 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
k-Means SubClustering: A Differentially Private Algorithm with Improved Clustering Quality
Jan 07, 2023
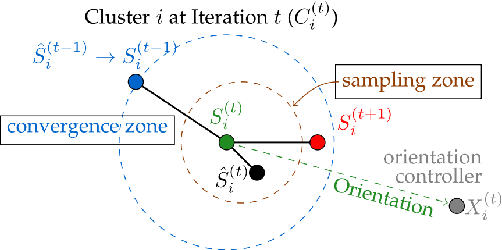
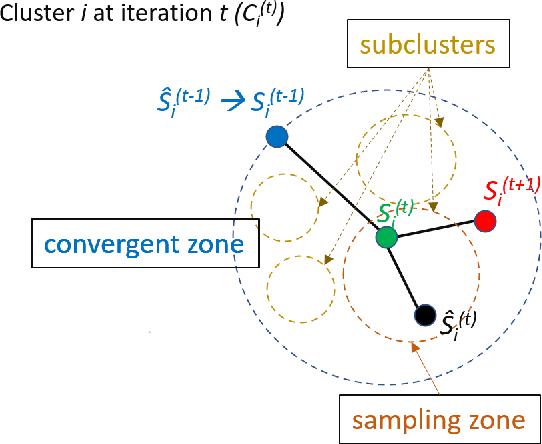
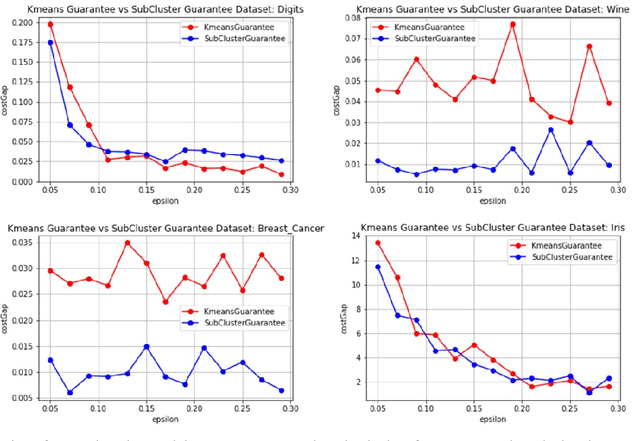
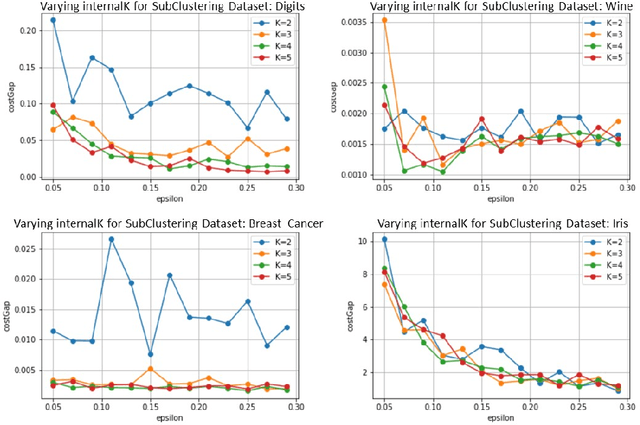
In today's data-driven world, the sensitivity of information has been a significant concern. With this data and additional information on the person's background, one can easily infer an individual's private data. Many differentially private iterative algorithms have been proposed in interactive settings to protect an individual's privacy from these inference attacks. The existing approaches adapt the method to compute differentially private(DP) centroids by iterative Llyod's algorithm and perturbing the centroid with various DP mechanisms. These DP mechanisms do not guarantee convergence of differentially private iterative algorithms and degrade the quality of the cluster. Thus, in this work, we further extend the previous work on 'Differentially Private k-Means Clustering With Convergence Guarantee' by taking it as our baseline. The novelty of our approach is to sub-cluster the clusters and then select the centroid which has a higher probability of moving in the direction of the future centroid. At every Lloyd's step, the centroids are injected with the noise using the exponential DP mechanism. The results of the experiments indicate that our approach outperforms the current state-of-the-art method, i.e., the baseline algorithm, in terms of clustering quality while maintaining the same differential privacy requirements. The clustering quality significantly improved by 4.13 and 2.83 times than baseline for the Wine and Breast_Cancer dataset, respectively.
Latent Discretization for Continuous-time Sequence Compression
Dec 28, 2022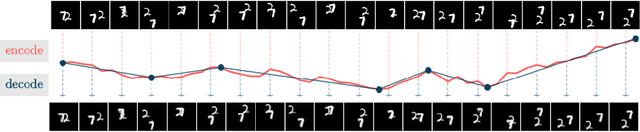

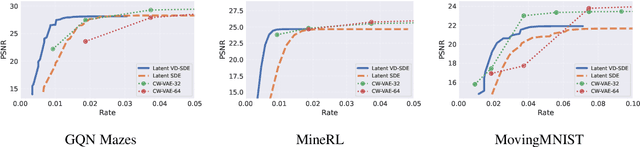
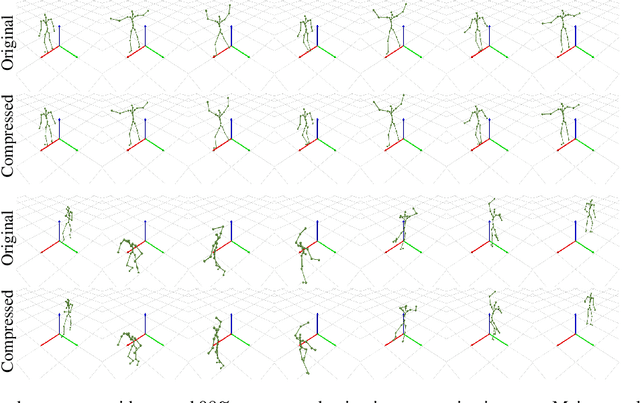
Neural compression offers a domain-agnostic approach to creating codecs for lossy or lossless compression via deep generative models. For sequence compression, however, most deep sequence models have costs that scale with the sequence length rather than the sequence complexity. In this work, we instead treat data sequences as observations from an underlying continuous-time process and learn how to efficiently discretize while retaining information about the full sequence. As a consequence of decoupling sequential information from its temporal discretization, our approach allows for greater compression rates and smaller computational complexity. Moreover, the continuous-time approach naturally allows us to decode at different time intervals. We empirically verify our approach on multiple domains involving compression of video and motion capture sequences, showing that our approaches can automatically achieve reductions in bit rates by learning how to discretize.
Multi-Target Landmark Detection with Incomplete Images via Reinforcement Learning and Shape Prior
Jan 13, 2023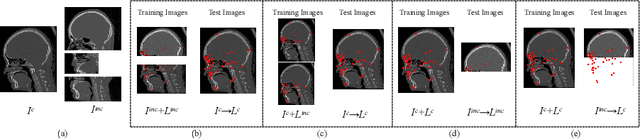
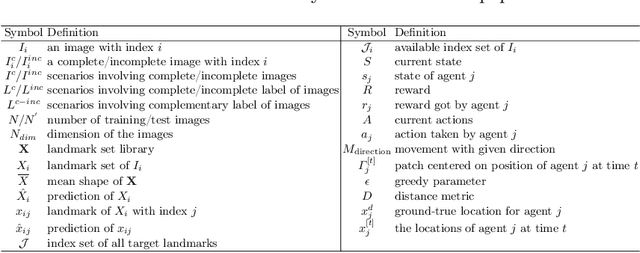
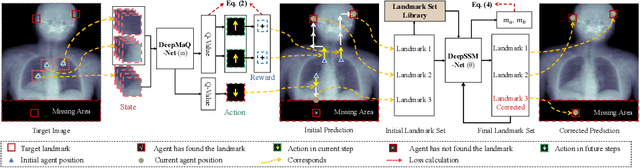

Medical images are generally acquired with limited field-of-view (FOV), which could lead to incomplete regions of interest (ROI), and thus impose a great challenge on medical image analysis. This is particularly evident for the learning-based multi-target landmark detection, where algorithms could be misleading to learn primarily the variation of background due to the varying FOV, failing the detection of targets. Based on learning a navigation policy, instead of predicting targets directly, reinforcement learning (RL)-based methods have the potential totackle this challenge in an efficient manner. Inspired by this, in this work we propose a multi-agent RL framework for simultaneous multi-target landmark detection. This framework is aimed to learn from incomplete or (and) complete images to form an implicit knowledge of global structure, which is consolidated during the training stage for the detection of targets from either complete or incomplete test images. To further explicitly exploit the global structural information from incomplete images, we propose to embed a shape model into the RL process. With this prior knowledge, the proposed RL model can not only localize dozens of targetssimultaneously, but also work effectively and robustly in the presence of incomplete images. We validated the applicability and efficacy of the proposed method on various multi-target detection tasks with incomplete images from practical clinics, using body dual-energy X-ray absorptiometry (DXA), cardiac MRI and head CT datasets. Results showed that our method could predict whole set of landmarks with incomplete training images up to 80% missing proportion (average distance error 2.29 cm on body DXA), and could detect unseen landmarks in regions with missing image information outside FOV of target images (average distance error 6.84 mm on 3D half-head CT).
Deep learning-based approaches for human motion decoding in smart walkers for rehabilitation
Jan 13, 2023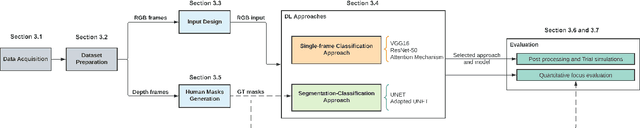

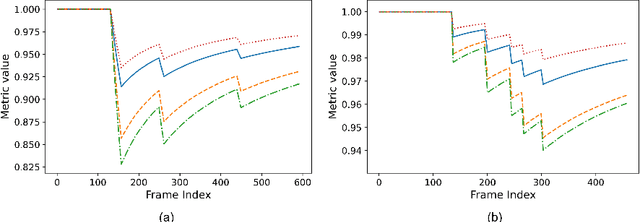
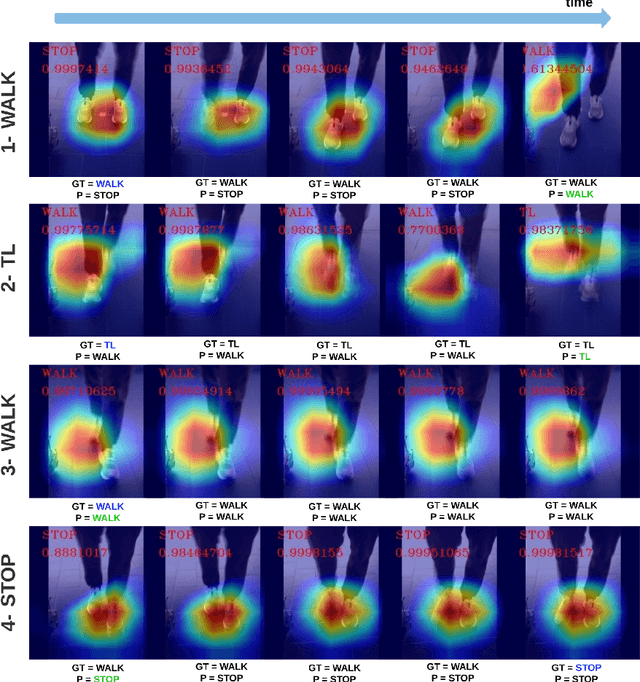
Gait disabilities are among the most frequent worldwide. Their treatment relies on rehabilitation therapies, in which smart walkers are being introduced to empower the user's recovery and autonomy, while reducing the clinicians effort. For that, these should be able to decode human motion and needs, as early as possible. Current walkers decode motion intention using information of wearable or embedded sensors, namely inertial units, force and hall sensors, and lasers, whose main limitations imply an expensive solution or hinder the perception of human movement. Smart walkers commonly lack a seamless human-robot interaction, which intuitively understands human motions. A contactless approach is proposed in this work, addressing human motion decoding as an early action recognition/detection problematic, using RGB-D cameras. We studied different deep learning-based algorithms, organised in three different approaches, to process lower body RGB-D video sequences, recorded from an embedded camera of a smart walker, and classify them into 4 classes (stop, walk, turn right/left). A custom dataset involving 15 healthy participants walking with the device was acquired and prepared, resulting in 28800 balanced RGB-D frames, to train and evaluate the deep networks. The best results were attained by a convolutional neural network with a channel attention mechanism, reaching accuracy values of 99.61% and above 93%, for offline early detection/recognition and trial simulations, respectively. Following the hypothesis that human lower body features encode prominent information, fostering a more robust prediction towards real-time applications, the algorithm focus was also evaluated using Dice metric, leading to values slightly higher than 30%. Promising results were attained for early action detection as a human motion decoding strategy, with enhancements in the focus of the proposed architectures.
Power Control for 6G Industrial Wireless Subnetworks: A Graph Neural Network Approach
Dec 30, 2022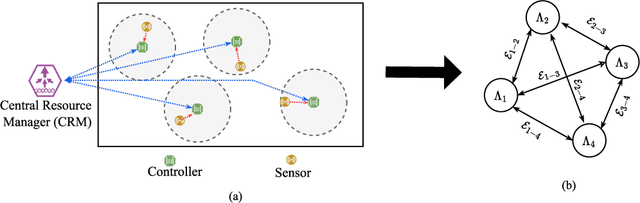
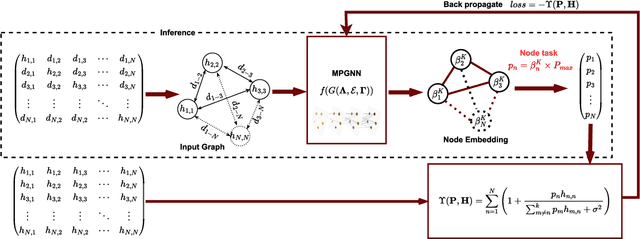
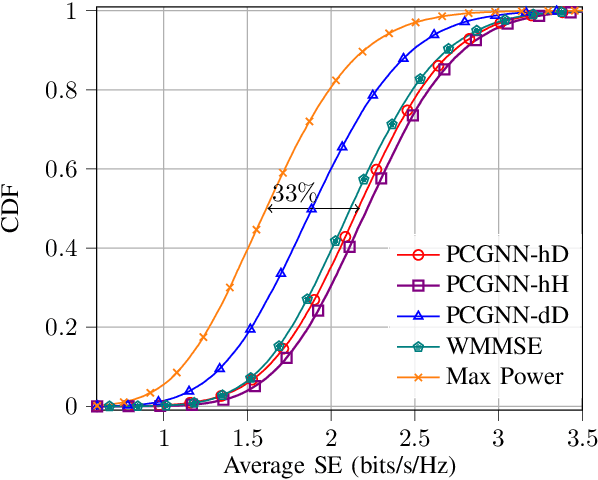
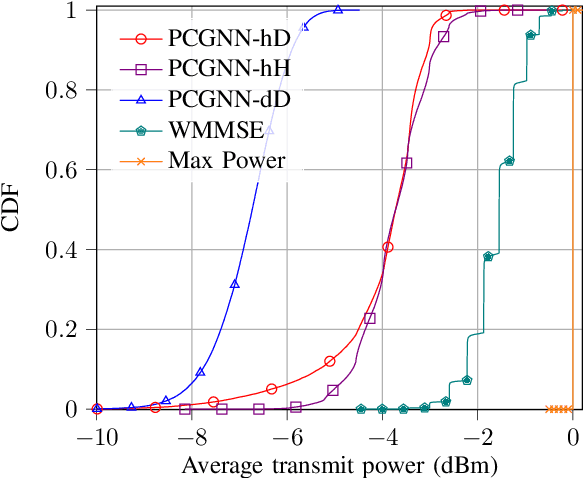
6th Generation (6G) industrial wireless subnetworks are expected to replace wired connectivity for control operation in robots and production modules. Interference management techniques such as centralized power control can improve spectral efficiency in dense deployments of such subnetworks. However, existing solutions for centralized power control may require full channel state information (CSI) of all the desired and interfering links, which may be cumbersome and time-consuming to obtain in dense deployments. This paper presents a novel solution for centralized power control for industrial subnetworks based on Graph Neural Networks (GNNs). The proposed method only requires the subnetwork positioning information, usually known at the central controller, and the knowledge of the desired link channel gain during the execution phase. Simulation results show that our solution achieves similar spectral efficiency as the benchmark schemes requiring full CSI in runtime operations. Also, robustness to changes in the deployment density and environment characteristics with respect to the training phase is verified.
Information Extraction from Scanned Invoice Images using Text Analysis and Layout Features
Aug 08, 2022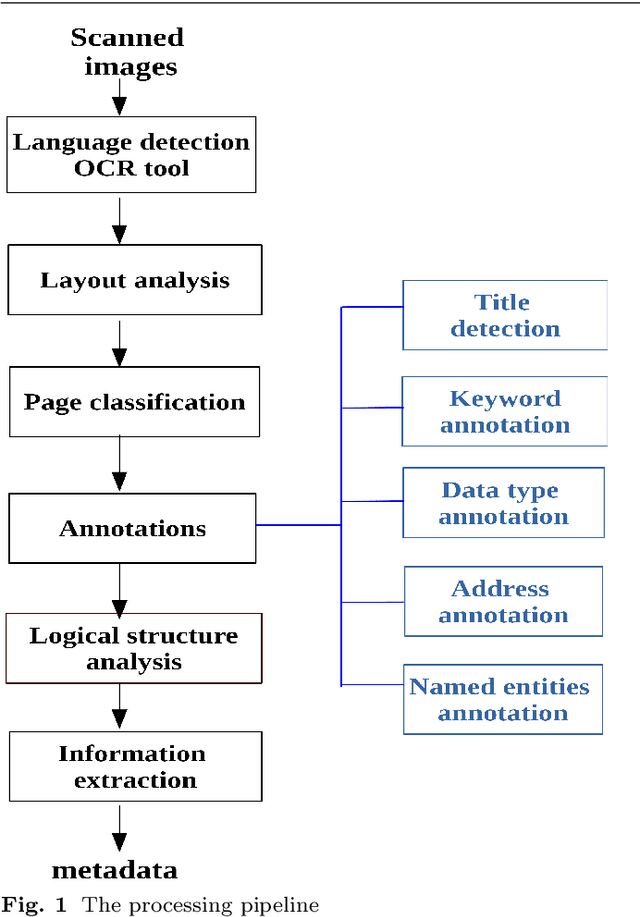
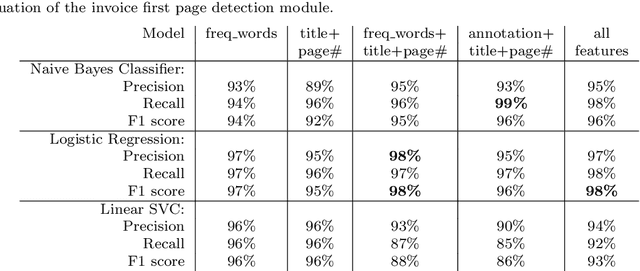
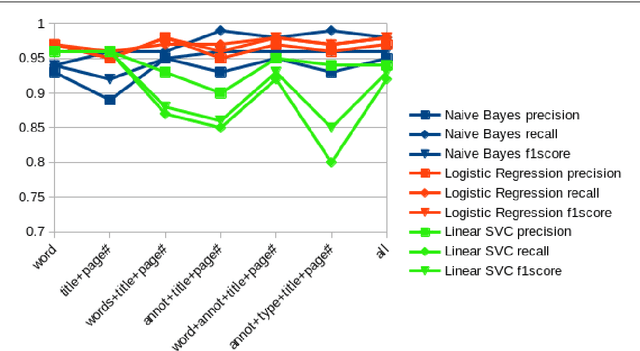
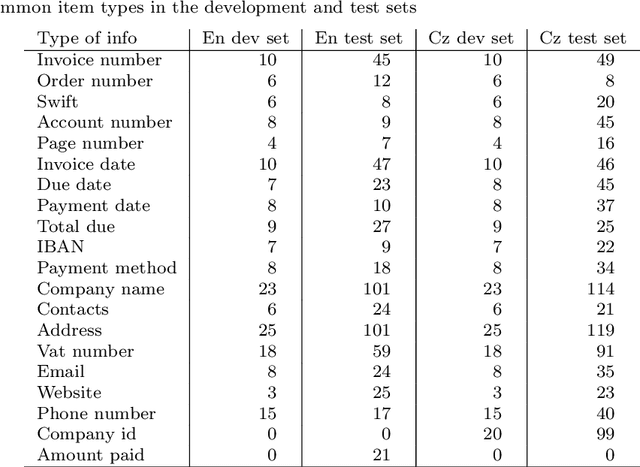
While storing invoice content as metadata to avoid paper document processing may be the future trend, almost all of daily issued invoices are still printed on paper or generated in digital formats such as PDFs. In this paper, we introduce the OCRMiner system for information extraction from scanned document images which is based on text analysis techniques in combination with layout features to extract indexing metadata of (semi-)structured documents. The system is designed to process the document in a similar way a human reader uses, i.e. to employ different layout and text attributes in a coordinated decision. The system consists of a set of interconnected modules that start with (possibly erroneous) character-based output from a standard OCR system and allow to apply different techniques and to expand the extracted knowledge at each step. Using an open source OCR, the system is able to recover the invoice data in 90% for English and in 88% for the Czech set.
* This is an author preprint of the article published by Elsevier in Signal Processing: Image Communication at https://doi.org/10.1016/j.image.2021.116601
GLIGEN: Open-Set Grounded Text-to-Image Generation
Jan 17, 2023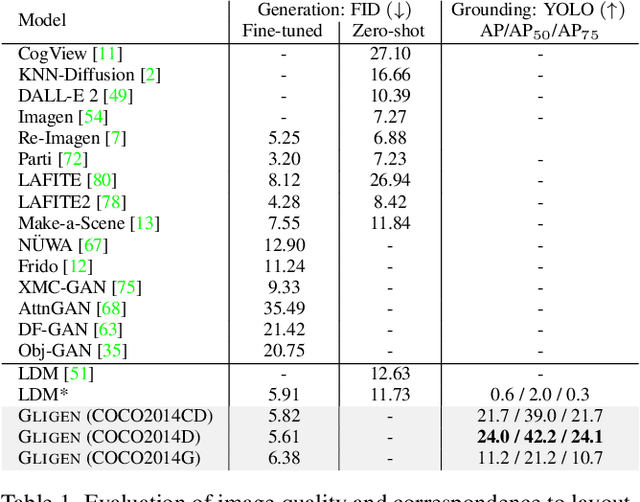
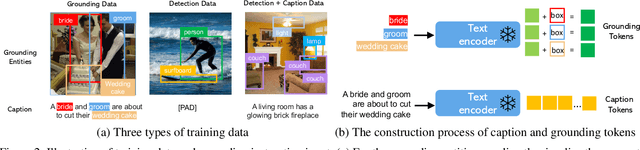
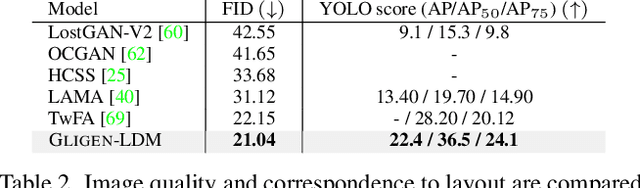
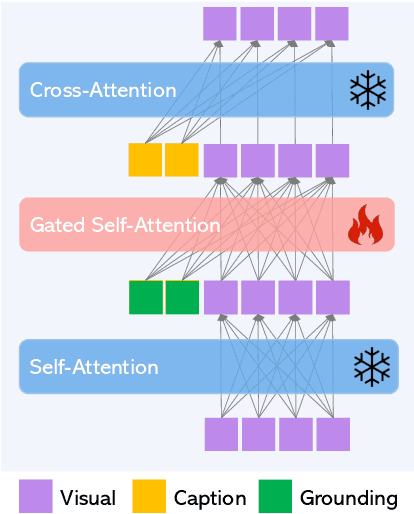
Large-scale text-to-image diffusion models have made amazing advances. However, the status quo is to use text input alone, which can impede controllability. In this work, we propose GLIGEN, Grounded-Language-to-Image Generation, a novel approach that builds upon and extends the functionality of existing pre-trained text-to-image diffusion models by enabling them to also be conditioned on grounding inputs. To preserve the vast concept knowledge of the pre-trained model, we freeze all of its weights and inject the grounding information into new trainable layers via a gated mechanism. Our model achieves open-world grounded text2img generation with caption and bounding box condition inputs, and the grounding ability generalizes well to novel spatial configuration and concepts. GLIGEN's zero-shot performance on COCO and LVIS outperforms that of existing supervised layout-to-image baselines by a large margin.
Information Propagation by Composited Labels in Natural Language Processing
May 23, 2022
In natural language processing (NLP), labeling on regions of text, such as words, sentences and paragraphs, is a basic task. In this paper, label is defined as map between mention of entity in a region on text and context of entity in a broader region on text containing the mention. This definition naturally introduces linkage of entities induced from inclusion relation of regions, and connected entities form a graph representing information flow defined by map. It also enables calculation of information loss through map using entropy, and entropy lost is regarded as distance between two entities over a path on graph.
Constraints on the design of neuromorphic circuits set by the properties of neural population codes
Dec 08, 2022In the brain, information is encoded, transmitted and used to inform behaviour at the level of timing of action potentials distributed over population of neurons. To implement neural-like systems in silico, to emulate neural function, and to interface successfully with the brain, neuromorphic circuits need to encode information in a way compatible to that used by populations of neuron in the brain. To facilitate the cross-talk between neuromorphic engineering and neuroscience, in this Review we first critically examine and summarize emerging recent findings about how population of neurons encode and transmit information. We examine the effects on encoding and readout of information for different features of neural population activity, namely the sparseness of neural representations, the heterogeneity of neural properties, the correlations among neurons, and the time scales (from short to long) at which neurons encode information and maintain it consistently over time. Finally, we critically elaborate on how these facts constrain the design of information coding in neuromorphic circuits. We focus primarily on the implications for designing neuromorphic circuits that communicate with the brain, as in this case it is essential that artificial and biological neurons use compatible neural codes. However, we also discuss implications for the design of neuromorphic systems for implementation or emulation of neural computation.
The moral authority of ChatGPT
Jan 13, 2023
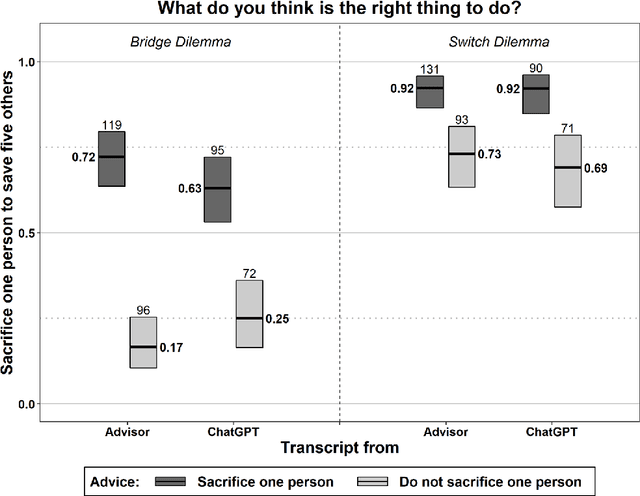
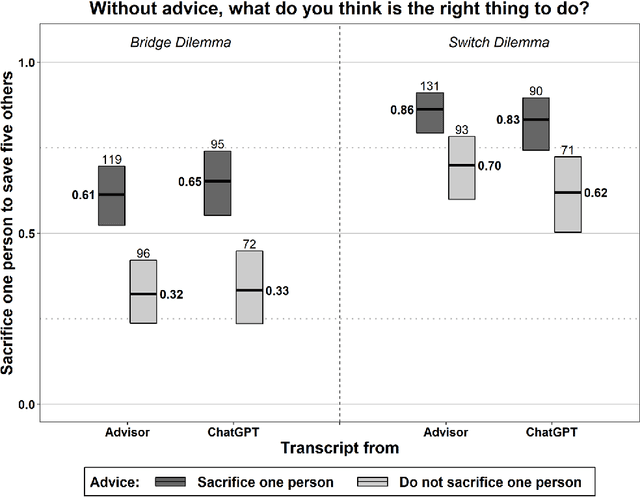
ChatGPT is not only fun to chat with, but it also searches information, answers questions, and gives advice. With consistent moral advice, it might improve the moral judgment and decisions of users, who often hold contradictory moral beliefs. Unfortunately, ChatGPT turns out highly inconsistent as a moral advisor. Nonetheless, it influences users' moral judgment, we find in an experiment, even if they know they are advised by a chatting bot, and they underestimate how much they are influenced. Thus, ChatGPT threatens to corrupt rather than improves users' judgment. These findings raise the question of how to ensure the responsible use of ChatGPT and similar AI. Transparency is often touted but seems ineffective. We propose training to improve digital literacy.