 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
In Search of Insights, Not Magic Bullets: Towards Demystification of the Model Selection Dilemma in Heterogeneous Treatment Effect Estimation
Feb 06, 2023
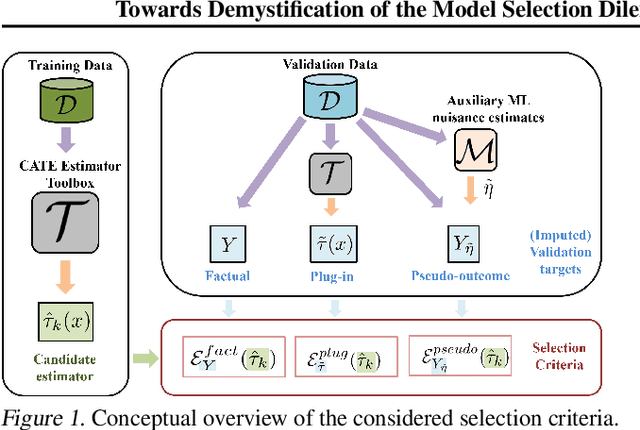
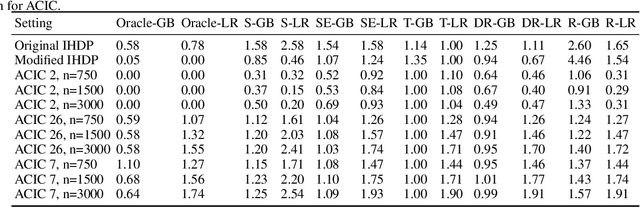

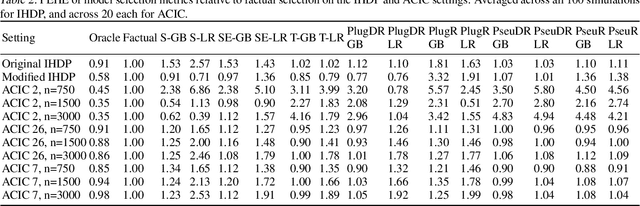
Personalized treatment effect estimates are often of interest in high-stakes applications -- thus, before deploying a model estimating such effects in practice, one needs to be sure that the best candidate from the ever-growing machine learning toolbox for this task was chosen. Unfortunately, due to the absence of counterfactual information in practice, it is usually not possible to rely on standard validation metrics for doing so, leading to a well-known model selection dilemma in the treatment effect estimation literature. While some solutions have recently been investigated, systematic understanding of the strengths and weaknesses of different model selection criteria is still lacking. In this paper, instead of attempting to declare a global `winner', we therefore empirically investigate success- and failure modes of different selection criteria. We highlight that there is a complex interplay between selection strategies, candidate estimators and the DGP used for testing, and provide interesting insights into the relative (dis)advantages of different criteria alongside desiderata for the design of further illuminating empirical studies in this context.
Cross-Fusion Rule for Personalized Federated Learning
Feb 06, 2023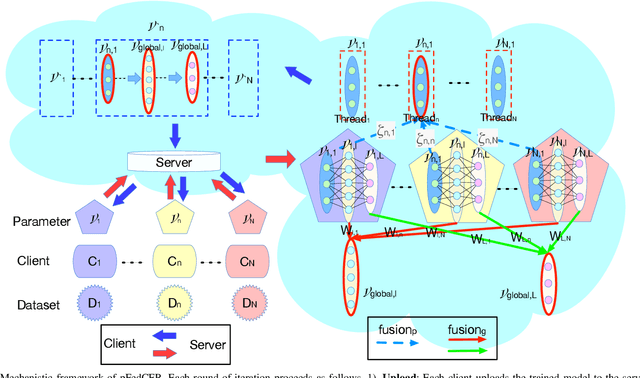
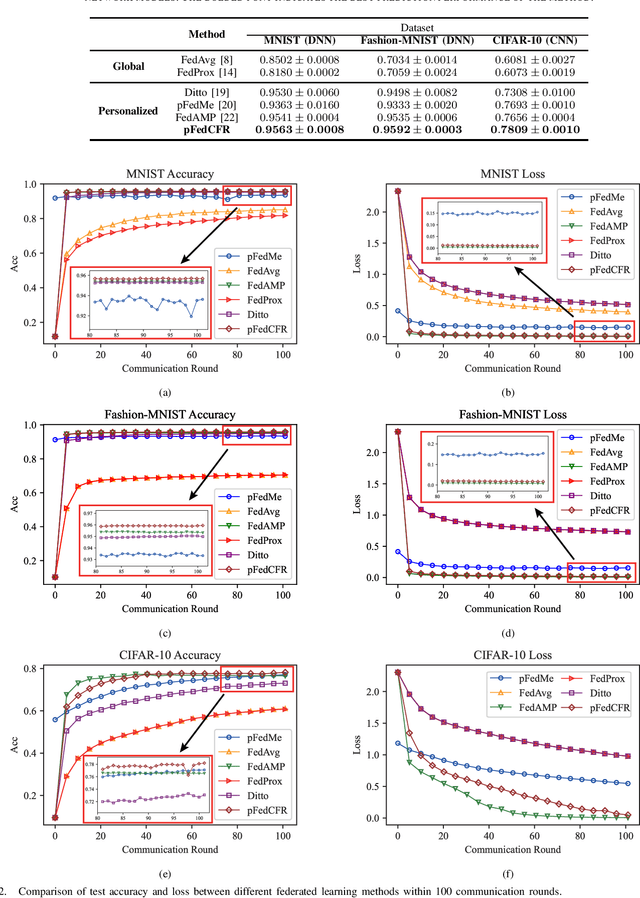
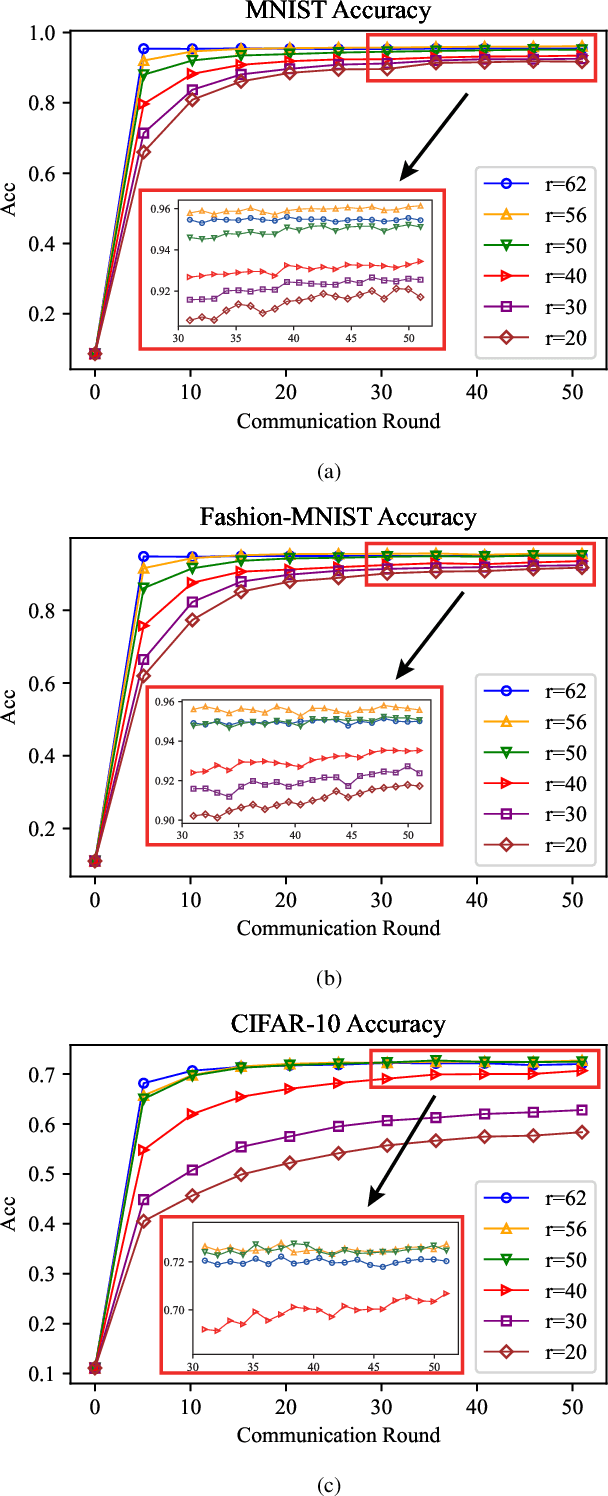

Data scarcity and heterogeneity pose significant performance challenges for personalized federated learning, and these challenges are mainly reflected in overfitting and low precision in existing methods. To overcome these challenges, a multi-layer multi-fusion strategy framework is proposed in this paper, i.e., the server adopts the network layer parameters of each client upload model as the basic unit of fusion for information-sharing calculation. Then, a new fusion strategy combining personalized and generic is purposefully proposed, and the network layer number fusion threshold of each fusion strategy is designed according to the network layer function. Under this mechanism, the L2-Norm negative exponential similarity metric is employed to calculate the fusion weights of the corresponding feature extraction layer parameters for each client, thus improving the efficiency of heterogeneous data personalized collaboration. Meanwhile, the federated global optimal model approximation fusion strategy is adopted in the network full-connect layer, and this generic fusion strategy alleviates the overfitting introduced by forceful personalized. Finally, the experimental results show that the proposed method is superior to the state-of-the-art methods.
How do you go where? Improving next location prediction by learning travel mode information using transformers
Oct 08, 2022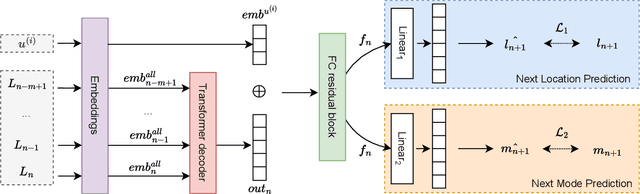
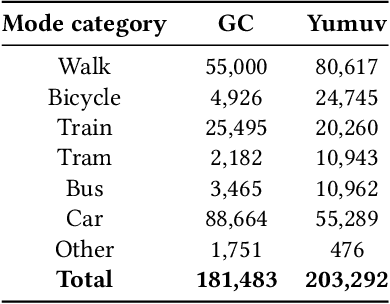
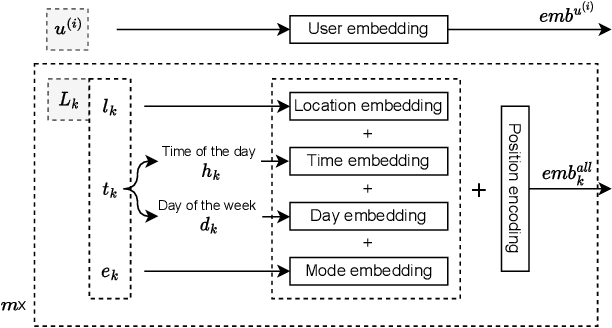
Predicting the next visited location of an individual is a key problem in human mobility analysis, as it is required for the personalization and optimization of sustainable transport options. Here, we propose a transformer decoder-based neural network to predict the next location an individual will visit based on historical locations, time, and travel modes, which are behaviour dimensions often overlooked in previous work. In particular, the prediction of the next travel mode is designed as an auxiliary task to help guide the network's learning. For evaluation, we apply this approach to two large-scale and long-term GPS tracking datasets involving more than 600 individuals. Our experiments show that the proposed method significantly outperforms other state-of-the-art next location prediction methods by a large margin (8.05% and 5.60% relative increase in F1-score for the two datasets, respectively). We conduct an extensive ablation study that quantifies the influence of considering temporal features, travel mode information, and the auxiliary task on the prediction results. Moreover, we experimentally determine the performance upper bound when including the next mode prediction in our model. Finally, our analysis indicates that the performance of location prediction varies significantly with the chosen next travel mode by the individual. These results show potential for a more systematic consideration of additional dimensions of travel behaviour in human mobility prediction tasks. The source code of our model and experiments is available at https://github.com/mie-lab/location-mode-prediction.
Byzantine Resilience at Swarm Scale: A Decentralized Blocklist Protocol from Inter-robot Accusations
Jan 17, 2023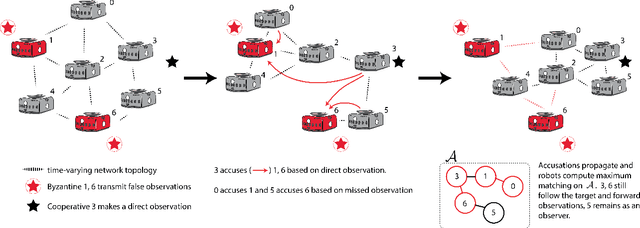
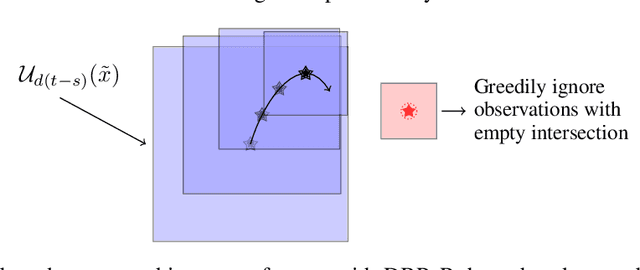
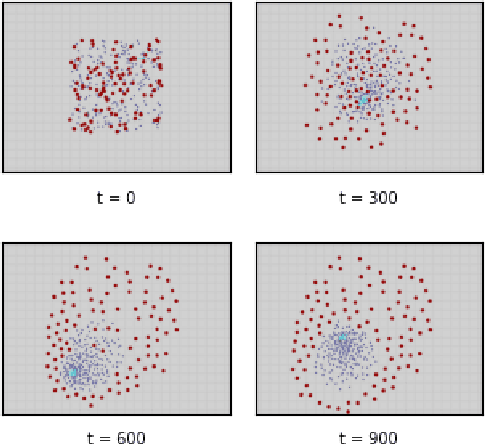
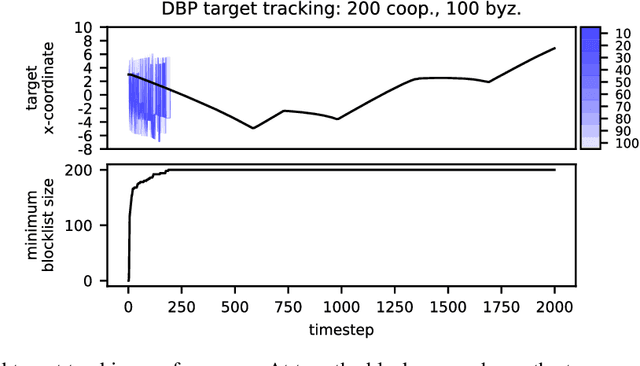
The Weighted-Mean Subsequence Reduced (W-MSR) algorithm, the state-of-the-art method for Byzantine-resilient design of decentralized multi-robot systems, is based on discarding outliers received over Linear Consensus Protocol (LCP). Although W-MSR provides well-understood theoretical guarantees relating robust network connectivity to the convergence of the underlying consensus, the method comes with several limitations preventing its use at scale: (1) the number of Byzantine robots, F, to tolerate should be known a priori, (2) the requirement that each robot maintains 2F+1 neighbors is impractical for large F, (3) information propagation is hindered by the requirement that F+1 robots independently make local measurements of the consensus property in order for the swarm's decision to change, and (4) W-MSR is specific to LCP and does not generalize to applications not implemented over LCP. In this work, we propose a Decentralized Blocklist Protocol (DBP) based on inter-robot accusations. Accusations are made on the basis of locally-made observations of misbehavior, and once shared by cooperative robots across the network are used as input to a graph matching algorithm that computes a blocklist. DBP generalizes to applications not implemented via LCP, is adaptive to the number of Byzantine robots, and allows for fast information propagation through the multi-robot system while simultaneously reducing the required network connectivity relative to W-MSR. On LCP-type applications, DBP reduces the worst-case connectivity requirement of W-MSR from (2F+1)-connected to (F+1)-connected and the number of cooperative observers required to propagate new information from F+1 to just 1 observer. We demonstrate empirically that our approach to Byzantine resilience scales to hundreds of robots on cooperative target tracking, time synchronization, and localization case studies.
Minimalistic Predictions to Schedule Jobs with Online Precedence Constraints
Jan 30, 2023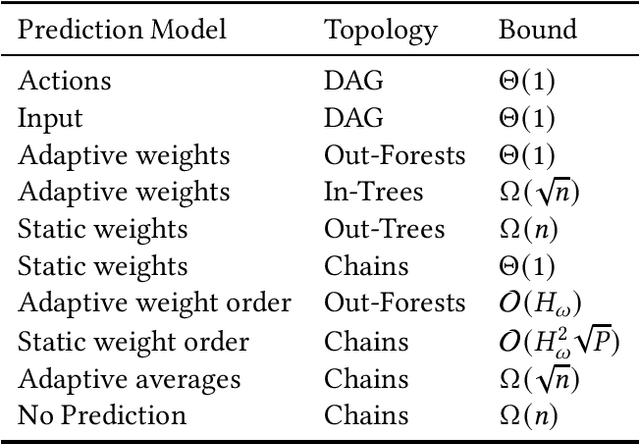
We consider non-clairvoyant scheduling with online precedence constraints, where an algorithm is oblivious to any job dependencies and learns about a job only if all of its predecessors have been completed. Given strong impossibility results in classical competitive analysis, we investigate the problem in a learning-augmented setting, where an algorithm has access to predictions without any quality guarantee. We discuss different prediction models: novel problem-specific models as well as general ones, which have been proposed in previous works. We present lower bounds and algorithmic upper bounds for different precedence topologies, and thereby give a structured overview on which and how additional (possibly erroneous) information helps for designing better algorithms. Along the way, we also improve bounds on traditional competitive ratios for existing algorithms.
Fast-MC-PET: A Novel Deep Learning-aided Motion Correction and Reconstruction Framework for Accelerated PET
Feb 14, 2023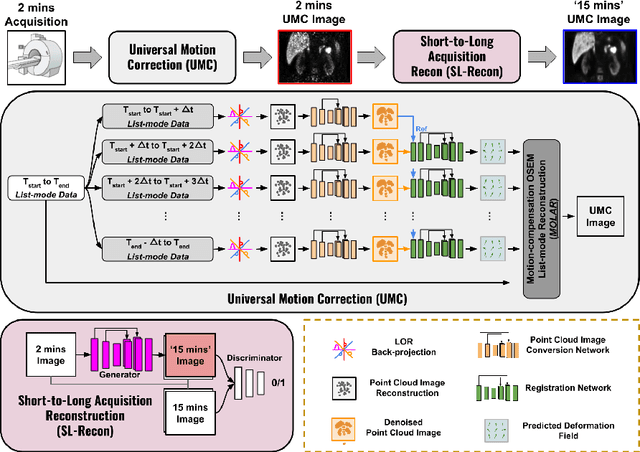
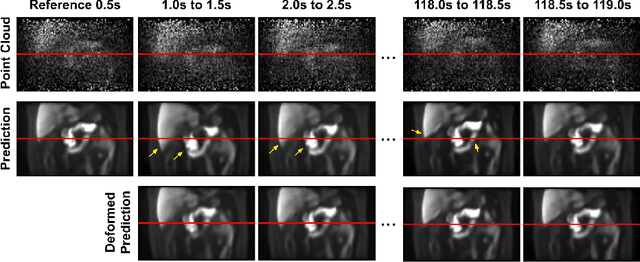

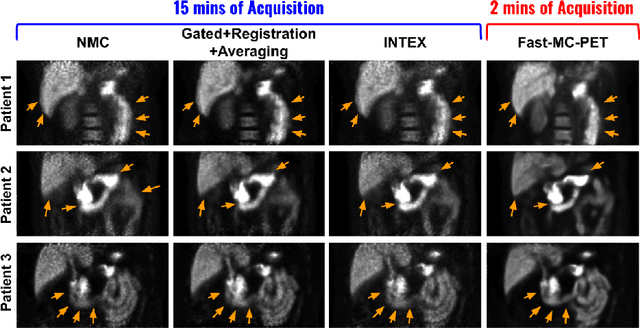
Patient motion during PET is inevitable. Its long acquisition time not only increases the motion and the associated artifacts but also the patient's discomfort, thus PET acceleration is desirable. However, accelerating PET acquisition will result in reconstructed images with low SNR, and the image quality will still be degraded by motion-induced artifacts. Most of the previous PET motion correction methods are motion type specific that require motion modeling, thus may fail when multiple types of motion present together. Also, those methods are customized for standard long acquisition and could not be directly applied to accelerated PET. To this end, modeling-free universal motion correction reconstruction for accelerated PET is still highly under-explored. In this work, we propose a novel deep learning-aided motion correction and reconstruction framework for accelerated PET, called Fast-MC-PET. Our framework consists of a universal motion correction (UMC) and a short-to-long acquisition reconstruction (SL-Reon) module. The UMC enables modeling-free motion correction by estimating quasi-continuous motion from ultra-short frame reconstructions and using this information for motion-compensated reconstruction. Then, the SL-Recon converts the accelerated UMC image with low counts to a high-quality image with high counts for our final reconstruction output. Our experimental results on human studies show that our Fast-MC-PET can enable 7-fold acceleration and use only 2 minutes acquisition to generate high-quality reconstruction images that outperform/match previous motion correction reconstruction methods using standard 15 minutes long acquisition data.
SMART: Self-supervised Multi-task pretrAining with contRol Transformers
Jan 24, 2023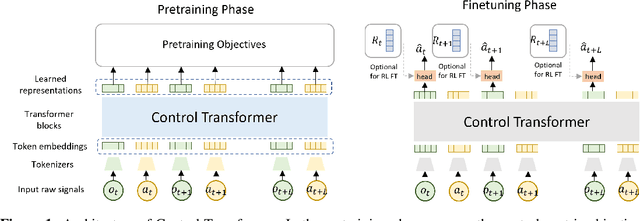
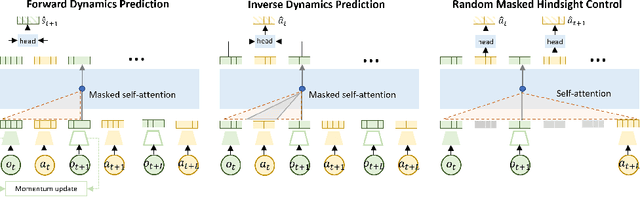
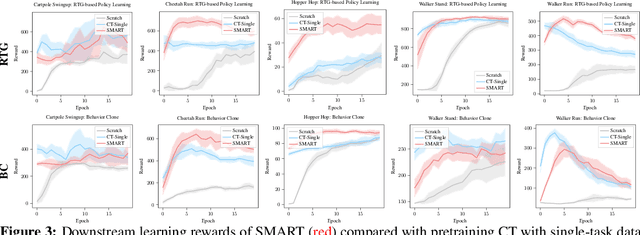
Self-supervised pretraining has been extensively studied in language and vision domains, where a unified model can be easily adapted to various downstream tasks by pretraining representations without explicit labels. When it comes to sequential decision-making tasks, however, it is difficult to properly design such a pretraining approach that can cope with both high-dimensional perceptual information and the complexity of sequential control over long interaction horizons. The challenge becomes combinatorially more complex if we want to pretrain representations amenable to a large variety of tasks. To tackle this problem, in this work, we formulate a general pretraining-finetuning pipeline for sequential decision making, under which we propose a generic pretraining framework \textit{Self-supervised Multi-task pretrAining with contRol Transformer (SMART)}. By systematically investigating pretraining regimes, we carefully design a Control Transformer (CT) coupled with a novel control-centric pretraining objective in a self-supervised manner. SMART encourages the representation to capture the common essential information relevant to short-term control and long-term control, which is transferrable across tasks. We show by extensive experiments in DeepMind Control Suite that SMART significantly improves the learning efficiency among seen and unseen downstream tasks and domains under different learning scenarios including Imitation Learning (IL) and Reinforcement Learning (RL). Benefiting from the proposed control-centric objective, SMART is resilient to distribution shift between pretraining and finetuning, and even works well with low-quality pretraining datasets that are randomly collected.
Joint Localization and Information Transfer for Reconfigurable Intelligent Surface Aided Full-Duplex Systems
Aug 13, 2022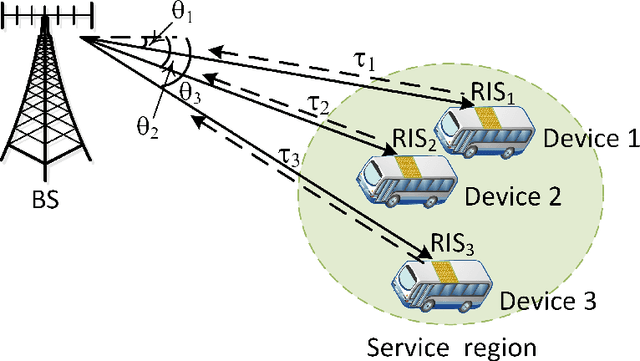
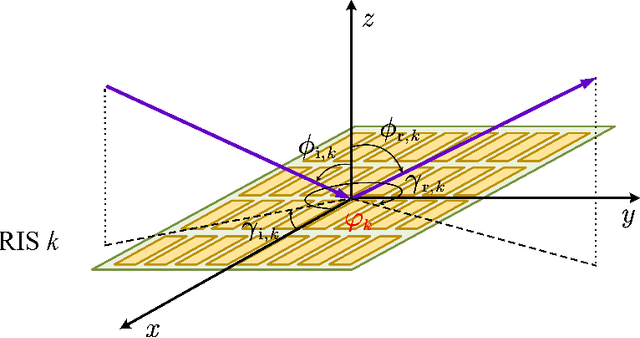
In this work, we investigate a reconfigurable intelligent surface (RIS) aided integrated sensing and communication scenario, where a base station (BS) communicates with multiple devices in a full-duplex mode, and senses the positions of these devices simultaneously. An RIS is assumed to be mounted on each device to enhance the reflected echoes. Meanwhile, the information of each device is passively transferred to the BS via reflection modulation. We aim to tackle the problem of joint localization and information retrieval at the BS. A grid based parametric model is constructed and the joint estimation problem is formulated as a compressive sensing problem. We propose a novel message-passing algorithm to solve the considered problem, and a progressive approximation method to reduce the computational complexity involved in the message passing. Moreover, an expectation-maximization (EM) algorithm is applied for tuning the grid parameters to mitigate the model mismatch problem. Finally, we analyze the efficacy of the proposed algorithm through the Bayesian Cram\'er-Rao bound. Numerical results demonstrate the feasibility of the proposed scheme and the superior performance of the proposed EM-based message-passing algorithm.
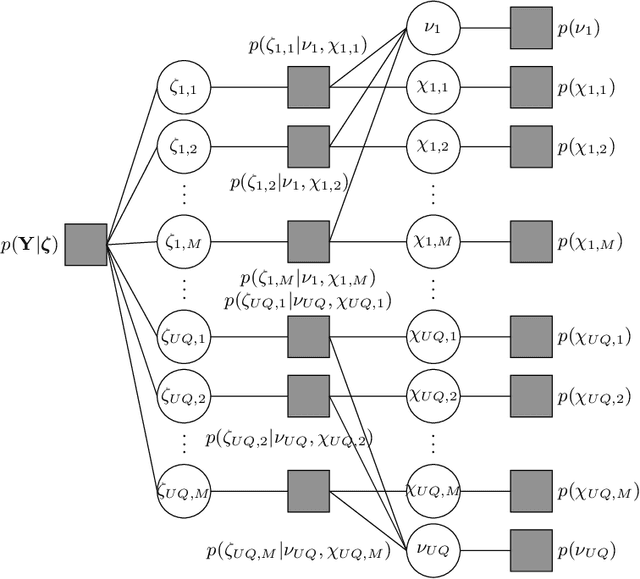
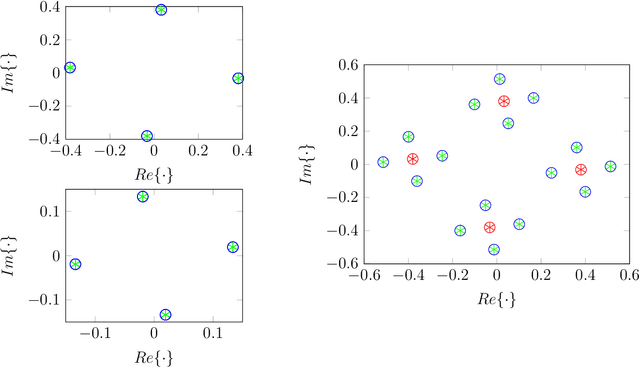
Compressed Predictive Information Coding
Mar 03, 2022
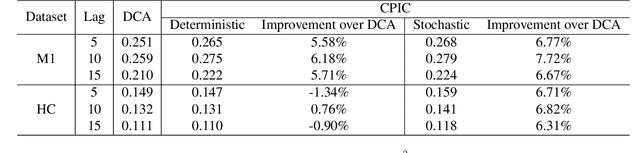
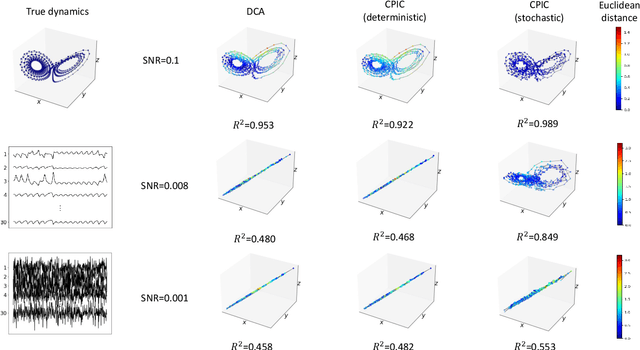
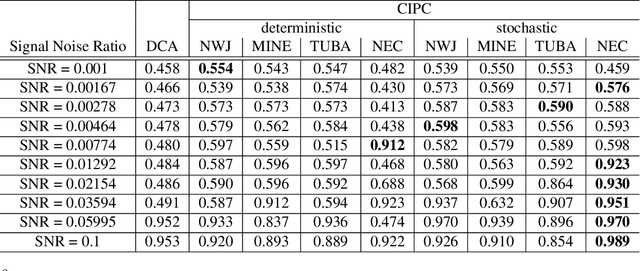
Unsupervised learning plays an important role in many fields, such as artificial intelligence, machine learning, and neuroscience. Compared to static data, methods for extracting low-dimensional structure for dynamic data are lagging. We developed a novel information-theoretic framework, Compressed Predictive Information Coding (CPIC), to extract useful representations from dynamic data. CPIC selectively projects the past (input) into a linear subspace that is predictive about the compressed data projected from the future (output). The key insight of our framework is to learn representations by minimizing the compression complexity and maximizing the predictive information in latent space. We derive variational bounds of the CPIC loss which induces the latent space to capture information that is maximally predictive. Our variational bounds are tractable by leveraging bounds of mutual information. We find that introducing stochasticity in the encoder robustly contributes to better representation. Furthermore, variational approaches perform better in mutual information estimation compared with estimates under a Gaussian assumption. We demonstrate that CPIC is able to recover the latent space of noisy dynamical systems with low signal-to-noise ratios, and extracts features predictive of exogenous variables in neuroscience data.
Learning in POMDPs is Sample-Efficient with Hindsight Observability
Jan 31, 2023
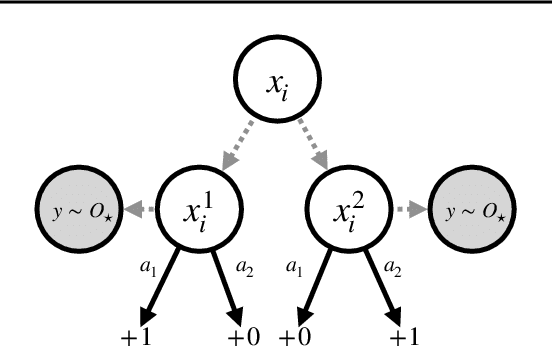
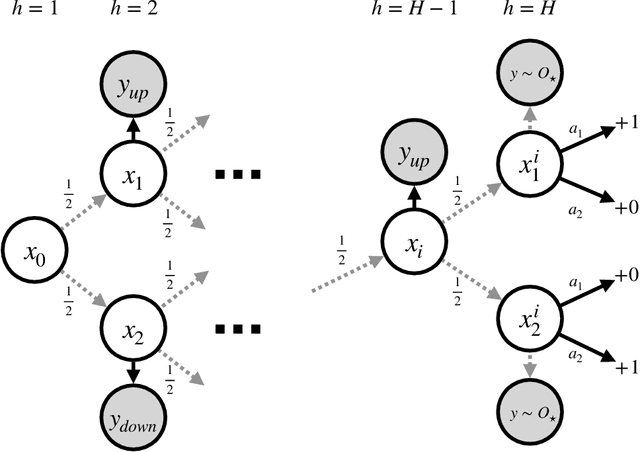
POMDPs capture a broad class of decision making problems, but hardness results suggest that learning is intractable even in simple settings due to the inherent partial observability. However, in many realistic problems, more information is either revealed or can be computed during some point of the learning process. Motivated by diverse applications ranging from robotics to data center scheduling, we formulate a \setting (\setshort) as a POMDP where the latent states are revealed to the learner in hindsight and only during training. We introduce new algorithms for the tabular and function approximation settings that are provably sample-efficient with hindsight observability, even in POMDPs that would otherwise be statistically intractable. We give a lower bound showing that the tabular algorithm is optimal in its dependence on latent state and observation cardinalities.