 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Heterophily-Aware Graph Attention Network
Feb 07, 2023
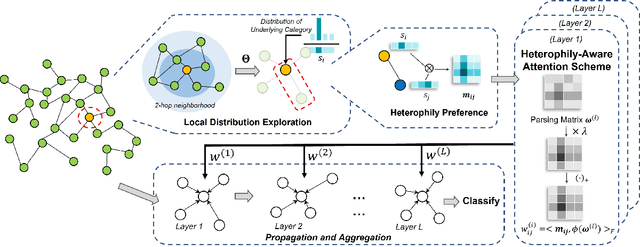
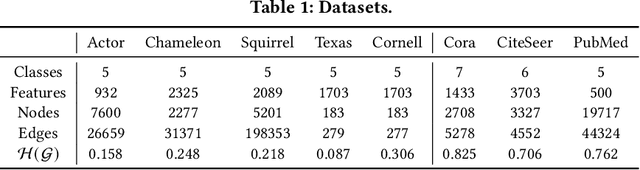
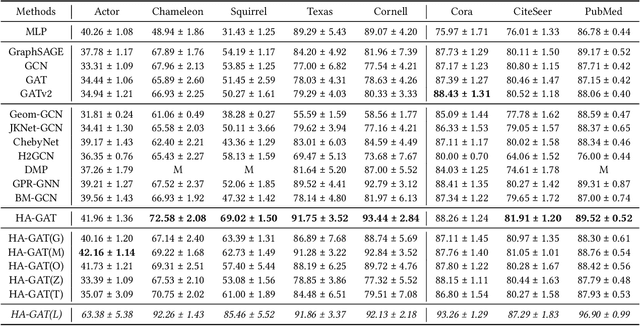
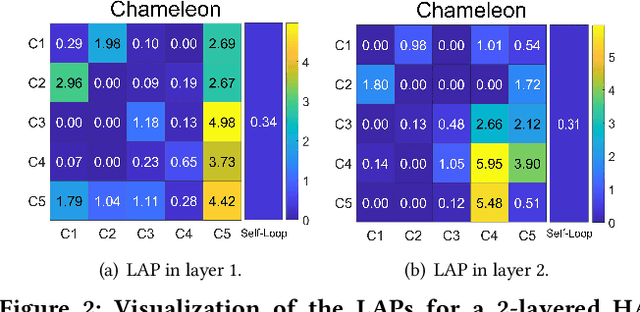
Graph Neural Networks (GNNs) have shown remarkable success in graph representation learning. Unfortunately, current weight assignment schemes in standard GNNs, such as the calculation based on node degrees or pair-wise representations, can hardly be effective in processing the networks with heterophily, in which the connected nodes usually possess different labels or features. Existing heterophilic GNNs tend to ignore the modeling of heterophily of each edge, which is also a vital part in tackling the heterophily problem. In this paper, we firstly propose a heterophily-aware attention scheme and reveal the benefits of modeling the edge heterophily, i.e., if a GNN assigns different weights to edges according to different heterophilic types, it can learn effective local attention patterns, which enable nodes to acquire appropriate information from distinct neighbors. Then, we propose a novel Heterophily-Aware Graph Attention Network (HA-GAT) by fully exploring and utilizing the local distribution as the underlying heterophily, to handle the networks with different homophily ratios. To demonstrate the effectiveness of the proposed HA-GAT, we analyze the proposed heterophily-aware attention scheme and local distribution exploration, by seeking for an interpretation from their mechanism. Extensive results demonstrate that our HA-GAT achieves state-of-the-art performances on eight datasets with different homophily ratios in both the supervised and semi-supervised node classification tasks.
Transfer learning for process design with reinforcement learning
Feb 07, 2023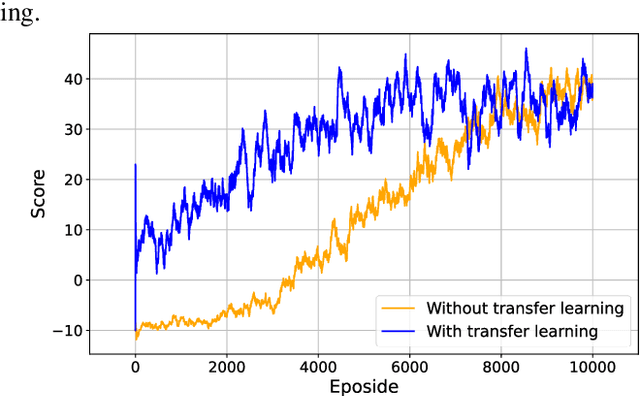

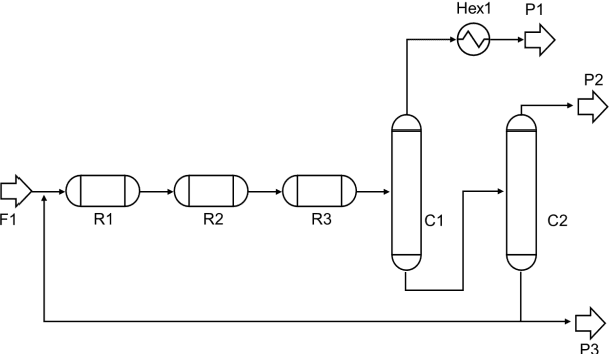
Process design is a creative task that is currently performed manually by engineers. Artificial intelligence provides new potential to facilitate process design. Specifically, reinforcement learning (RL) has shown some success in automating process design by integrating data-driven models that learn to build process flowsheets with process simulation in an iterative design process. However, one major challenge in the learning process is that the RL agent demands numerous process simulations in rigorous process simulators, thereby requiring long simulation times and expensive computational power. Therefore, typically short-cut simulation methods are employed to accelerate the learning process. Short-cut methods can, however, lead to inaccurate results. We thus propose to utilize transfer learning for process design with RL in combination with rigorous simulation methods. Transfer learning is an established approach from machine learning that stores knowledge gained while solving one problem and reuses this information on a different target domain. We integrate transfer learning in our RL framework for process design and apply it to an illustrative case study comprising equilibrium reactions, azeotropic separation, and recycles, our method can design economically feasible flowsheets with stable interaction with DWSIM. Our results show that transfer learning enables RL to economically design feasible flowsheets with DWSIM, resulting in a flowsheet with an 8% higher revenue. And the learning time can be reduced by a factor of 2.
OPERA: Harmonizing Task-Oriented Dialogs and Information Seeking Experience
Jun 24, 2022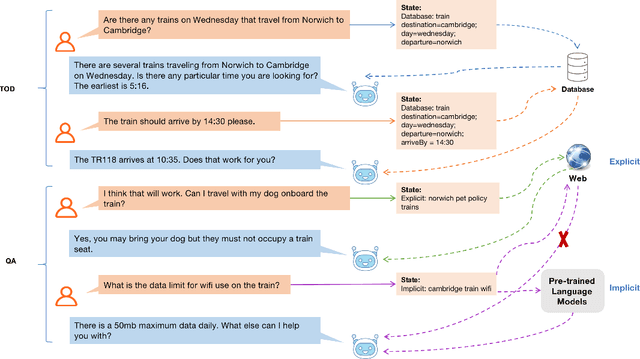
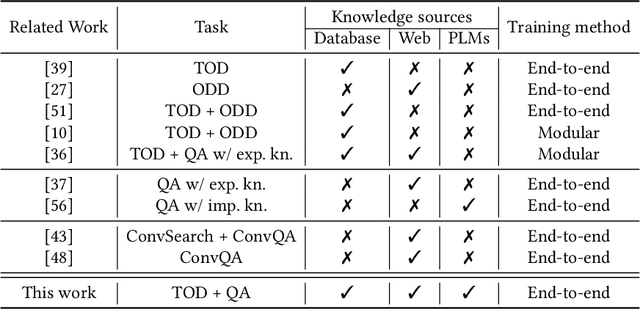
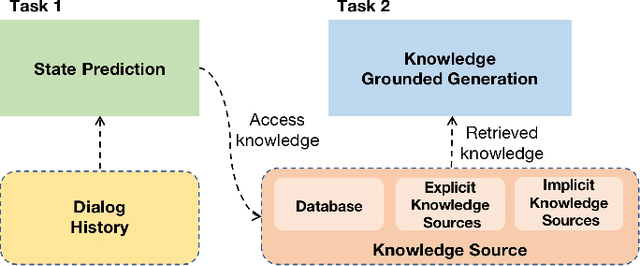

Existing studies in conversational AI mostly treat task-oriented dialog (TOD) and question answering (QA) as separate tasks. Towards the goal of constructing a conversational agent that can complete user tasks and support information seeking, it is important to build a system that handles both TOD and QA with access to various external knowledge. In this work, we propose a new task, Open-Book TOD (OB-TOD), which combines TOD with QA task and expand external knowledge sources to include both explicit knowledge sources (e.g., the Web) and implicit knowledge sources (e.g., pre-trained language models). We create a new dataset OB-MultiWOZ, where we enrich TOD sessions with QA-like information seeking experience grounded on external knowledge. We propose a unified model OPERA (Open-book End-to-end Task-oriented Dialog) which can appropriately access explicit and implicit external knowledge to tackle the defined task. Experimental results demonstrate OPERA's superior performance compared to closed-book baselines and illustrate the value of both knowledge types.
Active Deep Learning Guided by Efficient Gaussian Process Surrogates
Jan 07, 2023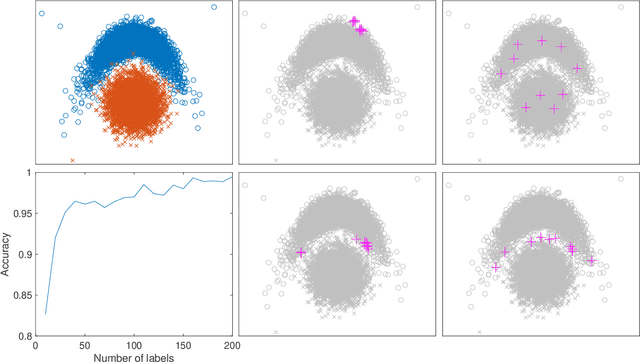
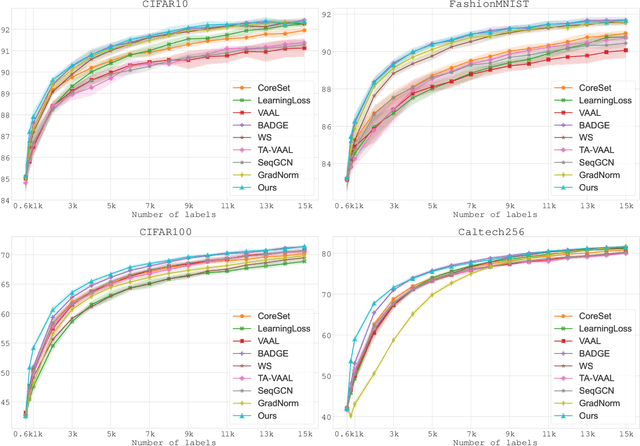
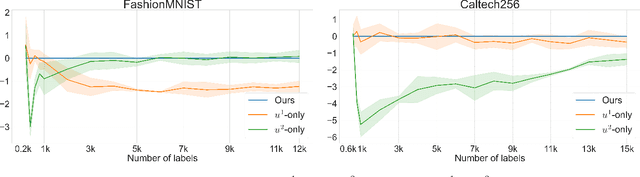
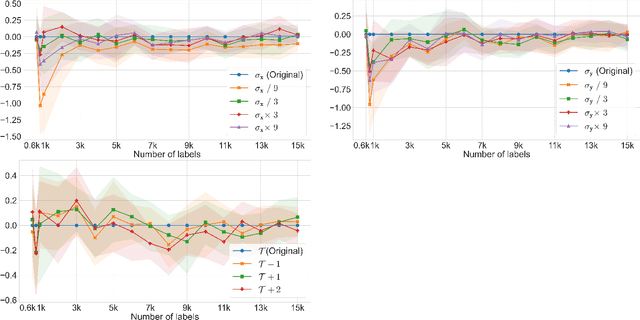
The success of active learning relies on the exploration of the underlying data-generating distributions, populating sparsely labeled data areas, and exploitation of the information about the task gained by the baseline (neural network) learners. In this paper, we present a new algorithm that combines these two active learning modes. Our algorithm adopts a Bayesian surrogate for the baseline learner, and it optimizes the exploration process by maximizing the gain of information caused by new labels. Further, by instantly updating the surrogate learner for each new data instance, our model can faithfully simulate and exploit the continuous learning behavior of the learner without having to actually retrain it per label. In experiments with four benchmark classification datasets, our method demonstrated significant performance gain over state-of-the-arts.
Learning to Generate Questions by Enhancing Text Generation with Sentence Selection
Dec 23, 2022
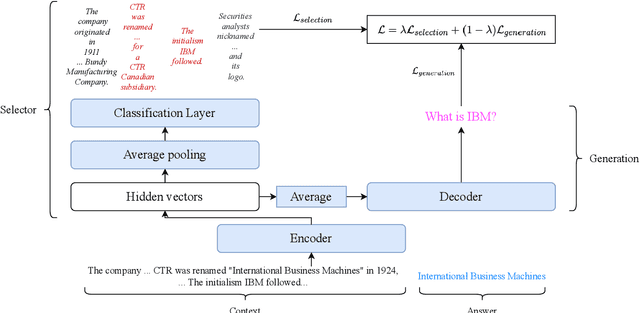
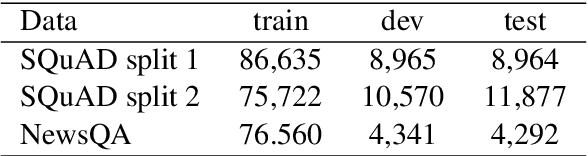
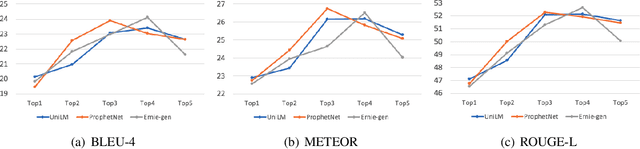
We introduce an approach for the answer-aware question generation problem. Instead of only relying on the capability of strong pre-trained language models, we observe that the information of answers and questions can be found in some relevant sentences in the context. Based on that, we design a model which includes two modules: a selector and a generator. The selector forces the model to more focus on relevant sentences regarding an answer to provide implicit local information. The generator generates questions by implicitly combining local information from the selector and global information from the whole context encoded by the encoder. The model is trained jointly to take advantage of latent interactions between the two modules. Experimental results on two benchmark datasets show that our model is better than strong pre-trained models for the question generation task. The code is also available (shorturl.at/lV567).
VoronoiPatches: Evaluating A New Data Augmentation Method
Dec 23, 2022



Overfitting is a problem in Convolutional Neural Networks (CNN) that causes poor generalization of models on unseen data. To remediate this problem, many new and diverse data augmentation methods (DA) have been proposed to supplement or generate more training data, and thereby increase its quality. In this work, we propose a new data augmentation algorithm: VoronoiPatches (VP). We primarily utilize non-linear recombination of information within an image, fragmenting and occluding small information patches. Unlike other DA methods, VP uses small convex polygon-shaped patches in a random layout to transport information around within an image. Sudden transitions created between patches and the original image can, optionally, be smoothed. In our experiments, VP outperformed current DA methods regarding model variance and overfitting tendencies. We demonstrate data augmentation utilizing non-linear re-combination of information within images, and non-orthogonal shapes and structures improves CNN model robustness on unseen data.
Leveraging Importance Weights in Subset Selection
Jan 28, 2023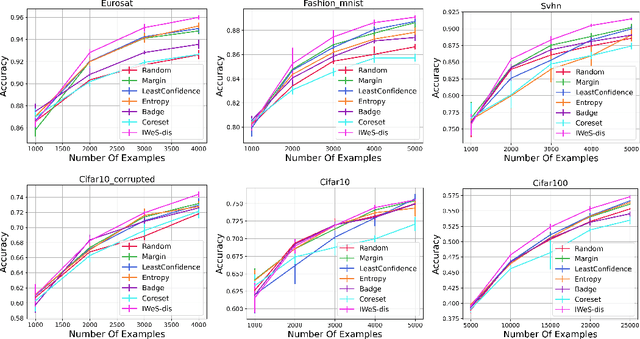
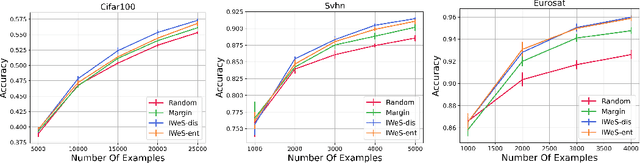
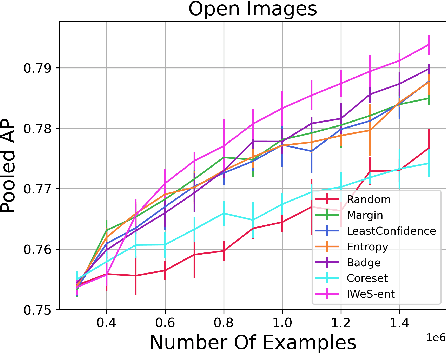
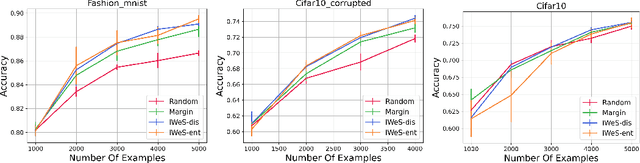
We present a subset selection algorithm designed to work with arbitrary model families in a practical batch setting. In such a setting, an algorithm can sample examples one at a time but, in order to limit overhead costs, is only able to update its state (i.e. further train model weights) once a large enough batch of examples is selected. Our algorithm, IWeS, selects examples by importance sampling where the sampling probability assigned to each example is based on the entropy of models trained on previously selected batches. IWeS admits significant performance improvement compared to other subset selection algorithms for seven publicly available datasets. Additionally, it is competitive in an active learning setting, where the label information is not available at selection time. We also provide an initial theoretical analysis to support our importance weighting approach, proving generalization and sampling rate bounds.
Two-Aspect Information Fusion Model For ABAW4 Multi-task Challenge
Jul 23, 2022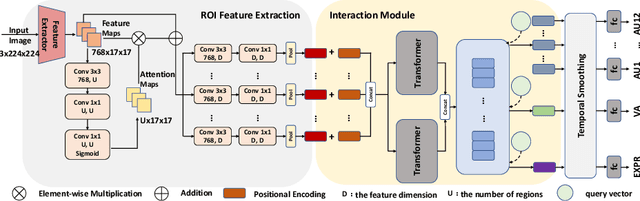
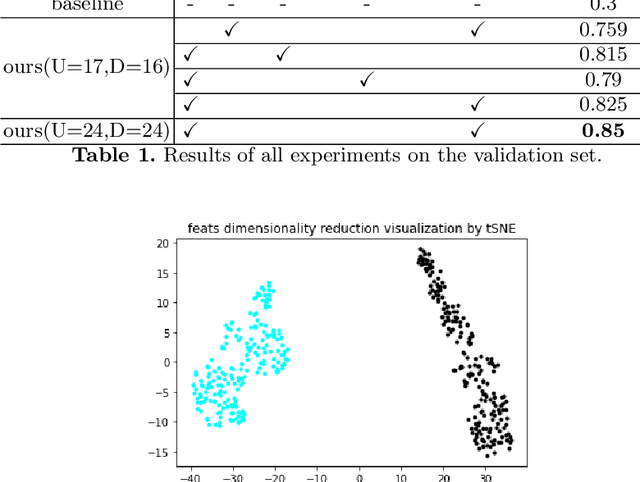

In this paper, we propose the solution to the Multi-Task Learning (MTL) Challenge of the 4th Affective Behavior Analysis in-the-wild (ABAW) competition. The task of ABAW is to predict frame-level emotion descriptors from videos: discrete emotional state; valence and arousal; and action units. Although researchers have proposed several approaches and achieved promising results in ABAW, current works in this task rarely consider interactions between different emotion descriptors. To this end, we propose a novel end to end architecture to achieve full integration of different types of information. Experimental results demonstrate the effectiveness of our proposed solution.
Reconstruction-driven motion estimation for motion-compensated MR CINE imaging
Feb 05, 2023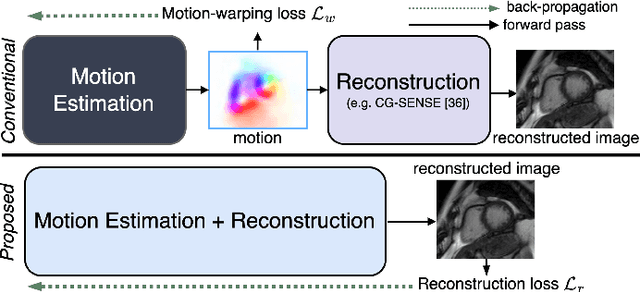
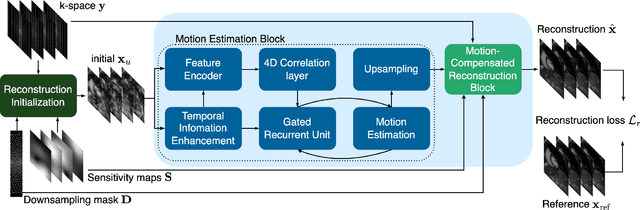
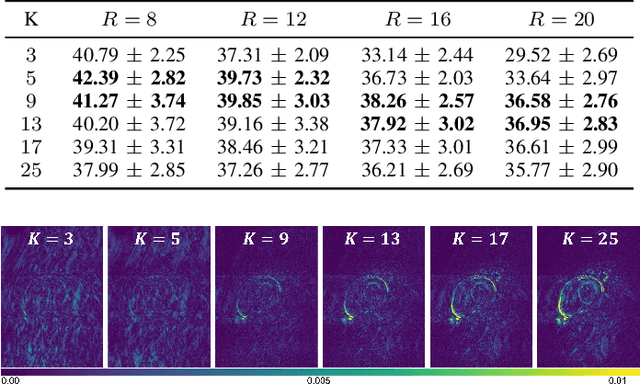
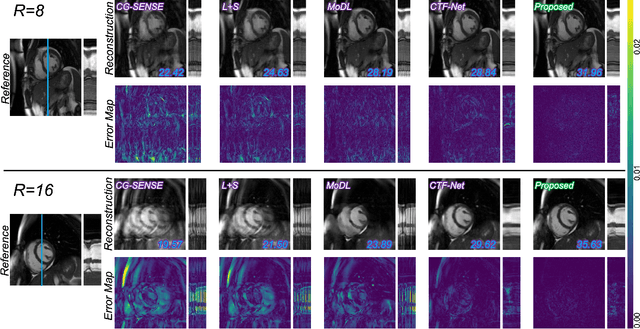
In cardiac CINE, motion-compensated MR reconstruction (MCMR) is an effective approach to address highly undersampled acquisitions by incorporating motion information between frames. In this work, we propose a deep learning-based framework to address the MCMR problem efficiently. Contrary to state-of-the-art (SOTA) MCMR methods which break the original problem into two sub-optimization problems, i.e. motion estimation and reconstruction, we formulate this problem as a single entity with one single optimization. We discard the canonical motion-warping loss (similarity measurement between motion-warped images and target images) to estimate the motion, but drive the motion estimation process directly by the final reconstruction performance. The higher reconstruction quality is achieved without using any smoothness loss terms and without iterative processing between motion estimation and reconstruction. Therefore, we avoid non-trivial loss weighting factors tuning and time-consuming iterative processing. Experiments on 43 in-house acquired 2D CINE datasets indicate that the proposed MCMR framework can deliver artifact-free motion estimation and high-quality MR images even for imaging accelerations up to 20x. The proposed framework is compared to SOTA non-MCMR and MCMR methods and outperforms these methods qualitatively and quantitatively in all applied metrics across all experiments with different acceleration rates.
Adversarial Learning Data Augmentation for Graph Contrastive Learning in Recommendation
Feb 05, 2023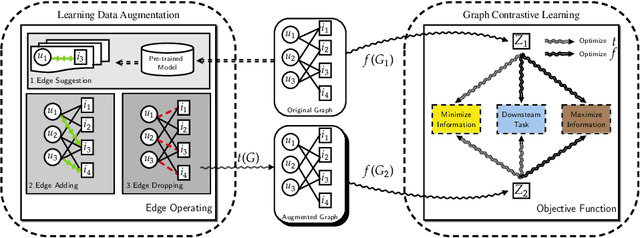
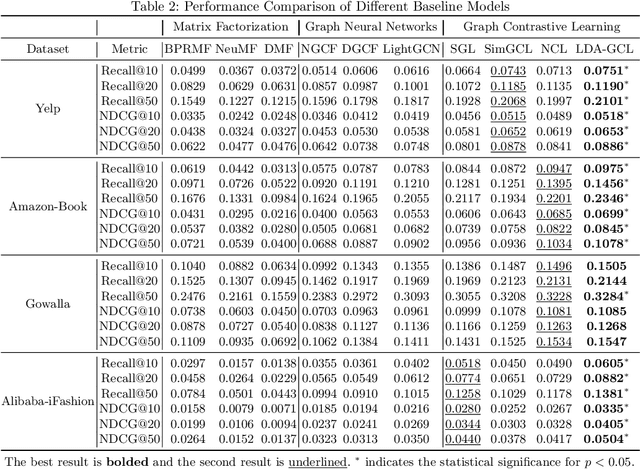
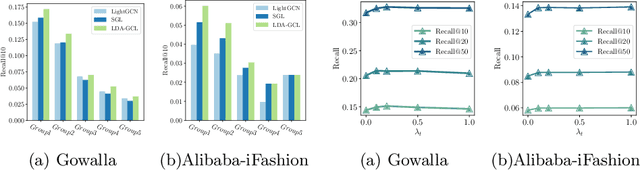
Recently, Graph Neural Networks (GNNs) achieve remarkable success in Recommendation. To reduce the influence of data sparsity, Graph Contrastive Learning (GCL) is adopted in GNN-based CF methods for enhancing performance. Most GCL methods consist of data augmentation and contrastive loss (e.g., InfoNCE). GCL methods construct the contrastive pairs by hand-crafted graph augmentations and maximize the agreement between different views of the same node compared to that of other nodes, which is known as the InfoMax principle. However, improper data augmentation will hinder the performance of GCL. InfoMin principle, that the good set of views shares minimal information and gives guidelines to design better data augmentation. In this paper, we first propose a new data augmentation (i.e., edge-operating including edge-adding and edge-dropping). Then, guided by InfoMin principle, we propose a novel theoretical guiding contrastive learning framework, named Learnable Data Augmentation for Graph Contrastive Learning (LDA-GCL). Our methods include data augmentation learning and graph contrastive learning, which follow the InfoMin and InfoMax principles, respectively. In implementation, our methods optimize the adversarial loss function to learn data augmentation and effective representations of users and items. Extensive experiments on four public benchmark datasets demonstrate the effectiveness of LDA-GCL.