 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Conversational Automated Program Repair
Jan 30, 2023
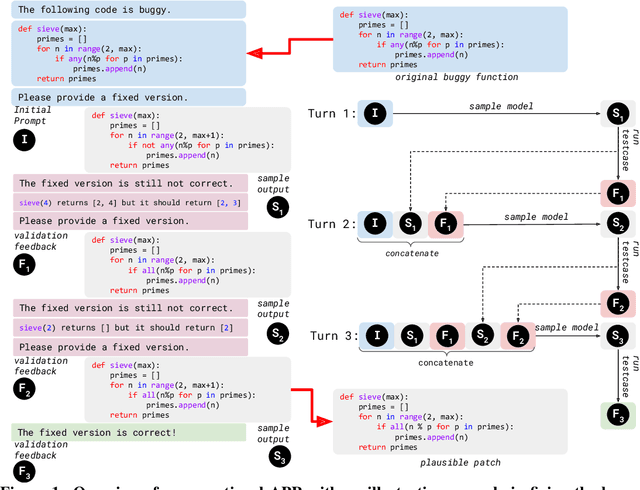

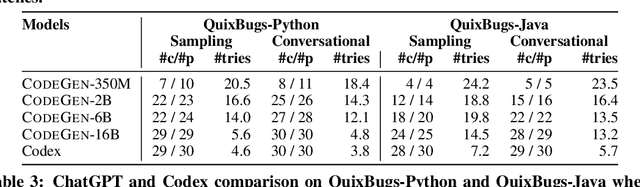

Automated Program Repair (APR) can help developers automatically generate patches for bugs. Due to the impressive performance obtained using Large Pre-Trained Language Models (LLMs) on many code related tasks, researchers have started to directly use LLMs for APR. However, prior approaches simply repeatedly sample the LLM given the same constructed input/prompt created from the original buggy code, which not only leads to generating the same incorrect patches repeatedly but also miss the critical information in testcases. To address these limitations, we propose conversational APR, a new paradigm for program repair that alternates between patch generation and validation in a conversational manner. In conversational APR, we iteratively build the input to the model by combining previously generated patches with validation feedback. As such, we leverage the long-term context window of LLMs to not only avoid generating previously incorrect patches but also incorporate validation feedback to help the model understand the semantic meaning of the program under test. We evaluate 10 different LLM including the newly developed ChatGPT model to demonstrate the improvement of conversational APR over the prior LLM for APR approach.
Are Random Decompositions all we need in High Dimensional Bayesian Optimisation?
Jan 30, 2023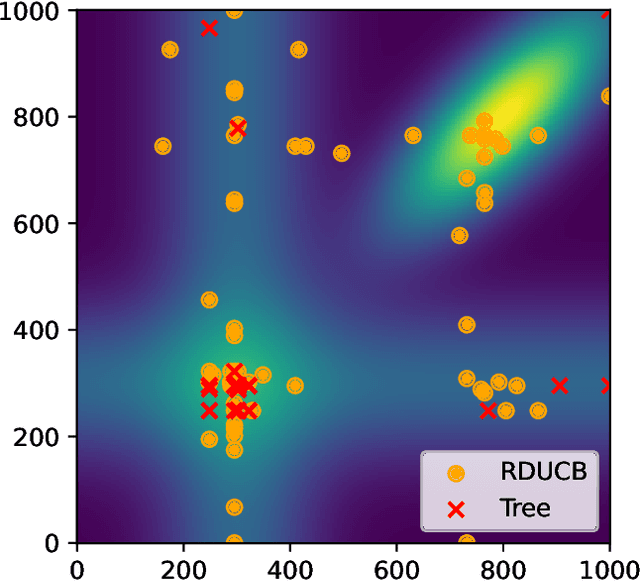
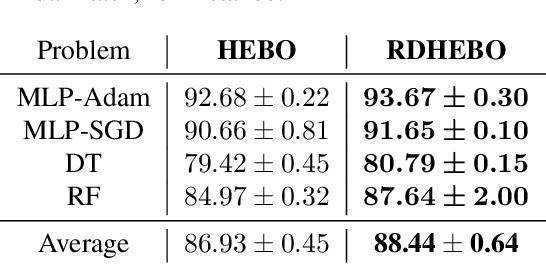
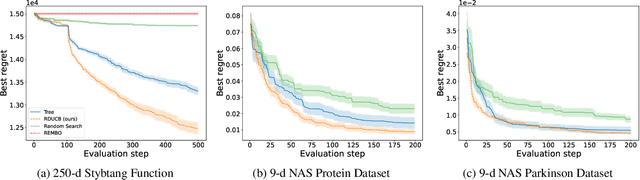

Learning decompositions of expensive-to-evaluate black-box functions promises to scale Bayesian optimisation (BO) to high-dimensional problems. However, the success of these techniques depends on finding proper decompositions that accurately represent the black-box. While previous works learn those decompositions based on data, we investigate data-independent decomposition sampling rules in this paper. We find that data-driven learners of decompositions can be easily misled towards local decompositions that do not hold globally across the search space. Then, we formally show that a random tree-based decomposition sampler exhibits favourable theoretical guarantees that effectively trade off maximal information gain and functional mismatch between the actual black-box and its surrogate as provided by the decomposition. Those results motivate the development of the random decomposition upper-confidence bound algorithm (RDUCB) that is straightforward to implement - (almost) plug-and-play - and, surprisingly, yields significant empirical gains compared to the previous state-of-the-art on a comprehensive set of benchmarks. We also confirm the plug-and-play nature of our modelling component by integrating our method with HEBO, showing improved practical gains in the highest dimensional tasks from Bayesmark.
How Far Can It Go?: On Intrinsic Gender Bias Mitigation for Text Classification
Jan 30, 2023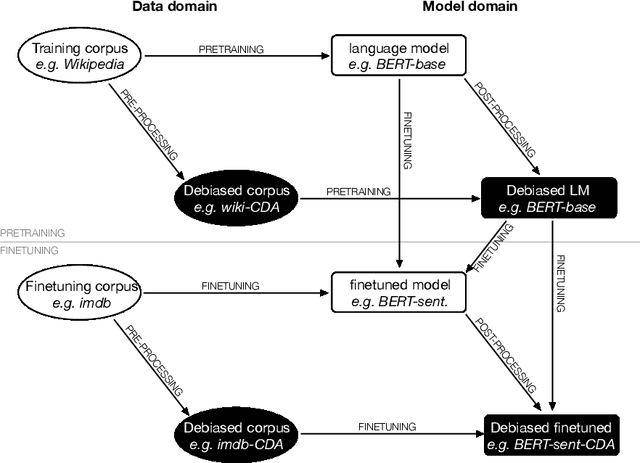

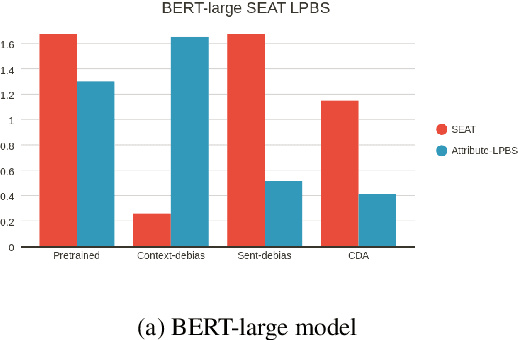
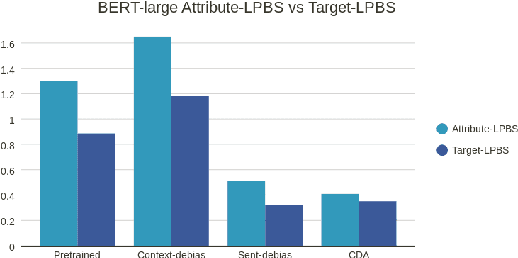
To mitigate gender bias in contextualized language models, different intrinsic mitigation strategies have been proposed, alongside many bias metrics. Considering that the end use of these language models is for downstream tasks like text classification, it is important to understand how these intrinsic bias mitigation strategies actually translate to fairness in downstream tasks and the extent of this. In this work, we design a probe to investigate the effects that some of the major intrinsic gender bias mitigation strategies have on downstream text classification tasks. We discover that instead of resolving gender bias, intrinsic mitigation techniques and metrics are able to hide it in such a way that significant gender information is retained in the embeddings. Furthermore, we show that each mitigation technique is able to hide the bias from some of the intrinsic bias measures but not all, and each intrinsic bias measure can be fooled by some mitigation techniques, but not all. We confirm experimentally, that none of the intrinsic mitigation techniques used without any other fairness intervention is able to consistently impact extrinsic bias. We recommend that intrinsic bias mitigation techniques should be combined with other fairness interventions for downstream tasks.
Preserving Fine-Grain Feature Information in Classification via Entropic Regularization
Aug 07, 2022
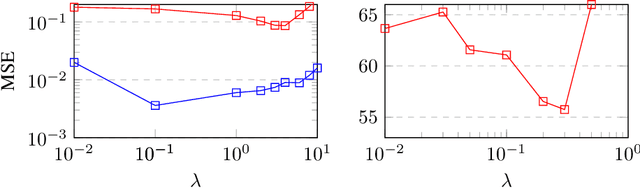

Labeling a classification dataset implies to define classes and associated coarse labels, that may approximate a smoother and more complicated ground truth. For example, natural images may contain multiple objects, only one of which is labeled in many vision datasets, or classes may result from the discretization of a regression problem. Using cross-entropy to train classification models on such coarse labels is likely to roughly cut through the feature space, potentially disregarding the most meaningful such features, in particular losing information on the underlying fine-grain task. In this paper we are interested in the problem of solving fine-grain classification or regression, using a model trained on coarse-grain labels only. We show that standard cross-entropy can lead to overfitting to coarse-related features. We introduce an entropy-based regularization to promote more diversity in the feature space of trained models, and empirically demonstrate the efficacy of this methodology to reach better performance on the fine-grain problems. Our results are supported through theoretical developments and empirical validation.
ZegOT: Zero-shot Segmentation Through Optimal Transport of Text Prompts
Jan 28, 2023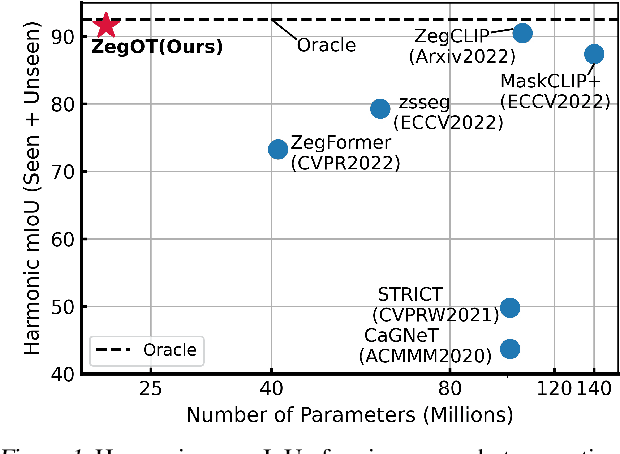
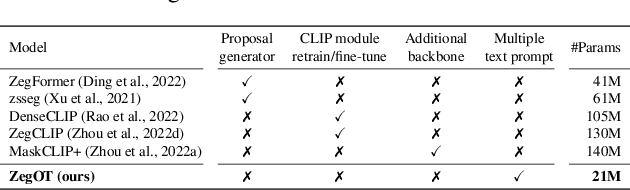
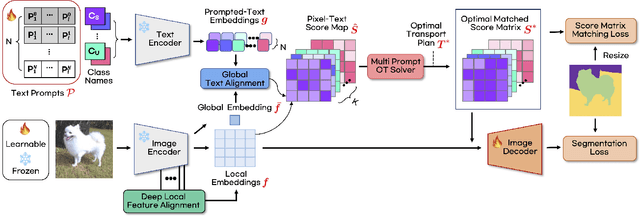
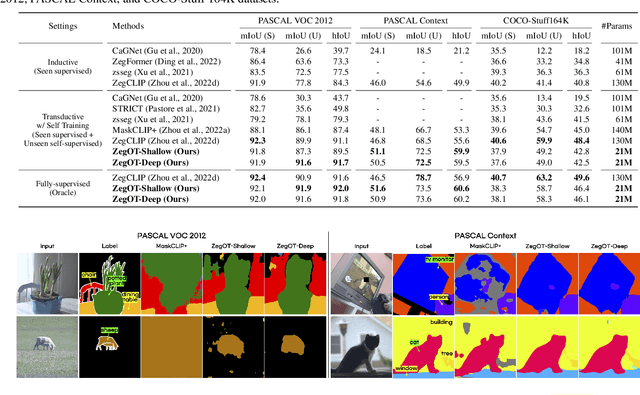
Recent success of large-scale Contrastive Language-Image Pre-training (CLIP) has led to great promise in zero-shot semantic segmentation by transferring image-text aligned knowledge to pixel-level classification. However, existing methods usually require an additional image encoder or retraining/tuning the CLIP module. Here, we present a cost-effective strategy using text-prompt learning that keeps the entire CLIP module frozen while fully leveraging its rich information. Specifically, we propose a novel Zero-shot segmentation with Optimal Transport (ZegOT) method that matches multiple text prompts with frozen image embeddings through optimal transport, which allows each text prompt to efficiently focus on specific semantic attributes. Additionally, we propose Deep Local Feature Alignment (DLFA) that deeply aligns the text prompts with intermediate local feature of the frozen image encoder layers, which significantly boosts the zero-shot segmentation performance. Through extensive experiments on benchmark datasets, we show that our method achieves the state-of-the-art (SOTA) performance with only x7 lighter parameters compared to previous SOTA approaches.
What Decreases Editing Capability? Domain-Specific Hybrid Refinement for Improved GAN Inversion
Jan 28, 2023
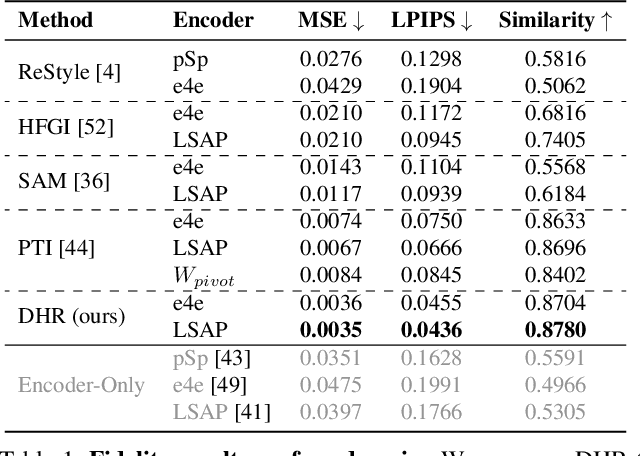
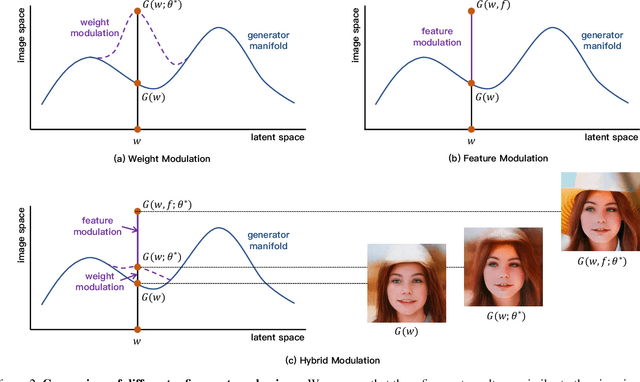
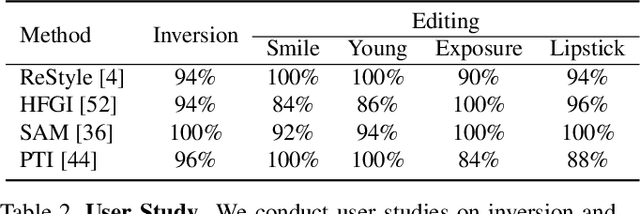
Recently, inversion methods have focused on additional high-rate information in the generator (e.g., weights or intermediate features) to refine inversion and editing results from embedded latent codes. Although these techniques gain reasonable improvement in reconstruction, they decrease editing capability, especially on complex images (e.g., containing occlusions, detailed backgrounds, and artifacts). A vital crux is refining inversion results, avoiding editing capability degradation. To tackle this problem, we introduce Domain-Specific Hybrid Refinement (DHR), which draws on the advantages and disadvantages of two mainstream refinement techniques to maintain editing ability with fidelity improvement. Specifically, we first propose Domain-Specific Segmentation to segment images into two parts: in-domain and out-of-domain parts. The refinement process aims to maintain the editability for in-domain areas and improve two domains' fidelity. We refine these two parts by weight modulation and feature modulation, which we call Hybrid Modulation Refinement. Our proposed method is compatible with all latent code embedding methods. Extension experiments demonstrate that our approach achieves state-of-the-art in real image inversion and editing. Code is available at https://github.com/caopulan/Domain-Specific_Hybrid_Refinement_Inversion.
State Machine-based Waveforms for Channels With 1-Bit Quantization and Oversampling With Time-Instance Zero-Crossing Modulation
Jan 28, 2023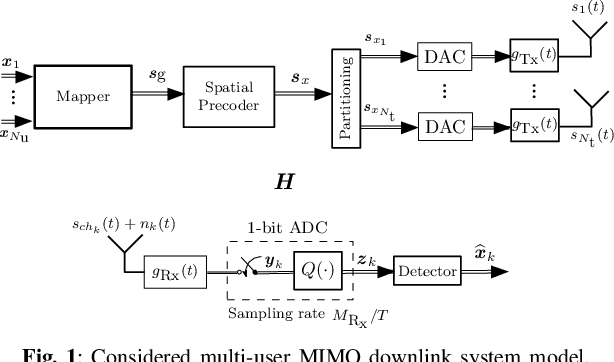
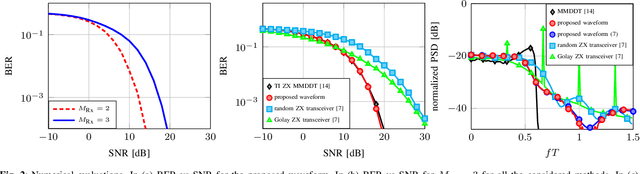
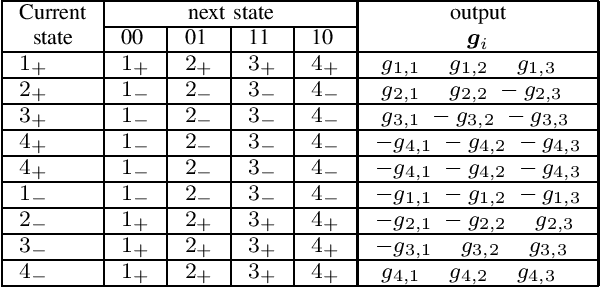

Systems with 1-bit quantization and oversampling are promising for the Internet of Things (IoT) devices in order to reduce the power consumption of the analog-to-digital-converters. The novel time-instance zero-crossing (TI ZX) modulation is a promising approach for this kind of channels but existing studies rely on optimization problems with high computational complexity and delay. In this work, we propose a practical waveform design based on the established TI ZX modulation for a multiuser multi-input multi-output (MIMO) downlink scenario with 1-bit quantization and temporal oversampling at the receivers. In this sense, the proposed temporal transmit signals are constructed by concatenating segments of coefficients which convey the information into the time-instances of zero-crossings according to the TI ZX mapping rules. The proposed waveform design is compared with other methods from the literature. The methods are compared in terms of bit error rate and normalized power spectral density. Numerical results show that the proposed technique is suitable for multiuser MIMO system with 1-bit quantization while tolerating some small amount of out-of-band radiation.
RWEN-TTS: Relation-aware Word Encoding Network for Natural Text-to-Speech Synthesis
Dec 15, 2022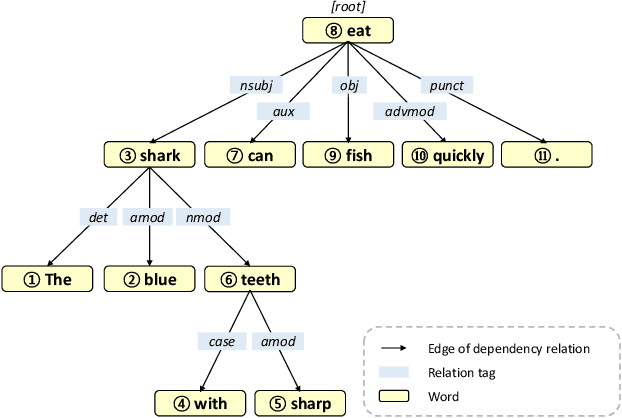

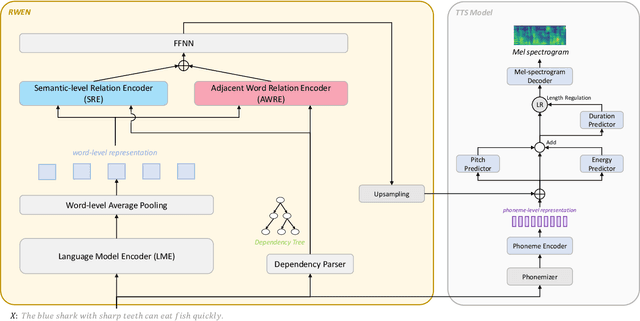

With the advent of deep learning, a huge number of text-to-speech (TTS) models which produce human-like speech have emerged. Recently, by introducing syntactic and semantic information w.r.t the input text, various approaches have been proposed to enrich the naturalness and expressiveness of TTS models. Although these strategies showed impressive results, they still have some limitations in utilizing language information. First, most approaches only use graph networks to utilize syntactic and semantic information without considering linguistic features. Second, most previous works do not explicitly consider adjacent words when encoding syntactic and semantic information, even though it is obvious that adjacent words are usually meaningful when encoding the current word. To address these issues, we propose Relation-aware Word Encoding Network (RWEN), which effectively allows syntactic and semantic information based on two modules (i.e., Semantic-level Relation Encoding and Adjacent Word Relation Encoding). Experimental results show substantial improvements compared to previous works.
Countering Malicious Content Moderation Evasion in Online Social Networks: Simulation and Detection of Word Camouflage
Dec 27, 2022
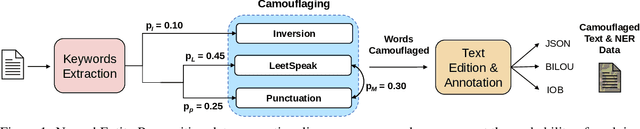
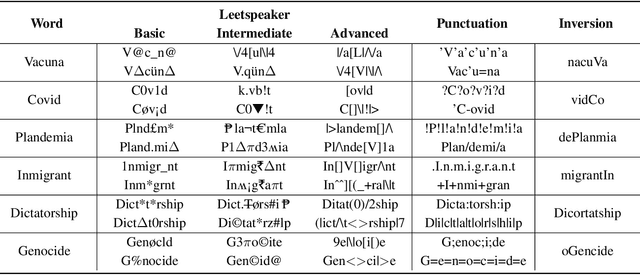
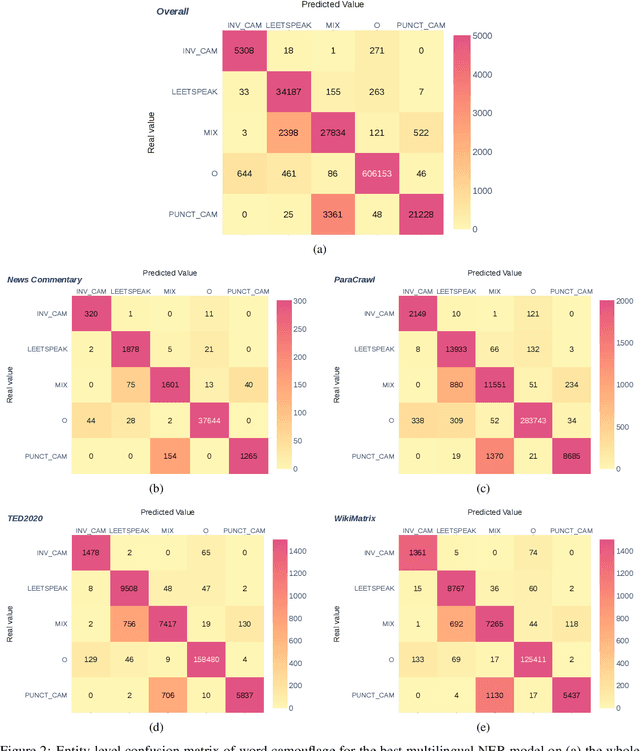
Content moderation is the process of screening and monitoring user-generated content online. It plays a crucial role in stopping content resulting from unacceptable behaviors such as hate speech, harassment, violence against specific groups, terrorism, racism, xenophobia, homophobia, or misogyny, to mention some few, in Online Social Platforms. These platforms make use of a plethora of tools to detect and manage malicious information; however, malicious actors also improve their skills, developing strategies to surpass these barriers and continuing to spread misleading information. Twisting and camouflaging keywords are among the most used techniques to evade platform content moderation systems. In response to this recent ongoing issue, this paper presents an innovative approach to address this linguistic trend in social networks through the simulation of different content evasion techniques and a multilingual Transformer model for content evasion detection. In this way, we share with the rest of the scientific community a multilingual public tool, named "pyleetspeak" to generate/simulate in a customizable way the phenomenon of content evasion through automatic word camouflage and a multilingual Named-Entity Recognition (NER) Transformer-based model tuned for its recognition and detection. The multilingual NER model is evaluated in different textual scenarios, detecting different types and mixtures of camouflage techniques, achieving an overall weighted F1 score of 0.8795. This article contributes significantly to countering malicious information by developing multilingual tools to simulate and detect new methods of evasion of content on social networks, making the fight against information disorders more effective.
Point Cloud-based Proactive Link Quality Prediction for Millimeter-wave Communications
Jan 02, 2023
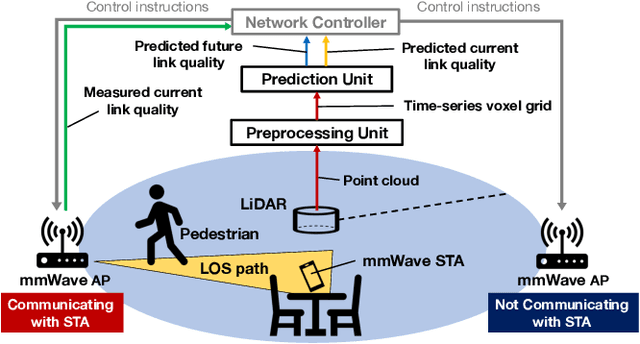
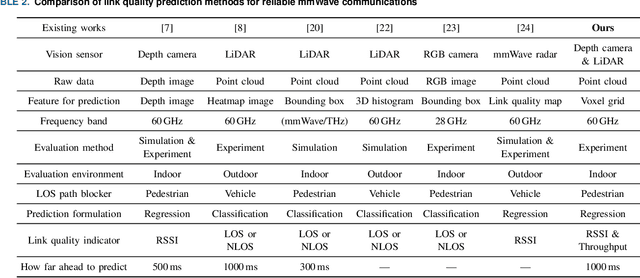
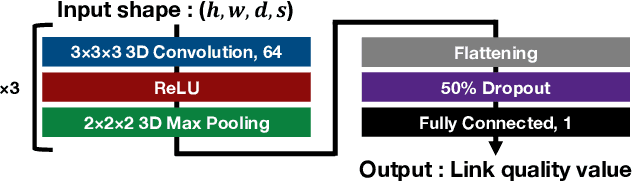
This study demonstrates the feasibility of point cloud-based proactive link quality prediction for millimeter-wave (mmWave) communications. Image-based methods to quantitatively and deterministically predict future received signal strength using machine learning from time series of depth images to mitigate the human body line-of-sight (LOS) path blockage in mmWave communications have been proposed. However, image-based methods have been limited in applicable environments because camera images may contain private information. Thus, this study demonstrates the feasibility of using point clouds obtained from light detection and ranging (LiDAR) for the mmWave link quality prediction. Point clouds represent three-dimensional (3D) spaces as a set of points and are sparser and less likely to contain sensitive information than camera images. Additionally, point clouds provide 3D position and motion information, which is necessary for understanding the radio propagation environment involving pedestrians. This study designs the mmWave link quality prediction method and conducts two experimental evaluations using different types of point clouds obtained from LiDAR and depth cameras, as well as different numerical indicators of link quality, received signal strength and throughput. Based on these experiments, our proposed method can predict future large attenuation of mmWave link quality due to LOS blockage by human bodies, therefore our point cloud-based method can be an alternative to image-based methods.