 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Semi-Automated Construction of Food Composition Knowledge Base
Jan 24, 2023
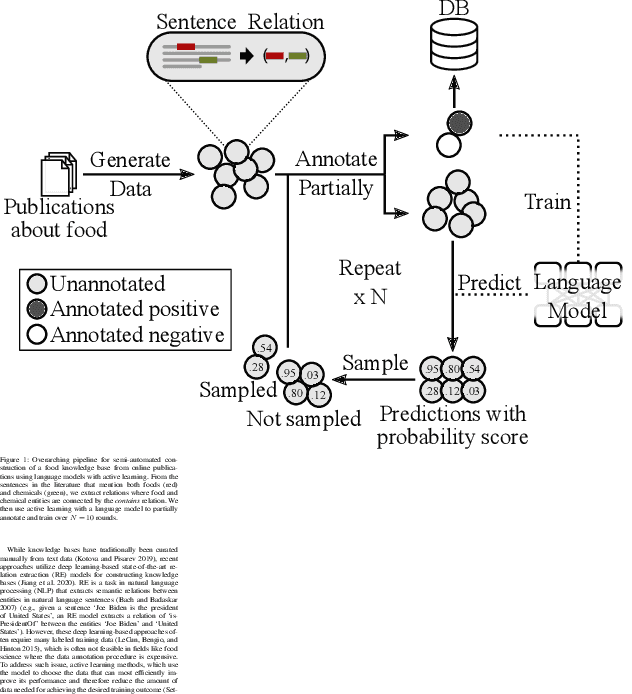
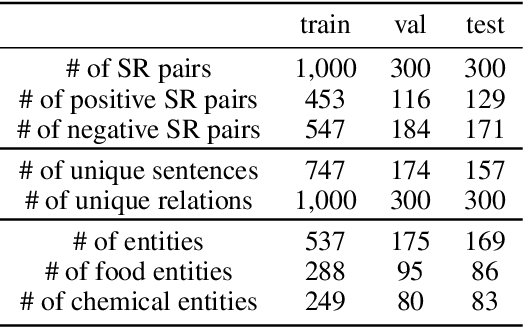
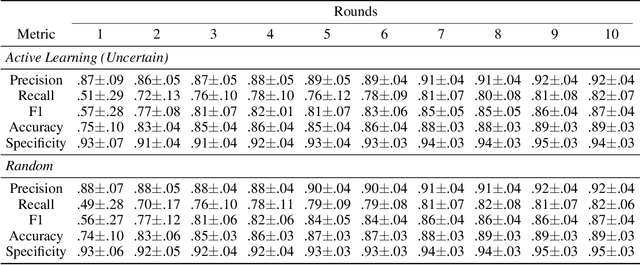
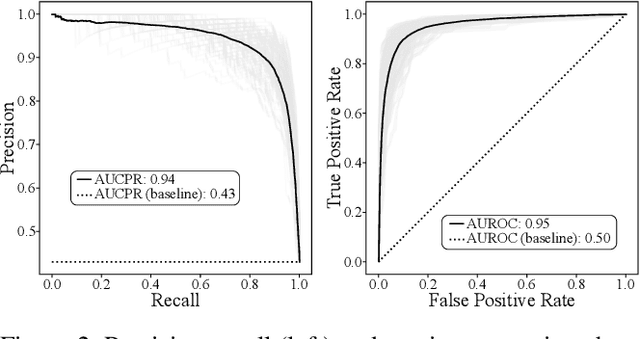
A food composition knowledge base, which stores the essential phyto-, micro-, and macro-nutrients of foods is useful for both research and industrial applications. Although many existing knowledge bases attempt to curate such information, they are often limited by time-consuming manual curation processes. Outside of the food science domain, natural language processing methods that utilize pre-trained language models have recently shown promising results for extracting knowledge from unstructured text. In this work, we propose a semi-automated framework for constructing a knowledge base of food composition from the scientific literature available online. To this end, we utilize a pre-trained BioBERT language model in an active learning setup that allows the optimal use of limited training data. Our work demonstrates how human-in-the-loop models are a step toward AI-assisted food systems that scale well to the ever-increasing big data.
Structure Flow-Guided Network for Real Depth Super-Resolution
Jan 31, 2023

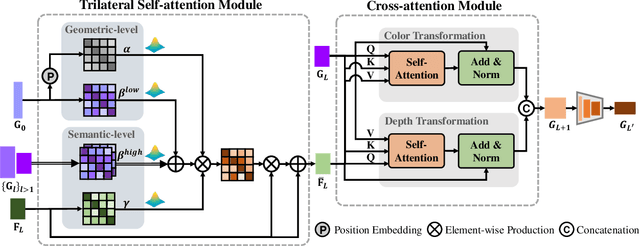

Real depth super-resolution (DSR), unlike synthetic settings, is a challenging task due to the structural distortion and the edge noise caused by the natural degradation in real-world low-resolution (LR) depth maps. These defeats result in significant structure inconsistency between the depth map and the RGB guidance, which potentially confuses the RGB-structure guidance and thereby degrades the DSR quality. In this paper, we propose a novel structure flow-guided DSR framework, where a cross-modality flow map is learned to guide the RGB-structure information transferring for precise depth upsampling. Specifically, our framework consists of a cross-modality flow-guided upsampling network (CFUNet) and a flow-enhanced pyramid edge attention network (PEANet). CFUNet contains a trilateral self-attention module combining both the geometric and semantic correlations for reliable cross-modality flow learning. Then, the learned flow maps are combined with the grid-sampling mechanism for coarse high-resolution (HR) depth prediction. PEANet targets at integrating the learned flow map as the edge attention into a pyramid network to hierarchically learn the edge-focused guidance feature for depth edge refinement. Extensive experiments on real and synthetic DSR datasets verify that our approach achieves excellent performance compared to state-of-the-art methods.
Hierarchical Disentangled Representation for Invertible Image Denoising and Beyond
Jan 31, 2023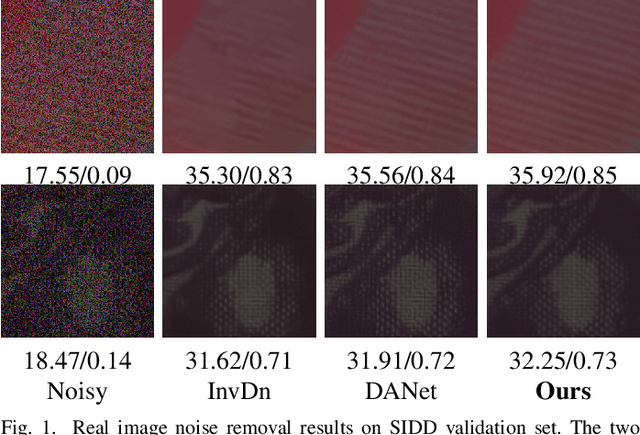
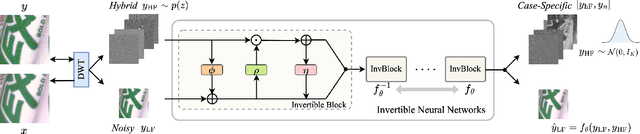
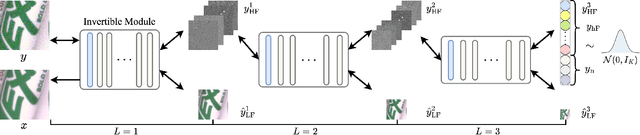
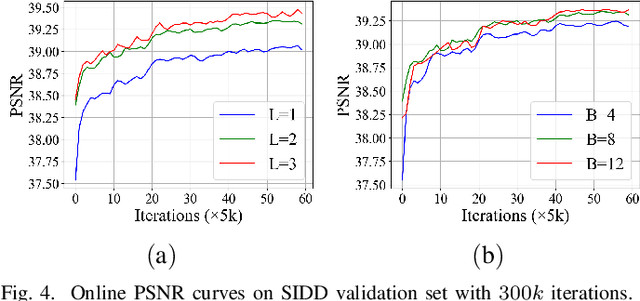
Image denoising is a typical ill-posed problem due to complex degradation. Leading methods based on normalizing flows have tried to solve this problem with an invertible transformation instead of a deterministic mapping. However, the implicit bijective mapping is not explored well. Inspired by a latent observation that noise tends to appear in the high-frequency part of the image, we propose a fully invertible denoising method that injects the idea of disentangled learning into a general invertible neural network to split noise from the high-frequency part. More specifically, we decompose the noisy image into clean low-frequency and hybrid high-frequency parts with an invertible transformation and then disentangle case-specific noise and high-frequency components in the latent space. In this way, denoising is made tractable by inversely merging noiseless low and high-frequency parts. Furthermore, we construct a flexible hierarchical disentangling framework, which aims to decompose most of the low-frequency image information while disentangling noise from the high-frequency part in a coarse-to-fine manner. Extensive experiments on real image denoising, JPEG compressed artifact removal, and medical low-dose CT image restoration have demonstrated that the proposed method achieves competing performance on both quantitative metrics and visual quality, with significantly less computational cost.
PerfectDou: Dominating DouDizhu with Perfect Information Distillation
Apr 05, 2022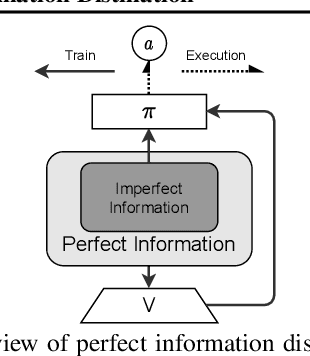

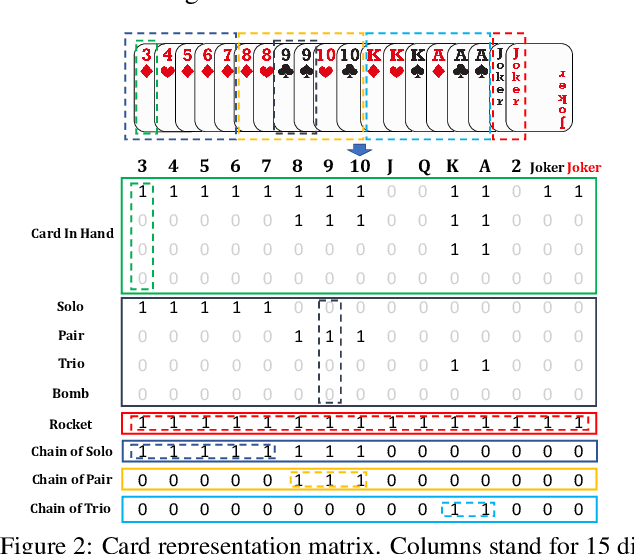
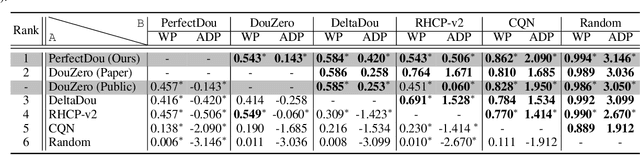
As a challenging multi-player card game, DouDizhu has recently drawn much attention for analyzing competition and collaboration in imperfect-information games. In this paper, we propose PerfectDou, a state-of-the-art DouDizhu AI system that dominates the game, in an actor-critic framework with a proposed technique named perfect information distillation. In detail, we adopt a perfect-training-imperfect-execution framework that allows the agents to utilize the global information to guide the training of the policies as if it is a perfect information game and the trained policies can be used to play the imperfect information game during the actual gameplay. To this end, we characterize card and game features for DouDizhu to represent the perfect and imperfect information. To train our system, we adopt proximal policy optimization with generalized advantage estimation in a parallel training paradigm. In experiments we show how and why PerfectDou beats all existing AI programs, and achieves state-of-the-art performance.
Information Fusion: Scaling Subspace-Driven Approaches
Apr 26, 2022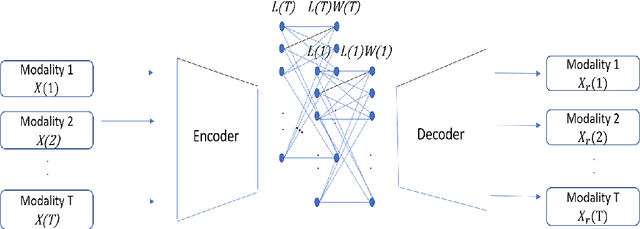
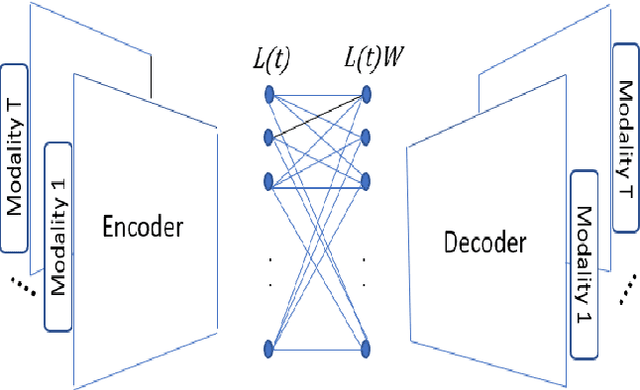
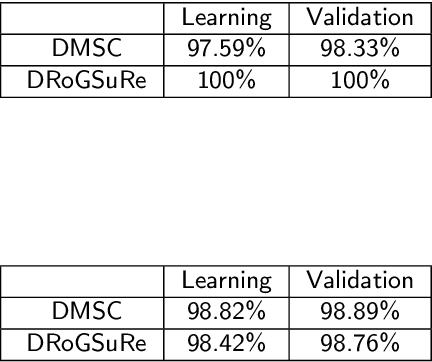
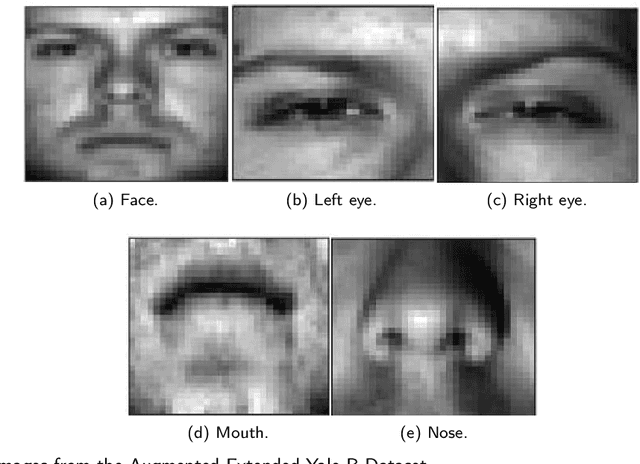
In this work, we seek to exploit the deep structure of multi-modal data to robustly exploit the group subspace distribution of the information using the Convolutional Neural Network (CNN) formalism. Upon unfolding the set of subspaces constituting each data modality, and learning their corresponding encoders, an optimized integration of the generated inherent information is carried out to yield a characterization of various classes. Referred to as deep Multimodal Robust Group Subspace Clustering (DRoGSuRe), this approach is compared against the independently developed state-of-the-art approach named Deep Multimodal Subspace Clustering (DMSC). Experiments on different multimodal datasets show that our approach is competitive and more robust in the presence of noise.
Energy-Aware, Collision-Free Information Gathering for Heterogeneous Robot Teams
Jul 30, 2022
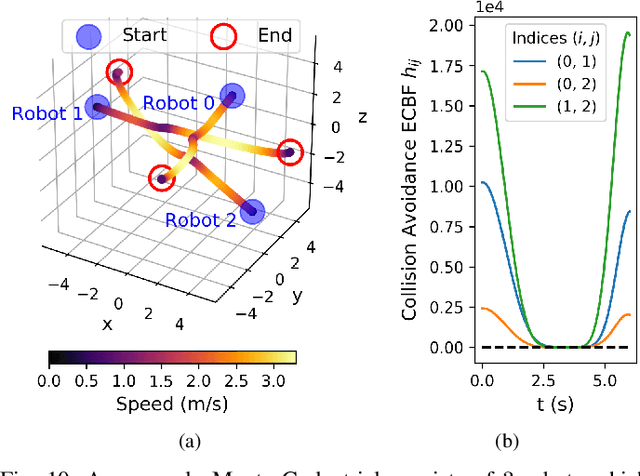
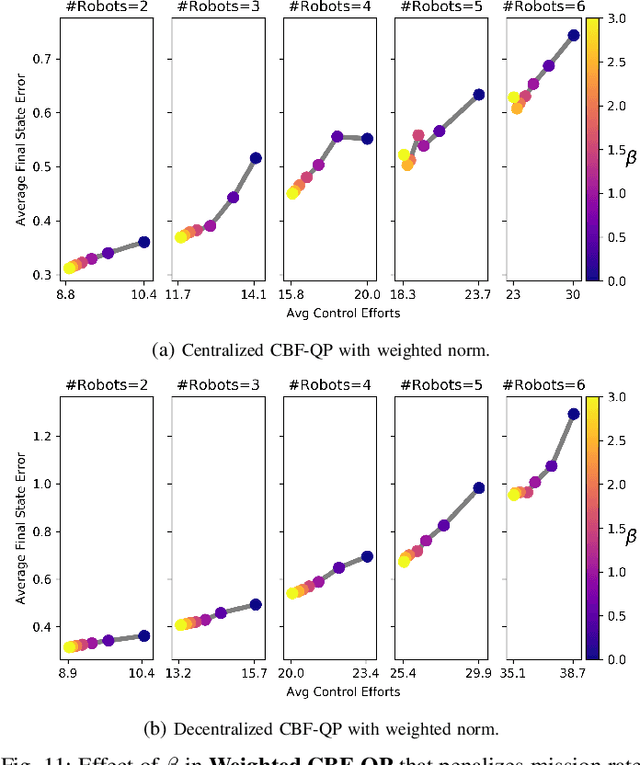
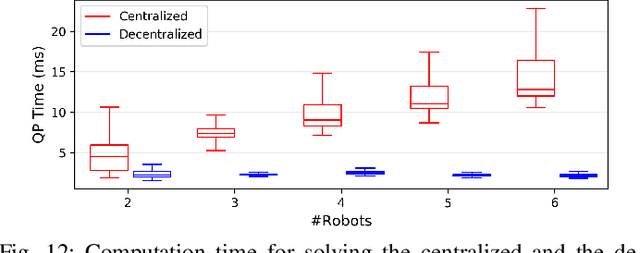
This paper considers the problem of safely coordinating a team of sensor-equipped robots to reduce uncertainty about a dynamical process, where the objective trades off information gain and energy cost. Optimizing this trade-off is desirable, but leads to a non-monotone objective function in the set of robot trajectories. Therefore, common multi-robot planners based on coordinate descent lose their performance guarantees. Furthermore, methods that handle non-monotonicity lose their performance guarantees when subject to inter-robot collision avoidance constraints. As it is desirable to retain both the performance guarantee and safety guarantee, this work proposes a hierarchical approach with a distributed planner that uses local search with a worst-case performance guarantees and a decentralized controller based on control barrier functions that ensures safety and encourages timely arrival at sensing locations. Via extensive simulations, hardware-in-the-loop tests and hardware experiments, we demonstrate that the proposed approach achieves a better trade-off between sensing and energy cost than coordinate descent based algorithms.
Knowledge-augmented Graph Neural Networks with Concept-aware Attention for Adverse Drug Event Detection
Jan 25, 2023
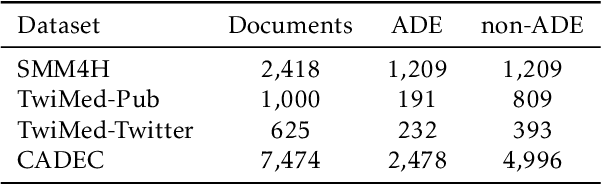
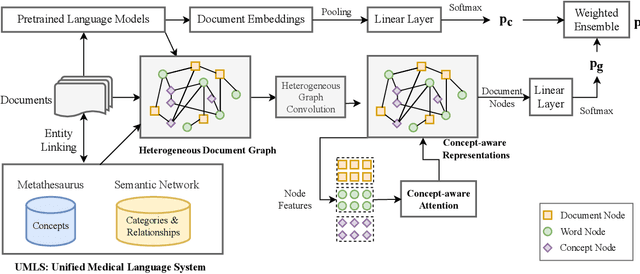
Adverse drug events (ADEs) are an important aspect of drug safety. Various texts such as biomedical literature, drug reviews, and user posts on social media and medical forums contain a wealth of information about ADEs. Recent studies have applied word embedding and deep learning -based natural language processing to automate ADE detection from text. However, they did not explore incorporating explicit medical knowledge about drugs and adverse reactions or the corresponding feature learning. This paper adopts the heterogenous text graph which describes relationships between documents, words and concepts, augments it with medical knowledge from the Unified Medical Language System, and proposes a concept-aware attention mechanism which learns features differently for the different types of nodes in the graph. We further utilize contextualized embeddings from pretrained language models and convolutional graph neural networks for effective feature representation and relational learning. Experiments on four public datasets show that our model achieves performance competitive to the recent advances and the concept-aware attention consistently outperforms other attention mechanisms.
Distributed Control of Partial Differential Equations Using Convolutional Reinforcement Learning
Jan 25, 2023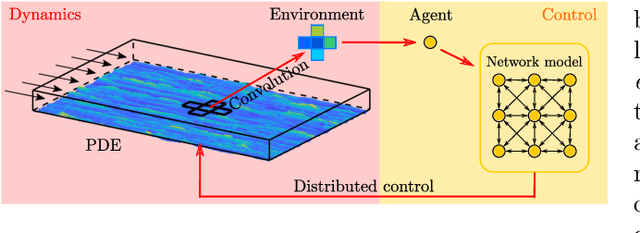

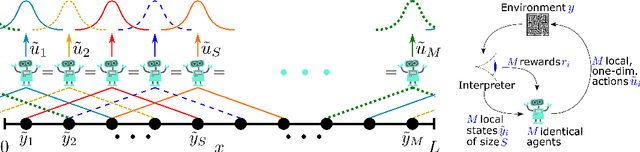
We present a convolutional framework which significantly reduces the complexity and thus, the computational effort for distributed reinforcement learning control of dynamical systems governed by partial differential equations (PDEs). Exploiting translational invariances, the high-dimensional distributed control problem can be transformed into a multi-agent control problem with many identical, uncoupled agents. Furthermore, using the fact that information is transported with finite velocity in many cases, the dimension of the agents' environment can be drastically reduced using a convolution operation over the state space of the PDE. In this setting, the complexity can be flexibly adjusted via the kernel width or by using a stride greater than one. Moreover, scaling from smaller to larger systems -- or the transfer between different domains -- becomes a straightforward task requiring little effort. We demonstrate the performance of the proposed framework using several PDE examples with increasing complexity, where stabilization is achieved by training a low-dimensional deep deterministic policy gradient agent using minimal computing resources.
Optimal and Robust Waveform Design for MIMO-OFDM Channel Sensing: A Cramér-Rao Bound Perspective
Jan 25, 2023
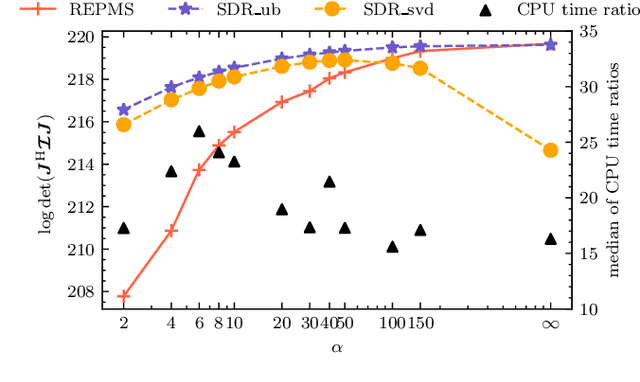
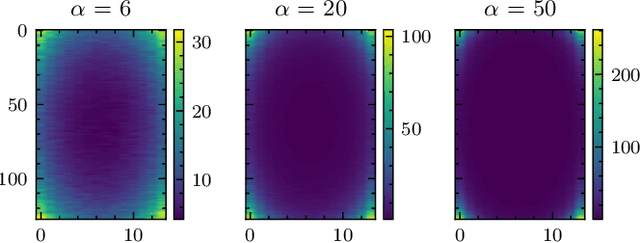
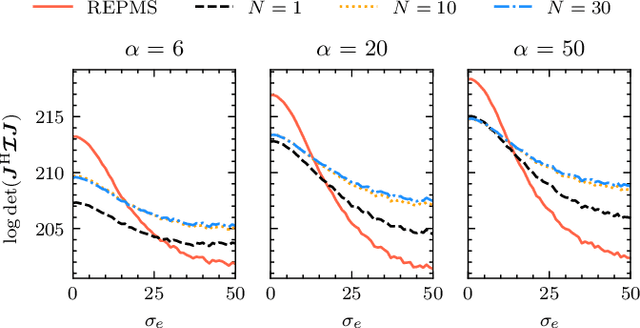
Wireless channel sensing is one of the key enablers for integrated sensing and communication (ISAC) which helps communication networks understand the surrounding environment. In this work, we consider MIMO-OFDM systems and aim to design optimal and robust waveforms for accurate channel parameter estimation given allocated OFDM resources. The Fisher information matrix (FIM) is derived first, and the waveform design problem is formulated by maximizing the log determinant of the FIM. We then consider the uncertainty in the parameters and state the stochastic optimization problem for a robust design. We propose the Riemannian Exact Penalty Method via Smoothing (REPMS) and its stochastic version SREPMS to solve the constrained non-convex problems. In simulations, we show that the REPMS yields comparable results to the semidefinite relaxation (SDR) but with a much shorter running time. Finally, the designed robust waveforms using SREMPS are investigated, and are shown to have a good performance under channel perturbations.
3D Tooth Mesh Segmentation with Simplified Mesh Cell Representation
Jan 25, 2023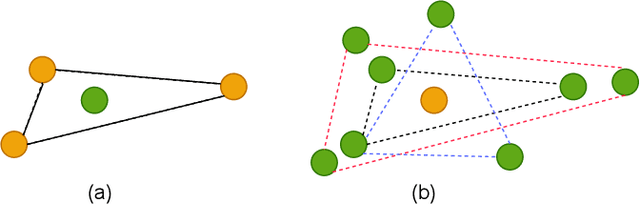
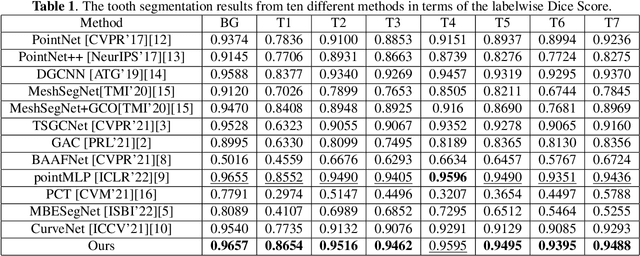
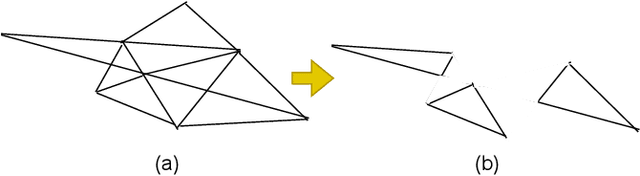
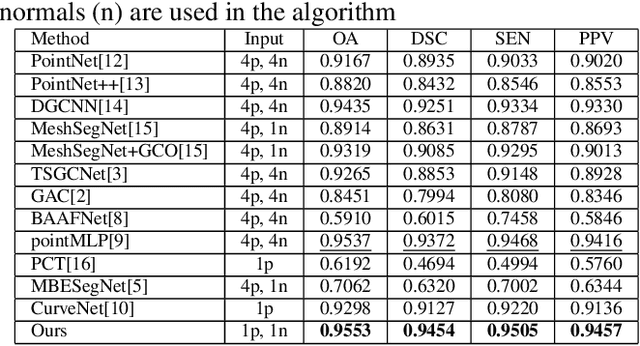
Manual tooth segmentation of 3D tooth meshes is tedious and there is variations among dentists. %Manual tooth annotation of 3D tooth meshes is a tedious task. Several deep learning based methods have been proposed to perform automatic tooth mesh segmentation. Many of the proposed tooth mesh segmentation algorithms summarize the mesh cell as - the cell center or barycenter, the normal at barycenter, the cell vertices and the normals at the cell vertices. Summarizing of the mesh cell/triangle in this manner imposes an implicit structural constraint and makes it difficult to work with multiple resolutions which is done in many point cloud based deep learning algorithms. We propose a novel segmentation method which utilizes only the barycenter and the normal at the barycenter information of the mesh cell and yet achieves competitive performance. We are the first to demonstrate that it is possible to relax the implicit structural constraint and yet achieve superior segmentation performance