 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
On the Feasibility of Out-of-Band Spatial Channel Information for Millimeter-Wave Beam Search
Aug 04, 2022

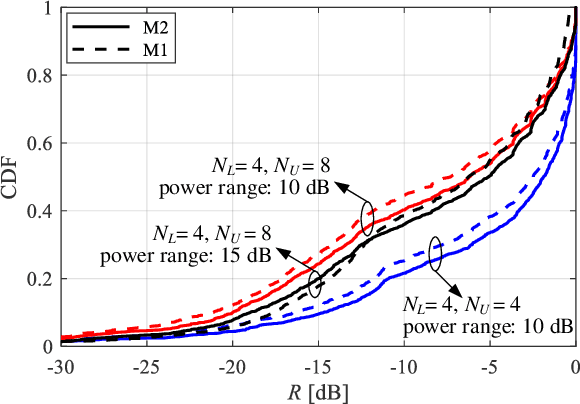
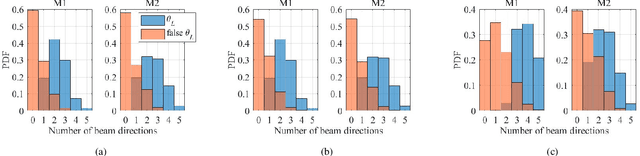
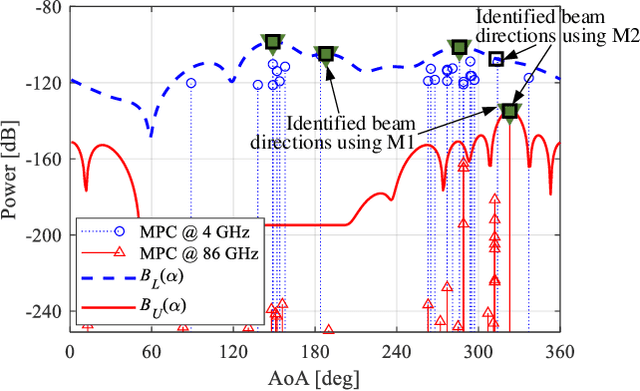
The rollout of millimeter-wave (mmWave) cellular network enables us to realize the full potential of 5G/6G with vastly improved throughput and ultra-low latency. MmWave communication relies on highly directional transmission, which significantly increase the training overhead for fine beam alignment. The concept of using out-of-band spatial information to aid mmWave beam search is developed when multi-band systems operating in parallel. The feasibility of leveraging low-band channel information for coarse estimation of high-band beam directions strongly depends on the spatial congruence between two frequency bands. In this paper, we try to provide insights into the answers of two important questions. First, how similar is the power angular spectra (PAS) of radio channels between two well-separated frequency bands? Then, what is the impact of practical system configurations on spatial channel similarity? Specifically, the beam direction-based metric is proposed to measure the power loss and number of false directions if out-of-band spatial information is used instead of in-band information. This metric is more practical and useful than comparing normalized PAS directly. Point cloud ray-tracing and measurement results across multiple frequency bands and environments show that the degree of spatial similarity of beamformed channels is related to antenna beamwidth, frequency gap, and radio link conditions.
Underwater target detection based on improved YOLOv7
Feb 14, 2023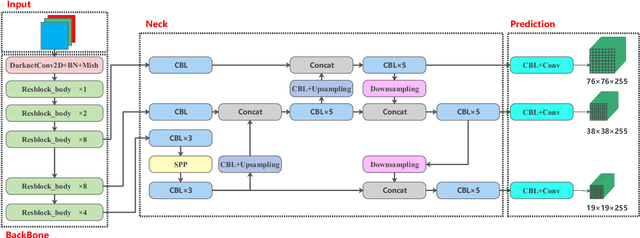
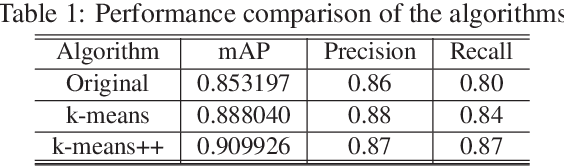
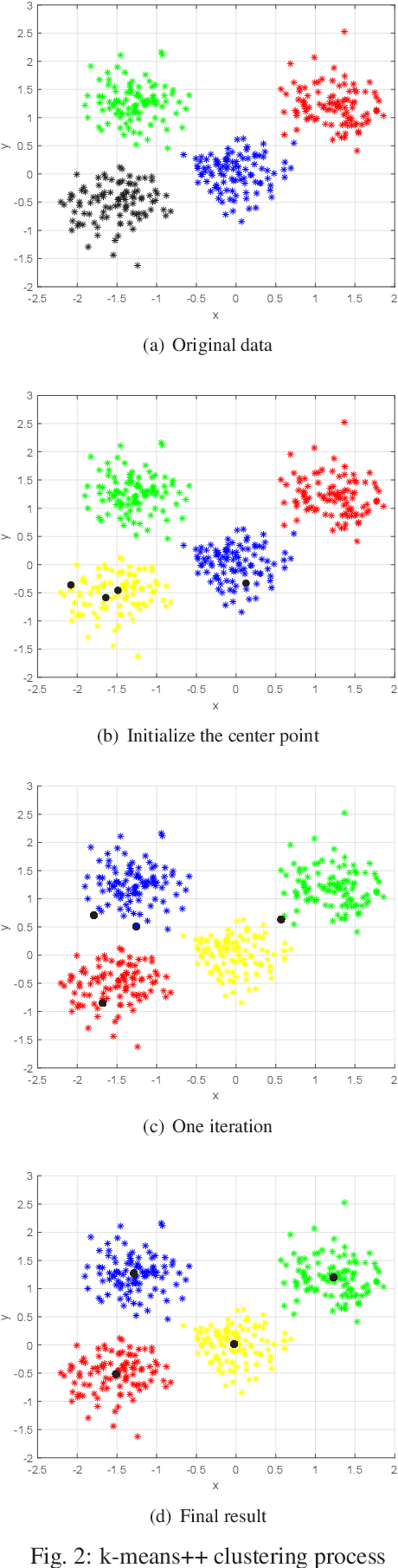
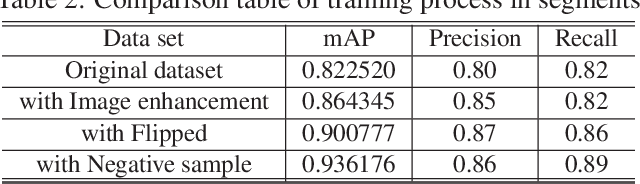
Underwater target detection is a crucial aspect of ocean exploration. However, conventional underwater target detection methods face several challenges such as inaccurate feature extraction, slow detection speed and lack of robustness in complex underwater environments. To address these limitations, this study proposes an improved YOLOv7 network (YOLOv7-AC) for underwater target detection. The proposed network utilizes an ACmixBlock module to replace the 3x3 convolution block in the E-ELAN structure, and incorporates jump connections and 1x1 convolution architecture between ACmixBlock modules to improve feature extraction and network reasoning speed. Additionally, a ResNet-ACmix module is designed to avoid feature information loss and reduce computation, while a Global Attention Mechanism (GAM) is inserted in the backbone and head parts of the model to improve feature extraction. Furthermore, the K-means++ algorithm is used instead of K-means to obtain anchor boxes and enhance model accuracy. Experimental results show that the improved YOLOv7 network outperforms the original YOLOv7 model and other popular underwater target detection methods. The proposed network achieved a mean average precision (mAP) value of 89.6% and 97.4% on the URPC dataset and Brackish dataset, respectively, and demonstrated a higher frame per second (FPS) compared to the original YOLOv7 model. The source code for this study is publicly available at https://github.com/NZWANG/YOLOV7-AC. In conclusion, the improved YOLOv7 network proposed in this study represents a promising solution for underwater target detection and holds great potential for practical applications in various underwater tasks.
Analytical Model of Nonlinear Fiber Propagation for General Dual-Polarization Four-Dimensional Modulation Format
Feb 14, 2023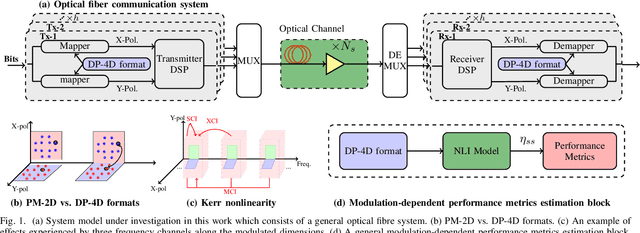
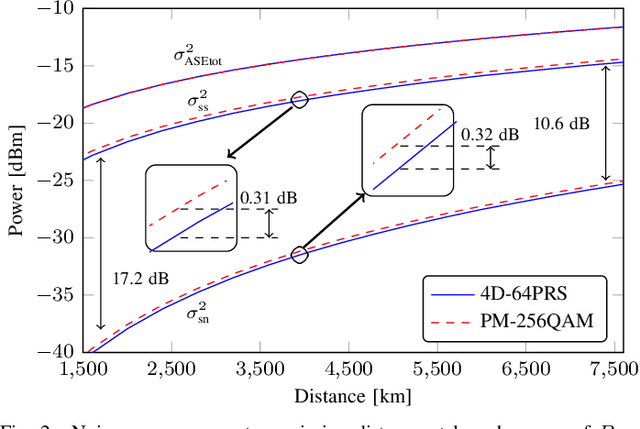
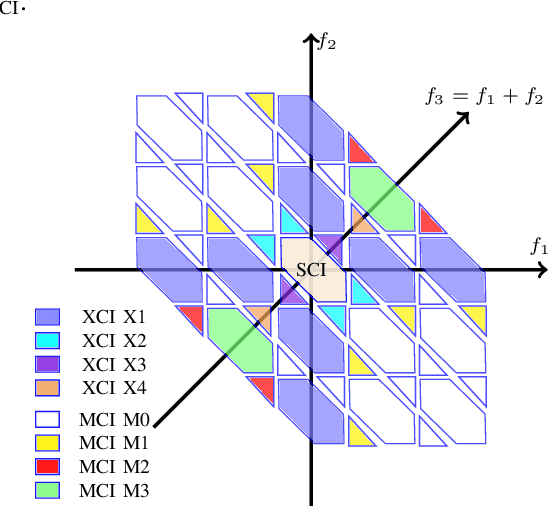
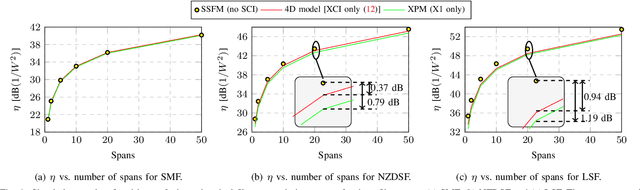
Coherent dual-polarization (DP) optical transmission systems encode information on the four available degrees of freedom of an optical field: the two polarization states, each with two quadrature components. Such systems naturally operate based on a four-dimensional (4D) signal space. Having a general analytical model to accurately estimate nonlinear interference (NLI) is key to analyze such transmission systems as well as to study how different DP-4D formats are affected by NLI. However, the available models in the literature are not completely general. They either do not apply to the entire DP-4D formats or do not consider all the NLI contributions. In this paper we develop a model that applies to the entire class of DP-4D modulation formats. Our model takes self-channel interference, cross-channel interference and multiple-channel interference effects into account. As an application of our model, we further study the effects of signal-noise interactions in long-haul transmission via the proposed model. When compared to previous results in the literature, our model is more accurate at predicting the contribution of NLI for both low and high dispersion fibers in single- and multi-channel transmission systems. For the NLI, we report an average gap from split step Fourier simulation results below 0.15dB. The simulation results further show that by considering signal-noise interactions, the proposed model in long-haul transmission improves the NLI power accuracy prediction by up to 8.5%.
Variational multichannel multiclass segmentation\endgraf using unsupervised lifting with CNNs
Feb 04, 2023


We propose an unsupervised image segmentation approach, that combines a variational energy functional and deep convolutional neural networks. The variational part is based on a recent multichannel multiphase Chan-Vese model, which is capable to extract useful information from multiple input images simultaneously. We implement a flexible multiclass segmentation method that divides a given image into $K$ different regions. We use convolutional neural networks (CNNs) targeting a pre-decomposition of the image. By subsequently minimising the segmentation functional, the final segmentation is obtained in a fully unsupervised manner. Special emphasis is given to the extraction of informative feature maps serving as a starting point for the segmentation. The initial results indicate that the proposed method is able to decompose and segment the different regions of various types of images, such as texture and medical images and compare its performance with another multiphase segmentation method.
Leveraging Angular Information Between Feature and Classifier for Long-tailed Learning: A Prediction Reformulation Approach
Dec 03, 2022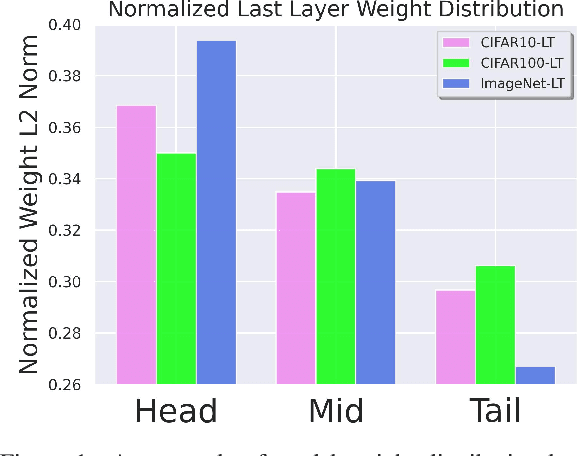
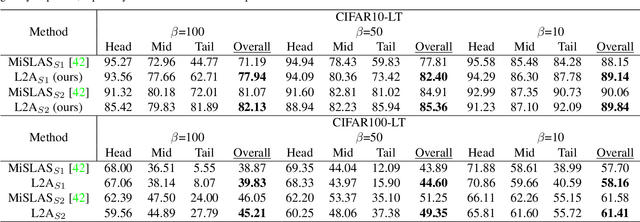
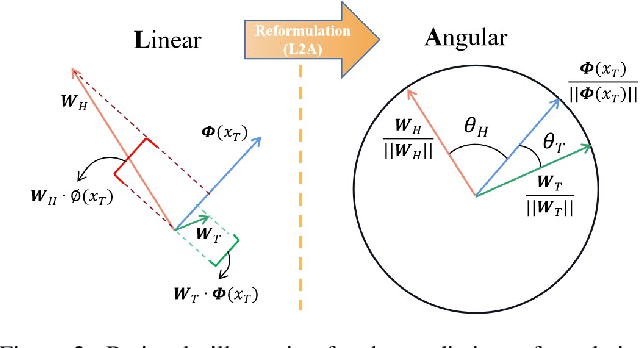
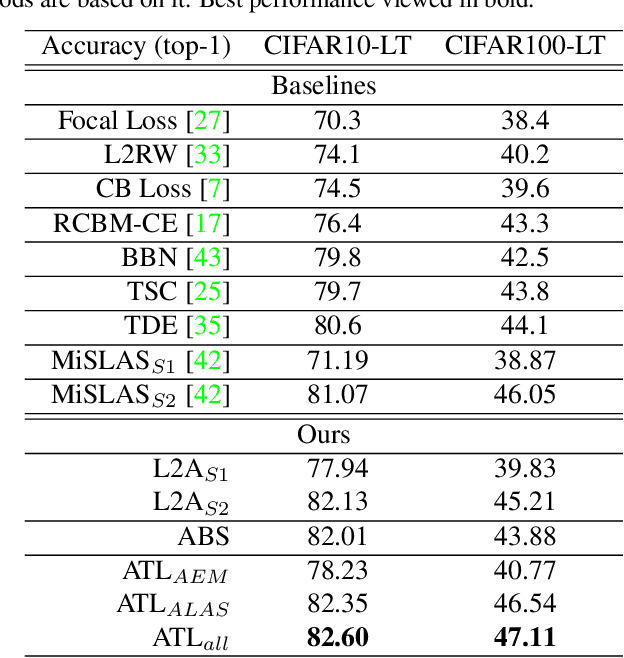
Deep neural networks still struggle on long-tailed image datasets, and one of the reasons is that the imbalance of training data across categories leads to the imbalance of trained model parameters. Motivated by the empirical findings that trained classifiers yield larger weight norms in head classes, we propose to reformulate the recognition probabilities through included angles without re-balancing the classifier weights. Specifically, we calculate the angles between the data feature and the class-wise classifier weights to obtain angle-based prediction results. Inspired by the performance improvement of the predictive form reformulation and the outstanding performance of the widely used two-stage learning framework, we explore the different properties of this angular prediction and propose novel modules to improve the performance of different components in the framework. Our method is able to obtain the best performance among peer methods without pretraining on CIFAR10/100-LT and ImageNet-LT. Source code will be made publicly available.
IH-ViT: Vision Transformer-based Integrated Circuit Appear-ance Defect Detection
Feb 09, 2023

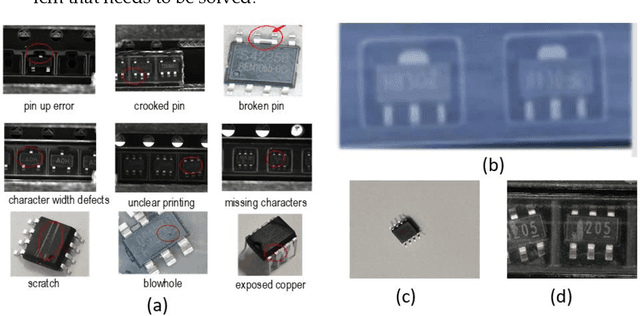

For the problems of low recognition rate and slow recognition speed of traditional detection methods in IC appearance defect detection, we propose an IC appearance defect detection algo-rithm IH-ViT. Our proposed model takes advantage of the respective strengths of CNN and ViT to acquire image features from both local and global aspects, and finally fuses the two features for decision making to determine the class of defects, thus obtaining better accuracy of IC defect recognition. To address the problem that IC appearance defects are mainly reflected in the dif-ferences in details, which are difficult to identify by traditional algorithms, we improved the tra-ditional ViT by performing an additional convolution operation inside the batch. For the problem of information imbalance of samples due to diverse sources of data sets, we adopt a dual-channel image segmentation technique to further improve the accuracy of IC appearance defects. Finally, after testing, our proposed hybrid IH-ViT model achieved 72.51% accuracy, which is 2.8% and 6.06% higher than ResNet50 and ViT models alone. The proposed algorithm can quickly and accurately detect the defect status of IC appearance and effectively improve the productivity of IC packaging and testing companies.
Reliable Natural Language Understanding with Large Language Models and Answer Set Programming
Feb 09, 2023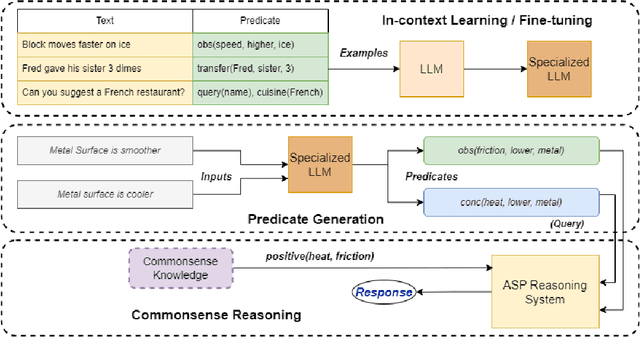
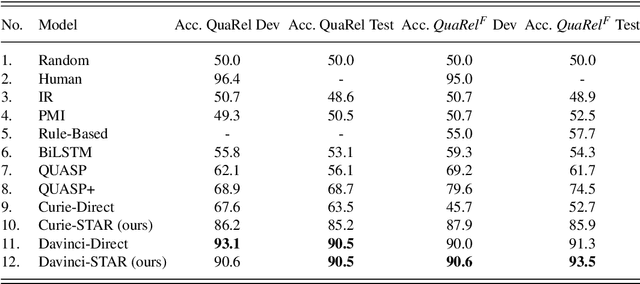

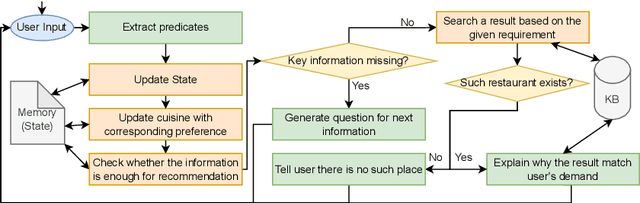
Humans understand language by extracting information (meaning) from sentences, combining it with existing commonsense knowledge, and then performing reasoning to draw conclusions. While large language models (LLMs) such as GPT-3 and ChatGPT are able to leverage patterns in the text to solve a variety of NLP tasks, they fall short in problems that require reasoning. They also cannot reliably explain the answers generated for a given question. In order to emulate humans better, we propose STAR, a framework that combines LLMs with Answer Set Programming (ASP). We show how LLMs can be used to effectively extract knowledge -- represented as predicates -- from language. Goal-directed ASP is then employed to reliably reason over this knowledge. We apply the STAR framework to three different NLU tasks requiring reasoning: qualitative reasoning, mathematical reasoning, and goal-directed conversation. Our experiments reveal that STAR is able to bridge the gap of reasoning in NLU tasks, leading to significant performance improvements, especially for smaller LLMs, i.e., LLMs with a smaller number of parameters. NLU applications developed using the STAR framework are also explainable: along with the predicates generated, a justification in the form of a proof tree can be produced for a given output.
Importance Sampling Deterministic Annealing for Clustering
Feb 09, 2023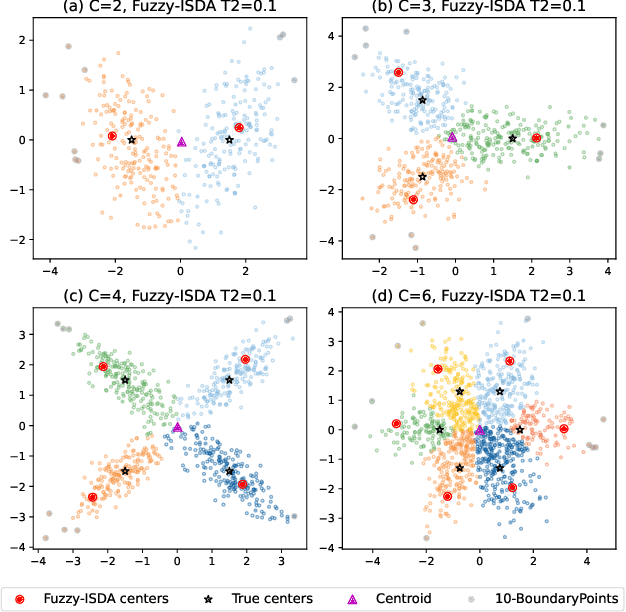
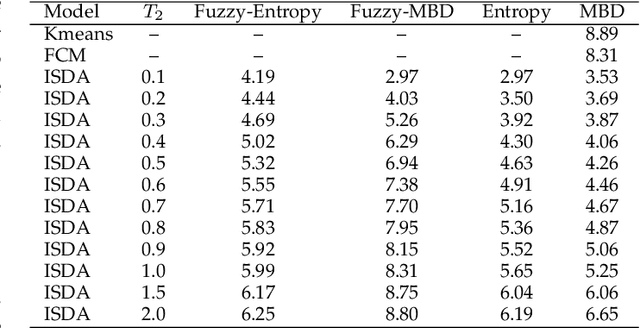
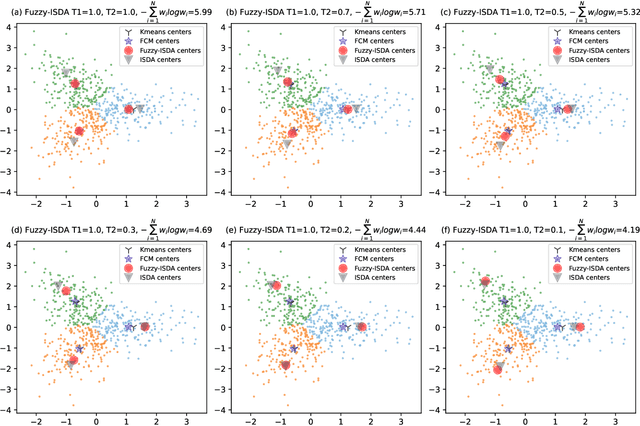
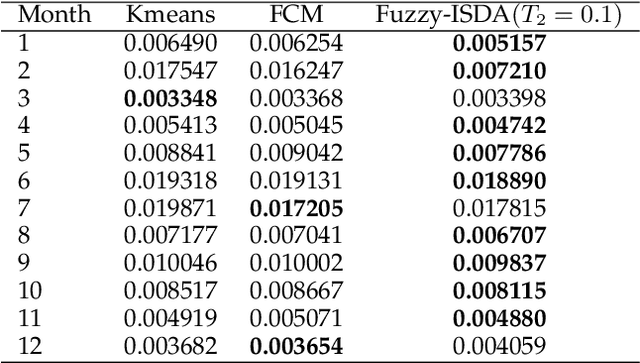
A current assumption of most clustering methods is that the training data and future data are taken from the same distribution. However, this assumption may not hold in some real-world scenarios. In this paper, we propose an importance sampling based deterministic annealing approach (ISDA) for clustering problems which minimizes the worst case of expected distortions under the constraint of distribution deviation. The distribution deviation constraint can be converted to the constraint over a set of weight distributions centered on the uniform distribution derived from importance sampling. The objective of the proposed approach is to minimize the loss under maximum degradation hence the resulting problem is a constrained minimax optimization problem which can be reformulated to an unconstrained problem using the Lagrange method and be solved by the quasi-newton algorithm. Experiment results on synthetic datasets and a real-world load forecasting problem validate the effectiveness of the proposed ISDA. Furthermore, we show that fuzzy c-means is a special case of ISDA with the logarithmic distortion. This observation sheds a new light on the relationship between fuzzy c-means and deterministic annealing clustering algorithms and provides an interesting physical and information-theoretical interpretation for fuzzy exponent $m$.
Improving the Generalizability of Collaborative Dialogue Analysis with Multi-Feature Embeddings
Feb 09, 2023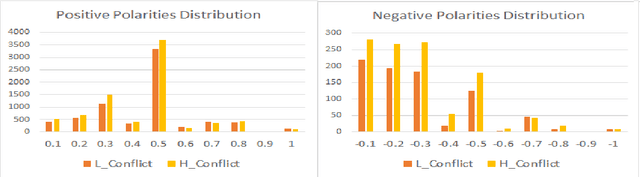
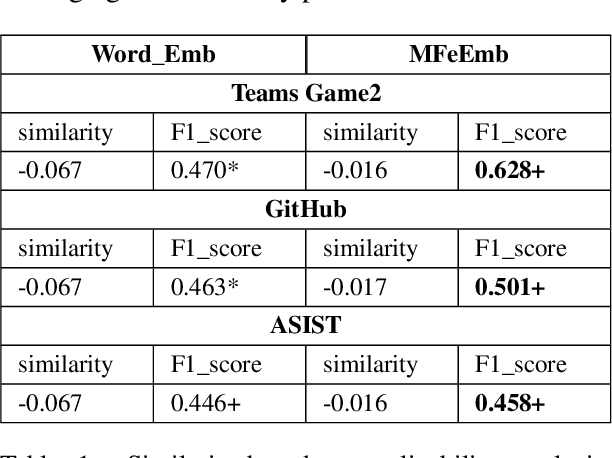
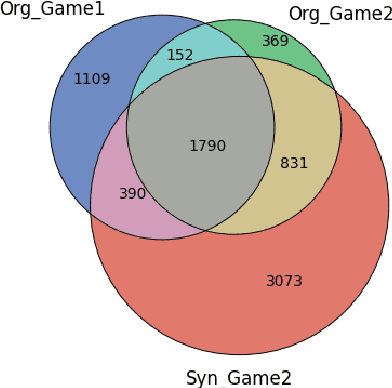
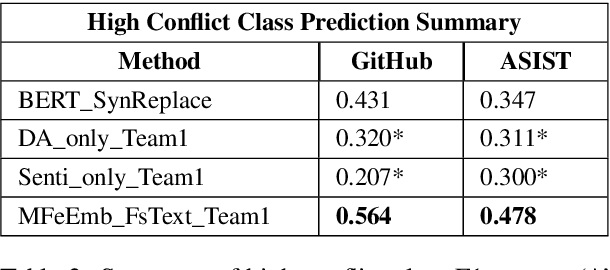
Conflict prediction in communication is integral to the design of virtual agents that support successful teamwork by providing timely assistance. The aim of our research is to analyze discourse to predict collaboration success. Unfortunately, resource scarcity is a problem that teamwork researchers commonly face since it is hard to gather a large number of training examples. To alleviate this problem, this paper introduces a multi-feature embedding (MFeEmb) that improves the generalizability of conflict prediction models trained on dialogue sequences. MFeEmb leverages textual, structural, and semantic information from the dialogues by incorporating lexical, dialogue acts, and sentiment features. The use of dialogue acts and sentiment features reduces performance loss from natural distribution shifts caused mainly by changes in vocabulary. This paper demonstrates the performance of MFeEmb on domain adaptation problems in which the model is trained on discourse from one task domain and applied to predict team performance in a different domain. The generalizability of MFeEmb is quantified using the similarity measure proposed by Bontonou et al. (2021). Our results show that MFeEmb serves as an excellent domain-agnostic representation for meta-pretraining a few-shot model on collaborative multiparty dialogues.
Incorporating Total Variation Regularization in the design of an intelligent Query by Humming system
Feb 09, 2023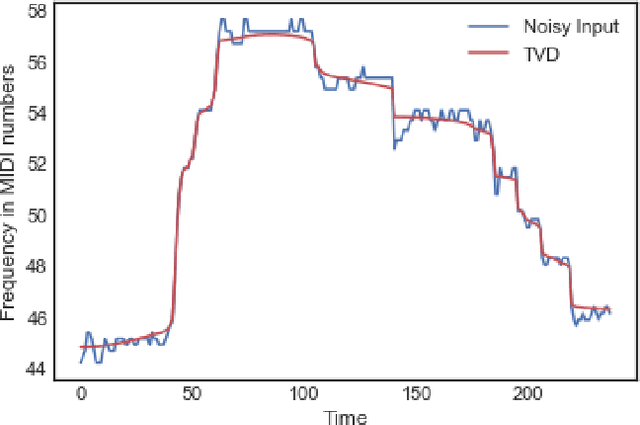
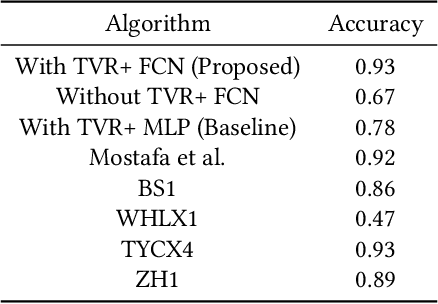
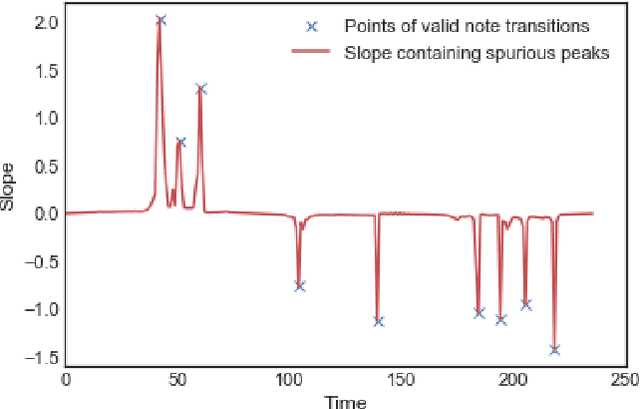
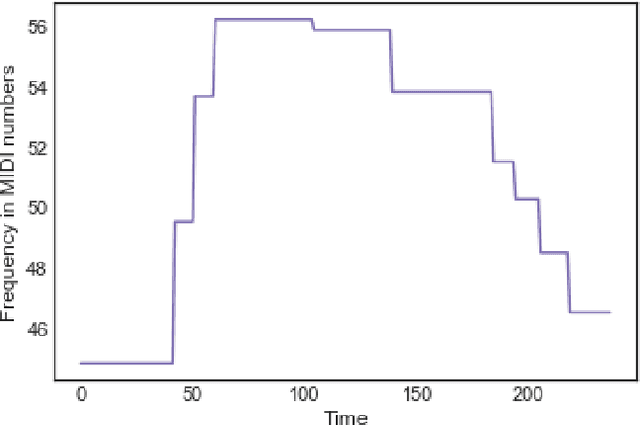
A Query-By-Humming (QBH) system constitutes a particular case of music information retrieval where the input is a user-hummed melody and the output is the original song which contains that melody. A typical QBH system consists of melody extraction and candidate melody retrieval. For melody extraction, accurate note transcription is the key enabling technology. However, current transcription methods are unable to definitively capture the melody and address inaccuracies in user-hummed queries. In this paper, we incorporate Total Variation Regularization (TVR) to denoise queries. This approach accounts for user error in humming without loss of meaningful data and reliably captures the underlying melody. For candidate melody retrieval, we employ a deep learning approach to time series classification using a Fully Convolutional Neural Network. The trained network classifies the incoming query as belonging to one of the target songs. For our experiments, we use Roger Jang's MIR-QBSH dataset which is the standard MIREX dataset. We demonstrate that inclusion of TVR denoised queries in the training set enhances the overall accuracy of the system to 93% which is higher than other state-of-the-art QBH systems.