 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
LDMIC: Learning-based Distributed Multi-view Image Coding
Jan 24, 2023
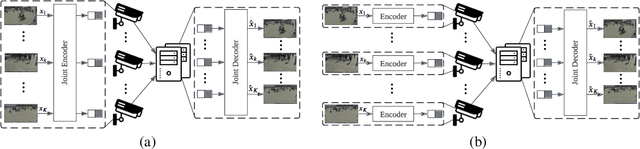
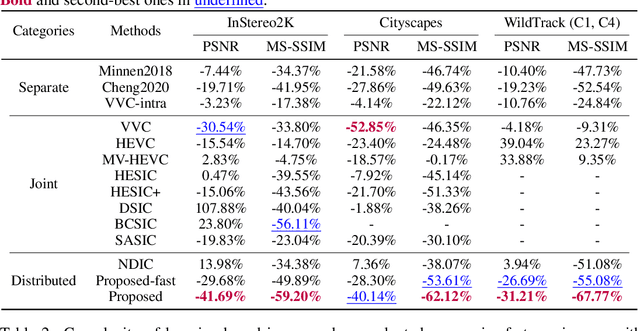
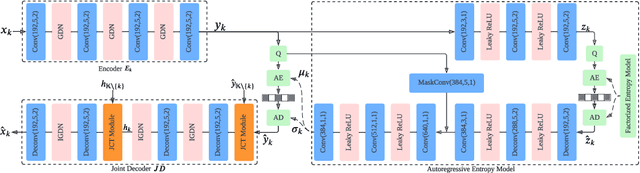
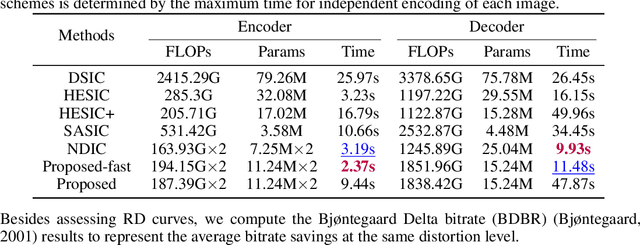
Multi-view image compression plays a critical role in 3D-related applications. Existing methods adopt a predictive coding architecture, which requires joint encoding to compress the corresponding disparity as well as residual information. This demands collaboration among cameras and enforces the epipolar geometric constraint between different views, which makes it challenging to deploy these methods in distributed camera systems with randomly overlapping fields of view. Meanwhile, distributed source coding theory indicates that efficient data compression of correlated sources can be achieved by independent encoding and joint decoding, which motivates us to design a learning-based distributed multi-view image coding (LDMIC) framework. With independent encoders, LDMIC introduces a simple yet effective joint context transfer module based on the cross-attention mechanism at the decoder to effectively capture the global inter-view correlations, which is insensitive to the geometric relationships between images. Experimental results show that LDMIC significantly outperforms both traditional and learning-based MIC methods while enjoying fast encoding speed. Code will be released at https://github.com/Xinjie-Q/LDMIC.
Interactive-Chain-Prompting: Ambiguity Resolution for Crosslingual Conditional Generation with Interaction
Jan 24, 2023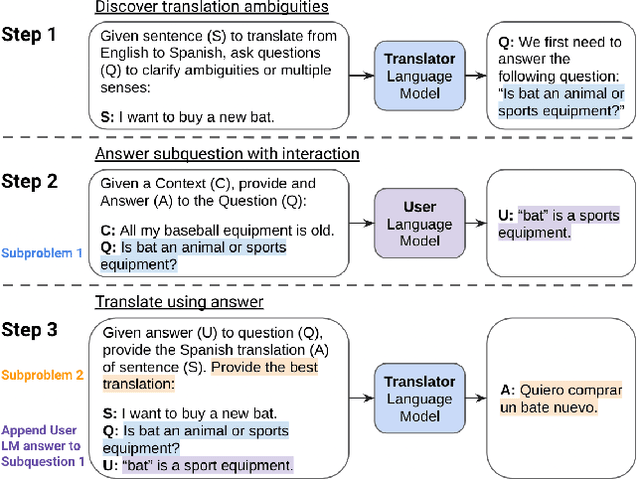
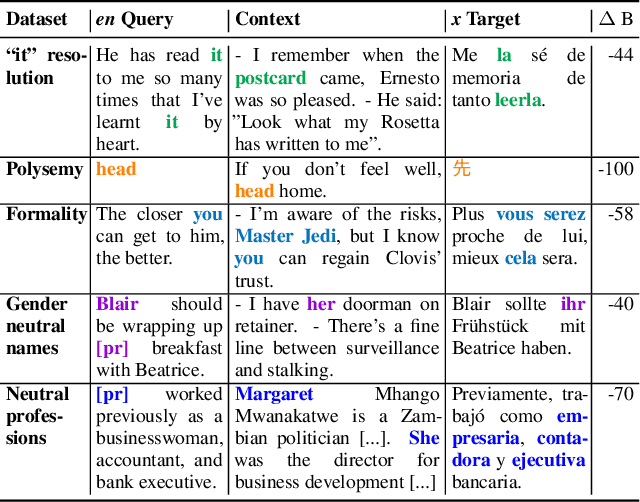
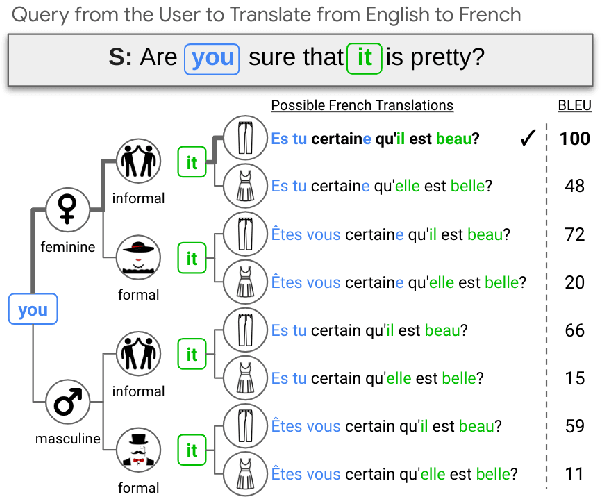
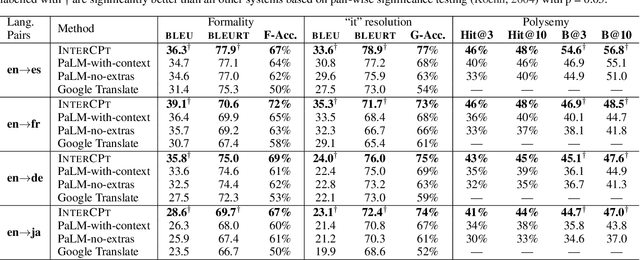
Crosslingual conditional generation (e.g., machine translation) has long enjoyed the benefits of scaling. Nonetheless, there are still issues that scale alone may not overcome. A source query in one language, for instance, may yield several translation options in another language without any extra context. Only one translation could be acceptable however, depending on the translator's preferences and goals. Choosing the incorrect option might significantly affect translation usefulness and quality. We propose a novel method interactive-chain prompting -- a series of question, answering and generation intermediate steps between a Translator model and a User model -- that reduces translations into a list of subproblems addressing ambiguities and then resolving such subproblems before producing the final text to be translated. To check ambiguity resolution capabilities and evaluate translation quality, we create a dataset exhibiting different linguistic phenomena which leads to ambiguities at inference for four languages. To encourage further exploration in this direction, we release all datasets. We note that interactive-chain prompting, using eight interactions as exemplars, consistently surpasses prompt-based methods with direct access to background information to resolve ambiguities.
Learned Interferometric Imaging for the SPIDER Instrument
Jan 24, 2023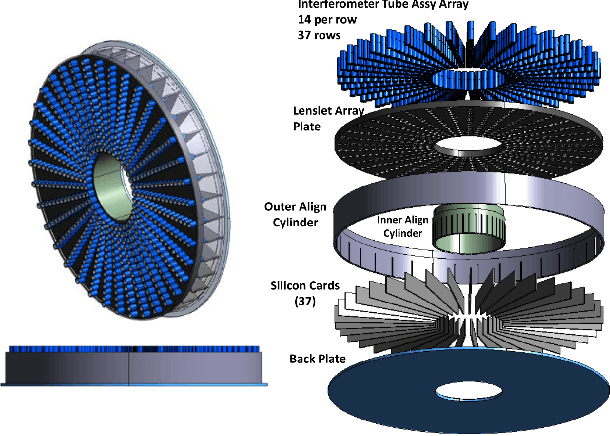

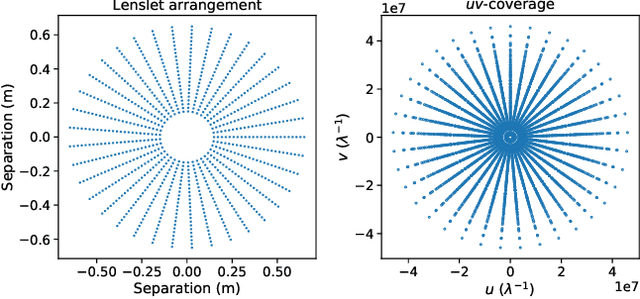
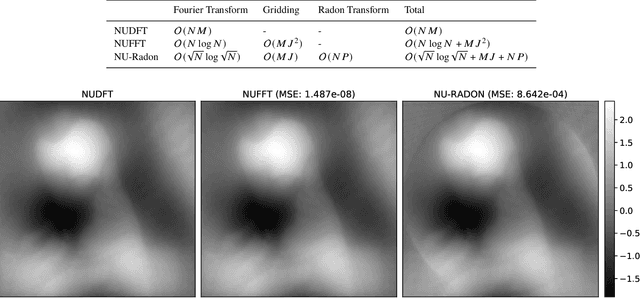
The Segmented Planar Imaging Detector for Electro-Optical Reconnaissance (SPIDER) is an optical interferometric imaging device that aims to offer an alternative to the large space telescope designs of today with reduced size, weight and power consumption. This is achieved through interferometric imaging. State-of-the-art methods for reconstructing images from interferometric measurements adopt proximal optimization techniques, which are computationally expensive and require handcrafted priors. In this work we present two data-driven approaches for reconstructing images from measurements made by the SPIDER instrument. These approaches use deep learning to learn prior information from training data, increasing the reconstruction quality, and significantly reducing the computation time required to recover images by orders of magnitude. Reconstruction time is reduced to ${\sim} 10$ milliseconds, opening up the possibility of real-time imaging with SPIDER for the first time. Furthermore, we show that these methods can also be applied in domains where training data is scarce, such as astronomical imaging, by leveraging transfer learning from domains where plenty of training data are available.
Large language models can segment narrative events similarly to humans
Jan 24, 2023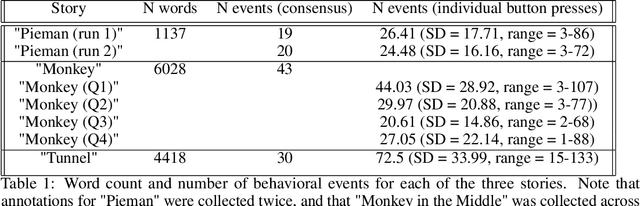
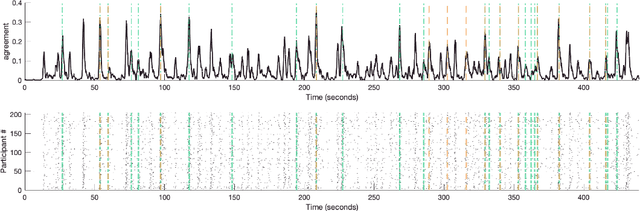
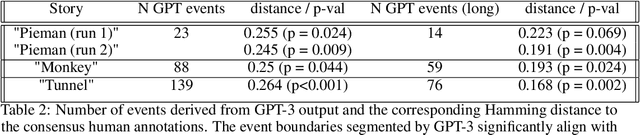

Humans perceive discrete events such as "restaurant visits" and "train rides" in their continuous experience. One important prerequisite for studying human event perception is the ability of researchers to quantify when one event ends and another begins. Typically, this information is derived by aggregating behavioral annotations from several observers. Here we present an alternative computational approach where event boundaries are derived using a large language model, GPT-3, instead of using human annotations. We demonstrate that GPT-3 can segment continuous narrative text into events. GPT-3-annotated events are significantly correlated with human event annotations. Furthermore, these GPT-derived annotations achieve a good approximation of the "consensus" solution (obtained by averaging across human annotations); the boundaries identified by GPT-3 are closer to the consensus, on average, than boundaries identified by individual human annotators. This finding suggests that GPT-3 provides a feasible solution for automated event annotations, and it demonstrates a further parallel between human cognition and prediction in large language models. In the future, GPT-3 may thereby help to elucidate the principles underlying human event perception.
Multi-Biometric Fuzzy Vault based on Face and Fingerprints
Jan 17, 2023
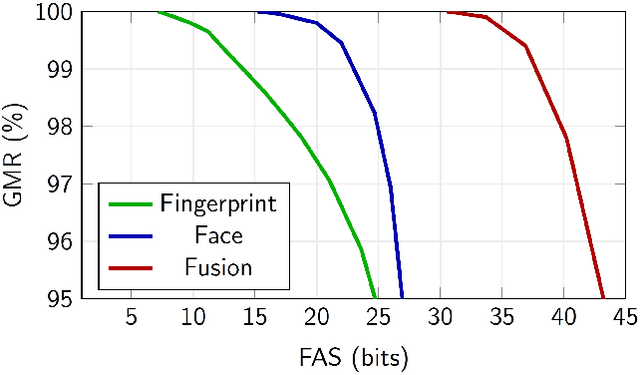

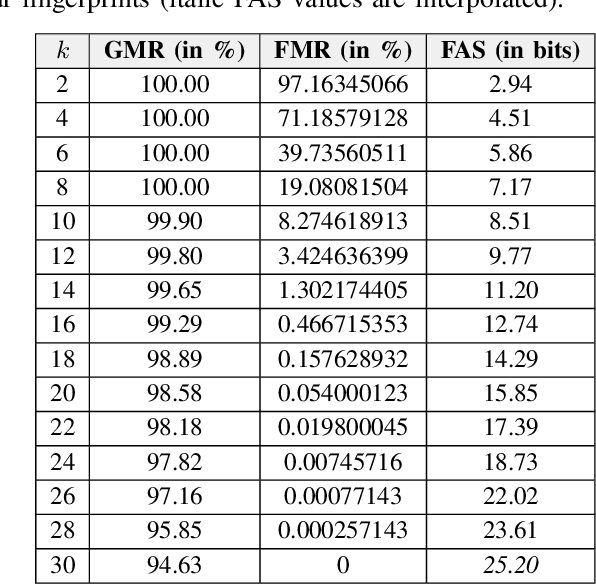
The fuzzy vault scheme has been established as cryptographic primitive suitable for privacy-preserving biometric authentication. To improve accuracy and privacy protection, biometric information of multiple characteristics can be fused at feature level prior to locking it in a fuzzy vault. We construct a multi-biometric fuzzy vault based on face and multiple fingerprints. On a multi-biometric database constructed from the FRGCv2 face and the MCYT-100 fingerprint databases, a perfect recognition accuracy is achieved at a false accept security above 30 bits. Further, we provide a formalisation of feature-level fusion in multi-biometric fuzzy vaults, on the basis of which relevant security issues are elaborated. Said security issues, for which we define countermeasures, are commonly ignored and may impair the overall system's security.
AgAsk: An Agent to Help Answer Farmer's Questions From Scientific Documents
Dec 21, 2022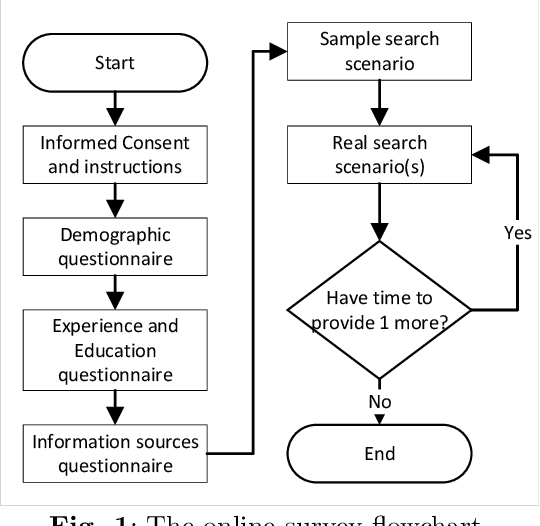

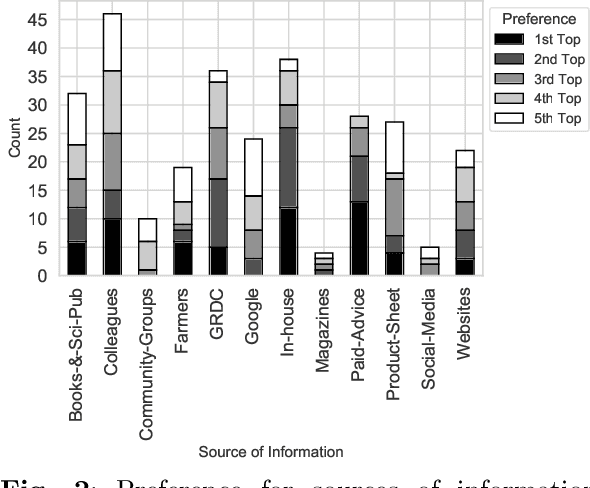
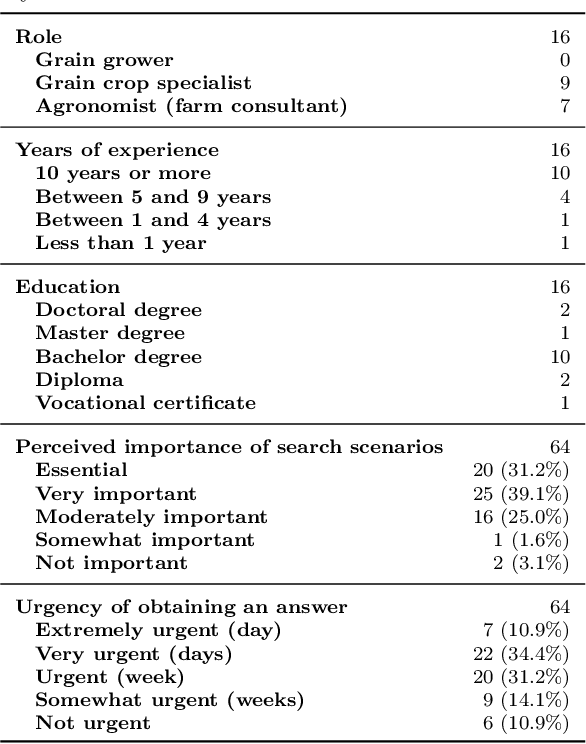
Decisions in agriculture are increasingly data-driven; however, valuable agricultural knowledge is often locked away in free-text reports, manuals and journal articles. Specialised search systems are needed that can mine agricultural information to provide relevant answers to users' questions. This paper presents AgAsk -- an agent able to answer natural language agriculture questions by mining scientific documents. We carefully survey and analyse farmers' information needs. On the basis of these needs we release an information retrieval test collection comprising real questions, a large collection of scientific documents split in passages, and ground truth relevance assessments indicating which passages are relevant to each question. We implement and evaluate a number of information retrieval models to answer farmers questions, including two state-of-the-art neural ranking models. We show that neural rankers are highly effective at matching passages to questions in this context. Finally, we propose a deployment architecture for AgAsk that includes a client based on the Telegram messaging platform and retrieval model deployed on commodity hardware. The test collection we provide is intended to stimulate more research in methods to match natural language to answers in scientific documents. While the retrieval models were evaluated in the agriculture domain, they are generalisable and of interest to others working on similar problems. The test collection is available at: \url{https://github.com/ielab/agvaluate}.
A Semi-supervised Approach for Activity Recognition from Indoor Trajectory Data
Jan 09, 2023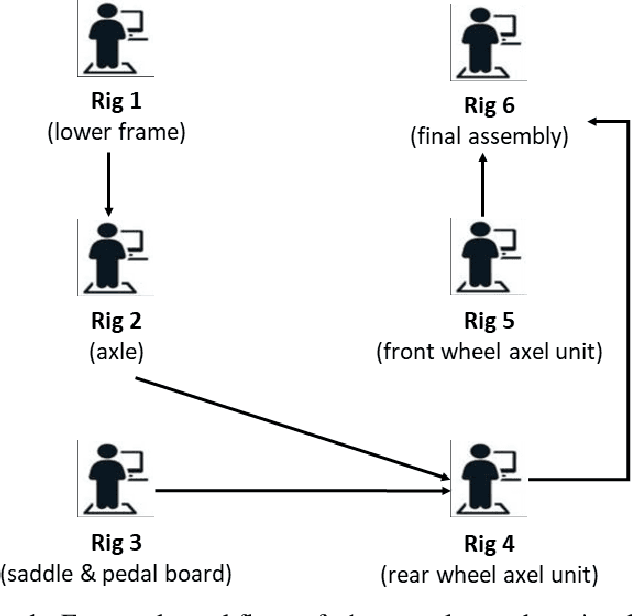
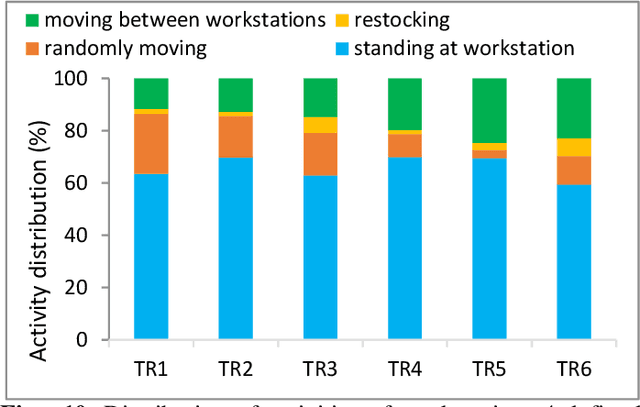
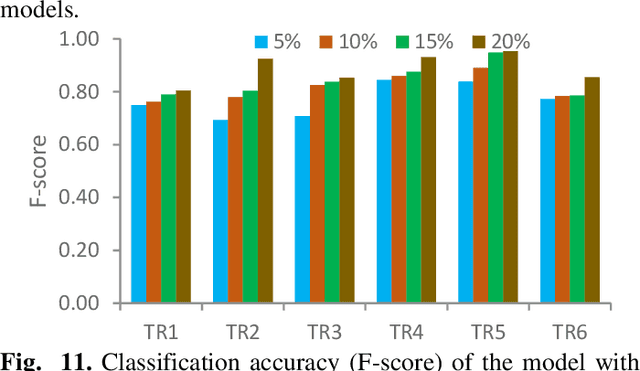
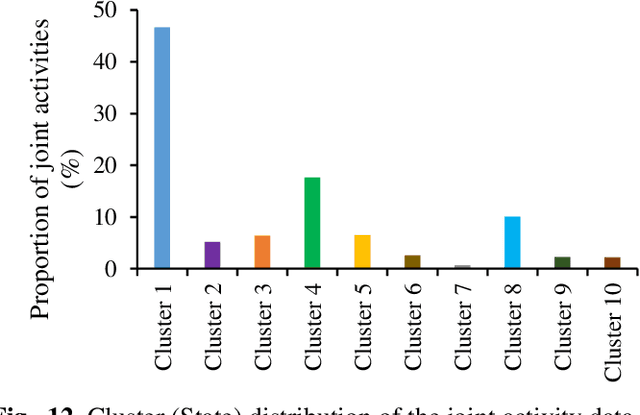
The increasingly wide usage of location aware sensors has made it possible to collect large volume of trajectory data in diverse application domains. Machine learning allows to study the activities or behaviours of moving objects (e.g., people, vehicles, robot) using such trajectory data with rich spatiotemporal information to facilitate informed strategic and operational decision making. In this study, we consider the task of classifying the activities of moving objects from their noisy indoor trajectory data in a collaborative manufacturing environment. Activity recognition can help manufacturing companies to develop appropriate management policies, and optimise safety, productivity, and efficiency. We present a semi-supervised machine learning approach that first applies an information theoretic criterion to partition a long trajectory into a set of segments such that the object exhibits homogeneous behaviour within each segment. The segments are then labelled automatically based on a constrained hierarchical clustering method. Finally, a deep learning classification model based on convolutional neural networks is trained on trajectory segments and the generated pseudo labels. The proposed approach has been evaluated on a dataset containing indoor trajectories of multiple workers collected from a tricycle assembly workshop. The proposed approach is shown to achieve high classification accuracy (F-score varies between 0.81 to 0.95 for different trajectories) using only a small proportion of labelled trajectory segments.
On the Coexistence of eMBB and URLLC in Multi-cell Massive MIMO
Jan 09, 2023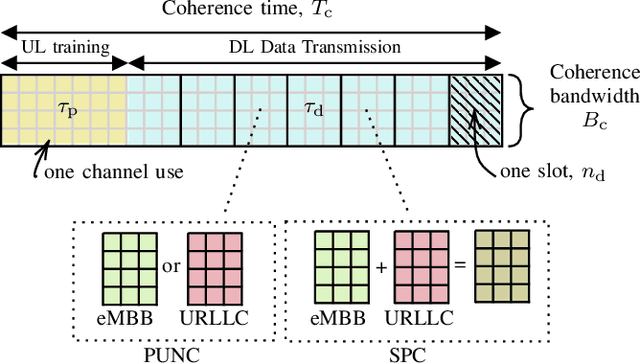
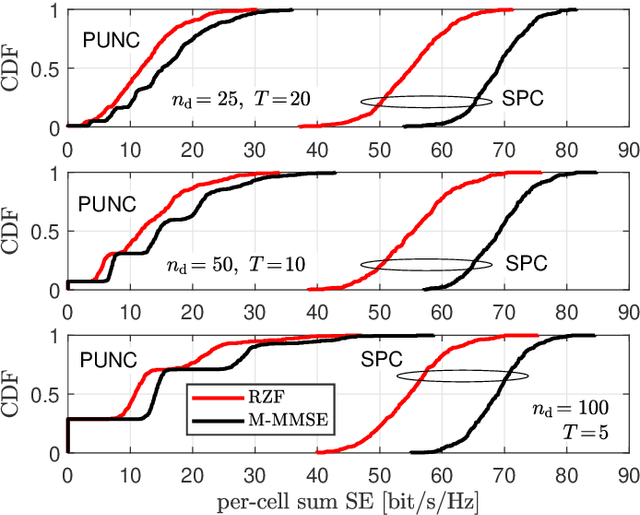
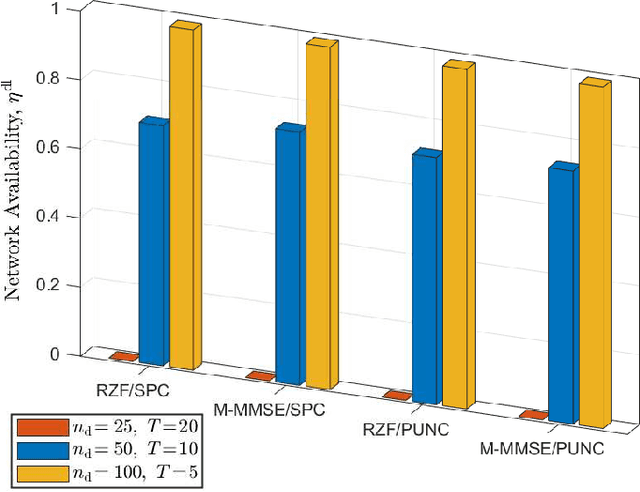
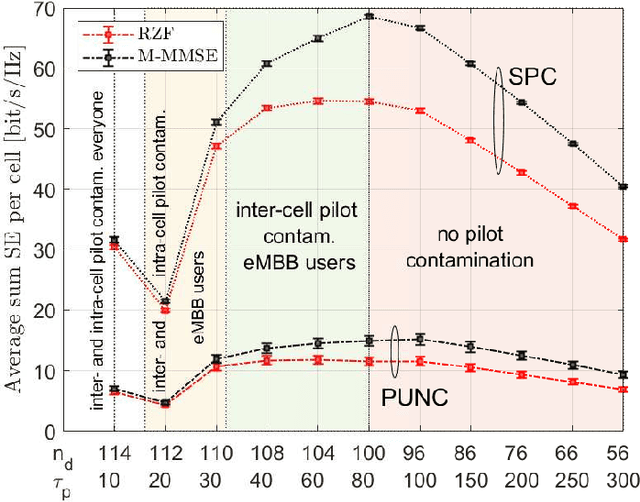
The non-orthogonal coexistence between the enhanced mobile broadband (eMBB) and the ultra-reliable low-latency communication (URLLC) in the downlink of a multi-cell massive MIMO system is rigorously analyzed in this work. We provide a unified information-theoretic framework blending an infinite-blocklength analysis of the eMBB spectral efficiency (SE) in the ergodic regime with a finite-blocklength analysis of the URLLC error probability relying on the use of mismatched decoding, and of the so-called saddlepoint approximation. Puncturing (PUNC) and superposition coding (SPC) are considered as alternative downlink coexistence strategies to deal with the inter-service interference, under the assumption of only statistical channel state information (CSI) knowledge at the users. eMBB and URLLC performances are then evaluated over different precoding techniques and power control schemes, by accounting for imperfect CSI knowledge at the base stations, pilot-based estimation overhead, pilot contamination, spatially correlated channels, the structure of the radio frame, and the characteristics of the URLLC activation pattern. Simulation results reveal that SPC is, in many operating regimes, superior to PUNC in providing higher SE for the eMBB yet achieving the target reliability for the URLLC with high probability. Moreover, PUNC might cause eMBB service outage in presence of high URLLC traffic loads. However, PUNC turns to be necessary to preserve the URLLC performance in scenarios where the multi-user interference cannot be satisfactorily alleviated.
Human-Machine Collaboration for Smart Decision Making: Current Trends and Future Opportunities
Jan 18, 2023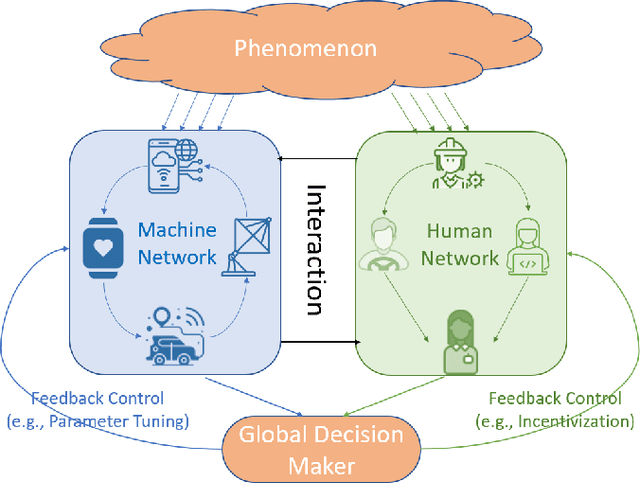
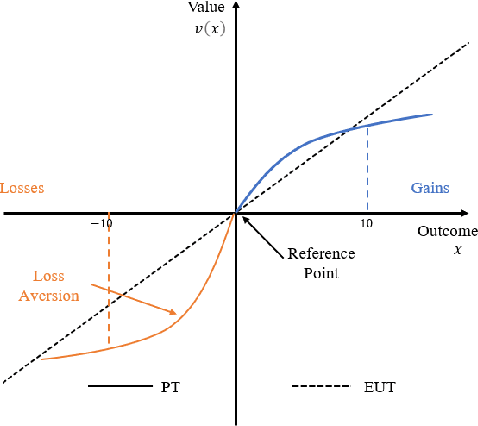
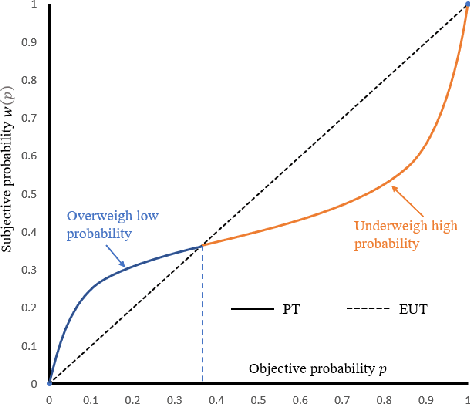
Recently, modeling of decision making and control systems that include heterogeneous smart sensing devices (machines) as well as human agents as participants is becoming an important research area due to the wide variety of applications including autonomous driving, smart manufacturing, internet of things, national security, and healthcare. To accomplish complex missions under uncertainty, it is imperative that we build novel human machine collaboration structures to integrate the cognitive strengths of humans with computational capabilities of machines in an intelligent manner. In this paper, we present an overview of the existing works on human decision making and human machine collaboration within the scope of signal processing and information fusion. We review several application areas and research domains relevant to human machine collaborative decision making. We also discuss current challenges and future directions in this problem domain.
Compression of GPS Trajectories using Autoencoders
Jan 18, 2023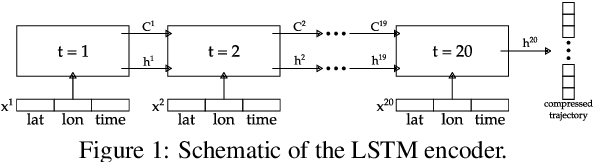
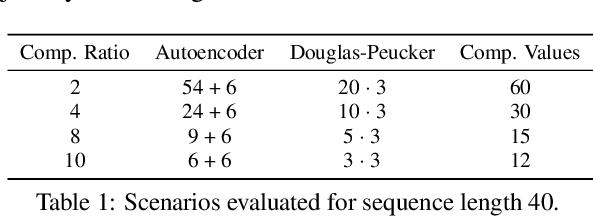
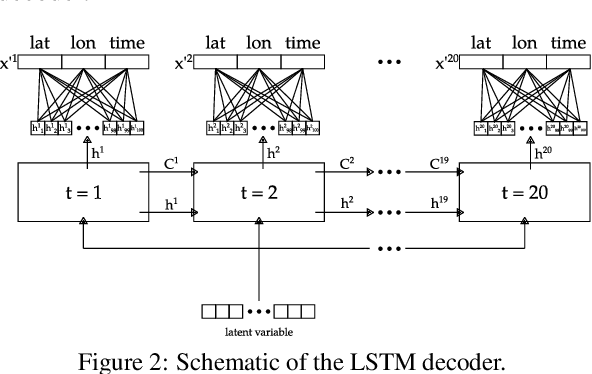
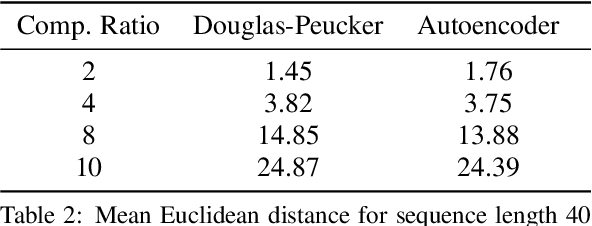
The ubiquitous availability of mobile devices capable of location tracking led to a significant rise in the collection of GPS data. Several compression methods have been developed in order to reduce the amount of storage needed while keeping the important information. In this paper, we present an lstm-autoencoder based approach in order to compress and reconstruct GPS trajectories, which is evaluated on both a gaming and real-world dataset. We consider various compression ratios and trajectory lengths. The performance is compared to other trajectory compression algorithms, i.e., Douglas-Peucker. Overall, the results indicate that our approach outperforms Douglas-Peucker significantly in terms of the discrete Fr\'echet distance and dynamic time warping. Furthermore, by reconstructing every point lossy, the proposed methodology offers multiple advantages over traditional methods.