 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
When Source-Free Domain Adaptation Meets Label Propagation
Jan 20, 2023
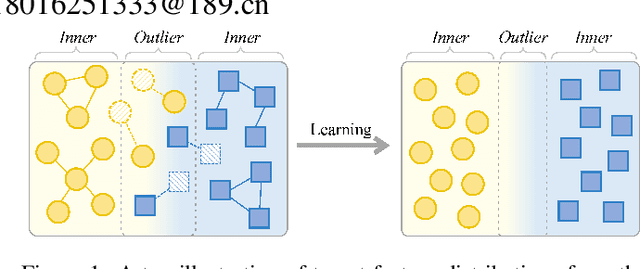
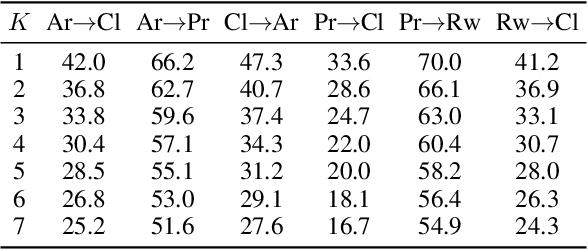
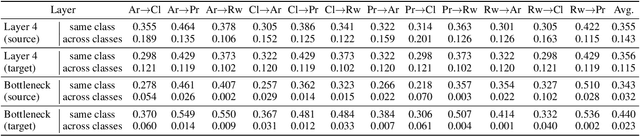
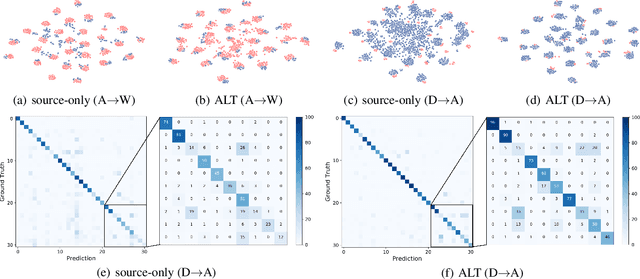
Source-free domain adaptation, where only a pre-trained source model is used to adapt to the target distribution, is a more general approach to achieving domain adaptation. However, it can be challenging to capture the inherent structure of the target features accurately due to the lack of supervised information on the target domain. To tackle this problem, we propose a novel approach called Adaptive Local Transfer (ALT) that tries to achieve efficient feature clustering from the perspective of label propagation. ALT divides the target data into inner and outlier samples based on the adaptive threshold of the learning state, and applies a customized learning strategy to best fits the data property. Specifically, inner samples are utilized for learning intra-class structure thanks to their relatively well-clustered properties. The low-density outlier samples are regularized by input consistency to achieve high accuracy with respect to the ground truth labels. In this way, local clustering can be prevented from forming spurious clusters while effectively propagating label information among subpopulations. Empirical evidence demonstrates that ALT outperforms the state of the arts on three public benchmarks: Office-31, Office-Home, and VisDA.
Learning to Count Isomorphisms with Graph Neural Networks
Feb 15, 2023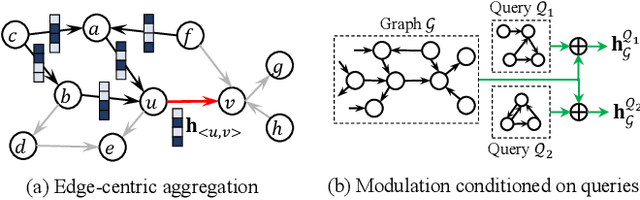
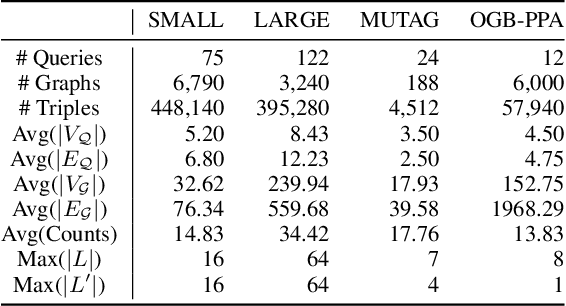
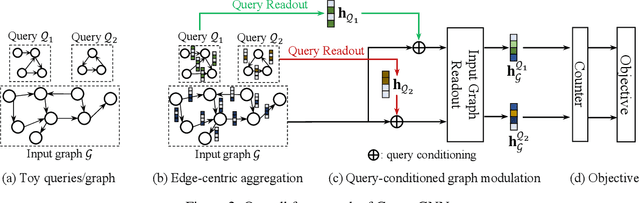
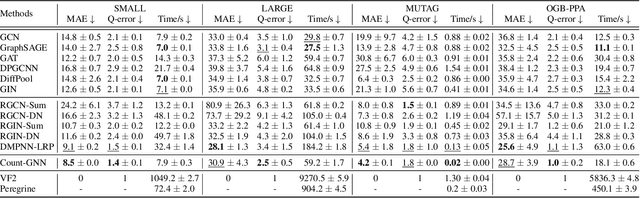
Subgraph isomorphism counting is an important problem on graphs, as many graph-based tasks exploit recurring subgraph patterns. Classical methods usually boil down to a backtracking framework that needs to navigate a huge search space with prohibitive computational costs. Some recent studies resort to graph neural networks (GNNs) to learn a low-dimensional representation for both the query and input graphs, in order to predict the number of subgraph isomorphisms on the input graph. However, typical GNNs employ a node-centric message passing scheme that receives and aggregates messages on nodes, which is inadequate in complex structure matching for isomorphism counting. Moreover, on an input graph, the space of possible query graphs is enormous, and different parts of the input graph will be triggered to match different queries. Thus, expecting a fixed representation of the input graph to match diversely structured query graphs is unrealistic. In this paper, we propose a novel GNN called Count-GNN for subgraph isomorphism counting, to deal with the above challenges. At the edge level, given that an edge is an atomic unit of encoding graph structures, we propose an edge-centric message passing scheme, where messages on edges are propagated and aggregated based on the edge adjacency to preserve fine-grained structural information. At the graph level, we modulate the input graph representation conditioned on the query, so that the input graph can be adapted to each query individually to improve their matching. Finally, we conduct extensive experiments on a number of benchmark datasets to demonstrate the superior performance of Count-GNN.
Deep Convolutional Neural Network for Plume Rise Measurements in Industrial Environments
Feb 15, 2023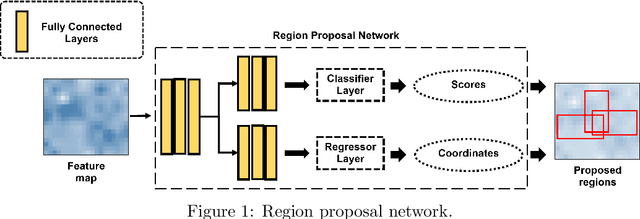
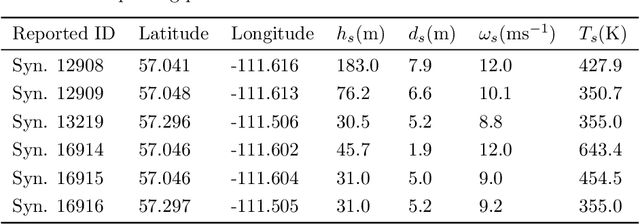
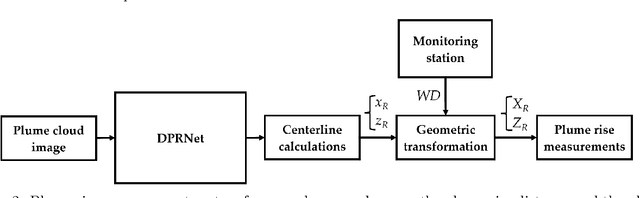
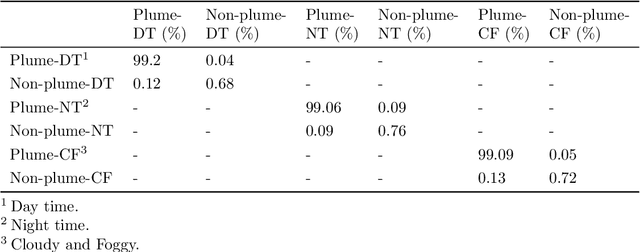
The estimation of plume cloud height is essential for air-quality transport models, local environmental assessment cases, and global climate models. When pollutants are released by a smokestack, plume rise is the constant height at which the plume cloud is carried downwind as its momentum dissipates and the temperatures of the plume cloud and the ambient equalize. Although different parameterizations and equations are used in most air quality models to predict plume rise, verification of these parameterizations has been limited in the past three decades. Beyond validation, there is also value in real-time measurement of plume rise to improve the accuracy of air quality forecasting. In this paper, we propose a low-cost measurement technology that can monitor smokestack plumes and make long-term, real-time measurements of plume rise, improving predictability. To do this, a two-stage method is developed based on deep convolutional neural networks. In the first stage, an improved Mask R-CNN is applied to detect the plume cloud borders and distinguish the plume from its background and other objects. This proposed model is called Deep Plume Rise Net (DPRNet). In the second stage, a geometric transformation phase is applied through the wind direction information from a nearby monitoring station to obtain real-life measurements of different parameters. Finally, the plume cloud boundaries are obtained to calculate the plume rise. Various images with different atmospheric conditions, including day, night, cloudy, and foggy, have been selected for DPRNet training algorithm. Obtained results show the proposed method outperforms widely-used networks in plume cloud border detection and recognition.
SynGraphy: Succinct Summarisation of Large Networks via Small Synthetic Representative Graphs
Feb 15, 2023
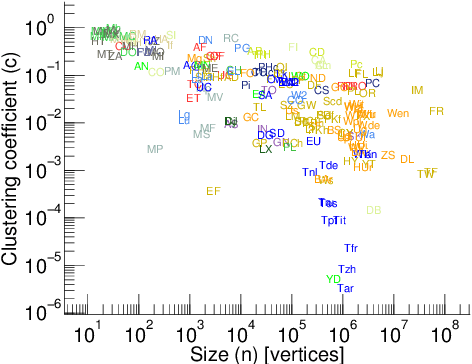
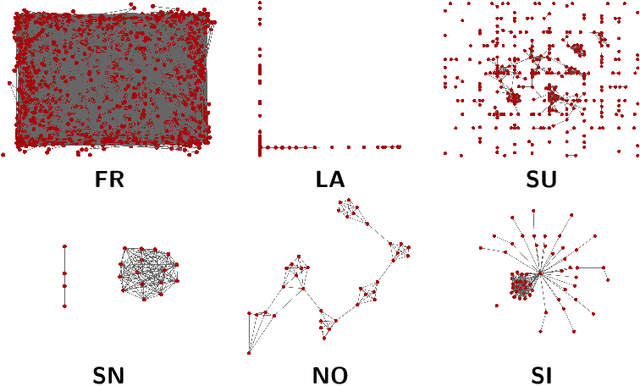
We describe SynGraphy, a method for visually summarising the structure of large network datasets that works by drawing smaller graphs generated to have similar structural properties to the input graphs. Visualising complex networks is crucial to understand and make sense of networked data and the relationships it represents. Due to the large size of many networks, visualisation is extremely difficult; the simple method of drawing large networks like those of Facebook or Twitter leads to graphics that convey little or no information. While modern graph layout algorithms can scale computationally to large networks, their output tends to a common "hairball" look, which makes it difficult to even distinguish different graphs from each other. Graph sampling and graph coarsening techniques partially address these limitations but they are only able to preserve a subset of the properties of the original graphs. In this paper we take the problem of visualising large graphs from a novel perspective: we leave the original graph's nodes and edges behind, and instead summarise its properties such as the clustering coefficient and bipartivity by generating a completely new graph whose structural properties match that of the original graph. To verify the utility of this approach as compared to other graph visualisation algorithms, we perform an experimental evaluation in which we repeatedly asked experimental subjects (professionals in graph mining and related areas) to determine which of two given graphs has a given structural property and then assess which visualisation algorithm helped in identifying the correct answer. Our summarisation approach SynGraphy compares favourably to other techniques on a variety of networks.
Time Encoding Sampling of Bandpass Signals
Jan 31, 2023This paper investigates the problem of sampling and reconstructing bandpass signals using time encoding machine(TEM). It is shown that the sampling in principle is equivalent to periodic non-uniform sampling (PNS). Then the TEM parameters can be set according to the signal bandwidth and amplitude instead of upper-edge frequency and amplitude as in the case of bandlimited/lowpass signals. For a bandpass signal of a single information band, it can be perfectly reconstructed if the TEM parameters are such that the difference between any consecutive values of the time sequence in each channel is bounded by the inverse of the signal bandwidth. A reconstruction method incorporating the interpolation functions of PNS is proposed. Numerical experiments validate the feasibility and effectiveness of the proposed TEM scheme.
Understanding Political Polarisation using Language Models: A dataset and method
Jan 02, 2023

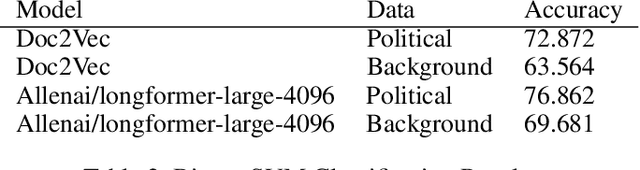
Our paper aims to analyze political polarization in US political system using Language Models, and thereby help candidates make an informed decision. The availability of this information will help voters understand their candidates views on the economy, healthcare, education and other social issues. Our main contributions are a dataset extracted from Wikipedia that spans the past 120 years and a Language model based method that helps analyze how polarized a candidate is. Our data is divided into 2 parts, background information and political information about a candidate, since our hypothesis is that the political views of a candidate should be based on reason and be independent of factors such as birthplace, alma mater, etc. We further split this data into 4 phases chronologically, to help understand if and how the polarization amongst candidates changes. This data has been cleaned to remove biases. To understand the polarization we begin by showing results from some classical language models in Word2Vec and Doc2Vec. And then use more powerful techniques like the Longformer, a transformer based encoder, to assimilate more information and find the nearest neighbors of each candidate based on their political view and their background.
Fusing Models for Prognostics and Health Management of Lithium-Ion Batteries Based on Physics-Informed Neural Networks
Jan 02, 2023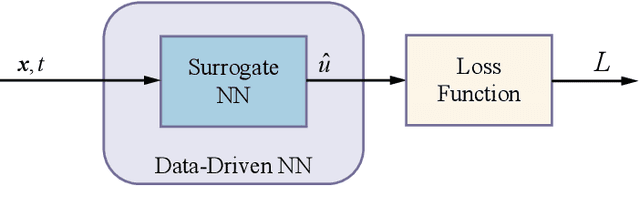
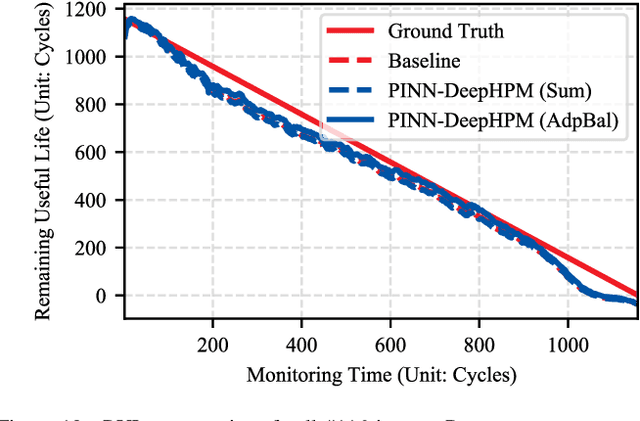
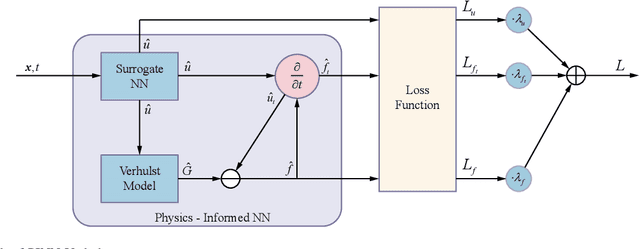
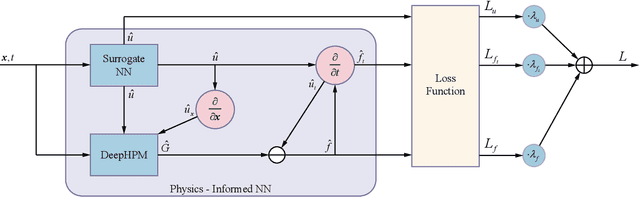
For Prognostics and Health Management (PHM) of Lithium-ion (Li-ion) batteries, many models have been established to characterize their degradation process. The existing empirical or physical models can reveal important information regarding the degradation dynamics. However, there is no general and flexible methods to fuse the information represented by those models. Physics-Informed Neural Network (PINN) is an efficient tool to fuse empirical or physical dynamic models with data-driven models. To take full advantage of various information sources, we propose a model fusion scheme based on PINN. It is implemented by developing a semi-empirical semi-physical Partial Differential Equation (PDE) to model the degradation dynamics of Li-ion-batteries. When there is little prior knowledge about the dynamics, we leverage the data-driven Deep Hidden Physics Model (DeepHPM) to discover the underlying governing dynamic models. The uncovered dynamics information is then fused with that mined by the surrogate neural network in the PINN framework. Moreover, an uncertainty-based adaptive weighting method is employed to balance the multiple learning tasks when training the PINN. The proposed methods are verified on a public dataset of Li-ion Phosphate (LFP)/graphite batteries.
A Comparative Analysis of Bias Amplification in Graph Neural Network Approaches for Recommender Systems
Jan 18, 2023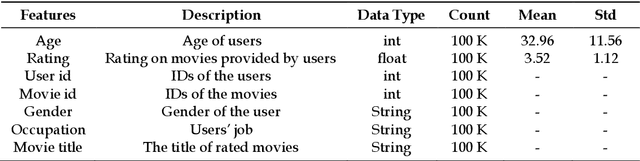
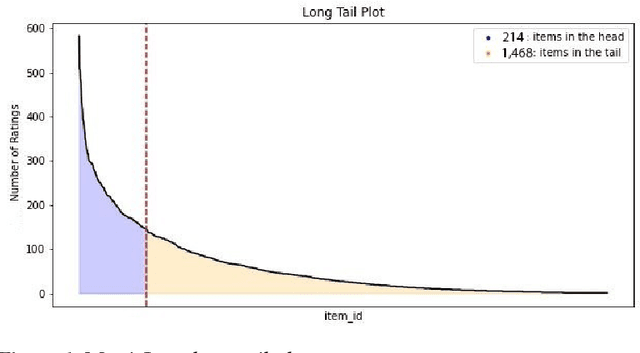
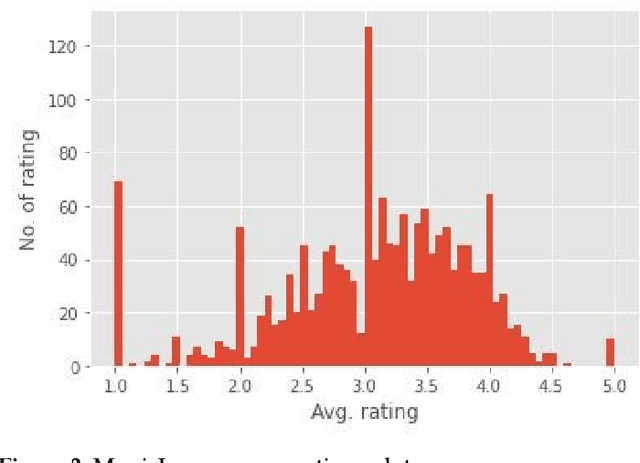
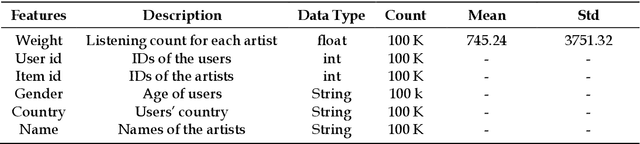
Recommender Systems (RSs) are used to provide users with personalized item recommendations and help them overcome the problem of information overload. Currently, recommendation methods based on deep learning are gaining ground over traditional methods such as matrix factorization due to their ability to represent the complex relationships between users and items and to incorporate additional information. The fact that these data have a graph structure and the greater capability of Graph Neural Networks (GNNs) to learn from these structures has led to their successful incorporation into recommender systems. However, the bias amplification issue needs to be investigated while using these algorithms. Bias results in unfair decisions, which can negatively affect the company reputation and financial status due to societal disappointment and environmental harm. In this paper, we aim to comprehensively study this problem through a literature review and an analysis of the behavior against biases of different GNN-based algorithms compared to state-of-the-art methods. We also intend to explore appropriate solutions to tackle this issue with the least possible impact on the model performance.
Gated-ViGAT: Efficient Bottom-Up Event Recognition and Explanation Using a New Frame Selection Policy and Gating Mechanism
Jan 18, 2023
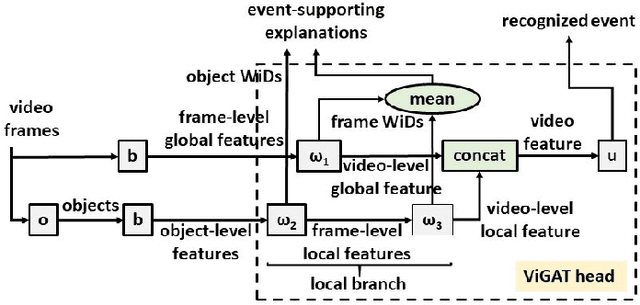
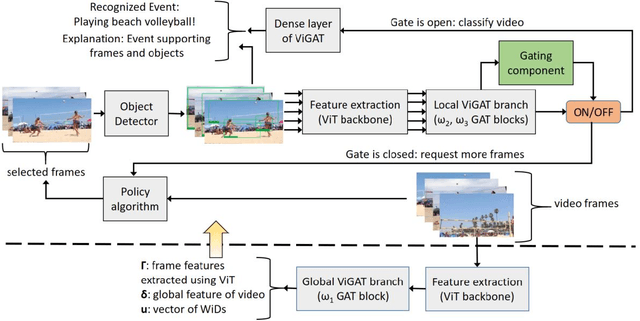

In this paper, Gated-ViGAT, an efficient approach for video event recognition, utilizing bottom-up (object) information, a new frame sampling policy and a gating mechanism is proposed. Specifically, the frame sampling policy uses weighted in-degrees (WiDs), derived from the adjacency matrices of graph attention networks (GATs), and a dissimilarity measure to select the most salient and at the same time diverse frames representing the event in the video. Additionally, the proposed gating mechanism fetches the selected frames sequentially, and commits early-exiting when an adequately confident decision is achieved. In this way, only a few frames are processed by the computationally expensive branch of our network that is responsible for the bottom-up information extraction. The experimental evaluation on two large, publicly available video datasets (MiniKinetics, ActivityNet) demonstrates that Gated-ViGAT provides a large computational complexity reduction in comparison to our previous approach (ViGAT), while maintaining the excellent event recognition and explainability performance. Gated-ViGAT source code is made publicly available at https://github.com/bmezaris/Gated-ViGAT
Decoupled Side Information Fusion for Sequential Recommendation
Apr 23, 2022
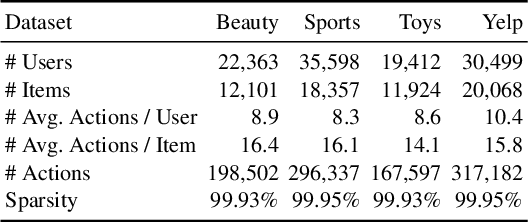
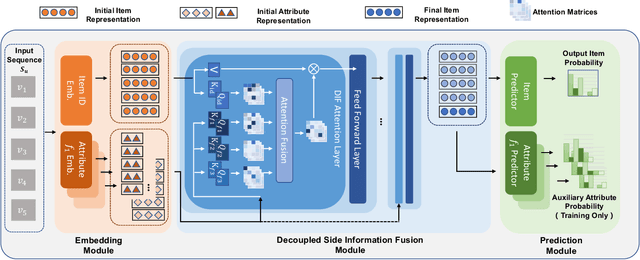
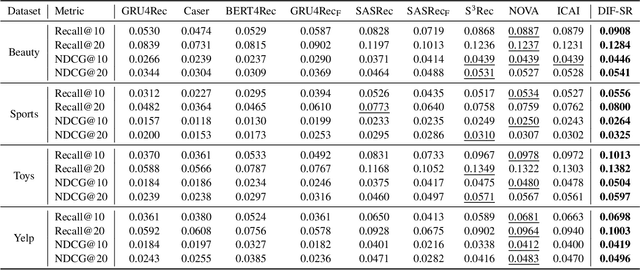
Side information fusion for sequential recommendation (SR) aims to effectively leverage various side information to enhance the performance of next-item prediction. Most state-of-the-art methods build on self-attention networks and focus on exploring various solutions to integrate the item embedding and side information embeddings before the attention layer. However, our analysis shows that the early integration of various types of embeddings limits the expressiveness of attention matrices due to a rank bottleneck and constrains the flexibility of gradients. Also, it involves mixed correlations among the different heterogeneous information resources, which brings extra disturbance to attention calculation. Motivated by this, we propose Decoupled Side Information Fusion for Sequential Recommendation (DIF-SR), which moves the side information from the input to the attention layer and decouples the attention calculation of various side information and item representation. We theoretically and empirically show that the proposed solution allows higher-rank attention matrices and flexible gradients to enhance the modeling capacity of side information fusion. Also, auxiliary attribute predictors are proposed to further activate the beneficial interaction between side information and item representation learning. Extensive experiments on four real-world datasets demonstrate that our proposed solution stably outperforms state-of-the-art SR models. Further studies show that our proposed solution can be readily incorporated into current attention-based SR models and significantly boost performance. Our source code is available at https://github.com/AIM-SE/DIF-SR.