 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Advances and Challenges in Multimodal Remote Sensing Image Registration
Feb 05, 2023
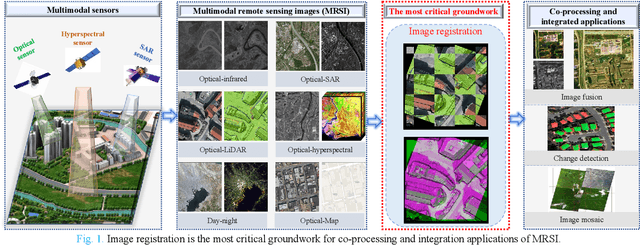
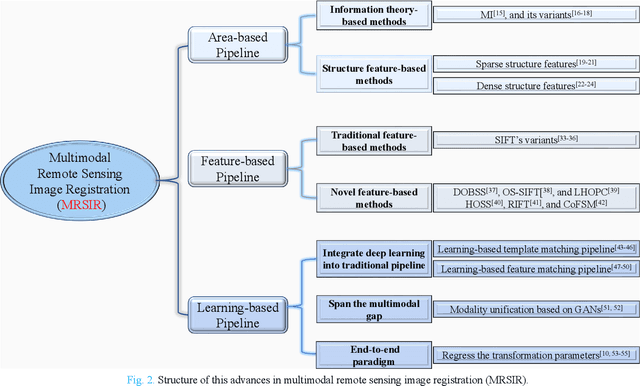
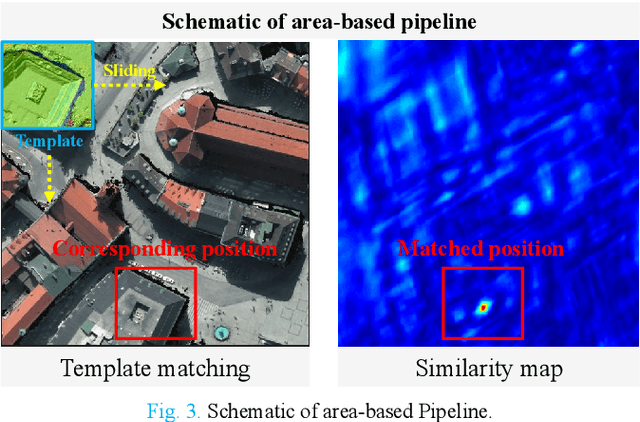

Over the past few decades, with the rapid development of global aerospace and aerial remote sensing technology, the types of sensors have evolved from the traditional monomodal sensors (e.g., optical sensors) to the new generation of multimodal sensors [e.g., multispectral, hyperspectral, light detection and ranging (LiDAR) and synthetic aperture radar (SAR) sensors]. These advanced devices can dynamically provide various and abundant multimodal remote sensing images with different spatial, temporal, and spectral resolutions according to different application requirements. Since then, it is of great scientific significance to carry out the research of multimodal remote sensing image registration, which is a crucial step for integrating the complementary information among multimodal data and making comprehensive observations and analysis of the Earths surface. In this work, we will present our own contributions to the field of multimodal image registration, summarize the advantages and limitations of existing multimodal image registration methods, and then discuss the remaining challenges and make a forward-looking prospect for the future development of the field.
VuLASTE: Long Sequence Model with Abstract Syntax Tree Embedding for vulnerability Detection
Feb 05, 2023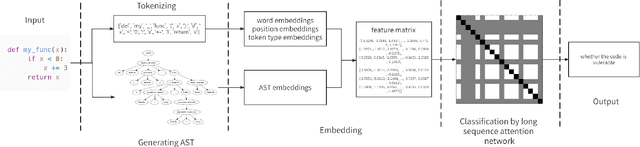
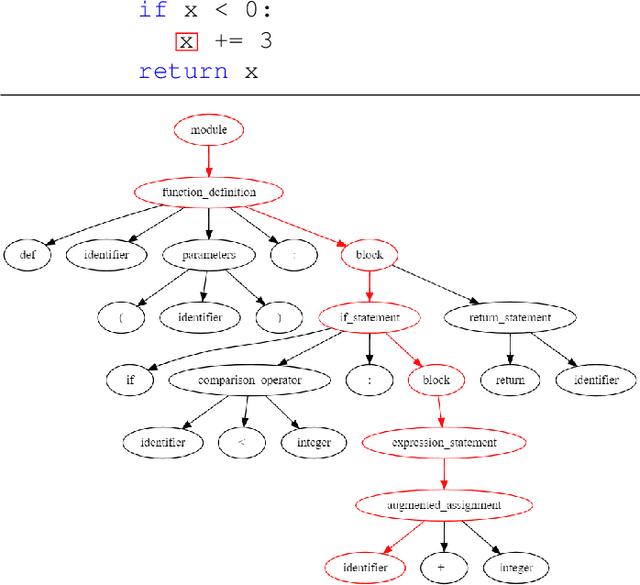
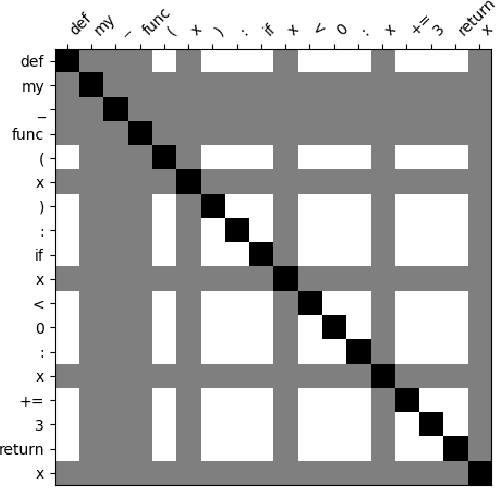

In this paper, we build a model named VuLASTE, which regards vulnerability detection as a special text classification task. To solve the vocabulary explosion problem, VuLASTE uses a byte level BPE algorithm from natural language processing. In VuLASTE, a new AST path embedding is added to represent source code nesting information. We also use a combination of global and dilated window attention from Longformer to extract long sequence semantic from source code. To solve the data imbalance problem, which is a common problem in vulnerability detection datasets, focal loss is used as loss function to make model focus on poorly classified cases during training. To test our model performance on real-world source code, we build a cross-language and multi-repository vulnerability dataset from Github Security Advisory Database. On this dataset, VuLASTE achieved top 50, top 100, top 200, top 500 hits of 29, 51, 86, 228, which are higher than state-of-art researches.
A Secure Dual-Function Radar Communication System via Time-Modulated Arrays
Feb 05, 2023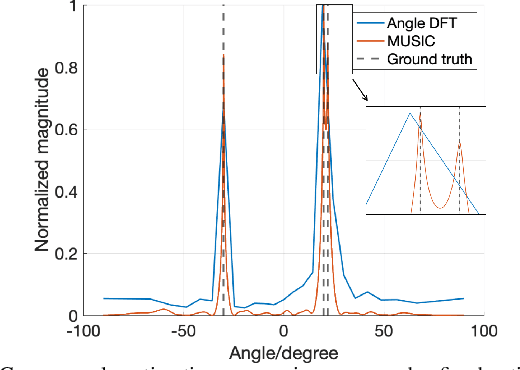
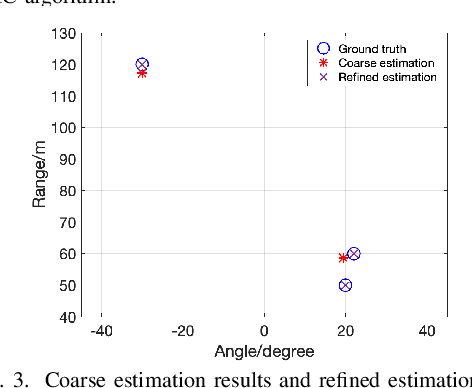
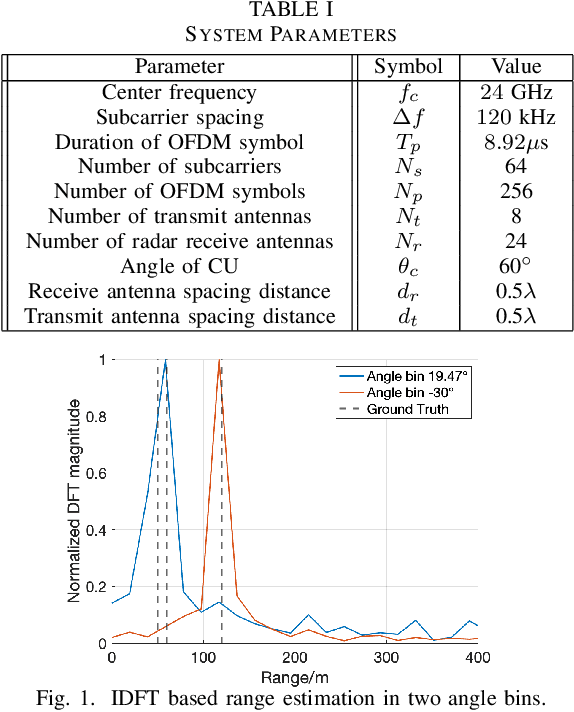
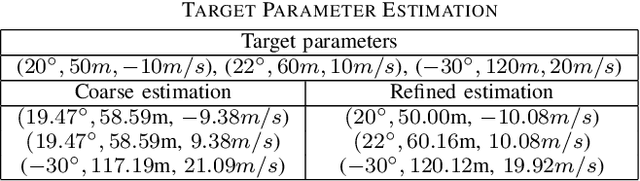
Dual-function radar-communication (DFRC) systems offer high spectral, hardware and power efficiency, as such are prime candidates for 6G wireless systems. DFRC systems use the same waveform for simultaneously probing the surroundings and communicating with other equipment. By exposing the communication information to potential targets, DFRC systems are vulnerable to eavesdropping. In this work, we propose to mitigate the problem by leveraging directional modulation (DM) enabled by a time-modulated array (TMA) that transmits OFDM waveforms. DM can scramble the signal in all directions except the directions of the legitimate user. However, the signal reflected by the targets is also scrambled, thus complicating the extraction of target parameters. We propose a novel, low-complexity target estimation method that estimates the target parameters based on the scrambled received symbols. We also propose a novel method to refine the obtained target estimates at the cost of increased complexity. With the proposed refinement algorithm, the proposed DFRC system can securely communicate with users while having high-precision sensing functionality.
Decoupled Side Information Fusion for Sequential Recommendation
Apr 23, 2022
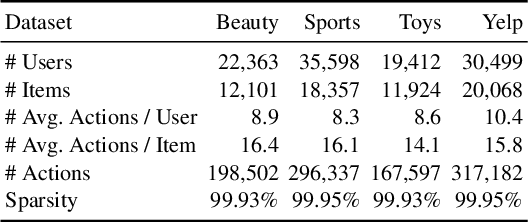
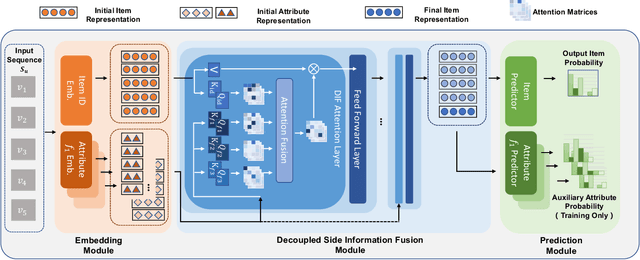
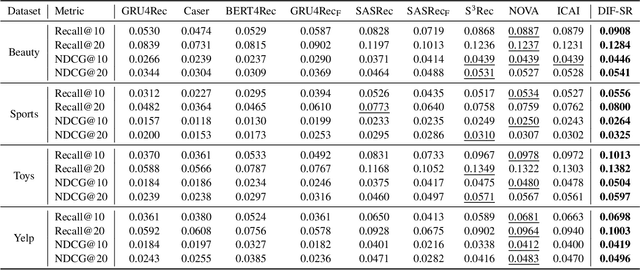
Side information fusion for sequential recommendation (SR) aims to effectively leverage various side information to enhance the performance of next-item prediction. Most state-of-the-art methods build on self-attention networks and focus on exploring various solutions to integrate the item embedding and side information embeddings before the attention layer. However, our analysis shows that the early integration of various types of embeddings limits the expressiveness of attention matrices due to a rank bottleneck and constrains the flexibility of gradients. Also, it involves mixed correlations among the different heterogeneous information resources, which brings extra disturbance to attention calculation. Motivated by this, we propose Decoupled Side Information Fusion for Sequential Recommendation (DIF-SR), which moves the side information from the input to the attention layer and decouples the attention calculation of various side information and item representation. We theoretically and empirically show that the proposed solution allows higher-rank attention matrices and flexible gradients to enhance the modeling capacity of side information fusion. Also, auxiliary attribute predictors are proposed to further activate the beneficial interaction between side information and item representation learning. Extensive experiments on four real-world datasets demonstrate that our proposed solution stably outperforms state-of-the-art SR models. Further studies show that our proposed solution can be readily incorporated into current attention-based SR models and significantly boost performance. Our source code is available at https://github.com/AIM-SE/DIF-SR.
Standing Between Past and Future: Spatio-Temporal Modeling for Multi-Camera 3D Multi-Object Tracking
Feb 07, 2023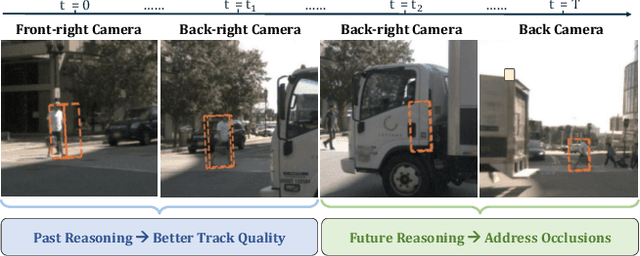
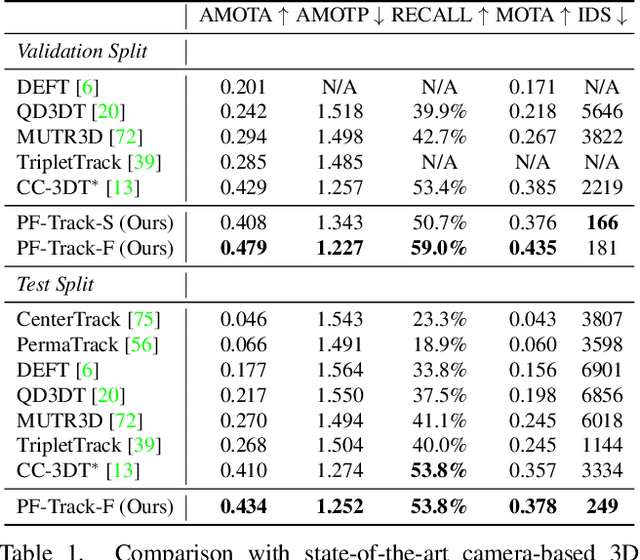
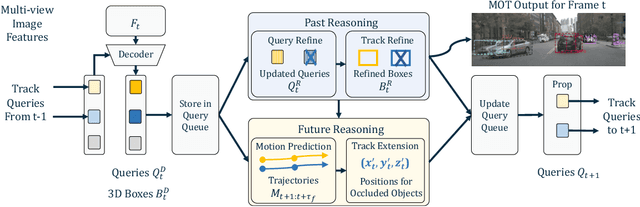
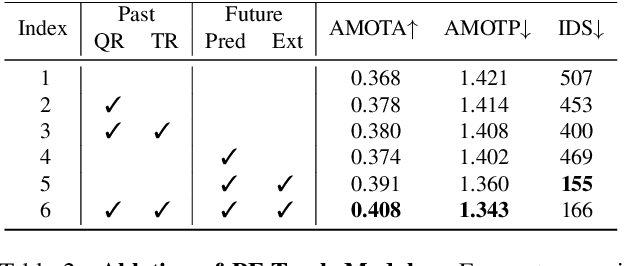
This work proposes an end-to-end multi-camera 3D multi-object tracking (MOT) framework. It emphasizes spatio-temporal continuity and integrates both past and future reasoning for tracked objects. Thus, we name it "Past-and-Future reasoning for Tracking" (PF-Track). Specifically, our method adapts the "tracking by attention" framework and represents tracked instances coherently over time with object queries. To explicitly use historical cues, our "Past Reasoning" module learns to refine the tracks and enhance the object features by cross-attending to queries from previous frames and other objects. The "Future Reasoning" module digests historical information and predicts robust future trajectories. In the case of long-term occlusions, our method maintains the object positions and enables re-association by integrating motion predictions. On the nuScenes dataset, our method improves AMOTA by a large margin and remarkably reduces ID-Switches by 90% compared to prior approaches, which is an order of magnitude less. The code and models are made available at https://github.com/TRI-ML/PF-Track.
N-Gram Nearest Neighbor Machine Translation
Feb 07, 2023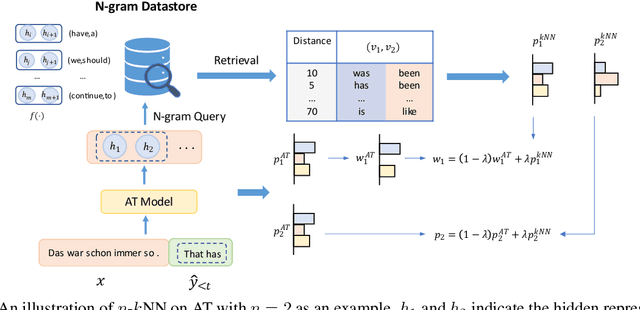
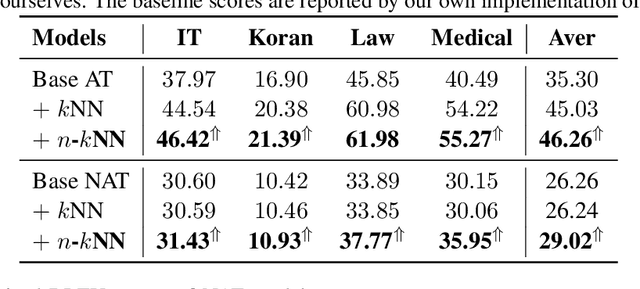
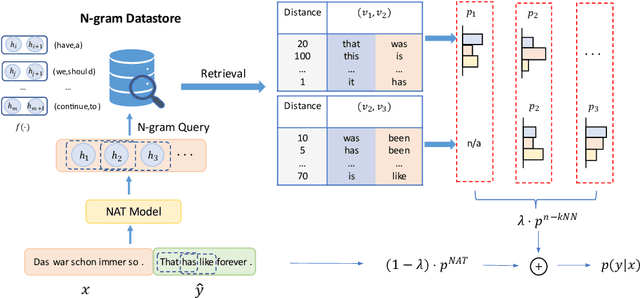
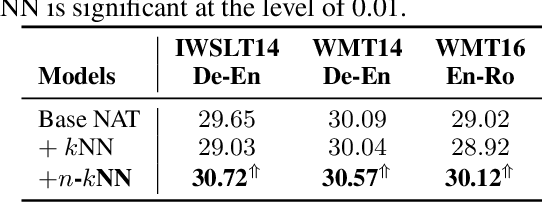
Nearest neighbor machine translation augments the Autoregressive Translation~(AT) with $k$-nearest-neighbor retrieval, by comparing the similarity between the token-level context representations of the target tokens in the query and the datastore. However, the token-level representation may introduce noise when translating ambiguous words, or fail to provide accurate retrieval results when the representation generated by the model contains indistinguishable context information, e.g., Non-Autoregressive Translation~(NAT) models. In this paper, we propose a novel $n$-gram nearest neighbor retrieval method that is model agnostic and applicable to both AT and NAT models. Specifically, we concatenate the adjacent $n$-gram hidden representations as the key, while the tuple of corresponding target tokens is the value. In inference, we propose tailored decoding algorithms for AT and NAT models respectively. We demonstrate that the proposed method consistently outperforms the token-level method on both AT and NAT models as well on general as on domain adaptation translation tasks. On domain adaptation, the proposed method brings $1.03$ and $2.76$ improvements regarding the average BLEU score on AT and NAT models respectively.
Graph Generation with Destination-Driven Diffusion Mixture
Feb 07, 2023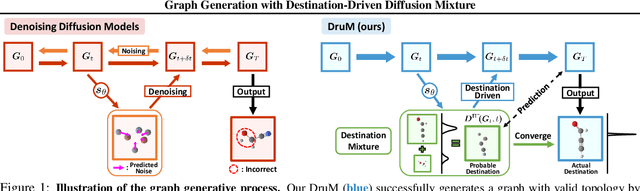
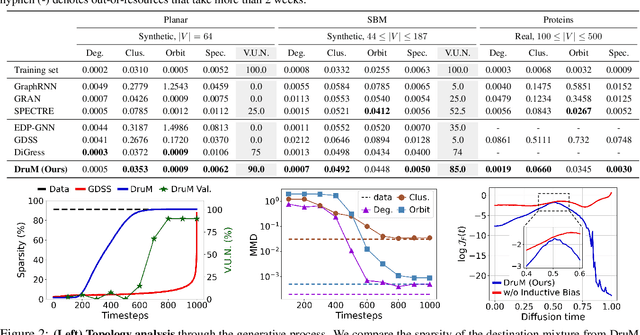
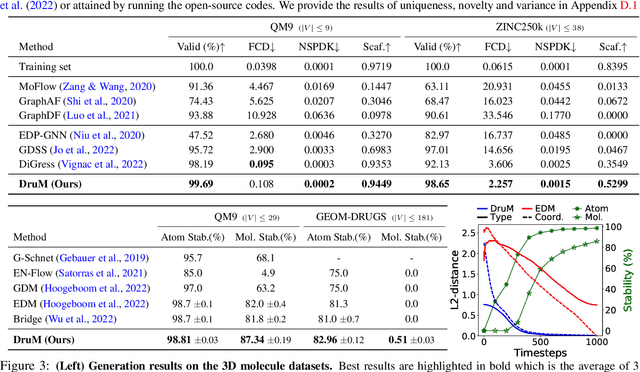
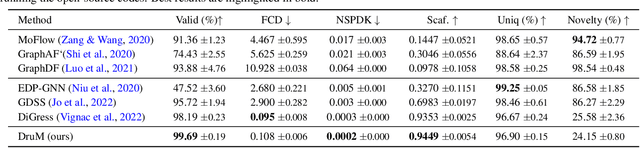
Generation of graphs is a major challenge for real-world tasks that require understanding the complex nature of their non-Euclidean structures. Although diffusion models have achieved notable success in graph generation recently, they are ill-suited for modeling the structural information of graphs since learning to denoise the noisy samples does not explicitly capture the graph topology. To tackle this limitation, we propose a novel generative process that models the topology of graphs by predicting the destination of the process. Specifically, we design the generative process as a mixture of diffusion processes conditioned on the endpoint in the data distribution, which drives the process toward the probable destination. Further, we introduce new training objectives for learning to predict the destination, and discuss the advantages of our generative framework that can explicitly model the graph topology and exploit the inductive bias of the data. Through extensive experimental validation on general graph and 2D/3D molecular graph generation tasks, we show that our method outperforms previous generative models, generating graphs with correct topology with both continuous and discrete features.
Uncoupled Learning of Differential Stackelberg Equilibria with Commitments
Feb 07, 2023A natural solution concept for many multiagent settings is the Stackelberg equilibrium, under which a ``leader'' agent selects a strategy that maximizes its own payoff assuming the ``follower'' chooses their best response to this strategy. Recent work has presented asymmetric learning updates that can be shown to converge to the \textit{differential} Stackelberg equilibria of two-player differentiable games. These updates are ``coupled'' in the sense that the leader requires some information about the follower's payoff function. Such coupled learning rules cannot be applied to \textit{ad hoc} interactive learning settings, and can be computationally impractical even in centralized training settings where the follower's payoffs are known. In this work, we present an ``uncoupled'' learning process under which each player's learning update only depends on their observations of the other's behavior. We prove that this process converges to a local Stackelberg equilibrium under similar conditions as previous coupled methods. We conclude with a discussion of the potential applications of our approach to human--AI cooperation and multi-agent reinforcement learning.
An Informative Path Planning Framework for Active Learning in UAV-based Semantic Mapping
Feb 07, 2023
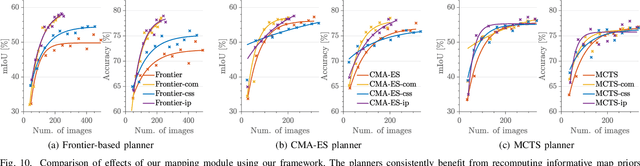

Unmanned aerial vehicles (UAVs) are crucial for aerial mapping and general monitoring tasks. Recent progress in deep learning enabled automated semantic segmentation of imagery to facilitate the interpretation of large-scale complex environments. Commonly used supervised deep learning for segmentation relies on large amounts of pixel-wise labelled data, which is tedious and costly to annotate. The domain-specific visual appearance of aerial environments often prevents the usage of models pre-trained on a static dataset. To address this, we propose a novel general planning framework for UAVs to autonomously acquire informative training images for model re-training. We leverage multiple acquisition functions and fuse them into probabilistic terrain maps. Our framework combines the mapped acquisition function information into the UAV's planning objectives. In this way, the UAV adaptively acquires informative aerial images to be manually labelled for model re-training. Experimental results on real-world data and in a photorealistic simulation show that our framework maximises model performance and drastically reduces labelling efforts. Our map-based planners outperform state-of-the-art local planning.
CoMap: Proactive Provision for Crowdsourcing Map in Automotive Edge Computing
Feb 07, 2023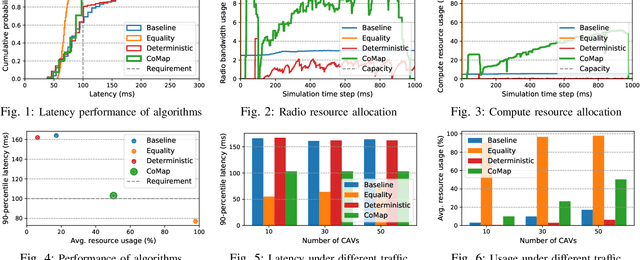
Crowdsourcing data from connected and automated vehicles (CAVs) is a cost-efficient way to achieve high-definition maps with up-to-date transient road information. Achieving the map with deterministic latency performance is, however, challenging due to the unpredictable resource competition and distributional resource demands. In this paper, we propose CoMap, a new crowdsourcing high definition (HD) map to minimize the monetary cost of network resource usage while satisfying the percentile requirement of end-to-end latency. We design a novel CROP algorithm to learn the resource demands of CAV offloading, optimize offloading decisions, and proactively allocate temporal network resources in a fully distributed manner. In particular, we create a prediction model to estimate the uncertainty of resource demands based on Bayesian neural networks and develop a utilization balancing scheme to resolve the imbalanced resource utilization in individual infrastructures. We evaluate the performance of CoMap with extensive simulations in an automotive edge computing network simulator. The results show that CoMap reduces up to 80.4% average resource usage as compared to existing solutions.