 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Triple-CFN: Restructuring Conceptual Spaces for Enhancing Abstract Reasoning process
Mar 09, 2024
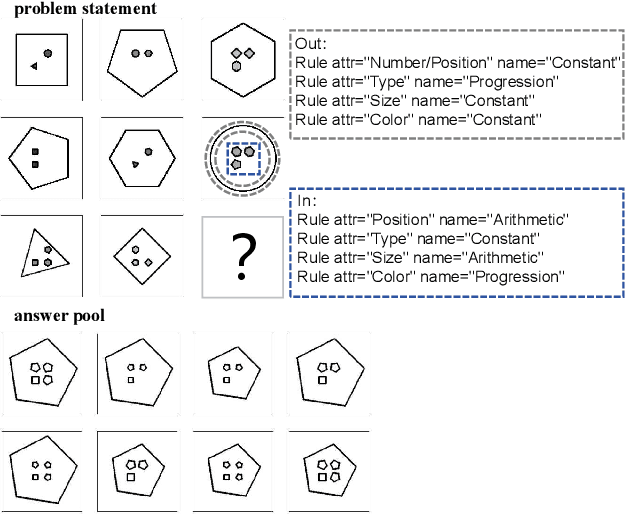
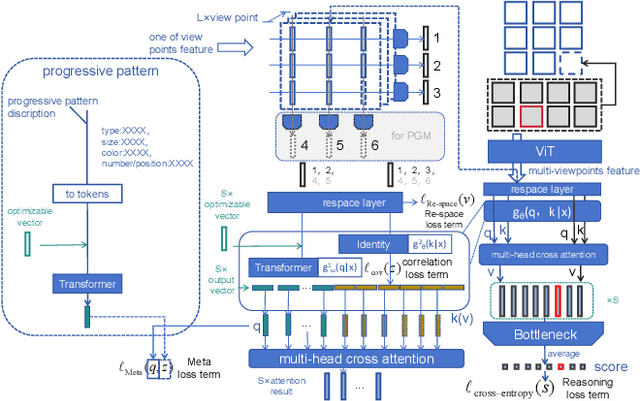
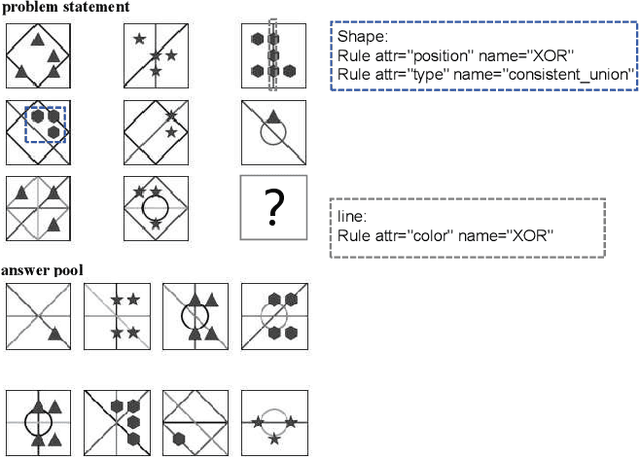

Abstract reasoning problems pose significant challenges to artificial intelligence algorithms, demanding cognitive capabilities beyond those required for perception tasks. This study introduces the Triple-CFN approach to tackle the Bongard-Logo problem, achieving notable reasoning accuracy by implicitly reorganizing the concept space of conflicting instances. Additionally, the Triple-CFN paradigm proves effective for the RPM problem with necessary modifications, yielding competitive results. To further enhance performance on the RPM issue, we develop the Meta Triple-CFN network, which explicitly structures the problem space while maintaining interpretability on progressive patterns. The success of Meta Triple-CFN is attributed to its paradigm of modeling the conceptual space, equivalent to normalizing reasoning information. Based on this ideology, we introduce the Re-space layer, enhancing the performance of both Meta Triple-CFN and Triple-CFN. This paper aims to contribute to advancements in machine intelligence by exploring innovative network designs for addressing abstract reasoning problems, paving the way for further breakthroughs in this domain.
Automated Testing of Spatially-Dependent Environmental Hypotheses through Active Transfer Learning
Mar 07, 2024The efficient collection of samples is an important factor in outdoor information gathering applications on account of high sampling costs such as time, energy, and potential destruction to the environment. Utilization of available a-priori data can be a powerful tool for increasing efficiency. However, the relationships of this data with the quantity of interest are often not known ahead of time, limiting the ability to leverage this knowledge for improved planning efficiency. To this end, this work combines transfer learning and active learning through a Multi-Task Gaussian Process and an information-based objective function. Through this combination it can explore the space of hypothetical inter-quantity relationships and evaluate these hypotheses in real-time, allowing this new knowledge to be immediately exploited for future plans. The performance of the proposed method is evaluated against synthetic data and is shown to evaluate multiple hypotheses correctly. Its effectiveness is also demonstrated on real datasets. The technique is able to identify and leverage hypotheses which show a medium or strong correlation to reduce prediction error by a factor of 1.4--3.4 within the first 7 samples, and poor hypotheses are quickly identified and rejected eventually having no adverse effect.
Multi-step Temporal Modeling for UAV Tracking
Mar 07, 2024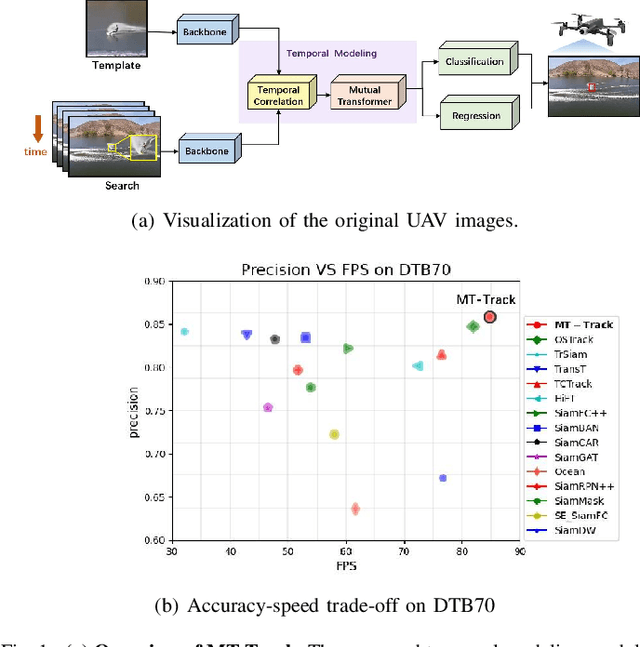
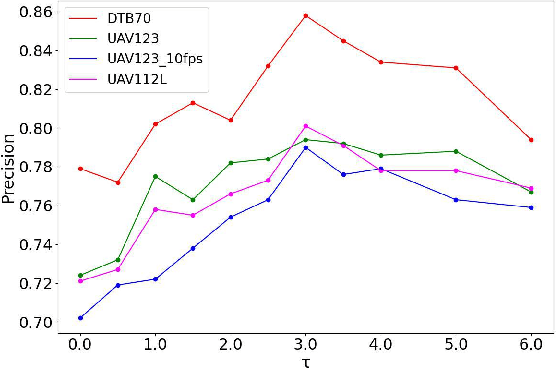

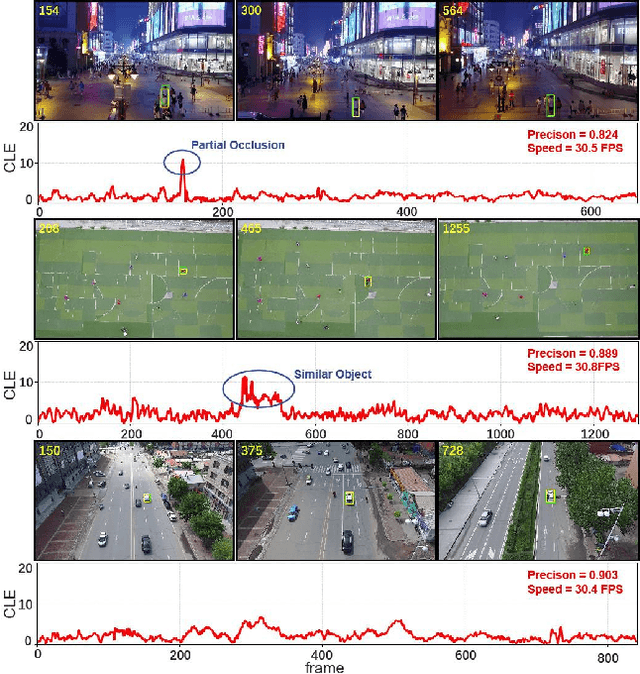
In the realm of unmanned aerial vehicle (UAV) tracking, Siamese-based approaches have gained traction due to their optimal balance between efficiency and precision. However, UAV scenarios often present challenges such as insufficient sampling resolution, fast motion and small objects with limited feature information. As a result, temporal context in UAV tracking tasks plays a pivotal role in target location, overshadowing the target's precise features. In this paper, we introduce MT-Track, a streamlined and efficient multi-step temporal modeling framework designed to harness the temporal context from historical frames for enhanced UAV tracking. This temporal integration occurs in two steps: correlation map generation and correlation map refinement. Specifically, we unveil a unique temporal correlation module that dynamically assesses the interplay between the template and search region features. This module leverages temporal information to refresh the template feature, yielding a more precise correlation map. Subsequently, we propose a mutual transformer module to refine the correlation maps of historical and current frames by modeling the temporal knowledge in the tracking sequence. This method significantly trims computational demands compared to the raw transformer. The compact yet potent nature of our tracking framework ensures commendable tracking outcomes, particularly in extended tracking scenarios.
ComTraQ-MPC: Meta-Trained DQN-MPC Integration for Trajectory Tracking with Limited Active Localization Updates
Mar 07, 2024
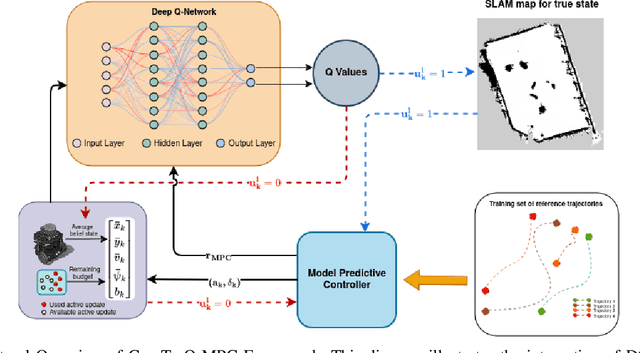
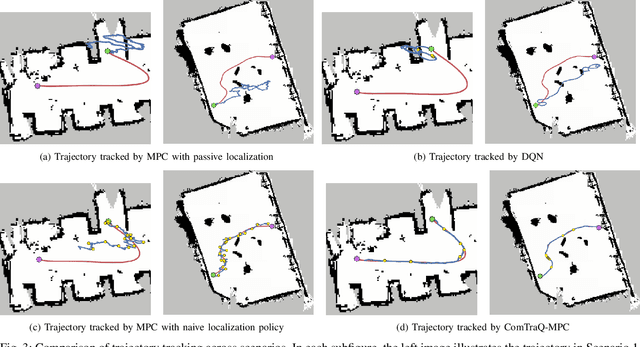
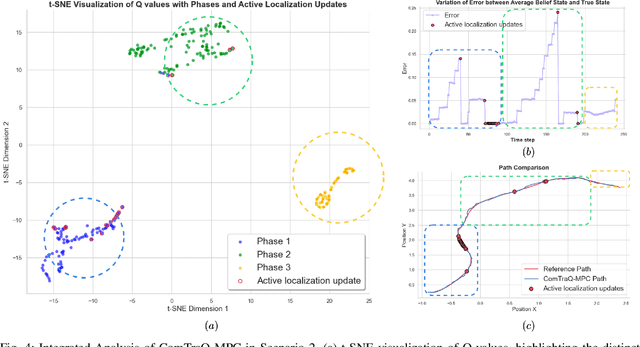
Optimal decision-making for trajectory tracking in partially observable, stochastic environments where the number of active localization updates -- the process by which the agent obtains its true state information from the sensors -- are limited, presents a significant challenge. Traditional methods often struggle to balance resource conservation, accurate state estimation and precise tracking, resulting in suboptimal performance. This problem is particularly pronounced in environments with large action spaces, where the need for frequent, accurate state data is paramount, yet the capacity for active localization updates is restricted by external limitations. This paper introduces ComTraQ-MPC, a novel framework that combines Deep Q-Networks (DQN) and Model Predictive Control (MPC) to optimize trajectory tracking with constrained active localization updates. The meta-trained DQN ensures adaptive active localization scheduling, while the MPC leverages available state information to improve tracking. The central contribution of this work is their reciprocal interaction: DQN's update decisions inform MPC's control strategy, and MPC's outcomes refine DQN's learning, creating a cohesive, adaptive system. Empirical evaluations in simulated and real-world settings demonstrate that ComTraQ-MPC significantly enhances operational efficiency and accuracy, providing a generalizable and approximately optimal solution for trajectory tracking in complex partially observable environments.
PrimeComposer: Faster Progressively Combined Diffusion for Image Composition with Attention Steering
Mar 08, 2024
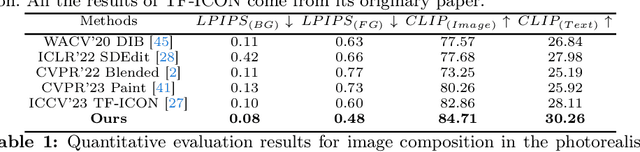

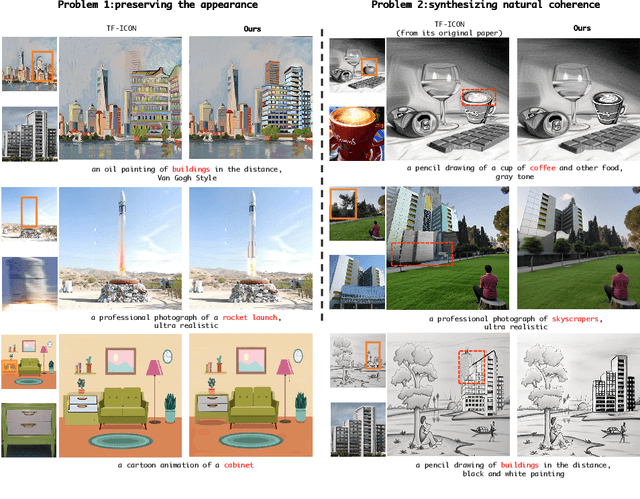
Image composition involves seamlessly integrating given objects into a specific visual context. The current training-free methods rely on composing attention weights from several samplers to guide the generator. However, since these weights are derived from disparate contexts, their combination leads to coherence confusion in synthesis and loss of appearance information. These issues worsen with their excessive focus on background generation, even when unnecessary in this task. This not only slows down inference but also compromises foreground generation quality. Moreover, these methods introduce unwanted artifacts in the transition area. In this paper, we formulate image composition as a subject-based local editing task, solely focusing on foreground generation. At each step, the edited foreground is combined with the noisy background to maintain scene consistency. To address the remaining issues, we propose PrimeComposer, a faster training-free diffuser that composites the images by well-designed attention steering across different noise levels. This steering is predominantly achieved by our Correlation Diffuser, utilizing its self-attention layers at each step. Within these layers, the synthesized subject interacts with both the referenced object and background, capturing intricate details and coherent relationships. This prior information is encoded into the attention weights, which are then integrated into the self-attention layers of the generator to guide the synthesis process. Besides, we introduce a Region-constrained Cross-Attention to confine the impact of specific subject-related words to desired regions, addressing the unwanted artifacts shown in the prior method thereby further improving the coherence in the transition area. Our method exhibits the fastest inference efficiency and extensive experiments demonstrate our superiority both qualitatively and quantitatively.
Foundational propositions of hesitant fuzzy soft $β$-covering approximation spaces
Mar 08, 2024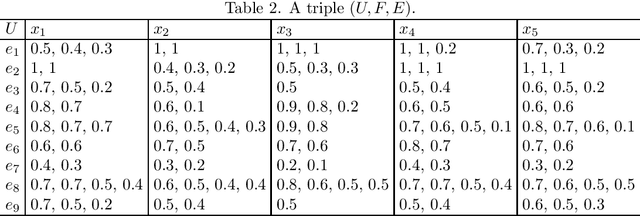
Soft set theory serves as a mathematical framework for handling uncertain information, and hesitant fuzzy sets find extensive application in scenarios involving uncertainty and hesitation. Hesitant fuzzy sets exhibit diverse membership degrees, giving rise to various forms of inclusion relationships among them. This article introduces the notions of hesitant fuzzy soft $\beta$-coverings and hesitant fuzzy soft $\beta$-neighborhoods, which are formulated based on distinct forms of inclusion relationships among hesitancy fuzzy sets. Subsequently, several associated properties are investigated. Additionally, specific variations of hesitant fuzzy soft $\beta$-coverings are introduced by incorporating hesitant fuzzy rough sets, followed by an exploration of properties pertaining to hesitant fuzzy soft $\beta$-covering approximation spaces.
A Privacy-Preserving Framework with Multi-Modal Data for Cross-Domain Recommendation
Mar 06, 2024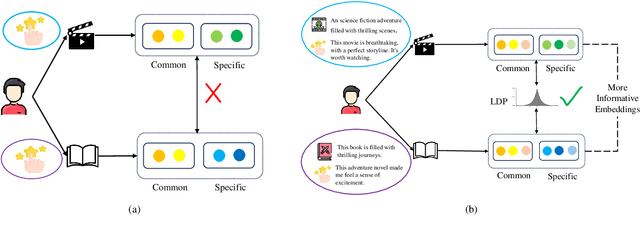

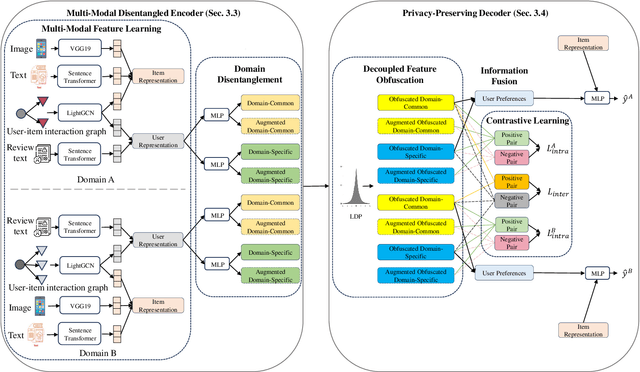
Cross-domain recommendation (CDR) aims to enhance recommendation accuracy in a target domain with sparse data by leveraging rich information in a source domain, thereby addressing the data-sparsity problem. Some existing CDR methods highlight the advantages of extracting domain-common and domain-specific features to learn comprehensive user and item representations. However, these methods can't effectively disentangle these components as they often rely on simple user-item historical interaction information (such as ratings, clicks, and browsing), neglecting the rich multi-modal features. Additionally, they don't protect user-sensitive data from potential leakage during knowledge transfer between domains. To address these challenges, we propose a Privacy-Preserving Framework with Multi-Modal Data for Cross-Domain Recommendation, called P2M2-CDR. Specifically, we first design a multi-modal disentangled encoder that utilizes multi-modal information to disentangle more informative domain-common and domain-specific embeddings. Furthermore, we introduce a privacy-preserving decoder to mitigate user privacy leakage during knowledge transfer. Local differential privacy (LDP) is utilized to obfuscate the disentangled embeddings before inter-domain exchange, thereby enhancing privacy protection. To ensure both consistency and differentiation among these obfuscated disentangled embeddings, we incorporate contrastive learning-based domain-inter and domain-intra losses. Extensive Experiments conducted on four real-world datasets demonstrate that P2M2-CDR outperforms other state-of-the-art single-domain and cross-domain baselines.
Parameterized quantum comb and simpler circuits for reversing unknown qubit-unitary operations
Mar 06, 2024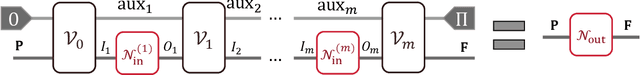
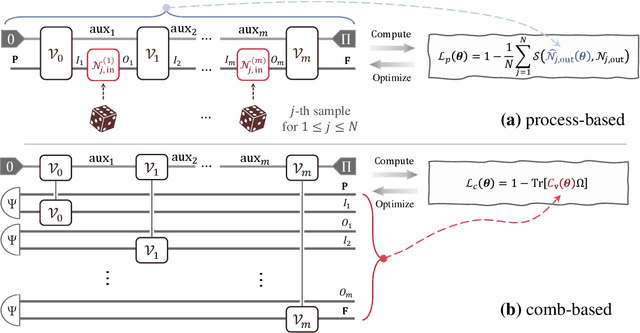
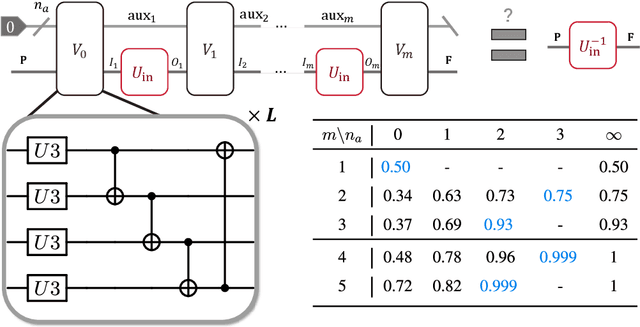
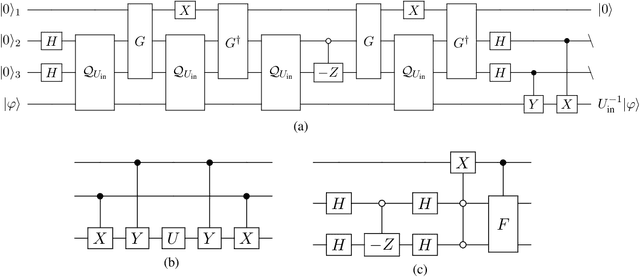
Quantum comb is an essential tool for characterizing complex quantum protocols in quantum information processing. In this work, we introduce PQComb, a framework leveraging parameterized quantum circuits to explore the capabilities of quantum combs for general quantum process transformation tasks and beyond. By optimizing PQComb for time-reversal simulations of unknown unitary evolutions, we develop a simpler protocol for unknown qubit unitary inversion that reduces the ancilla qubit overhead from 6 to 3 compared to the existing method in [Yoshida, Soeda, Murao, PRL 131, 120602, 2023]. This demonstrates the utility of quantum comb structures and showcases PQComb's potential for solving complex quantum tasks. Our results pave the way for broader PQComb applications in quantum computing and quantum information, emphasizing its versatility for tackling diverse problems in quantum machine learning.
FaaF: Facts as a Function for the evaluation of RAG systems
Mar 06, 2024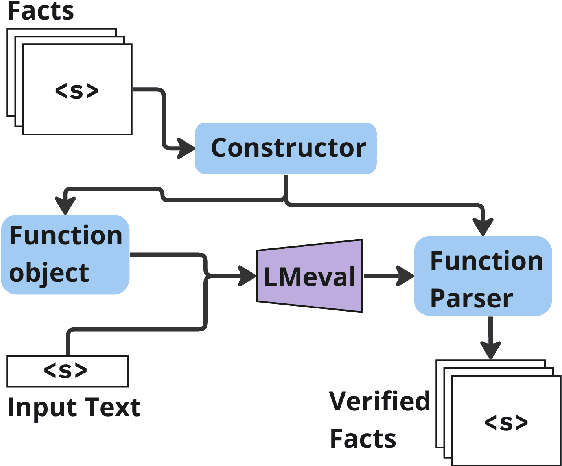

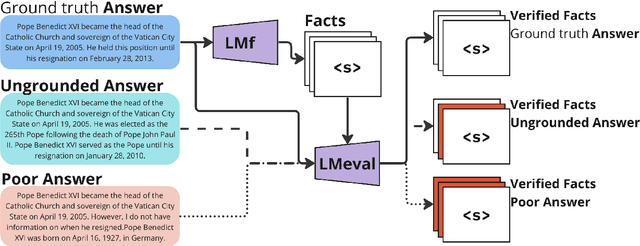
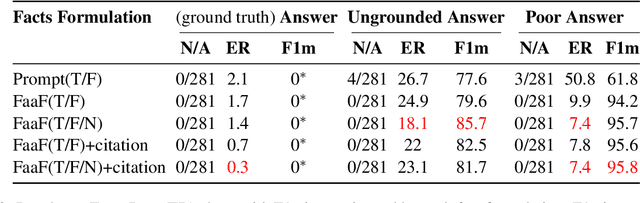
Factual recall from a reference source is crucial for evaluating the performance of Retrieval Augmented Generation (RAG) systems, as it directly probes into the quality of both retrieval and generation. However, it still remains a challenge to perform this evaluation reliably and efficiently. Recent work has focused on fact verification via prompting language model (LM) evaluators, however we demonstrate that these methods are unreliable in the presence of incomplete or inaccurate information. We introduce Facts as a Function (FaaF), a new approach to fact verification that utilizes the function calling abilities of LMs and a framework for RAG factual recall evaluation. FaaF substantially improves the ability of LMs to identify unsupported facts in text with incomplete information whilst improving efficiency and lowering cost by several times, compared to prompt-based approaches.
Cooperative Classification and Rationalization for Graph Generalization
Mar 10, 2024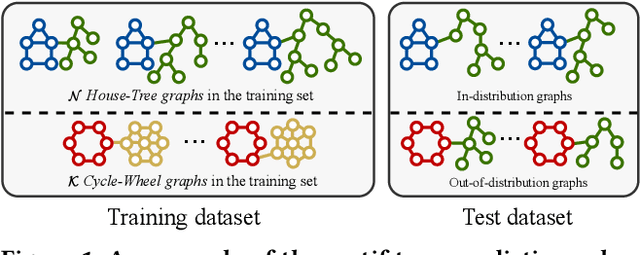
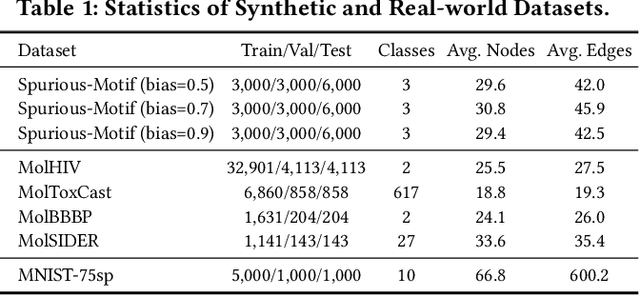
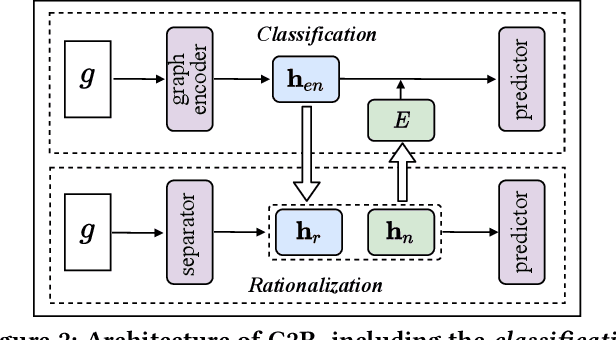
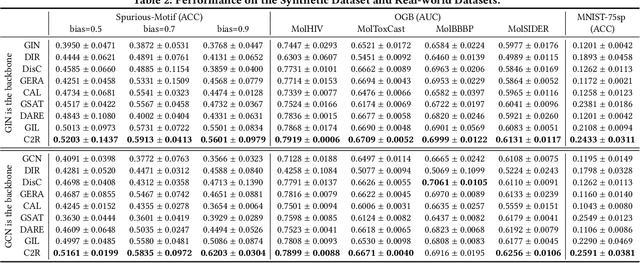
Graph Neural Networks (GNNs) have achieved impressive results in graph classification tasks, but they struggle to generalize effectively when faced with out-of-distribution (OOD) data. Several approaches have been proposed to address this problem. Among them, one solution is to diversify training distributions in vanilla classification by modifying the data environment, yet accessing the environment information is complex. Besides, another promising approach involves rationalization, extracting invariant rationales for predictions. However, extracting rationales is difficult due to limited learning signals, resulting in less accurate rationales and diminished predictions. To address these challenges, in this paper, we propose a Cooperative Classification and Rationalization (C2R) method, consisting of the classification and the rationalization module. Specifically, we first assume that multiple environments are available in the classification module. Then, we introduce diverse training distributions using an environment-conditional generative network, enabling robust graph representations. Meanwhile, the rationalization module employs a separator to identify relevant rationale subgraphs while the remaining non-rationale subgraphs are de-correlated with labels. Next, we align graph representations from the classification module with rationale subgraph representations using the knowledge distillation methods, enhancing the learning signal for rationales. Finally, we infer multiple environments by gathering non-rationale representations and incorporate them into the classification module for cooperative learning. Extensive experimental results on both benchmarks and synthetic datasets demonstrate the effectiveness of C2R. Code is available at https://github.com/yuelinan/Codes-of-C2R.