 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Spatial Clustering Approach for Vessel Path Identification
Mar 09, 2024
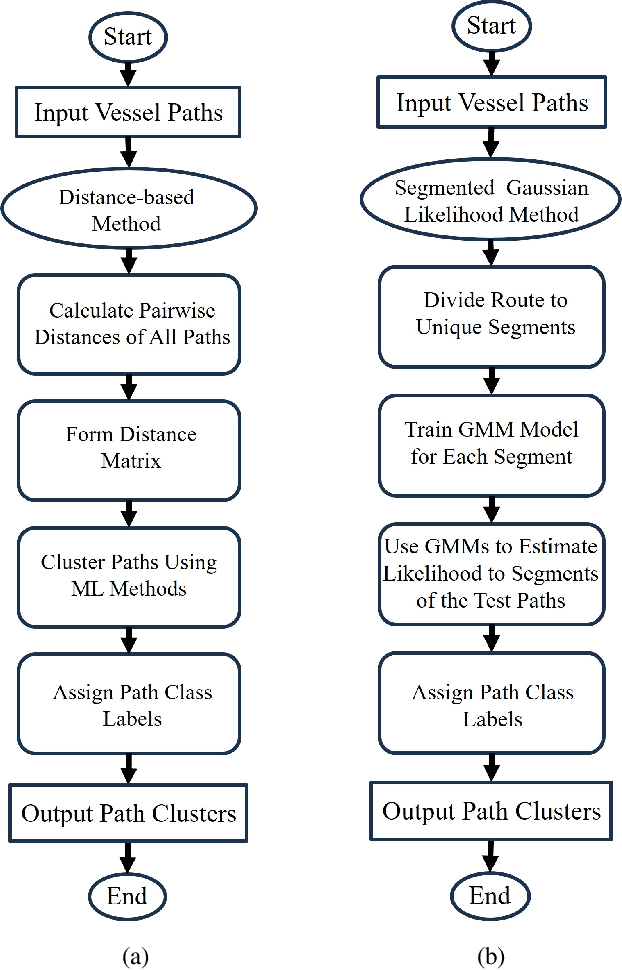
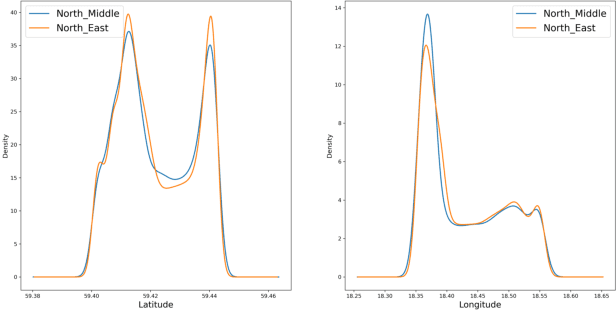
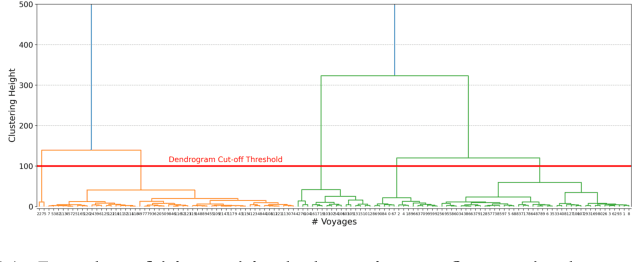

This paper addresses the challenge of identifying the paths for vessels with operating routes of repetitive paths, partially repetitive paths, and new paths. We propose a spatial clustering approach for labeling the vessel paths by using only position information. We develop a path clustering framework employing two methods: a distance-based path modeling and a likelihood estimation method. The former enhances the accuracy of path clustering through the integration of unsupervised machine learning techniques, while the latter focuses on likelihood-based path modeling and introduces segmentation for a more detailed analysis. The result findings highlight the superior performance and efficiency of the developed approach, as both methods for clustering vessel paths into five classes achieve a perfect F1-score. The approach aims to offer valuable insights for route planning, ultimately contributing to improving safety and efficiency in maritime transportation.
sVAD: A Robust, Low-Power, and Light-Weight Voice Activity Detection with Spiking Neural Networks
Mar 09, 2024
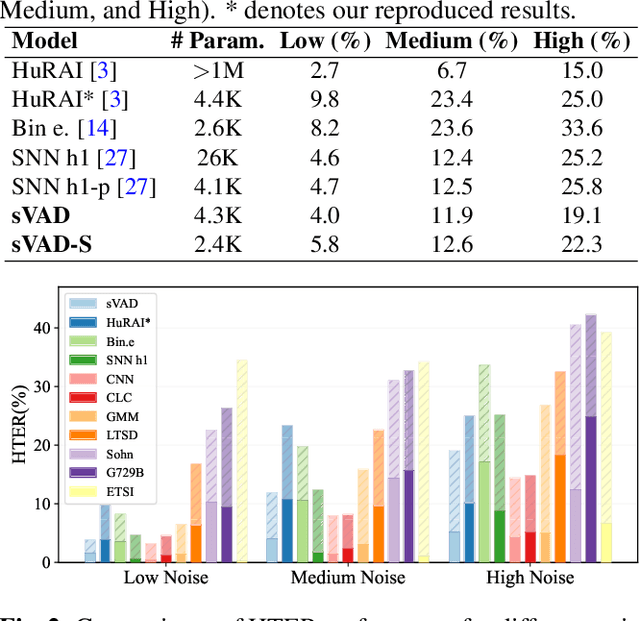
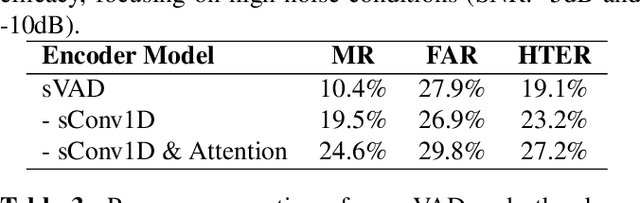
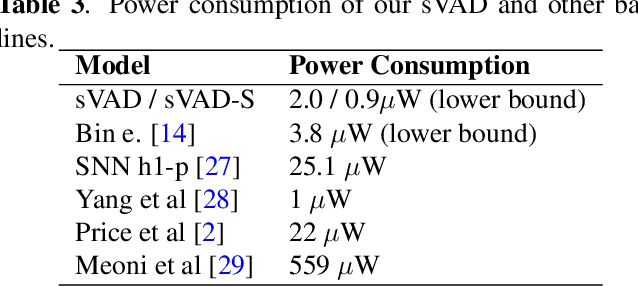
Speech applications are expected to be low-power and robust under noisy conditions. An effective Voice Activity Detection (VAD) front-end lowers the computational need. Spiking Neural Networks (SNNs) are known to be biologically plausible and power-efficient. However, SNN-based VADs have yet to achieve noise robustness and often require large models for high performance. This paper introduces a novel SNN-based VAD model, referred to as sVAD, which features an auditory encoder with an SNN-based attention mechanism. Particularly, it provides effective auditory feature representation through SincNet and 1D convolution, and improves noise robustness with attention mechanisms. The classifier utilizes Spiking Recurrent Neural Networks (sRNN) to exploit temporal speech information. Experimental results demonstrate that our sVAD achieves remarkable noise robustness and meanwhile maintains low power consumption and a small footprint, making it a promising solution for real-world VAD applications.
Solving the bongard-logo problem by modeling a probabilistic model
Mar 09, 2024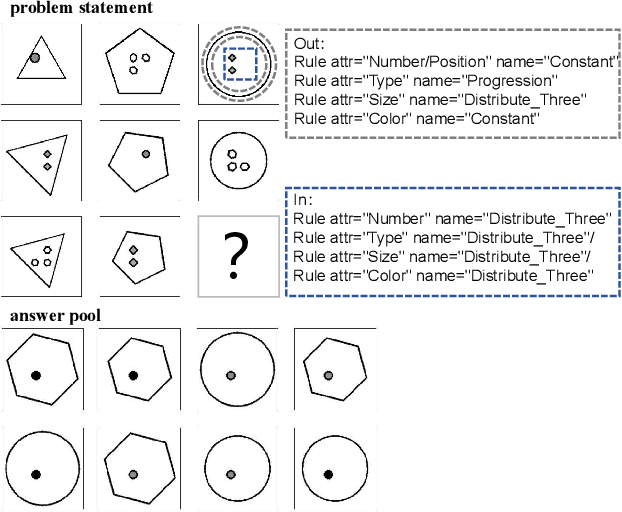
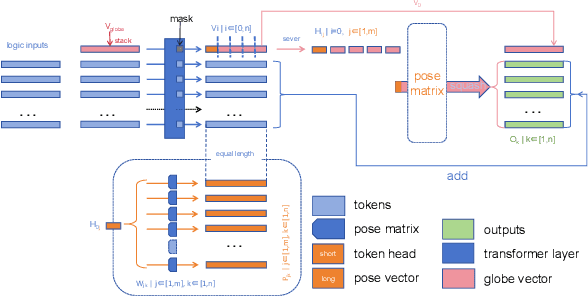
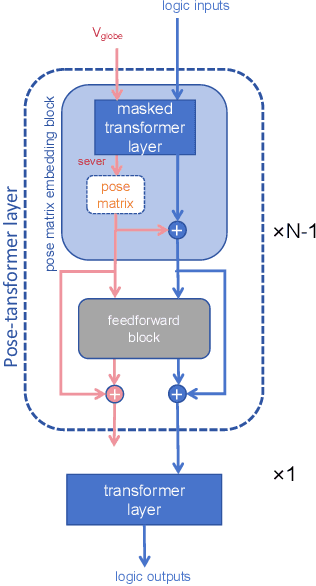
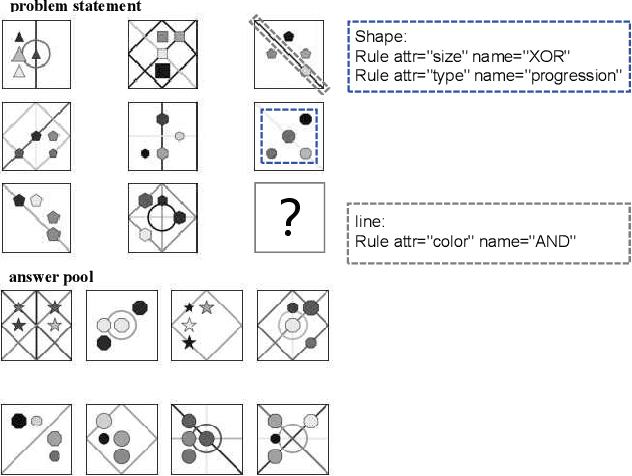
Abstract reasoning problems challenge the perceptual and cognitive abilities of AI algorithms, demanding deeper pattern discernment and inductive reasoning beyond explicit image features. This study introduces PMoC, a tailored probability model for the Bongard-Logo problem, achieving high reasoning accuracy by constructing independent probability models. Additionally, we present Pose-Transformer, an enhanced Transformer-Encoder designed for complex abstract reasoning tasks, including Bongard-Logo, RAVEN, I-RAVEN, and PGM. Pose-Transformer incorporates positional information learning, inspired by capsule networks' pose matrices, enhancing its focus on local positional relationships in image data processing. When integrated with PMoC, it further improves reasoning accuracy. Our approach effectively addresses reasoning difficulties associated with abstract entities' positional changes, outperforming previous models on the OIG, D3$\times$3 subsets of RAVEN, and PGM databases. This research contributes to advancing AI's capabilities in abstract reasoning and cognitive pattern recognition.
End-to-end solution for linked open data query logs analytics
Mar 09, 2024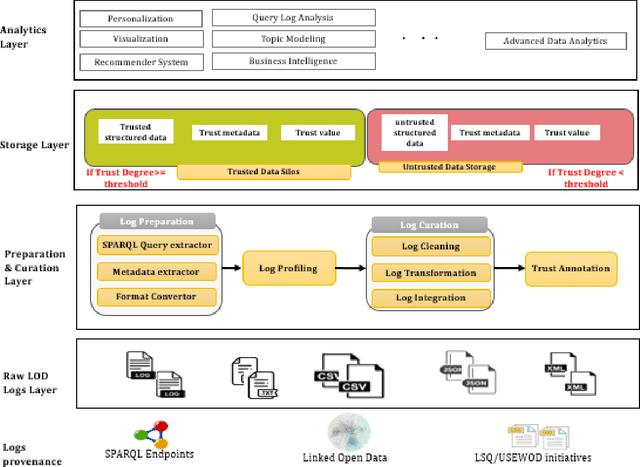
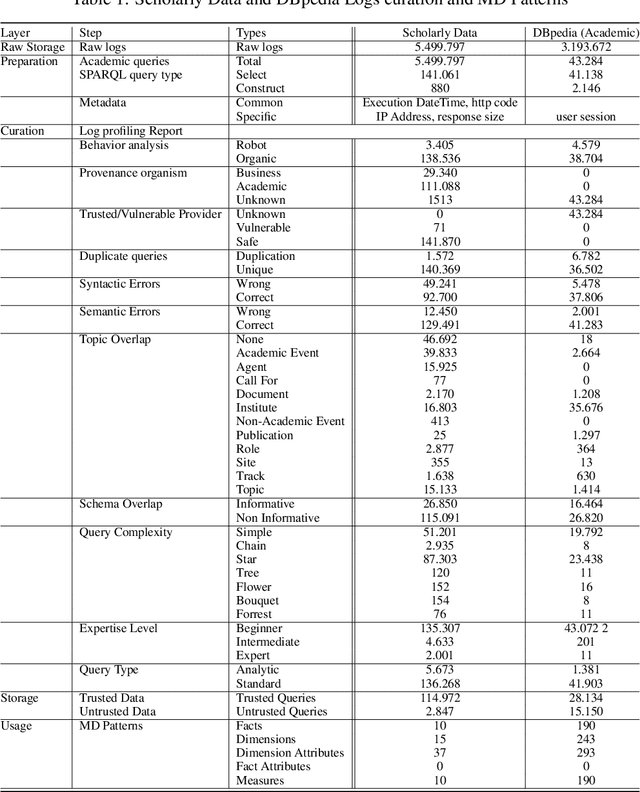
Important advances in pillar domains are derived from exploiting query-logs which represents users interest and preferences. Deep understanding of users provides useful knowledge which can influence strongly decision-making. In this work, we want to extract valuable information from Linked Open Data (LOD) query-logs. LOD logs have experienced significant growth due to the large exploitation of LOD datasets. However, exploiting these logs is a difficult task because of their complex structure. Moreover, these logs suffer from many risks related to their Quality and Provenance, impacting their trust. To tackle these issues, we start by clearly defining the ecosystem of LOD query-logs. Then, we provide an end-to-end solution to exploit these logs. At the end, real LOD logs are used and a set of experiments are conducted to validate the proposed solution.
Repeated Padding as Data Augmentation for Sequential Recommendation
Mar 11, 2024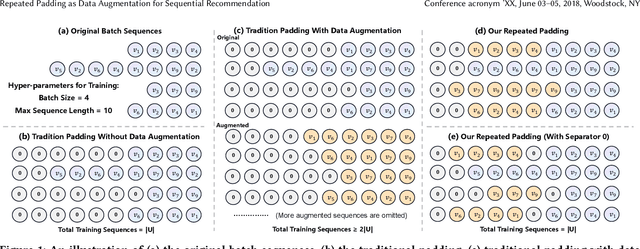


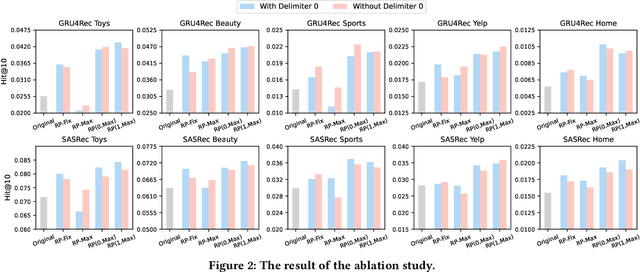
Sequential recommendation aims to provide users with personalized suggestions based on their historical interactions. When training sequential models, padding is a widely adopted technique for two main reasons: 1) The vast majority of models can only handle fixed-length sequences; 2) Batching-based training needs to ensure that the sequences in each batch have the same length. The special value \emph{0} is usually used as the padding content, which does not contain the actual information and is ignored in the model calculations. This common-sense padding strategy leads us to a problem that has never been explored before: \emph{Can we fully utilize this idle input space by padding other content to further improve model performance and training efficiency?} In this paper, we propose a simple yet effective padding method called \textbf{Rep}eated \textbf{Pad}ding (\textbf{RepPad}). Specifically, we use the original interaction sequences as the padding content and fill it to the padding positions during model training. This operation can be performed a finite number of times or repeated until the input sequences' length reaches the maximum limit. Our RepPad can be viewed as a sequence-level data augmentation strategy. Unlike most existing works, our method contains no trainable parameters or hyperparameters and is a plug-and-play data augmentation operation. Extensive experiments on various categories of sequential models and five real-world datasets demonstrate the effectiveness and efficiency of our approach. The average recommendation performance improvement is up to 60.3\% on GRU4Rec and 24.3\% on SASRec. We also provide in-depth analysis and explanation of what makes RepPad effective from multiple perspectives. The source code will be released to ensure the reproducibility of our experiments.
Not all tickets are equal and we know it: Guiding pruning with domain-specific knowledge
Mar 05, 2024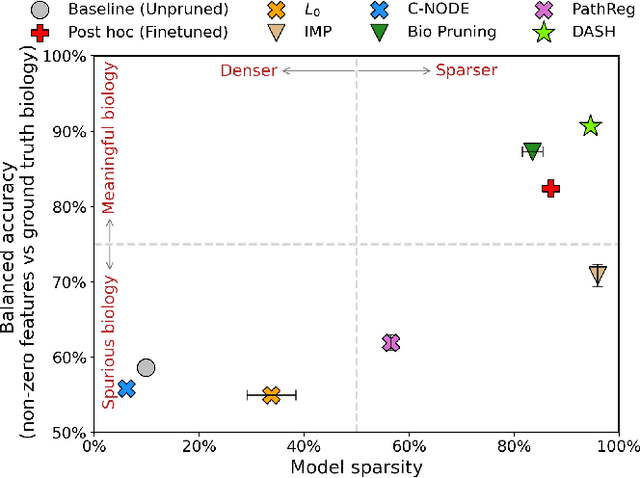
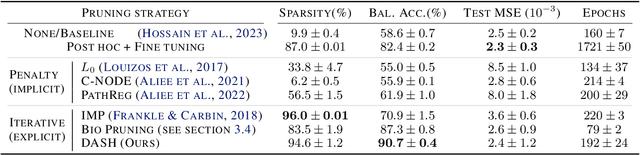
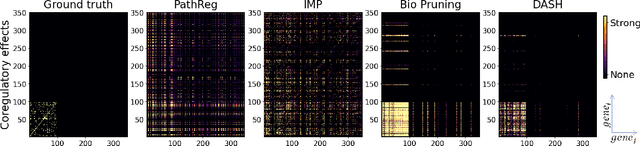
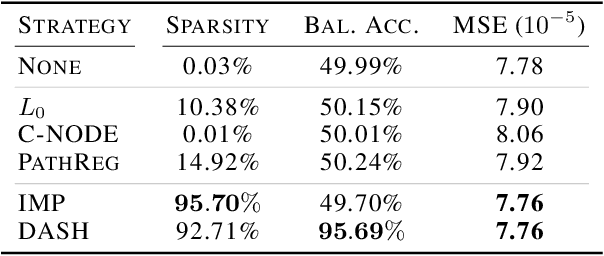
Neural structure learning is of paramount importance for scientific discovery and interpretability. Yet, contemporary pruning algorithms that focus on computational resource efficiency face algorithmic barriers to select a meaningful model that aligns with domain expertise. To mitigate this challenge, we propose DASH, which guides pruning by available domain-specific structural information. In the context of learning dynamic gene regulatory network models, we show that DASH combined with existing general knowledge on interaction partners provides data-specific insights aligned with biology. For this task, we show on synthetic data with ground truth information and two real world applications the effectiveness of DASH, which outperforms competing methods by a large margin and provides more meaningful biological insights. Our work shows that domain specific structural information bears the potential to improve model-derived scientific insights.
A Dataset for the Validation of Truth Inference Algorithms Suitable for Online Deployment
Mar 10, 2024
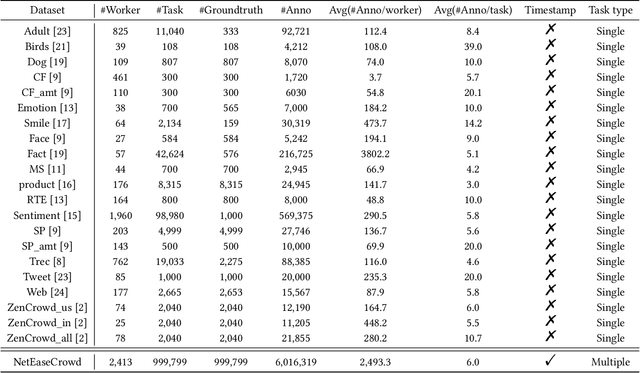
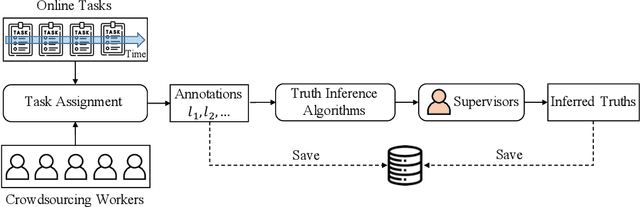
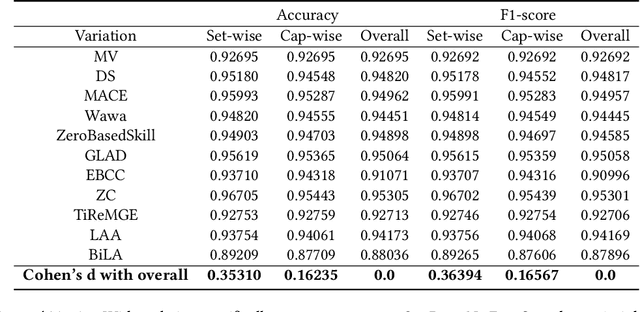
For the purpose of efficient and cost-effective large-scale data labeling, crowdsourcing is increasingly being utilized. To guarantee the quality of data labeling, multiple annotations need to be collected for each data sample, and truth inference algorithms have been developed to accurately infer the true labels. Despite previous studies having released public datasets to evaluate the efficacy of truth inference algorithms, these have typically focused on a single type of crowdsourcing task and neglected the temporal information associated with workers' annotation activities. These limitations significantly restrict the practical applicability of these algorithms, particularly in the context of long-term and online truth inference. In this paper, we introduce a substantial crowdsourcing annotation dataset collected from a real-world crowdsourcing platform. This dataset comprises approximately two thousand workers, one million tasks, and six million annotations. The data was gathered over a period of approximately six months from various types of tasks, and the timestamps of each annotation were preserved. We analyze the characteristics of the dataset from multiple perspectives and evaluate the effectiveness of several representative truth inference algorithms on this dataset. We anticipate that this dataset will stimulate future research on tracking workers' abilities over time in relation to different types of tasks, as well as enhancing online truth inference.
Cracking the neural code for word recognition in convolutional neural networks
Mar 10, 2024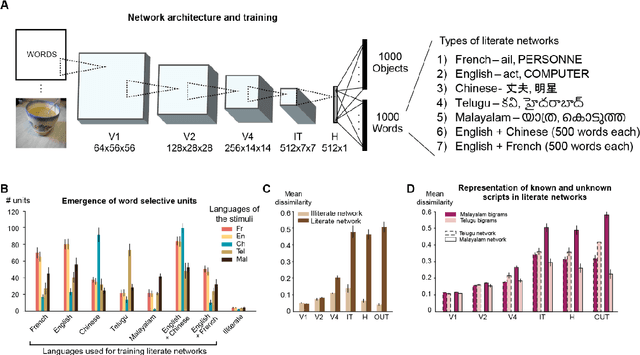
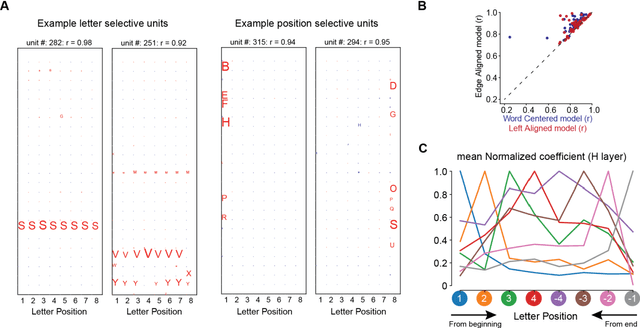
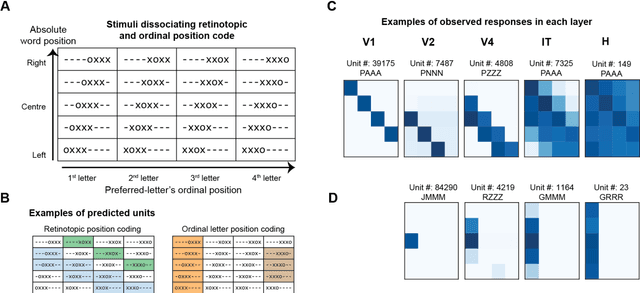
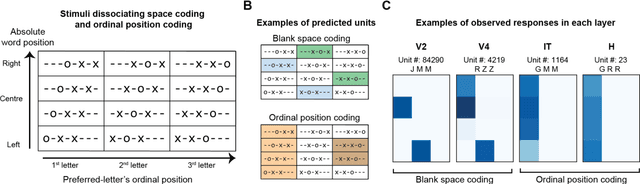
Learning to read places a strong challenge on the visual system. Years of expertise lead to a remarkable capacity to separate highly similar letters and encode their relative positions, thus distinguishing words such as FORM and FROM, invariantly over a large range of sizes and absolute positions. How neural circuits achieve invariant word recognition remains unknown. Here, we address this issue by training deep neural network models to recognize written words and then analyzing how reading-specialized units emerge and operate across different layers of the network. With literacy, a small subset of units becomes specialized for word recognition in the learned script, similar to the "visual word form area" of the human brain. We show that these units are sensitive to specific letter identities and their distance from the blank space at the left or right of a word, thus acting as "space bigrams". These units specifically encode ordinal positions and operate by pooling across low and high-frequency detector units from early layers of the network. The proposed neural code provides a mechanistic insight into how information on letter identity and position is extracted and allow for invariant word recognition, and leads to predictions for reading behavior, error patterns, and the neurophysiology of reading.
NetInfoF Framework: Measuring and Exploiting Network Usable Information
Feb 12, 2024Given a node-attributed graph, and a graph task (link prediction or node classification), can we tell if a graph neural network (GNN) will perform well? More specifically, do the graph structure and the node features carry enough usable information for the task? Our goals are (1) to develop a fast tool to measure how much information is in the graph structure and in the node features, and (2) to exploit the information to solve the task, if there is enough. We propose NetInfoF, a framework including NetInfoF_Probe and NetInfoF_Act, for the measurement and the exploitation of network usable information (NUI), respectively. Given a graph data, NetInfoF_Probe measures NUI without any model training, and NetInfoF_Act solves link prediction and node classification, while two modules share the same backbone. In summary, NetInfoF has following notable advantages: (a) General, handling both link prediction and node classification; (b) Principled, with theoretical guarantee and closed-form solution; (c) Effective, thanks to the proposed adjustment to node similarity; (d) Scalable, scaling linearly with the input size. In our carefully designed synthetic datasets, NetInfoF correctly identifies the ground truth of NUI and is the only method being robust to all graph scenarios. Applied on real-world datasets, NetInfoF wins in 11 out of 12 times on link prediction compared to general GNN baselines.
Self-seeding and Multi-intent Self-instructing LLMs for Generating Intent-aware Information-Seeking dialogs
Feb 18, 2024Identifying user intents in information-seeking dialogs is crucial for a system to meet user's information needs. Intent prediction (IP) is challenging and demands sufficient dialogs with human-labeled intents for training. However, manually annotating intents is resource-intensive. While large language models (LLMs) have been shown to be effective in generating synthetic data, there is no study on using LLMs to generate intent-aware information-seeking dialogs. In this paper, we focus on leveraging LLMs for zero-shot generation of large-scale, open-domain, and intent-aware information-seeking dialogs. We propose SOLID, which has novel self-seeding and multi-intent self-instructing schemes. The former improves the generation quality by using the LLM's own knowledge scope to initiate dialog generation; the latter prompts the LLM to generate utterances sequentially, and mitigates the need for manual prompt design by asking the LLM to autonomously adapt its prompt instruction when generating complex multi-intent utterances. Furthermore, we propose SOLID-RL, which is further trained to generate a dialog in one step on the data generated by SOLID. We propose a length-based quality estimation mechanism to assign varying weights to SOLID-generated dialogs based on their quality during the training process of SOLID-RL. We use SOLID and SOLID-RL to generate more than 300k intent-aware dialogs, surpassing the size of existing datasets. Experiments show that IP methods trained on dialogs generated by SOLID and SOLID-RL achieve better IP quality than ones trained on human-generated dialogs.