 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Mining the Factor Zoo: Estimation of Latent Factor Models with Sufficient Proxies
Jan 03, 2023

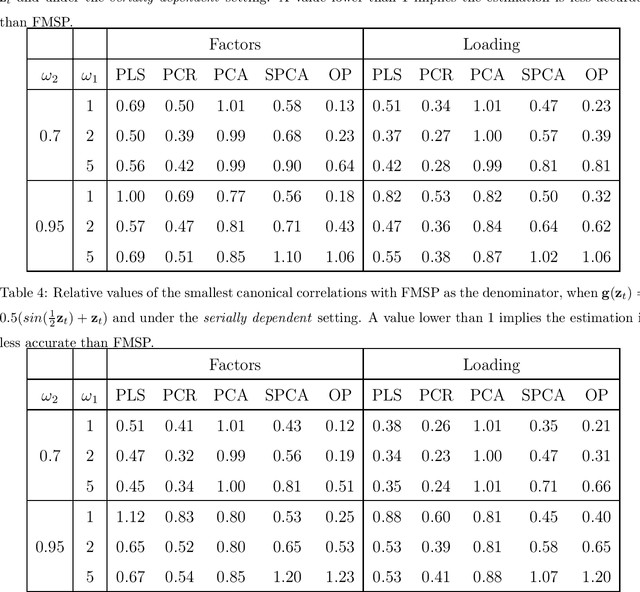
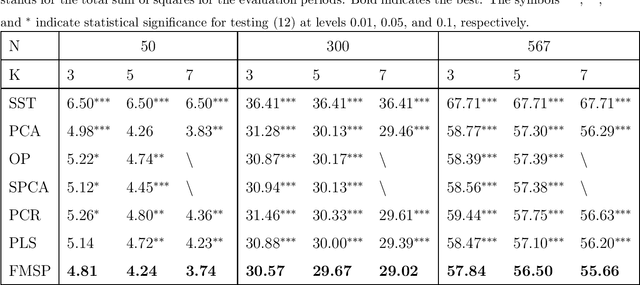
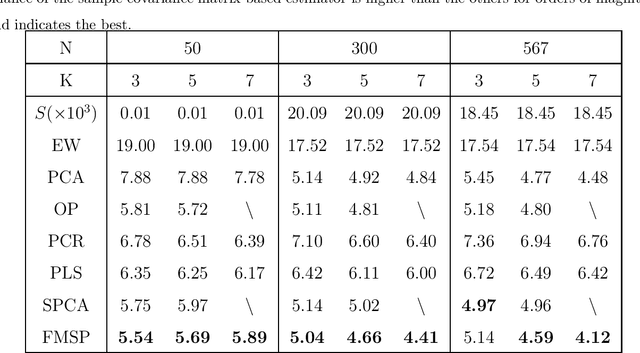
Latent factor model estimation typically relies on either using domain knowledge to manually pick several observed covariates as factor proxies, or purely conducting multivariate analysis such as principal component analysis. However, the former approach may suffer from the bias while the latter can not incorporate additional information. We propose to bridge these two approaches while allowing the number of factor proxies to diverge, and hence make the latent factor model estimation robust, flexible, and statistically more accurate. As a bonus, the number of factors is also allowed to grow. At the heart of our method is a penalized reduced rank regression to combine information. To further deal with heavy-tailed data, a computationally attractive penalized robust reduced rank regression method is proposed. We establish faster rates of convergence compared with the benchmark. Extensive simulations and real examples are used to illustrate the advantages.
IMKGA-SM: Interpretable Multimodal Knowledge Graph Answer Prediction via Sequence Modeling
Jan 11, 2023

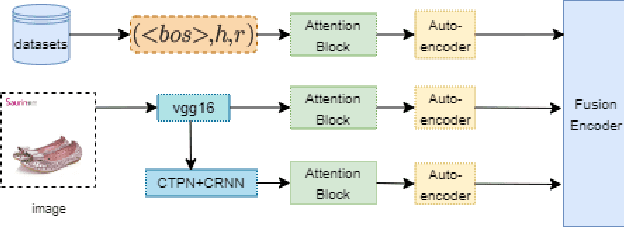

Multimodal knowledge graph link prediction aims to improve the accuracy and efficiency of link prediction tasks for multimodal data. However, for complex multimodal information and sparse training data, it is usually difficult to achieve interpretability and high accuracy simultaneously for most methods. To address this difficulty, a new model is developed in this paper, namely Interpretable Multimodal Knowledge Graph Answer Prediction via Sequence Modeling (IMKGA-SM). First, a multi-modal fine-grained fusion method is proposed, and Vgg16 and Optical Character Recognition (OCR) techniques are adopted to effectively extract text information from images and images. Then, the knowledge graph link prediction task is modelled as an offline reinforcement learning Markov decision model, which is then abstracted into a unified sequence framework. An interactive perception-based reward expectation mechanism and a special causal masking mechanism are designed, which "converts" the query into an inference path. Then, an autoregressive dynamic gradient adjustment mechanism is proposed to alleviate the insufficient problem of multimodal optimization. Finally, two datasets are adopted for experiments, and the popular SOTA baselines are used for comparison. The results show that the developed IMKGA-SM achieves much better performance than SOTA baselines on multimodal link prediction datasets of different sizes.
An Information-Theoretic and Contrastive Learning-based Approach for Identifying Code Statements Causing Software Vulnerability
Sep 20, 2022
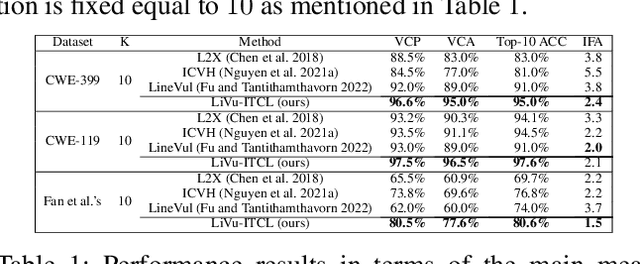
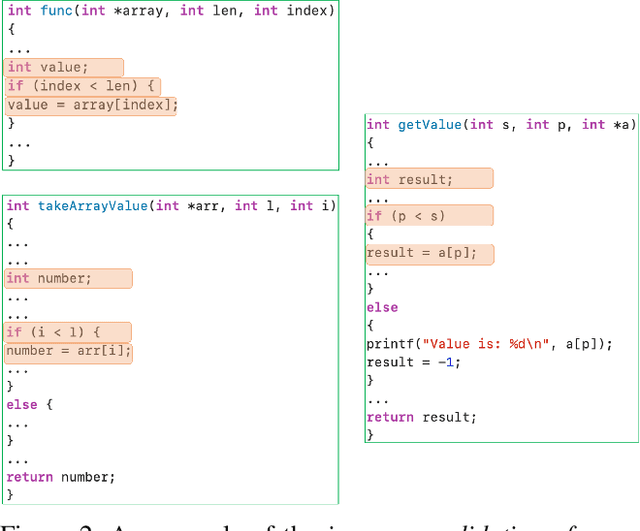
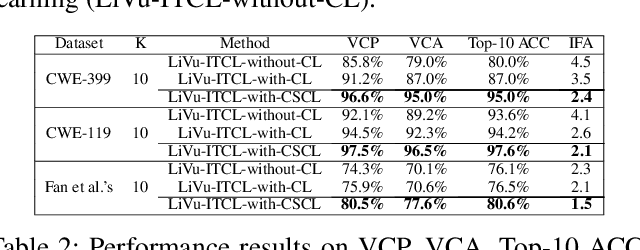
Software vulnerabilities existing in a program or function of computer systems are a serious and crucial concern. Typically, in a program or function consisting of hundreds or thousands of source code statements, there are only few statements causing the corresponding vulnerabilities. Vulnerability labeling is currently done on a function or program level by experts with the assistance of machine learning tools. Extending this approach to the code statement level is much more costly and time-consuming and remains an open problem. In this paper we propose a novel end-to-end deep learning-based approach to identify the vulnerability-relevant code statements of a specific function. Inspired by the specific structures observed in real world vulnerable code, we first leverage mutual information for learning a set of latent variables representing the relevance of the source code statements to the corresponding function's vulnerability. We then propose novel clustered spatial contrastive learning in order to further improve the representation learning and the robust selection process of vulnerability-relevant code statements. Experimental results on real-world datasets of 200k+ C/C++ functions show the superiority of our method over other state-of-the-art baselines. In general, our method obtains a higher performance in VCP, VCA, and Top-10 ACC measures of between 3\% to 14\% over the baselines when running on real-world datasets in an unsupervised setting. Our released source code samples are publicly available at \href{https://github.com/vannguyennd/livuitcl}{https://github.com/vannguyennd/livuitcl.}
A Watermark for Large Language Models
Jan 24, 2023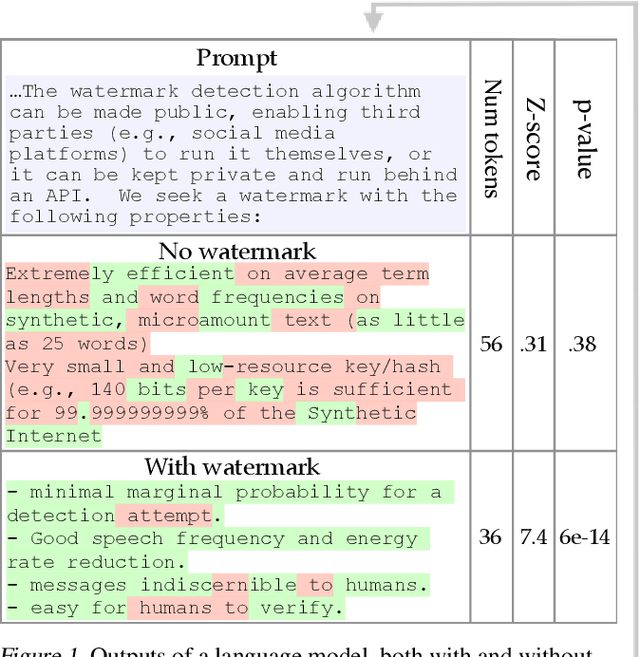
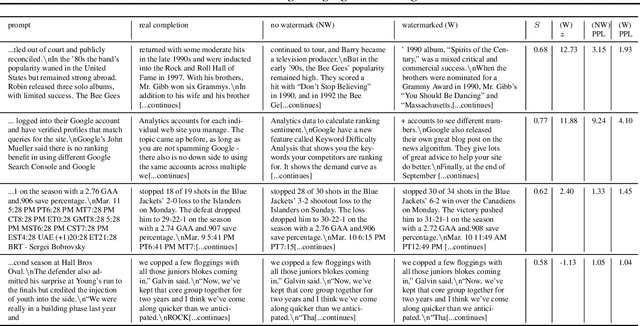
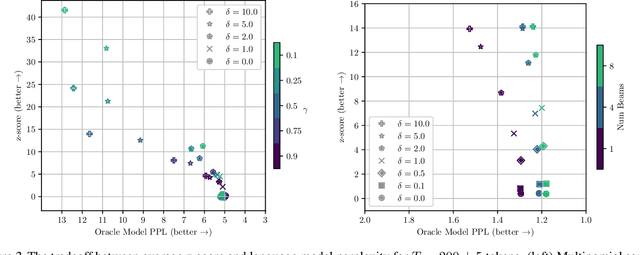
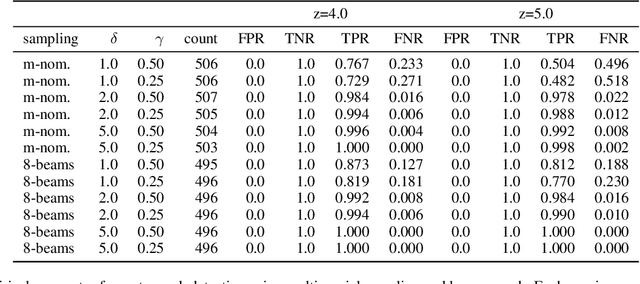
Potential harms of large language models can be mitigated by watermarking model output, i.e., embedding signals into generated text that are invisible to humans but algorithmically detectable from a short span of tokens. We propose a watermarking framework for proprietary language models. The watermark can be embedded with negligible impact on text quality, and can be detected using an efficient open-source algorithm without access to the language model API or parameters. The watermark works by selecting a randomized set of whitelist tokens before a word is generated, and then softly promoting use of whitelist tokens during sampling. We propose a statistical test for detecting the watermark with interpretable p-values, and derive an information-theoretic framework for analyzing the sensitivity of the watermark. We test the watermark using a multi-billion parameter model from the Open Pretrained Transformer (OPT) family, and discuss robustness and security.
Semi-Automated Construction of Food Composition Knowledge Base
Jan 24, 2023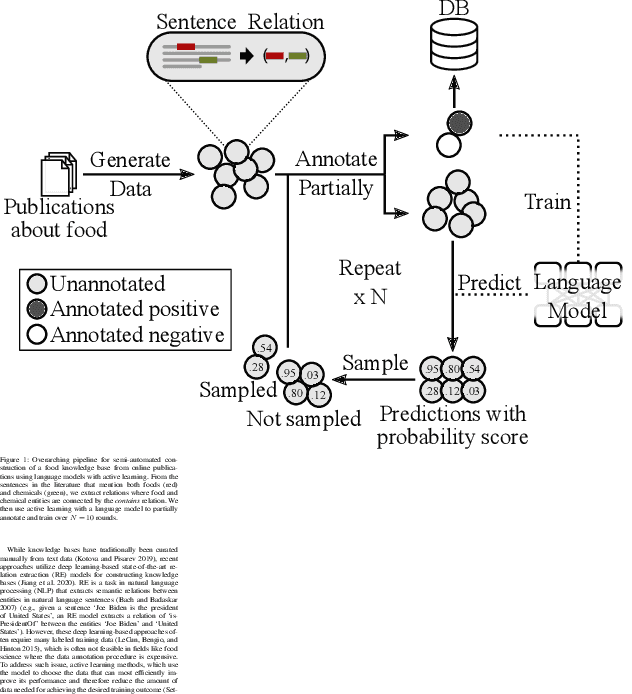
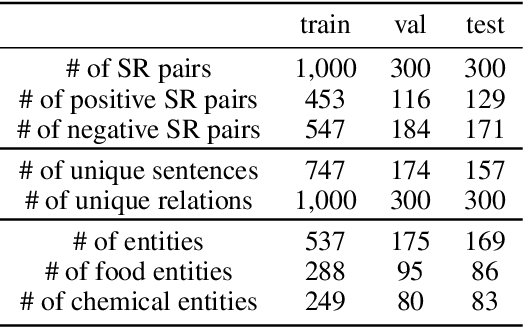
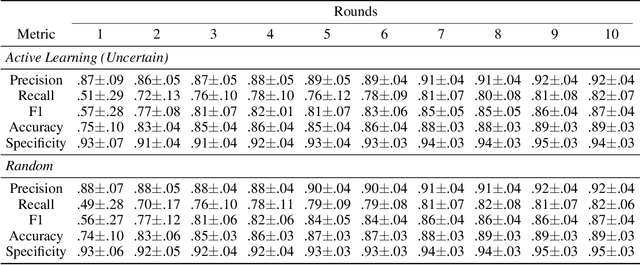
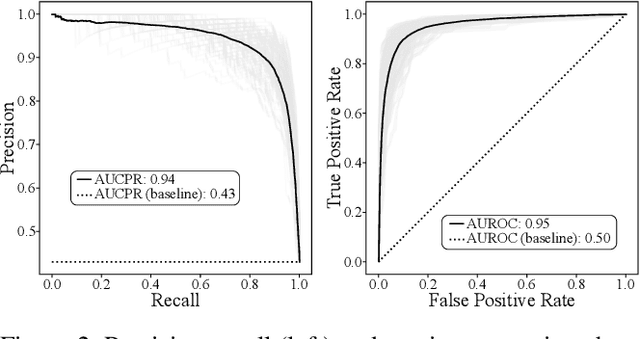
A food composition knowledge base, which stores the essential phyto-, micro-, and macro-nutrients of foods is useful for both research and industrial applications. Although many existing knowledge bases attempt to curate such information, they are often limited by time-consuming manual curation processes. Outside of the food science domain, natural language processing methods that utilize pre-trained language models have recently shown promising results for extracting knowledge from unstructured text. In this work, we propose a semi-automated framework for constructing a knowledge base of food composition from the scientific literature available online. To this end, we utilize a pre-trained BioBERT language model in an active learning setup that allows the optimal use of limited training data. Our work demonstrates how human-in-the-loop models are a step toward AI-assisted food systems that scale well to the ever-increasing big data.
Breaking the Curse of Multiagents in a Large State Space: RL in Markov Games with Independent Linear Function Approximation
Feb 07, 2023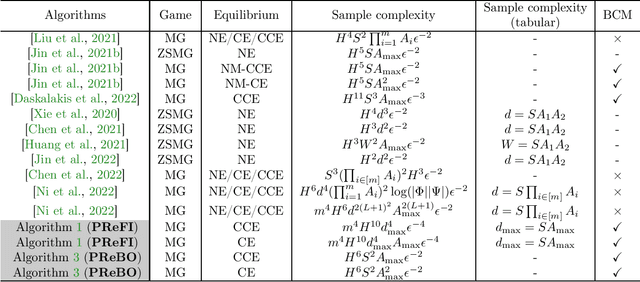
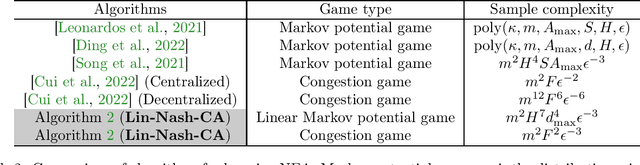
We propose a new model, independent linear Markov game, for multi-agent reinforcement learning with a large state space and a large number of agents. This is a class of Markov games with independent linear function approximation, where each agent has its own function approximation for the state-action value functions that are marginalized by other players' policies. We design new algorithms for learning the Markov coarse correlated equilibria (CCE) and Markov correlated equilibria (CE) with sample complexity bounds that only scale polynomially with each agent's own function class complexity, thus breaking the curse of multiagents. In contrast, existing works for Markov games with function approximation have sample complexity bounds scale with the size of the \emph{joint action space} when specialized to the canonical tabular Markov game setting, which is exponentially large in the number of agents. Our algorithms rely on two key technical innovations: (1) utilizing policy replay to tackle non-stationarity incurred by multiple agents and the use of function approximation; (2) separating learning Markov equilibria and exploration in the Markov games, which allows us to use the full-information no-regret learning oracle instead of the stronger bandit-feedback no-regret learning oracle used in the tabular setting. Furthermore, we propose an iterative-best-response type algorithm that can learn pure Markov Nash equilibria in independent linear Markov potential games. In the tabular case, by adapting the policy replay mechanism for independent linear Markov games, we propose an algorithm with $\widetilde{O}(\epsilon^{-2})$ sample complexity to learn Markov CCE, which improves the state-of-the-art result $\widetilde{O}(\epsilon^{-3})$ in Daskalakis et al. 2022, where $\epsilon$ is the desired accuracy, and also significantly improves other problem parameters.
Optimization with access to auxiliary information
Jun 01, 2022
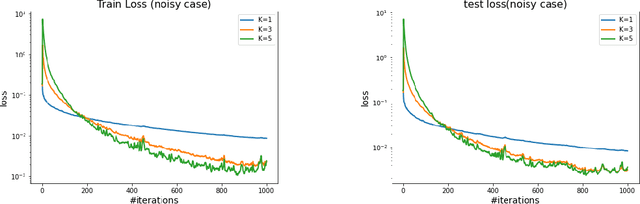
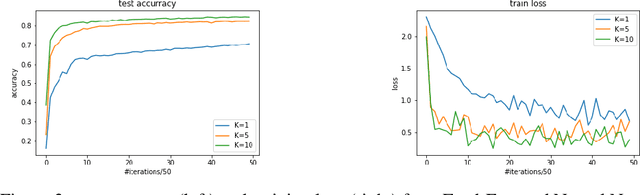
We investigate the fundamental optimization question of minimizing a target function $f(x)$ whose gradients are expensive to compute or have limited availability, given access to some auxiliary side function $h(x)$ whose gradients are cheap or more available. This formulation captures many settings of practical relevance such as i) re-using batches in SGD, ii) transfer learning, iii) federated learning, iv) training with compressed models/dropout, etc. We propose two generic new algorithms which are applicable in all these settings and prove using only an assumption on the Hessian similarity between the target and side information that we can benefit from this framework.
Knowledge-augmented Graph Neural Networks with Concept-aware Attention for Adverse Drug Event Detection
Jan 25, 2023
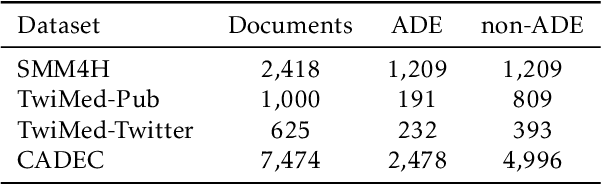
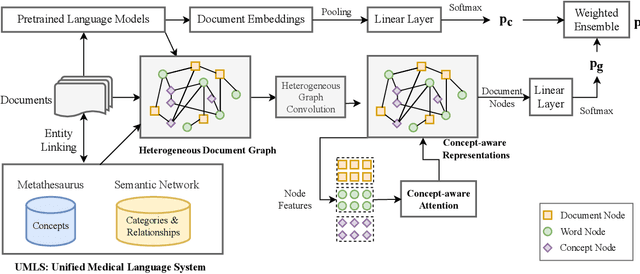
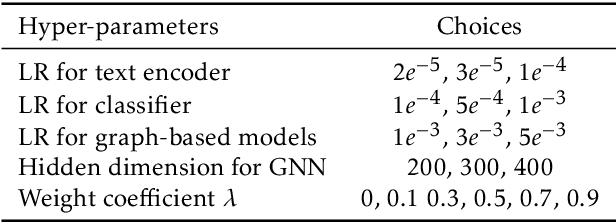
Adverse drug events (ADEs) are an important aspect of drug safety. Various texts such as biomedical literature, drug reviews, and user posts on social media and medical forums contain a wealth of information about ADEs. Recent studies have applied word embedding and deep learning -based natural language processing to automate ADE detection from text. However, they did not explore incorporating explicit medical knowledge about drugs and adverse reactions or the corresponding feature learning. This paper adopts the heterogenous text graph which describes relationships between documents, words and concepts, augments it with medical knowledge from the Unified Medical Language System, and proposes a concept-aware attention mechanism which learns features differently for the different types of nodes in the graph. We further utilize contextualized embeddings from pretrained language models and convolutional graph neural networks for effective feature representation and relational learning. Experiments on four public datasets show that our model achieves performance competitive to the recent advances and the concept-aware attention consistently outperforms other attention mechanisms.
3D Tooth Mesh Segmentation with Simplified Mesh Cell Representation
Jan 25, 2023
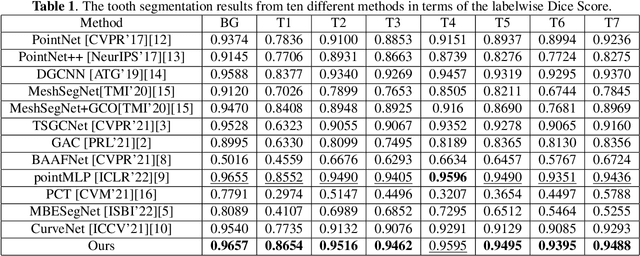
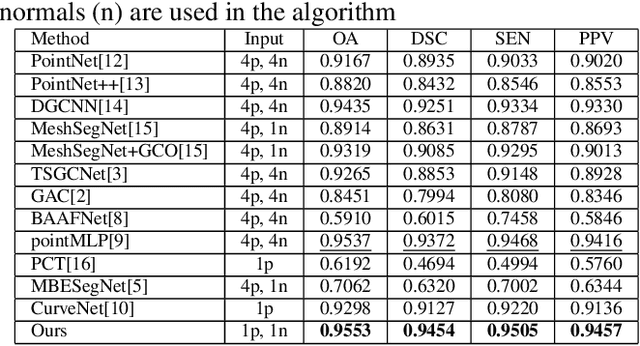
Manual tooth segmentation of 3D tooth meshes is tedious and there is variations among dentists. %Manual tooth annotation of 3D tooth meshes is a tedious task. Several deep learning based methods have been proposed to perform automatic tooth mesh segmentation. Many of the proposed tooth mesh segmentation algorithms summarize the mesh cell as - the cell center or barycenter, the normal at barycenter, the cell vertices and the normals at the cell vertices. Summarizing of the mesh cell/triangle in this manner imposes an implicit structural constraint and makes it difficult to work with multiple resolutions which is done in many point cloud based deep learning algorithms. We propose a novel segmentation method which utilizes only the barycenter and the normal at the barycenter information of the mesh cell and yet achieves competitive performance. We are the first to demonstrate that it is possible to relax the implicit structural constraint and yet achieve superior segmentation performance
Distributed Control of Partial Differential Equations Using Convolutional Reinforcement Learning
Jan 25, 2023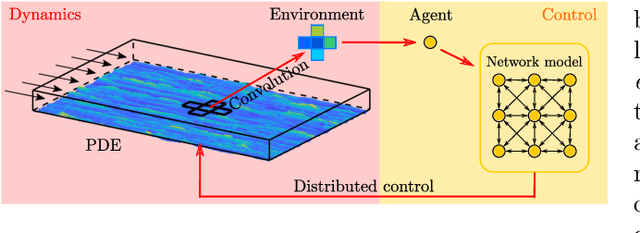

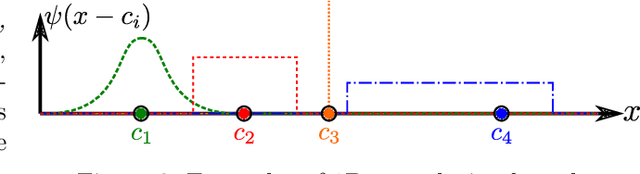
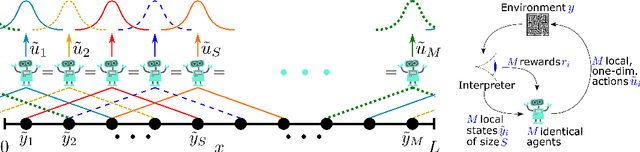
We present a convolutional framework which significantly reduces the complexity and thus, the computational effort for distributed reinforcement learning control of dynamical systems governed by partial differential equations (PDEs). Exploiting translational invariances, the high-dimensional distributed control problem can be transformed into a multi-agent control problem with many identical, uncoupled agents. Furthermore, using the fact that information is transported with finite velocity in many cases, the dimension of the agents' environment can be drastically reduced using a convolution operation over the state space of the PDE. In this setting, the complexity can be flexibly adjusted via the kernel width or by using a stride greater than one. Moreover, scaling from smaller to larger systems -- or the transfer between different domains -- becomes a straightforward task requiring little effort. We demonstrate the performance of the proposed framework using several PDE examples with increasing complexity, where stabilization is achieved by training a low-dimensional deep deterministic policy gradient agent using minimal computing resources.