 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Human-Machine Collaboration for Smart Decision Making: Current Trends and Future Opportunities
Jan 18, 2023
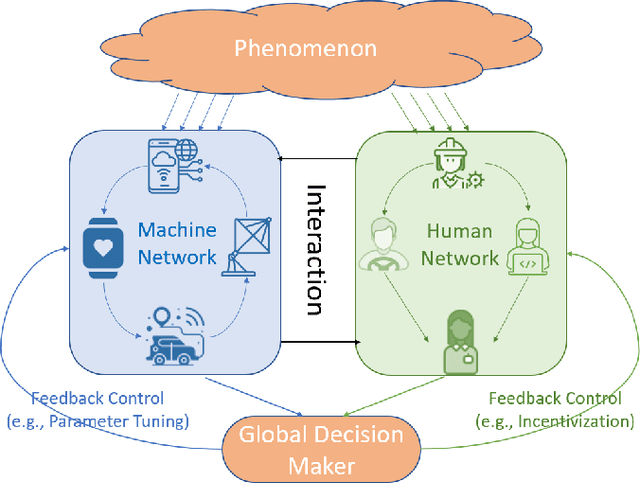
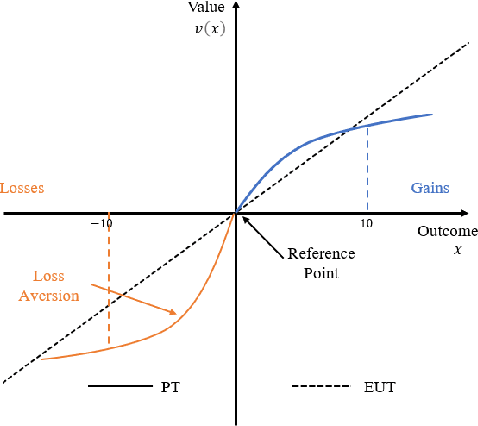
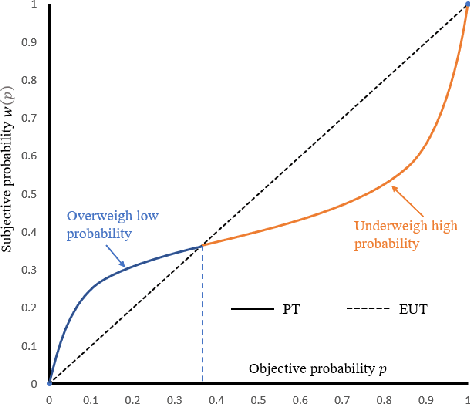
Recently, modeling of decision making and control systems that include heterogeneous smart sensing devices (machines) as well as human agents as participants is becoming an important research area due to the wide variety of applications including autonomous driving, smart manufacturing, internet of things, national security, and healthcare. To accomplish complex missions under uncertainty, it is imperative that we build novel human machine collaboration structures to integrate the cognitive strengths of humans with computational capabilities of machines in an intelligent manner. In this paper, we present an overview of the existing works on human decision making and human machine collaboration within the scope of signal processing and information fusion. We review several application areas and research domains relevant to human machine collaborative decision making. We also discuss current challenges and future directions in this problem domain.
Compression of GPS Trajectories using Autoencoders
Jan 18, 2023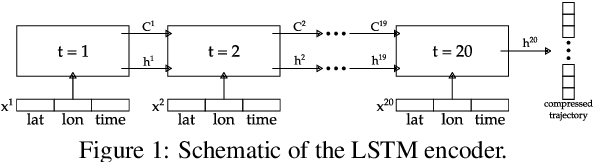
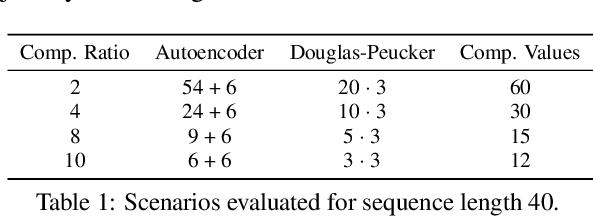
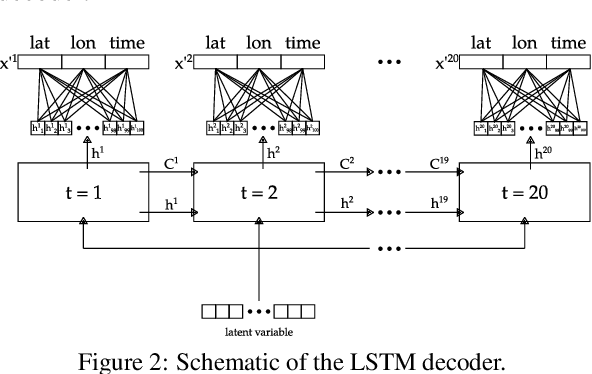
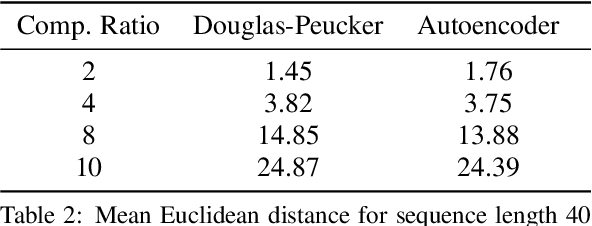
The ubiquitous availability of mobile devices capable of location tracking led to a significant rise in the collection of GPS data. Several compression methods have been developed in order to reduce the amount of storage needed while keeping the important information. In this paper, we present an lstm-autoencoder based approach in order to compress and reconstruct GPS trajectories, which is evaluated on both a gaming and real-world dataset. We consider various compression ratios and trajectory lengths. The performance is compared to other trajectory compression algorithms, i.e., Douglas-Peucker. Overall, the results indicate that our approach outperforms Douglas-Peucker significantly in terms of the discrete Fr\'echet distance and dynamic time warping. Furthermore, by reconstructing every point lossy, the proposed methodology offers multiple advantages over traditional methods.
RIScatter: Unifying Backscatter Communication and Reconfigurable Intelligent Surface
Dec 18, 2022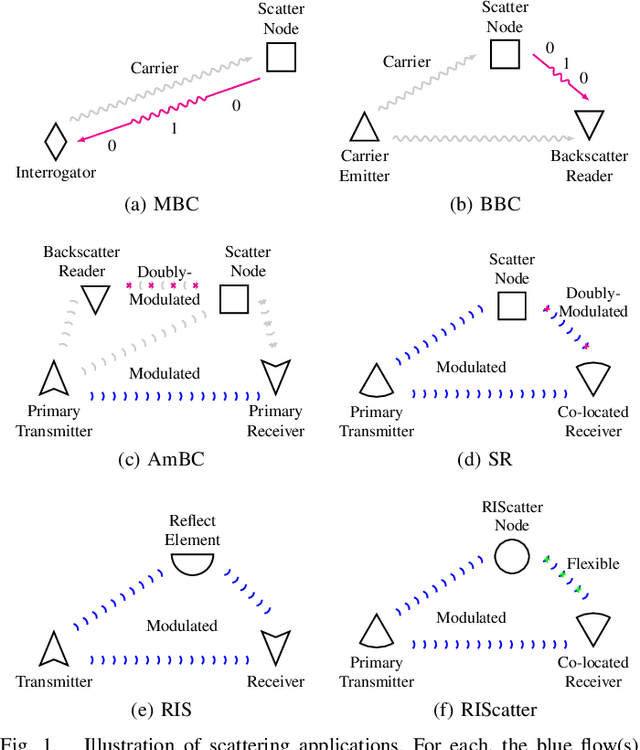
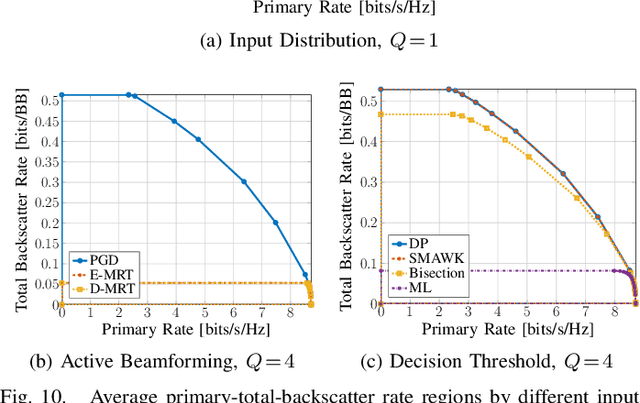
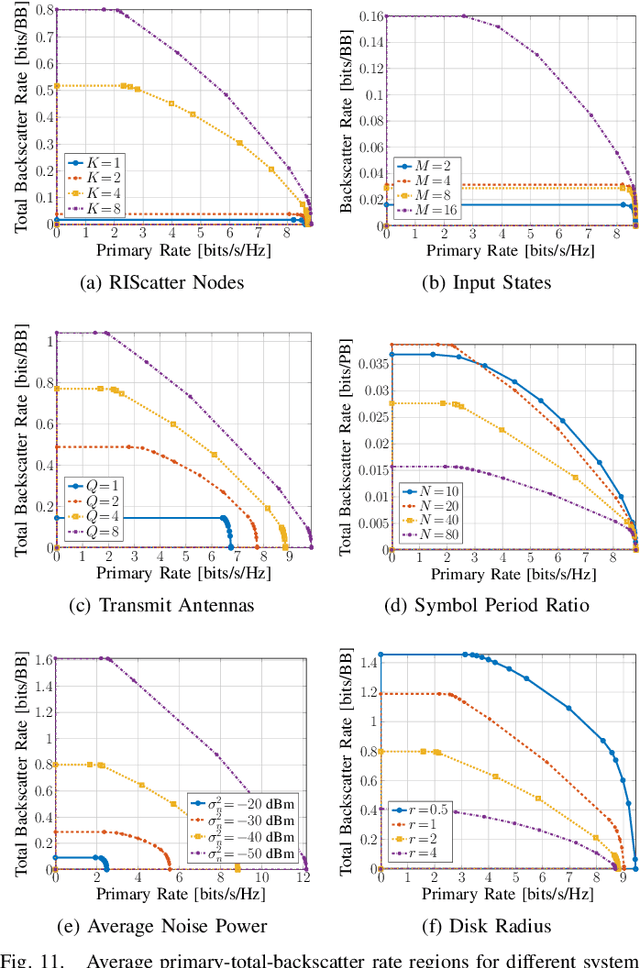

Backscatter Communication (BackCom) nodes harvest energy from and modulate information over an external electromagnetic wave. Reconfigurable Intelligent Surface (RIS) adapts its phase shift response to enhance or attenuate channel strength in specific directions. In this paper, we show how those two seemingly different technologies (and their derivatives) can be unified to leverage their benefits simultaneously into a single architecture called RIScatter. RIScatter consists of multiple dispersed or co-located scatter nodes, whose reflection states can be adapted to partially engineer the wireless channel of the existing link and partially modulate their own information onto the scattered wave. This contrasts with BackCom (resp. RIS) where the reflection pattern is exclusively a function of the information symbol (resp. Channel State Information (CSI)). The key principle in RIScatter is to render the probability distribution of reflection states (i.e., backscatter channel input) as a joint function of the information source, CSI, and Quality of Service (QoS) of the coexisting active primary and passive backscatter links. This enables RIScatter to softly bridge, generalize, and outperform BackCom and RIS; boil down to either under specific input distribution; or evolve in a mixed form for heterogeneous traffic control and universal hardware design. For a single-user multi-node RIScatter network, we characterize the achievable primary-(total-)backscatter rate region by optimizing the input distribution at the nodes, the active beamforming at the Access Point (AP), and the backscatter detection regions at the user. Simulation results demonstrate RIScatter nodes can exploit the additional propagation paths to smoothly transition between backscatter modulation and passive beamforming.
Time-Series Pattern Recognition in Smart Manufacturing Systems: A Literature Review and Ontology
Jan 29, 2023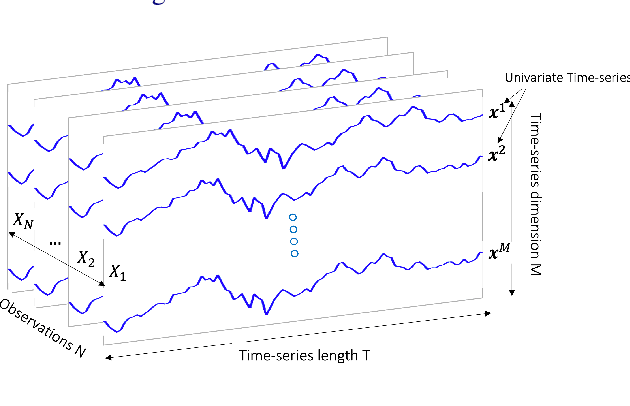
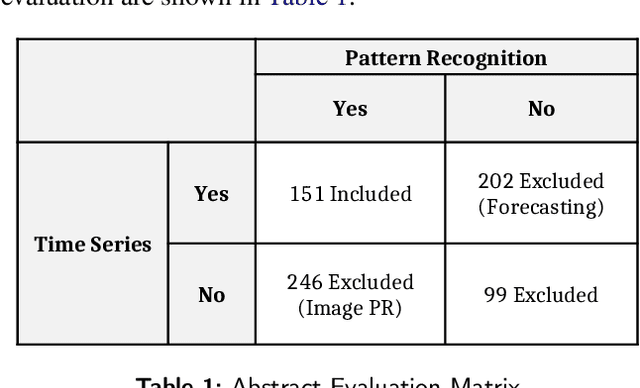
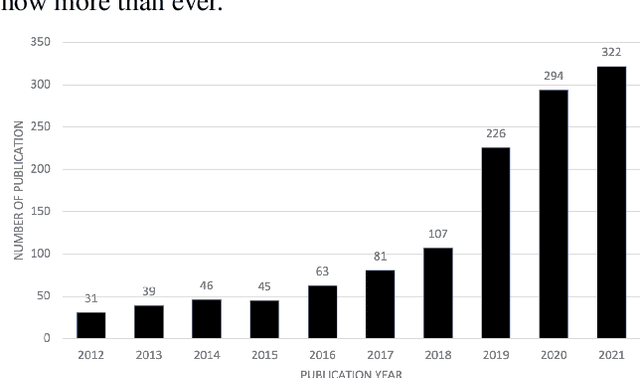
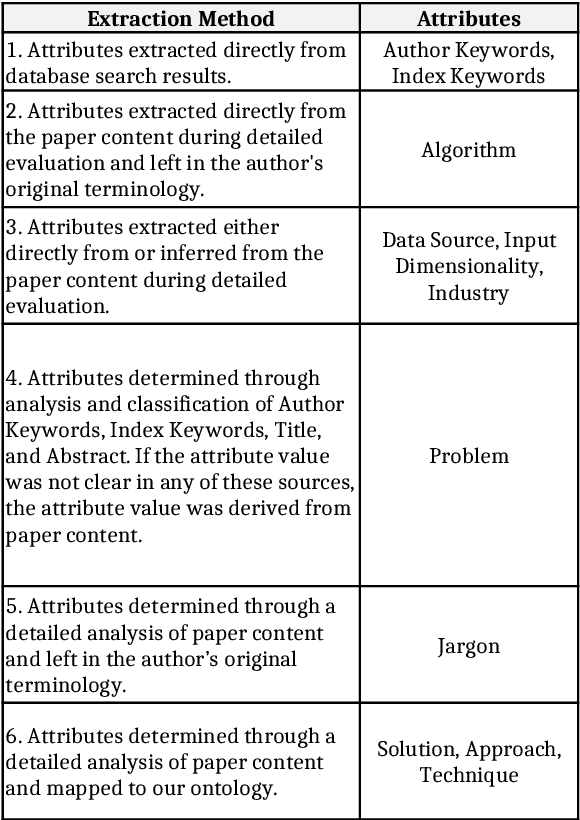
Since the inception of Industry 4.0 in 2012, emerging technologies have enabled the acquisition of vast amounts of data from diverse sources such as machine tools, robust and affordable sensor systems with advanced information models, and other sources within Smart Manufacturing Systems (SMS). As a result, the amount of data that is available in manufacturing settings has exploded, allowing data-hungry tools such as Artificial Intelligence (AI) and Machine Learning (ML) to be leveraged. Time-series analytics has been successfully applied in a variety of industries, and that success is now being migrated to pattern recognition applications in manufacturing to support higher quality products, zero defect manufacturing, and improved customer satisfaction. However, the diverse landscape of manufacturing presents a challenge for successfully solving problems in industry using time-series pattern recognition. The resulting research gap of understanding and applying the subject matter of time-series pattern recognition in manufacturing is a major limiting factor for adoption in industry. The purpose of this paper is to provide a structured perspective of the current state of time-series pattern recognition in manufacturing with a problem-solving focus. By using an ontology to classify and define concepts, how they are structured, their properties, the relationships between them, and considerations when applying them, this paper aims to provide practical and actionable guidelines for application and recommendations for advancing time-series analytics.
Multi-video Moment Ranking with Multimodal Clue
Jan 29, 2023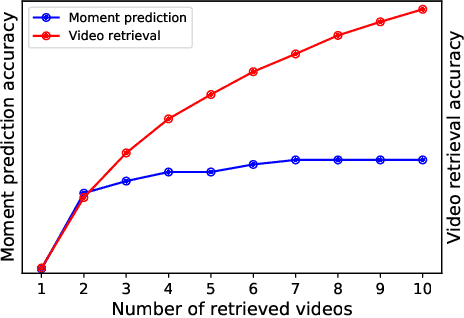
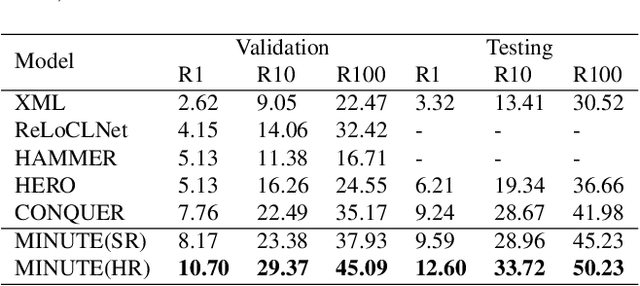

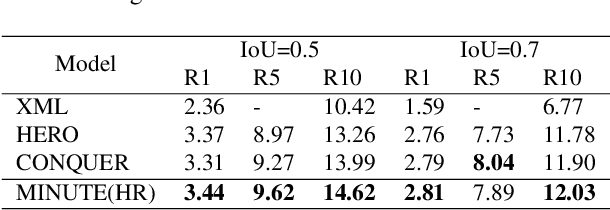
Video corpus moment retrieval~(VCMR) is the task of retrieving a relevant video moment from a large corpus of untrimmed videos via a natural language query. State-of-the-art work for VCMR is based on two-stage method. In this paper, we focus on improving two problems of two-stage method: (1) Moment prediction bias: The predicted moments for most queries come from the top retrieved videos, ignoring the possibility that the target moment is in the bottom retrieved videos, which is caused by the inconsistency of Shared Normalization during training and inference. (2) Latent key content: Different modalities of video have different key information for moment localization. To this end, we propose a two-stage model \textbf{M}ult\textbf{I}-video ra\textbf{N}king with m\textbf{U}l\textbf{T}imodal clu\textbf{E}~(MINUTE). MINUTE uses Shared Normalization during both training and inference to rank candidate moments from multiple videos to solve moment predict bias, making it more efficient to predict target moment. In addition, Mutilmdaol Clue Mining~(MCM) of MINUTE can discover key content of different modalities in video to localize moment more accurately. MINUTE outperforms the baselines on TVR and DiDeMo datasets, achieving a new state-of-the-art of VCMR. Our code will be available at GitHub.
On Approximating the Dynamic Response of Synchronous Generators via Operator Learning: A Step Towards Building Deep Operator-based Power Grid Simulators
Jan 29, 2023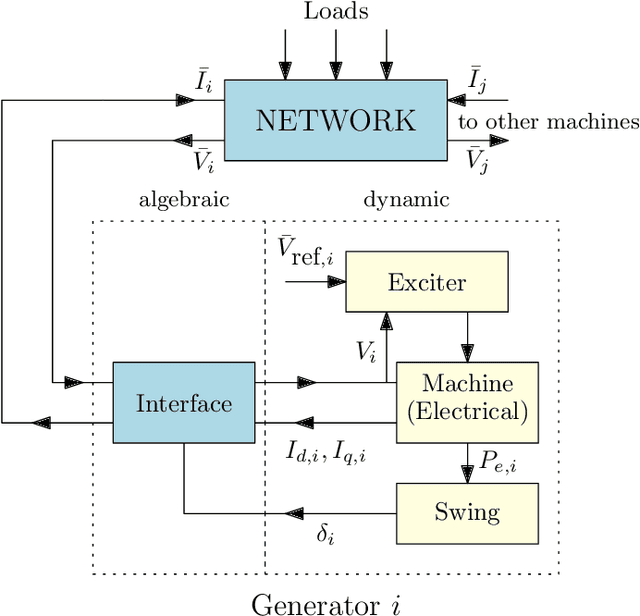

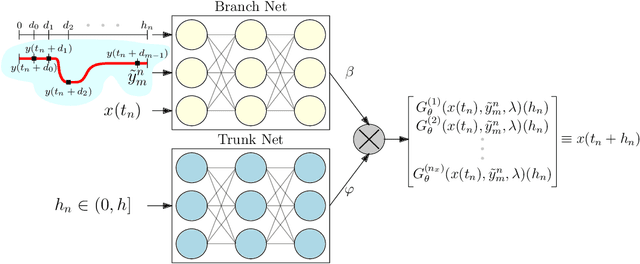

This paper designs an Operator Learning framework to approximate the dynamic response of synchronous generators. One can use such a framework to (i) design a neural-based generator model that can interact with a numerical simulator of the rest of the power grid or (ii) shadow the generator's transient response. To this end, we design a data-driven Deep Operator Network~(DeepONet) that approximates the generators' infinite-dimensional solution operator. Then, we develop a DeepONet-based numerical scheme to simulate a given generator's dynamic response over a short/medium-term horizon. The proposed numerical scheme recursively employs the trained DeepONet to simulate the response for a given multi-dimensional input, which describes the interaction between the generator and the rest of the system. Furthermore, we develop a residual DeepONet numerical scheme that incorporates information from mathematical models of synchronous generators. We accompany this residual DeepONet scheme with an estimate for the prediction's cumulative error. We also design a data aggregation (DAgger) strategy that allows (i) employing supervised learning to train the proposed DeepONets and (ii) fine-tuning the DeepONet using aggregated training data that the DeepONet is likely to encounter during interactive simulations with other grid components. Finally, as a proof of concept, we demonstrate that the proposed DeepONet frameworks can effectively approximate the transient model of a synchronous generator.
Unsupervised Domain Adaptation on Person Re-Identification via Dual-level Asymmetric Mutual Learning
Jan 29, 2023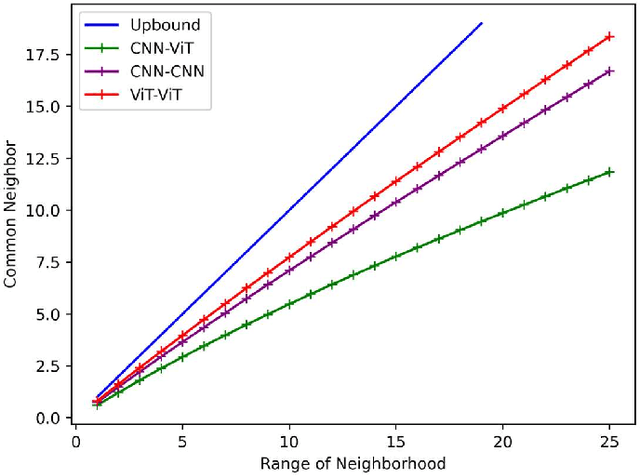
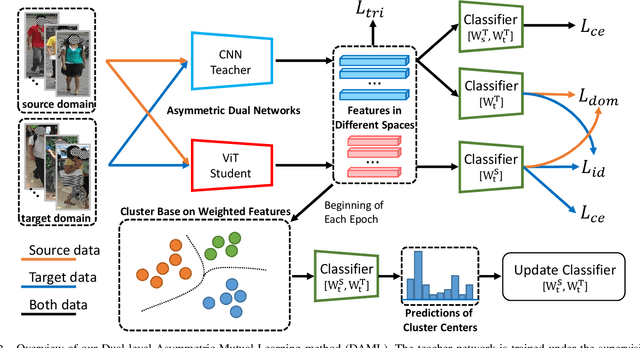
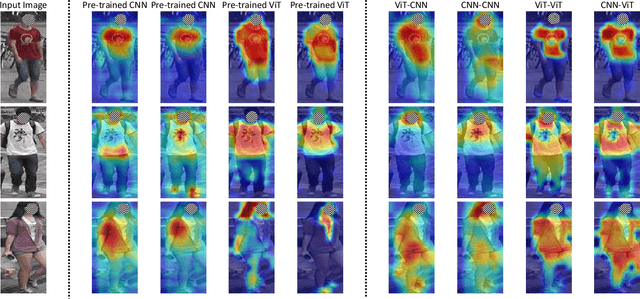
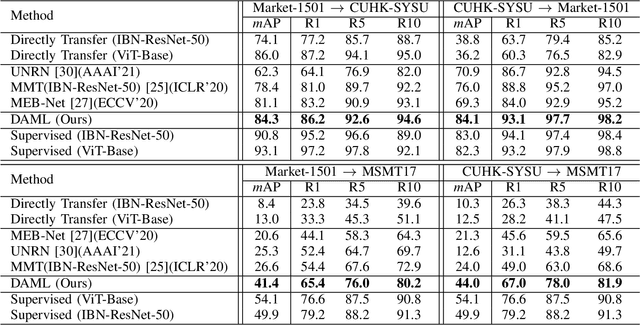
Unsupervised domain adaptation person re-identification (Re-ID) aims to identify pedestrian images within an unlabeled target domain with an auxiliary labeled source-domain dataset. Many existing works attempt to recover reliable identity information by considering multiple homogeneous networks. And take these generated labels to train the model in the target domain. However, these homogeneous networks identify people in approximate subspaces and equally exchange their knowledge with others or their mean net to improve their ability, inevitably limiting the scope of available knowledge and putting them into the same mistake. This paper proposes a Dual-level Asymmetric Mutual Learning method (DAML) to learn discriminative representations from a broader knowledge scope with diverse embedding spaces. Specifically, two heterogeneous networks mutually learn knowledge from asymmetric subspaces through the pseudo label generation in a hard distillation manner. The knowledge transfer between two networks is based on an asymmetric mutual learning manner. The teacher network learns to identify both the target and source domain while adapting to the target domain distribution based on the knowledge of the student. Meanwhile, the student network is trained on the target dataset and employs the ground-truth label through the knowledge of the teacher. Extensive experiments in Market-1501, CUHK-SYSU, and MSMT17 public datasets verified the superiority of DAML over state-of-the-arts.
PaCaNet: A Study on CycleGAN with Transfer Learning for Diversifying Fused Chinese Painting and Calligraphy
Feb 01, 2023

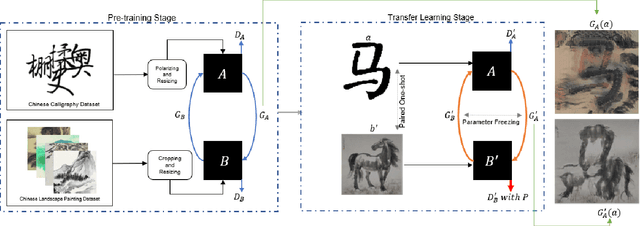
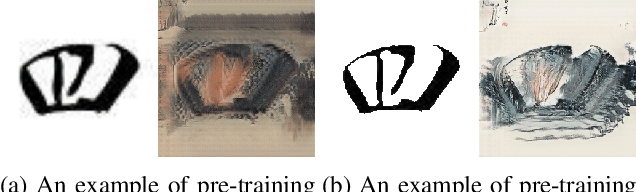
AI-Generated Content (AIGC) has recently gained a surge in popularity, powered by its high efficiency and consistency in production, and its capability of being customized and diversified. The cross-modality nature of the representation learning mechanism in most AIGC technology allows for more freedom and flexibility in exploring new types of art that would be impossible in the past. Inspired by the pictogram subset of Chinese characters, we proposed PaCaNet, a CycleGAN-based pipeline for producing novel artworks that fuse two different art types, traditional Chinese painting and calligraphy. In an effort to produce stable and diversified output, we adopted three main technical innovations: 1. Using one-shot learning to increase the creativity of pre-trained models and diversify the content of the fused images. 2. Controlling the preference over generated Chinese calligraphy by freezing randomly sampled parameters in pre-trained models. 3. Using a regularization method to encourage the models to produce images similar to Chinese paintings. Furthermore, we conducted a systematic study to explore the performance of PaCaNet in diversifying fused Chinese painting and calligraphy, which showed satisfying results. In conclusion, we provide a new direction of creating arts by fusing the visual information in paintings and the stroke features in Chinese calligraphy. Our approach creates a unique aesthetic experience rooted in the origination of Chinese hieroglyph characters. It is also a unique opportunity to delve deeper into traditional artwork and, in doing so, to create a meaningful impact on preserving and revitalizing traditional heritage.
Brazilian tailing dam collapse, retrospective precursory monitoring of InSAR data using spectral analysis of time series
Feb 01, 2023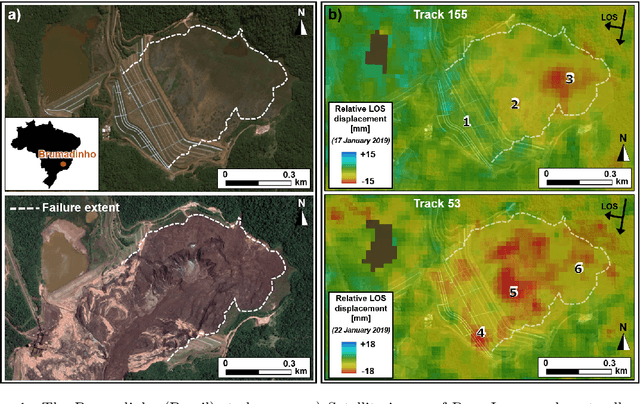
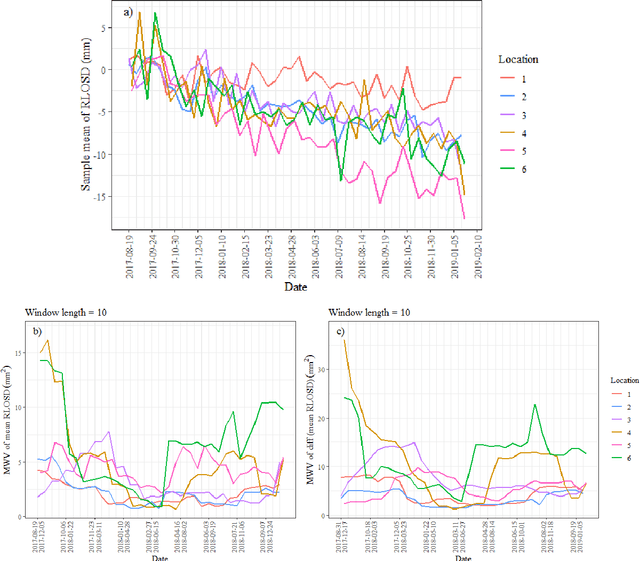
Slope failures possess destructive power that can cause significant damage to both life and infrastructure. Monitoring slopes prone to instabilities is therefore critical in mitigating the risk posed by their failure. The purpose of slope monitoring is to detect precursory signs of stability issues, such as changes in the rate of displacement with which a slope is deforming. This information can then be used to predict the timing or probability of an imminent failure in order to provide an early warning. In this study, a more objective, statistical-learning algorithm is proposed to detect and characterise the risk of a slope failure, based on spectral analysis of serially correlated displacement time series data. The algorithm is applied to satellite-based interferometric synthetic radar (InSAR) displacement time series data to retrospectively analyse the risk of the 2019 Brumadinho tailings dam collapse in Brazil. Two potential risk milestones are identified and signs of a definitive but emergent risk (27 February 2018 to 26 August 2018) and imminent risk of collapse of the tailings dam (27 June 2018 to 24 December 2018) are detected by the algorithm. Importantly, this precursory indication of risk of failure is detected as early as at least five months prior to the dam collapse on 25 January 2019. The results of this study demonstrate that the combination of spectral methods and second order statistical properties of InSAR displacement time series data can reveal signs of a transition into an unstable deformation regime, and that this algorithm can provide sufficient early warning that could help mitigate catastrophic slope failures.
Extrinsic Calibration of 2D mm-Wavelength Radar Pairs Using Ego-Velocity Estimates
Feb 01, 2023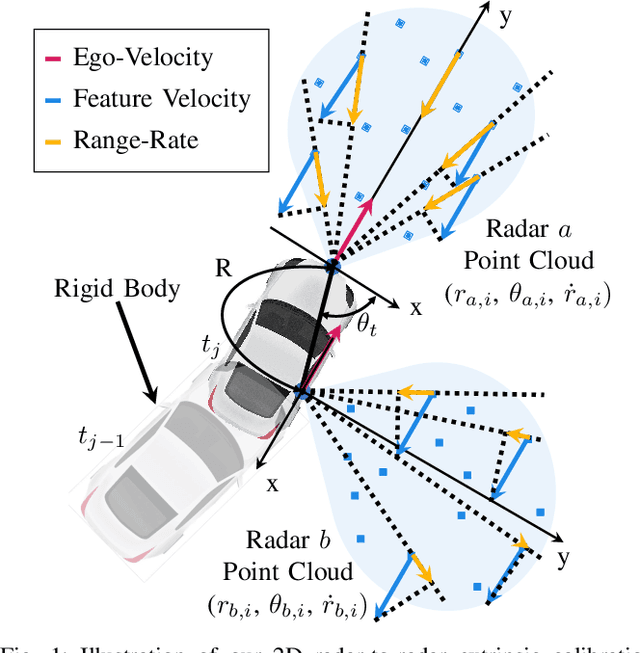
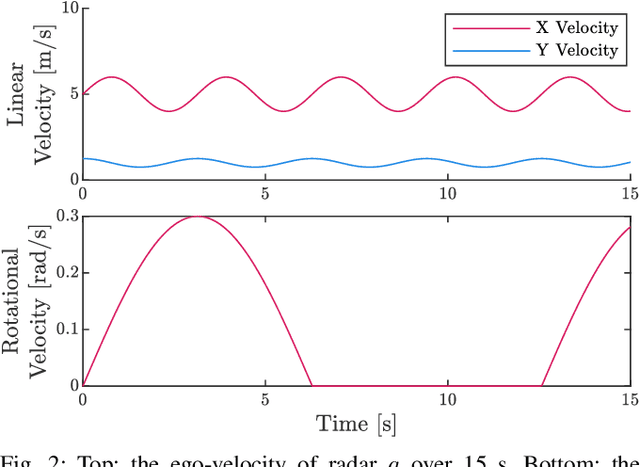
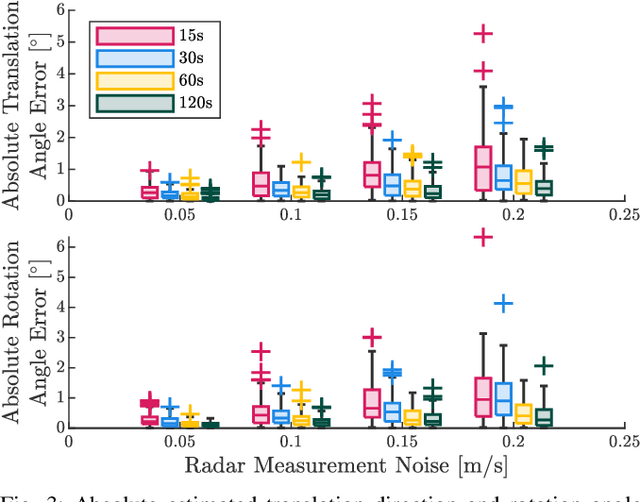
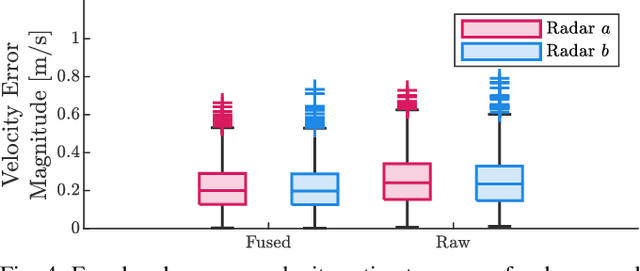
Correct radar data fusion depends on knowledge of the spatial transform between sensor pairs. Current methods for determining this transform operate by aligning identifiable features in different radar scans, or by relying on measurements from another, more accurate sensor (e.g., a lidar unit). Feature-based alignment requires the sensors to have overlapping fields of view or necessitates the construction of an environment map. Several existing methods require bespoke retroreflective radar targets. These requirements limit both where and how calibration can be performed. In this paper, we take a different approach: instead of attempting to track targets or features, which can be difficult in noisy radar data, we instead rely on ego-velocity estimates from each radar to perform calibration. Our method enables calibration of a subset of the transform parameters, including the yaw and axis of translation between the radar pair, without the need for a shared field of view or for specialized structures in the environment. In general, the yaw and axis of translation are the most important parameters for data fusion, the most likely to vary over time, and the most difficult to calibrate manually. We formulate calibration as a batch optimization problem, prove that the radar-radar system is identifiable, and specify the platform excitation requirements. Through simulations studies and real-world experiments, we establish that our method is more reliable and accurate at estimating the yaw and translation axis than state-of-the-art methods. Finally, we show that the full rigid-body transform can be recovered if relatively coarse information about the rotation rate is available.