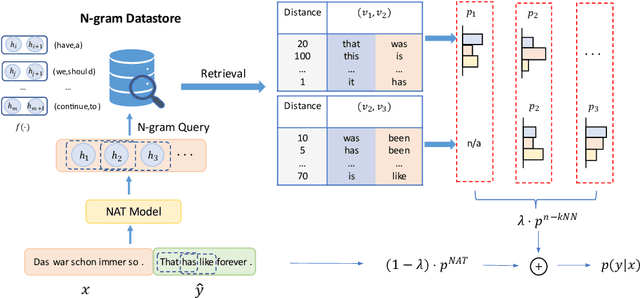
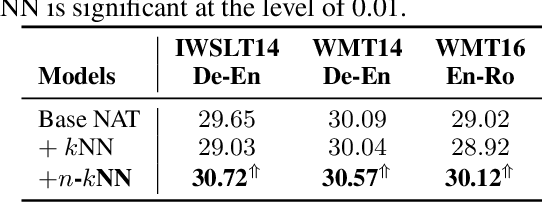
Nearest neighbor machine translation augments the Autoregressive Translation~(AT) with $k$-nearest-neighbor retrieval, by comparing the similarity between the token-level context representations of the target tokens in the query and the datastore. However, the token-level representation may introduce noise when translating ambiguous words, or fail to provide accurate retrieval results when the representation generated by the model contains indistinguishable context information, e.g., Non-Autoregressive Translation~(NAT) models. In this paper, we propose a novel $n$-gram nearest neighbor retrieval method that is model agnostic and applicable to both AT and NAT models. Specifically, we concatenate the adjacent $n$-gram hidden representations as the key, while the tuple of corresponding target tokens is the value. In inference, we propose tailored decoding algorithms for AT and NAT models respectively. We demonstrate that the proposed method consistently outperforms the token-level method on both AT and NAT models as well on general as on domain adaptation translation tasks. On domain adaptation, the proposed method brings $1.03$ and $2.76$ improvements regarding the average BLEU score on AT and NAT models respectively.
Action Capsules: Human Skeleton Action Recognition
Jan 30, 2023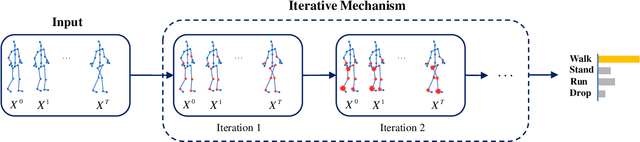
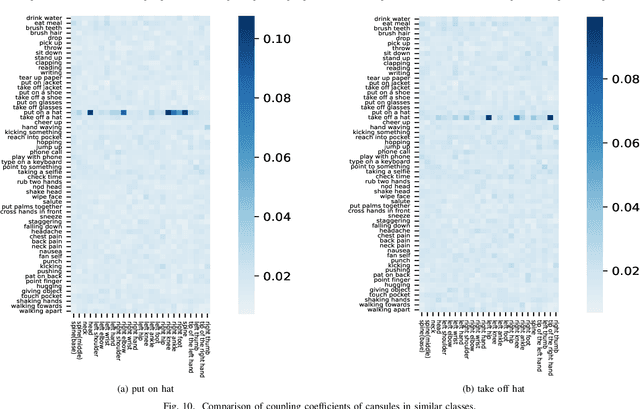
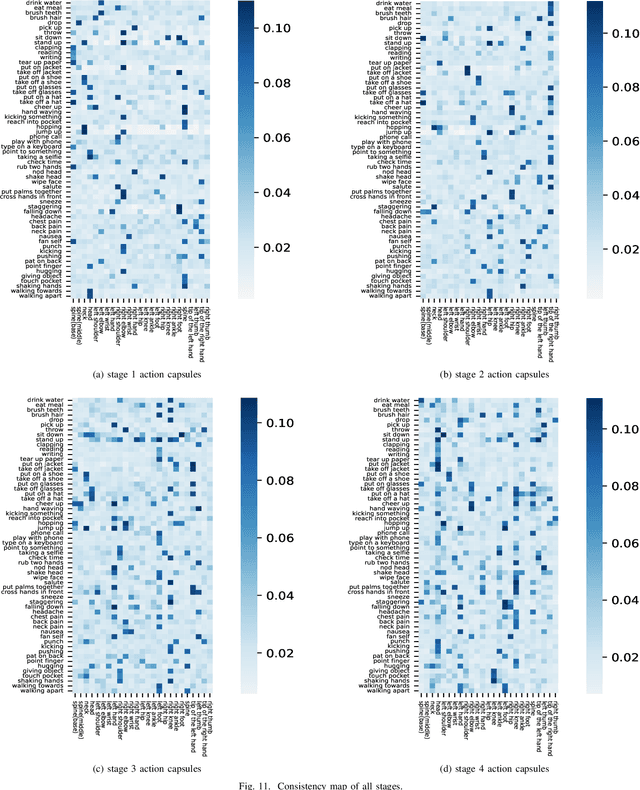
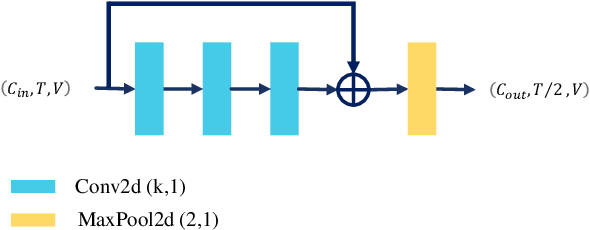
Due to the compact and rich high-level representations offered, skeleton-based human action recognition has recently become a highly active research topic. Previous studies have demonstrated that investigating joint relationships in spatial and temporal dimensions provides effective information critical to action recognition. However, effectively encoding global dependencies of joints during spatio-temporal feature extraction is still challenging. In this paper, we introduce Action Capsule which identifies action-related key joints by considering the latent correlation of joints in a skeleton sequence. We show that, during inference, our end-to-end network pays attention to a set of joints specific to each action, whose encoded spatio-temporal features are aggregated to recognize the action. Additionally, the use of multiple stages of action capsules enhances the ability of the network to classify similar actions. Consequently, our network outperforms the state-of-the-art approaches on the N-UCLA dataset and obtains competitive results on the NTURGBD dataset. This is while our approach has significantly lower computational requirements based on GFLOPs measurements.
On the Efficacy of Metrics to Describe Adversarial Attacks
Jan 30, 2023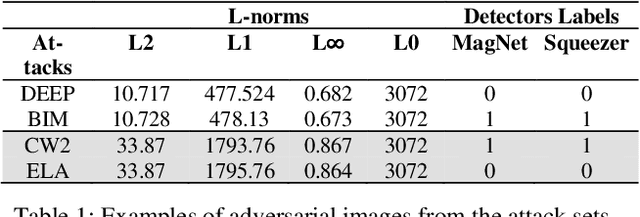
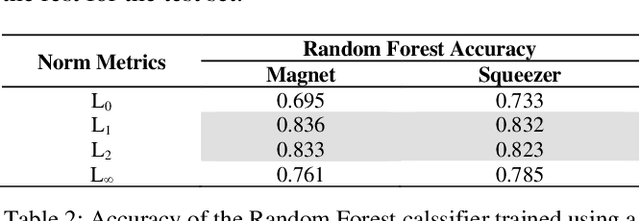
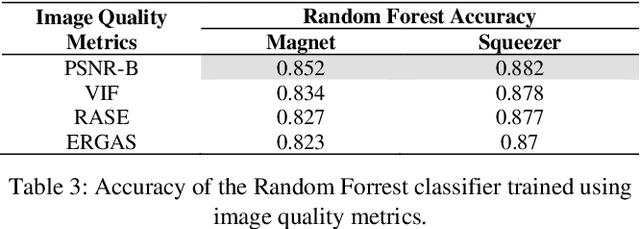

Adversarial defenses are naturally evaluated on their ability to tolerate adversarial attacks. To test defenses, diverse adversarial attacks are crafted, that are usually described in terms of their evading capability and the L0, L1, L2, and Linf norms. We question if the evading capability and L-norms are the most effective information to claim that defenses have been tested against a representative attack set. To this extent, we select image quality metrics from the state of the art and search correlations between image perturbation and detectability. We observe that computing L-norms alone is rarely the preferable solution. We observe a strong correlation between the identified metrics computed on an adversarial image and the output of a detector on such an image, to the extent that they can predict the response of a detector with approximately 0.94 accuracy. Further, we observe that metrics can classify attacks based on similar perturbations and similar detectability. This suggests a possible review of the approach to evaluate detectors, where additional metrics are included to assure that a representative attack dataset is selected.
Compression, Generalization and Learning
Jan 30, 2023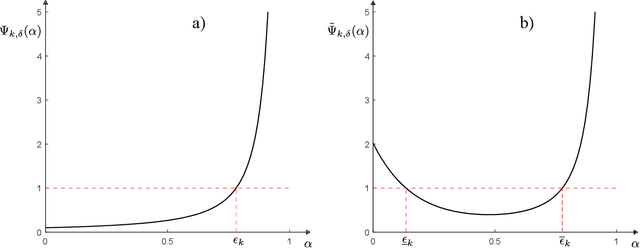
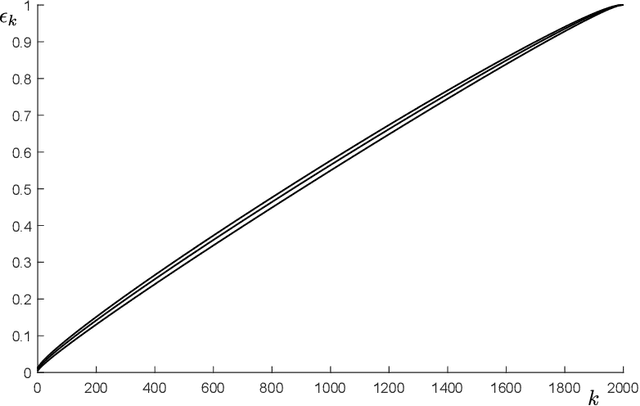
A compression function is a map that slims down an observational set into a subset of reduced size, while preserving its informational content. In multiple applications, the condition that one new observation makes the compressed set change is interpreted that this observation brings in extra information and, in learning theory, this corresponds to misclassification, or misprediction. In this paper, we lay the foundations of a new theory that allows one to keep control on the probability of change of compression (called the "risk"). We identify conditions under which the cardinality of the compressed set is a consistent estimator for the risk (without any upper limit on the size of the compressed set) and prove unprecedentedly tight bounds to evaluate the risk under a generally applicable condition of preference. All results are usable in a fully agnostic setup, without requiring any a priori knowledge on the probability distribution of the observations. Not only these results offer a valid support to develop trust in observation-driven methodologies, they also play a fundamental role in learning techniques as a tool for hyper-parameter tuning.
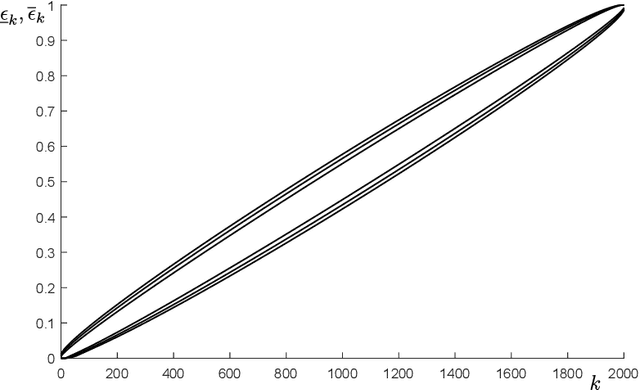
Learning to swim efficiently in a nonuniform flow field
Dec 22, 2022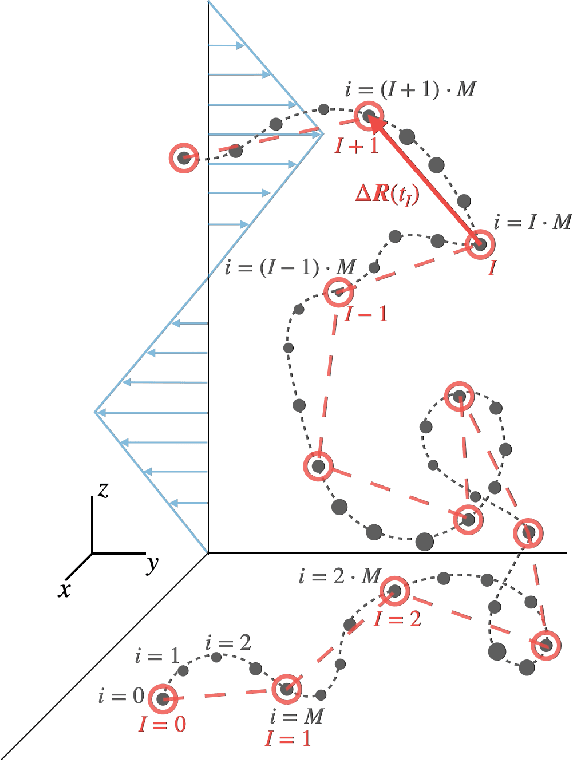
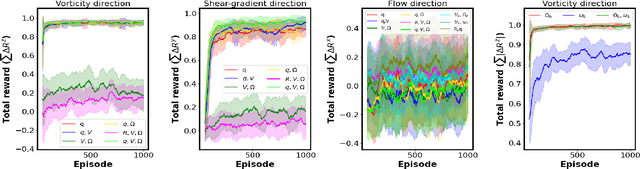
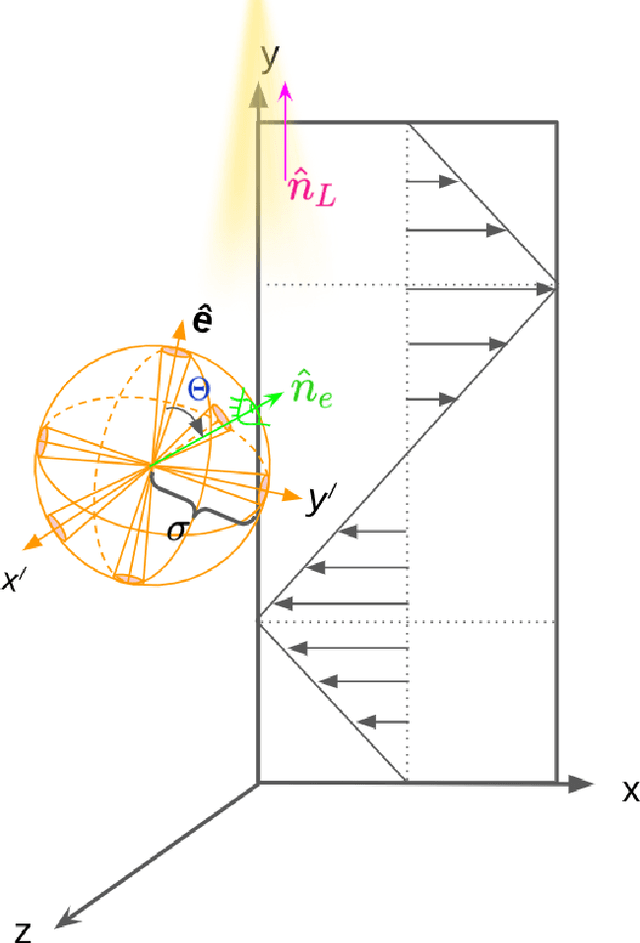
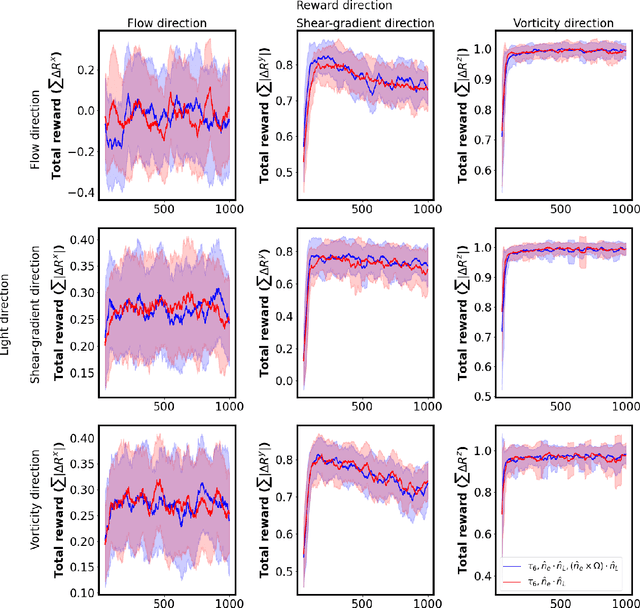
Microswimmers can acquire information on the surrounding fluid by sensing mechanical queues. They can then navigate in response to these signals. We analyse this navigation by combining deep reinforcement learning with direct numerical simulations to resolve the hydrodynamics. We study how local and non-local information can be used to train a swimmer to achieve particular swimming tasks in a non-uniform flow field, in particular a zig-zag shear flow. The swimming tasks are (1) learning how to swim in the vorticity direction, (2) the shear-gradient direction, and (3) the shear flow direction. We find that access to lab frame information on the swimmer's instantaneous orientation is all that is required in order to reach the optimal policy for (1,2). However, information on both the translational and rotational velocities seem to be required to achieve (3). Inspired by biological microorganisms we also consider the case where the swimmers sense local information, i.e. surface hydrodynamic forces, together with a signal direction. This might correspond to gravity or, for micro-organisms with light sensors, a light source. In this case, we show that the swimmer can reach a comparable level of performance as a swimmer with access to lab frame variables. We also analyse the role of different swimming modes, i.e. pusher, puller, and neutral swimmers.