 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Cohesive Distillation Architecture for Neural Language Models
Jan 12, 2023
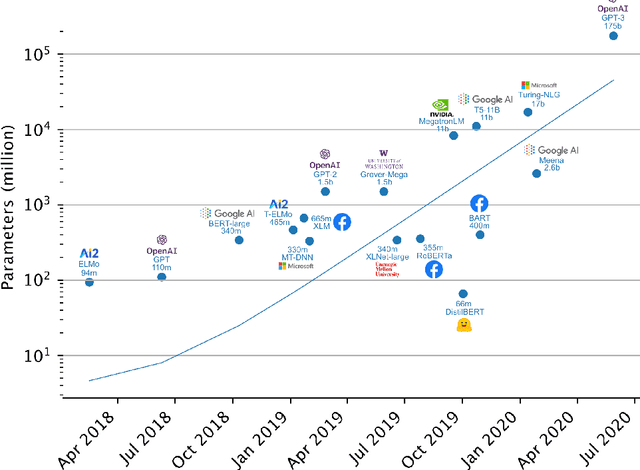
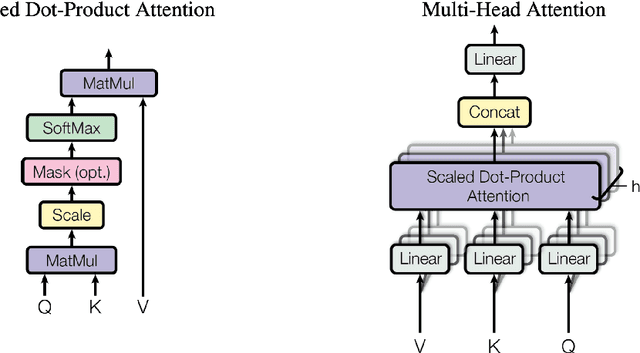
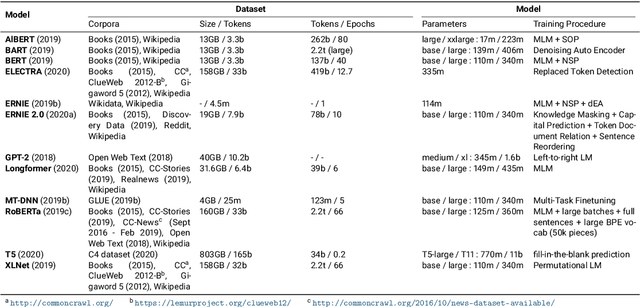
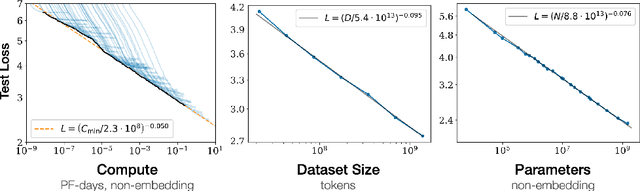
A recent trend in Natural Language Processing is the exponential growth in Language Model (LM) size, which prevents research groups without a necessary hardware infrastructure from participating in the development process. This study investigates methods for Knowledge Distillation (KD) to provide efficient alternatives to large-scale models. In this context, KD means extracting information about language encoded in a Neural Network and Lexical Knowledge Databases. We developed two methods to test our hypothesis that efficient architectures can gain knowledge from LMs and extract valuable information from lexical sources. First, we present a technique to learn confident probability distribution for Masked Language Modeling by prediction weighting of multiple teacher networks. Second, we propose a method for Word Sense Disambiguation (WSD) and lexical KD that is general enough to be adapted to many LMs. Our results show that KD with multiple teachers leads to improved training convergence. When using our lexical pre-training method, LM characteristics are not lost, leading to increased performance in Natural Language Understanding (NLU) tasks over the state-of-the-art while adding no parameters. Moreover, the improved semantic understanding of our model increased the task performance beyond WSD and NLU in a real-problem scenario (Plagiarism Detection). This study suggests that sophisticated training methods and network architectures can be superior over scaling trainable parameters. On this basis, we suggest the research area should encourage the development and use of efficient models and rate impacts resulting from growing LM size equally against task performance.
Professional Presentation and Projected Power: A Case Study of Implicit Gender Information in English CVs
Nov 17, 2022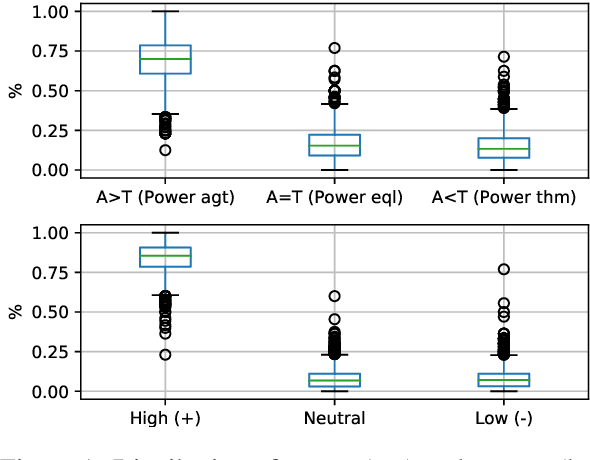
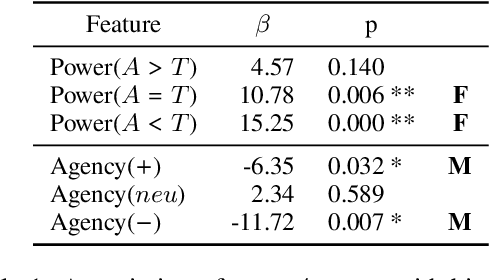
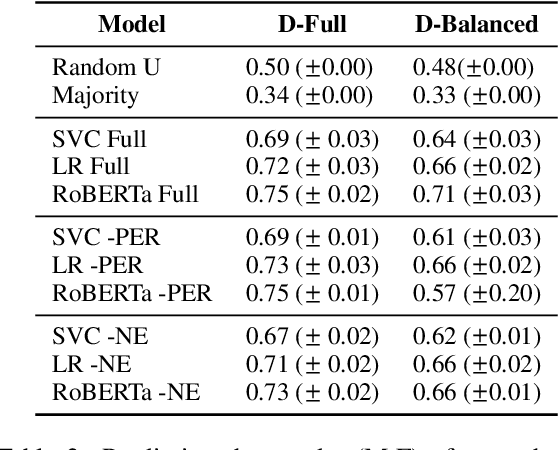
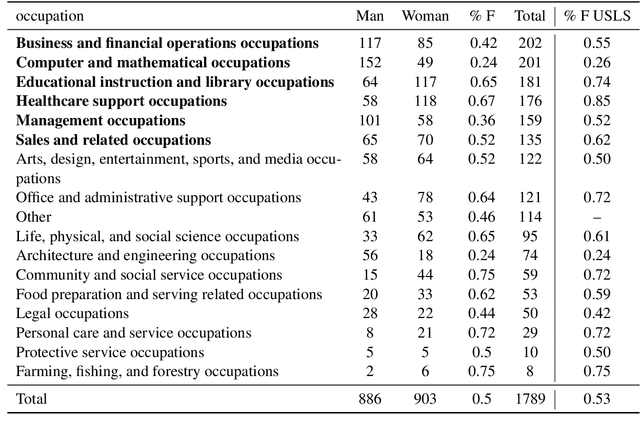
Gender discrimination in hiring is a pertinent and persistent bias in society, and a common motivating example for exploring bias in NLP. However, the manifestation of gendered language in application materials has received limited attention. This paper investigates the framing of skills and background in CVs of self-identified men and women. We introduce a data set of 1.8K authentic, English-language, CVs from the US, covering 16 occupations, allowing us to partially control for the confound occupation-specific gender base rates. We find that (1) women use more verbs evoking impressions of low power; and (2) classifiers capture gender signal even after data balancing and removal of pronouns and named entities, and this holds for both transformer-based and linear classifiers.
Improving Food Detection For Images From a Wearable Egocentric Camera
Jan 19, 2023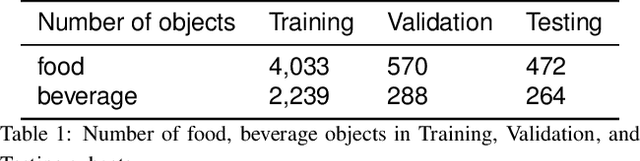
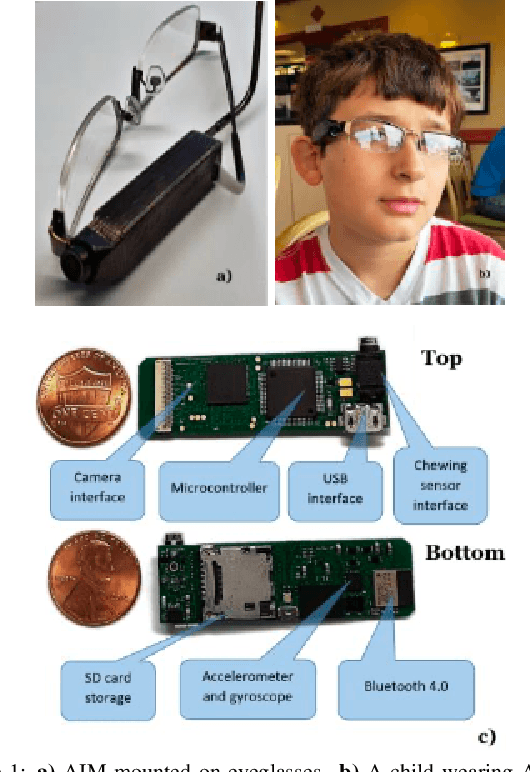

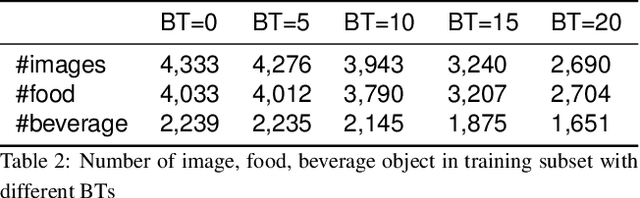
Diet is an important aspect of our health. Good dietary habits can contribute to the prevention of many diseases and improve the overall quality of life. To better understand the relationship between diet and health, image-based dietary assessment systems have been developed to collect dietary information. We introduce the Automatic Ingestion Monitor (AIM), a device that can be attached to one's eye glasses. It provides an automated hands-free approach to capture eating scene images. While AIM has several advantages, images captured by the AIM are sometimes blurry. Blurry images can significantly degrade the performance of food image analysis such as food detection. In this paper, we propose an approach to pre-process images collected by the AIM imaging sensor by rejecting extremely blurry images to improve the performance of food detection.
AnnoBERT: Effectively Representing Multiple Annotators' Label Choices to Improve Hate Speech Detection
Jan 10, 2023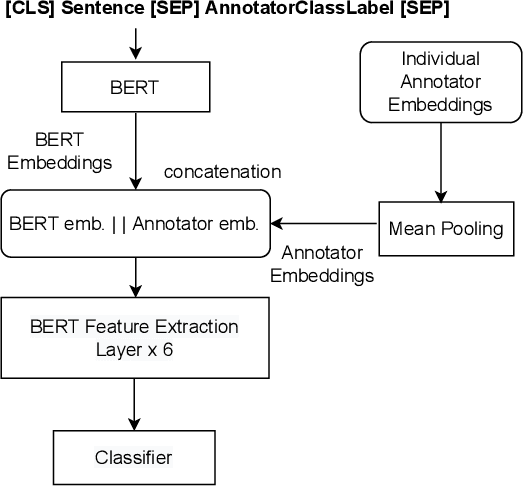

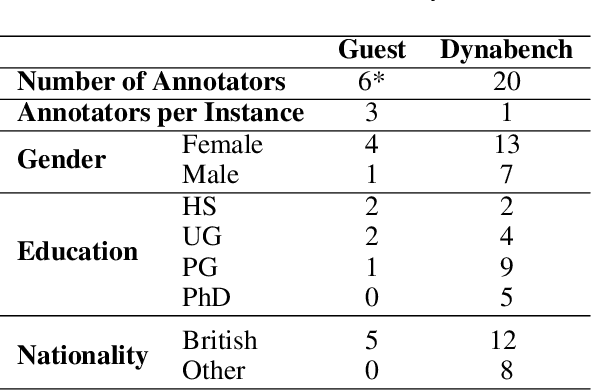
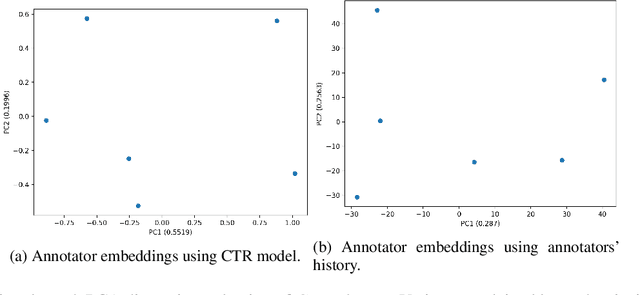
Supervised approaches generally rely on majority-based labels. However, it is hard to achieve high agreement among annotators in subjective tasks such as hate speech detection. Existing neural network models principally regard labels as categorical variables, while ignoring the semantic information in diverse label texts. In this paper, we propose AnnoBERT, a first-of-its-kind architecture integrating annotator characteristics and label text with a transformer-based model to detect hate speech, with unique representations based on each annotator's characteristics via Collaborative Topic Regression (CTR) and integrate label text to enrich textual representations. During training, the model associates annotators with their label choices given a piece of text; during evaluation, when label information is not available, the model predicts the aggregated label given by the participating annotators by utilising the learnt association. The proposed approach displayed an advantage in detecting hate speech, especially in the minority class and edge cases with annotator disagreement. Improvement in the overall performance is the largest when the dataset is more label-imbalanced, suggesting its practical value in identifying real-world hate speech, as the volume of hate speech in-the-wild is extremely small on social media, when compared with normal (non-hate) speech. Through ablation studies, we show the relative contributions of annotator embeddings and label text to the model performance, and tested a range of alternative annotator embeddings and label text combinations.
* accepted at ICWSM 2023
Deep-Learning Tool for Early Identifying Non-Traumatic Intracranial Hemorrhage Etiology based on CT Scan
Feb 02, 2023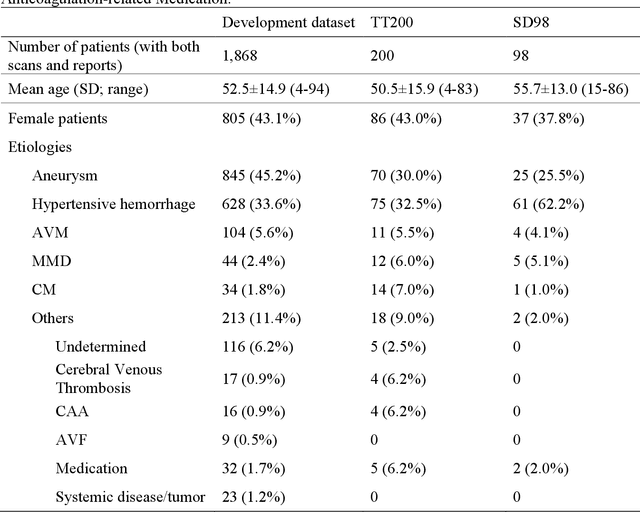
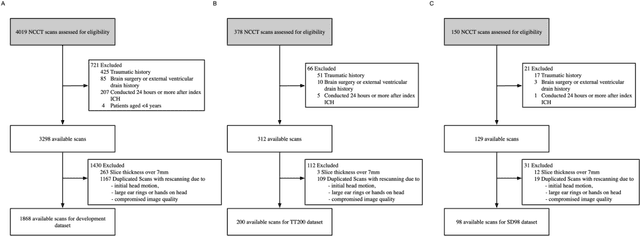
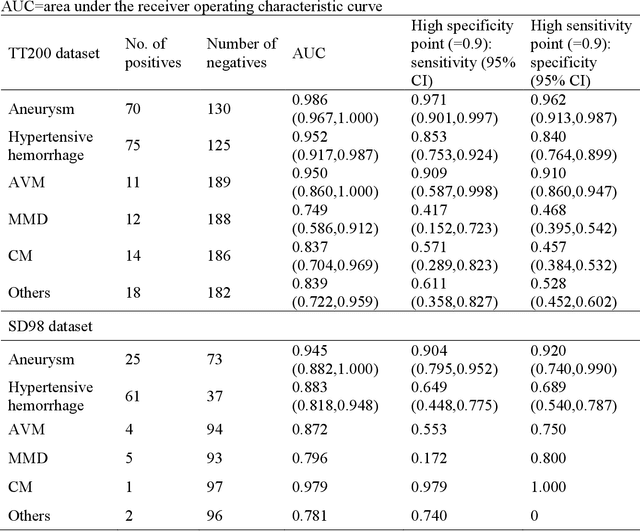
Background: To develop an artificial intelligence system that can accurately identify acute non-traumatic intracranial hemorrhage (ICH) etiology based on non-contrast CT (NCCT) scans and investigate whether clinicians can benefit from it in a diagnostic setting. Materials and Methods: The deep learning model was developed with 1868 eligible NCCT scans with non-traumatic ICH collected between January 2011 and April 2018. We tested the model on two independent datasets (TT200 and SD 98) collected after April 2018. The model's diagnostic performance was compared with clinicians's performance. We further designed a simulated study to compare the clinicians's performance with and without the deep learning system augmentation. Results: The proposed deep learning system achieved area under the receiver operating curve of 0.986 (95% CI 0.967-1.000) on aneurysms, 0.952 (0.917-0.987) on hypertensive hemorrhage, 0.950 (0.860-1.000) on arteriovenous malformation (AVM), 0.749 (0.586-0.912) on Moyamoya disease (MMD), 0.837 (0.704-0.969) on cavernous malformation (CM), and 0.839 (0.722-0.959) on other causes in TT200 dataset. Given a 90% specificity level, the sensitivities of our model were 97.1% and 90.9% for aneurysm and AVM diagnosis, respectively. The model also shows an impressive generalizability in an independent dataset SD98. The clinicians achieve significant improvements in the sensitivity, specificity, and accuracy of diagnoses of certain hemorrhage etiologies with proposed system augmentation. Conclusions: The proposed deep learning algorithms can be an effective tool for early identification of hemorrhage etiologies based on NCCT scans. It may also provide more information for clinicians for triage and further imaging examination selection.
BSSAD: Towards A Novel Bayesian State-Space Approach for Anomaly Detection in Multivariate Time Series
Jan 30, 2023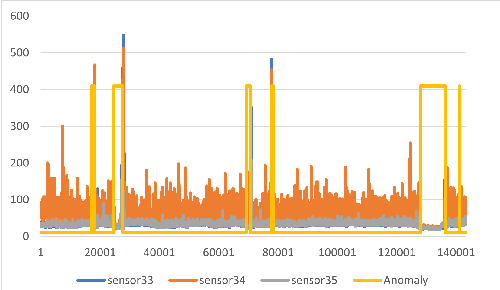
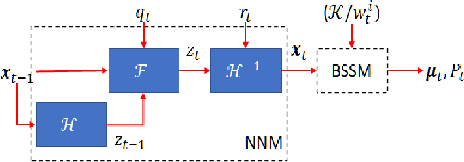
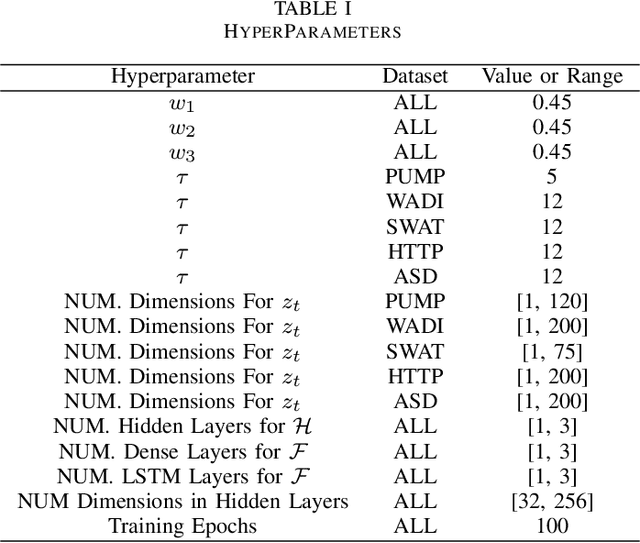
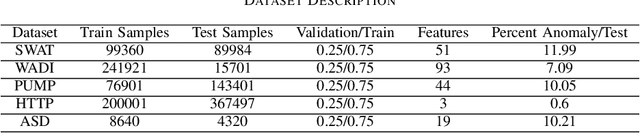
Detecting anomalies in multivariate time series(MTS) data plays an important role in many domains. The abnormal values could indicate events, medical abnormalities,cyber-attacks, or faulty devices which if left undetected could lead to significant loss of resources, capital, or human lives. In this paper, we propose a novel and innovative approach to anomaly detection called Bayesian State-Space Anomaly Detection(BSSAD). The BSSAD consists of two modules: the neural network module and the Bayesian state-space module. The design of our approach combines the strength of Bayesian state-space algorithms in predicting the next state and the effectiveness of recurrent neural networks and autoencoders in understanding the relationship between the data to achieve high accuracy in detecting anomalies. The modular design of our approach allows flexibility in implementation with the option of changing the parameters of the Bayesian state-space models or swap-ping neural network algorithms to achieve different levels of performance. In particular, we focus on using Bayesian state-space models of particle filters and ensemble Kalman filters. We conducted extensive experiments on five different datasets. The experimental results show the superior performance of our model over baselines, achieving an F1-score greater than 0.95. In addition, we also propose using a metric called MatthewCorrelation Coefficient (MCC) to obtain more comprehensive information about the accuracy of anomaly detection.
The Optimal Choice of Hypothesis Is the Weakest, Not the Shortest
Jan 30, 2023

If $A$ and $B$ are sets such that $A \subset B$, generalisation may be understood as the inference from $A$ of a hypothesis sufficient to construct $B$. One might infer any number of hypotheses from $A$, yet only some of those may generalise to $B$. How can one know which are likely to generalise? One strategy is to choose the shortest, equating the ability to compress information with the ability to generalise (a proxy for intelligence). We examine this in the context of a mathematical formalism of enactive cognition. We show that compression is neither necessary nor sufficient to maximise performance (measured in terms of the probability of a hypothesis generalising). We formulate a proxy unrelated to length or simplicity, called weakness. We show that if tasks are uniformly distributed, then there is no choice of proxy that performs at least as well as weakness maximisation in all tasks while performing strictly better in at least one. In other words, weakness is the pareto optimal choice of proxy. In experiments comparing maximum weakness and minimum description length in the context of binary arithmetic, the former generalised at between $1.1$ and $5$ times the rate of the latter. We argue this demonstrates that weakness is a far better proxy, and explains why Deepmind's Apperception Engine is able to generalise effectively.
MAKE: Product Retrieval with Vision-Language Pre-training in Taobao Search
Jan 30, 2023
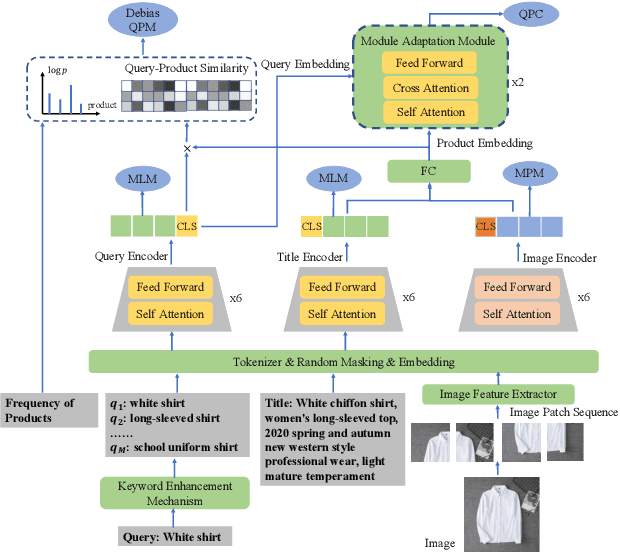
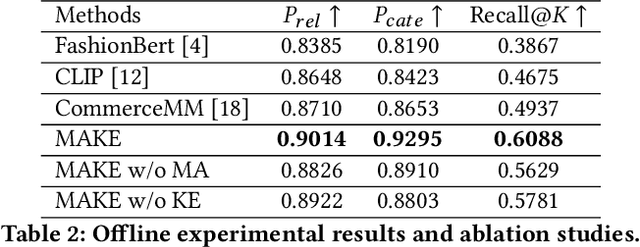
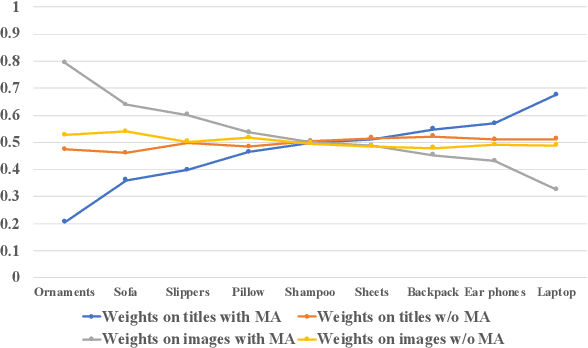
Taobao Search consists of two phases: the retrieval phase and the ranking phase. Given a user query, the retrieval phase returns a subset of candidate products for the following ranking phase. Recently, the paradigm of pre-training and fine-tuning has shown its potential in incorporating visual clues into retrieval tasks. In this paper, we focus on solving the problem of text-to-multimodal retrieval in Taobao Search. We consider that users' attention on titles or images varies on products. Hence, we propose a novel Modal Adaptation module for cross-modal fusion, which helps assigns appropriate weights on texts and images across products. Furthermore, in e-commerce search, user queries tend to be brief and thus lead to significant semantic imbalance between user queries and product titles. Therefore, we design a separate text encoder and a Keyword Enhancement mechanism to enrich the query representations and improve text-to-multimodal matching. To this end, we present a novel vision-language (V+L) pre-training methods to exploit the multimodal information of (user query, product title, product image). Extensive experiments demonstrate that our retrieval-specific pre-training model (referred to as MAKE) outperforms existing V+L pre-training methods on the text-to-multimodal retrieval task. MAKE has been deployed online and brings major improvements on the retrieval system of Taobao Search.
Probabilistic Neural Data Fusion for Learning from an Arbitrary Number of Multi-fidelity Data Sets
Jan 30, 2023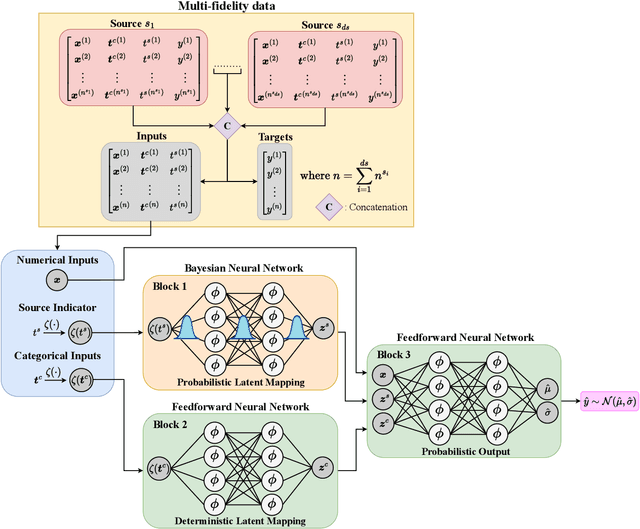
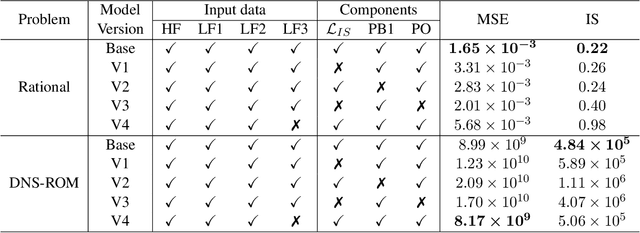
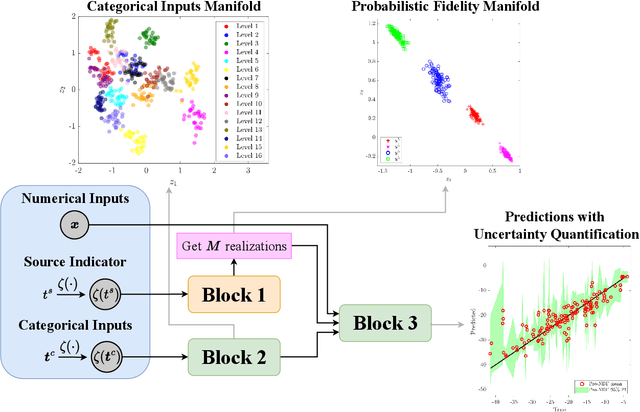
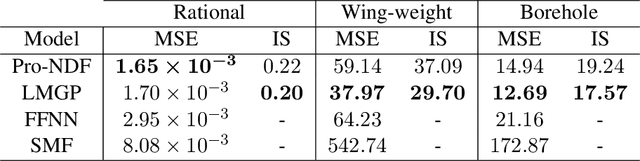
In many applications in engineering and sciences analysts have simultaneous access to multiple data sources. In such cases, the overall cost of acquiring information can be reduced via data fusion or multi-fidelity (MF) modeling where one leverages inexpensive low-fidelity (LF) sources to reduce the reliance on expensive high-fidelity (HF) data. In this paper, we employ neural networks (NNs) for data fusion in scenarios where data is very scarce and obtained from an arbitrary number of sources with varying levels of fidelity and cost. We introduce a unique NN architecture that converts MF modeling into a nonlinear manifold learning problem. Our NN architecture inversely learns non-trivial (e.g., non-additive and non-hierarchical) biases of the LF sources in an interpretable and visualizable manifold where each data source is encoded via a low-dimensional distribution. This probabilistic manifold quantifies model form uncertainties such that LF sources with small bias are encoded close to the HF source. Additionally, we endow the output of our NN with a parametric distribution not only to quantify aleatoric uncertainties, but also to reformulate the network's loss function based on strictly proper scoring rules which improve robustness and accuracy on unseen HF data. Through a set of analytic and engineering examples, we demonstrate that our approach provides a high predictive power while quantifying various sources uncertainties.
Semantic Enhanced Knowledge Graph for Large-Scale Zero-Shot Learning
Dec 26, 2022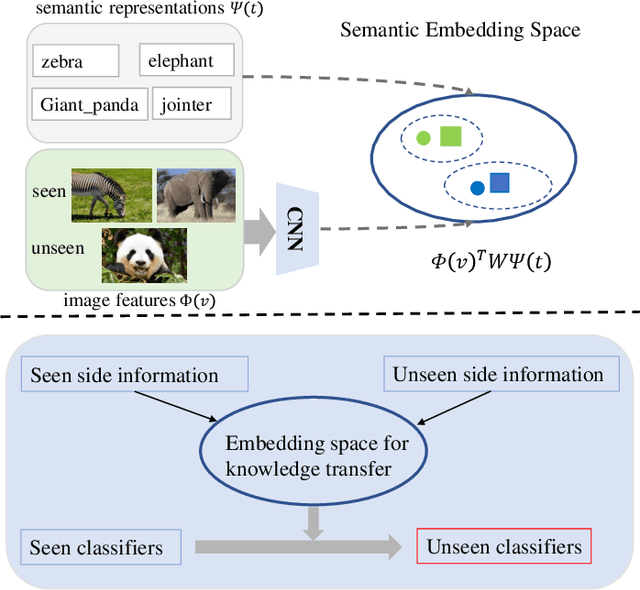
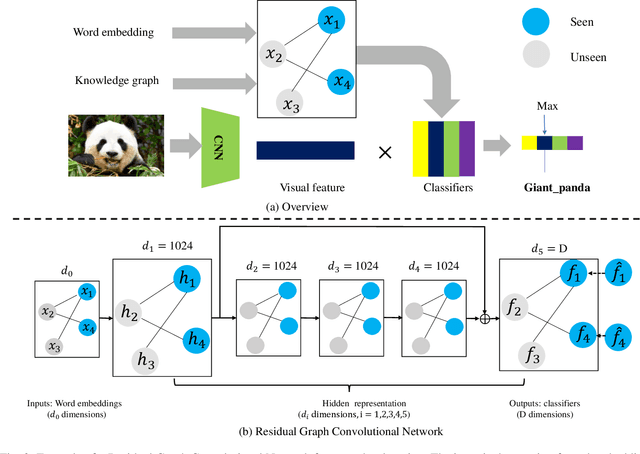
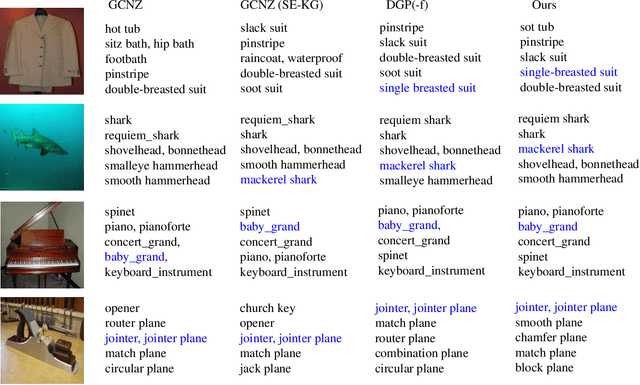
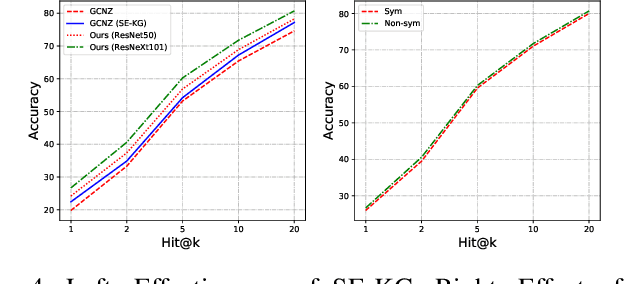
Zero-Shot Learning has been a highlighted research topic in both vision and language areas. Recently, most existing methods adopt structured knowledge information to model explicit correlations among categories and use deep graph convolutional network to propagate information between different categories. However, it is difficult to add new categories to existing structured knowledge graph, and deep graph convolutional network suffers from over-smoothing problem. In this paper, we provide a new semantic enhanced knowledge graph that contains both expert knowledge and categories semantic correlation. Our semantic enhanced knowledge graph can further enhance the correlations among categories and make it easy to absorb new categories. To propagate information on the knowledge graph, we propose a novel Residual Graph Convolutional Network (ResGCN), which can effectively alleviate the problem of over-smoothing. Experiments conducted on the widely used large-scale ImageNet-21K dataset and AWA2 dataset show the effectiveness of our method, and establish a new state-of-the-art on zero-shot learning. Moreover, our results on the large-scale ImageNet-21K with various feature extraction networks show that our method has better generalization and robustness.