 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Using meaning instead of words to track topics
Jan 02, 2023
The ability to monitor the evolution of topics over time is extremely valuable for businesses. Currently, all existing topic tracking methods use lexical information by matching word usage. However, no studies has ever experimented with the use of semantic information for tracking topics. Hence, we explore a novel semantic-based method using word embeddings. Our results show that a semantic-based approach to topic tracking is on par with the lexical approach but makes different mistakes. This suggest that both methods may complement each other.
Semantic Image Segmentation: Two Decades of Research
Feb 13, 2023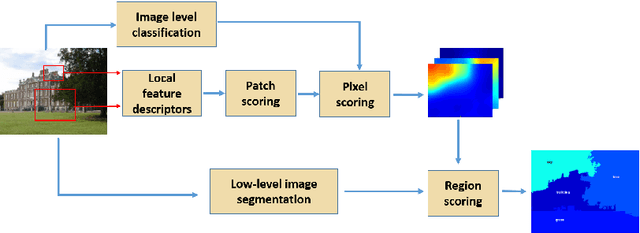
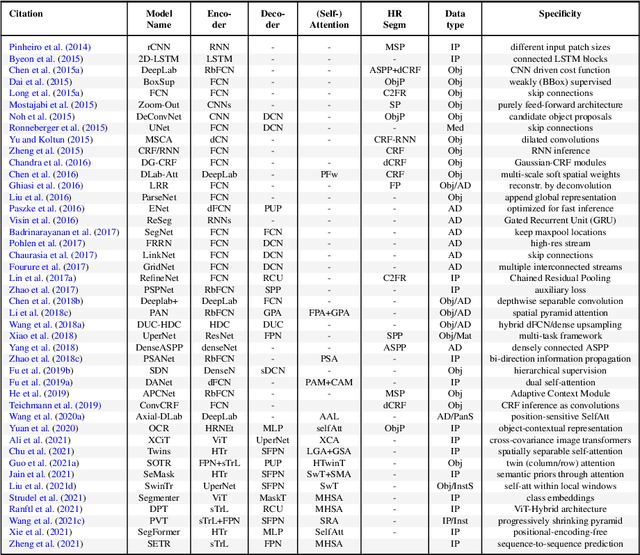
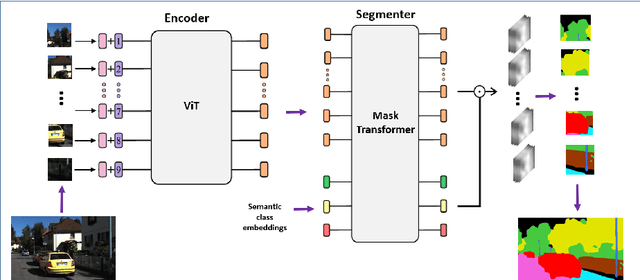

Semantic image segmentation (SiS) plays a fundamental role in a broad variety of computer vision applications, providing key information for the global understanding of an image. This survey is an effort to summarize two decades of research in the field of SiS, where we propose a literature review of solutions starting from early historical methods followed by an overview of more recent deep learning methods including the latest trend of using transformers. We complement the review by discussing particular cases of the weak supervision and side machine learning techniques that can be used to improve the semantic segmentation such as curriculum, incremental or self-supervised learning. State-of-the-art SiS models rely on a large amount of annotated samples, which are more expensive to obtain than labels for tasks such as image classification. Since unlabeled data is instead significantly cheaper to obtain, it is not surprising that Unsupervised Domain Adaptation (UDA) reached a broad success within the semantic segmentation community. Therefore, a second core contribution of this book is to summarize five years of a rapidly growing field, Domain Adaptation for Semantic Image Segmentation (DASiS) which embraces the importance of semantic segmentation itself and a critical need of adapting segmentation models to new environments. In addition to providing a comprehensive survey on DASiS techniques, we unveil also newer trends such as multi-domain learning, domain generalization, domain incremental learning, test-time adaptation and source-free domain adaptation. Finally, we conclude this survey by describing datasets and benchmarks most widely used in SiS and DASiS and briefly discuss related tasks such as instance and panoptic image segmentation, as well as applications such as medical image segmentation.
Explainable artificial intelligence toward usable and trustworthy computer-aided early diagnosis of multiple sclerosis from Optical Coherence Tomography
Feb 13, 2023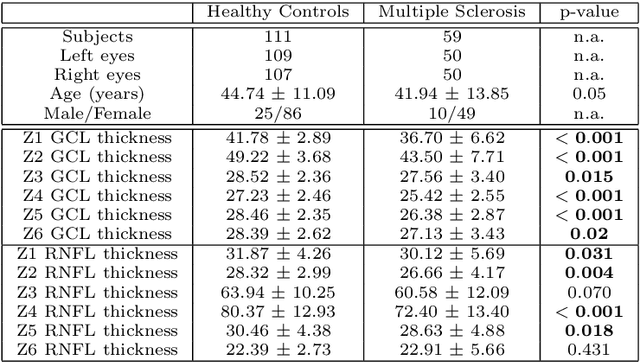
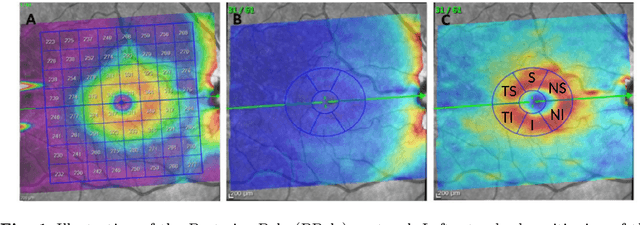
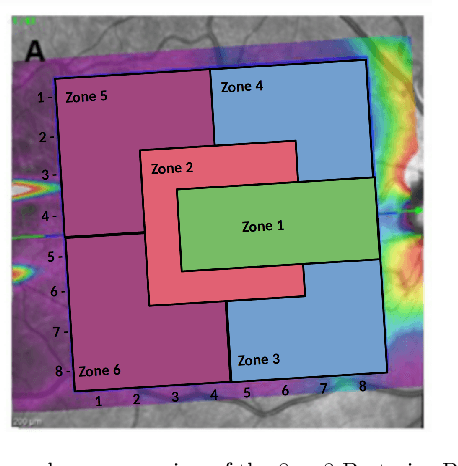
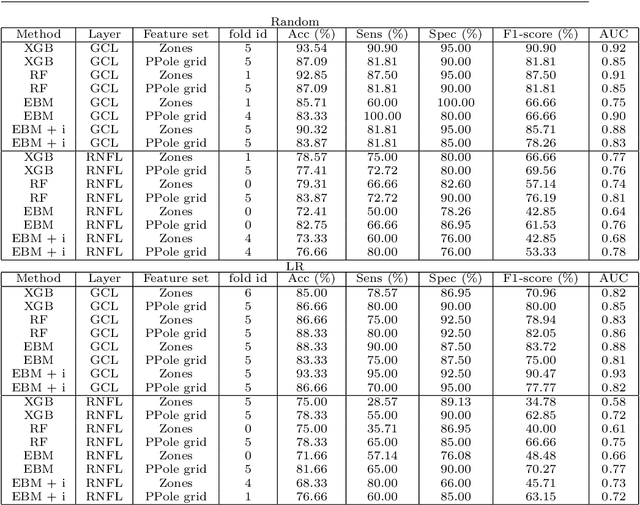
Background: Several studies indicate that the anterior visual pathway provides information about the dynamics of axonal degeneration in Multiple Sclerosis (MS). Current research in the field is focused on the quest for the most discriminative features among patients and controls and the development of machine learning models that yield computer-aided solutions widely usable in clinical practice. However, most studies are conducted with small samples and the models are used as black boxes. Clinicians should not trust machine learning decisions unless they come with comprehensive and easily understandable explanations. Materials and methods: A total of 216 eyes from 111 healthy controls and 100 eyes from 59 patients with relapsing-remitting MS were enrolled. The feature set was obtained from the thickness of the ganglion cell layer (GCL) and the retinal nerve fiber layer (RNFL). Measurements were acquired by the novel Posterior Pole protocol from Spectralis Optical Coherence Tomography (OCT) device. We compared two black-box methods (gradient boosting and random forests) with a glass-box method (explainable boosting machine). Explainability was studied using SHAP for the black-box methods and the scores of the glass-box method. Results: The best-performing models were obtained for the GCL layer. Explainability pointed out to the temporal location of the GCL layer that is usually broken or thinning in MS and the relationship between low thickness values and high probability of MS, which is coherent with clinical knowledge. Conclusions: The insights on how to use explainability shown in this work represent a first important step toward a trustworthy computer-aided solution for the diagnosis of MS with OCT.
Context Query Simulation for Smart Carparking Scenarios in the Melbourne CDB
Feb 13, 2023
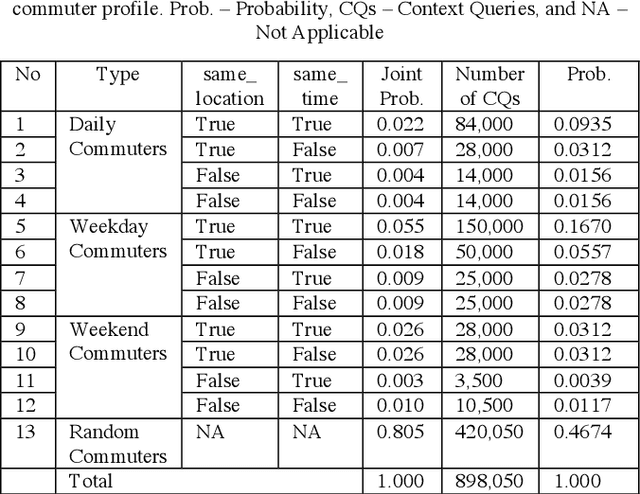
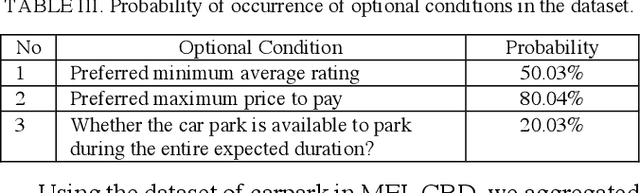

The rapid growth in Internet of Things (IoT) has ushered in the way for better context-awareness enabling more smarter applications. Although for the growth in the number of IoT devices, Context Management Platforms (CMPs) that integrate different domains of IoT to produce context information lacks scalability to cater to a high volume of context queries. Research in scalability and adaptation in CMPs are of significant importance due to this reason. However, there is limited methods to benchmarks and validate research in this area due to the lack of sizable sets of context queries that could simulate real-world situations, scenarios, and scenes. Commercially collected context query logs are not publicly accessible and deploying IoT devices, and context consumers in the real-world at scale is expensive and consumes a significant effort and time. Therefore, there is a need to develop a method to reliably generate and simulate context query loads that resembles real-world scenarios to test CMPs for scale. In this paper, we propose a context query simulator for the context-aware smart car parking scenario in Melbourne Central Business District in Australia. We present the process of generating context queries using multiple real-world datasets and publicly accessible reports, followed by the context query execution process. The context query generator matches the popularity of places with the different profiles of commuters, preferences, and traffic variations to produce a dataset of context query templates containing 898,050 records. The simulator is executable over a seven-day profile which far exceeds the simulation time of any IoT system simulator. The context query generation process is also generic and context query language independent.
Event-based Backpropagation for Analog Neuromorphic Hardware
Feb 13, 2023

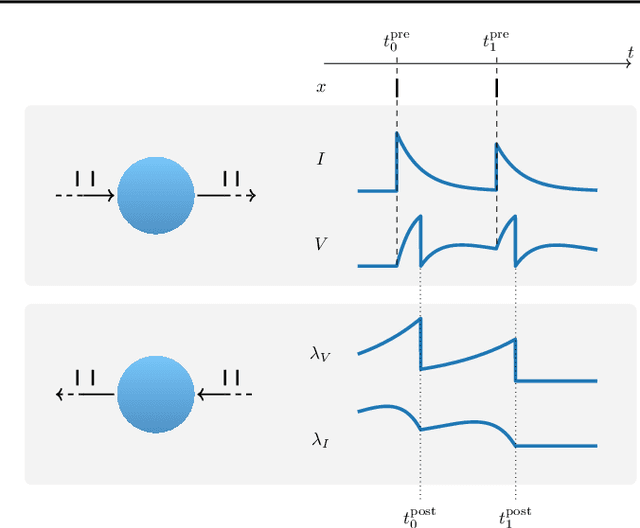
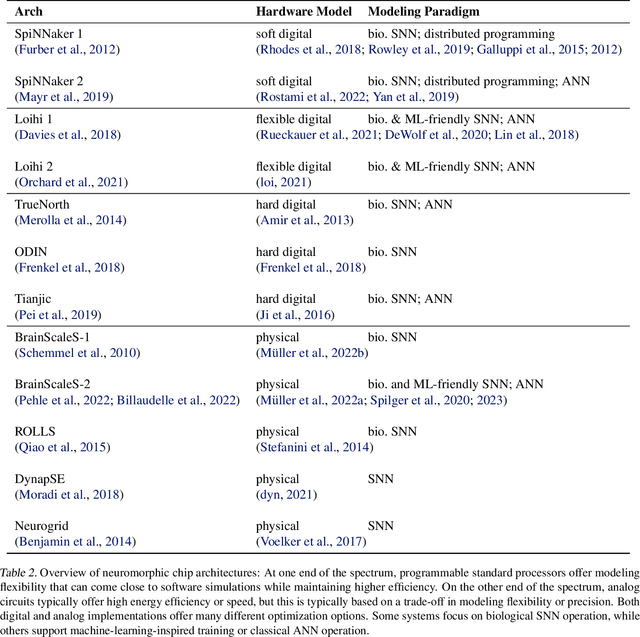
Neuromorphic computing aims to incorporate lessons from studying biological nervous systems in the design of computer architectures. While existing approaches have successfully implemented aspects of those computational principles, such as sparse spike-based computation, event-based scalable learning has remained an elusive goal in large-scale systems. However, only then the potential energy-efficiency advantages of neuromorphic systems relative to other hardware architectures can be realized during learning. We present our progress implementing the EventProp algorithm using the example of the BrainScaleS-2 analog neuromorphic hardware. Previous gradient-based approaches to learning used "surrogate gradients" and dense sampling of observables or were limited by assumptions on the underlying dynamics and loss functions. In contrast, our approach only needs spike time observations from the system while being able to incorporate other system observables, such as membrane voltage measurements, in a principled way. This leads to a one-order-of-magnitude improvement in the information efficiency of the gradient estimate, which would directly translate to corresponding energy efficiency improvements in an optimized hardware implementation. We present the theoretical framework for estimating gradients and results verifying the correctness of the estimation, as well as results on a low-dimensional classification task using the BrainScaleS-2 system. Building on this work has the potential to enable scalable gradient estimation in large-scale neuromorphic hardware as a continuous measurement of the system state would be prohibitive and energy-inefficient in such instances. It also suggests the feasibility of a full on-device implementation of the algorithm that would enable scalable, energy-efficient, event-based learning in large-scale analog neuromorphic hardware.
Improved Regret for Efficient Online Reinforcement Learning with Linear Function Approximation
Jan 30, 2023We study reinforcement learning with linear function approximation and adversarially changing cost functions, a setup that has mostly been considered under simplifying assumptions such as full information feedback or exploratory conditions.We present a computationally efficient policy optimization algorithm for the challenging general setting of unknown dynamics and bandit feedback, featuring a combination of mirror-descent and least squares policy evaluation in an auxiliary MDP used to compute exploration bonuses.Our algorithm obtains an $\widetilde O(K^{6/7})$ regret bound, improving significantly over previous state-of-the-art of $\widetilde O (K^{14/15})$ in this setting. In addition, we present a version of the same algorithm under the assumption a simulator of the environment is available to the learner (but otherwise no exploratory assumptions are made), and prove it obtains state-of-the-art regret of $\widetilde O (K^{2/3})$.
Robust Precoding via Characteristic Functions for VSAT to Multi-Satellite Uplink Transmission
Jan 30, 2023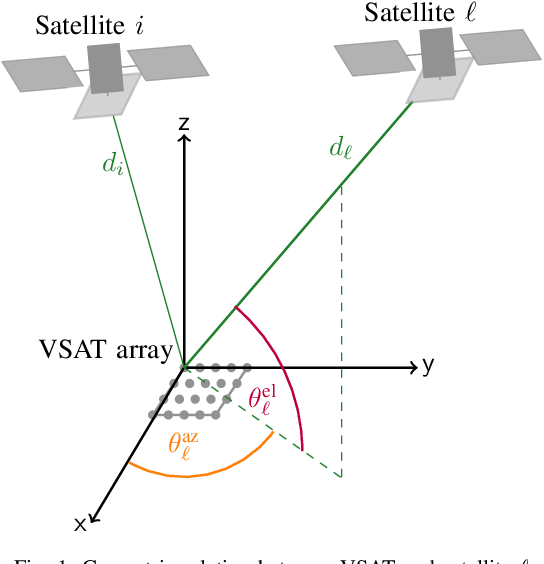
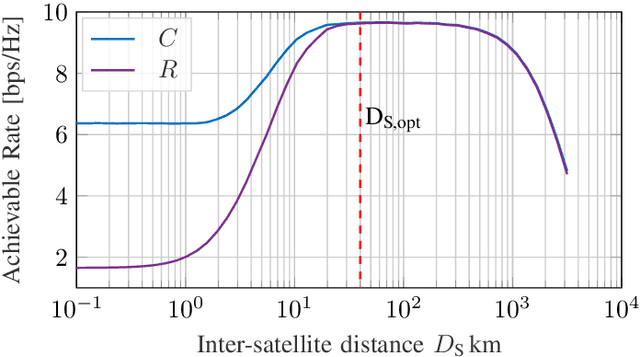
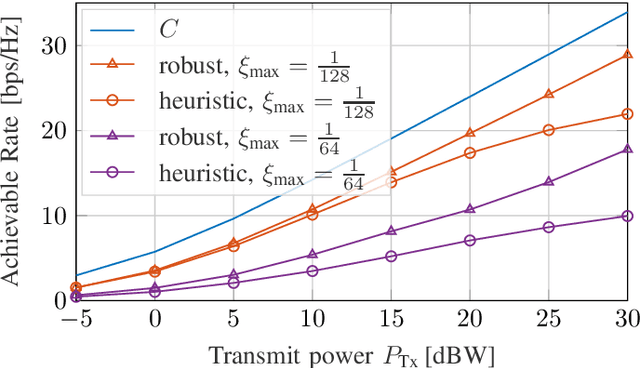
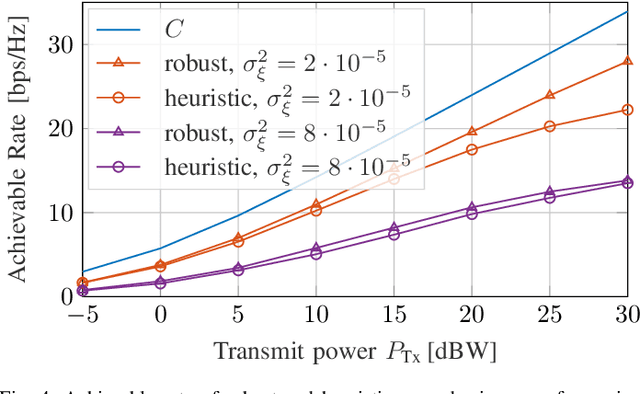
The uplink from a very small aperture terminal (VSAT) towards multiple satellites is considered, in this paper. VSATs can be equipped with multiple antennas, allowing parallel transmission to multiple satellites. A low-complexity precoder based on imperfect positional information of the satellites is presented. The probability distribution of the position uncertainty and the statistics of the channel elements are related by the characteristic function of the position uncertainty. This knowledge is included in the precoder design to maximize the mean signal-to-leakage-and-noise ratio (SLNR) at the satellites. Furthermore, the performance w.r.t. the inter-satellite distance is numerically evaluated. It is shown that the proposed approach achieves the capacity for perfect position knowledge and sufficiently large inter-satellite distances. In case of imperfect position knowledge, the performance degradation of the robust precoder is relatively small.
MMA-RNN: A Multi-level Multi-task Attention-based Recurrent Neural Network for Discrimination and Localization of Atrial Fibrillation
Feb 07, 2023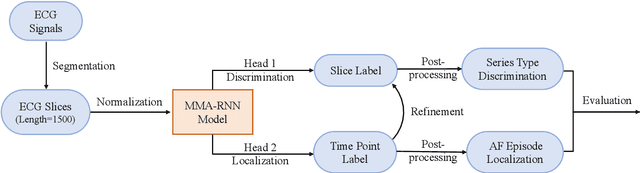

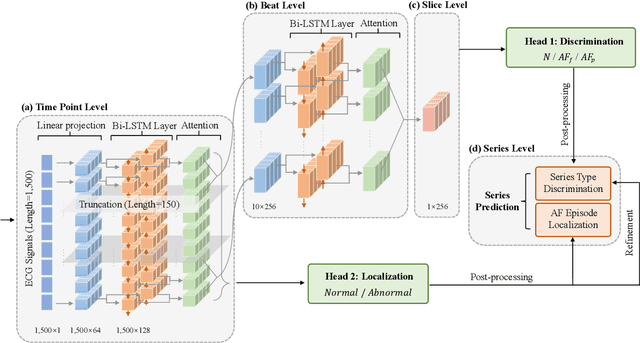

The automatic detection of atrial fibrillation based on electrocardiograph (ECG) signals has received wide attention both clinically and practically. It is challenging to process ECG signals with cyclical pattern, varying length and unstable quality due to noise and distortion. Besides, there has been insufficient research on separating persistent atrial fibrillation from paroxysmal atrial fibrillation, and little discussion on locating the onsets and end points of AF episodes. It is even more arduous to perform well on these two distinct but interrelated tasks, while avoiding the mistakes inherent from stage-by-stage approaches. This paper proposes the Multi-level Multi-task Attention-based Recurrent Neural Network for three-class discrimination on patients and localization of the exact timing of AF episodes. Our model captures three-level sequential features based on a hierarchical architecture utilizing Bidirectional Long and Short-Term Memory Network (Bi-LSTM) and attention layers, and accomplishes the two tasks simultaneously with a multi-head classifier. The model is designed as an end-to-end framework to enhance information interaction and reduce error accumulation. Finally, we conduct experiments on CPSC 2021 dataset and the result demonstrates the superior performance of our method, indicating the potential application of MMA-RNN to wearable mobile devices for routine AF monitoring and early diagnosis.
Cluster-Level Contrastive Learning for Emotion Recognition in Conversations
Feb 07, 2023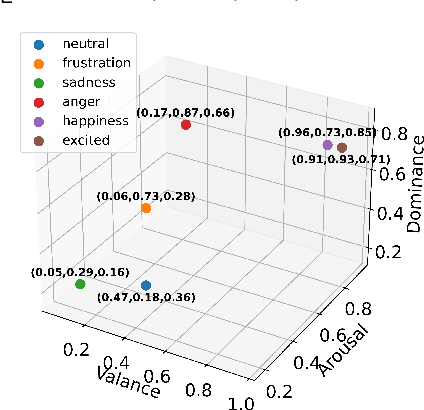

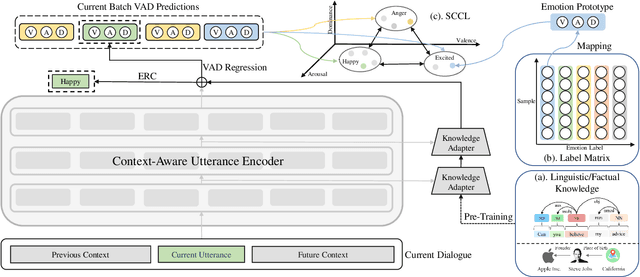
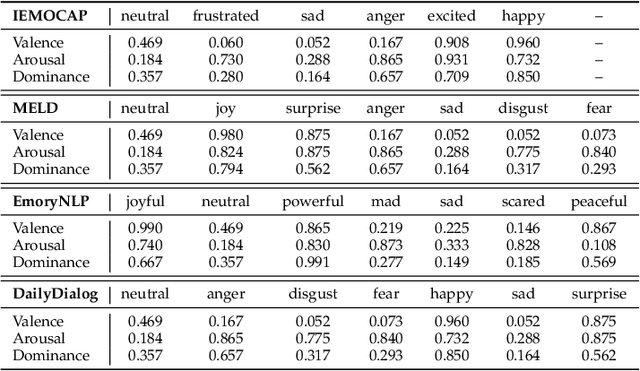
A key challenge for Emotion Recognition in Conversations (ERC) is to distinguish semantically similar emotions. Some works utilise Supervised Contrastive Learning (SCL) which uses categorical emotion labels as supervision signals and contrasts in high-dimensional semantic space. However, categorical labels fail to provide quantitative information between emotions. ERC is also not equally dependent on all embedded features in the semantic space, which makes the high-dimensional SCL inefficient. To address these issues, we propose a novel low-dimensional Supervised Cluster-level Contrastive Learning (SCCL) method, which first reduces the high-dimensional SCL space to a three-dimensional affect representation space Valence-Arousal-Dominance (VAD), then performs cluster-level contrastive learning to incorporate measurable emotion prototypes. To help modelling the dialogue and enriching the context, we leverage the pre-trained knowledge adapters to infuse linguistic and factual knowledge. Experiments show that our method achieves new state-of-the-art results with 69.81% on IEMOCAP, 65.7% on MELD, and 62.51% on DailyDialog datasets. The analysis also proves that the VAD space is not only suitable for ERC but also interpretable, with VAD prototypes enhancing its performance and stabilising the training of SCCL. In addition, the pre-trained knowledge adapters benefit the performance of the utterance encoder and SCCL. Our code is available at: https://github.com/SteveKGYang/SCCL
Learning Discretized Neural Networks under Ricci Flow
Feb 07, 2023
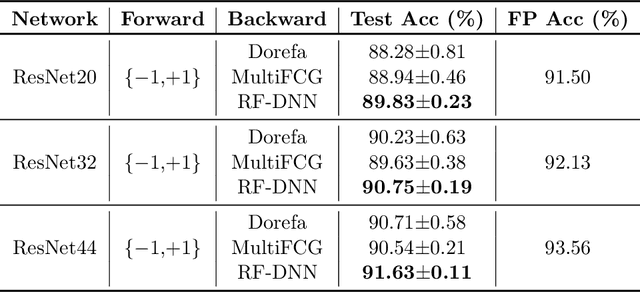
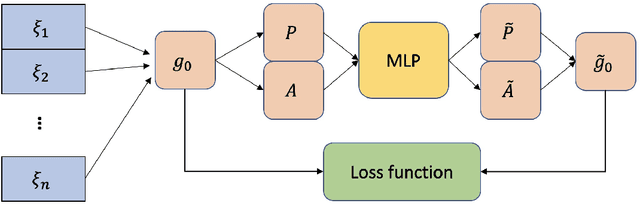
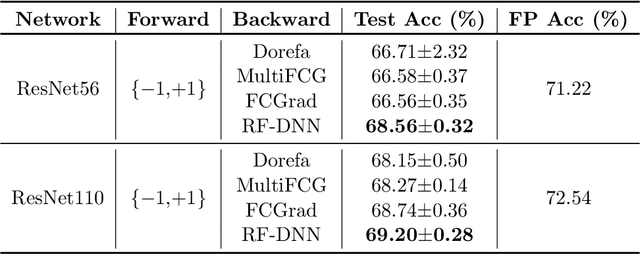
In this paper, we consider Discretized Neural Networks (DNNs) consisting of low-precision weights and activations, which suffer from either infinite or zero gradients caused by the non-differentiable discrete function in the training process. In this case, most training-based DNNs use the standard Straight-Through Estimator (STE) to approximate the gradient w.r.t. discrete value. However, the standard STE will cause the gradient mismatch problem, i.e., the approximated gradient direction may deviate from the steepest descent direction. In other words, the gradient mismatch implies the approximated gradient with perturbations. To address this problem, we introduce the duality theory to regard the perturbation of the approximated gradient as the perturbation of the metric in Linearly Nearly Euclidean (LNE) manifolds. Simultaneously, under the Ricci-DeTurck flow, we prove the dynamical stability and convergence of the LNE metric with the $L^2$-norm perturbation, which can provide a theoretical solution for the gradient mismatch problem. In practice, we also present the steepest descent gradient flow for DNNs on LNE manifolds from the viewpoints of the information geometry and mirror descent. The experimental results on various datasets demonstrate that our method achieves better and more stable performance for DNNs than other representative training-based methods.