 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ISAC-Enabled V2I Networks Based on 5G NR: How Many Overheads Can Be Reduced?
Jan 30, 2023
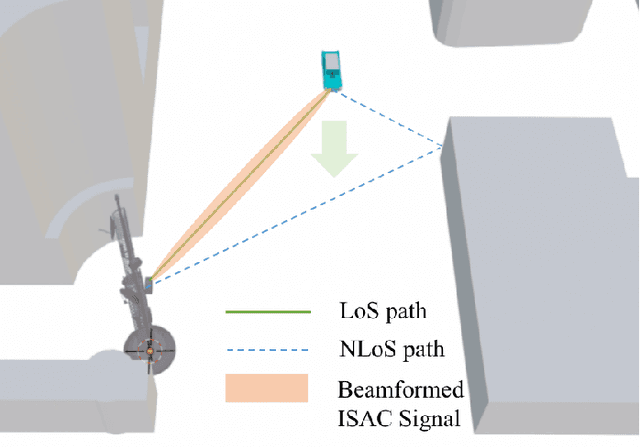
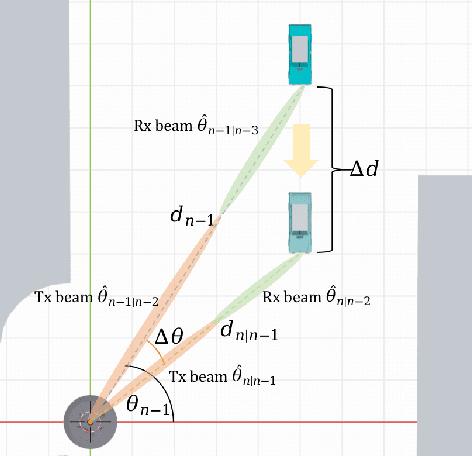
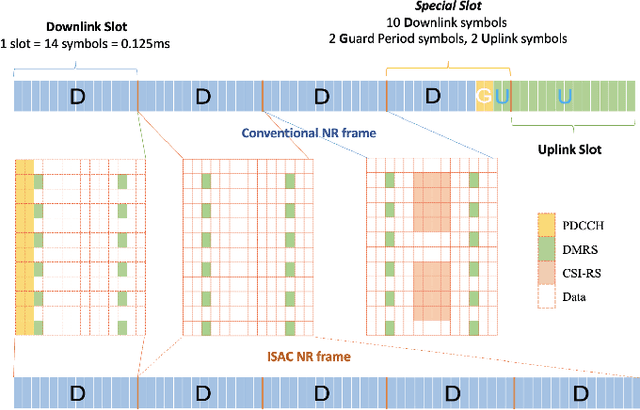
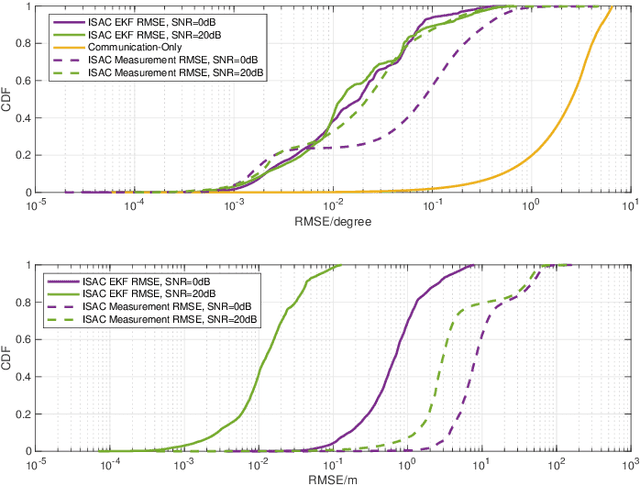
The emergence of the fifth-generation (5G) New Radio (NR) brings additional possibilities to vehicle-to-everything (V2X) network with improved quality of services. In order to obtain accurate channel state information (CSI) in high-mobility V2X networks, pilot signals and frequent handover between vehicles and infrastructures are required to establish and maintain the communication link, which increases the overheads and reduces the communication throughput. To address this issue, integrated sensing and communications (ISAC) was employed at the base station (BS) in the vehicle-to-infrastructure (V2I) network to reduce a certain amount of overheads, thus improve the spectral efficiency. Nevertheless, the exact amount of overheads reduction remains unclear, particularly for practical NR based V2X networks. In this paper, we study a link-level NR based V2I system employing ISAC signaling to facilitate the communication beam management, where the Extended Kalman filtering (EKF) algorithm is performed to realize the functions of tracking and predicting the motion of the vehicle. We provide detailed analysis on the overheads reduction with the aid of ISAC, and show that up to 43.24% overheads can be reduced under assigned NR frame structure. In addition, numerical results are provided to validate the improved performance on the beam tracking and communication throughput.
IMKGA-SM: Interpretable Multimodal Knowledge Graph Answer Prediction via Sequence Modeling
Jan 10, 2023

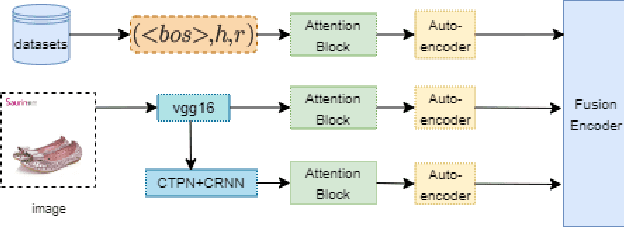

Multimodal knowledge graph link prediction aims to improve the accuracy and efficiency of link prediction tasks for multimodal data. However, for complex multimodal information and sparse training data, it is usually difficult to achieve interpretability and high accuracy simultaneously for most methods. To address this difficulty, a new model is developed in this paper, namely Interpretable Multimodal Knowledge Graph Answer Prediction via Sequence Modeling (IMKGA-SM). First, a multi-modal fine-grained fusion method is proposed, and Vgg16 and Optical Character Recognition (OCR) techniques are adopted to effectively extract text information from images and images. Then, the knowledge graph link prediction task is modelled as an offline reinforcement learning Markov decision model, which is then abstracted into a unified sequence framework. An interactive perception-based reward expectation mechanism and a special causal masking mechanism are designed, which ``converts" the query into an inference path. Then, an autoregressive dynamic gradient adjustment mechanism is proposed to alleviate the insufficient problem of multimodal optimization. Finally, two datasets are adopted for experiments, and the popular SOTA baselines are used for comparison. The results show that the developed IMKGA-SM achieves much better performance than SOTA baselines on multimodal link prediction datasets of different sizes.
Graph state-space models
Jan 04, 2023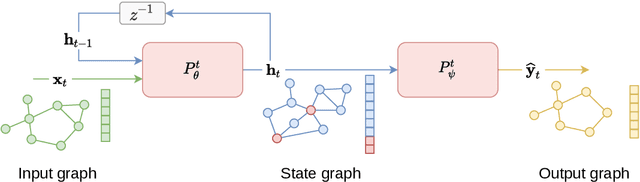

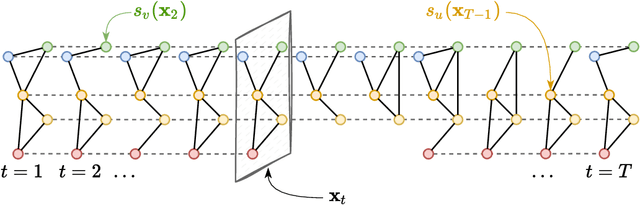
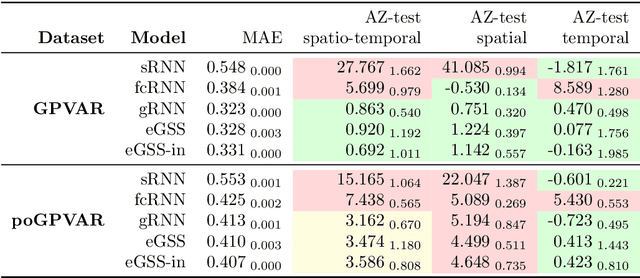
State-space models constitute an effective modeling tool to describe multivariate time series and operate by maintaining an updated representation of the system state from which predictions are made. Within this framework, relational inductive biases, e.g., associated with functional dependencies existing among signals, are not explicitly exploited leaving unattended great opportunities for effective modeling approaches. The manuscript aims, for the first time, at filling this gap by matching state-space modeling and spatio-temporal data where the relational information, say the functional graph capturing latent dependencies, is learned directly from data and is allowed to change over time. Within a probabilistic formulation that accounts for the uncertainty in the data-generating process, an encoder-decoder architecture is proposed to learn the state-space model end-to-end on a downstream task. The proposed methodological framework generalizes several state-of-the-art methods and demonstrates to be effective in extracting meaningful relational information while achieving optimal forecasting performance in controlled environments.
Falsification of Learning-Based Controllers through Multi-Fidelity Bayesian Optimization
Jan 04, 2023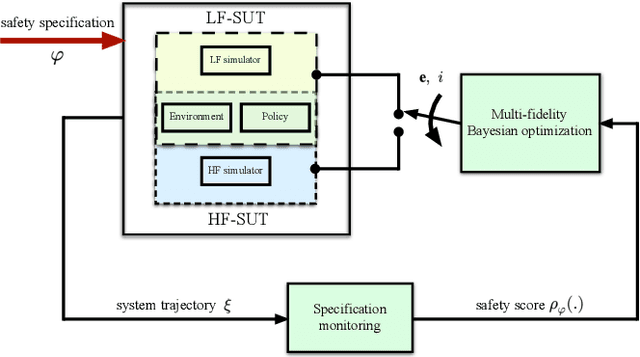
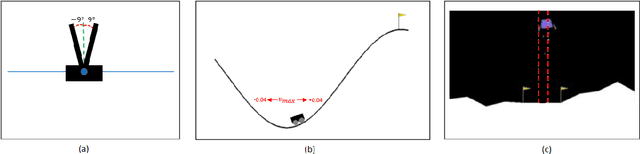
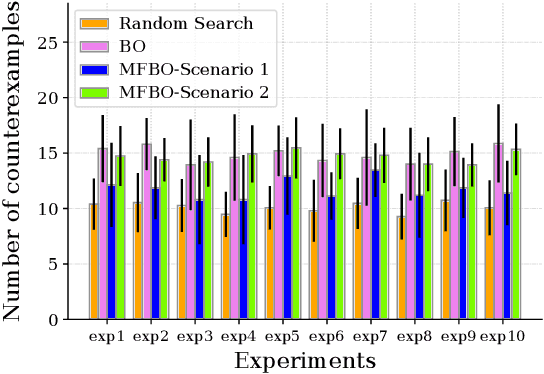
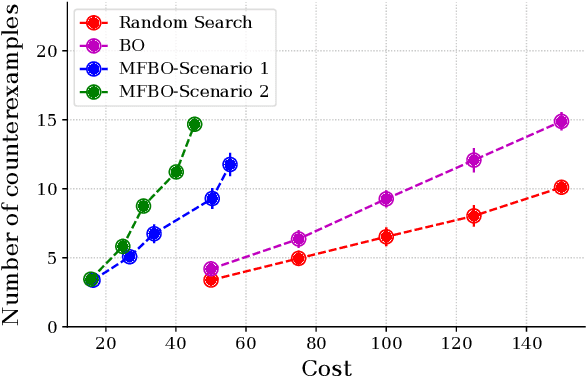
Simulation-based falsification is a practical testing method to increase confidence that the system will meet safety requirements. Because full-fidelity simulations can be computationally demanding, we investigate the use of simulators with different levels of fidelity. As a first step, we express the overall safety specification in terms of environmental parameters and structure this safety specification as an optimization problem. We propose a multi-fidelity falsification framework using Bayesian optimization, which is able to determine at which level of fidelity we should conduct a safety evaluation in addition to finding possible instances from the environment that cause the system to fail. This method allows us to automatically switch between inexpensive, inaccurate information from a low-fidelity simulator and expensive, accurate information from a high-fidelity simulator in a cost-effective way. Our experiments on various environments in simulation demonstrate that multi-fidelity Bayesian optimization has falsification performance comparable to single-fidelity Bayesian optimization but with much lower cost.
End-to-end Recording Device Identification Based on Deep Representation Learning
Dec 05, 2022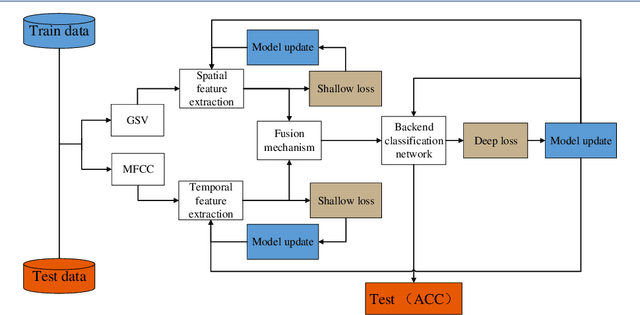

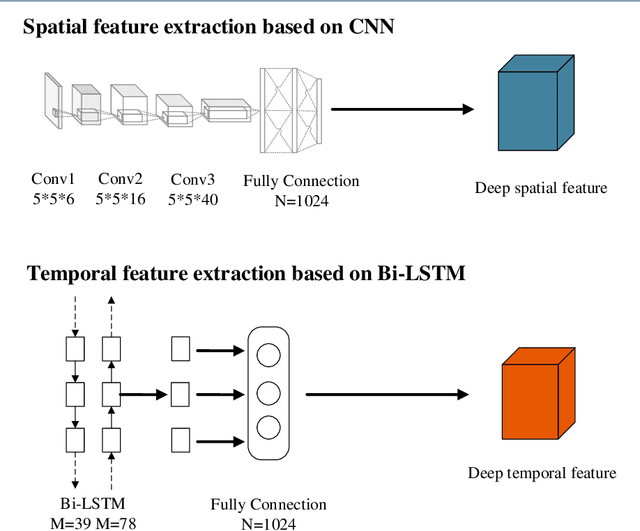

Deep learning techniques have achieved specific results in recording device source identification. The recording device source features include spatial information and certain temporal information. However, most recording device source identification methods based on deep learning only use spatial representation learning from recording device source features, which cannot make full use of recording device source information. Therefore, in this paper, to fully explore the spatial information and temporal information of recording device source, we propose a new method for recording device source identification based on the fusion of spatial feature information and temporal feature information by using an end-to-end framework. From a feature perspective, we designed two kinds of networks to extract recording device source spatial and temporal information. Afterward, we use the attention mechanism to adaptively assign the weight of spatial information and temporal information to obtain fusion features. From a model perspective, our model uses an end-to-end framework to learn the deep representation from spatial feature and temporal feature and train using deep and shallow loss to joint optimize our network. This method is compared with our previous work and baseline system. The results show that the proposed method is better than our previous work and baseline system under general conditions.
Fully Dynamic Online Selection through Online Contention Resolution Schemes
Jan 08, 2023
We study fully dynamic online selection problems in an adversarial/stochastic setting that includes Bayesian online selection, prophet inequalities, posted price mechanisms, and stochastic probing problems subject to combinatorial constraints. In the classical ``incremental'' version of the problem, selected elements remain active until the end of the input sequence. On the other hand, in the fully dynamic version of the problem, elements stay active for a limited time interval, and then leave. This models, for example, the online matching of tasks to workers with task/worker-dependent working times, and sequential posted pricing of perishable goods. A successful approach to online selection problems in the adversarial setting is given by the notion of Online Contention Resolution Scheme (OCRS), that uses a priori information to formulate a linear relaxation of the underlying optimization problem, whose optimal fractional solution is rounded online for any adversarial order of the input sequence. Our main contribution is providing a general method for constructing an OCRS for fully dynamic online selection problems. Then, we show how to employ such OCRS to construct no-regret algorithms in a partial information model with semi-bandit feedback and adversarial inputs.
Jointist: Simultaneous Improvement of Multi-instrument Transcription and Music Source Separation via Joint Training
Feb 02, 2023
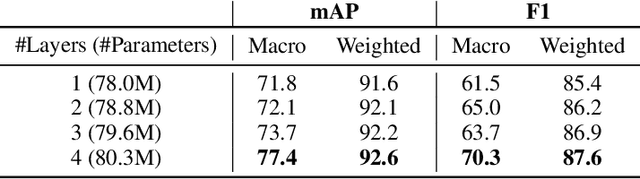
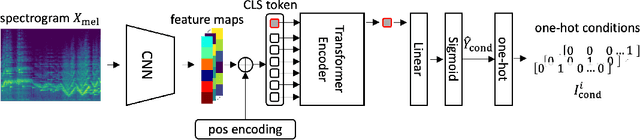
In this paper, we introduce Jointist, an instrument-aware multi-instrument framework that is capable of transcribing, recognizing, and separating multiple musical instruments from an audio clip. Jointist consists of an instrument recognition module that conditions the other two modules: a transcription module that outputs instrument-specific piano rolls, and a source separation module that utilizes instrument information and transcription results. The joint training of the transcription and source separation modules serves to improve the performance of both tasks. The instrument module is optional and can be directly controlled by human users. This makes Jointist a flexible user-controllable framework. Our challenging problem formulation makes the model highly useful in the real world given that modern popular music typically consists of multiple instruments. Its novelty, however, necessitates a new perspective on how to evaluate such a model. In our experiments, we assess the proposed model from various aspects, providing a new evaluation perspective for multi-instrument transcription. Our subjective listening study shows that Jointist achieves state-of-the-art performance on popular music, outperforming existing multi-instrument transcription models such as MT3. We conducted experiments on several downstream tasks and found that the proposed method improved transcription by more than 1 percentage points (ppt.), source separation by 5 SDR, downbeat detection by 1.8 ppt., chord recognition by 1.4 ppt., and key estimation by 1.4 ppt., when utilizing transcription results obtained from Jointist. Demo available at \url{https://jointist.github.io/Demo}.
Lower Bounds for Learning in Revealing POMDPs
Feb 02, 2023
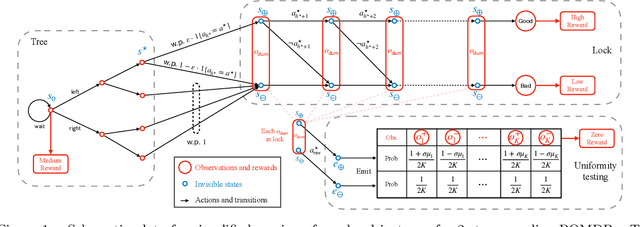
This paper studies the fundamental limits of reinforcement learning (RL) in the challenging \emph{partially observable} setting. While it is well-established that learning in Partially Observable Markov Decision Processes (POMDPs) requires exponentially many samples in the worst case, a surge of recent work shows that polynomial sample complexities are achievable under the \emph{revealing condition} -- A natural condition that requires the observables to reveal some information about the unobserved latent states. However, the fundamental limits for learning in revealing POMDPs are much less understood, with existing lower bounds being rather preliminary and having substantial gaps from the current best upper bounds. We establish strong PAC and regret lower bounds for learning in revealing POMDPs. Our lower bounds scale polynomially in all relevant problem parameters in a multiplicative fashion, and achieve significantly smaller gaps against the current best upper bounds, providing a solid starting point for future studies. In particular, for \emph{multi-step} revealing POMDPs, we show that (1) the latent state-space dependence is at least $\Omega(S^{1.5})$ in the PAC sample complexity, which is notably harder than the $\widetilde{\Theta}(S)$ scaling for fully-observable MDPs; (2) Any polynomial sublinear regret is at least $\Omega(T^{2/3})$, suggesting its fundamental difference from the \emph{single-step} case where $\widetilde{O}(\sqrt{T})$ regret is achievable. Technically, our hard instance construction adapts techniques in \emph{distribution testing}, which is new to the RL literature and may be of independent interest.
PIER: Permutation-Level Interest-Based End-to-End Re-ranking Framework in E-commerce
Feb 06, 2023

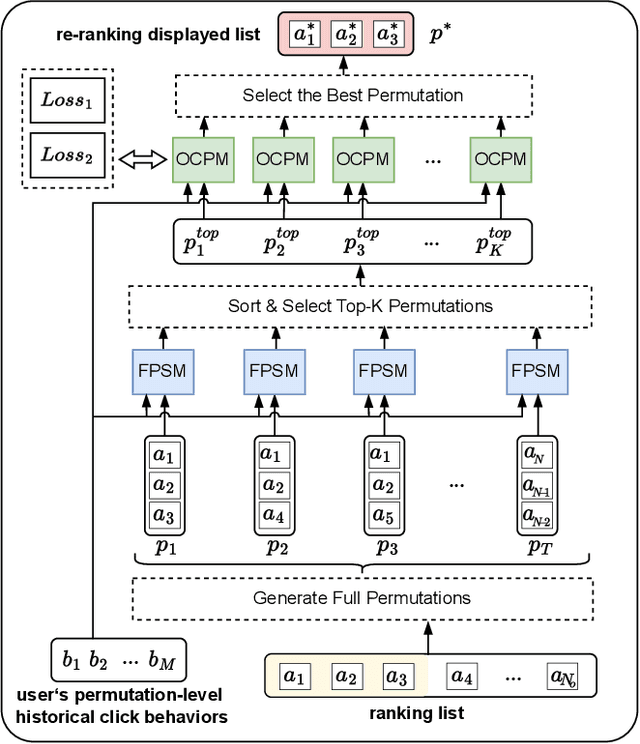
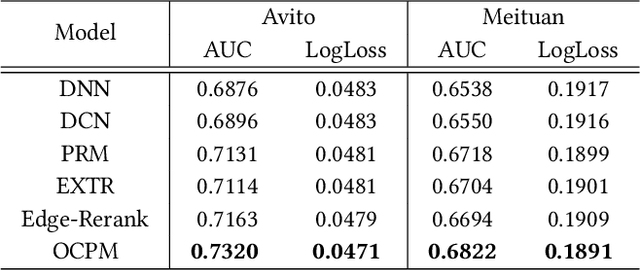
Re-ranking draws increased attention on both academics and industries, which rearranges the ranking list by modeling the mutual influence among items to better meet users' demands. Many existing re-ranking methods directly take the initial ranking list as input, and generate the optimal permutation through a well-designed context-wise model, which brings the evaluation-before-reranking problem. Meanwhile, evaluating all candidate permutations brings unacceptable computational costs in practice. Thus, to better balance efficiency and effectiveness, online systems usually use a two-stage architecture which uses some heuristic methods such as beam-search to generate a suitable amount of candidate permutations firstly, which are then fed into the evaluation model to get the optimal permutation. However, existing methods in both stages can be improved through the following aspects. As for generation stage, heuristic methods only use point-wise prediction scores and lack an effective judgment. As for evaluation stage, most existing context-wise evaluation models only consider the item context and lack more fine-grained feature context modeling. This paper presents a novel end-to-end re-ranking framework named PIER to tackle the above challenges which still follows the two-stage architecture and contains two mainly modules named FPSM and OCPM. We apply SimHash in FPSM to select top-K candidates from the full permutation based on user's permutation-level interest in an efficient way. Then we design a novel omnidirectional attention mechanism in OCPM to capture the context information in the permutation. Finally, we jointly train these two modules end-to-end by introducing a comparative learning loss. Offline experiment results demonstrate that PIER outperforms baseline models on both public and industrial datasets, and we have successfully deployed PIER on Meituan food delivery platform.
Learning Optimal Features via Partial Invariance
Jan 28, 2023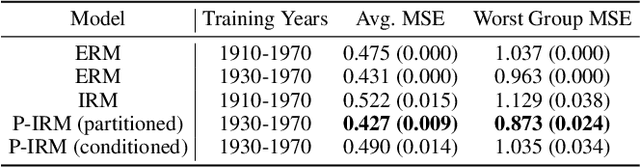
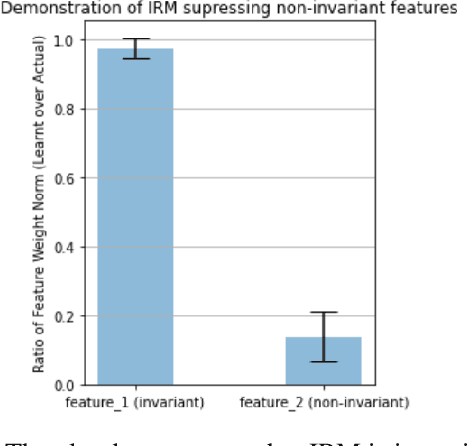
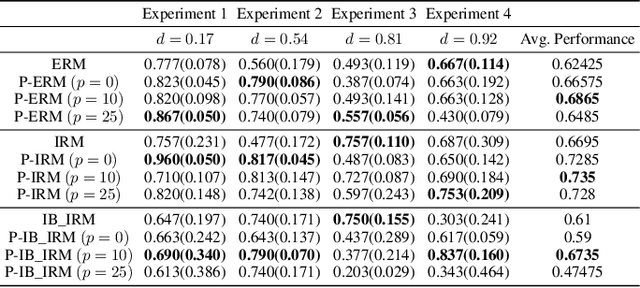
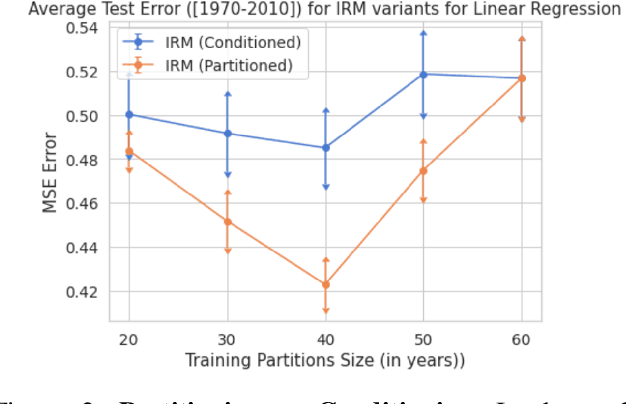
Learning models that are robust to test-time distribution shifts is a key concern in domain generalization, and in the wider context of their real-life applicability. Invariant Risk Minimization (IRM) is one particular framework that aims to learn deep invariant features from multiple domains and has subsequently led to further variants. A key assumption for the success of these methods requires that the underlying causal mechanisms/features remain invariant across domains and the true invariant features be sufficient to learn the optimal predictor. In practical problem settings, these assumptions are often not satisfied, which leads to IRM learning a sub-optimal predictor for that task. In this work, we propose the notion of partial invariance as a relaxation of the IRM framework. Under our problem setting, we first highlight the sub-optimality of the IRM solution. We then demonstrate how partitioning the training domains, assuming access to some meta-information about the domains, can help improve the performance of invariant models via partial invariance. Finally, we conduct several experiments, both in linear settings as well as with classification tasks in language and images with deep models, which verify our conclusions.