 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GTR-CTRL: Instrument and Genre Conditioning for Guitar-Focused Music Generation with Transformers
Feb 10, 2023
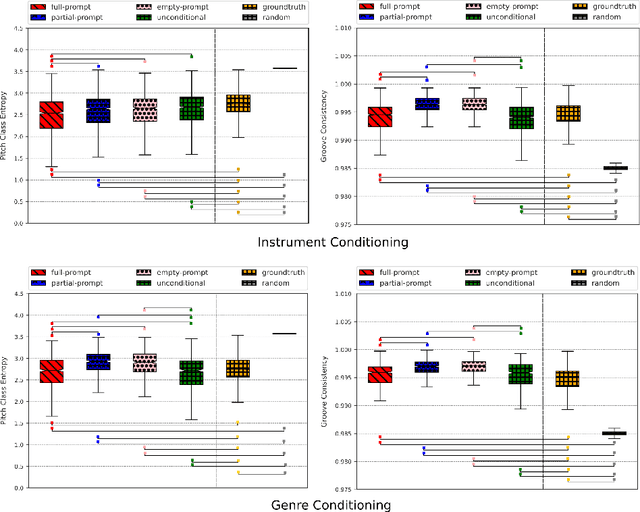

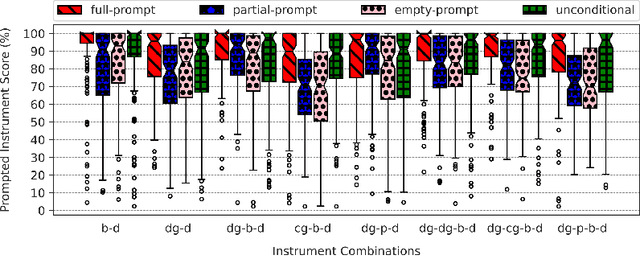
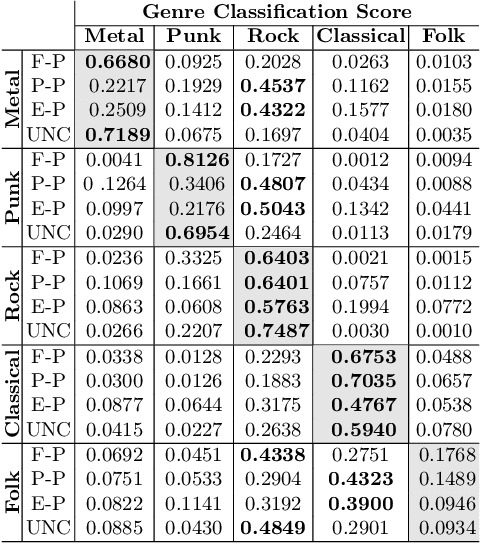
Recently, symbolic music generation with deep learning techniques has witnessed steady improvements. Most works on this topic focus on MIDI representations, but less attention has been paid to symbolic music generation using guitar tablatures (tabs) which can be used to encode multiple instruments. Tabs include information on expressive techniques and fingerings for fretted string instruments in addition to rhythm and pitch. In this work, we use the DadaGP dataset for guitar tab music generation, a corpus of over 26k songs in GuitarPro and token formats. We introduce methods to condition a Transformer-XL deep learning model to generate guitar tabs (GTR-CTRL) based on desired instrumentation (inst-CTRL) and genre (genre-CTRL). Special control tokens are appended at the beginning of each song in the training corpus. We assess the performance of the model with and without conditioning. We propose instrument presence metrics to assess the inst-CTRL model's response to a given instrumentation prompt. We trained a BERT model for downstream genre classification and used it to assess the results obtained with the genre-CTRL model. Statistical analyses evidence significant differences between the conditioned and unconditioned models. Overall, results indicate that the GTR-CTRL methods provide more flexibility and control for guitar-focused symbolic music generation than an unconditioned model.
* This preprint is licensed under a Creative Commons Attribution 4.0 International License (CC BY 4.0). The Version of Record of this contribution is published in Proceedings of EvoMUSART: International Conference on Computational Intelligence in Music, Sound, Art and Design (Part of EvoStar) 2023
Globally Optimized TDOA High Frequency Source Localization Based on Quasi-Parabolic Ionosphere Modeling and Collaborative Gradient Projection
Feb 10, 2023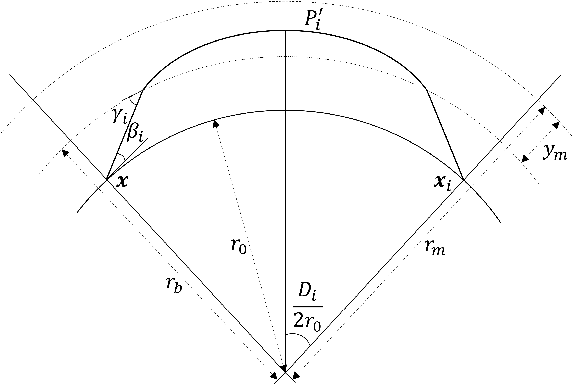
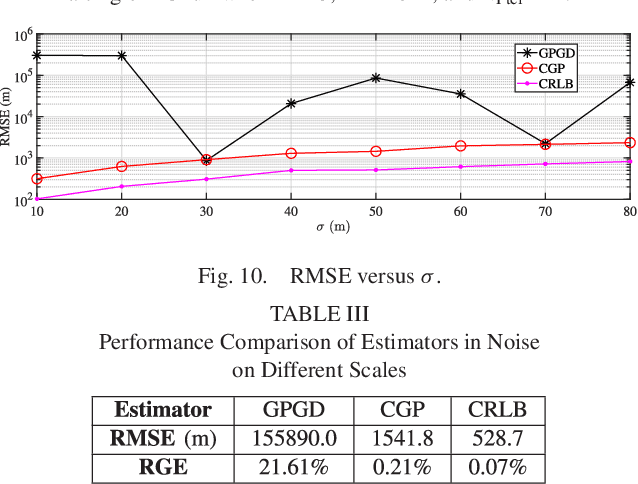
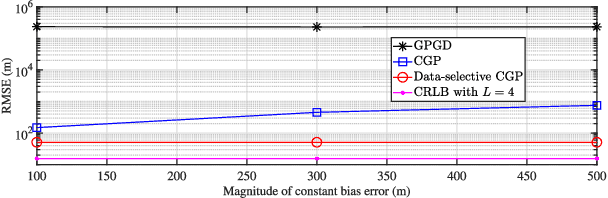
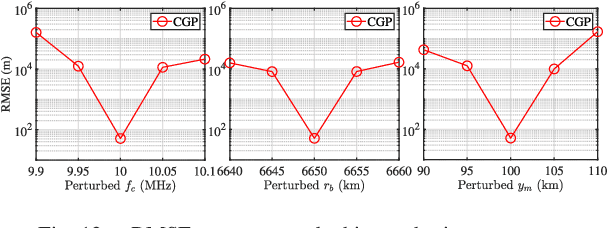
We investigate the problem of high frequency (HF) source localization using the time-difference-of-arrival (TDOA) observations of ionosphere-refracted radio rays based on quasi-parabolic (QP) modeling. An unresolved but pertinent issue in such a field is that the existing gradient-type scheme can easily get trapped in local optima for practical use. This will lead to the difficulty in initializing the algorithm and finally degraded positioning performance if the starting point is inappropriately selected. In this paper, we develop a collaborative gradient projection (GP) algorithm in order to globally solve the highly nonconvex QP-based TDOA HF localization problem. The metaheuristic of particle swarm optimization (PSO) is exploited for information sharing among multiple GP models, each of which is guaranteed to work out a critical point solution to the simplified maximum likelihood formulation. Random mutations are incorporated to avoid the early convergence of PSO. Rather than treating the geolocation of HF transmitter as a pure optimization problem, we further provide workarounds for addressing the possible impairments and challenges when the proposed technique is applied in practice. Numerical results demonstrate the effectiveness of our PSO-assisted re-initialization strategy in achieving the global optimality, and the superiority of our method over its competitor in terms of positioning accuracy.
* This is the accepted version. The final version of this paper has been published in the IEEE Transactions on Aerospace and Electronic Systems. The copyright is with IEEE. This version prevails, as there are unfortunately uncorrected editing mistakes in the final one
Project and Probe: Sample-Efficient Domain Adaptation by Interpolating Orthogonal Features
Feb 10, 2023
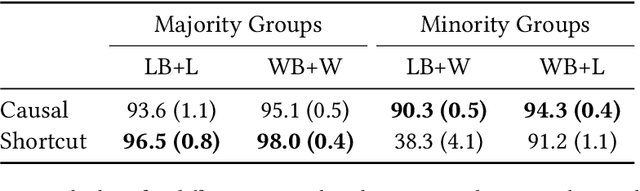

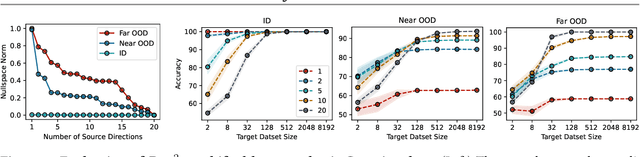
Conventional approaches to robustness try to learn a model based on causal features. However, identifying maximally robust or causal features may be difficult in some scenarios, and in others, non-causal "shortcut" features may actually be more predictive. We propose a lightweight, sample-efficient approach that learns a diverse set of features and adapts to a target distribution by interpolating these features with a small target dataset. Our approach, Project and Probe (Pro$^2$), first learns a linear projection that maps a pre-trained embedding onto orthogonal directions while being predictive of labels in the source dataset. The goal of this step is to learn a variety of predictive features, so that at least some of them remain useful after distribution shift. Pro$^2$ then learns a linear classifier on top of these projected features using a small target dataset. We theoretically show that Pro$^2$ learns a projection matrix that is optimal for classification in an information-theoretic sense, resulting in better generalization due to a favorable bias-variance tradeoff. Our experiments on four datasets, with multiple distribution shift settings for each, show that Pro$^2$ improves performance by 5-15% when given limited target data compared to prior methods such as standard linear probing.
Fast Gumbel-Max Sketch and its Applications
Feb 10, 2023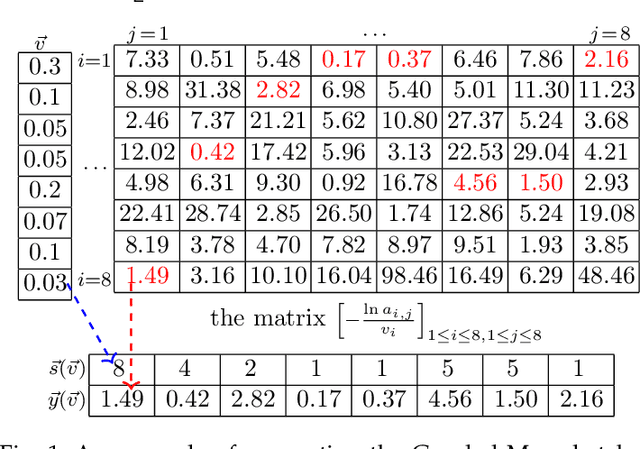
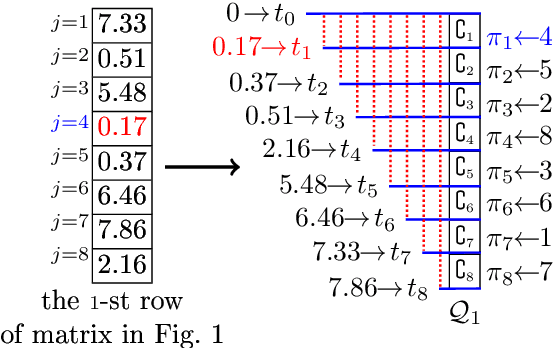
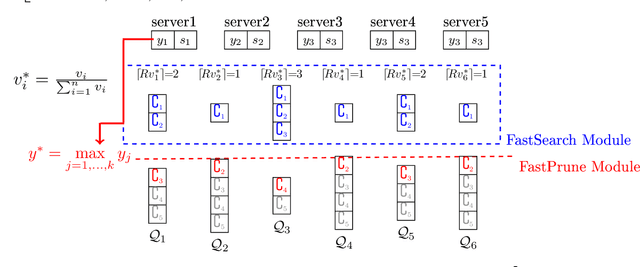
The well-known Gumbel-Max Trick for sampling elements from a categorical distribution (or more generally a non-negative vector) and its variants have been widely used in areas such as machine learning and information retrieval. To sample a random element $i$ in proportion to its positive weight $v_i$, the Gumbel-Max Trick first computes a Gumbel random variable $g_i$ for each positive weight element $i$, and then samples the element $i$ with the largest value of $g_i+\ln v_i$. Recently, applications including similarity estimation and weighted cardinality estimation require to generate $k$ independent Gumbel-Max variables from high dimensional vectors. However, it is computationally expensive for a large $k$ (e.g., hundreds or even thousands) when using the traditional Gumbel-Max Trick. To solve this problem, we propose a novel algorithm, FastGM, which reduces the time complexity from $O(kn^+)$ to $O(k \ln k + n^+)$, where $n^+$ is the number of positive elements in the vector of interest. FastGM stops the procedure of Gumbel random variables computing for many elements, especially for those with small weights. We perform experiments on a variety of real-world datasets and the experimental results demonstrate that FastGM is orders of magnitude faster than state-of-the-art methods without sacrificing accuracy or incurring additional expenses.
Compressed Predictive Information Coding
Mar 03, 2022
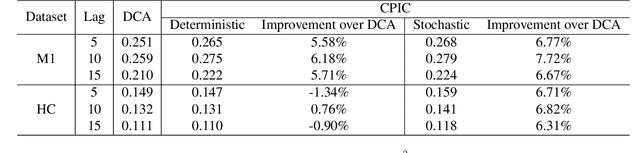
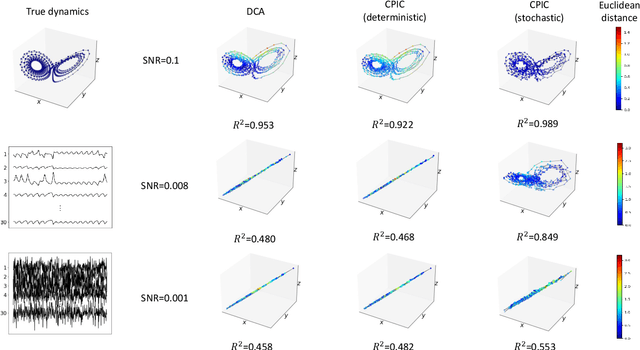
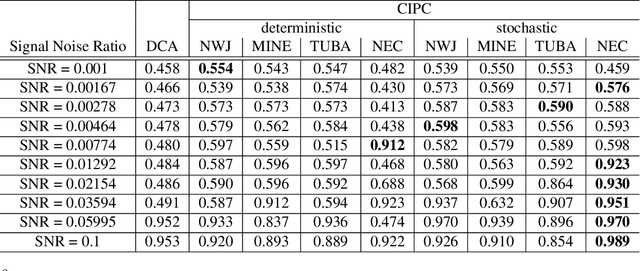
Unsupervised learning plays an important role in many fields, such as artificial intelligence, machine learning, and neuroscience. Compared to static data, methods for extracting low-dimensional structure for dynamic data are lagging. We developed a novel information-theoretic framework, Compressed Predictive Information Coding (CPIC), to extract useful representations from dynamic data. CPIC selectively projects the past (input) into a linear subspace that is predictive about the compressed data projected from the future (output). The key insight of our framework is to learn representations by minimizing the compression complexity and maximizing the predictive information in latent space. We derive variational bounds of the CPIC loss which induces the latent space to capture information that is maximally predictive. Our variational bounds are tractable by leveraging bounds of mutual information. We find that introducing stochasticity in the encoder robustly contributes to better representation. Furthermore, variational approaches perform better in mutual information estimation compared with estimates under a Gaussian assumption. We demonstrate that CPIC is able to recover the latent space of noisy dynamical systems with low signal-to-noise ratios, and extracts features predictive of exogenous variables in neuroscience data.
Lexical Simplification using multi level and modular approach
Feb 03, 2023
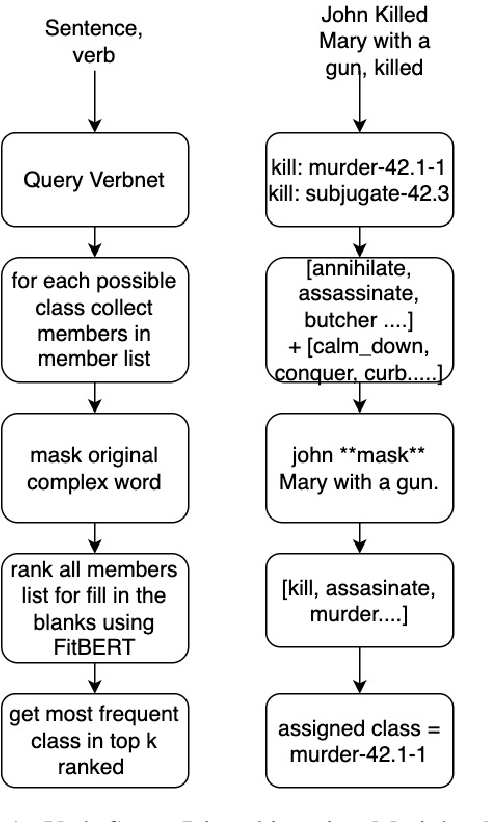

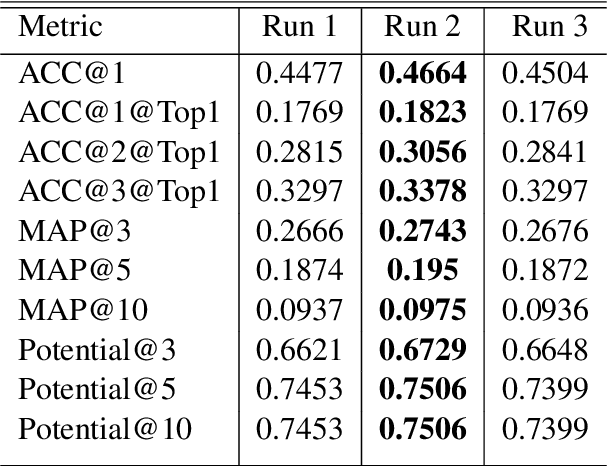
Text Simplification is an ongoing problem in Natural Language Processing, solution to which has varied implications. In conjunction with the TSAR-2022 Workshop @EMNLP2022 Lexical Simplification is the process of reducing the lexical complexity of a text by replacing difficult words with easier to read (or understand) expressions while preserving the original information and meaning. This paper explains the work done by our team "teamPN" for English sub task. We created a modular pipeline which combines modern day transformers based models with traditional NLP methods like paraphrasing and verb sense disambiguation. We created a multi level and modular pipeline where the target text is treated according to its semantics(Part of Speech Tag). Pipeline is multi level as we utilize multiple source models to find potential candidates for replacement, It is modular as we can switch the source models and their weight-age in the final re-ranking.
Semantic Feature Integration network for Fine-grained Visual Classification
Feb 13, 2023
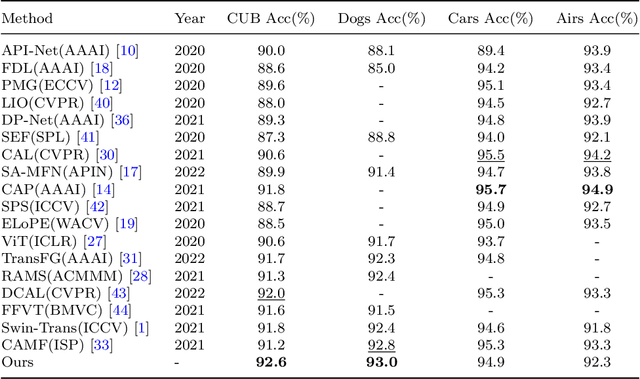
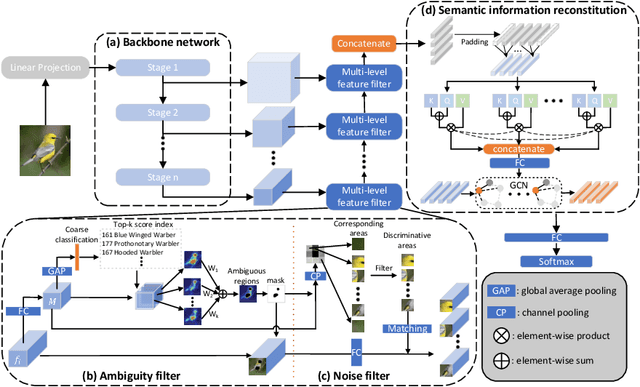
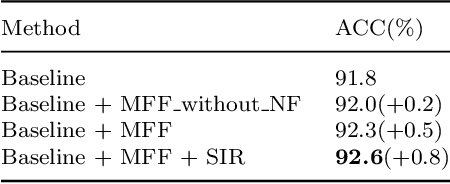
Fine-Grained Visual Classification (FGVC) is known as a challenging task due to subtle differences among subordinate categories. Many current FGVC approaches focus on identifying and locating discriminative regions by using the attention mechanism, but neglect the presence of unnecessary features that hinder the understanding of object structure. These unnecessary features, including 1) ambiguous parts resulting from the visual similarity in object appearances and 2) noninformative parts (e.g., background noise), can have a significant adverse impact on classification results. In this paper, we propose the Semantic Feature Integration network (SFI-Net) to address the above difficulties. By eliminating unnecessary features and reconstructing the semantic relations among discriminative features, our SFI-Net has achieved satisfying performance. The network consists of two modules: 1) the multi-level feature filter (MFF) module is proposed to remove unnecessary features with different receptive field, and then concatenate the preserved features on pixel level for subsequent disposal; 2) the semantic information reconstitution (SIR) module is presented to further establish semantic relations among discriminative features obtained from the MFF module. These two modules are carefully designed to be light-weighted and can be trained end-to-end in a weakly-supervised way. Extensive experiments on four challenging fine-grained benchmarks demonstrate that our proposed SFI-Net achieves the state-of-the-arts performance. Especially, the classification accuracy of our model on CUB-200-2011 and Stanford Dogs reaches 92.64% and 93.03%, respectively.
How do you go where? Improving next location prediction by learning travel mode information using transformers
Oct 08, 2022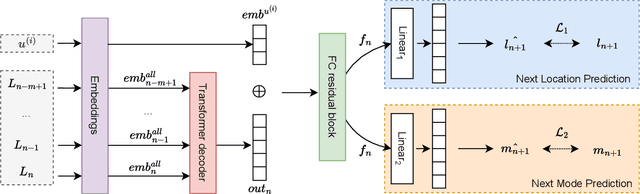
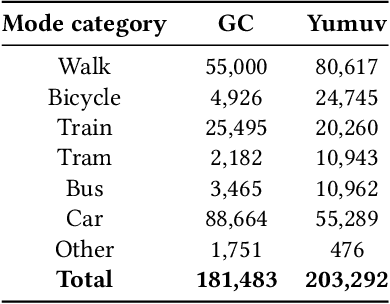
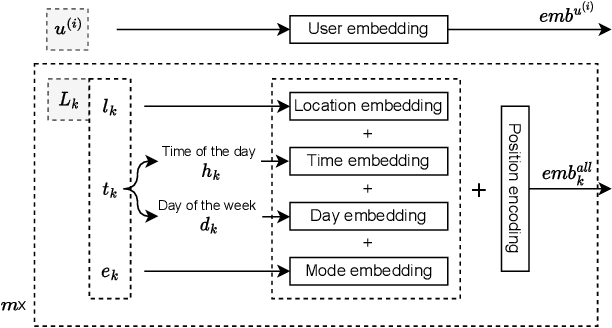
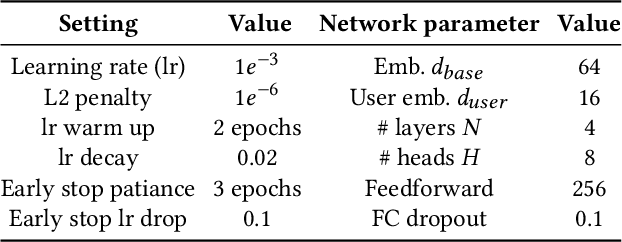
Predicting the next visited location of an individual is a key problem in human mobility analysis, as it is required for the personalization and optimization of sustainable transport options. Here, we propose a transformer decoder-based neural network to predict the next location an individual will visit based on historical locations, time, and travel modes, which are behaviour dimensions often overlooked in previous work. In particular, the prediction of the next travel mode is designed as an auxiliary task to help guide the network's learning. For evaluation, we apply this approach to two large-scale and long-term GPS tracking datasets involving more than 600 individuals. Our experiments show that the proposed method significantly outperforms other state-of-the-art next location prediction methods by a large margin (8.05% and 5.60% relative increase in F1-score for the two datasets, respectively). We conduct an extensive ablation study that quantifies the influence of considering temporal features, travel mode information, and the auxiliary task on the prediction results. Moreover, we experimentally determine the performance upper bound when including the next mode prediction in our model. Finally, our analysis indicates that the performance of location prediction varies significantly with the chosen next travel mode by the individual. These results show potential for a more systematic consideration of additional dimensions of travel behaviour in human mobility prediction tasks. The source code of our model and experiments is available at https://github.com/mie-lab/location-mode-prediction.
Characterizing the Entities in Harmful Memes: Who is the Hero, the Villain, the Victim?
Jan 26, 2023
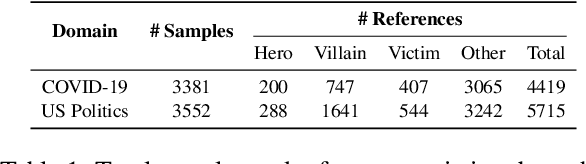
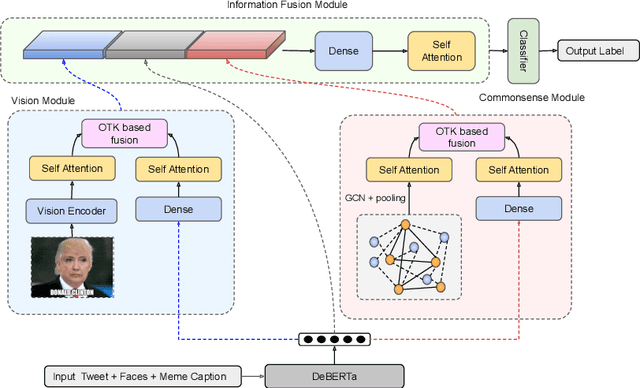
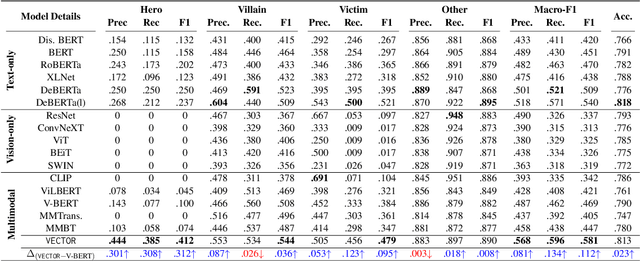
Memes can sway people's opinions over social media as they combine visual and textual information in an easy-to-consume manner. Since memes instantly turn viral, it becomes crucial to infer their intent and potentially associated harmfulness to take timely measures as needed. A common problem associated with meme comprehension lies in detecting the entities referenced and characterizing the role of each of these entities. Here, we aim to understand whether the meme glorifies, vilifies, or victimizes each entity it refers to. To this end, we address the task of role identification of entities in harmful memes, i.e., detecting who is the 'hero', the 'villain', and the 'victim' in the meme, if any. We utilize HVVMemes - a memes dataset on US Politics and Covid-19 memes, released recently as part of the CONSTRAINT@ACL-2022 shared-task. It contains memes, entities referenced, and their associated roles: hero, villain, victim, and other. We further design VECTOR (Visual-semantic role dEteCToR), a robust multi-modal framework for the task, which integrates entity-based contextual information in the multi-modal representation and compare it to several standard unimodal (text-only or image-only) or multi-modal (image+text) models. Our experimental results show that our proposed model achieves an improvement of 4% over the best baseline and 1% over the best competing stand-alone submission from the shared-task. Besides divulging an extensive experimental setup with comparative analyses, we finally highlight the challenges encountered in addressing the complex task of semantic role labeling within memes.
CitationSum: Citation-aware Graph Contrastive Learning for Scientific Paper Summarization
Jan 26, 2023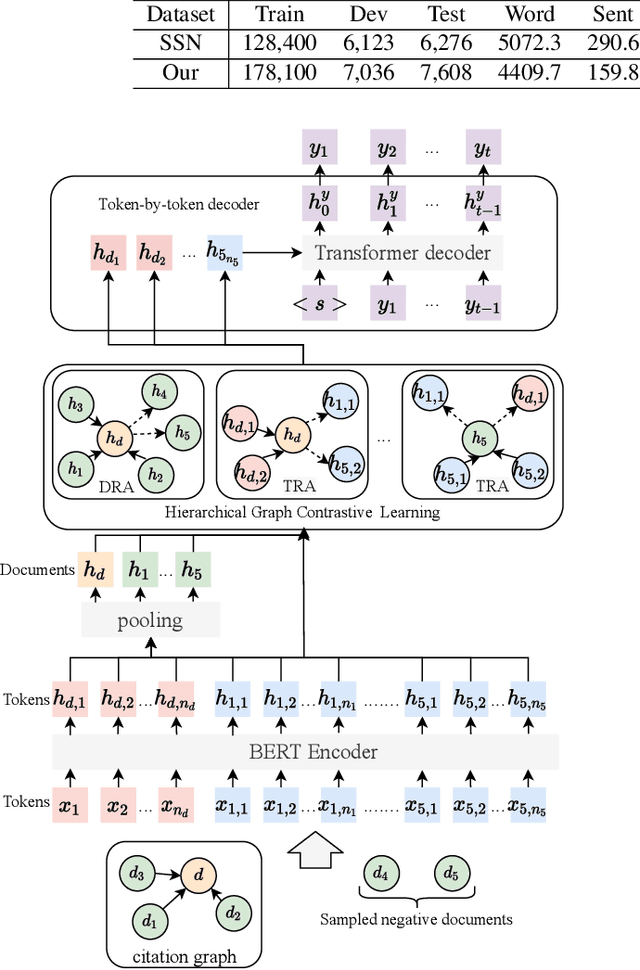

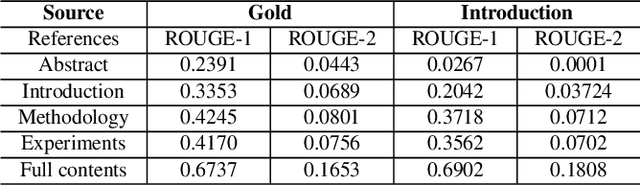
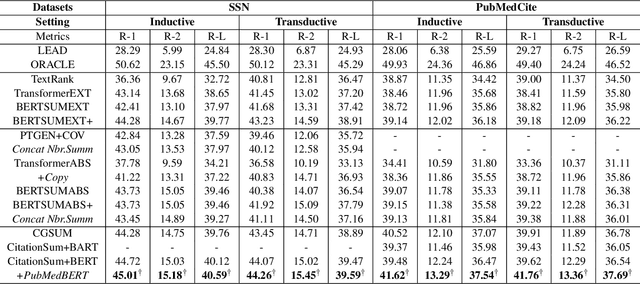
The citation graph is essential for generating high-quality summaries of scientific papers, in which references of a scientific paper and their correlations provide extra knowledge for understanding its background and main contributions. Despite the promising role of the citation graph, effectively incorporating it still remains a big challenge, given the difficulty of accurately identifying and leveraging relevant contents in references for a source paper, as well as modelling their correlations of different intensities. Existing methods either ignore or utilize only abstracts indiscriminately from references, failing to tackle the challenge mentioned above. To fill the gap, we propose a novel citation-aware scientific paper summarization framework based on the citation graph, with the ability to accurately locate and incorporate the salient contents from references, as well as capture varying relevance between source papers and their references. Specifically, we first build a domain-specific dataset PubMedCite with about 192K biomedical scientific papers and a large citation graph preserving 917K citation relationships between them. It is characterized by preserving the salient contents extracted from full texts of references, and the weighted correlation between the salient contents of references and the source paper. Based on it, we design a self-supervised citation-aware summarization framework (CitationSum) with graph contrastive learning, which boosts the summarization generation by efficiently fusing the salient information in references with source paper contents under the guidance of their correlations. Experimental results show that our model outperforms the state-of-the-art methods, due to efficiently leveraging the information of references and citation correlations.