 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Integrating features from lymph node stations for metastatic lymph node detection
Jan 09, 2023

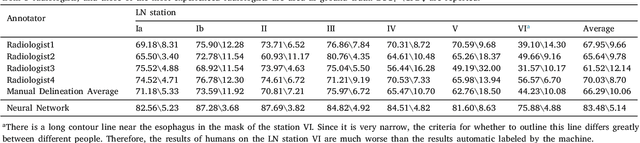
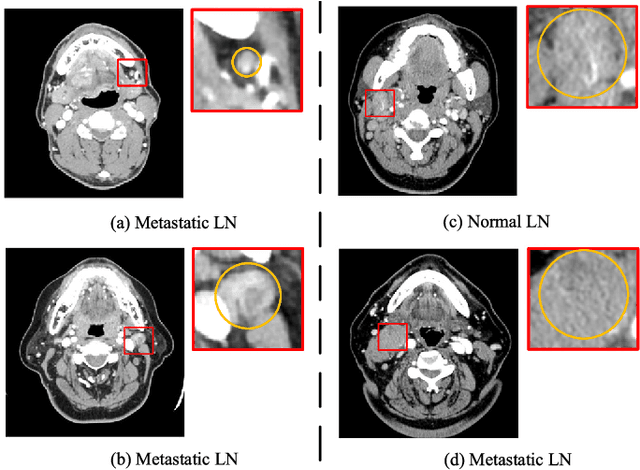
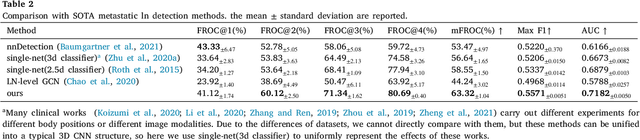
Metastasis on lymph nodes (LNs), the most common way of spread for primary tumor cells, is a sign of increased mortality. However, metastatic LNs are time-consuming and challenging to detect even for professional radiologists due to their small sizes, high sparsity, and ambiguity in appearance. It is desired to leverage recent development in deep learning to automatically detect metastatic LNs. Besides a two-stage detection network, we here introduce an additional branch to leverage information about LN stations, an important reference for radiologists during metastatic LN diagnosis, as supplementary information for metastatic LN detection. The branch targets to solve a closely related task on the LN station level, i.e., classifying whether an LN station contains metastatic LN or not, so as to learn representations for LN stations. Considering that a metastatic LN station is expected to significantly affect the nearby ones, a GCN-based structure is adopted by the branch to model the relationship among different LN stations. At the classification stage of metastatic LN detection, the above learned LN station features, as well as the features reflecting the distance between the LN candidate and the LN stations, are integrated with the LN features. We validate our method on a dataset containing 114 intravenous contrast-enhanced Computed Tomography (CT) images of oral squamous cell carcinoma (OSCC) patients and show that it outperforms several state-of-the-art methods on the mFROC, maxF1, and AUC scores,respectively.
A Comparison between RSMA, SDMA, and OMA in Multibeam LEO Satellite Systems
Jan 24, 2023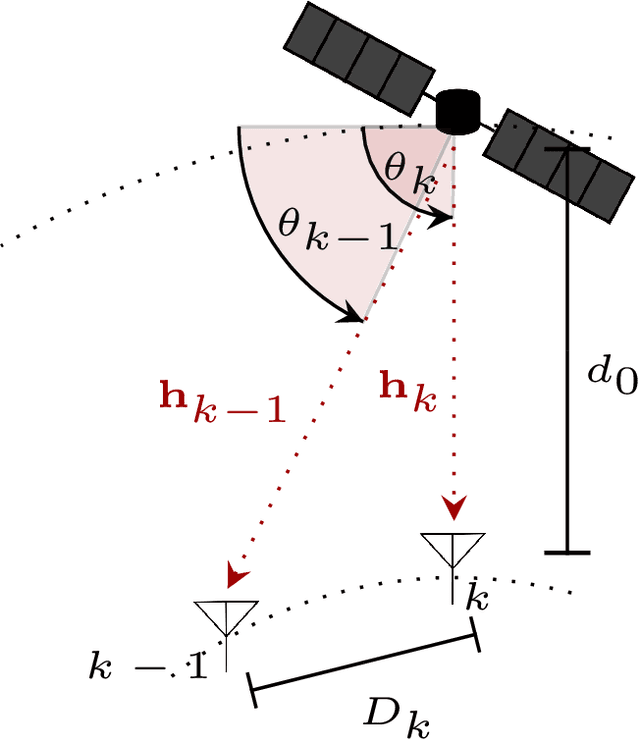
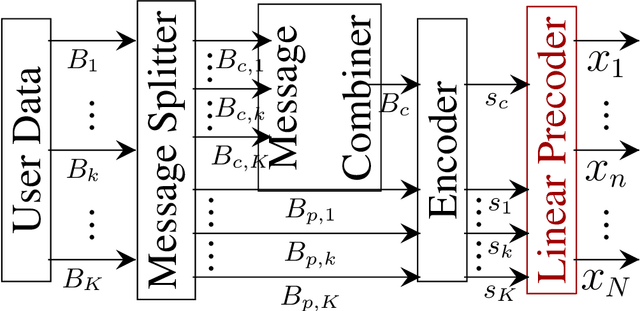
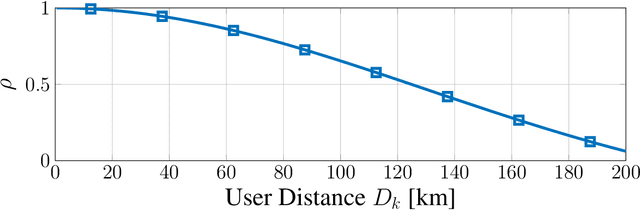
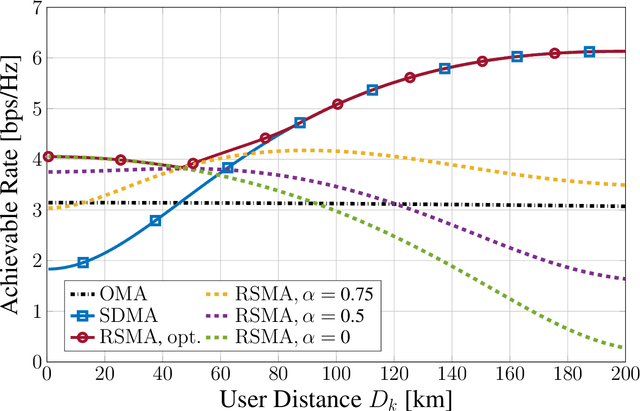
Low Earth orbit (LEO) satellite systems enable close to global coverage and are therefore expected to become important pillars of future communication standards. However, a particular challenge faced by LEO satellites is the high orbital velocities due to which a precise channel estimation is difficult. We model this influence as an erroneous angle of departure (AoD), which corresponds to imperfect channel state information (CSI) at the transmitter (CSIT). Poor CSIT and non-orthogonal user channels degrade the performance of space-division multiple access (SDMA) precoding by increasing inter-user interference (IUI). In contrast to SDMA, there is no IUI in orthogonal multiple access (OMA), but it requires orthogonal time or frequency resources for each user. Rate-splitting multiple access (RSMA), unifying SDMA, OMA, and non-orthogonal multiple access (NOMA), has recently been proven to be a flexible approach for robust interference management considering imperfect CSIT. In this paper, we investigate RSMA as a promising strategy to manage IUI in LEO satellite downlink systems caused by non-orthogonal user channels as well as imperfect CSIT. We evaluate the optimal configuration of RSMA depending on the geometrical constellation between the satellite and users.
Unifying Molecular and Textual Representations via Multi-task Language Modelling
Jan 29, 2023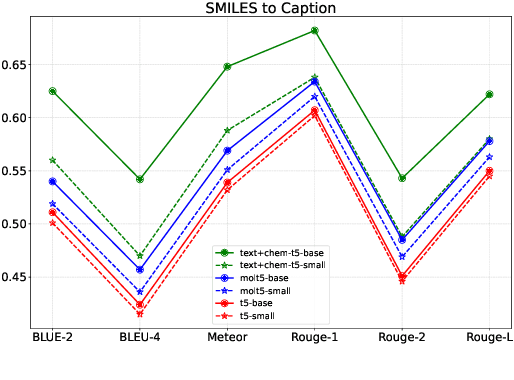
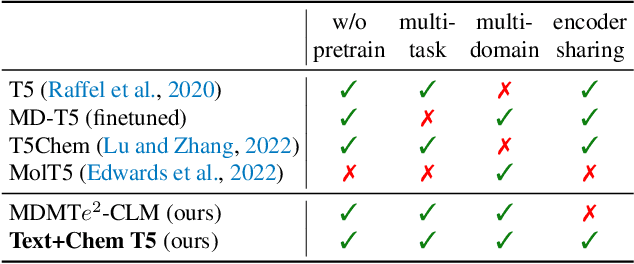
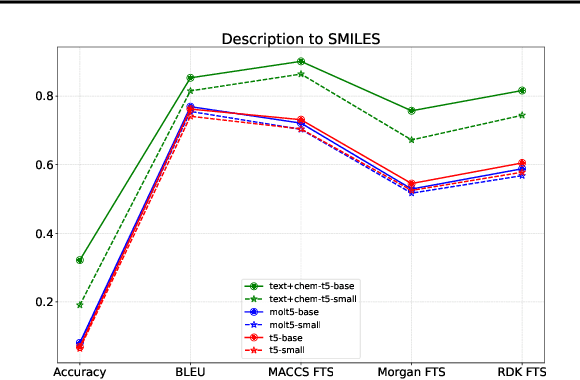
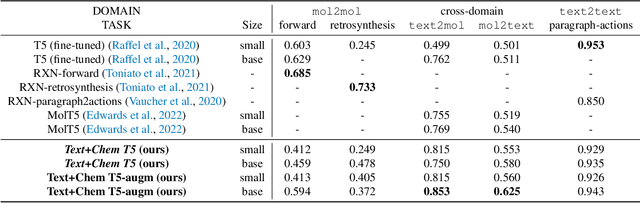
The recent advances in neural language models have also been successfully applied to the field of chemistry, offering generative solutions for classical problems in molecular design and synthesis planning. These new methods have the potential to optimize laboratory operations and fuel a new era of data-driven automation in scientific discovery. However, specialized models are still typically required for each task, leading to the need for problem-specific fine-tuning and neglecting task interrelations. The main obstacle in this field is the lack of a unified representation between natural language and chemical representations, complicating and limiting human-machine interaction. Here, we propose a multi-domain, multi-task language model to solve a wide range of tasks in both the chemical and natural language domains. By leveraging multi-task learning, our model can handle chemical and natural language concurrently, without requiring expensive pre-training on single domains or task-specific models. Interestingly, sharing weights across domains remarkably improves our model when benchmarked against state-of-the-art baselines on single-domain and cross-domain tasks. In particular, sharing information across domains and tasks gives rise to large improvements in cross-domain tasks, the magnitude of which increase with scale, as measured by more than a dozen of relevant metrics. Our work suggests that such models can robustly and efficiently accelerate discovery in physical sciences by superseding problem-specific fine-tuning and enhancing human-model interactions.
Self-supervised Semi-implicit Graph Variational Auto-encoders with Masking
Jan 29, 2023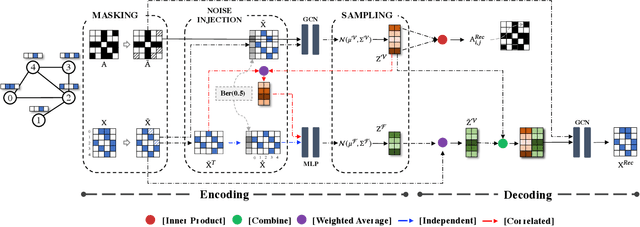
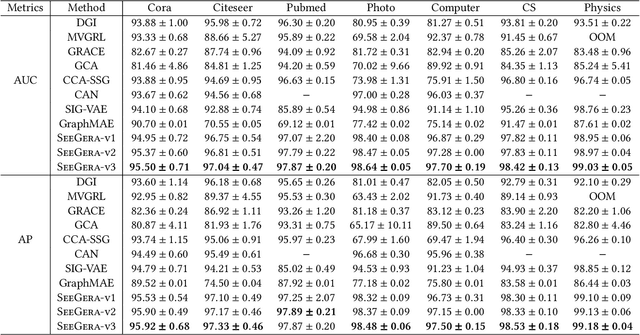

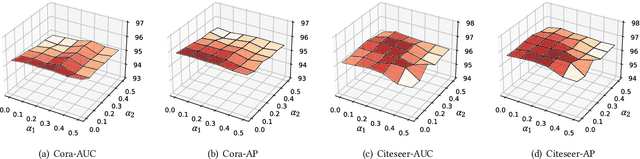
Generative graph self-supervised learning (SSL) aims to learn node representations by reconstructing the input graph data. However, most existing methods focus on unsupervised learning tasks only and very few work has shown its superiority over the state-of-the-art graph contrastive learning (GCL) models, especially on the classification task. While a very recent model has been proposed to bridge the gap, its performance on unsupervised learning tasks is still unknown. In this paper, to comprehensively enhance the performance of generative graph SSL against other GCL models on both unsupervised and supervised learning tasks, we propose the SeeGera model, which is based on the family of self-supervised variational graph auto-encoder (VGAE). Specifically, SeeGera adopts the semi-implicit variational inference framework, a hierarchical variational framework, and mainly focuses on feature reconstruction and structure/feature masking. On the one hand, SeeGera co-embeds both nodes and features in the encoder and reconstructs both links and features in the decoder. Since feature embeddings contain rich semantic information on features, they can be combined with node embeddings to provide fine-grained knowledge for feature reconstruction. On the other hand, SeeGera adds an additional layer for structure/feature masking to the hierarchical variational framework, which boosts the model generalizability. We conduct extensive experiments comparing SeeGera with 9 other state-of-the-art competitors. Our results show that SeeGera can compare favorably against other state-of-the-art GCL methods in a variety of unsupervised and supervised learning tasks.
Confidence-Aware Calibration and Scoring Functions for Curriculum Learning
Jan 29, 2023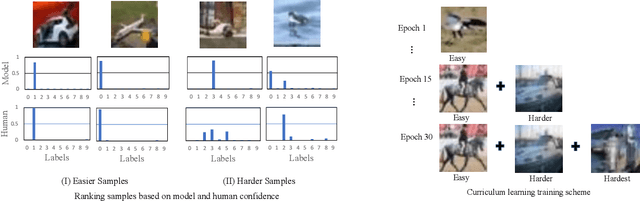
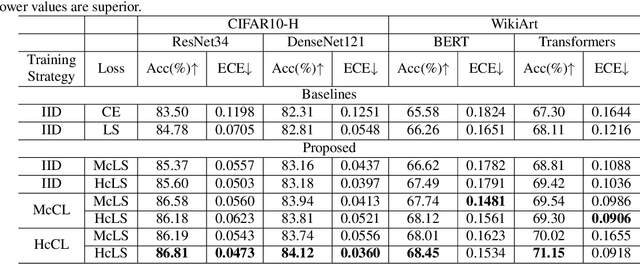
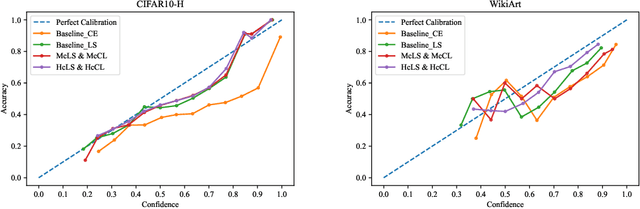
Despite the great success of state-of-the-art deep neural networks, several studies have reported models to be over-confident in predictions, indicating miscalibration. Label Smoothing has been proposed as a solution to the over-confidence problem and works by softening hard targets during training, typically by distributing part of the probability mass from a `one-hot' label uniformly to all other labels. However, neither model nor human confidence in a label are likely to be uniformly distributed in this manner, with some labels more likely to be confused than others. In this paper we integrate notions of model confidence and human confidence with label smoothing, respectively \textit{Model Confidence LS} and \textit{Human Confidence LS}, to achieve better model calibration and generalization. To enhance model generalization, we show how our model and human confidence scores can be successfully applied to curriculum learning, a training strategy inspired by learning of `easier to harder' tasks. A higher model or human confidence score indicates a more recognisable and therefore easier sample, and can therefore be used as a scoring function to rank samples in curriculum learning. We evaluate our proposed methods with four state-of-the-art architectures for image and text classification task, using datasets with multi-rater label annotations by humans. We report that integrating model or human confidence information in label smoothing and curriculum learning improves both model performance and model calibration. The code are available at \url{https://github.com/AoShuang92/Confidence_Calibration_CL}.
Differentially Private Natural Language Models: Recent Advances and Future Directions
Jan 22, 2023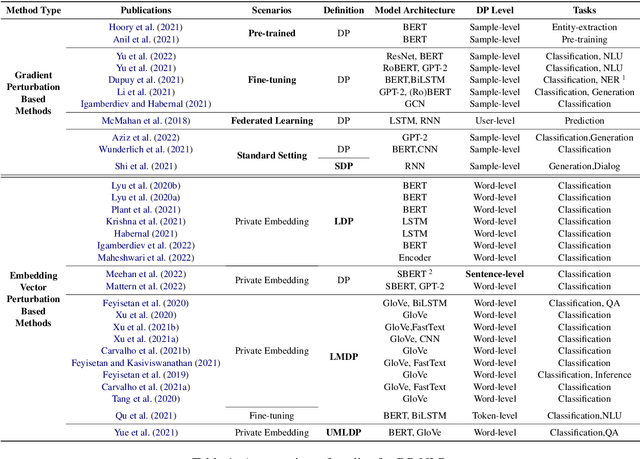
Recent developments in deep learning have led to great success in various natural language processing (NLP) tasks. However, these applications may involve data that contain sensitive information. Therefore, how to achieve good performance while also protect privacy of sensitive data is a crucial challenge in NLP. To preserve privacy, Differential Privacy (DP), which can prevent reconstruction attacks and protect against potential side knowledge, is becoming a de facto technique for private data analysis. In recent years, NLP in DP models (DP-NLP) has been studied from different perspectives, which deserves a comprehensive review. In this paper, we provide the first systematic review of recent advances on DP deep learning models in NLP. In particular, we first discuss some differences and additional challenges of DP-NLP compared with the standard DP deep learning. Then we investigate some existing work on DP-NLP and present its recent developments from two aspects: gradient perturbation based methods and embedding vector perturbation based methods. We also discuss some challenges and future directions of this topic.
Distributed LSTM-Learning from Differentially Private Label Proportions
Jan 15, 2023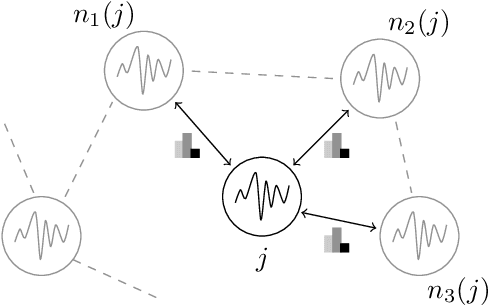
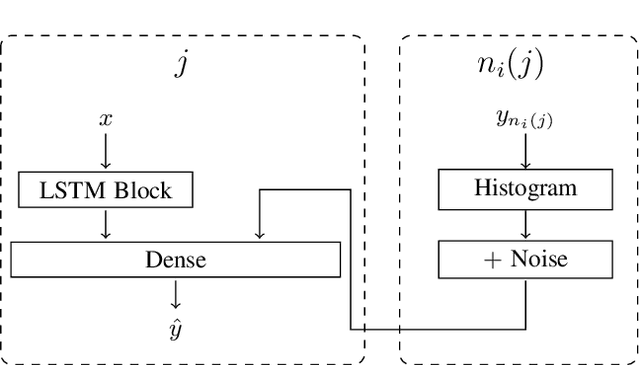
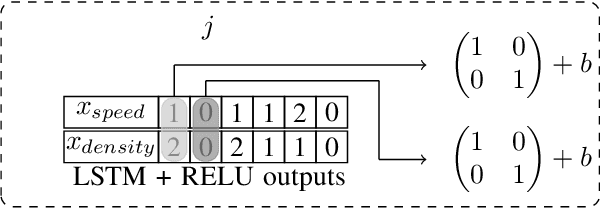
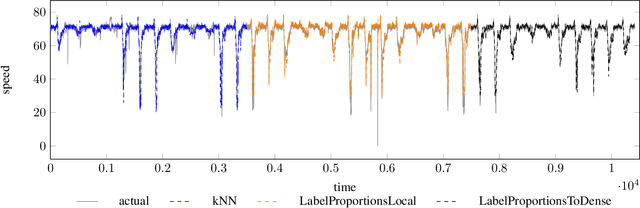
Data privacy and decentralised data collection has become more and more popular in recent years. In order to solve issues with privacy, communication bandwidth and learning from spatio-temporal data, we will propose two efficient models which use Differential Privacy and decentralized LSTM-Learning: One, in which a Long Short Term Memory (LSTM) model is learned for extracting local temporal node constraints and feeding them into a Dense-Layer (LabelProportionToLocal). The other approach extends the first one by fetching histogram data from the neighbors and joining the information with the LSTM output (LabelProportionToDense). For evaluation two popular datasets are used: Pems-Bay and METR-LA. Additionally, we provide an own dataset, which is based on LuST. The evaluation will show the tradeoff between performance and data privacy.
Learning as Conversation: Dialogue Systems Reinforced for Information Acquisition
May 29, 2022



We propose novel AI-empowered chat bots for learning as conversation where a user does not read a passage but gains information and knowledge through conversation with a teacher bot. Our information-acquisition-oriented dialogue system employs a novel adaptation of reinforced self-play so that the system can be transferred to various domains without in-domain dialogue data, and can carry out conversations both informative and attentive to users. Our extensive subjective and objective evaluations on three large public data corpora demonstrate the effectiveness of our system to deliver knowledge-intensive and attentive conversations and help end users substantially gain knowledge without reading passages. Our code and datasets are publicly available for follow-up research.
k-Means SubClustering: A Differentially Private Algorithm with Improved Clustering Quality
Jan 07, 2023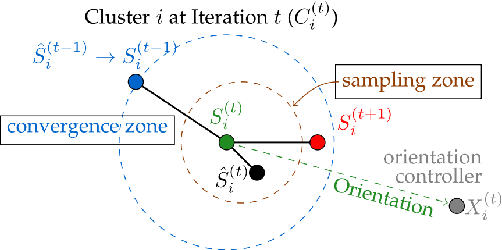
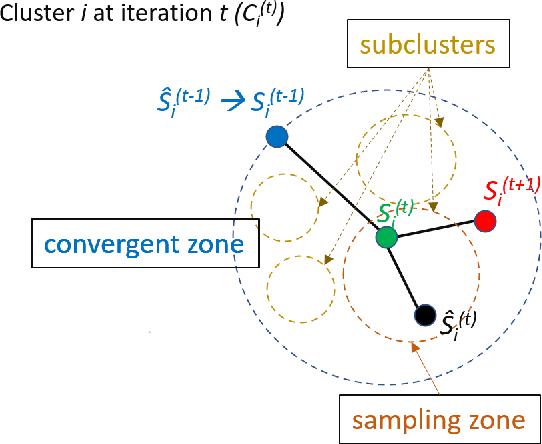
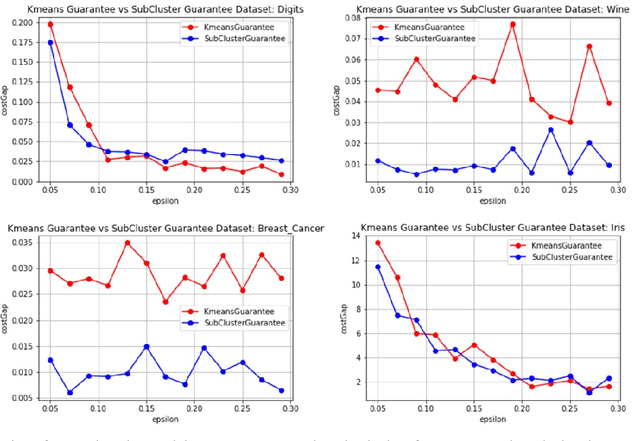
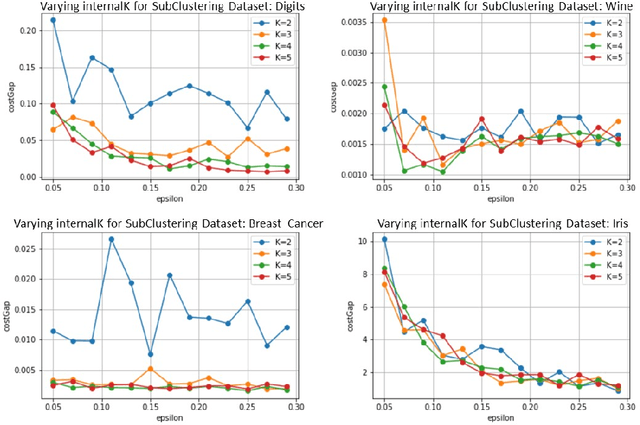
In today's data-driven world, the sensitivity of information has been a significant concern. With this data and additional information on the person's background, one can easily infer an individual's private data. Many differentially private iterative algorithms have been proposed in interactive settings to protect an individual's privacy from these inference attacks. The existing approaches adapt the method to compute differentially private(DP) centroids by iterative Llyod's algorithm and perturbing the centroid with various DP mechanisms. These DP mechanisms do not guarantee convergence of differentially private iterative algorithms and degrade the quality of the cluster. Thus, in this work, we further extend the previous work on 'Differentially Private k-Means Clustering With Convergence Guarantee' by taking it as our baseline. The novelty of our approach is to sub-cluster the clusters and then select the centroid which has a higher probability of moving in the direction of the future centroid. At every Lloyd's step, the centroids are injected with the noise using the exponential DP mechanism. The results of the experiments indicate that our approach outperforms the current state-of-the-art method, i.e., the baseline algorithm, in terms of clustering quality while maintaining the same differential privacy requirements. The clustering quality significantly improved by 4.13 and 2.83 times than baseline for the Wine and Breast_Cancer dataset, respectively.
Better Hit the Nail on the Head than Beat around the Bush: Removing Protected Attributes with a Single Projection
Dec 08, 2022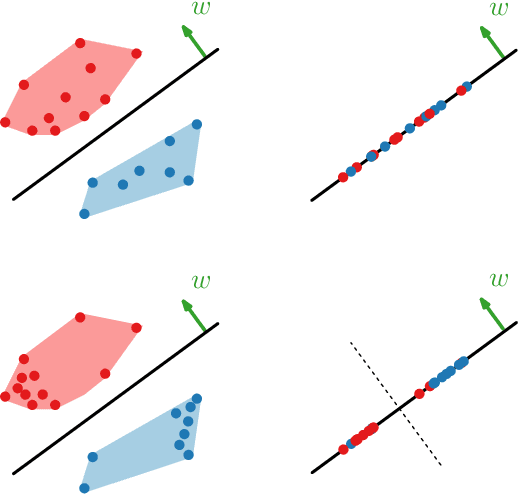
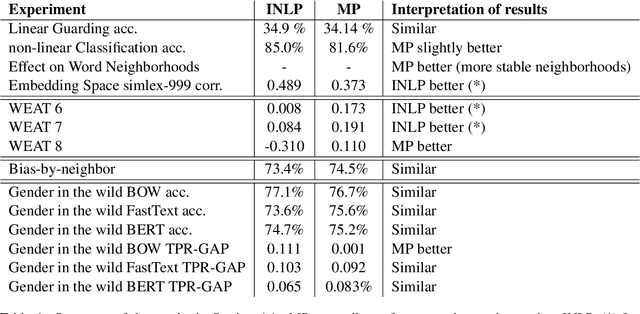
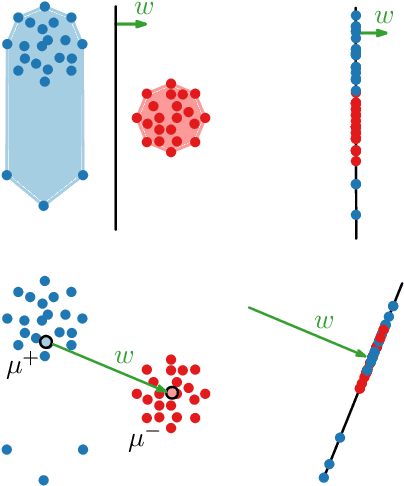

Bias elimination and recent probing studies attempt to remove specific information from embedding spaces. Here it is important to remove as much of the target information as possible, while preserving any other information present. INLP is a popular recent method which removes specific information through iterative nullspace projections. Multiple iterations, however, increase the risk that information other than the target is negatively affected. We introduce two methods that find a single targeted projection: Mean Projection (MP, more efficient) and Tukey Median Projection (TMP, with theoretical guarantees). Our comparison between MP and INLP shows that (1) one MP projection removes linear separability based on the target and (2) MP has less impact on the overall space. Further analysis shows that applying random projections after MP leads to the same overall effects on the embedding space as the multiple projections of INLP. Applying one targeted (MP) projection hence is methodologically cleaner than applying multiple (INLP) projections that introduce random effects.
* EMNLP 2022